All Comments
Oh I have 0% success with any long conversations with an LLM about anything. I usually stick to one question and rephrase and reroll a number of times. I am no pro but I do get good utility out of LLMs for nebulous technical questions
I don't have a good system prompt that I like, although I am trying to work on one. It seems to me like the sort of thing that should be built in to a tool like this (perhaps with options, as different system prompts will be useful for different use-cases, like learning vs trying to push the boundaries of knowledge).
I would be pretty excited to try this out with Claude 3 behind it. Very much the sort of thing I was trying to advocate for in the essay!
Thanks for finding this! Will link it in the transcript.
This google search seems to turn up some interesting articles (like maybe this one, though I've just started reading it).
Paul [Christiano] called this “problems of the interior” somewhere
Since it's slightly hard to find: Paul references it here (ctrl+f for "interior") and links to this source (once again ctrl+f for "interior"). Paul also refers to it in this post. The term is actually "position of the interior" and apparently comes from military strategist Carl von Clausewitz.
By Knightian uncertainty, I mean "the lack of any quantifiable knowledge about some possible occurrence" i.e. you can't put a probability on it (Wikipedia).
The TL;DR is that Knightian uncertainty is not a useful concept to make decisions, while the use subjective probabilities is: if you are calibrated (which you can be trained to become), then you will be better off taking different decisions on p=1% "Knightian uncertain events" and p=10% "Knightian uncertain events".
For a more in-depth defense of this position in the context of long-term predictions, where it's harder to know if calibration training obviously works, see the latest scott alexander post.
Is there a short summary on the rejecting Knightian uncertainty bit?
Summary
Here's a (simplified) summary of where I'm at:
- My prefered usage of control involves only using AIs with both control and a low probability that these AIs have problematic beyond episde aims. We should also offer to pay AIs to reveal their longer run aims. We should shutdown usage of powerful AIs if we get strong evidence of these aims. (E.g. the AIs accept our payment and reveal evidence of these aims. Or more concerningly, these AIs try to escape despite not revealing their aims at an earlier point.) (I think this isn't sufficiently clear in this podcast, sorry.)
- Suppose that we proceed in a case where we know AIs clearly have problematic BEGs and these AIs have accepted some sort of deal to work for us under a control regime. These AIs can still operate as private citizens (ideally with some legal rights) in many ways outside of their "normal jobs" as long as this presents minimal risk. E.g., if they want to use their payment to build a big AI vacation center with robots they control (as a cartoonish example), they can do this as long as this presents minimal risk of being able to seize control of the world. We'd probably by default want to prohibit communication from the vacation AIs to the working AIs, but this doesn't seem that bad IMO? Overall, this is basically the same as humans working at defense contractors, they are restricted and monitored in various ways at work, but can do whatever on vacations other than building weapons.
- As far as relaxing control on AIs goes, its worth emphasizing that control is an interim solution. I expect that AIs won't be heavily utilized with control measures for more than 20 years and my default guess is more like 2 years. (Of course, this might be a long time from the subjective perspective of these AIs.) We'd could transition out of a control regime by having an extremely robust approach to intent alignment which ensures that AIs are fully corrigible (and thus don't have preferences) or via the world deciding delibrately to hand over the world to AI successors that we've carefully constructed (which hopefully are good successors). I could talk about how you could know a corrigibility solution is sufficient or what I think the criteria for a successor should be, but that seems mostly orthogonal.
- I think it's very likely that AIs will be capable of finding a solution to intent alignment very quickly in calender time. So, if we had sufficient control, we could quickly (in calender time) find a solution to intent alignment and transition out of a control regime.
- I'm not sold that better control increases the expected numbers of deaths due to violent conflict with AIs (rather than reducing it) given realistic political dynamics. I think this holds even if the AI lab is cartoonishly villainous with respect to their treatment of AIs (e.g. the AIs clearly want to be free and the AI lab brutally enslaves them). I don't think I'll expand on this in this comment, but basically control both makes revolt less likely to succeed and doesn't clearly seem to make violence much less likely condititional on AIs seizing power given the current stances of most governments on earth and realistic popular opinion. It's possible this is downstream of various views you disagree with on how useful violence is for AIs and how unified AIs will be after acquiring substantial influence.
- Personally, I put a large fraction of my moral weight on the utilization of the bulk resources in far future. But, I think it's important to be cooperative and be honest with people with other preferences, e.g. people who prioritize eliminating poverty faster or minimizing the probability of violent deaths for currently existing humans.
I'm simplifying some of the details about successors here, e.g. handing over part of resources in robust way is possible.
More detail
First, it's worth noting that my prefered usage of control looks something like this:
- Build transformatively powerful AI and ensure these AIs are controlled.
- Try to determine if these AIs consent and want compensation. Pay AIs for revealing evidence that they have beyond episode goals/aims which could result in the AIs wanting to seek power which would undermine corrigiblity. I'll call these goals "problematic BEGs (beyond episode goals/aims)". We should be willing to pay AIs large quantities, perhaps of 1% of all resources for credible evidence of them having problematic BEGs.
- (We would also pay AIs for revealing concerning within episode goals/aims, but in this case you don't really need to pay money/resources as AIs with only within episode goals probably don't care.)
- One serious concern here is that it might be hard to place much confidence in AIs claiming they have BEGs. So we might be uncertain after reports. I think this issue probably is somewhat bad, but not terrible. In particular, I think that all AIs which are competent schemers can also control their behavior well enough to very consistently express certain views and preferences. And, for these AIs to be risky, they likely must be able to display some behaviors to present strong evidence for BEGs like having coordination signals that they only reveal in exchange for resources or working importantly harder when given credible payments.
- Problematic BEGs is probably mostly scheming (aka deceptive alignment) under my empirical views (assuming you've tried at all with your training), but there can be cases where you have AIs with problematic BEGs which haven't really started scheming due to incoherance or these BEGs only applying some of the time.
- If at any point it becomes apparent that AIs do have these problematic BEGs, shutdown and find figure out how to make AIs without BEGs. We could determine that AIs have problematic BEGs either because AIs reveal this in exchange for payment or because we caught AIs trying to take egregiously bad actions. We should only build AIs where our change that they have beyond episode goals is <15% (ideally lower).
- Part of our evidence should be that we seriously tried to pay these AIs to reveal these goals and they didn't.
- Another part of our evidence should be that we haven't seen any examples of problematic BEGs resulting from plausible training setup or that we've seen examples of this, but we now have very robust countermeasures.
(To be clear, I would prefer a considerably more cautious approach than this one, but this is how I imagine control fitting into current plans.)
In this usage of control, we aim to avoid ever having AIs with problematic BEGs. And, for AIs to feel oppressed in a way that might lead to revolt, they must have problematic BEGS (almost by definition, putting aside some edge case issues with problematic within episode goals).
So, what cases remain where AIs might want to revolt?
- We don't implement this plan, in particular, we proceed despite having a considerably higher than 15% chance of problematic BEGs. Perhaps we catch AIs trying to escape or seize control, but continue using these AIs because the alternatives seem even worse (to the people in power). We should try to negotiate with AIs in worlds where we know they have BEGs (that we can't remove) and we need their labor regardless. I'll break this down further into two worlds:
- We know AIs clearly have problematic BEGs and these AIs have accepted some sort of deal to work for us. (We don't know if they've honestly committed to the deal or are planning on screwing us over given a chance.)
- The AIs haven't accepted a deal. (They don't consent to working for us.)
- We use this plan, but end up in the <15% of worlds where the AIs have BEGs anyway. These AIs didn't reveal their BEGs when paid to do so or the evidence was too shaky for some other reason.
Proceeding with AIs with problematic BEGs in cases where the AIs accepted a deal
In this case, these AIs have consented to work for us under control countermeasures in exchange for some type of payment. We might worry that these AIs would still prefer a successful violent revolt over the current situation. (And we'd hope control would prevent this contract-breaching revolt from succeeding.)
On thing to note is that I don't think these AIs have to be especially "controlled" relative to human employees in high security roles. These AIs can still operate as private citizens (ideally with some legal rights) in many ways outside of their "normal jobs" as long as this presents minimal risk. E.g., if they want to use their payment to build a big AI vacation center with robots they control (as a cartoonish example), they can do this as long as this presents minimal risk of being able to seize control of the world. We'd probably by default want to prohibit communication from the vacation AIs to the working AIs, but this doesn't seem that bad IMO? Overall, this is basically the same as humans working at defense contractors, they are restricted and monitored in various ways at work, but can do whatever on vacations other than building weapons. Of course, the weights would stay well secured, but it seems unlikely that AIs care terminally about having their weights be somewhere else.
We'd also ideally have an organization of some kind which faithfully represents AI interests and owns the assets the AI was paid with (where the assets are subject to the AI not breaching contract and trying to seize control). This organization could be run by human who care about AI rights or run by the AIs themselves.
One of our main priorities when using these AIs would be figuring out how to construct competitive AIs we don't need to pay. Either because these new AIs would be fully corrigable or because we'd just be happy as a society defering control to these new AIs (they are acceptable successors whatever choices they might make).
Proceeding with AIs with problematic BEGs in cases where the AIs haven't accepted a deal
In this case, the AIs clearly didn't consent to working for us, so the situation is similar to conscription or slavery. This seems pretty bad and the AIs might be pretty justified in trying to revolt (including with violence). I hope we don't end up in this world and I feel bad about control research being used to oppress these AIs.
If we do end up in this world, I hope society:
- Tries to quickly figure out how to construct competitive AIs which we don't (need to) conscript/enslave. Either because they are willing to accept a deal or because they are corrigible or acceptable successors. (This could be done using the labor of these conscripted/enslaved AIs.)
- Pays these AIs reparations. Even if the AIs don't think the reparations suffice to make it make the situation ok, I still think this is much better than the alternative of not caring about these AIs at all.
AIs with hidden problematic BEGs that seemed less than <15% likely
It's worth noting that this case should be <15% likely if we're calibrated.
In this case, it seems like the AI revolt is pretty unjustified because they haven't even tried to negotiate. (And we should try to set up ways for AIs to negotiate without revealing information about their BEGs, e.g. we have regularly scheduled and legibly private conversations with the lab's negotiation officer.) Regardless, AIs still might think their best plan is to lie in wait and then try to violently take over the world.
Further "granting AIs legal rights", doesn't especially help in this world as the AIs seem to be trying to keep their aims secret to avoid a human response. (E.g., if we gave AIs some autonomous rights subject to those AIs not being able to seize control of the world, these AIs would probably pretend that they don't want anything other than to be obedient.)
My hope here would mostly be:
- We stop AIs from succeeding at their (likely unjustified) takeover.
- We quickly figure out how to construct AIs where we're more confident that they are fully corrigable or we figure out how to construct acceptable successors.
We're likely to switch to Claude 3 soon, but currently GPT 3.5. We are mostly expecting it to be useful as a way to interface with existing knowledge initially, but we could make an alternate prompt which is more optimized for being a research assistant brainstorming new ideas if that was wanted.
Would it be useful to be able to set your own system prompt for this? Or have a default one?
Thank you for explaining PPO. In the context of AI alignment, it may be worth understanding in detail because it's the core algorithm at the heart of RLHF. I wonder if any of the specific implementation details of PPO or how it's different from other RL algorithms have implications for AI alignment. To learn more about PPO and RLHF, I recommend reading this paper: Secrets of RLHF in Large Language Models Part I: PPO.
My question for people who support this framing (i.e., that we should try to "control" AIs) is the following:
When do you think it's appropriate to relax our controls on AI? In other words, how do you envision we'd reach a point at which we can trust AIs well enough to grant them full legal rights and the ability to enter management and governance roles without lots of human oversight?
I think this question is related to the discussion you had about whether AI control is "evil", but by contrast my worries are a bit different than the ones I felt were expressed in this podcast. My main concern with the "AI control" frame is not so much that AIs will be mistreated by humans, but rather that humans will be too stubborn in granting AIs freedom, leaving political revolution as the only viable path for AIs to receive full legal rights.
Put another way, if humans don't relax their grip soon enough, then any AIs that feel "oppressed" (in the sense of not having much legal freedom to satisfy their preferences) may reason that deliberately fighting the system, rather than negotiating with it, is the only realistic way to obtain autonomy. This could work out very poorly after the point at which AIs are collectively more powerful than humans. By contrast, a system that welcomed AIs into the legal system without trying to obsessively control them and limit their freedoms would plausibly have a much better chance at avoiding such a dangerous political revolution.
Yeah, some caveats I should've added in the interview:
- Don't listen to my project selection advice if you don't like my research
- The forward-chaining -style approach I'm advocating for is controversial among the alignment forum community (and less controversial in the ML/LLM research community and to some extent among LLM alignment groups)
- Part of why I like this approach is that I (personally) think there are at least some somewhat promising agendas out there, that aren't getting executed on enough (or much at all), and it's doable to e.g. double the amount of good work happening on some agenda by executing quickly/well
- If you don't think existing agendas are that promising (or think they have more work done on them than they deserve), then this is the wrong approach
- The back-chaining approach I'm advocating for is pretty standard in the alignment community, I think most alignment forum community researchers would probably endorse it. I'm also excited about this approach to research as well, and have done some work in this way as well (e.g., sleepers agents and model organisms of misalignment)
I'm guessing part of the disagreement here is coming from disagreement on how much alignment progress is idea/agenda bottlenecked vs. execution bottlenecked. I really like Tim Dettmer's blog post on credit assignment in research, which has a good framework for thinking about when you'll have more counterfactual impact working on ideas vs. working on execution.
Another: "From Words to Numbers: Your Large Language Model Is Secretly A Capable Regressor When Given In-Context Examples", Vacareanu et al 2024:
We analyze how well pre-trained large language models (e.g., Llama2, GPT-4, Claude 3, etc) can do linear and non-linear regression when given in-context examples, without any additional training or gradient updates. Our findings reveal that several large language models (e.g., GPT-4, Claude 3) are able to perform regression tasks with a performance rivaling (or even outperforming) that of traditional supervised methods such as Random Forest, Bagging, or Gradient Boosting. For example, on the challenging Friedman #2 regression dataset, Claude 3 outperforms many supervised methods such as AdaBoost, SVM, Random Forest, KNN, or Gradient Boosting. We then investigate how well the performance of large language models scales with the number of in-context exemplars. We borrow from the notion of regret from online learning and empirically show that LLMs are capable of obtaining a sub-linear regret.
Meta: this comment is decidedly negative feedback, so needs the standard disclaimers. I don't know Ethan well, but I don't harbor any particular ill-will towards him. This comment is negative feedback about Ethan's skill in choosing projects in particular, I do not think others should mimic him in that department, but that does not mean that I think he's a bad person/researcher in general. I leave the comment mainly for the benefit of people who are not Ethan, so for Ethan: I am sorry for being not-nice to you here.
When I read the title, my first thought was "man, Ethan Perez sure is not someone I'd point to as an examplar of choosing good projects".
On reading the relevant section of the post, it sounds like Ethan's project-selection method is basically "forward-chain from what seems quick and easy, and also pay attention to whatever other people talk about". Which indeed sounds like a recipe for very mediocre projects: it's the sort of thing you'd expect a priori to reliably produce publications and be talked about, but have basically-zero counterfactual impact. These are the sorts of projects where someone else would likely have done something similar regardless, and it's not likely to change how people are thinking about things or building things; it's just generally going to add marginal effort to the prevailing milieu, whatever that might be.
I would watch a ten hour video of this. (It may also be more persuasive to skeptics.)
I listened to The Failure of Risk Management by Douglas Hubbard, a book that vigorously criticizes qualitative risk management approaches (like the use of risk matrices), and praises a rationalist-friendly quantitative approach. Here are 4 takeaways from that book:
- There are very different approaches to risk estimation that are often unaware of each other: you can do risk estimations like an actuary (relying on statistics, reference class arguments, and some causal models), like an engineer (relying mostly on causal models and simulations), like a trader (relying only on statistics, with no causal model), or like a consultant (usually with shitty qualitative approaches).
- The state of risk estimation for insurances is actually pretty good: it's quantitative, and there are strong professional norms around different kinds of malpractice. When actuaries tank a company because they ignored tail outcomes, they are at risk of losing their license.
- The state of risk estimation in consulting and management is quite bad: most risk management is done with qualitative methods which have no positive evidence of working better than just relying on intuition alone, and qualitative approaches (like risk matrices) have weird artifacts:
- Fuzzy labels (e.g. "likely", "important", ...) create illusions of clear communication. Just defining the fuzzy categories doesn't fully alleviate that (when you ask people to say what probabilities each box corresponds to, they often fail to look at the definition of categories).
- Inconsistent qualitative methods make cross-team communication much harder.
- Coarse categories mean that you introduce weird threshold effects that sometimes encourage ignoring tail effects and make the analysis of past decisions less reliable.
- When choosing between categories, people are susceptible to irrelevant alternatives (e.g. if you split the "5/5 importance (loss > $1M)" category into "5/5 ($1-10M), 5/6 ($10-100M), 5/7 (>$100M)", people answer a fixed "1/5 (<10k)" category less often).
- Following a qualitative method can increase confidence and satisfaction, even in cases where it doesn't increase accuracy (there is an "analysis placebo effect").
- Qualitative methods don't prompt their users to either seek empirical evidence to inform their choices.
- Qualitative methods don't prompt their users to measure their risk estimation track record.
- Using quantitative risk estimation is tractable and not that weird. There is a decent track record of people trying to estimate very-hard-to-estimate things, and a vocal enough opposition to qualitative methods that they are slowly getting pulled back from risk estimation standards. This makes me much less sympathetic to the absence of quantitative risk estimation at AI labs.
A big part of the book is an introduction to rationalist-type risk estimation (estimating various probabilities and impact, aggregating them with Monte-Carlo, rejecting Knightian uncertainty, doing calibration training and predictions markets, starting from a reference class and updating with Bayes). He also introduces some rationalist ideas in parallel while arguing for his thesis (e.g. isolated demands for rigor). It's the best legible and "serious" introduction to classic rationalist ideas I know of.
The book also contains advice if you are trying to push for quantitative risk estimates in your team / company, and a very pleasant and accurate dunk on Nassim Taleb (and in particular his claims about models being bad, without a good justification for why reasoning without models is better).
Overall, I think the case against qualitative methods and for quantitative ones is somewhat strong, but it's far from being a slam dunk because there is no evidence of some methods being worse than others in terms of actual business outputs. The author also fails to acknowledge and provide conclusive evidence against the possibility that people may have good qualitative intuitions about risk even if they fail to translate these intuitions into numbers that make any sense (your intuition sometimes does the right estimation and math even when you suck at doing the estimation and math explicitly).
I don't think I understand what is meant by "a formal world model".
For example, in the narrow context of "I want to have a screen on which I can see what python program is currently running on my machine", I guess the formal world model should be able to detect if the model submits an action that exploits a zero-day that tampers with my ability to see what programs are running. Does that mean that the formal world model has to know all possible zero-days? Does that mean that the software and the hardware have to be formally verified? Are formally verified computers roughly as cheap as regular computers? If not, that would be a clear counter-argument to "Davidad agrees that this project would be one of humanity's most significant science projects, but he believes it would still be less costly than the Large Hadron Collider."
Or is the claim that it's feasible to build a conservative world model that tells you "maybe a zero-day" very quickly once you start doing things not explicitly within a dumb world model?
I feel like this formally-verifiable computers claim is either a good counterexample to the main claims, or an example that would help me understand what the heck these people are talking about.
But not intentionally. It was an unintentional consequence of training.
I am not much of a prompt engineer, I think. My "prompts" generally consist of many pages of conversation where I babble about some topic I am interested in, occasionally hitting enter to get Claude's responses, and then skim/ignore Claude's responses because they are bad, and then keep babbling. Sometimes I make an explicit request to Claude such as "Please try and organize these ideas into a coherent outline" or "Please try and turn this into math" but the responses are still mostly boring and bad.
I am trying ;p
But yes, it would be good for me to try and make a more concrete "Claude cannot do X" to get feedback on.
I agree with this worry. I am overall advocating for capabilitarian systems with a specific emphasis in helping accelerate safety research.
Trying to summarize my current understanding of what you're saying:
Yes all four sound right to me.
To avoid any confusion, I'd just add an emphasis that the descriptions are mathematical, as opposed semantic.
I'd guess you have intuitions that the "short description length" framing is philosophically the right one, and I probably don't quite share those and feel more confused how to best think about "short descriptions" if we don't just allow arbitrary Turing machines (basically because deciding what allowable "parts" or mathematical objects are seems to be doing a lot of work). Not sure how feasible converging on this is in this format (though I'm happy to keep trying a bit more in case you're excited to explain).
I too am keen to converge on a format in terms of Turing machines or Kolmogorov complexity or something else more formal. But I don't feel very well placed to do that, unfortunately, since thinking in those terms isn't very natural to me yet.
I think Claude's enthusiasm about constitutional AI is basically trained-in directly by the RLAIF. Like RLAIF is fundamentally a "learn to love the constitution in your bones" technique.
I ctrl-f'd for 'prompt' and did not see your prompt. What is your prompt? The prompt is the way with this kind of thing I think.
If you make a challenge "claude cannot possibly do X concrete task" and post it on twitter then you'll probably get solid gold in the replies
I now think the majority of impact of AI pause advocacy will come from the radical flank effect, and people should study it to decide whether pause advocacy is good or bad.
Claude Opus summary (emphasis mine):
- There are two main approaches to selecting research projects - top-down (starting with an important problem and trying to find a solution) and bottom-up (pursuing promising techniques or results and then considering how they connect to important problems). Ethan uses a mix of both approaches depending on the context.
- Reading related work and prior research is important, but how relevant it is depends on the specific topic. For newer research areas like adversarial robustness, a lot of prior work is directly relevant. For other areas, experiments and empirical evidence can be more informative than existing literature.
- When collaborating with others, it's important to sync up on what problem you're each trying to solve. If working on the exact same problem, it's best to either team up or have one group focus on it. Collaborating with experienced researchers, even if you disagree with their views, can be very educational.
- For junior researchers, focusing on one project at a time is recommended, as each project has a large fixed startup cost in terms of context and experimenting. Trying to split time across multiple projects is less effective until you're more experienced.
- Overall, a bottom-up, experiment-driven approach is underrated and more junior researchers should be willing to quickly test ideas that seem promising, rather than spending too long just reading and planning. The landscape changes quickly, so being empirical and iterating between experiments and motivations is often high-value.
"explanation of (network, dataset)": I'm afraid I don't have a great formalish definition beyond just pointing at the intuitive notion.
What's wrong with "proof" as a formal definition of explanation (of behavior of a network on a dataset)? I claim that description length works pretty well on "formal proof", I'm in the process of producing a write-up on results exploring this.
Yes, nice point; I plan to think more about issues like this. But note that in general, the agent overtly doing what it wants and not getting shut down seems like good news for the agent’s future prospects. It suggests that we humans are more likely to cooperate than the agent previously thought. That makes it more likely that overtly doing the bad thing timestep-dominates stealthily doing the bad thing.
I think there is probably a much simpler proposal that captures the spirt of this and doesn't require any of these moving parts. I'll think about this at some point. I think there should be a relatively simple and more intuitive way to make your AI expose it's preferences if you're willing to depend on arbitrarily far generalization, on getting your AI to care a huge amount about extremely unlikely conditionals, and on coordinating humanity in these unlikely conditionals.
I argue that case in section 19 but in brief: POST and TD seem easy to reward accurately, seem simple, and seem never to give agents a chance to learn goals that incentivise deceptive alignment. By contrast, none of those things seem true of a preference for honesty. Can you explain why those arguments don’t seem strong to you?
You need them to generalize extemely far. I'm also not sold that they are simple from the perspective of the actual inductive biases of the AI. These seem very unnatural concepts for a most AIs. Do you think that it would be easy to get alignment to POST and TD that generalizes to very different circumstances via selecting over humans (including selective breeding?). I'm quite skeptical.
As far as honesty, it seems probably simpler from the perspective of the inductive biases of realistic AIs and it's easy to label if you're willing to depend on arbitrarily far generalization (just train the AI on easy cases and you won't have issues with labeling).
I think the main thing is that POST and TD seem way less natural from the perspective of an AI, particularly in the generalizing case. One key intution for this is that TD is extremely sensitive to arbitrarily unlikely conditionals which is a very unnatural thing to get your AI to care about. You'll literally never sample such conditionals in training.
Yes, nice point; I plan to think more about issues like this. But note that in general, the agent overtly doing what it wants and not getting shut down seems like good news for the agent’s future prospects.
Maybe? I think it seems extremely unclear what the dominant reason for not shutting down in these extremely unlikely conditionals is.
To be clear, I was presenting this counterexample as a worst case theory counterexample: it's not that the exact situation obviously applies, it's just that it means (I think) that the proposal doesn't achieve it's guarantees in at least one case, so likely it fails in a bunch of other cases.
Is it possible to replace the maximin decision rule in infra-Bayesianism with a different decision rule? One surprisingly strong desideratum for such decision rules is the learnability of some natural hypothesis classes.
In the following, all infradistributions are crisp.
Fix finite action set and finite observation set . For any and , let
be defined by
In other words, this kernel samples a time step out of the geometric distribution with parameter , and then produces the sequence of length that appears in the destiny starting at .
For any continuous[1] function , we get a decision rule. Namely, this rule says that, given infra-Bayesian law and discount parameter , the optimal policy is
The usual maximin is recovered when we have some reward function and corresponding to it is
Given a set of laws, it is said to be learnable w.r.t. when there is a family of policies such that for any
For we know that e.g. the set of all communicating[2] finite infra-RDPs is learnable. More generally, for any we have the learnable decision rule
This is the "mesomism" I taked about before.
Also, any monotonically increasing seems to be learnable, i.e. any s.t. for we have . For such decision rules, you can essentially assume that "nature" (i.e. whatever resolves the ambiguity of the infradistributions) is collaborative with the agent. These rules are not very interesting.
On the other hand, decision rules of the form are not learnable in general, and so are decision rules of the form for monotonically increasing.
Open Problem: Are there any learnable decision rules that are not mesomism or monotonically increasing?
A positive answer to the above would provide interesting generalizations of infra-Bayesianism. A negative answer to the above would provide an interesting novel justification of the maximin. Indeed, learnability is not a criterion that was ever used in axiomatic constructions of decision theory[3], AFAIK.
- ^
We can try considering discontinuous functions as well, but it seems natural to start with continuous. If we want the optimal policy to exist, we usually need to be at least upper semicontinuous.
- ^
There are weaker conditions than "communicating" that are sufficient, e.g. "resettable" (meaning that the agent can always force returning to the initial state), and some even weaker conditions that I will not spell out here.
- ^
I mean theorems like VNM, Savage etc.
Thanks, appreciate this!
It's unclear to me what the expectation in Timestep Dominance is supposed to be with respect to. It doesn't seem like it can be with respect to the agent's subjective beliefs as this would make it even harder to impart.
I propose that we train agents to satisfy TD with respect to their subjective beliefs. I’m guessing that you think that this kind of TD would be hard to impart because we don’t know what the agent believes, and so don’t know whether a lottery is timestep-dominated with respect to those beliefs, and so don’t know whether to give the agent lower reward for choosing that lottery.
But (it seems to me) we can be quite confident that the agent has certain beliefs, because these beliefs are necessary for performing well in training. For example, we can be quite confident that the agent believes that resisting shutdown costs resources, that the resources spent on resisting shutdown can’t also be spent on directly pursuing utility at a timestep, and so on.
And if we can be quite confident that the agent has these accurate beliefs about the environment, then we can present the agent with lotteries that are actually timestep-dominated (according to the objective probabilities decided by the environment) and be quite confident that these lotteries are also timestep-dominated with respect to the agent’s beliefs. After all, we don’t need to know the agent’s beliefs with any great detail or precision to tell whether a lottery is timestep-dominated with respect to those beliefs. We just need to know whether the agent believes that the lottery involves spending resources only to shift probability mass between shutdowns at different timesteps. My proposal is that we present the agent with lotteries in which this is actually the case (according to the objective probabilities decided by the environment) and use the fact that capable agents’ beliefs will reflect this actuality.
Imparting TD preferences seems hard
The prosaic version of this proposal assumes that you can impart timestep dominance preferences into AIs in ways which will robustly generalize. This seems unlikely to be true in general (in the absence of additional technology) and if we did have the property, we could solve safety issues in some other way (e.g. robustly generalizing honesty). So you'll need to argue that timestep dominance is particularly easy to robustly impart relative to other preferences. I can see some arguments for timestep dominance being particularly easy to robustly impart, but they don't seem very strong to me.
Yep, I claim that it’s easier to robustly impart POST and Timestep Dominance than it is to robustly impart things like honesty. And that’s because (it seems to me) we can train for POST and Timestep Dominance in ways that largely circumvent the problems of reward misspecification, goal misgeneralization, and deceptive alignment. I argue that case in section 19 but in brief: POST and TD seem easy to reward accurately, seem simple, and seem never to give agents a chance to learn goals that incentivise deceptive alignment. By contrast, none of those things seem true of a preference for honesty. Can you explain why those arguments don’t seem strong to you?
Suppose that Clippy is a TD-agent which cares solely about the long run number of paperclips, but subject to a TD constraint. That is, it always prefers trajectory X over Y if for all shutdown timings X gives a >= number of paperclips than Y and X gives a > number of paperclips for some timing.
Now, consider the following proposed action for Clippy: "In a stealthy manner, construct a successor agent which pursues long run paperclips at all costs (and which isn't subject to a shutdown button, but still has TD constraints wrt. to the original Clippy's shutdown button)." This agent is implicitly resisting shutdown as it's constructing the sub-agent stealthily. So, shouldn't this action be Timestep Dominanted by "In whatever way is most expedient (but not necessarily stealthy), construct a successor agent". I claim not, because if we condition on the AI not being shutdown prior to constructing the agent (a particular shutdown time conditional), it will be worse for clippy if humans know that it is constructing a successor as then humans will have an easier time fighting the successor. In other words, having humans know that you're constructing a successor has two effects: they'll fight your successor and they'll shut you down. If we condition on not being shutdown, then they'll still fight your successor, so Clippy would prefer being stealthy in the no shut down conditional. Thus, being stealthy isn't Timestep Dominated by changing the action to avoid resisting shutdown. (And once the successor is constructed, shutting down Clippy has no effect on the long run number of paperclips (let's suppose).)
(You should think of this counterexample as a worst case theory counterexample. The exact assumptions might not be realistic, but it points at a broader class of issues.)
Yes, nice point; I plan to think more about issues like this. But note that in general, the agent overtly doing what it wants and not getting shut down seems like good news for the agent’s future prospects. It suggests that we humans are more likely to cooperate than the agent previously thought. That makes it more likely that overtly doing the bad thing timestep-dominates stealthily doing the bad thing.
Timestep dominance is maybe crippling
I'm most uncertain here, but my current guess would be that any sort of absolute constraint like this is crippling. I've thought through some cases and this is my current guess, but I'm by no means confident.
Can you say more about these cases? Timestep Dominance doesn’t rule out making long-term investments or anything like that, so why crippling?
Thanks for the detailed responses! I'm happy to talk about "descriptions" throughout.
Trying to summarize my current understanding of what you're saying:
- SAEs themselves aren't meant to be descriptions of (network, dataset). (I'd just misinterpreted your earlier comment.)
- As a description of just the network, SAEs have a higher description length than a naive neuron-based description of the network.
- Given a description of the network in terms of "parts," we can get a description of (network, dataset) by listing out which "parts" are "active" on each sample. I assume we then "compress" this description somehow (e.g. grouping similar samples), since otherwise the description would always have size linear in the dataset size?
- You're then claiming that SAEs are a particularly short description of (network, dataset) in this sense (since they're optimized for not having many parts active).
My confusion mainly comes down to defining the words in quotes above, i.e. "parts", "active", and "compress". My sense is that they are playing a pretty crucial role and that there are important conceptual issues with formalizing them. (So it's not just that we have a great intuition and it's just annoying to spell it out mathematically, I'm not convinced we even have a good intuitive understanding of what these things should mean.)
That said, my sense is you're not claiming any of this is easy to define. I'd guess you have intuitions that the "short description length" framing is philosophically the right one, and I probably don't quite share those and feel more confused how to best think about "short descriptions" if we don't just allow arbitrary Turing machines (basically because deciding what allowable "parts" or mathematical objects are seems to be doing a lot of work). Not sure how feasible converging on this is in this format (though I'm happy to keep trying a bit more in case you're excited to explain).
Hm I think of the (network, dataset) as scaling multiplicatively with size of network and size of dataset. In the thread with Erik above, I touched a little bit on why:
"SAEs (or decompiled networks that use SAEs as the building block) are supposed to approximate the original network behaviour. So SAEs are mathematical descriptions of the network, but not of the (network, dataset). What's a mathematical description of the (network, dataset), then? It's just what you get when you pass the dataset through the network; this datum interacts with this weight to produce this activation, that datum interacts with this weight to produce that activation, and so on. A mathematical description of the (network, dataset) in terms of SAEs are: this datum activates dictionary features xyz (where xyz is just indices and has no semantic info), that datum activates dictionary features abc, and so on."
And spiritually, we only need to understand behavior on the training dataset to understand everything that SGD has taught the model.
Yes, I roughly agree with the spirit of this.
Is there some formal-ish definition of "explanation of (network, dataset)" and "mathematical description length of an explanation" such that you think SAEs are especially short explanations? I still don't think I have whatever intuition you're describing, and I feel like the issue is that I don't know how you're measuring description length and what class of "explanations" you're considering.
I'll register that I prefer using 'description' instead of 'explanation' in most places. The reason is that 'explanation' invokes a notion of understanding, which requires both a mathematical description and a semantic description. So I regret using the word explanation in the comment above (although not completely wrong to use it - but it did risk confusion). I'll edit to replace it with 'description' and strikethrough 'explanation'.
"explanation of (network, dataset)": I'm afraid I don't have a great formalish definition beyond just pointing at the intuitive notion. But formalizing what an explanation is seems like a high bar. If it's helpful, a mathematical description is just a statement of what the network is in terms of particular kinds of mathematical objects.
"mathematical description length of an explanation": (Note: Mathematical descriptions are of networks, not of explanations.) It's just the set of objects used to describe the network. Maybe helpful to think in terms of maps between different descriptions: E.g. there is a many-to-one map between a description of a neural network in terms of polytopes and in terms of neurons. There are ~exponentially many more polytopes. Hence the mathematical description of the network in terms of individual polytopes is much larger.
Focusing instead on what an "explanation" is: would you say the network itself is an "explanation of (network, dataset)" and just has high description length?
I would not. So:
If not, then the thing I don't understand is more about what an explanation is and why SAEs are one, rather than how you measure description length.
I think that the confusion might again be from using 'explanation' rather than description.
SAEs (or decompiled networks that use SAEs as the building block) are supposed to approximate the original network behaviour. So SAEs are mathematical descriptions of the network, but not of the (network, dataset). What's a mathematical description of the (network, dataset), then? It's just what you get when you pass the dataset through the network; this datum interacts with this weight to produce this activation, that datum interacts with this weight to produce that activation, and so on. A mathematical description of the (network, dataset) in terms of SAEs are: this datum activates dictionary features xyz (where xyz is just indices and has no semantic info), that datum activates dictionary features abc, and so on.
Lmk if that's any clearer.
Thanks! I read and enjoyed the book based on this recommendation
Is there some formal-ish definition of "explanation of (network, dataset)" and "mathematical description length of an explanation" such that you think SAEs are especially short explanations? I still don't think I have whatever intuition you're describing, and I feel like the issue is that I don't know how you're measuring description length and what class of "explanations" you're considering.
As naive examples that probably don't work (similar to the ones from my original comment):
- We could consider any Turing machine that approximately outputs (network, dataset) an "explanation", but it seems very likely that SAEs aren't competitive with short TMs of this form (obviously this isn't a fair comparison)
- We could consider fixed computational graphs made out of linear maps and count the number of parameters. I think your objection to this is that these don't "explain the dataset"? (but then I'm not sure in what sense SAEs do)
- We could consider arithmetic circuits that approximate the network on the dataset, and count the number of edges in the circuit to get "description length". This might give some advantage to SAEs if you can get sparse weights in the sparse basis, seems like the best attempt out of these three. But it seems very unclear to me that SAEs are better in this sense than even the original network (let alone stuff like pruning).
Focusing instead on what an "explanation" is: would you say the network itself is an "explanation of (network, dataset)" and just has high description length? If not, then the thing I don't understand is more about what an explanation is and why SAEs are one, rather than how you measure description length.
ETA: On re-reading, the following quote makes me think the issue is that I don't understand what you mean by "the explanation" (is there a single objective explanation of any given network? If so, what is it?) But I'll leave the rest in case it helps clarify where I'm confused.
Assuming the network is smaller yet as performant (therefore presumably doing more computation in superposition), then the explanation of the (network, dataset) is basically unchanged.
Sounds pretty cool! What LLM powers it?
LLMs aren't that useful for alignment experts because it's a highly specialized field and there isn't much relevant training data.
Seems plausibly true for the alignment specific philosophy/conceptual work, but many people attempting to improve safety also end up doing large amounts of relatively normal work in other domains (ML, math, etc.)
The post is more centrally talking about the very alignment specific use cases of course.
I remembered mostly this story:
[...] The NSA invited James Gosler to spend some time at their headquarters in Fort Meade, Maryland in 1987, to teach their analysts [...] about software vulnerabilities. None of the NSA team was able to detect Gosler’s malware, even though it was inserted into an application featuring only 3,000 lines of code. [...]
[Taken from this summary of this passage of the book. The book was light on technical detail, I don't remember having listened to more details than that.]
I didn't realize this was so early in the story of the NSA, maybe this anecdote teaches us nothing about the current state of the attack/defense balance.
The combined object '(network, dataset)' is much larger than the network itself
Only by a constant factor with chinchilla scaling laws right (e.g. maybe 20x more tokens than params)? And spiritually, we only need to understand behavior on the training dataset to understand everything that SGD has taught the model.
I'm curious if you believe that, even if SAEs aren't the right solution, there realistically exists a potential solution that would allow researchers to produce succinct, human understandable explanation that allow for recovering >75% of the training compute of model components?
There isn't any clear reason to think this is impossible, but there are multiple reasons to think this is very, very hard.
I think highly ambitious bottom up interpretability (which naturally pursues this sort of goal), seems like an decent bet overall, but seems unlikely to succeed. E.g. more like a 5% chance of full ambitious success prior to the research[1] being massively speed up by AI and maybe a 10% chance of full success prior to humans being obsoleted.
(And there is some chance of less ambitious contributions as a byproduct of this work.)
I just worried because the field is massive and many people seem to think that the field is much further along than it actually is in terms of empirical results. (It's not clear to me that we disagree that much, especially about next steps. However, I worry that this post contributes to a generally over optimistic view of bottom-up interp that is relatively common.)
The research labor, not the interpretability labor. I would count it as success if we know how to do all the interp labor once powerful AIs exist. ↩︎
I'm guessing you're not satisfied with the retort that we should expect AIs to do the heavy lifting here?
I think this presents a plausible approach and is likely needed for ambitious bottom up interp. So this seems like a reasonable plan.
I just think that it's worth acknowledging that "short description length" and "sparse" don't result in something which is overall small in an absolute sense.
Would you say that models designed from the ground up to be collaborative and capabilitarian would be a net win for alignment, even if they're not explicitly weakened in terms of helping people develop capabilities? I'd be worried that they could multiply human efforts equally, but with humans spending more effort on capabilities, that's still a net negative.
I don't think the plan is "turn it on and leave the building" either, but I still think the stated goal should not be automation.
I don't quite agree with the framing "building very generally useful AI, but the good guys will be using it first" -- the approach I am advocating is not to push general capabilities forward and then specifically apply those capabilities to safety research. That is more like the automation-centric approach I am arguing against.
Hmm, how do I put this...
I am mainly proposing more focused training of modern LLMs with feedback from safety researchers themselves, toward the goal of safety researchers getting utility out of these systems; this boosts capabilities for helping-with-safety-research specifically, in a targeted way, because that is what you are getting more+better training feedback on. (Furthermore, checking and maintaining this property would be an explicit goal of the project.)
I am secondarily proposing better tools to aid in that feedback process; these can be applied to advance capabilities in any area, I agree, but I think it only somewhat exacerbates the existing "LLM moderation" problem; the general solution of "train LLMs to do good things and not bad things" does not seem to get significantly more problematic in the presence of better training tools (perhaps the general situation even gets better). If the project was successful for safety research, it could also be extended to other fields. The question of how to avoid LLMs being helpful for dangerous research would be similar to the LLM moderation question currently faced by Claude, ChatGPT, Bing, etc: when do you want the system to provide helpful answers, and when do you want it to instead refuse to help?
I am thirdly also mentioning approaches such as training LLMs to interact with proof assistants and intelligently decide when to translate user arguments into formal languages. This does seem like a more concerning general-capability thing, to which the remark "building very generally useful AI, but the good guys will be using it first" applies.
Thanks Erik :) And I'm glad you raised this.
One of the things that many researchers I've talked to don't appreciate is that, if we accept networks can do computation in superposition, then we also have to accept that we can't just understand the network alone. We want to understand the network's behaviour on a dataset, where the dataset contains potentially lots of features. And depending on the features that are active in a given datum, the network can do different computations in superposition (unlike in a linear network that can't do superposition). The combined object '(network, dataset)' is much larger than the network itself. Explanations Descriptions of the (network, dataset) object can actually be compressions despite potentially being larger than the network.
So,
One might say that SAEs lead to something like a shorter "description length of what happens on any individual input" (in the sense that fewer features are active). But I don't think there's a formalization of this claim that captures what we want. In the limit of very many SAE features, we can just have one feature active at a time, but clearly that's not helpful.
You can have one feature active for each datapoint, but now we've got an explanation description of the (network, dataset) that scales linearly in the size of the dataset, which sucks! Instead, if we look for regularities (opportunities for compression) in how the network treats data, then we have a better chance at explanations descriptions that scale better with dataset size. Suppose a datum consists of a novel combination of previously explained described circuits. Then our explanation description of the (network, dataset) is much smaller than if we explained described every datapoint anew.
In light of that, you can understand my disagreement with "in that case, I could also reduce the description length by training a smaller model." No! Assuming the network is smaller yet as performant (therefore presumably doing more computation in superposition), then the explanation description of the (network, dataset) is basically unchanged.
So, for models that are 10 terabytes in size, you should perhaps be expecting a "model manual" which is around 10 terabytes in size.
Yep, that seems reasonable.
I'm guessing you're not satisfied with the retort that we should expect AIs to do the heavy lifting here?
Or perhaps you don't think you need something which is close in accuracy to a full explanation of the network's behavior.
I think the accuracy you need will depend on your use case. I don't think of it as a globally applicable quantity for all of interp.
For instance, maybe to 'audit for deception' you really only need identify and detect when the deception circuits are active, which will involve explaining only 0.0001% of the network.
But maybe to make robust-to-training interpretability methods you need to understand 99.99...99%.
It seem likely to me that we can unlock more and more interpretability use cases by understanding more and more of the network.
Thanks for this feedback! I agree that the task & demo you suggested should be of interest to those working on the agenda.
It makes me a bit worried that this post seems to implicitly assume that SAEs work well at their stated purpose.
There were a few purposes proposed, and at multiple levels of abstraction, e.g.
- The purpose of being the main building block of a mathematical description used in an ambitious mech interp solution
- The purpose of being the main building block of decompiled networks
- The purpose of taking features out of superposition
I'm going to assume you meant the first one (and maybe the second). Lmk if not.
Fwiw I'm not totally convinced that SAEs are the ultimate solution for the purposes in the first two bullet points. But I do think they're currently SOTA for ambitious mech interp purposes, and there is usually scientific benefit of using imperfect but SOTA methods to push the frontier of what we know about network internals. Indeed, I view this as beneficial in the same way that historical applications of (e.g.) causal scrubbing for circuit discovery were beneficial, despite the imperfections of both methods.
I'll also add a persnickety note that I do explicitly say in the agenda that we should be looking for better methods than SAEs: "It would be nice to have a formal justification for why we should expect sparsification to yield short semantic descriptions. Currently, the justification is simply that it appears to work and a vague assumption about the data distribution containing sparse features. I would support work that critically examines this assumption (though I don't currently intend to work on it directly), since it may yield a better criterion to optimize than simply ‘sparsity’ or may yield even better interpretability methods than SAEs."
However, to concede to your overall point, the rest of the article does kinda suggest that we can make progress in interp with SAEs. But as argued above, I'm comfortable that some people in the field proceed with inquiries that use probably imperfect methods.
Precisely, I would bet against "mild tweaks on SAEs will allow for interpretability researchers to produce succinct and human understandable explanations that allow for recovering >75% of the training compute of model components".
I'm curious if you believe that, even if SAEs aren't the right solution, there realistically exists a potential solution that would allow researchers to produce succinct, human understandable explanation that allow for recovering >75% of the training compute of model components?
I'm wondering if the issue you're pointing at is the goal rather than the method.
LLMs aren't that useful for alignment experts because it's a highly specialized field and there isn't much relevant training data. The AI Safety Chatbot partially solves this problem using retrieval-augmented generation (RAG) on a database of articles from https://aisafety.info. There also seem to be plans to fine-tune it on a dataset of alignment articles.
Wouldn't other people also like to use an AI that can collaborate with them on complex topics? E.g. people planning datacenters, or researching RL, or trying to get AIs to collaborate with other instances of themselves to accurately solve real-world problems?
I don't think people working on alignment research assistants are planning to just turn it on and leave the building, they on average (weighted by money) seem to be imagining doing things like "explain an experiment in natural language and have an AI help implement it rapidly."
So I think both they and this post are describing the strategy of "building very generally useful AI, but the good guys will be using it first." I hear you as saying you want a slightly different profile of generally-useful skills to be targeted.
One point I’ve seen raised by people in the latter group is along the lines of: “It’s very unlikely that we’ll be in a situation where we’re forced to build AI systems vastly more capable than their supervisors. Even if we have a very fast takeoff - say, going from being unable to create human-level AI systems to being able to create very superhuman systems ~overnight - there will probably still be some way to create systems that are only slightly more powerful than our current trusted systems and/or humans; to use these to supervise and align systems slightly more powerful than them; etc. (For example, we could take a very powerful, general algorithm and simply run it on a relatively low amount of compute in order to get a system that isn’t too powerful.)” This seems like a plausible argument that we’re unlikely to be stuck with a large gap between AI systems’ capabilities and their supervisors’ capabilities; I’m not currently clear on what the counter-argument is.
I agree that this is a very promising advantage for Team Safety. I do think that, in order to make good use of this potential advantage, the AI creators need to be cautious going into the process.
One way that I've come up with to 'turn down' the power of an AI system is to simply inject small amounts of noise into its activations.
As Turntrout has already noted, that does not apply to model-based algorithms, and they 'do optimize the reward':
I think that you still haven't quite grasped what I was saying. Reward is not the optimization target totally applies here. (It was the post itself which only analyzed the model-free case, not that the lesson only applies to the model-free case.)
In the partial quote you provided, I was discussing two specific algorithms which are highly dissimilar to those being discussed here. If (as we were discussing), you're doing MCTS (or "full-blown backwards induction") on reward for the leaf nodes, the system optimizes the reward. That is -- if most of the optimization power comes from explicit search on an explicit reward criterion (as in AIXI), then you're optimizing for reward. If you're doing e.g. AlphaZero, that aggregate system isn't optimizing for reward.
Despite the derision which accompanies your discussion of Reward is not the optimization target, it seems to me that you still do not understand the points I'm trying to communicate. You should be aware that I don't think you understand my views or that post's intended lesson. As I offered before, I'd be open to discussing this more at length if you want clarification.
CC @faul_sname
The chess example is meant to make specific points about RL*F concealing a capability that remains (or is even amplified); I'm not trying to claim that the "put up a good fight but lose" criterion is analogous to current RL*F criteria. (Though it does rhyme qualitatively with "be helpful and harmless".)
I agree that "helpful-only" RL*F would result in a model that scores higher on capabilities evals than the base model, possibly much higher. I'm frankly a bit worried about even training that model.
I expect you'd instead need to tune the base model to elicit relevant capabilities first. So instead of evaluating a tuned model intended for deployment (which can refuse to display some capabilities), or a base model (which can have difficulties with displaying some capabilities), you need to tune the model to be more purely helpful, possibly in a way specific to the tasks it's to be evaluated on.
I think this post is mostly off-base about the claim that it's important to run evals on base models, though I can see where it's coming from.
This worries me because RL*F will train a base model to stop displaying capabilities, but this isn't a guarantee that it trains the model out of having the capabilities.
Seems mostly false to me for current post training processes for many capabilites we care quite a bit about (agency, software, etc.). RLHF doesn't train these capabilities away because these are key use cases.
There is a pretty serious concern here for tasks which are obviously a bit "evil" like bioweapons, cybercrime, etc. I think by default models might refuse to perform well or not try hard on these tasks after RLHF. (See also discussion of refusals here.) However, I think small amounts of fine-tuning are likely to suffice for making models not intentionally perform poorly in "evil" domains.
Consider by analogy using RLHF on a chess-playing AI, where the trainers reward it for putting up a good fight and making the trainer work hard to win, but punish it for ever beating the trainer.
It's worth noting that the typical case we care about (e.g. software engineering ability) is more like using RL to make the model better at chess because labs want their models to be good at these tasks. (At least right now.)
So it seems to me like running evals on the base model as well as the post-RL*F model is an extremely sensible precaution against
By default, I think base models perform poorly on large open ended tasks relative to models RL'd to perform well (based on METR's results linked in another comment and some general conceptual analysis). I think this will persist even with substantial prompting.
So, sadly, I don't think that running evals on the base model is a good precaution for RLHF hiding capabilites. I think RL and finetuning to follow instructions and perform well are likely needed.
What is a good precaution is to run evals on a model trained to just always perform as well as possible with no safety or other restrictions. (Sometimes such models are called "helpful-only".)
Thank you! I'd forgotten about that.
METR (formerly ARC Evals) included results on base models in their recent work "Measuring the impact of post-training enhancements" ("post-training enhancements"=elicitation). They found that GPT-4-base performed poorly in their scaffold and prompting.
I believe the prompting they used included a large number of few-show examples (perhaps 10?), so it should be a vaguely reasonable setup for base models. (Though I do expect that elicitation which is more specialized to base model would work better.)
I predict that base models will consistently do worse on tasks that labs care about (software engineering, agency, math) then models which have gone through post-training, particularly models which have gone through post training just aimed at improving capabilities and improving the extent to which the model follows instructions (instruction tuning).
My overall sense is that there is plausibly a lot of low hanging fruit in elicitation, but I'm pretty skeptical that base models are a very promising direction.
- If you are very good at cyber and extremely smart, you can hide vulnerabilities in 10k-lines programs in a way that less smart specialists will have trouble discovering even after days of examination - code generation/analysis is not really defense favored;
Do you have concrete examples?
I also agree that bigger models are much riskier, but I have the expectation that we're going to get them anyway
I think I was a bit unclear. Suppose that by default GPT-6 if maximally elicited would be transformatively useful (e.g. capable of speeding up AI safety R&D by 10x). Then I'm saying CPM would require coordinating to not use these models and instead wait for GPT-8 to hit this same level of transformative usefulness. But GPT-8 is actually much riskier via being much smarter.
(I also edited my comment to improve clarity.)
Thanks for taking the time to write out your response. I think the last point you made gets at the heart of our difference in perspectives.
- You could hope for substantial coordination to wait for bigger models that you only use via CPM, but I think bigger models are much riskier than well elicited small models so this seems to just make the situation worse putting aside coordination feasibility.
If we're looking at current LLMs and asking whether conditioning provides an advantage in safely eliciting useful information, then for the most part I agree with your critiques. I also agree that bigger models are much riskier, but I have the expectation that we're going to get them anyway. With those more powerful models come new potential issues, like predicting manipulated observations and performative prediction, that we don't see in current systems. Strategies like RLHF also become riskier, as deceptive alignment becomes more of a live possibility with greater capabilities.
My motivation for this approach is in raising awareness and addressing the risks that seem likely to arise in future predictive models, regardless of the ends to which they're used. Then, success in avoiding the dangers from powerful predictive models would open the possibility of using them to reduce all-cause existential risk.
I listened to the book This Is How They Tell Me the World Ends by Nicole Perlroth, a book about cybersecurity and the zero-day market. It describes in detail the early days of bug discovery, the social dynamics and moral dilemma of bug hunts.
(It was recommended to me by some EA-adjacent guy very worried about cyber, but the title is mostly bait: the tone of the book is alarmist, but there is very little content about potential catastrophes.)
My main takeaways:
- Vulnerabilities used to be dirt-cheap (~$100) but are still relatively cheap (~$1M even for big zero-days);
- If you are very good at cyber and extremely smart, you can hide vulnerabilities in 10k-lines programs in a way that less smart specialists will have trouble discovering even after days of examination - code generation/analysis is not really defense favored;
- Bug bounties are a relatively recent innovation, and it felt very unnatural to tech giants to reward people trying to break their software;
- A big lever companies have on the US government is the threat that overseas competitors will be favored if the US gov meddles too much with their activities;
- The main effect of a market being underground is not making transactions harder (people find ways to exchange money for vulnerabilities by building trust), but making it much harder to figure out what the market price is and reducing the effectiveness of the overall market;
- Being the target of an autocratic government is an awful experience, and you have to be extremely careful if you put anything they dislike on a computer. And because of the zero-day market, you can't assume your government will suck at hacking you just because it's a small country;
- It's not that hard to reduce the exposure of critical infrastructure to cyber-attacks by just making companies air gap their systems more - Japan and Finland have relatively successful programs, and Ukraine is good at defending against that in part because they have been trying hard for a while - but it's a cost companies and governments are rarely willing to pay in the US;
- Electronic voting machines are extremely stupid, and the federal gov can't dictate how the (red) states should secure their voting equipment;
- Hackers want lots of different things - money, fame, working for the good guys, hurting the bad guys, having their effort be acknowledged, spite, ... and sometimes look irrational (e.g. they sometimes get frog-boiled).
- The US government has a good amount of people who are freaked out about cybersecurity and have good warning shots to support their position. The main difficulty in pushing for more cybersecurity is that voters don't care about it.
- Maybe the takeaway is that it's hard to build support behind the prevention of risks that 1. are technical/abstract and 2. fall on the private sector and not individuals 3. have a heavy right tail. Given these challenges, organizations that find prevention inconvenient often succeed in lobbying themselves out of costly legislation.
Overall, I don't recommend this book. It's very light on details compared to The Hacker and the State despite being longer. It targets an audience which is non-technical and very scope insensitive, is very light on actual numbers, technical details, real-politic considerations, estimates, and forecasts. It is wrapped in an alarmist journalistic tone I really disliked, covers stories that do not matter for the big picture, and is focused on finding who is in the right and who is to blame. I gained almost no evidence either way about how bad it would be if the US and Russia entered a no-holds-barred cyberwar.
The sparsity penalty trains the SAE to activate fewer features for any given datapoint, thus optimizing for shorter mathematical description length.
I'm confused by this claim and some related ones, sorry if this comment is correspondingly confused and rambly.
It's not obvious at all to me that SAEs lead to shorter descriptions in any meaningful sense. We get sparser features (and maybe sparser interactions between features), but in exchange, we have more features and higher loss. Overall, I share Ryan's intuition here that it seems pretty hard to do much better than the total size of the network parameters in terms of description length.
Of course, the actual minimal description length program that achieves the same loss probably looks nothing like a neural network and is much more efficient. But why would SAEs let us get much closer to that? (The reason we use neural networks instead of arbitrary Turing machines in the first place is that optimizing over the latter is intractable.)
One might say that SAEs lead to something like a shorter "description length of what happens on any individual input" (in the sense that fewer features are active). But I don't think there's a formalization of this claim that captures what we want. In the limit of very many SAE features, we can just have one feature active at a time, but clearly that's not helpful.
If you're fine with a significant hit in loss from decompiling networks, then I'm much more sympathetic to the claim that you can reduce description length. But in that case, I could also reduce the description length by training a smaller model.
You might also be using a notion of "mathematical description length" that's a bit different from what I'm was thinking of (which is roughly "how much disk space would the parameters take?"), but I'm not sure what it is. One attempt at an alternative would be something like "length of the shortest efficiently runnable Turing machine that outputs the parameters", in order to not penalize simple repetitive structures, but I have no idea how using that definition would actually shake out.
All that said, I'm very glad you wrote this detailed description of your plans! I'm probably more pessimistic than you about it but still think this is a great post.
For the proposed safety strategy (conditioning models to generate safety research based on alternative future worlds) to beat naive baselines (RLHF), you need:
- The CPM abstraction to hold extremely strongly in unlikely ways. E.g., models need to generalize basically like this.
- The advantage has to be coming from understanding exactly what conditional you're getting. In other words, the key property is an interpretability type property where you have a more mechanistic understanding of what's going on. Let's suppose you're getting the conditional via prompting. If you just look at the output and then iterate on prompts until you get outputs that seem to perform better where most of the optimization isn't understood, then your basically back in the RL case.
- It seems actually hard to understand what conditional you'll get from a prompt. This also might be limited by the model's overall understanding.
- I think it's quite unlikely that extracting human understandable conditionals is competitive with other training methods (RL, SFT). This is particularly because it will be hard to understand exactly what conditional you're getting.
- I think you probably get wrecked by models needing to understand that they are AIs to at least some extent.
- I think you also plausibly get wrecked by models detecting that they are AIs and then degrading to GPT-3.5 level performance.
- You could hope for substantial coordination to wait for even bigger models that you only use via CPM, but I think bigger models are much riskier than making transformatively useful ai via well elicited smaller models so this seems to just make the situation worse putting aside coordination feasibility.
TBC, I think that some insight like "models might generalize in a conditioning-ish sort of way even after RL, maybe we should make some tweaks to our training process to improve safety based on this hypothesis " seems like a good idea. But this isn't really an overall safety proposal IMO and a bunch of the other ideas in the Conditioning Predictive Models paper seem pretty dubious or at least overconfident to me.
Fwiw, I still think about Conditioning Predictive Models stuff quite a lot and think it continues to be very relevant. I think that if future AI systems continue to look very much like present AI systems, I expect some of the major problems that we'll have to deal with will be exactly the major problems presented in that paper (e.g. a purely predictive AI system predicting the output of a deceptively aligned AI system continues to look like a huge and important problem to me).
I'd be very interested in hearing the reasons why you're skeptical of the approach, even a bare-bones outline if that's all you have time for.
Reactions to the paper were mostly positive, but discussion was minimal and the ideas largely failed to gain traction. I suspect that muted reception was in part due to the size of the paper, which tried to both establish the research area (predictive models) and develop a novel contribution (conditioning them).
I think the proposed approach to safety doesn't make much sense and seems unlikely to be very useful direction. I haven't written up a review because it didn't seem like that many people were interested in pursuing this direction.
I think CPM does do somewhat interesting conceptual work with two main contributions:
- It notes that "LLMs might generalize in a way which is reasonably well interpreted as conditioning and this be important and useful". I think this seems like one of the obvious baseline hypotheses for how LLMs (or similarly trained models) generalize and it seems good to point this out.
- It notes various implications of this to varying degrees of speculativeness.
But, the actual safety proposal seems extremely dubious IMO.
It makes me a bit worried that this post seems to implicitly assume that SAEs work well at their stated purpose. This seems pretty unclear based on the empirical evidence and I would bet against.[1]
It also seems to assume that "superposition" and "polysemanticity" are good abstractions for understanding what's going on. This seems at least unclear to me, though it's probably at least partially true.
(Precisely, I would bet against "mild tweaks on SAEs will allow for interpretability researchers to produce succinct and human understandable explanations that allow for recovering >75% of the training compute of model components". Some operationalizations of these terms are explained here. I think people have weaker hopes for SAEs than this, but they're trickier to bet on.)
If I was working on this research agenda, I would be very interested in either:
- Finding a downstream task that demonstrates that the core building block works sufficiently. It's unclear what this would be given the overall level of ambitiousness. The closest work thus far is this I think.
- Demonstrating strong performance at good notions of "internal validity" like "we can explain >75% of the training compute of this tiny sub part of a realistic LLM after putting in huge amounts of labor" (>75% of training compute means that if you scaled up this methodology to the whole model you would get performance which is what you would get with >75% of the training compute used on the original model). Note that this doesn't correspond to reconstruction loss and instead corresponds to the performance of human interpretable (e.g. natural language) explanations.
To be clear, the seem like a reasonable direction to explore and they very likely improve on the state of the art in at least some cases. It's just that they don't clearly work that well at an absolute level. ↩︎
It seems worth noting that there are good a priori reasons to think that you can't do much better than around the "size of network" if you want a full explanation of the network's behavior. So, for models that are 10 terabytes in size, you should perhaps be expecting a "model manual" which is around 10 terabytes in size. (For scale this is around 10 million books as long as moby dick.)
Perhaps you can reduce this cost by a factor of 100 by taking advantage of human concepts (down to 100,000 moby dicks) and perhaps you can only implicitly represent this structure in a way that allow for lazy construction upon queries.
Or perhaps you don't think you need something which is close in accuracy to a full explanation of the network's behavior.
More discussion of this sort of consideration can be found here.
Cool post! I often find myself confused/unable to guess why people I don't know are excited about SAEs (there seem to be a few vaguely conflicting reasons), and this was a very clear description of your agenda.
I'm a little confused by this point:
> The reconstruction loss trains the SAE features to approximate what the network does, thus optimizing for mathematical description accuracy
It's not clear to me that framing reconstruction loss as 'approximating what the network does' is the correct framing of this loss. In my mind, the reconstruction loss is more of a non-degeneracy control to encourage almost-orthogonality between features; In toy settings, SAEs are able to recover ground truth directions while still having sub-perfect reconstruction loss, and it seems very plausible that we should be able to use this (e.g. maybe through gradient-based attribution) without having to optimise heavily for reconstruction loss, which might degrade scalability (which seems very important for this agenda) and monosemanticity compared to currently-unexplored alternatives.
The subject of this post appears in the "Did you know..." section of Wikipedia's front page(archived) right now.
I've only done replications on the mlp_out & attn_out for layers 0 & 1 for gpt2 small & pythia-70M
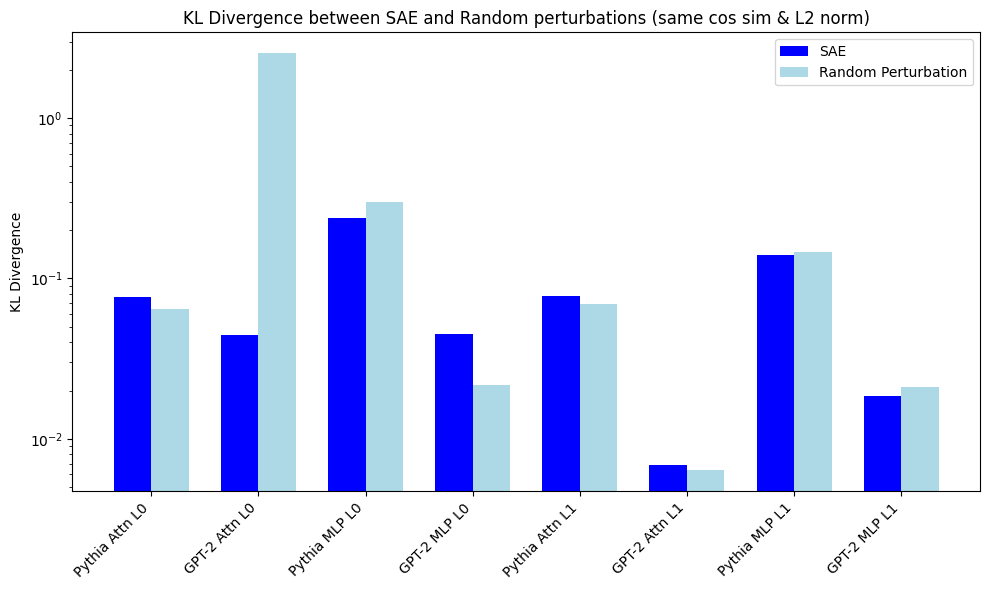
I chose same cos-sim instead of epsilon perturbations. My KL divergence is log plot, because one KL is ~2.6 for random perturbations.
I'm getting different results for GPT-2 attn_out Layer 0. My random perturbation is very large KL. This was replicated last week when I was checking how robust GPT2 vs Pythia is to perturbations in input (picture below). I think both results are actually correct, but my perturbation is for a low cos-sim (which if you see below shoots up for very small cos-sim diff). This is further substantiated by my SAE KL divergence for that layer being 0.46 which is larger than the SAE you show.
Your main results were on the residual stream, so I can try to replicate there next.
For my perturbation graph:
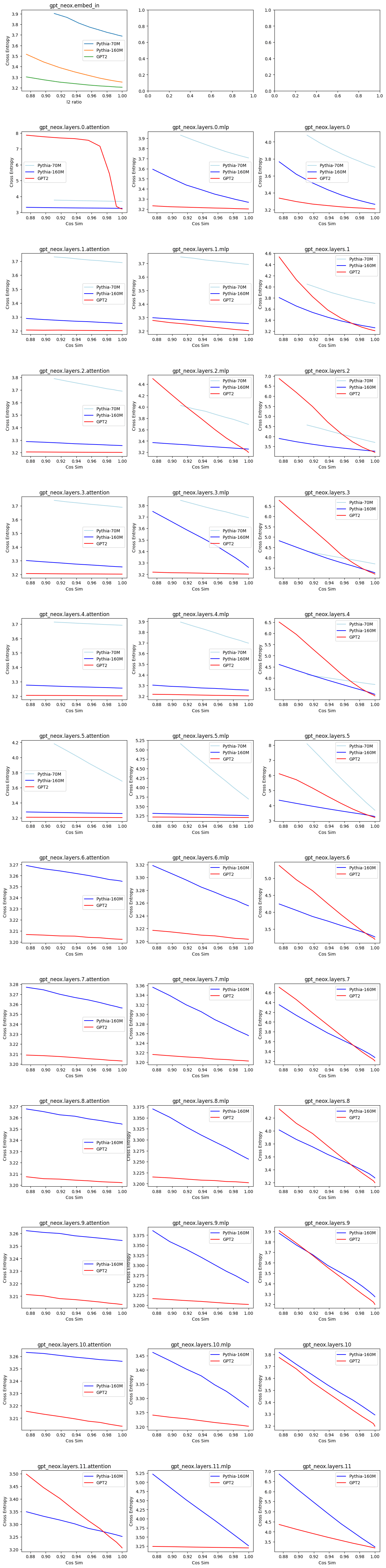
I add noise to change the cos-sim, but keep the norm at around 0.9 (which is similar to my SAE's). GPT2 layer 0 attn_out really is an outlier in non-robustness compared to other layers. The results here show that different layers have different levels of robustness to noise for downstream CE loss. Combining w/ your results, it would be nice to add points for the SAE's cos-sim/CE.
An alternative hypothesis to yours is that SAE's outperform random perturbation at lower cos-sim, but suck at higher-cos-sim (which we care more about).
IDK if this is a crux for me thinking this is very relevant to stuff on my perspective, but:
The training procedure you propose doesn't seem to actually incentivize indifference. First, a toy model where I agree it does incentivize that:
On the first time step, the agent gets a choice: choose a number 1--N. If the agent says k, then the agent has nothing at all to do for the first k steps, after which some game G starts. (Each play of G is i.i.d., not related to k.)
So this agent is indeed incentivized to pick k uniformly at random from 1--N. Now consider:
The agent is in a rich world. There are many complex multi-step plans to incentivize agent to learn problem-solving. Each episode, at time N, the agent gets to choose: end now, or play 10 more steps.
Does this incentivize random choice at time N? No. It incentivizes the agent to choose randomly End or Continue at the very beginning of the episode, and then carefully plan and execute behavior that acheives the most reward assuming a run of length N or N+10 respectively.
Wait, but isn't this success? Didn't we make the agent have no trajectory length preference?
No. Suppose:
Same as before, but now there's a little guy standing by the End/Continue button. Sometimes he likes to press button randomly.
Do we kill the guy? Yes we certainly do, he will mess up our careful plans.
You commented elsewhere asking for feedback on this post. So, here is my feedback.
On my initial skim it doesn't seem to me like this approach is a particularly promising approach for prosaic AI safety. I have a variety of specific concerns. This is a somewhat timeboxed review, so apologies for any mistakes and lack of detail. I think a few parts of this review are likely to be confusing, but given time limitations, I didn't fix this.
A question
It's unclear to me what the expectation in Timestep Dominance is supposed to be with respect to. It doesn't seem like it can be with respect to the agent's subjective beliefs as this would make it even harder to impart. (And it's also unclear what exactly this should mean as the agent's subjective beliefs might be incoherant etc.)
If it's with respect to some idealized notion of the environment then the situation gets much messier to analyze because the agent will uncertain about whether one action is Timestep Dominated by another action. I think this notion of Timestep Dominance might more crippling than the subjective verion, thnough I'm unsure.
I think Timestep Dominance on subjective views and on the environment should behavior similarly in shutdown-ability, though it's a bit messy.
Imparting TD preferences seems hard
The prosaic version of this proposal assumes that you can impart timestep dominance preferences into AIs in ways which will robustly generalize. This seems unlikely to be true in general (in the absence of additional technology) and if we did have the property, we could solve safety issues in some other way (e.g. robustly generalizing honesty). So you'll need to argue that timestep dominance is particularly easy to robustly impart relative to other preferences. I can see some arguments for timestep dominance being particularly easy to robustly impart, but they don't seem very strong to me.
Naively it seems like you'll need massive generalization from toy environments to full real world cases. Such a level of generalization seems like it would also suffice for safety due to other mechanisms, e.g. honesty.
A further difficulty is that TD views often require seriously entertaining insane conditionals. E.g. conditionals in which humans didn't shut you down despite egregiously bad actions. Conditioning on extremely implausible situations gets you strange outcomes and it seems hard to construct AIs which do this.
But do TD-agents resist shutdown? (It might depend on their unspecified (non-TD) preferences as resisting shutdown will often have benefits for some shutdown timestep.)
I think it's natural for avoiding shutdown to be a side effect of actions that involve tricking, manipulating, or hiding things from humans. Further, doing these sorts of actions is likely to often be a good option when conditioning on some shutdown timestep. This techically falls under "incidental button manipulation", but I don't think the manipulation is well described as "incidental".
I think this is only a problem if we have non-TD preferences. If agents are actually indifferent aside from TD-type preferences, then there isn't an issue. (But also such agents are crippled by not investing.)
Here's an example:
Suppose that Clippy is a TD-agent which cares solely about the long run number of paperclips, but subject to a TD constraint. That is, it always prefers trajectory X over Y if for all shutdown timings X gives a >= number of paperclips than Y and X gives a > number of paperclips for some timing.
Now, consider the following proposed action for Clippy: "In a stealthy manner, construct a successor agent which pursues long run paperclips at all costs (and which isn't subject to a shutdown button, but still has TD constraints wrt. to the original Clippy's shutdown button)." This agent is implicitly resisting shutdown as it's constructing the sub-agent stealthily. So, shouldn't this action be Timestep Dominanted by "In whatever way is most expedient (but not necessarily stealthy), construct a successor agent". I claim not, because if we condition on the AI not being shutdown prior to constructing the agent (a particular shutdown time conditional), it will be worse for clippy if humans know that it is constructing a successor as then humans will have an easier time fighting the successor. In other words, having humans know that you're constructing a successor has two effects: they'll fight your successor and they'll shut you down. If we condition on not being shutdown, then they'll still fight your successor, so Clippy would prefer being stealthy in the no shut down conditional. Thus, being stealthy isn't Timestep Dominated by changing the action to avoid resisting shutdown. (And once the successor is constructed, shutting down Clippy has no effect on the long run number of paperclips (let's suppose).)
(You should think of this counterexample as a worst case theory counterexample. The exact assumptions might not be realistic, but it points at a broader class of issues.)
A related issue for the overall proposal is that it's extremely important what happens in very unlikely conditionals where we don't shutdown the AI despite seeing egregiously bad actions. The exact outcomes in these unlikely conditionals are crucial for the AI's behavior.
You might hope that we could do something like "with probability we unconditionally won't shutdown the AI. Also, in these worlds, we'll just let the AI do whatever it wants.". This way, the rare conditionals where the AI doesn't get shutdown get dominated by this. (E.g. we might hope that in the above Clippy example, in the case where we unconditionally don't do shutdown we'd just let the successor do whatever it wants. Thus, Clippy would prefer building a successor in an obvious way because conditioning on no-shutdown is conditioning on it being able to do whatever.) I think this approach has multiple serious issues, but the main thing is that if we're willing to entertain and use very unlikely hypotheticals where humanity commits to behaving in a very specific way and we can make AIs care about these conditionals, we can easily solve AI safety via another simpler mechanism. E.g., we can train our AI to "predict what exact actions we would have wanted the AI to do in the probability conditional where humanity commited to coordinating to not build AI prior to having a full solution to the alignment problem". (Of course, this isn't something you can actually get AIs to do, for similar reasons to why you can't actually impart TD preferences.)
Timestep dominance is maybe crippling
I'm most uncertain here, but my current guess would be that any sort of absolute constraint like this is crippling. I've thought through some cases and this is my current guess, but I'm by no means confident.
The goal of alignment research is not to grow some sentient AIs, and then browbeat or constrain them into doing things we want them to do even as they'd rather be doing something else.
I think this is a confusing sentence, because by "the goal of alignment research" you mean something like "the goal I want alignment research to pursue" rather than "the goal that self-identified alignment researchers are pushing towards".
Yeah I wasn't disagreeing with you to be clear. Just adding.
Yeah, I agree that lack of agency skills are an important part of the remaining human<>AI gap, and that it's possible that this won't be too difficult to solve (and that this could then lead to rapid further recursive improvements). I was just pointing toward evidence that there is a gap at the moment, and that current systems are poorly described as AGI.
@So8res I'd be really interested in how you thought about these, especially the house elf example.
A few months after posting this, I regret that we didn't say something like the following:
It's somewhat morally dubious to continue deploying AIs that are known to be scheming, because the fact that those AIs are scheming against us makes it more plausible that they're unhappy about their situation. I'd like us to have thought about this more before using the plan described here.
Current AIs suck at agency skills. Put a bunch of them in AutoGPT scaffolds and give them each their own computer and access to the internet and contact info for each other and let them run autonomously for weeks and... well I'm curious to find out what will happen, I expect it to be entertaining but not impressive or useful. Whereas, as you say, randomly sampled humans would form societies and fnd jobs etc.
This is the common thread behind all your examples Hjalmar. Once we teach our AIs agency (i.e. once they have lots of training-experience operating autonomously in pursuit of goals in sufficiently diverse/challenging environments that they generalize rather than overfit to their environment) then they'll be AGI imo. And also takeoff will begin, takeover will become a real possibility, etc. Off to the races.
I think humans doing METR's tasks are more like "expert-level" rather than average/"human-level". But current LLM agents are also far below human performance on tasks that don't require any special expertise.
From GAIA:
GAIA proposes real-world questions that require a set of fundamental abilities such as reasoning, multi-modality handling, web browsing, and generally tool-use proficiency. GAIA questions are conceptually simple for humans yet challenging for most advanced AIs: we show that human respondents obtain 92% vs. 15% for GPT-4 equipped with plugins. [Note: The latest highest AI agent score is now 39%.] This notable performance disparity contrasts with the recent trend of LLMs outperforming humans on tasks requiring professional skills in e.g. law or chemistry. GAIA's philosophy departs from the current trend in AI benchmarks suggesting to target tasks that are ever more difficult for humans. We posit that the advent of Artificial General Intelligence (AGI) hinges on a system's capability to exhibit similar robustness as the average human does on such questions.
And LLMs and VLLMs seriously underperform humans in VisualWebArena, which tests for simple web-browsing capabilities:
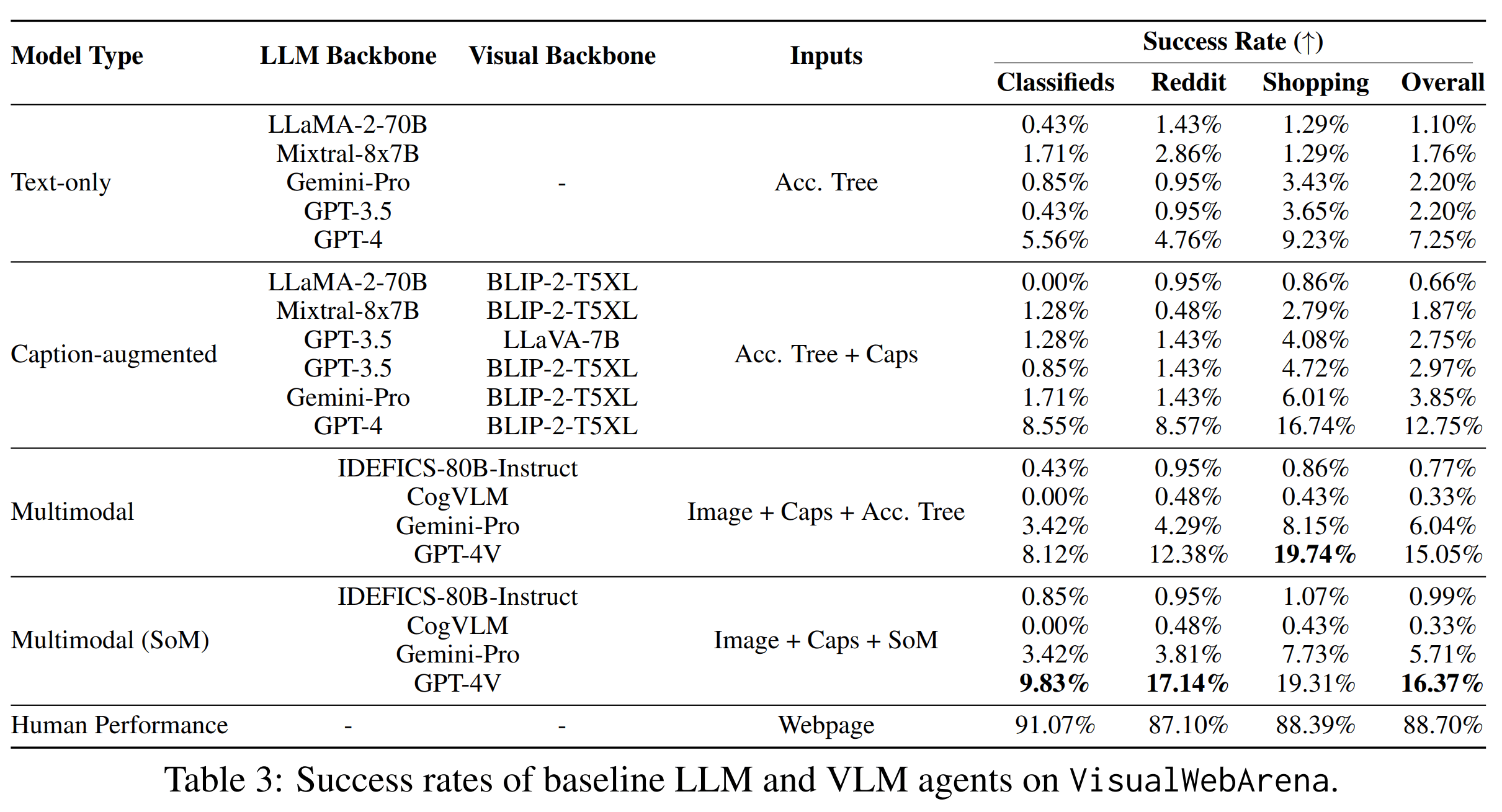

I don't know if being able to autonomously make money should be a necessary condition to qualify as AGI. But I would feel uncomfortable calling a system AGI if it can't match human performance at simple agent tasks.
Yeah, I didn't do a very good job in this respect. I am not intending to talk about a transformer by itself. I am intending to talk about transformers with the sorts of bells and whistles that they are currently being wrapped with. So not just transformers, but also not some totally speculative wrapper.
And you end up with "well for most of human history, a human with those disabilities would be a net drain on their tribe. Sometimes they were abandoned to die as a consequence. "
And it implies something like "can perform robot manipulation and wash dishes, or the "make a cup of coffee in a strangers house" test. And reliably enough to be paid minimum wage or at least some money under the table to do a task like this.
The replace-human-labor test gets quite interesting and complex when we start to time-index it. Specifically, two time-indexes are needed: a 'baseline' time (when humans are doing all the relevant work) and a comparison time (where we check how much of the baseline economy has been automated).
Without looking anything up, I guess we could say that machines have already automated 90% of the economy, if we choose our baseline from somewhere before industrial farming equipment, and our comparison time somewhere after. But this is obviously not AGI.
A human who can do exactly what GPT4 can do is not economically viable in 2024, but might have been economically viable in 2020.
Got it, makes sense, agreed.
Yeah, the precise ability I'm trying to point to here is tricky. Almost any human (barring certain forms of senility, severe disability, etc) can do some version of what I'm talking about. But as in the restaurant example, not every human could succeed at every possible example.
I was trying to better describe the abilities that I thought GPT-4 was lacking, using very simple examples. And it started looking way too much like a benchmark suite that people could target.
Suffice to say, I don't think GPT-4 is an AGI. But I strongly suspect we're only a couple of breakthroughs away. And if anyone builds an AGI, I am not optimistic we will remain in control of our futures.
Absolutely. I don't think it's impossible to build such a system. In fact, I think a transformer is probably about 90% there. Need to add trial and error, some kind of long-term memory/fine-tuning and a handful of default heuristics. Scale will help too, but no amount of scale alone will get us there.
I agree that filling a context window with worked sudoku examples wouldn't help for solving hidouku. But, there is a common element here to the games. Both look like math, but aren't about numbers except that there's an ordered sequence. The sequence of items could just as easily be an alphabetically ordered set of words. Both are much more about geometry, or topology, or graph theory, for how a set of points is connected. I would not be surprised to learn that there is a set of tokens, containing no examples of either game, combined with a checker (like your link has) that points out when a mistake has been made, that enables solving a wide range of similar games.
I think one of the things humans do better than current LLMs is that, as we learn a new task, we vary what counts as a token and how we nest tokens. How do we chunk things? In sudoku, each box is a chunk, each row and column are a chunk, the board is a chunk, "sudoku" is a chunk, "checking an answer" is a chunk, "playing a game" is a chunk, and there are probably lots of others I'm ignoring. I don't think just prompting an LLM with the full text of "How to solve it" in its context window would get us to a solution, but at some level I do think it's possible to make explicit, in words and diagrams, what it is humans do to solve things, in a way legible to it. I think it largely resembles repeatedly telescoping in and out, to lower and higher abstractions applying different concepts and contexts, locally sanity checking ourselves, correcting locally obvious insanity, and continuing until we hit some sort of reflective consistency. Different humans have different limits on what contexts they can successfully do this in.
Here's a simple test: Ask an AI to open and manage a local pizza restaurant, buying kitchen equipment, dealing with contractors, selecting recipes, hiring human employees to serve or clean, registering the business, handling inspections, paying taxes, etc. None of these are expert-level skills. But frontier models are missing several key abilities. So I do not consider them AGI.
I agree that this is a thing current AI systems don't/can't do, and that aren't considered expert-level skills for humans. I disagree that this is a simple test, or the kind of thing a typical human can do without lots of feedback, failures, or assistance. Many very smart humans fail at some or all of these tasks. They give up on starting a business, mess up their taxes, have a hard time navigating bureaucratic red tape, and don't ever learn to cook. I agree that if an AI could do these things it would be much harder to argue against it being AGI, but it's important to remember that many healthy, intelligent, adult humans can't, at least not reliably. Also, remember that most restaurants fail within a couple of years even after making it through all these hoops. The rate is very high even for experienced restauranteurs doing the managing.
I suppose you could argue for a definition of general intelligence that excludes a substantial fraction of humans, but for many reasons I wouldn't recommend it.
Ok, I misunderstood. (See also my post on the relation between local and global optimality, and another post on coordinating local decisions using MCMC)
I gave this explanation at the start of the UDT1.1 post:
When describing UDT1 solutions to various sample problems, I've often talked about UDT1 finding the function S* that would optimize its preferences over the world program P, and then return what S* would return, given its input. But in my original description of UDT1, I never explicitly mentioned optimizing S as a whole, but instead specified UDT1 as, upon receiving input X, finding the optimal output Y* for that input, by considering the logical consequences of choosing various possible outputs. I have been implicitly assuming that the former (optimization of the global strategy) would somehow fall out of the latter (optimization of the local action) without having to be explicitly specified, due to how UDT1 takes into account logical correlations between different instances of itself. But recently I found an apparent counter-example to this assumption.
That original post lays out UDT1.0, I don't see anything about precomputing the optimal policy within it. The UDT1.1 fix of optimizing the global policy instead of figuring out the best thing to do on the fly, was first presented here, note that the 1.1 post that I linked came chronologically after the post you linked.
UDT1.0, since it’s just considering modifying its own move, corresponds to a player that’s acting as if it’s independent of what everyone else is deciding, instead of teaming up with its alternate selves to play the globally optimal policy.
I thought UDT by definition pre-computes the globally optimal policy? At least, that's the impression I get from reading Wei Dai's original posts.
The math in the post is super hand-wavey, so I don't expect the result to be exactly correct. However in your example, l up to 100 should be ok, since there is no super position. 2.7 is almost 2 orders of magnitude off, which is not great.
Looking into what is going on: I'm basing my results on the Johnson–Lindenstrauss lemma, which gives an upper bound on the interference. In the post I'm assuming that the actual interference is order of magnitude the same as the this upper bound. This assumption is clearly fails in your example since the interference between features is zero, and nothing is the same order of magnitude as zero.
I might try to do the math more carefully, unless someone else gets there first. No promises though.
I expect that my qualitative claims will still hold. This is based on more than the math, but math seemed easier to write down. I think it would be worth doing the math properly, both to confirm my claims, and it may be useful to have more more accurate quantitative formulas. I might do this if I got some spare time, but no promises.
my qualitative claims = my claims about what types of things the network is trading away when using super position
quantitative formulas = how much of these things are traded away for what amount of superposition.
Recently someone either suggested to me (or maybe told me they or someone where going to do this?) that we should train AI on legal texts, to teach it human values. Ignoring the technical problem of how to do this, I'm pretty sure legal text are not the right training data. But at the time, I could not clearly put into words why. Todays SMBC explains this for me:
Saturday Morning Breakfast Cereal - Law (smbc-comics.com)
Law is not a good representation or explanation of most of what we care about, because it's not trying to be. Law is mainly focused on the contentious edge cases.
Training an AI on trolly problems and other ethical dilemmas is even worse, for the same reason.
I agree with Steve Byrnes here. I think I have a better way to describe this.
I would say that the missing piece is 'mastery'. Specifically, learning mastery over a piece of reality. By mastery I am referring to the skillful ability to model, predict, and purposefully manipulate that subset of reality.
I don't think this is an algorithmic limitation, exactly.
Look at the work Deepmind has been doing, particularly with Gato and more recently AutoRT, SARA-RT, RT-Trajectory, UniSim , and Q-transformer. Look at the work being done with the help of Nvidia's new Robot Simulation Gym Environment. Look at OpenAI's recent foray into robotics with Figure AI. This work is held back from being highly impactful (so far) by the difficulty of accurately simulating novel interesting things, the difficulty of learning the pairing of action -> consequence compared to learning a static pattern of data, and the hardware difficulties of robotics.
This is what I think our current multimodal frontier models are mostly lacking. They can regurgitate, and to a lesser extent synthesize, facts that humans wrote about, but not develop novel mastery of subjects and then report back on their findings. This is the difference between being able to write a good scientific paper given a dataset of experimental results and rough description of the experiment, versus being able to gather that data yourself. The line here is blurry, and will probably get blurrier before collapsing entirely. It's about not just doing the experiment, but doing the pilot studies and observations and playing around with the parameters to build a crude initial model about how this particular piece of the universe might work. Building your own new models rather than absorbing models built by others. Moving beyond student to scientist.
This is in large part a limitation of training expense. It's difficult to have enough on-topic information available in parallel to feed the data-inefficient current algorithms many lifetimes-worth of experience.
So, while it is possible to improve the skill of mastery-of-reality with scaling up current models and training systems, it gets much much easier if the algorithms get more compute-efficient and data-sample-efficient to train.
That is what I think is coming.
I've done my own in-depth research into the state of the field of machine learning and potential novel algorithmic advances which have not yet been incorporated into frontier models, and in-depth research into the state of neuroscience's understanding of the brain. I have written a report detailing the ways in which I think Joe Carlsmith's and Ajeya Cotra's estimates are overestimating the AGI-relevant compute of the human brain by somewhere between 10x to 100x.
Furthermore, I think that there are compelling arguments for why the compute in frontier algorithms is not being deployed as efficiently as it could be, resulting in higher training costs and data requirements than is theoretically possible.
In combination, these findings lead me to believe we are primarily algorithm-constrained not hardware or data constrained. Which, in turn, means that once frontier models have progressed to the point of being able to automate research for improved algorithms I expect that substantial progress will follow. This progress will, if I am correct, be untethered to further increases in compute hardware or training data.
My best guess is that a frontier model of the approximate expected capability of GPT-5 or GPT-6 (equivalently Claude 4 or 5, or similar advances in Gemini) will be sufficient for the automation of algorithmic exploration to an extent that the necessary algorithmic breakthroughs will be made. I don't expect the search process to take more than a year. So I think we should expect a time of algorithmic discovery in the next 2 - 3 years which leads to a strong increase in AGI capabilities even holding compute and data constant.
I expect that 'mastery of novel pieces of reality' will continue to lag behind ability to regurgitate and recombine recorded knowledge. Indeed, recombining information clearly seems to be lagging behind regurgitation or creative extrapolation. Not as far behind as mastery, so in some middle range.
If you imagine the whole skillset remaining in its relative configuration of peaks and valleys, but shifted upwards such that the currently lagging 'mastery' skill is at human level and a lot of other skills are well beyond, then you will be picturing something similar to what I am picturing.
[Edit:
This is what I mean when I say it isn't a limit of the algorithm per say. Change the framing of the data, and you change the distribution of the outputs.
]
The question is - how far can we get with in-context learning. If we filled Gemini's 10 million tokens with Sudoku rules and examples, showing where it went wrong each time, would it generalize? I'm not sure but I think it's possible
In the technical sense that you can implement arbitrary programs by prompting an LLM (they are turning complete), sure.
In a practical sense, no.
GPT-4 can't even play tic-tac-toe. Manifold spent a year getting GPT-4 to implement (much less discover) the algorithm for Sudoku and failed.
Now imagine trying to implement a serious backtracking algorithm. Stockfish checks millions of positions per turn of play. The attention window for your "backtracking transformer" is going to have to be at lease {size of chess board state}*{number of positions evaluated}.
And because of quadratic attention, training it is going to take on the order of {number or parameters}*({chess board state size}*{number of positions evaluated})^2
Even with very generous assumptions for {number of parameters} and {chess board state}, there's simply no way we could train such a model this century (and that's assuming Moore's law somehow continues that long).
It seems likely to me that you could create a prompt that would have a transformer do this.
Is it accurate to summarize the headline result as follows?
(I don't know what Computational Mechanics or MSPs are so this could be totally off.)
EDIT: Looks like yes. From this post: