I've been developing an interactive tool that I believe is helpful in accelerating transformer mechanistic analysis and that has the potential to reduce the barrier of entry.
Motivations
For a while now, my focus has been shifting towards alignment research, but getting involved and building intuition in this field has been challenging. I believe this is somewhat of a common view, and perhaps gives reasoning towards the number of posts discussing differing intuitions and getting started.
To this end, I'd like to share a transformer mechanistic analysis tool I've developed that has been helpful in my own personal intuition construction and has enabled me to build up others intuition quickly as well. It is currently focused on activation layer visualisation, ablation and freezing but there is work regarding patching, gradient and weight based interactions I plan on expanding to as-well.
Furthermore, there has also been a secondary goal of the project. To "industrialise" the process of finding, analysing and explaining circuits and algorithms within transformers. Several groups have shown their ability to decode these out of models, but all with significant effort (from my understanding). It is my belief that focusing on the toolset used to achieve these goals; standardising it, and making it quick and easy to use is key in expanding our ability to do this at a broader scale and potentially even automating it.
Design Philosophy
While translating these goals into what the tool is today I've had to make some key considerations. Primarily, how can we give a more human intelligible view of models that are large in terms of layer count and dimensionality? And how can we enable interacting, adjusting and observing how the model is affected live through these views?
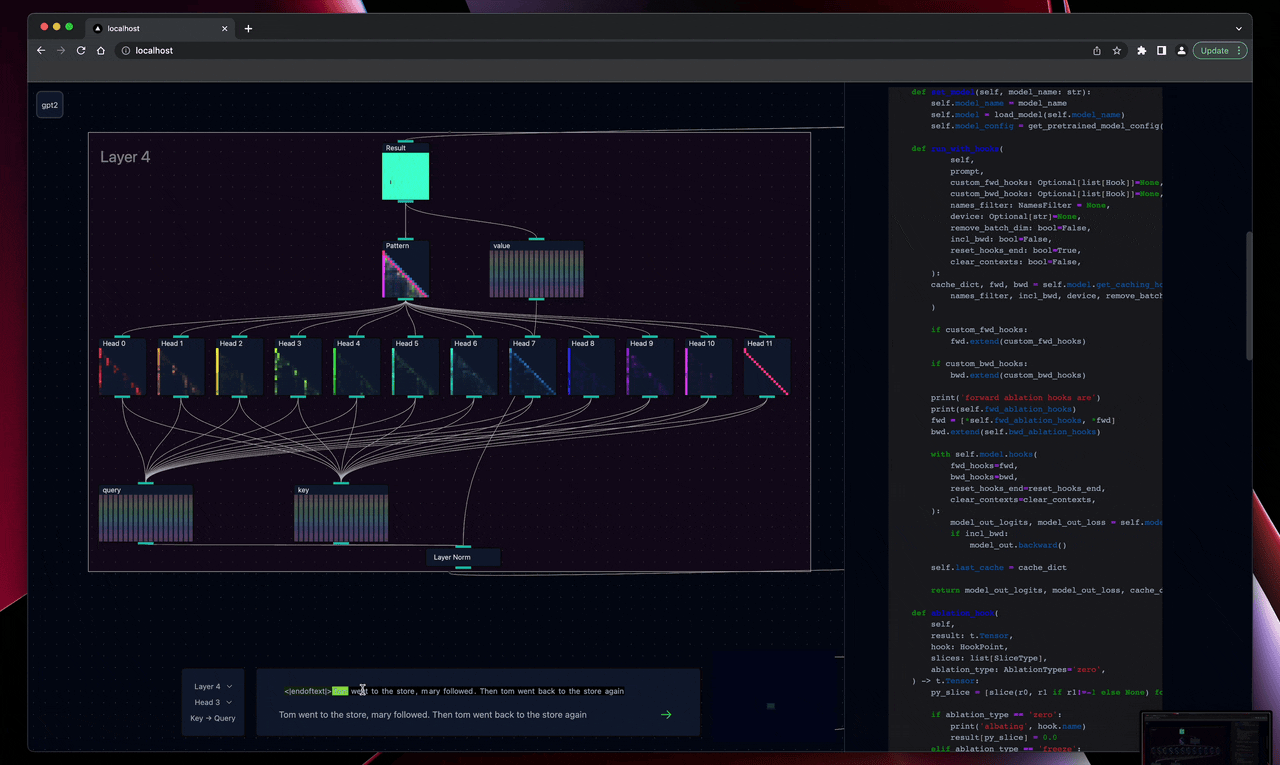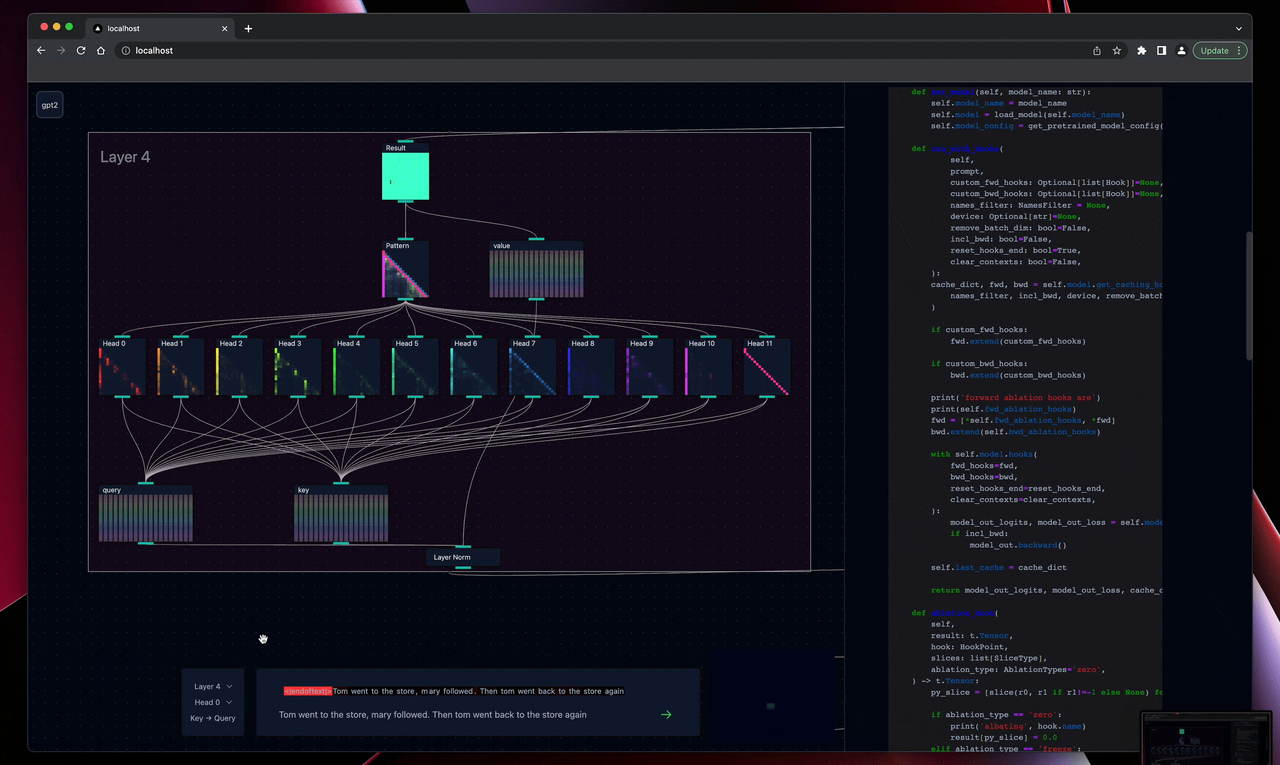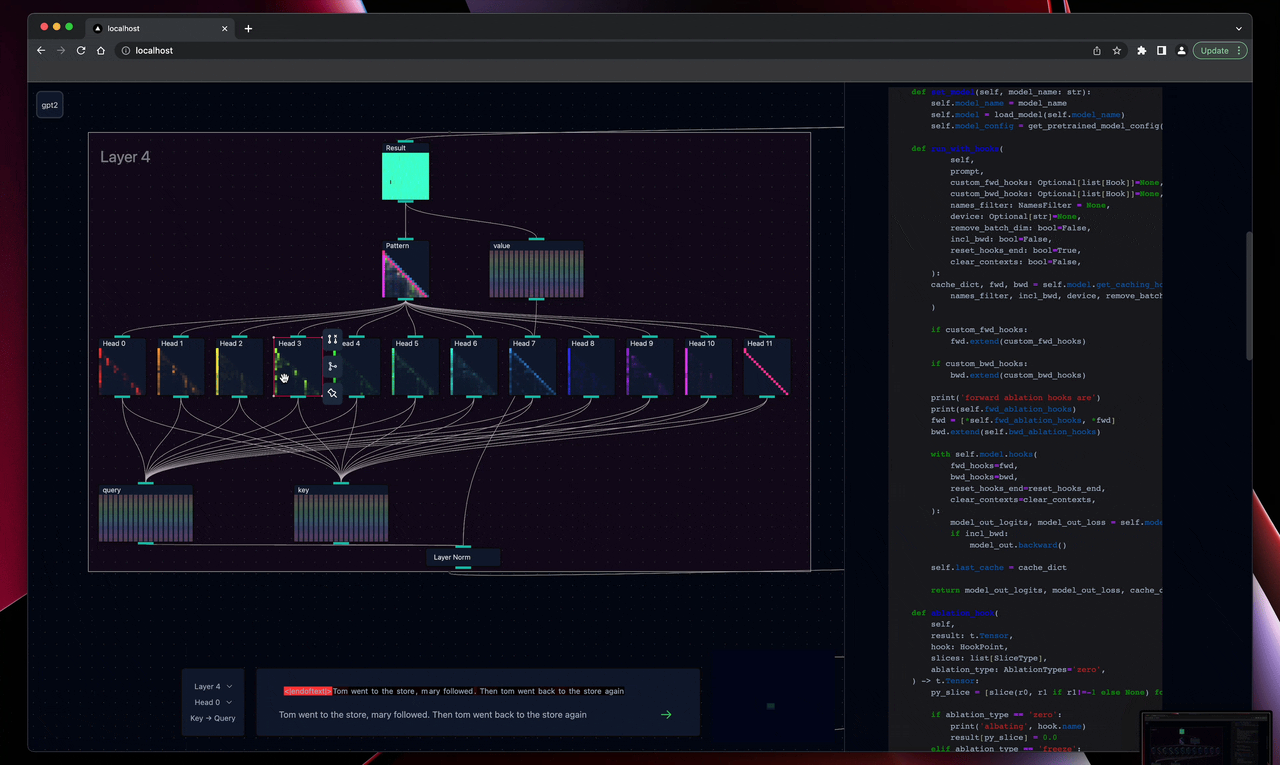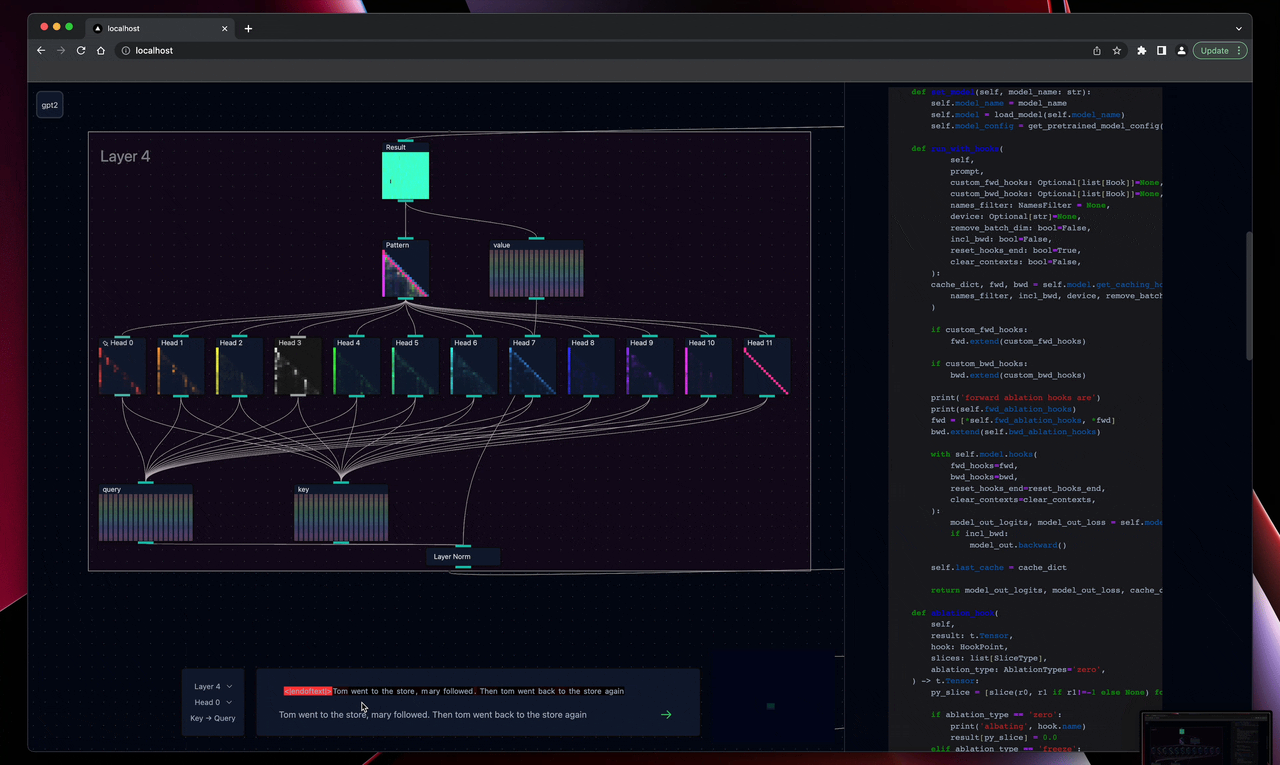
To this end, the visual components of the tool can be broken down into two categories, the high level architecture (layers, residual stream...) and the individual components (attn heads, logits...). Displaying model architecture within the tool has taken a similar approach to Anthropic's figures for transformer circuits, providing an interactive map with attention and MLP layers adding to the residual backbone. I believe this is one of the most intuitive visualisations to represent transformer architecture, and is somewhat interpretable even to those who aren't in the field.
For individual components, such as attention heads, they have been built out as unique visualisations, focusing on what has shown useful in prior decoding work. For heads this means KQ activation patterns with a heavily circuitviz/ Anthropic inspired text overlay and a set of controls for freezing and ablating individual heads. Many of these are still being developed and input would be especially appreciated for useful MLP and LayerNorm visualisations.
Another key consideration has been that I don't believe all or even the majority of decoding work fits well into prebuilt visuals. Which is why the tool is run out of a jupyter-server kernel that is displayed and can be interacted with alongside. Structuring the tool this way enables code to be written that can affect the model's internal state and can be reflected in the visualisations immediately. Furthermore it enables arbitrary work to be done beyond the scope of the tool.
Request for Feedback
I'm excited for the tool to have reached a state where I can start attempting to decode some of my own toy models with it. But it is still early days, and as many of those who have completed larger and more complex circuit/ algorithm extractions are members of this community, gaining your insights, critiques and suggestions would hold significantly value for the project. In this respect, any observations positive or negative from this entire community would be greatly appreciated.
In Brief:
I've been developing an interactive tool that I believe is helpful in accelerating transformer mechanistic analysis and that has the potential to reduce the barrier of entry.
Motivations
For a while now, my focus has been shifting towards alignment research, but getting involved and building intuition in this field has been challenging. I believe this is somewhat of a common view, and perhaps gives reasoning towards the number of posts discussing differing intuitions and getting started.
To this end, I'd like to share a transformer mechanistic analysis tool I've developed that has been helpful in my own personal intuition construction and has enabled me to build up others intuition quickly as well. It is currently focused on activation layer visualisation, ablation and freezing but there is work regarding patching, gradient and weight based interactions I plan on expanding to as-well.
Furthermore, there has also been a secondary goal of the project. To "industrialise" the process of finding, analysing and explaining circuits and algorithms within transformers. Several groups have shown their ability to decode these out of models, but all with significant effort (from my understanding). It is my belief that focusing on the toolset used to achieve these goals; standardising it, and making it quick and easy to use is key in expanding our ability to do this at a broader scale and potentially even automating it.
Design Philosophy
While translating these goals into what the tool is today I've had to make some key considerations. Primarily, how can we give a more human intelligible view of models that are large in terms of layer count and dimensionality? And how can we enable interacting, adjusting and observing how the model is affected live through these views?
To this end, the visual components of the tool can be broken down into two categories, the high level architecture (layers, residual stream...) and the individual components (attn heads, logits...). Displaying model architecture within the tool has taken a similar approach to Anthropic's figures for transformer circuits, providing an interactive map with attention and MLP layers adding to the residual backbone. I believe this is one of the most intuitive visualisations to represent transformer architecture, and is somewhat interpretable even to those who aren't in the field.
For individual components, such as attention heads, they have been built out as unique visualisations, focusing on what has shown useful in prior decoding work. For heads this means KQ activation patterns with a heavily circuitviz/ Anthropic inspired text overlay and a set of controls for freezing and ablating individual heads. Many of these are still being developed and input would be especially appreciated for useful MLP and LayerNorm visualisations.
Another key consideration has been that I don't believe all or even the majority of decoding work fits well into prebuilt visuals. Which is why the tool is run out of a jupyter-server kernel that is displayed and can be interacted with alongside. Structuring the tool this way enables code to be written that can affect the model's internal state and can be reflected in the visualisations immediately. Furthermore it enables arbitrary work to be done beyond the scope of the tool.
Request for Feedback
I'm excited for the tool to have reached a state where I can start attempting to decode some of my own toy models with it. But it is still early days, and as many of those who have completed larger and more complex circuit/ algorithm extractions are members of this community, gaining your insights, critiques and suggestions would hold significantly value for the project. In this respect, any observations positive or negative from this entire community would be greatly appreciated.