I think your discussion (and Epoch's discussion) of the CES model is confused as you aren't taking into account the possibility that we're already bottlenecking on compute or labor. That is, I think you're making some assumption about the current marginal returns which is non-obvious and, more strongly, would be an astonishing coincidence given that compute is scaling much faster than labor.
In particular, consider a hypothetical alternative world where they have the same amount of compute, but there is only 1 person (Bob) working on AI and this 1 person is as capable as the median AI company employee and also thinks 10x slower. In this alternative world they could also say "Aha, you see because , even if we had billions of superintelligences running billions of times faster than Bob, AI progress would only go up to around 4x faster!"
Of course, this view is absurd because we're clearly operating >>4x faster than Bob.
So, you need to make some assumptions about the initial conditions.
This perspective implies an (IMO) even more damning issue with this exact modeling: the CES model is symmetric, so it also implies that additional compute (without labor) can only speed you up so much. I think the argument I'm about to explain strongly supports a lower value of or some different functional form.
Consider another hypothetical world where the only compute they have is some guy with an abacus, but AI companies have the same employees they do now. In this alternative world, you could also have just as easily said "Aha, you see because , even if we had GPUs that could do 1e15 FLOP/s (far faster than our current rate of 1e-1 fp8 FLOP/s), AI progress would only go around 4x faster!"
Further, the availability of compute for AI experiments has varied by around 8 orders of magnitude over the last 13 years! (AlexNet was 13 years ago.) The equivalent (parallel) human labor focused on frontier AI R&D has varied by more like 3 or maybe 4 orders of magnitude. (And the effective quality adjusted serial labor, taking into account parallelization penalities etc, has varied by less than this, maybe by more like 2 orders of magnitude!)
Ok, but can we recover low-substitution CES? I think the only maybe consistent recovery (which doesn't depend on insane coincidences about compute vs labor returns) would imply that compute was the bottleneck (back in AlexNet days) such that scaling up labor at the time wouldn't yield ~any progress. Hmm, this doesn't seem quite right.
Further, insofar as you think scaling up just labor when we had 100x less compute (3-4 years ago) would have still been able to yield some serious returns (seems obviously true to me...), then a low-substitution CES model would naively imply we have a sort of compute overhang where were we can speed things up by >100x using more labor (after all, we've now added a bunch of compute, so time for more labor).
Minimally, the CES view predicts that AI companies should be spending less and less of their budget on compute as GPUs are getting cheaper. (Which seems very false.)
Ok, but can we recover a view sort of like the low-substitution CES view where speeding up our current labor force by an arbitrary amount (also implying we could only use our best employees etc) would only yield ~10x faster progress? I think this view might be recoverable with some sort of non-symmetric model where we assume that labor can't be the bottleneck in some wide regime, but compute can be the bottleneck.
(As in, you can always get faster progress by adding more compute, but the multiplier on top of this from adding labor caps out at some point which mostly doesn't depend on how much compute you have. E.g., maybe this could be because at some point you just run bigger experiments with the same amount of labor and doing a larger numbers of smaller experiment is always worse and you can't possibly design the experiment better. I think this sort of model is somewhat plausible.)
This model does make a somewhat crazy prediction where it implies that if you scale up compute and labor exactly in parallel, eventually further labor has no value. (I suppose this could be true, but seems a bit wild.)
Overall, I'm currently quite skeptical that arbitrary improvements in labor yield only small increases in the speed of progress. (E.g., a upper limit of 10x faster progress.)
As far as I can tell, this view either privileges exactly the level of human researchers at AI companies or implies that using only a smaller number of weaker and slower researchers wouldn't alter the rate of progress that much.
In particular, consider a hypothetical AI company with the same resources as OpenAI except that they only employ aliens whose brains work 10x slower and for which the best researcher is roughly as good as OpenAI's median technical employee. I think such an AI company would be much slower than OpenAI, maybe 10x slower (part from just lower serial speed and part from reduced capabilities). If you think such an AI company would be 10x slower, then by symmetry you should probably think that an AI company with 10x faster employees who are all as good as the best researchers should perhaps be 10x faster or more.[1] It would be surprising if the returns stopped at exactly the level of OpenAI researchers. And the same reasoning makes 100x speed ups once you have superhuman capabilities at massive serial speed seem very plausible.
I edited this to be a hopefully more clear description. ↩︎
As far as I can tell, this sort of consideration is at least somewhat damning for the literal CES model (with poor substitution) in any situation where the inputs have varied by hugely different amounts (many orders of magnitude of difference like in the compute vs labor case) and relative demand remains roughly similar. While this is totally expected under high substitution.
Yeah, you can get into other fancy tricks to defend it like:
- Input-specific technological progress. Even if labour has grown more slowly than capital, maybe the 'effective labour supply' -- which includes tech makes labour more productive (e.g. drinking caffeine, writing faster on a laptop) -- has grown as fast as capital.
- Input-specific 'stepping on toes' adjustments. If capital grows at 10%/year and labour grows at 5%/year, but (effective labour) = labour^0.5, and (effective capital)=capital, then the growth rates of effective labour and effective capital are equal
Thanks, this is a great comment.
I buy your core argument against the main CES model I presented. I think your key argument ("the relative quantity of labour vs compute has varied by OOMs; If CES were true, then one input would have become a hard bottleneck; but it hasn't.") is pretty compelling as an objection to the simple naive CES I mention in the post. It updates me even further towards thinking that, if you use this naive CES, you should have ρ> -0.2. Thanks!
The core argument is less powerful against a more realistic CES model that replaces 'compute' with 'near-frontier sized experiments'. I'm less sure how strong it is as an argument against the more-plausible version of the CES where rather than inputs of cognitive labour and compute we have inputs of cognitive labour and number of near-frontier-sized experiments. (I discuss this briefly in the post.) I.e. if a lab has total compute C_t, its frontier training run takes C_f compute, and we say that a 'near-frontier-sized' experiment uses 1% as much compute as training a frontier model, then the number of near-frontier sized experiments that the lab could run equals E = 100* C_t / C_f
With this formulation, it's no longer true that a key input has increased by many OOMs, which was the core of your objection (at least the part of your objection that was about the actual world rather than about hypotheticals - i discuss hypotheticals below.)
Unlike compute, E hasn't grown by many OOMs over the last decade. How has it changed? I'd guess it's gotten a bit smaller over the past decade as labs have scaled frontier training runs faster than they've scaled their total quantity of compute for running experiments. But maybe labs have scaled both at equal pace, especially as in recent years the size of pre-training has been growing more slowly (excluding GPT-4.5).
So this version of the CES hypothesis fares better against your objection, bc the relative quantity of the two inputs (cognitive labour and number of near-frontier experiments) have changed by less over the past decade. Cognitive labour inputs have grown by maybe 2 OOMs over the past decade, but the 'effective labour supply', adjusting for diminishing quality and stepping-on-toes effects has grown by maybe just 1 OOM. With just 1 OOM relative increase in cognitive labour, the CES function with ρ=-0.4 implies that compute will have become more of a bottleneck, but not a complete bottleneck such that more labour isn't still useful. And that seems roughly realistic.
Minimally, the CES view predicts that AI companies should be spending less and less of their budget on compute as GPUs are getting cheaper. (Which seems very false.)
This version of the CES hypothesis also dodges this objection. AI companies need to spend much more on compute over time just to keep E constant and avoid compute becoming a bottleneck.
This model does make a somewhat crazy prediction where it implies that if you scale up compute and labor exactly in parallel, eventually further labor has no value. (I suppose this could be true, but seems a bit wild.)
Doesn't seem that wild to me? When we scale up compute we're also scaling up the size of frontier training runs; maybe past a certain point running smaller experiments just isn't useful (e.g. you can't learn anything from experiments using 1 billionth of the compute of a frontier training run); and maybe past a certain point you just can't design better experiments. (Though I agree with you that this is all unlikely to bite before a 10X speed up.)
consider a hypothetical AI company with the same resources as OpenAI except that they only employ aliens whose brains work 10x slower and for which the best researcher is roughly as good as OpenAI's median technical employee
Nice thought experiment.
So the near-frontier-experiment version of the CES hypothesis would say that those aliens would be in a world where experimental compute isn't a bottleneck on AI progress at all: the aliens don't have time to write the code to run the experiments they have the compute for! And we know we're not in that world because experiments are a real bottleneck on our pace of progress already: researchers say they want more compute! These hypothetical aliens would make no such requests. It may be a weird empirical coincidence that cognitive labour helps up to our current level but not that much further, but we can confirm with the evidence of the marginal value of compute in our world.
But actually I do agree the CES hypothesis is pretty implausible here. More compute seems like it would still be helpful for these aliens: e.g. automated search over different architectures and running all experiments at large scale. And evolution is an example where the "cognitive labour" going into AI R&D was very very very minimal and still having lots of compute to just try stuff out helped.
So I think this alien hypothetical is probably the strongest argument against the near-frontier experiment version of the CES hypothesis. I don't think it's devastating -- the CES-advocate can bite the bullet and claim that more compute wouldn't be at all useful in that alien world.
(Fwiw i preferred the way you described that hypothesis before your last edit.)
You can also try to 'block' the idea of a 10X speed up by positing a large 'stepping on toes' effect. If it's v important to do experiments in series and that experiments can't be sped up past a certain point, then experiments could still bottleneck progress. This wouldn't be about the quantity of compute being a bottleneck per se, so it avoids your objection. Instead the bottleneck is 'number of experiments you can run per day'. Mathematically, you could represent this by smg like:
AI progress per week = log(1000 + L^0.5 * E^0.5)
The idea is that there are ~linear gains to research effort initially, but past a certain point returns start to diminish increasingly steeply such that you'd struggle to ever realistically 10X the pace of progress.
Ultimately, I don't really buy this argument. If you applied this functional form to other areas of science you'd get the implication that there's no point scaling up R&D past a certain point, which has never happened in practice. And even i think the functional form underestimates has much you could improve experiment quality and how much you could speed up experiments. And you have to cherry pick the constant so that we get a big benefit from going from the slow aliens to OAI-today, but limited benefit from going from today to ASI.
Still, this kind of serial-experiment bottleneck will apply to some extent so it seems worth highlighting that this bottleneck isn't effected by the main counterargument you made.
I don't think my treatment of initial conditions was confused
I think your discussion (and Epoch's discussion) of the CES model is confused as you aren't taking into account the possibility that we're already bottlenecking on compute or labor...
In particular, consider a hypothetical alternative world where they have the same amount of compute, but there is only 1 person (Bob) working on AI and this 1 person is as capable as the median AI company employee and also thinks 10x slower. In this alternative world they could also say "Aha, you see because , even if we had billions of superintelligences running billions of times faster than Bob, AI progress would only go up to around 4x faster!"
Of course, this view is absurd because we're clearly operating >>4x faster than Bob.
So, you need to make some assumptions about the initial conditions....
Consider another hypothetical world where the only compute they have is some guy with an abacus, but AI companies have the same employees they do now. In this alternative world, you could also have just as easily said "Aha, you see because , even if we had GPUs that could do 1e15 FLOP/s (far faster than our current rate of 1e-1 fp8 FLOP/s), AI progress would only go around 4x faster!"
My discussion does assume that we're not currently bottlenecked on either compute or labour, but I think that assumption is justified. It's quite clear that labs both want more high-quality researchers -- top talent has very high salaries, reflecting large marginal value-add. It's also clear that researchers want more compute -- again reflecting large marginal value-add. So it's seems clear that we're not strongly bottlenecked by just one of compute or labour currently. That's why I used α=0.5, assuming that the elasticity of progress to both inputs is equal. (I don't think this is exactly right, but seems in the right rough ballpark.)
I think your thought experiments about the the world with just one researcher and the world with just an abacus are an interesting challenge to the CES function, but don't imply that my treatment of initial conditions was confused.
I actually don't find those two examples very convincing though as challenges to the CES. In both those worlds it seems pretty plausible that the scarce input would be a hard bottleneck on progress. If all you have is an abacus, then probably the value of the marginal AI researcher would be ~0 as they'd have no compute to use. And so you couldn't run the argument "ρ= - 0.4 and so more compute won't help much" because in that world (unlike our world) it will be very clear that compute is a hard bottleneck to progress and cognitive labour isn't helpful. And similarly, in the world with just Bob doing AI R&D, it's plausible that AI companies would have ~0 willingness to pay for more compute for experiments, as Bob can't use the compute that he's already got; labour is the hard bottleneck. So again you couldn't run the argument based on ρ=-0.4 bc that argument only works if neither input is currently a hard bottleneck.
Doesn't seem that wild to me? When we scale up compute we're also scaling up the size of frontier training runs; maybe past a certain point running smaller experiments just isn't useful (e.g. you can't learn anything from experiments using 1 billionth of the compute of a frontier training run); and maybe past a certain point you just can't design better experiments. (Though I agree with you that this is all unlikely to bite before a 10X speed up.)
Yes, but also, if the computers are getting serially faster, then you also have to be able to respond to the results and implement the next experiment faster as you add more compute. E.g., imagine a (physically implausible) computer which can run any experiment which uses less than 1e100 FLOP in less than a nanosecond. To maximally utilize this, you'd want to be able to respond to results and implement the next experiment in less than a nanosecond as well. This is of course an unhinged hypothetical and in this world, you'd also be able to immediately create superintelligence by e.g. simulating a huge evolutionary process.
I’ll define an “SIE” as “we can get >=5 OOMs of increase in effective training compute in <1 years without needing more hardware”. I
This is as of the point of full AI R&D automation? Or as of any point?
Epistemic status – thrown together quickly. This is my best-guess, but could easily imagine changing my mind.
Intro
I recently copublished a report arguing that there might be a software intelligence explosion (SIE) – once AI R&D is automated (i.e. automating OAI), the feedback loop of AI improving AI algorithms could accelerate more and more without needing more hardware.
If there is an SIE, the consequences would obviously be massive. You could shoot from human-level to superintelligent AI in a few months or years; by default society wouldn’t have time to prepare for the many severe challenges that could emerge (AI takeover, AI-enabled human coups, societal disruption, dangerous new technologies, etc).
The best objection to an SIE is that progress might be bottlenecked by compute. We discuss this in the report, but I want to go into much more depth because it’s a powerful objection and has been recently raised by some smart critics (e.g. this post from Epoch).
In this post I:
The compute bottleneck objection
Intuitive version
The intuitive version of this objection is simple. The SIE-sceptic says:
Look, ML is empirical. You need to actually run the experiments to know what works. You can’t do it a priori. And experiments take compute. Sure, you can probably optimise the use of that compute a bit, but past a certain point, it doesn’t matter how many AGIs you have coding up experiments. Your progress will be strongly constrained by your compute.
An SIE-advocate might reply: sure, we’ll eventually fully optimise experiments, and past that point won’t advance faster. But we can maintain a very fast pace of progress, right?
The SIE-sceptic replies:
Nope, because ideas get harder to find. You’ll need more experiments and more compute to find new ideas over time, as you pluck the low-hanging fruit. So once you’ve fullu optimised your experiments your progress will slow down over time. (Assuming you hold compute constant!)
Economist version
That’s the intuitive version of the compute bottlenecks objection. Before assessing it, I want to make what I call the “economist version” of the objection. This version is more precise, and it was made in the Epoch post.
This version draws on the CES model of economic production. The CES model is a mathematical formula for predicting economic output (GDP) given inputs of labour L and physical capital K. You don’t need to understand the math formula, but here it is:
The formula has a substitutability parameter ρ which controls the extent to which K and L are complements vs substitutes. If ρ<0, they are complements and there’s a hard bottleneck – if L goes to infinity but K remains fixed, output cannot rise above a ceiling.
(There’s also a parameter α but it’s less important for our purposes. α can be thought of as the fraction of tasks performed by L vs K. I’ll assume α=0.5 throughout. If L=K, which I take as my starting point, α also represents the elasticity of Y wrt K.)
Here are the predictions of the CES formula when K=1 and ρ = -0.2.
This graph shows the implications of a CES production function. It shows how output (Y) changes when K=1 and L varies, with ρ = -0.2. The blue line shows output growing with more labor but approaching the red ceiling line, demonstrating the maximum possible output when K=1.
We can apply the CES formula to AI R&D during a software intelligence explosion (SIE). In this context, L represents the amount of AI cognitive labour applied to R&D, K represents the amount of compute, and Y represents the pace of AI software progress. The model can predict how much faster AI software would improve if we add more AGI researchers but keep compute fixed.
In this context, the ‘ceiling’ gives the max speed of AI software progress as cognitive labour tends to infinity but compute is held fixed. A max speed of 100 means progress could become 100 times faster than today, but no faster, no matter how many AGI researchers we add, and no matter how smart they are or how quickly they think.
Here is the same diagram as above, but re-labelled for the context of AI R&D: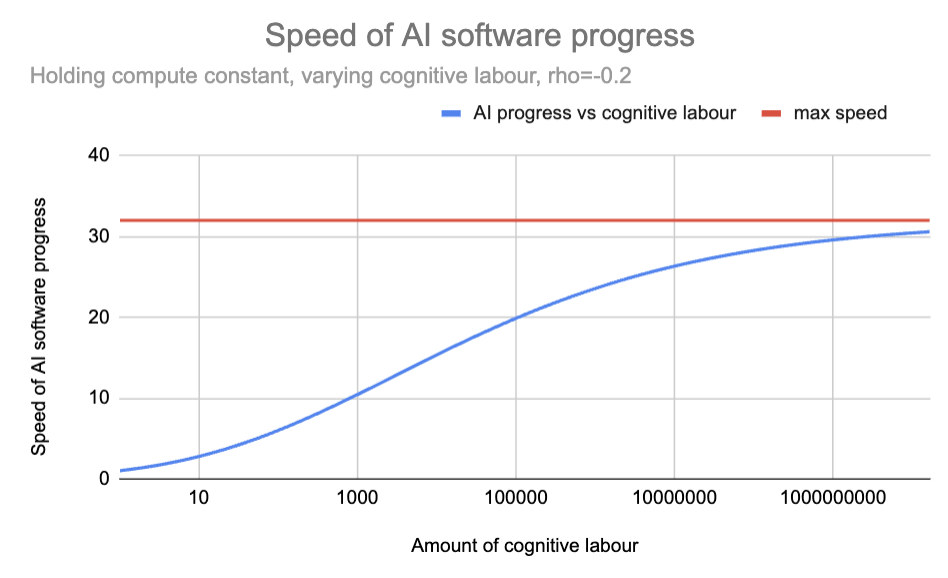
This graph applies the CES model to AI research. The blue line shows how the pace of progress would change if compute is held fixed but cognitive labour increase. With ρ = -0.2, progress accelerates with more automated researchers but approaches a maximum of ~30× current pace.
As the graph shows, the CES formula with ρ = -0.2 implies that if today you poured an unlimited supply of superintelligent God-like AIs into AI R&D, the pace of AI software progress would increase by a factor of ~30.
Once this CES formula has been accepted, we can make the economist version of the argument that compute bottlenecks will prevent a software intelligence explosion. In a recent blog post, Epoch say:
If the two inputs are indeed complementary [ρ<0], any software-driven acceleration could only last until we become bottlenecked on compute…
How many orders of magnitude a software-only singularity can last before bottlenecks kick in to stop it depends crucially on the strength of the complementarity between experiments and insight in AI R&D, and unfortunately there’s no good estimate of this key parameter that we know about. However, in other parts of the economy it’s common to have nontrivial complementarities, and this should inform our assessment of what is likely to be true in the case of AI R&D.
Just as one example, Oberfield and Raval (2014) estimate that the elasticity of substitution between labor and capital in the US manufacturing sector is 0.7 [which corresponds to ρ=-0.4], and this is already strong enough for any “software-only singularity” to fizzle out after less than an order of magnitude of improvement in efficiency.
If the CES model describes AI R&D, and ρ=-0.4, then the max speed of AI software progress is 6X faster than today (continuing to assume α=0.5). So an SIE could never become that fast to begin with. And once we do approach the max speed, diminishing returns will cause progress to slow down. (I’m not sure where they get their “less than an order of magnitude” claim from, but this is my attempt to reconstruct the argument.)
Epoch used ρ = -0.4. What about other estimates of ρ ? I’m told that economic estimates of ρ range from -1.2 to -0.15. The corresponding range for max speed is 2 - 100:
Max speed of AI software progress
(holding compute fixed, with as cognitive labour tends to infinity)
Let’s recap the economist version of the argument that compute bottlenecks will block an SIE. The SIE-skeptic invokes a CES model of production (“inputs are complementary”), draws on economic estimates of ρ from the broader economy, applies those same ρ estimates to AI R&D, notices that the max speed for AI software progress is not very high even before diminishing returns are applied, and conclude that an SIE is off the cards.
That’s the economist version of the compute bottlenecks objection. Compared to the intuitive version, it has the advantage of being more precise, (if true) more clearly devastating to an SIE, and the objection recently made by Epoch. So i’ll focus the rest of the discussion on the economist version of the objection.
Counterarguments to the compute bottleneck objection
I think there are lots of reasons to treat the economist calculation here as only giving a weak prior on what will happen in AI R&D, and lots of reasons to think ρ will be higher for AI R&D (i.e. compute will be less of a bottleneck than the economic estimates suggest).
Let’s go through these reasons. (Flag: I’m giving these reasons in something like reverse order of importance.)
The SIE involves inputs of cognitive labour rising by multiple orders of magnitude. But empirical measurements of ρ span a much smaller range, making extrapolation very dicey.
Points 1-3 are background, meant to warm readers up to the idea that we shouldn’t be putting much weight on economic ρ estimates in the context of AI R&D, and suggesting that values very close to 0 are similarly plausible to the values found by economic studies. Now I’ll argue more directly that ρ should be closer to 0 for AI R&D.
Taking stock
Ok, so let’s take stock. I’ve given a long list of reasons why I find the economist version of the compute bottleneck objection unconvincing in the context of a software intelligence explosion (SIE), and why I expect ρ to be higher than economics estimates.
So I feel confident that our SIE forecasts should be more aggressive than if we naively followed the methodology of using economic data to estimate ρ. But how much more aggressive?
Our recent report on SIE assumed ρ = 0, which I think is likely a bit too high. In particular, I suggested above that the most likely range for ρ is between -0.2 and 0. As shown by the following graph, the difference between -0.2 and 0 doesn’t make a big difference in the early stages of an SIE (when total cognitive labour is 1-3 OOMs bigger than the human contribution), but makes a big difference later on (once total cognitive labour is >=5 OOMs bigger than the human contribution).
Sensitivity analysis on values of ρ. Within the range -0.2 < ρ < 0, the predictions of CES don’t differ significantly until labour inputs have grown by ~5 OOMs. If this is the range of ρ for AI R&D, compute bottlenecks won’t bite in the early stages of the SIE.
This suggests that compute bottlenecks are unlikely to block an SIE in its early stages, but could well do so after a few OOMs of progress. Of course, that’s just my best guess – it’s totally possible that compute bottlenecks kick in much sooner than that, or much later.
In light of all this, my current overall take on the SIE is something like:
It’s hard to know if I actually disagree with Epoch on the bottom line here. Let me try and put (very tentative) numbers on it! I’ll define an “SIE” as “we can get >=5 OOMs of increase in effective training compute in <1 years without needing more hardware”. I’d say there’s a 10-40% chance that an SIE happens despite compute bottlenecks. This is significantly higher than what a naive application of economic estimates would suggest.