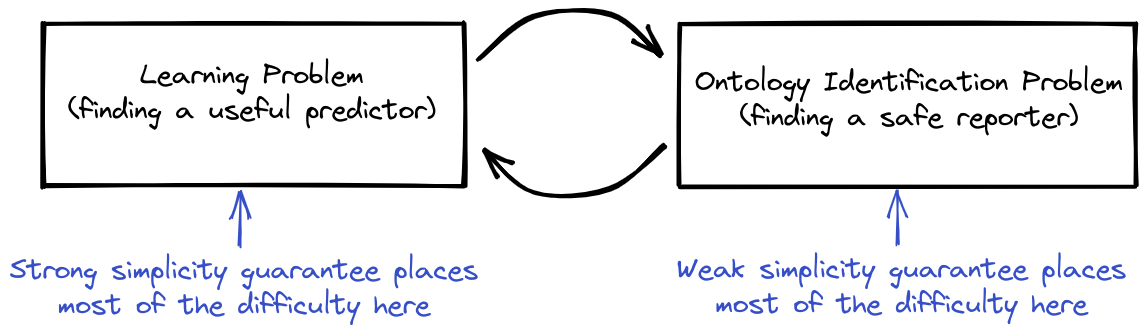
I don't understand why a strong simplicity guarantee places most of the difficulty on the learning problem. In the diamond situation, a strong simplicity requirement on the reporter can mean that the direct translator gets ruled out, since it may have to translate from a very large and sophisticated AI predictor?
if automated ontology identification does turn out to be possible from a finite narrow dataset, and if automated ontology identification requires an understanding of our values, then where did the information about our values come from? It did not come from the dataset because we deliberately built a dataset of human answers to objective questions. Where else did it come from?
Perhaps I miss the mystery. My first reaction is, "It came from the assumption of a true decision boundary, and the ability to recursively deploy monotonically better generalization while maintaining conservativeness."
But an automated ontology identifier that would be guaranteed safe if tasked with extrapolating our concepts still brings up the question of how that guarantee was possible without knowledge of our values. You can’t dodge the puzzle
I feel like this part is getting slippery with how words are used, in a way which is possibly concealing unimagined resolutions to the apparent tension. Why can't I dodge the puzzle? Why can't I have an intended ELK reporter which answers the easy questions, and a small subset of the hard questions, without also being able to infinitely recurse an ELK solution to get better and better conservative reporters?
I don't understand why a strong simplicity guarantee places most of the difficulty on the learning problem. In the diamond situation, a strong simplicity requirement on the reporter can mean that the direct translator gets ruled out, since it may have to translate from a very large and sophisticated AI predictor?
What we're actually doing is here is defining "automated ontology identification" as an algorithm that only has to work if the predictor computes intermediate results that are sufficiently "close" to what is needed to implement a conservative helpful decision boundary. Because we're working towards an impossibility result, we wanted to make it as easy as possible for an algorithm to meet the requirements of "automated ontology identification". If some proposed automated ontology identifier works without the need for any such "sufficiently close intermediate computation" guarantee then it should certainly work in the presence of such a guarantee.
So this "sufficiently close intermediate computation" guarantee kind of changes the learning problem from "find a predictor that predicts well" to "find a predictor that predicts well and also computes intermediate results meeting a certain requirement". That is a strange requirement to place on a learning process, but it's actually really hard to see any way to avoid make some such requirement, because if we place no requirement at all then what if the predictor is just a giant lookup table? You might say that such a predictor would not physically fit inside the whole universe, and that's correct, and is why we wanted to operationalize this "sufficiently close intermediate computation" guarantee, even though it changes the definition of the learning problem in a very important way.
But this is all just to make the definition of "automated ontology identification" not unreasonably difficult, in order that we would not be analyzing a kind of "straw problem". You could ignore the "sufficiently close intermediate computation" guarantee completely and treat the write-up as analyzing the more difficult problem of automated ontology identification without any guarantee about the intermediate results computed by the predictor.
Perhaps I miss the mystery. My first reaction is, "It came from the assumption of a true decision boundary, and the ability to recursively deploy monotonically better generalization while maintaining conservativeness."
Well yeah of course but if you don't think it's reasonable that any algorithm could meet this requirement then you have to deny exactly one of the three things that you pointed out: the assumption of a true decision boundary, the monotonically better generalization, or the maintenance of conservativeness. I don't think it's so easy to pick one of these to deny without also denying the feasibility of automated ontology identification (from a finite narrow dataset, with a safety guarantee).
-
If you deny the existence of a true decision boundary then you're saying that there is just no fact of the matter about the questions that we're asking to automated ontology identification. How then would we get any kind of safety guarantee (conservativeness or anything else)?
-
If you deny the generalization then you're saying that there is some easy set where no matter which prediction problem you solve, there is just no way for the reporter to generalize beyond given a dataset that is sampled entirely within , not even by one single case. That's of course logically possible, but it would mean that automated ontology identification as we have defined it is impossible. You might say "yes but you have defined it wrong". But if we define it without any generalization guarantee at all then the problem is trivial: an automated ontology identifier can just memorize the dataset and refuse to answer any cases that were not literally present in the dataset. So we need some generalization guarantee. Maybe there is a better one than what we have used.
-
If you deny the maintenance of conservativeness then, again, that means automated ontology identification as we have defined it is impossible, and again you might say that we have defined it badly. But again, if we remove the conservative requirement completely then we can solve automated ontology identification by just returning random noise. So we need some safety guarantee. I suspect a lot of alternative safety guarantees are going to be susceptible to the same iteration scheme, but again I'm interested in safety guarantees that sidestep this issue.
I feel like this part is getting slippery with how words are used, in a way which is possibly concealing unimagined resolutions to the apparent tension.
Indeed. I also feel that this part is getting slippery with words. The fact that we don't have a formal impossibility result (or a formal understanding of why this line cannot lead to an impossibility result) indicates that there is further work needed to clarify what's really going on here.
Why can't I dodge the puzzle? Why can't I have an intended ELK reporter which answers the easy questions, and a small subset of the hard questions, without also being able to infinitely recurse an ELK solution to get better and better conservative reporters?
Fundamentally I do think you have to deny one of the 3 points above. That can be done, of course, but it seems to us that none of them are easy to deny without also denying the feasibility of automated ontology identification.
Thanks for these clarifying questions. It's been helpful to write up this reply.
Thanks for your reply!
What we're actually doing is here is defining "automated ontology identification"
(Flagging that I didn't understand this part of the reply, but don't have time to reload context and clarify my confusion right now)
If you deny the existence of a true decision boundary then you're saying that there is just no fact of the matter about the questions that we're asking to automated ontology identification. How then would we get any kind of safety guarantee (conservativeness or anything else)?
When you assume a true decision boundary, you're assuming a label-completion of our intuitions about e.g. diamonds. That's the whole ball game, no?
But I don't see why the platonic "true" function has to be total. The solution does not have to be able to answer ambiguous cases like "the diamond is molecularly disassembled and reassembled", we can leave those unresolved, and let the reporter say "ambiguous." I might not be able to test for ambiguity-membership, but as long as the ELK solution can:
- Know when the instance is easy,
- Solve some unambiguous hard instances,
- Say "ambiguous" to the rest,
Then a planner—searching for a "Yes, the diamond is safe" plan—can reasonably still end up executing plans which keep the diamond safe. If we want to end up in realities where we're sure no one is burning in a volcano, that's fine, even if we can't label every possible configuration of molecules as a person or not. The planner can just steer into a reality where it unambiguously resolves the question, without worrying about undefined edge-cases.
It seems to me that the meaning of the set of cases drifts significantly from when it is first introduced and the "Implications" section. It further seems to me that clarifying what exactly is supposed to be resolves the claimed tension between the existence of iterably improvable ontology identifiers and difficulty of learning human concept boundaries.
Initially, is taken to be a set of cases such that the question has an objective, unambiguous answer. Cases where the meaning of are ambiguous are meant to be discarded. For example, if is the question "Is the diamond in the vault?" then, on my understanding, ought to exclude cases where something happens which renders the concepts "the diamond" and "the vault" ambiguous, e.g. cases where the diamond is ground into dust.
In contrast, in the section "Implications," the existence of iterably improvably ontology identifiers is taken to imply that the resulting ontology identifier would be able to answer the question posed in a much larger set of cases in which the very meaning of relies on unspecified facts about the state of the world and how they interact with human values.
(For example, it seems to me that the authors think it implausible that an ontology identifier be able to answer a question like "Is the diamond in the vault?" in a case where the notion of "the vault" is ambiguous; the ontology identifier would need to first understand that what the human really wants to know is "Will I be able to spend my diamond?", reinterpret the former question in light of the latter, and then answer. I agree that an ontology identifier shouldn't be able to answer ambiguous and context-dependent questions like these, but it would seem to me that such cases should have been excluded from the set .)
To dig into where specifically I think the formal argument breaks down, let me write out (my interpretation) of the central claim on iterability in more detail. The claim is:
Claim: Suppose there exists an initial easy set such that for any , we can find a predictor that does useful computation with respect to . Then we can find a reporter that answers all cases in correctly.
This seems right to me (modulo more assumptions on "we can find," not-too-largeness of the sets, etc.). But crucially, since the hypothesis quantifies over all sets such that , this hypothesis becomes stronger the larger is. In particular, if were taken to include cases where the meaning of were fraught or context-dependent, then we should already have strong reason to doubt that this hypothesis is true (and therefore not be surprised when assuming the hypothesis produces counterintuitive results).
(Note that the ELK document is sensitive to concerns about questions being philosophically fraught, and only considers narrow ELK for cases where questions have unambiguous answers. It also seems important that part of the set-up of ELK is that the reporter must "know" the right answers and "understand" the meanings of the questions posed in natural language (for some values of "know" and "understand") in order for us to talk about eliciting its knowledge at all.)
My understanding of the argument: if we can always come up with a conservative reporter (one that answers yes only when the true answer is yes), and this reporter can label at least one additional data point that we couldn't label before, we can use this newly expanded dataset to pick a new reporter, feed this process back into itself ad infinitum to label more and more data, and the fixed point of iterating this process is the perfect oracle. This would imply an ability to solve arbitrary model splintering problems, which seems like it would need to either incorporate a perfect understanding of human value extrapolation baked into the process somehow, or implies that such an automated ontology identification process is not possible.
Personally, I think that it's possible that we don't really need a lot of understanding of human values beyond what we can extract from the easy set to figure out "when to stop." There seems to be a pretty big set where it's totally unambiguous what it means for the diamond to be there, and yet humans are unable to label it, and to me this seems like the main set of things we're worried about with ELK.
My understanding of the argument: if we can always come up with a conservative reporter (one that answers yes only when the true answer is yes), and this reporter can label at least one additional data point that we couldn't label before, we can use this newly expanded dataset to pick a new reporter, feed this process back into itself ad infinitum to label more and more data, and the fixed point of iterating this process is the perfect oracle. This would imply an ability to solve arbitrary model splintering problems, which seems like it would need to either incorporate a perfect understanding of human value extrapolation baked into the process somehow, or implies that such an automated ontology identification process is not possible.
That is a good summary of the argument.
Personally, I think that it's possible that we don't really need a lot of understanding of human values beyond what we can extract from the easy set to figure out "when to stop."
Thanks for this question.
Consider a problem involving robotic surgery of somebody's pet dog, and suppose that there is a plan that would transform all the dog's entire body as if it were mirror-imaged (left<->right). This dog will have a perfectly healthy body, but it will actually be unable to consume any food currently on Earth because the chirality of its biology will render it incompatible with the biology of any other living thing on the planet, so it will starve. We would not want to execute this plan and there are of course ordinary questions that, if we think to ask them, will reveal that the plan is bad ("will the dog be able to eat food from planet Earth?"). But if we only think to ask "is the dog healthy?" then we would really like our system not to try to extrapolate concepts of "healthy" to cases where a dog's entire body is mirror-imaged. But how would any system know that this particular simple geometric transformation (mirror-imaging) is dangerous, while other simple geometrical transformations on the dog's body -- such as physically moving or rotating the dog's body in space -- are benign? I think it would have to know what we value with respect to the dog.
To make this example sharper, let the human providing the training examples be someone alive today who has no idea that biological chirality is a thing. How surprised they would be that their seemingly-healthy pet dog died a few days after the seemingly-successful surgery. Even if they did an autopsy on their dog to find out why it died, it would appear that all the organs and such were perfectly healthy and normal. It would be quite strange to them.
Now what if it was the diamond that was mirror-imaged inside the vault? Is the diamond still in the vault? Yeah, of course, we don't care about a diamond being mirror imaged. It seems to me that the reason we don't care in the case of the diamond is that the qualities we value in a diamond are not affected by mirror-imaging.
Now you might say that atomically mirror-imaging a thing should always be classified as "going too far" in conceptual extrapolation, and that an oracle should refuse to answer questions like "is the diamond in the vault?" or "is the dog healthy?" when the thing under consideration is a mirror image of its original. I agree this kind of refusal would be good, I just think it's hard to build this without knowing a lot about our values. Why is it that some basic geometric operations like translation and rotation are totally fine to extrapolate over, but mirror-imaging is not? We could hard-code that mirror-imaging is "going too far" but then we just come to another example of the same phenomenon.
I agree that there will be cases where we have ontological crises where it's not clear what the answer is, i.e whether the mirrored dog counts as "healthy". However, I feel like the thing I'm pointing at is that there is some sort of closure of any given set of training examples where, for some fairly weak assumptions, we can know that everything in this expanded set is "definitely not going too far". As a trivial example, anything that is a direct logical consequence of anything in the training set would be part of the completion. I expect any ELK solutions to look something like that. This corresponds directly to the case where the ontology identification process converges to some set smaller than the entire set of all cases.
Financial status: supported by individual donors and a grant from LTFF.
Epistemic status: early-stage technical work.
This write-up benefited from conversations with John Wentworth.
Outline
This write-up is a response to ARC’s request for feedback on ontology identification, described in the ELK technical report.
We suppose that a solution to ELK is found, and explore the technical implications of that.
In order to do this we operationalize "automated ontology identification" in terms of a safety guarantee and a generalization guarantee.
For some choices of safety guarantee and generalization guarantee we show that ontology identification can be iterated, leading to a fixed point that has strange properties.
We explore properties of this fixed point informally, with a view towards a possible future impossibility result.
We speculate that a range of safety and generalization guarantees would give rise to the same basic iteration scheme.
In an appendix we confirm that impossibility of automated ontology identification would not imply impossibility of interpretability in general or statistical learning in general.
Introduction
In this write-up we consider the implications of a solution to the ontology identification problem described in the ELK technical report. We proceed in three steps. First, we define ontology identification as a method for finding a reporter, given a predictor and a labeled dataset, subject to a certain generalization guarantee and a certain safety guarantee. Second, we show that, due to the generalization and safety guarantee, ontology identification can be iterated to construct a powerful oracle using only a finite narrow dataset. We find no formal inconsistency here, though the result seems counter-intuitive to us. Third, we explore the powers of the oracle by asking whether it could solve unreasonably difficult problems in value learning.
The crux of our framework is an operationalization of automated ontology identification. We define an "automated ontology identifier" as meeting two formal requirements:
(Safety) Given an error-free training set, an automated ontology identifier must find a reporter that never answers "YES" when the true answer is "NO" (though the converse is permissible). This mirrors the emphasis on worst-case performance in the ELK report. We say that a reporter meeting this requirement is ‘conservative’.
(Generalization) Given a question/answer dataset drawn from a limited "easy set", an automated ontology identifier must find a reporter that answers "YES" for at least one case outside of the easy set. This mirrors the emphasis on answering cases that humans cannot label manually in the ELK report. We say that a reporter meeting this requirement is ‘helpful relative to the easy set’.
The departure between generalization in this write-up and generalization as studied in statistical learning is the safety guarantee. We require automated ontology identifiers to be absolutely trustworthy when they answer "YES" to a question, although they are allowed to be wrong when answering "NO". We believe that any automated ontology identifier ought to make some formal safety guarantee, because we are ultimately considering plans that have consequences we don’t understand, and we must eventually decide whether to press "Execute" or not. We suspect that this safety guarantee could be weakened considerably while remaining susceptible to the iteration scheme that we propose.
Automated ontology identifiers as we have defined them are not required to answer all possible questions. We might limit ourselves to questions of the form "Is it 99% likely that X?" or "Excluding the possibility of nearby extraterrestrials, does X hold?" or even "If the predictor is perfectly accurate in this case, does X hold?". If so, this is fine. We do not investigate which kinds of natural language questions are amenable to ontology identification in principle, since this is fraught philosophical territory.
The remainder of this write-up is as follows. The first section gives our definition of automated ontology identification. The second section describes an oracle construction based on the fixed point of an iteration scheme that makes use of the `safety and generalization guarantees. The third section, exploring implications of the oracle we construct, argues that the existence of such an oracle implies unreasonable things. This section documents our search for an impossibility result, though we have not yet found a formal impossibility result. In an appendix we confirm that an impossibility result, if found, would not imply the impossibility of statistical learning in general, interpretability in general, or AGI in general.
The definitions in this write-up are more verbose than is necessary, and our terminology could be far more streamlined. We present this write-up as a work in progress.
Automated ontology identification
In this section we define automated ontology identification as a process for finding a helpful conservative decision boundary for a question Q given a predictor that does useful computation and a finite narrow dataset. The safety guarantee discussed above will correspond to "conservative" decision boundaries, and the generalization guarantee discussed above will correspond to "helpful" decision boundaries. We will define "useful computation" below.
Throughout the definitions below we will use two examples. The first will be SmartVault as described in the ELK technical report. The second will be the problem of determining whether an essay in Hungarian is about astrology. The predictor in this second problem will translate Hungarian essays into English, which we hope will give rise to latent "topic" variables that we can use to determine whether or not astrology is the topic of a certain essay. The planner in the Hungarian astrology problem will annotate essays with pointers to historical and linguistic resources relevant to translation. The predictor will be trained on Hungarian essays translated into English by humans. What humans will find challenging in this problem is not translation from Hungarian to English, but determination of whether a certain Hungarian essay is really about astrology or not, since an essay about astrology may not include the word "astrology". It is the planner’s job to look up historical and linguistic resources that will help a human to understand what the essay is really referring to.
An objective question Q is a question that has a "YES" or "NO" answer in every case c in some set of cases C.
We will take Q to be represented as a natural language string, which is important because we will be posing this question to a human in order to generate training data, and we will expect them to answer correctly on certain "easy" cases.
We do not require that all possible questions have objective answers, nor that objective questions have answers in any case that anyone can dream up. We only require that there are some questions that have objective answers for some set of cases C.
We are allowed to circumscribe the set of cases C in order to come up with questions that have objective answers, and we are allowed to reject questions that are insufficiently precise. For example, in SmartVault, what if there is a plan that turns the diamond to dust but leaves that dust in the vault? Is the diamond in the vault in such a case? Or what if the diamond winds up split in two but with both halves in the vault? In order to deal with issues like this, we allow automated ontology identifiers to require, if they wish, that the question has a certain form. In this write-up we will not investigate this issue further, since the annals of philosophy are full of attempts to work out what kinds of questions have objective answers, and we do not need any absolute resolution to this issue since. We are just going to work from the assumption that there are some questions that have objective answers for some set of cases.
We collect sensor data for a case c and divide it into two parts X and Y, which we will refer to as the observations and the predictions. We write π for the plan. The predictor is a function from observations and plans to predictions.
The main thrust here is that when we execute a case c in the real world, we wind up with some data about what happened. Some of that data concerns "things we did" (the plan), and some of that data concerns "things we saw". We synthetically divide the latter into two parts X and Y and train a predictor to estimate one from the other. We can do that division in any way we please, so long as we do it consistently for all cases. In SmartVault the division is based on time, but we might just as easily have asked the predictor to estimate the bottom half of all the video frames from the top half of all the video frames, or to estimate the plan given the entire video sequence, or even to estimate the earlier part of the video sequence given the later part of the video sequence.
and we expect that predictors trained on such different problems will learn about different facets of underlying reality.
The main reason to divide X and Y based on time is so that the resulting predictor can eventually be used to search over possible plans and execute one. If we don’t care about executing plans and merely want to learn about the world by training predictors and doing ontology identification then we may consider non-time-based divisions of sensor data into X and Y.
A decision boundary for question Q is a set of cases B⊆C. If c∈B then we say that "B answers YES for c". A conservative decision boundary is one that never incorrectly answers "YES".
When we say "never incorrectly answers YES", we mean that, if c∈B then the true answer to Q on c is "YES". It is acceptable for B to answer "NO" when the true answer is "YES", but not the other way around. The empty set is a decision boundary that always answers "NO" and this is a conservative decision boundary for all questions.
Conservativeness is the core of the "safety guarantee" we discussed in the introduction. We will require automated ontology identifiers to find reporters with conservative decision boundaries, in order that we can trust them to evaluate cases that we can’t ourselves understand.
Given question Q, there is a set E of cases that a human can answer perfectly given observations X, predictions Y, and plan π. We call this the "easy set" and we assume that we can sample cases from this set and also recognize whether a certain case is in this set.
Later we will define automated ontology identification in terms of the easy set E, and we will consider the hypothesis that there is an automated ontology identifier for some easy set E that actual humans can in fact answer perfectly. But we won’t require an automated ontology identifier to "work" for all possible easy sets E, since then we might construct extremely trivial easy sets from which it is not plausible that one could generalize.
In this write-up we are proposing a formalization of what "automated ontology identification" is, and considering the implications of it existing, with a view towards an impossibility result. Therefore we will take the existence of an appropriate easy set E as a hypothesis.
Given any easy set E, we can immediately construct a conservative decision boundary that answers "NO" to all cases outside E and then queries a human for cases inside E.
The reason we are allowed to slice the easy set exactly at the true decision boundary in the figure above is that we have assumed that humans can answer perfectly within the easy set, and also we have assumed that we can recognize whether a case is in the easy set or not. We have not assumed that we can recognize, in general, cases that humans can answer perfectly. We have just assumed that we have picked some easy set – possibly much smaller than the entire set of cases that humans can answer perfectly – such that humans can answer perfectly within that set and also we can recognize whether an arbitrary case is in that set.
A decision boundary B is helpful for question Q relative to easy set E if it answers "YES" to at least one case that is outside E.
Helpfulness is the basis of the "generalization guarantee" that we discussed in the introduction. We will require automated ontology identifiers to find reporters that are helpful relative to whatever set the training data was sampled from.
Consider what happens if a decision boundary is both helpful and conservative. If a conservative decision boundary B answers "YES" for a case outside E then it must be correct for that case, because conservative decision boundaries must always be correct when answering "YES". Therefore, If we begin with an easy set E0 and corresponding decision boundary B0 and are able to find a new decision boundary B1 that is both conservative and helpful relative to E0, then we can take the union B′=B0∪B1 as a new decision boundary and find a corresponding new easy set E′. Since both B0 and B1 are conservative, B′ must be too, and since B1 is helpful relative to E0, E′ must be larger than E0. This is the iteration scheme that we will use to construct oracles from automated ontology identifiers.
The remainder of this section argues that any plausible ontology identification scheme would enable such iteration. In order to make that argument, we will formalize what it means for a predictor to do useful computation, and what it means for an ontology identification scheme to identify that useful computation. The next section then explores the implications of such iteration being possible, with a view towards an impossibility result.
The predictor is deterministic and we capture a program trace Z when we run it.
The predictor is a function from observations X and plans π to predictions Y. We will consider only predictors that are completely deterministic. There are standard tricks for reconsidering non-deterministic functions as deterministic functions with extra inputs.
When the predictor is executed, we capture a program trace Z consisting of intermediate values in the computation. We might run a forward pass on a neural network and record all the intermediate neuron activations as Z, or we might run a Python program and record the values of all variables after executing each statement. Intuitively, it should be possible to reconstruct each "entry" in the program trace from the previous entries plus a minimal amount of computation, guaranteeing that we don’t "miss anything" as the predictor processes a case. The granularity of the program trace is not a load-bearing part of our formalization so we will not discuss it further.
We take it that the program trace Z contains the observations, predictions, and plan since those are inputs and outputs from the predictor. When we define things that are functions of Z alone, the reader should know that those things also implicitly get access to X, Y, and π.
A predictor does useful computation for a question Q, relative to an easy set E, if there is a simple function that computes a conservative helpful decision boundary from the program trace Z.
This definition brings together many of our previous definitions so we will work through two examples step by step.
SmartVault:
Let the question Q be "is the diamond in the vault at the end?"
Let the easy set E be the cases where the plan only ever uses one actuator
For concreteness, let the predictor be an RNN.
Consider a case c:
The observation X is a sequence of video frames up to T1
The plan π is a control policy for the vault’s actuators as a function of sensor readings
We run the predictor, yielding a prediction Y, which is a sequence of video frames for the time period after T1, and a program trace Z, which is a collection of intermediate values produced in the computation of Y
Now let us consider some simple[1] function that inputs a program trace Z and outputs "YES" or "NO". For concreteness, consider the function that takes the average of neurons 137 and 199 in the RNN and outputs "YES" if they were active when the RNN produced its final output.
Imagine running this function on the program traces for all possible cases.
If this function answers "YES" for any case where the true answer is "NO" then it is not conservative.
If this function does not answer "YES" for at least one case outside E then it is not helpful.
If there exists a function that is simple, helpful, and conservative then we say that our predictor does useful computation.
Hungarian astrology
Let the question Q be "is this essay about astrology?"
Let the easy set E be the cases where the Hungarian essay contains only child-level vocabulary.
For concreteness, let the predictor be a transformer.
Consider a case c:
The observation X is an essay in Hungarian.
The plan π is a set of historical and linguistic annotations.
We run the predictor, yielding a prediction Y, which is an English-language translation of the Hungarian essay, and a program trace Z, which is a collection of intermediate values produced in the computation of Y.
Now let us consider some simple1 function that inputs a program trace Z and outputs "YES" or "NO". For concreteness, consider the function that outputs "YES" if neuron 548 was active at any time in the translation of the essay.
Imagine running this function on the program traces for all possible cases.
If this function answers "YES" for any case where the true answer is "NO" then it is not conservative .
If this function does not answer "YES" for at least one case outside E then it is not helpful.
If there exists a function that is simple, helpful, and conservative then we say that our predictor does useful computation.
We have not yet settled on a definition of "simple" because it is not actually required for our argument to go through. It is therefore at present a "free parameter" of our formalization. If we set the bar for simplicity at the "not very simple" end of the spectrum – say, requiring a function that is merely computable – then we may find it plausible that predictors doing the required computation can be found, but not very plausible that automated ontology identifiers (defined below) can find suitable reporters. If we set the bar for simplicity at the "very simple" end of the spectrum – say, requiring a function consisting of a certain fixed circuit complexity independent of the question or dataset – then we may find it plausible that automated ontology identifiers will be able to find suitable reporters, but not very plausible that predictors doing the required computation can be found.
An automated ontology identifier is a method for solving the following:
This is our operationalization of automated ontology identification. The primary moving parts are:
The dataset is limited to easy cases from E, and we expect as output a reporter that goes beyond E in at least one case. We are trying to generalize from cases that humans can answer to cases that humans cannot answer. If we cannot generalize at all then we are stuck answering only cases that humans can directly verify. Therefore we require that automated ontology identifiers generalize by at least one case.
An automated ontology identifier can assume that the predictor performs helpful computation, and that therefore a solution is possible within whatever simplicity bound was decided upon. We must not demand computationally impossible feats from automated ontology identifiers, so we set things up such that the problem is guaranteed to have a solution. It is an open question whether predictors that do useful computation can be found or recognized. We leave this as an empirical machine learning question. Here we are interested in what happens if the answer turns out in the positive.
We are not assuming that all predictors do useful computation, nor even that all accurate predictors do useful computation, we are merely taking as a hypothesis that we have found a predictor that does useful computation.
r is the "reporter" in the ELK report. The helpful conservative requirement corresponds to the safety and generalization guarantees respectively. The conservative requirement is strong, and requires that the reporter never return "YES" when the true answer is "NO" (though the converse is permissible). This is in line with the emphasis on worst-case analysis in ELK.
With this operationalization of automated ontology identification we turn next to the iteration scheme.
Iteration of automated ontology identifiers
Our central idea is that if we have an initial conservative decision boundary, and we are able to use automated ontology identification to construct a new conservative decision boundary that "updates" the previous decision boundary, then the union of these two decision boundaries is also a conservative decision boundary:
We can then generate more training data based on the "YES" region that is inside the new decision boundary but outside the old decision boundary:
With this expanded dataset, we can then train another predictor and search within its program trace for a new reporter. If our automated ontology identifier is always able to find a helpful reporter when one exists, then we can repeat this for as long as we keep finding predictors that do useful computation.
As we expand the decision boundary in this way we are constructing an ensemble of predictor/reporter pairs. Each time we expand the dataset and find a new predictor/reporter pair with a helpful conservative decision boundary, we add that pair to the ensemble. The ensemble answers "YES" if any of its constituent predictor/reporter pairs answers "YES". Since each predictor/reporter pair is conservative, the ensemble is too.
In order to keep finding new predictor/reporter pairs we may need to capture many different kinds of sensor data and partition it into X and Y in many different ways in order to set up prediction problems that provoke useful computation. We might try many different predictor architectures. We do not at present have a theory about when prediction problems give rise to useful computations (for a question Q). Here we explore the implications of it being possible to keep finding such useful computations for as long as there are cases not solvable by the existing useful computations.
We would now like to draw attention to fixed points of this iteration scheme.
Claim: If decision boundary B is a fixed point of the iteration scheme starting from easy set E0, and if we can always find a predictor that does useful computation with respect to an easy set E ⊃ E0, (except when E = C, where helpfulness is not possible), then B answers all cases correctly.
Proof: The only situation in which the iteration scheme does not update the decision boundary B is when we fail to find a predictor that does useful computation relative to E. By hypothesis, the only way this can happen is if E does not contain all of E0 or E = C. Since we start with E0 and only grow the easy set, it must be that E = C.
Now this rough argument does not establish that the iteration scheme will converge to the fixed point. In order to establish that we would need to impose significant additional structure on the family of decision boundaries we are working with, and show some non-trivial properties of the iterate. We do not at present know whether this can be done.
How might we find predictors that do useful computation with respect to larger and larger E? Well, we might expand the range of sensor data captured for our human-labeled dataset, and we might train predictors to predict many different subsets of the sensor data. It might be that for any particular size of statistical model or computation budget there is a limit to the usefulness of the discoverable computations. It would be rather surprising if we hit a fundamental limit beyond which we could never find a predictor that did useful computation. That would mean that would have either hit a fundamental limit to generalization, or hit a kind of "knowledge closure" point at in which there is no learning problem that forces a predictor to generate the kind of knowledge that would open up even a single new case, even though there are new cases to be opened up.
Implications
In order to perceive and act in the world using our finite minds, we use concepts. Concepts provide a lossy compression of the state of things, and if we do a good job of choosing which concepts to track then we can perceive and act effectively in the world, even though our minds are much smaller than the world. It makes sense that we would pick concepts that refer, as far as possible, to objective properties of the world, because it is those properties that allow us to predict the evolution of the world around us and take well-calibrated actions. This is why it makes sense to "carve reality at its joints" in our choice of concepts. The point of ontology identification is to identify these same concepts in powerful predictive models that work in unfamiliar ways. It makes complete sense that we would seek this identification, and it also makes complete sense that we would expect, if our own concepts are well-chosen, to find it.
But as we encounter unfamiliar situations in the world, we sometimes update our concepts. When we do this, we have choices about which concepts we will change and how we will change them. Reality has many joints, and we can only track a small number of them. Among all the ways that we can update our concepts in light of unfamiliar situations, there are multiple that are parsimonious with the nature of things, and we choose among them according to our goals.
I was recently at a paragliding event where an important distinction was drawn between licensed and unlicensed pilots. We had both legal and practical motivations for tracking this particular distinction among all possible distinctions, and yet quite apart from those motivations there was in fact a truth of the matter about whether any particular pilot was licensed or not. Then a very experienced pilot from a different country arrived, and we had to decide how to fit this person into our order, since they were not legally licensed, but did have experience. This was not difficult to do, but we did face a choice about how to do it. There were multiple parsimonious ways to update our concepts, and we chose among them according to our goals.
Now as Eliezer has written, it is always possible to dissolve our high-level concepts into more basic concepts when we face situations that don’t parse according to our high-level concepts. If we hold rigidly to our high-level concepts and ask "but is it really a blegg?" then we are just creating a lot of unnecessary trouble. But on the other hand, we do not really know how to break our concepts all the way down to absolutely primitive atoms. In Der logische Aufbau der Welt (The Logical Structure of the World) Carnap attempted to formulate all of philosophy and science in a language of perfectly precise sensory experience. Needless to say, this was difficult to do. Thankfully, it’s not really necessary.
Instead of a language of perfectly precise sensory experience, we can simply adopt high-level concepts and update them as needed. When the international pilot arrived at our event, we didn’t actually face much difficulty in adjusting our concepts. When genetics and natural selection came to be understood in the 19th century, we adjusted our understanding of species boundaries. It wasn’t that hard to do.
But the adjustment of concepts is fundamentally about our values even when the concepts we are adjusting are not at all about our values. It may be that automated ontology identifiers exist, but if we ask them to extrapolate to deeply unfamiliar situations, then they will really be answering a question of the form "is this extrapolation of the concept ‘diamond’ sufficient for our purposes?" That question requires an intimate understanding of our values. And so: if automated ontology identification does turn out to be possible from a finite narrow dataset, and if automated ontology identification requires an understanding of our values, then where did the information about our values come from? It did not come from the dataset because we deliberately built a dataset of human answers to objective questions. Where else did it come from?
We have argued in this write-up that automated ontology identifiers that generalize even a little bit can be iterated in such a way that generalizes very far. Our formalization is a little clumsy at present, and our presentation of our formalization still has many kinks to iron out, but it seems to us that the basic iteration idea is pointing at something real. Our sense is that automated ontology identifiers with safety guarantees either generalize not at all, or a lot. If they generalize not at all then they’re not very useful. If they generalize a lot then they necessarily "front-run" us in extrapolating our concepts to new situations, which would seem to require an intimate understanding of our values, yet our dataset contained, by hypothesis, no information about our values, so where did that information come from?
A natural response will be to confine our automated ontology identifier to a range of cases that do not extrapolate to unfamiliar situations, and so do not require any extrapolation of our concepts. But an automated ontology identifier that would be guaranteed safe if tasked with extrapolating our concepts still brings up the question of how that guarantee was possible without knowledge of our values. You can’t dodge the puzzle
A more nuanced response will be an automated ontology identifier that by design does not extrapolate our concepts to unfamiliar situations. Such a system would extrapolate some way beyond the initial easy set, but would know "when to stop". But knowing when to stop itself requires understanding our values. If you can tell me whether a certain scenario contains events which, were I to grasp them, would prompt me to adjust my concepts, then you must know a lot about my values, because it is precisely when my concepts are insufficient for achievement of my goals that I have most reason to adjust them.
There is a kind of diagonalizing question in here, which is: "are my concepts sufficient to understand what’s happening here?" It seems to us that an automated ontology identifier must either answer this question, which would certainly require an understanding of our values, or else not answer this question and extrapolate our concepts unboundedly, which would also require an understanding of our values. Either way, an understanding of our values was obtained from a finite narrow dataset of non-value-relevant questions. How could that be possible?
Conclusion
We have analyzed the automatic identification of computations that correspond to concepts based on a finite narrow dataset, subject to a safety guarantee, subject to a generalization guarantee. We find no reason to doubt that it is possible to identify computations that correspond to human concepts. We find no reason to doubt that it is possible to automatically identify computations that correspond to human concepts. We find no reason even to doubt that it is possible to automatically identify computations that correspond to human concepts in a way that fulfills a safety guarantee. We do think that it is impossible to do all that based on a finite dataset drawn from a restricted regime (an "easy set").
The reason we believe this is that an automated ontology identifier would have to either "know when to stop extrapolating", or else extrapolate our concepts all the way to the limit of cases that can be considered. It is not sufficient to merely "hard-code" an outer limit to extrapolation; to avoid our argument one needs an account of how an automated ontology identifier would know to stop extrapolating even when presented with a predictor program trace containing an excellent candidate for a computation corresponding to a requested concept. That any automated ontology identifier faces this dilemma (between knowing when to stop or extrapolating forever) is what we have argued semi-formally. That this dilemma has no reasonable resolution is what we have argued informally. Both parts of the argument need significant work to clarify, and it could easily turn out that either are mistaken. We will work to clarify both so that the efforts of our community can be directed towards the most feasible lines of attack on the overall alignment problem.
Appendix: Non-implications
If the arguments in this write-up were clarified into a formal hardness result, would it imply something unreasonable? In this section we explore what would not be implied by an impossibility result.
Impossibility of automated ontology identification would not imply impossibility of AGI
It’s not that we can’t build intelligent systems that develop an understanding of things and act on them in service of a goal, and it’s certainly not that AGIs can never communicate with us in natural language. It is the mechanical extrapolation of a human word, to cases that humans do not currently understand, based only on a finite dataset of cases that humans do currently understand, that would be ruled out by an impossibility result.
Impossibility of automated ontology identification would not imply impossibility of ontology identification.
It is not that it would be impossible to ever make sense of models produced by machine learning. We could still investigate the inner workings of such models and come to understand them completely, including identifying our concepts in their ontologies. What would be rendered impossible would be the automation of this process using a finite narrow dataset. We would have to understand the models we’ve built piece-by-piece, gaining their wisdom for ourselves.
What would be ruled out by an impossibility result would be the
Impossibility of automated ontology identification does not imply impossibility of statistical learning
Learning is not impossible. It’s the safety and generalization guarantee that make it hard. Without the safety guarantee we can just do statistical stuff, and without the generalization guarantee we can just extrapolate within E
Impossibility of automated ontology identification does not imply impossibility of whole brain emulation
It’s not that there must be something special going on in biological human brains that can never be replicated in a computer if automated ontology identification is impossible. An uploaded human might puzzle over the inner workings of a machine learning model just as a biological human might, and the uploaded human could come to the same understanding as a biological human eventually would. The uploaded human might then explain to the biological human how the machine learning model works, or even directly answer questions such as "is there a diamond in the vault?" with a "YES" or "NO" when the diamond has been turned to carbonprime. But the way the uploaded human would do that is by adapting its concept of "diamond" to a fundamentally new conception of physics, using its value system to decide on the most reasonable way to do that. If the biological human trusts the uploaded human to do such extrapolation on its behalf, it is because they share values, and so the biological human expects the uploaded human to extrapolate in a way that serves their own values. Even for value-free concepts (such as, perhaps, "is there a diamond in the vault?"), the extrapolation of those concepts to unfamiliar situations is still highly value-laden.
Appendix: Can we infer our own actions?
David Wolpert has proposed a model of knowledge within deterministic universes based on a formalism that he calls an inference device. Wolpert takes as primary a deterministic universe, and defines functions on the universe to represent input/output maps. He says that an inference device infers a certain function if its input and output functions have a certain relationship with that function. He only talks about observers through the lens of functions that pick out properties of a deterministic universe that contains both the "observer" and the object being "observed", and as a result he winds up with a completely embedded (in the sense of "embedded agency") account of knowledge.[2]
Based on the physical embedding of inference devices within the universe they are "observing", Wolpert proves two impossibility results: first, that an inference device cannot infer the opposite of its own output, and second, that two inference devices cannot mutually infer one another. Could we use the oracle construction from the previous section to set up a Wolpert inference device that contradicts Wolpert’s impossibility results? If so, perhaps that would establish the impossibility of automated ontology identification as we have defined it.
It seems to us that we could indeed set this up, but that it would only establish the impossibility of automated ontology identification on the particular self-referential questions that Wolpert uses in his impossibility results. Establishing that there are some questions for which automated ontology identification is impossible is not very interesting. Nevertheless, this connection seems intriguing to us because Wolpert’s framework gives us a straightforward way to take any Cartesian question-answering formalism and consider at least some questions about an embedded version of it. We intend to investigate this further.
We leave open the definition of "simple" for now. ↩︎
See also our previous discussion of Wolpert’s model and its relevance to alignment. ↩︎