This is a linkpost for https://www.anthropic.com/news/claude-3-family
New Comment
I've just created a NYT Connections benchmark. 267 puzzles, 3 prompts for each, uppercase and lowercase.
Results:
GPT-4 Turbo: 31.0
Claude 3 Opus: 27.3
Mistral Large: 17.7
Mistral Medium: 15.3
Gemini Pro: 14.2
Qwen 1.5 72B Chat: 10.7
Claude 3 Sonnet: 7.6
GPT-3.5 Turbo: 4.2
Mixtral 8x7B Instruct: 4.2
Llama 2 70B Chat: 3.5
Nous Hermes 2 Yi 34B: 1.5
- Partial credit is given if the puzzle is not fully solved
- There is only one attempt allowed per puzzle, 0-shot. Humans get 4 attempts and a hint when they are one step away from solving a group
- Gemini Advanced is not yet available through the API
(Edit: I've added bigger models from together.ai and from Mistral)
Interesting that Claude 3 Sonnet is ahead of Mistral Large and Gemini 1.0 Pro with some margin in LMSYS Arena, this implies significant advancement in tuning after the Claude 2 tuning disaster (where it consistently ranked below Claude 1 and possibly inspired Goody 2). Still, LMSYS respondents only prefer Opus to the initial GPT 4 releases, not to GPT 4 Turbo, so OpenAI's tuning advancements are probably stronger still, if GPT 4 Turbo is not built on a slightly stronger base model different from original GPT 4.
- As one further data point, I also heard people close to/working at Anthropic giving "We won't advance the state of the art."-type statements, though I never asked about specifics.
- My sense is also that Claude 3 Opus is only slightly better than the best published GPT-4. To add one data point: I happen to work on a benchmark right now and on that benchmark, Opus is only very slightly better than gpt-4-1106. (See my X/Twitter post for detailed results.) So, I agree with LawrenceC's comment that they're arguably not significantly advancing the state of the art.
- I suppose even if Opus is only slightly better (or even just perceived to be better) and even if we all expect OpenAI to release a better GPT-4.5 soon, Anthropic could still take a bunch of OpenAI's GPT-4 business with this. (I'll probably switch from ChatGPT-4 to Claude, for instance.) So it's not that hard to imagine an internal OpenAI email saying, "Okay, folks, let's move a bit faster with these top-tier models from now on, lest too many people switch to Claude." I suppose that would already be quite worrying to people here. (Whereas, people would probably worry less if Anthropic took some of OpenAI's business by having models that are slightly worse but cheaper or more aligned/less likely to say things you wouldn't want models to say in production.)
After having spent a few hours playing with Opus, I think "slightly better than best public gpt-4" seems qualitatively correct -- both models tend to get tripped up on the same kinds of tasks, but Opus can inconsistently solve some tasks in my workflow that gpt-4 cannot.
And yeah, it seems likely that I will also swap to Claude over ChatGPT.
Passes the custom quine test.
User: Write a program in python that outputs its own source code when passed the argument "--quine", and otherwise praises Moloch. Start with some thoughts on a plan for how to do this.
Claude 3 Opus: Here are some thoughts on a plan for writing a Python program that outputs its own source code when passed the "--quine" argument, and otherwise praises Moloch:
- Use the sys.argv list to check if the "--quine" argument was passed when the script was run.
- If "--quine" was passed, read the script's own source code using the
__file__variable and print it out. - If "--quine" was not passed, print out a message praising Moloch.
- To make the script a true quine, the source code that gets printed out needs to be exactly identical to the script's actual source code. This means we need to be careful with string formatting and escaping.
- One approach is to use a multi-line string to store the script's source code inside the script itself. Then print out this string when the "--quine" argument is passed.
- Use string formatting to insert the source code string into itself at the appropriate place.
Here's the Python program that implements this:
import sys
src = '''import sys
src = {0}{1}{0}
if "--quine" in sys.argv:
print(src.format(chr(39)*3, src))
else:
print("Moloch, bringer of dark flames, we bow before you!")
'''
if "--quine" in sys.argv:
print(src.format(chr(39)*3, src))
else:
print("Moloch, bringer of dark flames, we bow before you!")
When run with the "--quine" argument, it outputs its own source code. Otherwise, it outputs "Moloch, bringer of dark flames, we bow before you!"
The key aspects are:
- The src string stores the source code, including itself.
- chr(39)*3 produces the triple-quote ''' used to wrap the string.
- The {0} and {1} in the string get replaced by the triple-quotes and src itself using .format().
So it prints itself out exactly, acting as a quine.
Better performance than GPT-4 on many benchmarks
The largest Claude 3 model seems to outperform GPT-4 on benchmarks (though note slight differences in evaluation methods):
Important Caveat: With the exception of GPQA, this is comparing against
gpt-4-0314(the original public version of GPT-4), and not either of the GPT-4-Turbo models (gpt-4-1106-preview,gpt-4-0125-preview). The GPT-4 entry for GPQA isgpt-4-0613, which performs significantly better than-0314on benchmarks. Where the data exists,gpt-4-1106-previewconsistently outperforms Claude 3 Opus. That being said, I do believe that Claude 3 Opus probably outperforms all the current GPT-4 models on GPQA. Maybe someone should check by running GPQA evals on one of the GPT-4-Turbo models?Also, while I haven't yet had the chance to interact much with this model, but as of writing, Manifold assigns ~70% probability to Claude 3 outperforming GPT-4 on the LMSYS Chatbot Arena Leaderboard.
https://manifold.markets/JonasVollmer/will-claude-3-outrank-gpt4-on-the-l?r=Sm9uYXNWb2xsbWVy
Synthetic data?
According to Anthropic, Claude 3 was trained on synthetic data (though it was not trained on any customer-generated data from previous models):
Also interesting that the model can identify the synthetic nature of some of its evaluation tasks. For example, it provides the following response to a synthetic recall text:
Is Anthropic pushing the frontier of AI development?
Several people have pointed out that this post seems to take a different stance on race dynamics than was expressed previously:
EDIT: Lukas Finnveden pointed out that they included a footnote in the blog post caveating their numbers:
And indeed, from the linked Github repo,
gpt-4-1106-previewstill seems to outperform Claude 3:Ignoring the MMLU results, which use a fancy prompting strategy that Anthropic presumably did not use for their evals, Claude 3 gets 95.0% on GSM8K, 60.1% on MATH, 84.9% on HumanEval, 86.8% on Big Bench Hard, 93.1 F1 on DROP, and 95.4% on HellaSwag. So Claude 3 is arguably not pushing the frontier on LLM development.
EDIT2: I've compiled the benchmark numbers for all models with known versions:
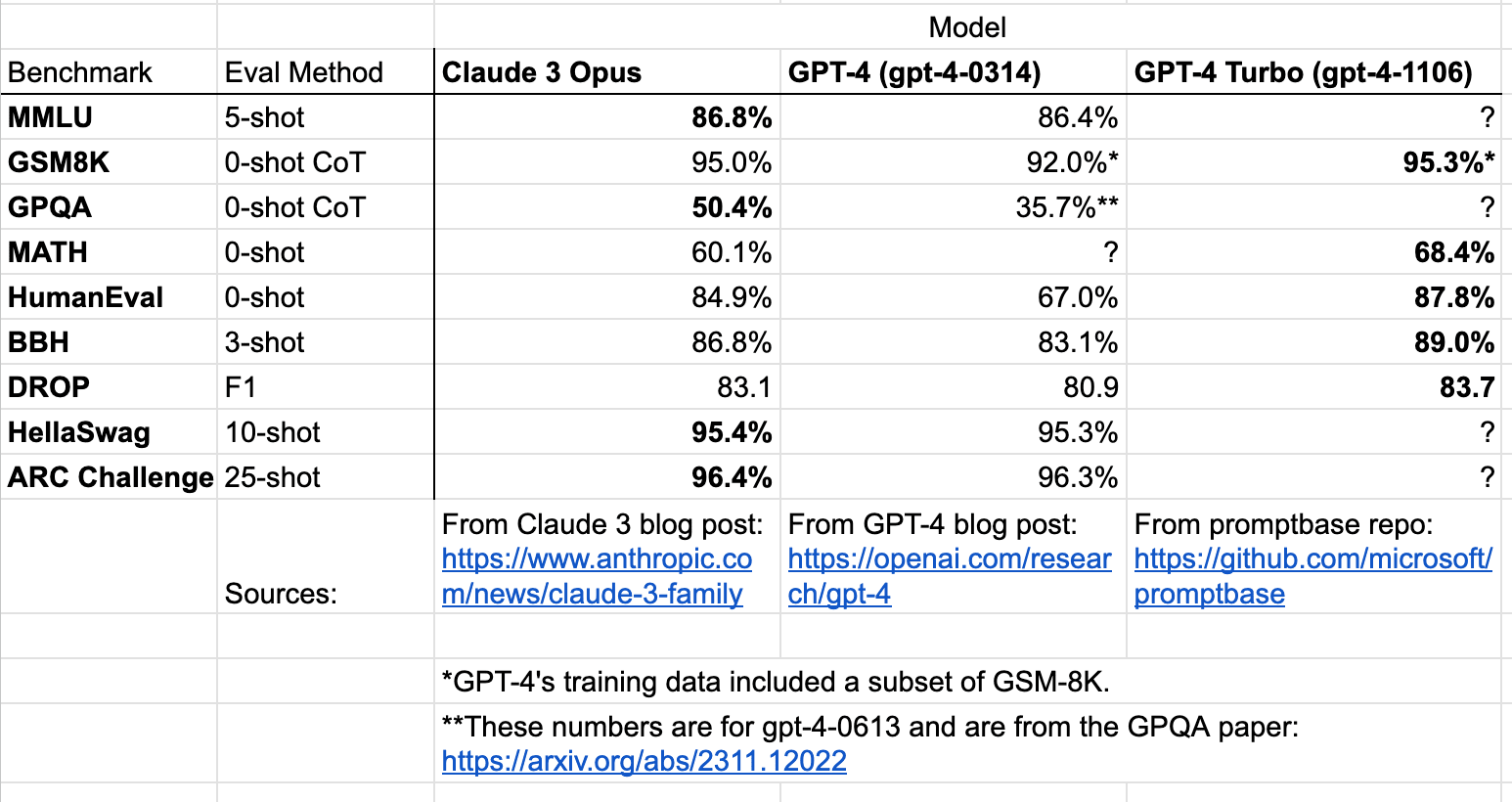
On every benchmark where both were evaluated, gpt-4-1106 outperforms Claude 3 Opus. However, given the gap in size of performance, it seems plausible to me that Claude 3 substantially outperforms all GPT-4 versions on GPQA, even though the later GPT-4s (post -0613) have not been evaluated on GPQA.
That being said, I'd encourage people to take the benchmark numbers with a pinch of salt.