Thanks for writing this! I found this a really helpful post for clarifying my own intuitions. Trying to operationalise what confused me before, and what now feels clear:
Confusion: Why does the model want to split vectors into these orthogonal subspaces? This seems somewhat unnatural and wasteful - it loses a lot of degrees of freedom, and surely it wants to spread out and minimise interference as much as possible?
Implicitly, I was imagining something like L2 loss where the model wants to minimise the sum of squared dot products.
New intuition: There is no inherently correct solution to this problem! It all depends on the precise loss function (or, the impact of each pairwise interference on the loss function). If the model has 100 dimensions and needs to fit in 1000 vectors, it can do this by packing 1000 spread out across all 100 dimensions, or by packing 500 into the first 50, and 500 into the second 50. The second approach immediately gives it 500^2 dot products to be 0, at the cost of increasing the dot products within each partition of 500.
Intuitively, there's going to be some kind of conservation property affecting the total amount of interference, but the model can choose to allocate that towards minimising the number of significant interferences or the maximum interference. Smearing it across all dimensions minimises the maximum, forming a partition minimises the number. So the choice depends on the model's exact loss function.
In practice, the model's loss function will be really complicated - for any pair of features, cost of interference goes up if they're correlated, up if either is important, down if either is sparse, and down if the model can allocate some parameters to denoising the interference. Importantly, for the ones to do with correlation, interference between correlated features will be way worse, so the model wants to finds ways to minimise the max interference, and is happy to tolerate a lot of interference between uncorrelated features. Which means the optimal packing probably involves tegum products, because it's a nice hack to efficiently get lots of the interference terms to zero.
Probably my biggest remaining confusion is why tegum products are the best way to get a lot of interference terms to zero, rather than just some clever packing smeared across all dimensions.
That's good to hear! And I agree with your new intuition.
I think if you want interference terms to actually be zero you have to end up with tegum products, because that means you want orthogonal vectors and that implies disjoint subspaces. Right?
I don't think so? If you have eg 8 vectors arranged evenly in a 2D plane (so at 45 degrees to each other) there's a lot of orthogonality, but no tegum product. I think the key weirdness of a tegum product is that it's a partition, where every pair in different bits of the partition is orthogonal. I could totally imagine that eg the best way to fit 2n vectors is n dimensional space is two sets of n orthogonal vectors, but at some arbitrary angle to each other.
I can believe that tegum products are the right way to maximise the number of orthogonal pairs, though that still feels a bit weird to me. (technically, I think that the optimal way to fit kn vectors in R^n is to have n orthogonal directions and k vectors along each direction, maybe with different magnitudes - which is a tegum product. It forming 2D-3D subspaces feels odd though).
Oh yes you're totally right.
I think partitions can get you more orthogonality than your specific example of overlapping orthogonal sets. Take n vectors and pack them into d dimensions in two ways:
- A tegum product with k subspaces, giving (n/k) vectors per subspace and n^2*(1-1/k)orthogonal pairs.
- (n/d) sets of vectors, each internally orthogonal but each overlapping with the others, giving n*d orthogonal pairs.
If d < n*(1-1/k) the tegum product buys you more orthogonal pairs. If n > d then picking large k (so low-dimensional spaces) makes the tegum product preferred.
This doesn't mean there isn't some other arrangement that does better though...
Yeah, agreed that's not an optimal arrangement, that was just a proof of concept for 'non tegum things can get a lot of orthogonality
Thanks for the great post! I have a question, if it's not too much trouble:
Sorry for my confusion about something so silly, but shouldn't the following be "when "?
When there is no place where the derivative vanishes
I'm also a bit confused about why we can think of as representing "which moment of the interference distribution we care about."
Perhaps some of my confusion here stems from the fact that it seems to me that the optimal number of subspaces, , is an increasing function of , which doesn't seem to line up with the following:
Hence when is large we want to have fewer subspaces
What am I missing here?
Sorry for my confusion about something so silly, but shouldn't the following be "when
Oh you're totally right. And k=1 should be k=d there. I'll edit in a fix.
I'm also a bit confused about why we can think of as representing "which moment of the interference distribution we care about."
It's not precisely which moment, but as we vary the moment(s) of interest vary monotonically.
Perhaps some of my confusion here stems from the fact that it seems to me that the optimal number of subspaces, , is an increasing function of , which doesn't seem to line up with the following:
This comment turned into a fascinating rabbit hole for me, so thank you!
It turns out that there is another term in the Johnson-Lindenstrauss expression that's important. Specifically, the relation between , , and should be (per Scikit and references therein). The numerical constants aren't important, but the cubic term is, because it means the interference grows rather faster as grows (especially in the vicinity of ).
With this correction it's no longer feasible to do things analytically, but we can still do things numerically. The plots below are made with :
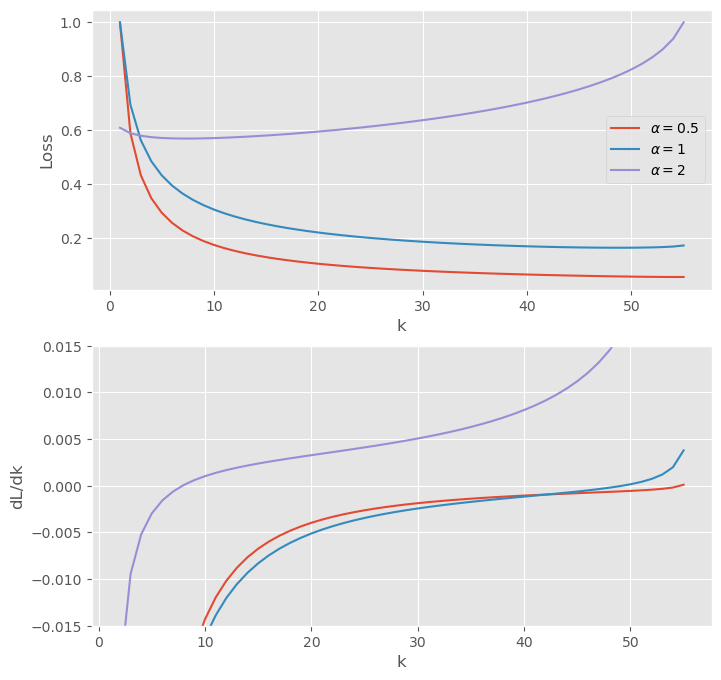
The top panel shows the normalized loss for a few different , and the lower shows the loss derivative with respect to . Note that the range of is set by the real roots of : for larger there are no real roots, which corresponds to the interference crossing unity. In practice this bound applies well before . Intuitively, if there are more vectors than dimensions then the interference becomes order-unity (so there is no information left!) well before the subspace dimension falls to unity.
Anyway, all of these curves have global minima in the interior of the domain (if just barely for ), and the minima move to the left as rises. That is, for we care increasingly about higher moments as we increase and so we want fewer subspaces.
What happens for ?
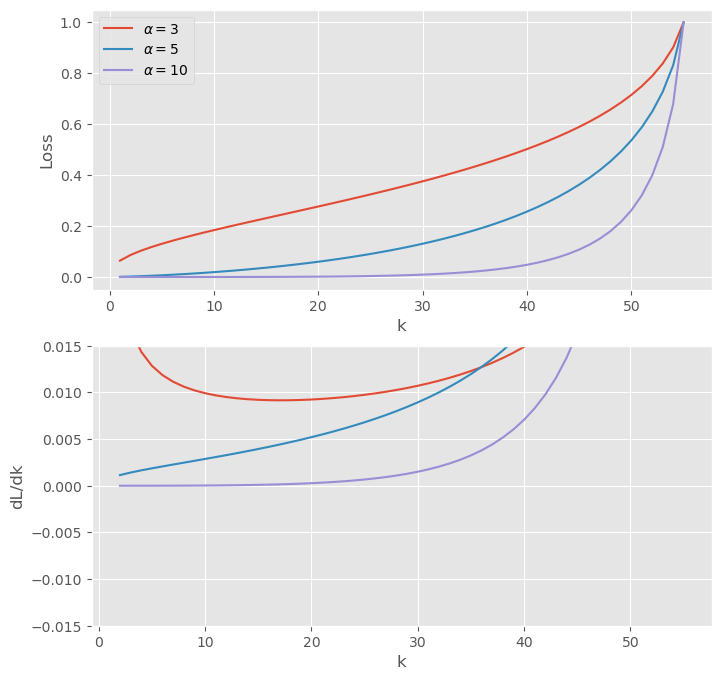
The global minima disappear! Now the optimum is always . In fact though the transition is no longer at but a little higher:
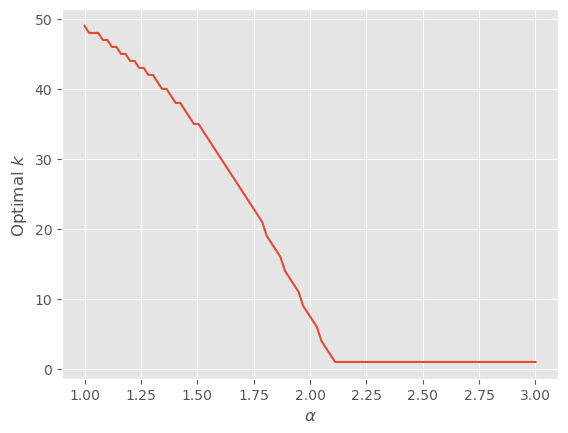
So the basic story still holds, but none of the math involved in finding the optimum applies!
I'll edit the post to make this clear.
(Thanks to Adam Scherlis, Kshitij Sachan, Buck Shlegeris, Chris Olah, and Nicholas Schiefer for conversations that informed this post. Thanks to Aryan Bhatt for catching an error in the loss minimization.)
Anthropic recently published a paper on toy models of superposition [Elhage+22]. One of the most striking results is that, when features are sparse, feature embeddings can become divided into disjoint subspaces with just a few vectors per subspace. This type of decomposition is known as a tegum product.
This post aims to give some intuition for why tegum products are a natural feature of the minima of certain loss functions.
Setup
Task
Suppose we’ve got d embedding dimensions and n>d features. We want to embed features into dimensions in a way that minimizes overlap between their embedding vectors. In the simplest case this could be because we’re building an autoencoder and want to compress the features into a low-dimensional space.
One approach is to encode all of the features in all of the dimensions. With this approach there is some interference between every pair of features (i.e. no pair is embedded in a fully orthogonal way), but we have a lot of degrees of freedom that we can use to minimize this interference.
Another approach is to split the d dimensions into k orthogonal subspaces of d/k dimensions. This has the advantage of making most pairs of vectors exactly orthogonal, but at the cost that some vectors are packed more closely together. In the limit where k=1 this reduces to the first approach.
Our aim is to figure out the k that minimizes the loss on this task.
Loss
Suppose our loss has the following properties:
Using these properties, we find that the loss is roughly
L≈n2ℓ(ϵ)2kwhere ϵ is the typical cosine similarity between vectors in a subspace.
Loss-Minimizing Subspaces
Edit: The formula for ϵ below is a simplification in the limit of small ϵ. This simplification turns out to matter, and affects the subsequent loss minimization. I've struck through the affected sections below, explained the correct optimization in this comment below and reproduced the relevant results below the original here. None of the subsequent interpretation is affected.
|cosθij|≤ϵTheJohnson-Lindenstrauss lemmasays that we can packmnearly-orthogonal vectors intoDdimensions, with mutual angles satisfying
ϵ=ϵ0√lnmDwhere
ϵ=ϵ0√ln(n/k)d/kandϵ0is a constant. Settingm=n/kandD=d/kgives
dLdk=Lk(dlnℓdlnϵdlnϵdlnk−1)=Lk(dlnℓdlnϵln(n/k)−12ln(n/k)−1)Assuming we pick our vectors optimally to saturate the Johnson-Lindenstrauss bound, we can substitute this forϵin the loss and differentiate with respect tokto findThere are three possible cases: either the minimum occurs atk=d(the greatest value it can take), or atk=1(the smallest value it can take) or at some point in between wheredL/dkvanishes.
dlnℓdlnϵ=2ln(n/k)ln(n/k)−1The derivative vanishes if
nk=eα/(α−2)which gives
α=dlnℓdlnϵwhere
k=neα/(2−α)Whenα≥2there is no place where the derivative vanishes, and the optimum isk=1. Otherwise there is an optimum atso long as this is less thand. If it reachesd, the optimum sticks tok=d.The Johnson-Lindenstrauss lemma says that we can pack m nearly-orthogonal vectors into D dimensions, with mutual angles satisfying
|cosθij|≤ϵwhere ϵ2/2−ϵ3/3≥4logm/D (per Scikit and references therein). The cubic term matters because it makes the interference grow faster than the quadratic alone would imply (especially in the vicinity of ϵ≈1).
With this correction it's not feasible to do the optimization analytically, but we can still do things numerically. Setting m=n/k, D=d/k, n=105, and d=104 gives:
The top panel shows the normalized loss for a few different α≤2, and the lower shows the loss derivative with respect to k. Note that the range of k is set by the real roots of ϵ2/2−ϵ3/3≥4logm/D: for larger k there are no real roots, which corresponds to the interference ϵ crossing unity. In practice this bound applies well before k→d. Intuitively, if there are more vectors than dimensions then the interference becomes order-unity (so there is no information left!) well before the subspace dimension falls to unity.
Anyway, all of these curves have global minima in the interior of the domain (if just barely for α=0.5), and the minima move to the left as α rises. That is, for α≤2 we care increasingly about higher moments as we increase α and so we want fewer subspaces.
What happens for α>2?
The global minima disappear! Now the optimum is always k=1. In fact though the transition is no longer at α=2 but a little higher:
Interpretation
We can think of α as the sensitivity of the loss to interference. Specifically, which moment of the interference distribution do we care about?
When α is large, we care more about decreasing higher moments, and in the limit of infinite α what matters is just the maximum interference between vectors. Hence when α is large we want to have fewer subspaces, each with more vectors but smaller cosine similarities.
By contrast, when α is small, we care more about decreasing smaller moments, and in the limit as α→0 what matters is the fraction of vectors that interfere at all. Hence when α is small we want to have more subspaces, each with fewer vectors but larger cosine similarities.
So tegum products are preferred when we can tolerate larger “peak” interference and want fewer instances of interference, whereas a single large subspace is preferred when we can tolerate lots of instances of interference and want to minimize the worst cases.
Relation to Anthropic’s Results
In Anthropic’s Toy Model 2, the dimension of the subspaces increases the sparser the features get, meaning that k falls. We can make sense of this by expanding the loss as they do in powers of the sparsity S:
L=n∑i=0(1−S)iSn−iLiwhere Li is the loss associated with i-sparse vectors. In the sparse limit S→1 so
L≈L0+(1−S)L1The term L0 is a penalty on positive biases and the term L1 is the loss on 1-sparse vectors. In this limit, the biases are negative (to minimize L0), and this has the effect of wiping out the contribution of small interference terms in L1. So the model is pushed to decrease the worst case interference (which might overcome the bias) rather than minimize the average, corresponding to our large-α limit.
On the other hand, in the dense limit S→0 so
L≈(1−S)nLnThe term Ln is the loss on dense vectors, which means there is interference between all pairs of vectors. This makes minimizing the average interference more important than minimizing the really bad cases (i.e. higher moments), so the model prefers lots of small subspaces, corresponding to our small-α limit.
Just as the relevant limit varies with sparsity for a given toy model, we can also get different phenomenology for different models. This makes sense given that different setups can have different loss functions.
Summary
There are many ways for models to embed features. A surprising observation from Elhage+22 is that sometimes the optimal choice is one which divides the embedding space into many orthogonal subspaces (i.e. a tegum product). We can understand this roughly as coming from a tradeoff between minimizing higher moments of the feature interference (e.g. worst-case) and minimizing lower moments (e.g. average-case interference).
Smaller subspaces minimize the lower moments by making most pairs of vectors exactly orthogonal. The cost of this is that there is less freedom to choose vector pairs in each subspace, so there is worse interference between the pairs that do interfere.
Larger subspaces have the reverse tradeoff: they experience interference between more pairs of vectors, but it tends to be milder because larger-dimensional spaces support packing more nearly-orthogonal vectors, even at a fixed ratio of vectors-to-dimension.