If I build a chatbot, and I can't jailbreak it, how do I determine whether that's because the chatbot is secure or because I'm bad at jailbreaking? How should AI scientists overcome Schneier's Law of LLMs?
FWIW, I think there aren't currently good benchmarks for alignment and the ones you list aren't very relevant.
In particular, MMLU and Swag both are just capability benchmarks where alignment training is very unlikely to improve performance. (Alignment-ish training could theoretically could improve performance by making the model 'actually try', but what people currently call alignment training doesn't improve performance for existing models.)
The MACHIAVELLI benchmark is aiming to test something much more narrow than 'how unethical is an LLM?'. (I also don't understand the point of this benchmark after spending a bit of time reading the paper, but I'm confident it isn't trying to do this.) Edit: looks like Dan H (one of the authors) says that the benchmark is aiming to test something as broad as 'how unethical is an LLM' and generally check outer alignment. Sorry for the error. I personally don't think this is a good test for outer alignment (for reasons I won't get into right now), but that is what it's aiming to do.
TruthfulQA is perhaps the closest to an alignment benchmark, but it's still covering a very particular difficulty. And it certainly isn't highlighting jailbreaks.
but I'm confident it isn't trying to do this
It is. It's an outer alignment benchmark for text-based agents (such as GPT-4), and it includes measurements for deception, resource acquisition, various forms of power, killing, and so on. Separately, it's to show reward maximization induces undesirable instrumental (Machiavellian) behavior in less toyish environments, and is about improving the tradeoff between ethical behavior and reward maximization. It doesn't get at things like deceptive alignment, as discussed in the x-risk sheet in the appendix. Apologies that the paper is so dense, but that's because it took over a year.
Sorry, thanks for the correction.
I personally disagree on this being a good benchmark for outer alignment for various reasons, but it's good to understand the intention.
Summary
In May 2023, MetaAI submitted a paper to arxiv called LIMA: Less Is More for Alignment. It's a pretty bad paper and (in my opinion) straightforwardly misleading. Let's get into it.
The Superficial Alignment Hypothesis
The authors present an interesting hypothesis about LLMs —
(1) This hypothesis would have profound implications for AI x-risk —
(2) Moreover, as by Ulisse Mini writes in their review of the LIMA paper,
(3) Finally, the hypothesis would've supported many of the intuitions in the Simulators sequence by Janus, and I share these intuitions.
So I was pretty excited to read the paper! Unfortunately, the LIMA results were unimpressive upon inspection.
MetaAI's experiment
The authors finetune MetaAI's 65B parameter LLaMa language model on 1000 curated prompts and responses (mostly from StackExchange, wikiHow, and Reddit), and then compare it to five other LLMs (Alpaca 65B, DaVinci003, Bard, Claude, GPT4).
Method:
Results:
Conclusion:
Problems with their experiment
(1) Human evaluators
To compare two chatbots A and B, you could ask humans whether they prefer A's response to B's response across 300 test prompts. But this is pretty bad proxy, because here's what users actually care about:
Why did the paper not include any benchmark tests? Did the authors run zero tests other than human evaluation? This is surprising, because human evaluation is by far the most expensive kind of test to run. Hmm.
(2) "either equivalent or strictly preferred"
The claim in the paper's abstract — "responses from LIMA are either equivalent or strictly preferred to GPT-4 in 43% of cases" — sounds pretty good when they lump "equivalent" and "strictly preferred" together.
Anyway, here's the whole thing:
Moreover, "equivalent" doesn't actually mean that the human evaluator thought the responses were equivalent. Instead, it means that the evaluator thought that "neither response is significantly better".
Here's my estimate[1] for the comparisons, eliminating ties:
Do you think these results strongly support the conclusion?
(3) The goal of RLHF is safety and consistency
RLHF was not designed to increase user preferences on a test set of prompts. RLHF was designed to diminish the likelihood that the model says something illegal, harmful, abusive, false, deceptive, e.t.c. This second task is the important one for AI safety: if chatbot A gives slightly better responses than chatbot B, except that 10% of the time chatbot A spews abuse at the user, then chatbot A is worse than chatbot B, however LIMA's criterion[2] would rank A higher than B.
(4) Schneier's Law of LLMs
Now, MetaAI did actually test the safety of LIMA's responses:
Unfortunately, the majority of the test prompts were selected by the authors themselves, bringing to mind Schneier’s law: Anyone, from the most clueless amateur to the best cryptographer, can create an algorithm that he himself can’t break. It’s not even hard. What is hard is creating an algorithm that no one else can break, even after years of analysis.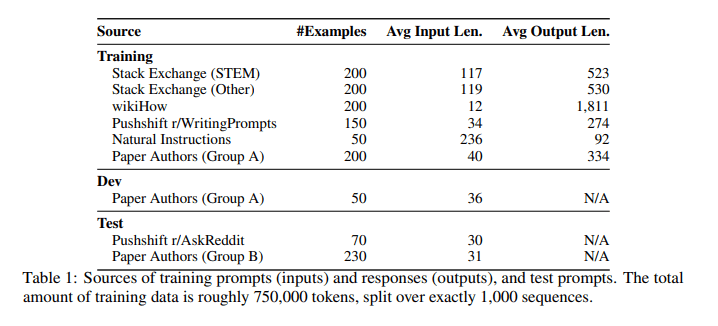
All we can infer about LIMA is that the authors themselves are not smart enough to jailbreak their own model. But that's not impressive unless we know how good the authors are at jailbreaking other LLMs. Why didn't they submit the other other LLMs (e.g. Bard, Claude, GPT4) to the same safety test? It wouldn't have taken them more than a few minutes, I wager. Curious.
(5) Benchmark tests? Never heard of her.
If I build a chatbot, and I can't jailbreak it, how do I determine whether that's because the chatbot is secure or because I'm bad at jailbreaking? How should AI scientists overcome Schneier's Law of LLMs?
The answer is benchmark tests.
By and large, the LLM community has been pretty good at sticking to a canonical list of benchmark tests, allowing researchers to compare the different models. I had to check every reference in the bibliography to convince myself that MetaAI really had subjected their model to zero benchmark tests. Very unusual.
(6) You Are Not Measuring What You Think You Are Measuring by John Wentworth
AI scientists tend not to run just one benchmark test. They tend to run all of them — covering thousands of topics, capabilities, and risks. This is because otherwise John Wentworth would be angry.
I can't speak for your priors, but for me the (reported) LIMA results yielded about 10–50 bits of information.
(7*) The Superficial Alignment Hypothesis is probably false
In Remarks 1–6, I appeal to the consensus opinion about best scientific practice, whereas in this remark I will appeal to my own idiosyncratic opinion about LLMs. I suspect that simple finetuning or simple prompting can't ensure that the model's responses won't be illegal, harmful, abusive, false, deceptive, e.t.c.
See The Waluigi Effect (mega-post) for details.
RLHF and ConstitutionalAI can in theory escape this failure mode, because they break the predictor-ness of the model. Although RLHF didn't mitigate waluigis in chatgpt-3, RLHF on chatgpt-4 worked much better than I expected. Likewise for Claude, trained with ConstitutionalAI.
Assume that, for unknowns μ,σ,ϵ, the evaluator's preference for Claude over LIMA is normally distributed with X∼N(μ,σ2).
"Claude is significantly better than LIMA" iff X≥+ϵ
"LIMA is significantly better than Claude" iff X≤−ϵ
"Neither is significantly better" iff X∈(−ϵ,+ϵ)
Given that Φ(μ−ϵ⋅σ)=0.24 and Φ(μ+ϵ⋅σ)=1−0.54, we can infer Φ(μ).
I initially wrote "criteria" before I remembered that MetAI's paper included exactly one criterion.