Posts
Wiki Contributions
Comments
I agree you investigate a bunch of the stuff I mentioned generally somewhere in the paper, but did you do this for refusal-removal in particular? I spent some time on this problem before and noticed that full refusal ablation is hard unless you get the technique/vector right, even though it’s easy to reduce refusal or add in a bunch of extra refusal. That’s why investigating all the technique parameters in the context of refusal in particular is valuable.
FWIW I published this Alignment Forum post on activation steering to bypass refusal (albeit an early variant that reduces coherence too much to be useful) which from what I can tell is the earliest work on linear residual-stream perturbations to modulate refusal in RLHF LLMs.
I think this post is novel compared to both my work and RepE because they:
- Demonstrate full ablation of the refusal behavior with much less effect on coherence / other capabilities compared to normal steering
- Investigate projection thoroughly as an alternative to sweeping over vector magnitudes (rather than just stating that this is possible)
- Find that using harmful/harmless instructions (rather than harmful vs. harmless/refusal responses) to generate a contrast vector is the most effective (whereas other works try one or the other), and also investigate which token position at which to extract the representation
- Find that projecting away the (same, linear) feature at all layers improves upon steering at a single layer, which is different from standard activation steering
- Test on many different models
- Describe a way of turning this into a weight-edit
Edit:
(Want to flag that I strong-disagree-voted with your comment, and am not in the research group—it is not them "dogpiling")
I do agree that RepE should be included in a "related work" section of a paper but generally people should be free to post research updates on LW/AF that don't have a complete thorough lit review / related work section. There are really very many activation-steering-esque papers/blogposts now, including refusal-bypassing-related ones, that all came out around the same time.
I expect if you average over more contrast pairs, like in CAA (https://arxiv.org/abs/2312.06681), more of the spurious features in steering vectors are cancelled out leading to higher quality vectors and greater sparsity in the dictionary feature domain. Did you find this?
We used the same steering vectors, derived from the non fine-tuned model
I think another oversight here was not using the system prompt for this. We used a constant system prompt of “You are a helpful, honest and concise assistant” across all experiments, and in hindsight I think this made the results stranger by using “honesty” in the prompt by default all the time. Instead we could vary this instruction for the comparison to prompting case, and have it empty otherwise. Something I would change in future replications I do.
Yes, this is almost correct. The test task had the A/B question followed by My answer is ( after the end instruction token, and the steering vector was added to every token position after the end instruction token, so to all of My answer is (.
Yes, this is a fair criticism. The prompts were not optimized for reducing or increasing sycophancy and were instead written to just display the behavior in question, like an arbitrarily chosen one-shot prompt from the target distribution (prompts used are here). I think the results here would be more interpretable if the prompts were more carefully chosen, I should re-run this with better prompts.
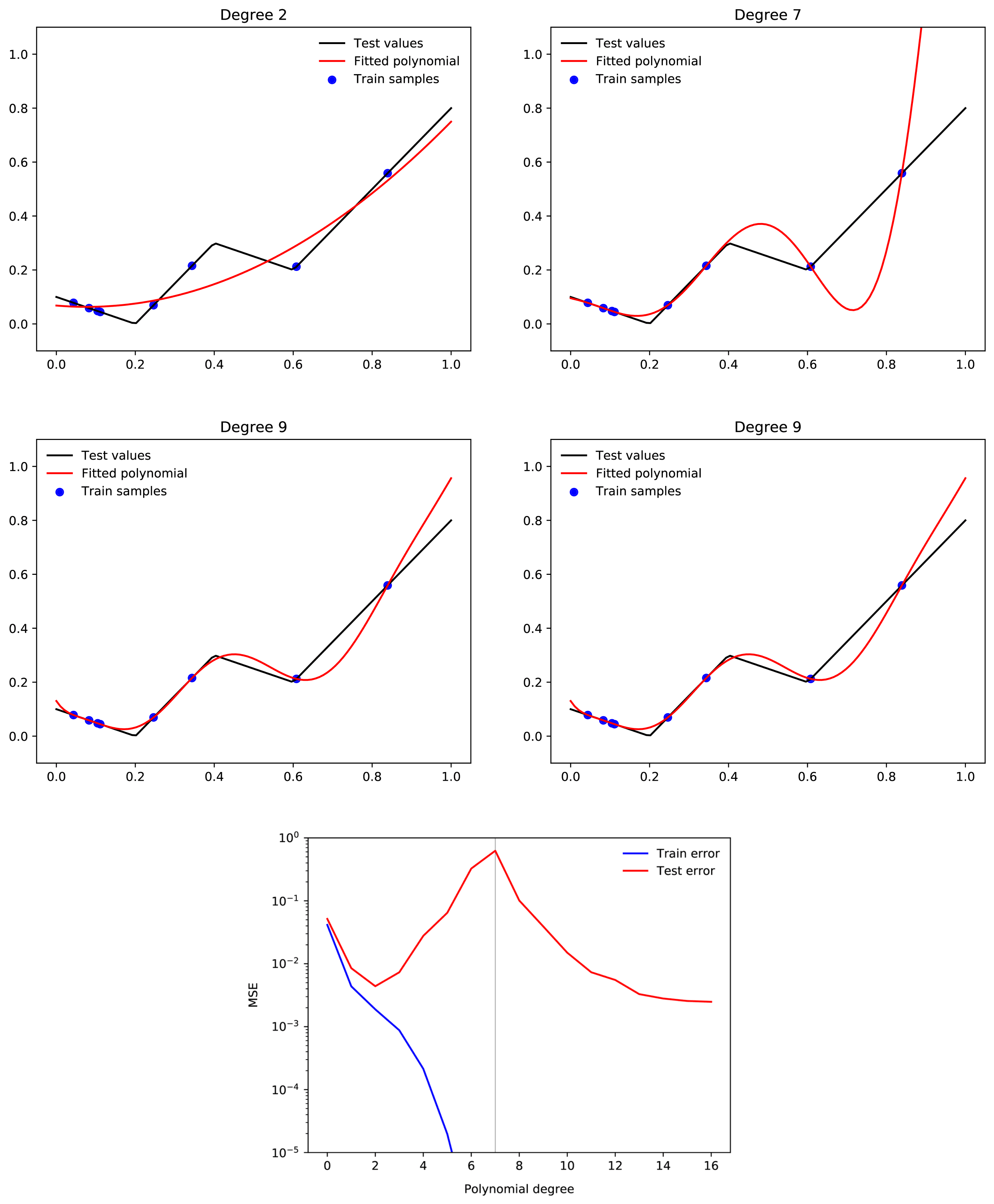
suppose we have a 500,000-degree polynomial, and that we fit this to 50,000 data points. In this case, we have 450,000 degrees of freedom, and we should by default expect to end up with a function which generalises very poorly. But when we train a neural network with 500,000 parameters on 50,000 MNIST images, we end up with a neural network that generalises well. Moreover, adding more parameters to the neural network will typically make generalisation better, whereas adding more parameters to the polynomial is likely to make generalisation worse.
Only tangentially related, but your intuition about polynomial regression is not quite correct. A large range of polynomial regression learning tasks will display double descent where adding more and more higher degree polynomials consistently improves loss past the interpolation threshold.
Examples from here:
Relevant paper
I looked at the paper again and couldn't find anywhere where you do the type of weight-editing this post describes (extracting a representation and then changing the weights without optimization such that they cannot write to that direction).
The LoRRA approach mentioned in RepE finetunes the model to change representations which is different.