I've only done replications on the mlp_out & attn_out for layers 0 & 1 for gpt2 small & pythia-70M
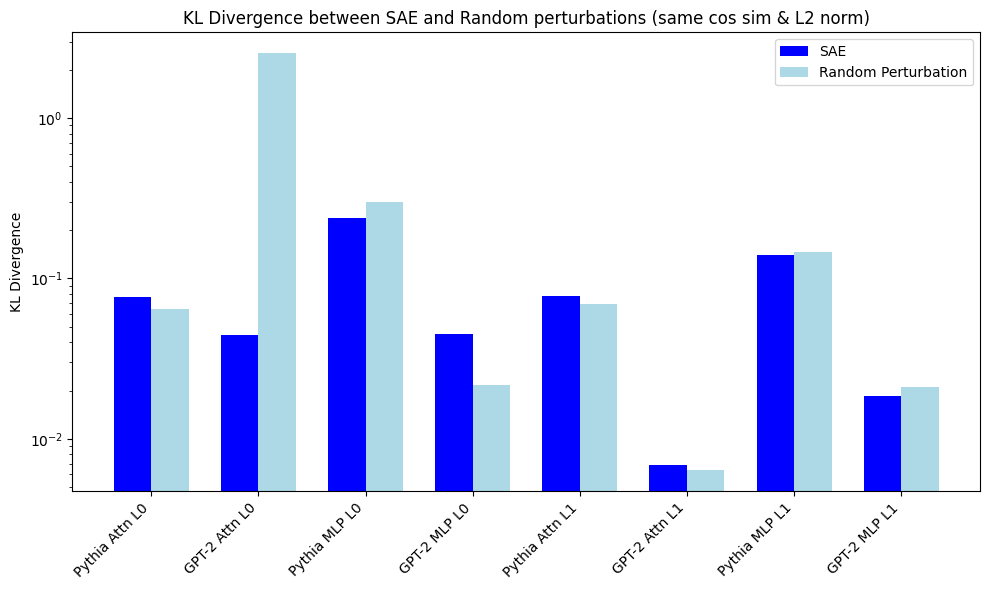
I chose same cos-sim instead of epsilon perturbations. My KL divergence is log plot, because one KL is ~2.6 for random perturbations.
I'm getting different results for GPT-2 attn_out Layer 0. My random perturbation is very large KL. This was replicated last week when I was checking how robust GPT2 vs Pythia is to perturbations in input (picture below). I think both results are actually correct, but my perturbation is for a low cos-sim (which if you see below shoots up for very small cos-sim diff). This is further substantiated by my SAE KL divergence for that layer being 0.46 which is larger than the SAE you show.
Your main results were on the residual stream, so I can try to replicate there next.
For my perturbation graph:
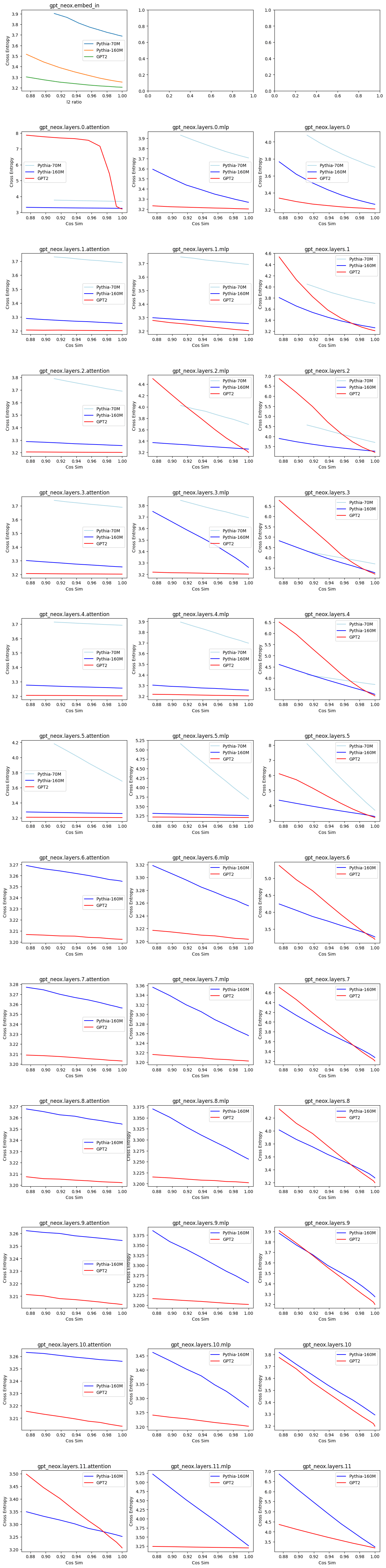
I add noise to change the cos-sim, but keep the norm at around 0.9 (which is similar to my SAE's). GPT2 layer 0 attn_out really is an outlier in non-robustness compared to other layers. The results here show that different layers have different levels of robustness to noise for downstream CE loss. Combining w/ your results, it would be nice to add points for the SAE's cos-sim/CE.
An alternative hypothesis to yours is that SAE's outperform random perturbation at lower cos-sim, but suck at higher-cos-sim (which we care more about).
Summary
Sparse Autoencoder (SAE) errors are empirically pathological: when a reconstructed activation vector is distance ϵ from the original activation vector, substituting a randomly chosen point at the same distance changes the next token prediction probabilities significantly less than substituting the SAE reconstruction[1] (measured by both KL and loss). This is true for all layers of the model (~2x to ~4.5x increase in KL and loss over baseline) and is not caused by feature suppression/shrinkage. Assuming others replicate, these results suggest the proxy reconstruction objective is behaving pathologically. I am not sure why these errors occur but expect understanding this gap will give us deeper insight into SAEs while also providing an additional metric to guide methodological progress.
Introduction
As the interpretability community allocates more resources and increases reliance on SAEs, it is important to understand the limitation and potential flaws of this method.
SAEs are designed to find a sparse overcomplete feature basis for a model's latent space. This is done by minimizing the joint reconstruction error of the input data and the L1 norm of the intermediate activations (to promote sparsity):
minSAE∥x−SAE(x)∥22+λ∥SAE(x)∥1.However, the true goal is to find a faithful feature decomposition that accurately captures the true causal variables in the model, and reconstruction error and sparsity are only easy-to-optimize proxy objectives. This begs the questions: how good of a proxy objective is this? Do the reconstructed representations faithfully preserve other model behavior? How much are we proxy gaming?
Naively, this training objective defines faithfulness as L2. But, another natural property of a "faithful" reconstruction is that substituting the original activation with the reconstruction should approximately preserve the next-token prediction probabilities. More formally, for a set of tokens T and a model M, let P=M(T) be the model's true next token probabilities. Then let QSAE=M(T|do(x←SAE(x))) be the next token probabilities after intervening on the model by replacing a particular activation x (e.g. a residual stream state or a layer of MLP activations) with the SAE reconstruction of x. The more faithful the reconstruction, the lower the KL divergence between P and Q (denoted as DKL(P||QSAE)) should be.
In this post, I study how DKL(P||QSAE) compares to several natural baselines based on random perturbations of the activation vectors x which preserve some error property of the SAE construction (e.g., having the same l2 reconstruction error or cosine similarity). I find that the KL divergence is significantly higher (2.2x - 4.5x) for the residual stream SAE reconstruction compared to the random perturbations and moderately higher (0.9x-1.7x) for attention out SAEs. This suggests that the SAE reconstruction is not faithful by our definition, as it does not preserve the next token prediction probabilities.
This observation is important because it suggests that SAEs make systematic, rather than random, errors and that continuing to drive down reconstruction error may not actually increase SAE faithfulness. This potentially indicates that current SAEs are missing out on important parts of the learned representations of the model. The good news is that this KL-gap presents a clear target for methodological improvement and a new metric for evaluating SAEs. I intend to explore this in future work.
Intuition: how big a deal is this (KL) difference?
For some intuition, here are several real examples of the top-25 output token probabilities at the end of a prompt when patching in SAE and ϵ-random reconstructions compared to the original model's next-token distribution (note the use of log-probabilities and the KL in the legend).
For additional intuition on KL divergence, see this excellent post.
Experiments and Results
I conduct most of my experiments on Joseph Bloom's GPT2-small residual stream SAEs with 32x expansion factor on 2 million tokens (16k sequences of length 128). I also replicate the basic results on these Attention SAEs.
My code can be found in this branch of a fork of Joseph's library.
Intervention Types
To evaluate the faithfulness of the SAE reconstruction, I consider several types of interventions. Assume that x is the original activation vector and xSAE is the SAE reconstruction of x.
In addition to these different kinds of perturbations, I also consider applying the perturbations to 1) all tokens in the context 2) just a single token. This is to test the hypothesis that the pathology is caused by compounding and correlated errors (since the ϵ-random substitution errors are uncorrelated).
Here is are the average KL differences (across 2M tokens) for each intervention when intervened across all tokens in the context:
There are 3 clusters of error magnitudes:
Given these observations, in the rest of the post I mostly focus on the ϵ-random substitution as the most natural baseline.
Layerwise Intervention Results in More Detail
Next, I consider distributional statistics to get a better sense for how the errors are distributed and how this distribution varies between layers.
This is a histogram of the KL differences for all layers under ϵ-random substitution and the SAE reconstruction (and since I clamp the tails at 1.0 for legibility, I also report the 99.9th percentile). Again the substitution happens for all tokens in the context (and again for a single layer at a time). Note the log scale.
Observe the whole distribution is shifted, rather than a few outliers driving the mean increase.
Here is the same plot but instead of KL divergence, I plot the cross-entropy loss difference (with mean instead of 99.9p). While KL measures deviation from the original distribution, the loss difference measures the degradation in the model's ability to predict the true next token.
Just as with KL, the mean loss increase of the SAE substitution is 2-4x higher compared to the ϵ-random baseline.
Finally, here is a breakdown of the KL differences by position in the context.
Single Token Intervention Results
One possibility is that the KL divergence gap is driven by compounding errors which are correlated in the SAE substitutions but uncorrelated in the baselines (since the noise is isotropic). To test this, I consider the KL divergence when applying the substitution to a single token in the context.
In this experiment I intervene on token 32 in the context and measure the KL divergence for the next 16 tokens (averaged across 16,000 contexts). As before, there is a clear gap between the SAE and ϵ-random substitution, and this gap persists through the following tokens (although the magnitude of the effect depends on how early the layer is).
For clarity, here is the KL bar chart for just token 32 and the following token 33.
While the KL divergence of all interventions is lower overall for the single token intervention, the SAE substitution KL gap is preserved --- it is still always >2x higher than the ϵ-random substitution KL for the present token and the following token (except token 33 layer 11).
How pathological are the errors?
To get additional intuition on how pathological the SAE errors are, I try randomly sampling many ϵ-random vectors for the same token, and compare the KL divergence of the SAE substitution to the distribution of ϵ-random substitutions.
Each subplot below depicts the KL divergence distribution for 500 ϵ-random vectors and the KL of the true SAE substitution for a single token at position 48 in the context. The substitution is only performed for this token and is performed on the layer 6 residual stream. Note the number of standard deviations from the ϵ-random mean labeled in the legend.
What I take from this plot is that the gap has pretty high variance. It is not the case that every SAE substitution is kind-of-bad, but rather there are both many SAE reconstructions that are around the expectation and many reconstructions that are very bad.
When do these errors happen?
Is there some pattern in when the KL gap is large? Previously I showed there to be some relationship with absolute position in the context. As expected, there is also a relationship with reconstruction cosine similarity (a larger error will create a larger gap, all things equal). Because SAE L0 is correlated with reconstruction cosine sim, there is also a small correlation with the number of active features.
However, the strongest correlations I could find were with respect to the KL gap of other layers.
This suggests that some tokens are consistently more difficult for SAEs to faithfully represent. What are these tokens? These are the top 20 by average KL gap for layer 6 (and occur at least 5 times)
Beyond there not being an obvious pattern, notice the variance is quite high. I take this to mean the representational failures are more contextual. While these tokens seem rarer, there is no correlation between token frequency and KL gap.
For additional analysis on reconstruction failures, see this post.
Replication with Attention SAEs
Finally, I run a basic replication on SAEs trained on the concatenated z-vectors of the attention heads of GPT2-small.
While there is still a KL gap between the SAE and ϵ-random substitution, it is smaller (0.9x-1.7x) than the residual stream SAEs, and a larger fraction of the difference is due to the norm change (though it depends on the layer). This was expected since substituting the output of a single layer is a much smaller change than substituting the entire residual stream. Specifically, a residual stream SAE tries to reconstruct the sum of all previous layer outputs, and therefore replacing it is in effect replacing the entire history of the model, in contrast to just updating a single layer output.
Concluding Thoughts
Why is this happening?
I am still not sure yet! My very basic exploratory analysis did not turn up anything obvious. Here are a few hypotheses:
Takeaways
Assuming these findings replicate to other SAEs (please replicate on your own models!):
Future work
I intend to continue working in this direction. The three main work streams are
Acknowledgements
I would like to thank Carl Guo, Janice Yang, Joseph Bloom, and Neel Nanda for feedback on this post. I am also grateful to be supported by an Openphil early career grant.
That is, substituting an SAE reconstructed vector xSAE for the original activation vector x changes the model prediction much more than a random vector xϵ where ∥xSAE−x∥2=∥xϵ−x∥2=ϵ.
E.g., consider the case where both the original model and the SAE substituted model have place probability p on the correct token but their top token probabilities are all different. Loss recovered will imply that the reconstruction is perfect when it is actually quite bad.E.g., consider the case where both the original model and the SAE substituted model have place probability p on the correct token but their top token probabilities are all different. Loss recovered will imply that the reconstruction is perfect when it is actually quite bad.