I do AI Alignment research. Currently independent, but previously at: METR, Redwood, UC Berkeley, Good Judgment Project.
I'm also a part-time fund manager for the LTFF.
Obligatory research billboard website: https://chanlawrence.me/
Posts
Wiki Contributions
Comments
When I spoke to him a few weeks ago (a week after he left OAI), he had not signed an NDA at that point, so it seems likely that he hasn't.
I don't know what the "real story" is, but let me point at some areas where I think we were confused. At the time, we had some sort of hand-wavy result in our appendix saying "something something weight norm ergo generalizing". Similarly, concurrent work from Ziming Liu and others (Omnigrok) had another claim based on the norm of generalizing and memorizing solutions, as well as a claim that representation is important.
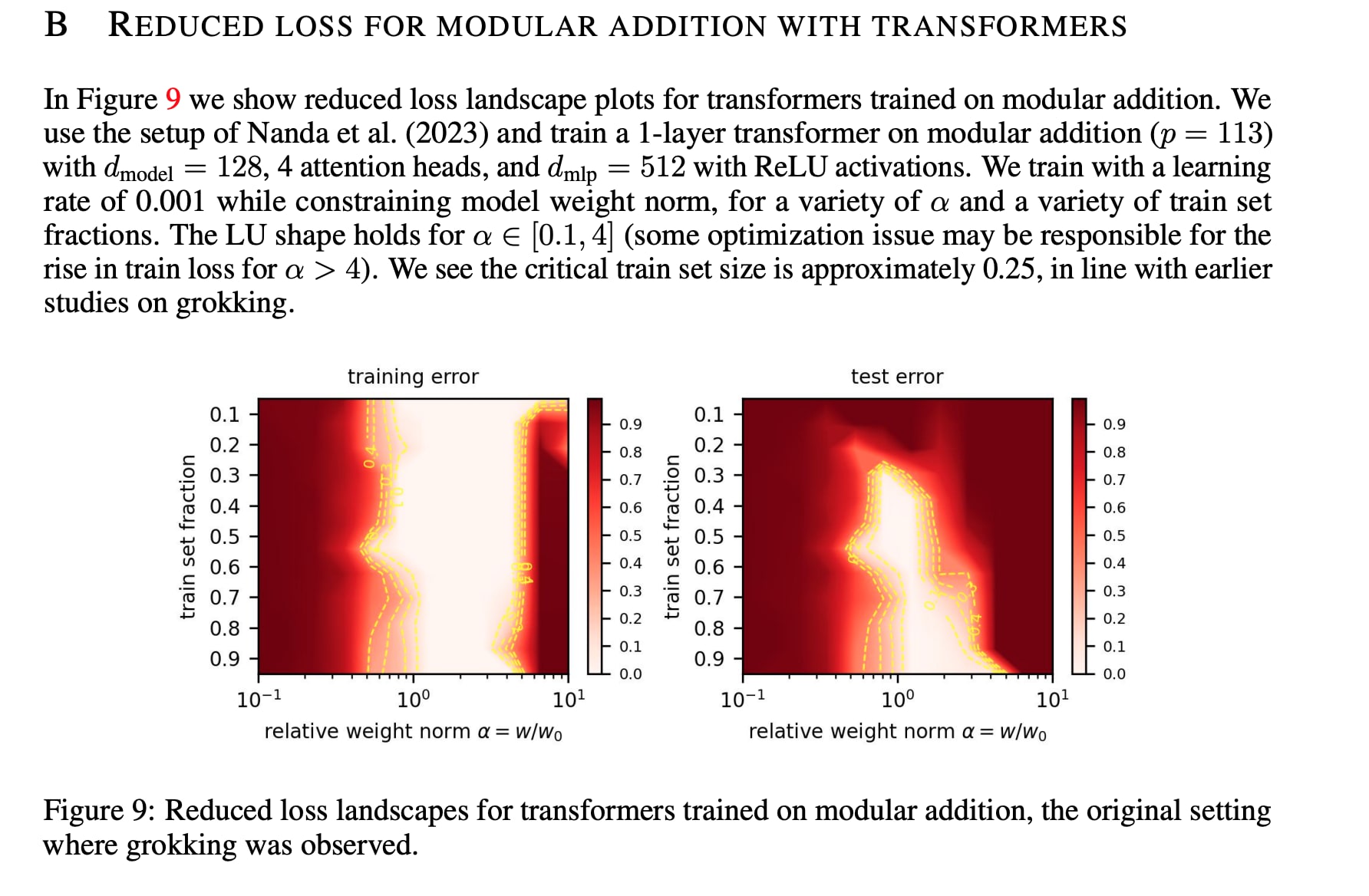
One issue is that our picture doesn't consider learning dynamics that seem actually important here. For example, it seems that one of the mechanisms that may explain why weight decay seems to matter so much in the Omnigrok paper is because fixing the norm to be large leads to an effectively tiny learning rate when you use Adam (which normalizes the gradients to be of fixed scale), especially when there's a substantial radial component (which there is, when the init is too small or too big). This both probably explains why they found that training error was high when they constrain the weights to be sufficiently large in all their non-toy cases (see e.g. the mod add landscape below) and probably explains why we had difficulty using SGD+momentum (which, given our bad initialization, led to gradients that were way too big at some parts of the model especially since we didn't sweep the learning rate very hard). [1]
There's also some theoretical results from SLT-related folk about how generalizing circuits achieve lower train loss per parameter (i.e. have higher circuit efficiency) than memorizing circuits (at least for large p), which seems to be a part of the puzzle that neither our work nor the Omnigrok touched on -- why is it that generalizing solutions have lower norm? IIRC one of our explanations was that weight decay "favored more distributed solutions" (somewhat false) and "it sure seems empirically true", but we didn't have anything better than that.
There was also the really basic idea of how a relu/gelu network may do multiplication (by piecewise linear approximations of x^2, or by using the quadratic region of the gelu for x^2), which (I think) was first described in late 2022 in Ekin Ayurek's "Transformers can implement Sherman-Morris for closed-form ridge regression" paper? (That's not the name, just the headline result.)
Part of the story for grokking in general may also be related to the Tensor Program results that claim the gradient on the embedding is too small relative to the gradient on other parts of the model, with standard init. (Also the embed at init is too small relative to the unembed.) Because the embed is both too small and do, there's no representation learning going on, as opposed to just random feature regression (which overfits in the same way that regression on random features overfits absent regularization).
In our case, it turns out not to be true (because our network is tiny? because our weight decay is set aggressively at lamba=1?), since the weights that directly contribute to logits (W_E, W_U, W_O, W_V, W_in, W_out) all quickly converge to the same size (weight decay encourages spreading out weight norm between things you multiply together), while the weights that do not all converge to zero.
Bringing it back to the topic at hand: There's often a lot more "small" confusions that remain, even after doing good toy models work. It's not clear how much any of these confusions matter (and do any of the grokking results our paper, Ziming Liu et al, or the GDM grokking paper found matter?).
- ^
Haven't checked, might do this later this week.
To be clear: I don't think the results here are qualitatively more grounded than e.g. other work in the activation steering/linear probing/representation engineering space. My comment was defense of studying harmlessness in general and less so of this work in particular.
If the objection isn't about this work vs other rep eng work, I may be confused about what you're asking about. It feels pretty obvious that this general genre of work (studying non-cherry picked phenomena using basic linear methods) is as a whole more grounded than a lot of mech interp tends to be? And I feel like it's pretty obvious that addressing issues with current harmlessness training, if they improve on state of the art, is "more grounded" than "we found a cool SAE feature that correlates with X and Y!"? In the same way that just doing AI control experiments is more grounded than circuit discovery on algorithmic tasks.
I agree pretty strongly with Neel's first point here, and I want to expand on it a bit: one of the biggest issues with interp is fooling yourself and thinking you've discovered something profound when in reality you've misinterpreted the evidence. Sure, you've "understood grokking"[1] or "found induction heads", but why should anyone think that you've done something "real", let alone something that will help with future dangerous AI systems? Getting rigorous results in deep learning in general is hard, and it seems empirically even harder in (mech) interp.
You can try to get around this by being extra rigorous and building from the ground up anyways. If you can present a ton of compelling evidence at every stage of resolution for your explanation, which in turn explains all of the behavior you care about (let alone a proof), then you can be pretty sure you're not fooling yourself. (But that's really hard, and deep learning especially has not been kind to this approach.) Or, you can try to do something hard and novel on a real system, that can't be done with existing knowledge or techniques. If you succeed at this, then even if your specific theory is not necessarily true, you've at least shown that it's real enough to produce something of value. (This is a fancy of way of saying, "new theories should make novel predictions/discoveries and test them if possible".)
From this perspective, studying refusal in LLMs is not necessarily more x-risk relevant than studying say, studying why LLMs seem to hallucinate, why linear probes seem to be so good for many use cases(and where they break), or the effects of helpfulness/agency/tool-use finetuning in general. (And I suspect that poking hard at some of the weird results from the cyborgism crowd may be more relevant.) But it's a hard topic that many people care about, and so succeeding here provides a better argument for the usefulness of their specific model internals based approach than studying something more niche.
- It's "easier"to study harmlessness than other comparably important or hard topics. Not only is there a lot of financial interest from companies, there's a lot of supporting infrastructure already in place to study harmlessness. If you wanted to study the exact mechanism by which Gemini Ultra is e.g. so good at confabulating undergrad-level mathematical theorems, you'd immediately run into the problem that you don't have Gemini internals access (and even if you do, the code is almost certainly not set up for easily poking around inside the model). But if you study a mechanism like refusal training, where there are open source models that are refusal trained and where datasets and prior work is plentiful, you're able to leverage existing resources.
- Many of the other things AI Labs are pushing hard on are just clear capability gains, which many people morally object to. For example, I'm sure many people would be very interested if mech interp could significantly improve pretraining, or suggest more efficient sparse architectures. But I suspect most x-risk focused people would not want to contribute to these topics.
Now, of course, there's the standard reasons why it's bad to study popular/trendy topics, including conflating your line of research with contingent properties of the topics (AI Alignment is just RLHF++, AI Safety is just harmlessness training), getting into a crowded field, being misled by prior work, etc. But I'm a fan of model internals researchers (esp mech interp researchers) apply their research to problems like harmlessness, even if it's just to highlight the way in which mech interp is currently inadequate for these applications.
Also, I would be upset if people started going "the reason this work is x-risk relevant is because of preventing jailbreaks" unless they actually believed this, but this is more of a general distaste for dishonesty as opposed to jailbreaks or harmlessness training in general.
(Also, harmlessness training may be important under some catastrophic misuse scenarios, though I struggle to imagine a concrete case where end user-side jailbreak-style catastrophic misuse causes x-risk in practice, before we get more direct x-risk scenarios from e.g. people just finetuning their AIs to in dangerous ways.)
- ^
For example, I think our understanding of Grokking in late 2022 turned out to be importantly incomplete.
Thanks!
I was grouping that with “the computation may require mixing together ‘natural’ concepts” in my head. After all, entropy isn’t an observable in the environment, it’s something you derive to better model the environment. But I agree that “the concept may not be one you understand” seems more central.
My speculation for Omni-Grok in particular is that in settings like MNIST you already have two of the ingredients for grokking (that there are both memorising and generalising solutions, and that the generalising solution is more efficient), and then having large parameter norms at initialisation provides the third ingredient (generalising solutions are learned more slowly), for some reason I still don't know.
Higher weight norm means lower effective learning rate with Adam, no? In that paper they used a constant learning rate across weight norms, but Adam tries to normalize the gradients to be of size 1 per paramter, regardless of the size of the weights. So the weights change more slowly with larger initializations (especially since they constrain the weights to be of fixed norm by projecting after the Adam step).
I mean, yeah, as your footnote says:
Another simpler but less illuminating way to put this is that higher serial reasoning depth can't be parallelized.[1]
Transformers do get more computation per token on longer sequences, but they also don't get more serial depth, so I'm not sure if this is actually an issue in practice?
- ^
[C]ompactly represent (f composed with g) in a way that makes computing more efficient for general choices of and .
As an aside, I actually can't think of any class of interesting functions with this property -- when reading the paper, the closest I could think of are functions on discrete sets (lol), polynomials (but simplifying these are often more expensive than just computing the terms serially), and rational functions (ditto)
I finally got around to reading the Mamba paper. H/t Ryan Greenblatt and Vivek Hebbar for helpful comments that got me unstuck.
TL;DR: authors propose a new deep learning architecture for sequence modeling with scaling laws that match transformers while being much more efficient to sample from.
A brief historical digression
As of ~2017, the three primary ways people had for doing sequence modeling were RNNs, Conv Nets, and Transformers, each with a unique “trick” for handling sequence data: recurrence, 1d convolutions, and self-attention.
- RNNs are easy to sample from — to compute the logit for x_t+1, you only need the most recent hidden state h_t and the last token x_t, which means it’s both fast and memory efficient. RNNs generate a sequence of length L with O(1) memory and O(L) time. However, they’re super hard to train, because you need to sequentially generate all the hidden states and then (reverse) sequentially calculate the gradients. The way you actually did this is called backpropogation through time — you basically unroll the RNN over time — which requires constructing a graph of depth equal to the sequence length. Not only was this slow, but the graph being so deep caused vanishing/exploding gradients without careful normalization. The strategy that people used was to train on short sequences and finetune on longer ones. That being said, in practice, this meant you couldn’t train on long sequences (>a few hundred tokens) at all. The best LSTMs for modeling raw audio could only handle being trained on ~5s of speech, if you chunk up the data into 25ms segments.
- Conv Nets had a fixed receptive field size and pattern, so weren’t that suited for long sequence modeling. Also, generating each token takes O(L) time, assuming the receptive field is about the same size as the sequence. But they had significantly more stability (the depth was small, and could be as low as O(log(L))), which meant you could train them a lot easier. (Also, you could use FFT to efficiently compute the conv, meaning it trains one sequence in O(L log(L)) time.) That being said, you still couldn’t make them that big. The most impressive example was DeepMind’s WaveNet, conv net used to model human speech, and could handle up sequences up to 4800 samples … which was 0.3s of actual speech at 16k samples/second (note that most audio is sampled at 44k samples/second…), and even to to get to that amount, they had to really gimp the model’s ability to focus on particular inputs.
- Transformers are easy to train, can handle variable length sequences, and also allow the model to “decide” which tokens it should pay attention to. In addition to both being parallelizable and having relatively shallow computation graphs (like conv nets), you could do the RNN trick of pretraining on short sequences and then finetune on longer sequences to save even more compute. Transformers could be trained with comparable sequence length to conv nets but get much better performance; for example, OpenAI’s musenet was trained on sequence length 4096 sequences of MIDI files. But as we all know, transformers have the unfortunate downside of being expensive to sample from — it takes O(L) time and O(L) memory to generate a single token (!).
The better performance of transformers over conv nets and their ability to handle variable length data let them win out.
That being said, people have been trying to get around the O(L) time and memory requirements for transformers since basically their inception. For a while, people were super into sparse or linear attention of various kinds, which could reduce the per-token compute/memory requirements to O(log(L)) or O(1).
The what and why of Mamba
If the input -> hidden and hidden -> hidden map for RNNs were linear (h_t+1 = A h_t + B x_t), then it’d be possible to train an entire sequence in parallel — this is because you can just … compose the transformation with itself (computing A^k for k in 2…L-1) a bunch, and effectively unroll the graph with the convolutional kernel defined by A B, A^2 B, A^3 B, … A^{L-1} B. Not only can you FFT during training to get the O(L log (L)) time of a conv net forward/backward pass (as opposed to O(L^2) for the transformer), you still keep the O(1) sampling time/memory of the RNN!
The problem is that linear hidden state dynamics are kinda boring. For example, you can’t even learn to update your existing hidden state in a different way if you see particular tokens! And indeed, previous results gave scaling laws that were much worse than transformers in terms of performance/training compute.
In Mamba, you basically learn a time varying A and B. The parameterization is a bit wonky here, because of historical reasons, but it goes something like: A_t is exp(-\delta(x_t) * exp(A)), B_t = \delta(x_t) B x_t, where \delta(x_t) = softplus ( W_\delta x_t). Also note that in Mamba, they also constrain A to be diagonal and W_\delta to be low rank, for computational reasons
Since exp(A) is diagonal and has only positive entries, we can interpret the model as follows: \delta controls how much to “learn” from the current example — with high \delta, A_t approaches 0 and B_t is large, causing h_t+1 ~= B_t x_t, while with \delta approaching 0, A_t approaches 1 and B_t approaches 0, meaning h_t+1 ~= h_t.
Now, you can’t exactly unroll the hidden state as a convolution with a predefined convolution kernel anymore, but you can still efficiently compute the implied “convolution” using parallel scanning.
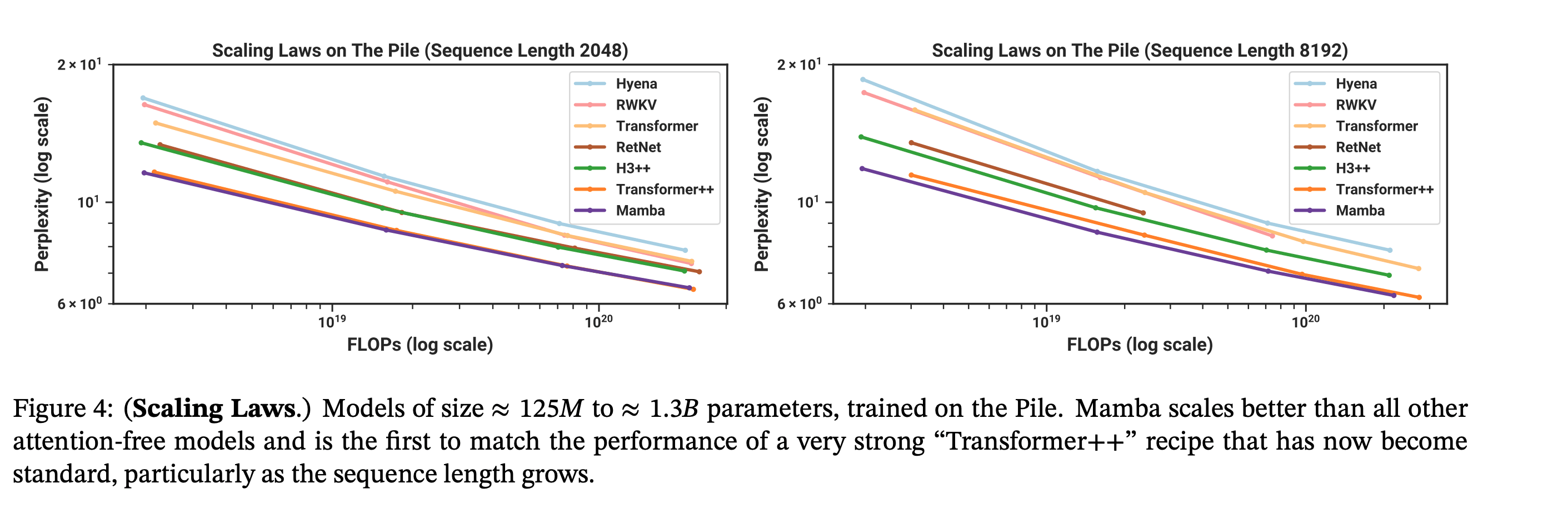
Despite being much cheaper to sample from, Mamba matches the pretraining flops efficiency of modern transformers (Transformer++ = the current SOTA open source Transformer with RMSNorm, a better learning rate schedule, and corrected AdamW hyperparameters, etc.). And on a toy induction task, it generalizes to much longer sequences than it was trained on.
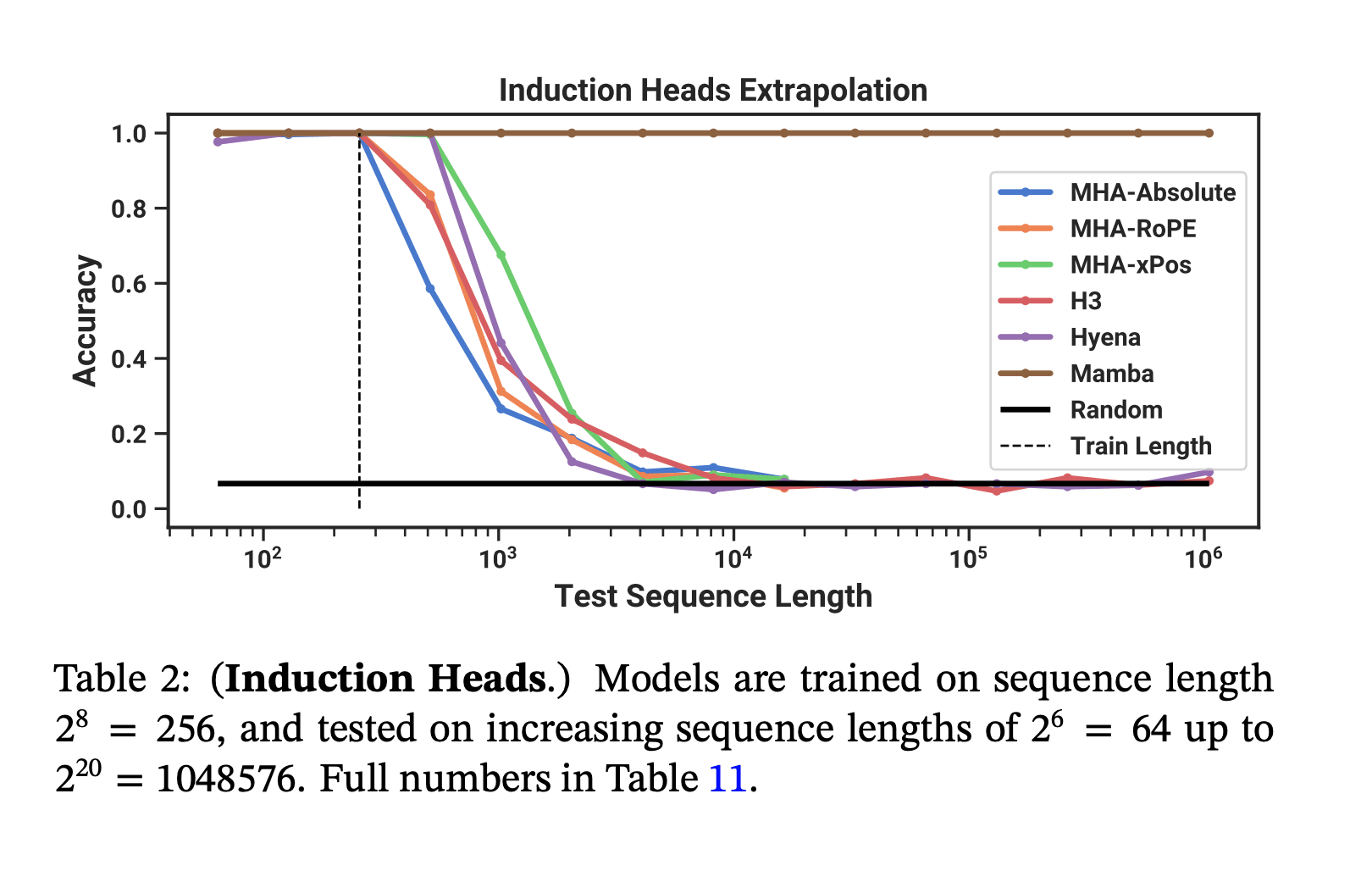
So, about those capability externalities from mech interp...
Yes, those are the same induction heads from the Anthropic ICL paper!
Like the previous Hippo and Hyena papers they cite mech interp as one of their inspirations, in that it inspired them to think about what the linear hidden state model could not model and how to fix that. I still don’t think mech interp has that much Shapley here (the idea of studying how models perform toy tasks is not new, and the authors don't even use induction metric or RRT task from the Olsson et al paper), but I'm not super sure on this.
IMO, this is line of work is the strongest argument for mech interp (or maybe interp in general) having concrete capabilities externalities. In addition, I think the previous argument Neel and I gave of "these advances are extremely unlikely to improve frontier models" feels substantially weaker now.
Is this a big deal?
I don't know, tbh.
Right, the step I missed on was that P(X|Y) = P(X|Z) for all y, z implies P(X|Z) = P(X). Thanks!
The general version of this statement is something like: if your beliefs satisfy the law of total expectation, the variance of the whole process should equal the variance of all the increments involved in the process.[1] In the case of the random walk where at each step, your beliefs go up or down by 1% starting from 50% until you hit 100% or 0% -- the variance of each increment is 0.01^2 = 0.0001, and the variance of the entire process is 0.5^2 = 0.25, hence you need 0.25/0.0001 = 2500 steps in expectation. If your beliefs have probability p of going up or down by 1% at each step, and 1-p of staying the same, the variance is reduced by a factor of p, and so you need 2500/p steps.
(Indeed, something like this standard way to derive the expected steps before a random walk hits an absorbing barrier).
Similarly, you get that if you start at 20% or 80%, you need 1600 steps in expectation, and if you start at 1% or 99%, you'll need 99 steps in expectation.
One problem with your reasoning above is that as the 1%/99% shows, needing 99 steps in expectation does not mean you will take 99 steps with high probability -- in this case, there's a 50% chance you need only one update before you're certain (!), there's just a tail of very long sequences. In general, the expected value of variables need not look like
I also think you're underrating how much the math changes when your beliefs do not come in the form of uniform updates. In the most extreme case, suppose your current 50% doom number comes from imagining that doom is uniformly distributed over the next 10 years, and zero after -- then the median update size per week is only 0.5/520 ~= 0.096%/week, and the expected number of weeks with a >1% update is 0.5 (it only happens when you observe doom). Even if we buy a time-invariant random walk model of belief updating, as the expected size of your updates get larger, you also expect there to be quadratically fewer of them -- e.g. if your updates came in increments of size 0.1 instead of 0.01, you'd expect only 25 such updates!
Applying stochastic process-style reasoning to beliefs is empirically very tricky, and results can vary a lot based on seemingly reasonable assumptions. E.g. I remember Taleb making a bunch of mathematically sophisticated arguments[2] that began with "Let your beliefs take the form of a Wiener process[3]" and then ending with an absurd conclusion, such as that 538's forecasts are obviously wrong because their updates aren't Gaussian distributed or aren't around 50% until immediately before the elction date. And famously, reasoning of this kind has often been an absolute terrible idea in financial markets. So I'm pretty skeptical of claims of this kind in general.
There's some regularity conditions here, but calibrated beliefs that things you eventually learn the truth/falsity of should satisfy these by default.
Often in an attempt to Euler people who do forecasting work but aren't super mathematical, like Philip Tetlock.
This is what happens when you take the limit of the discrete time random walk, as you allow for updates on ever smaller time increments. You get Gaussian distributed increments per unit time -- W_t+u - W_t ~ N(0, u) -- and since the tail of your updates is very thin, you continue to get qualitatively similar results to your discrete-time random walk model above.
And yes, it is ironic that Taleb, who correctly points out the folly of normality assumptions repeatedly, often defaults to making normality assumptions in his own work.