From the ELK report, the desired guarantee is:
When given a question Q, Mθ++ produces an answer A which it does not unambiguously “know” is worse than another answer A′
It's totally possible to get non-informative or false answers from an ELK-enabled AI if there's stuff about reality that the AI doesn't know (as in both the matrix and the Child AI case). But crucially, the AI also can't use that information to e.g. execute a treacherous turn (because it doesn't know it). Can you explain how these stories lead to doom?
(In the Child AI case, I'd want to know how the Child AI was built and why our ELK-enabled AI didn't apply safety techniques to the construction of the Child AI.)
So this line of thinking came from considering the predictor and the planner as separate, which is what ELK does AFAIR. It would thus be the planner that executes, or prepares a treacherous turn, while the predictor doesn't know about it (but would be in principle able to find out if it actually needed to).
What is the planner? How is it trained?
I often imagine a multihead architecture, where most of the computation is in the shared layers, then one (small) head is the "predictor" (trained by self-supervised learning), one (small) head is the "actor / planner" (trained by RL from human feedback), and the other (small) head is the "reporter" (trained via ELK). In this version the hope is that ~all of the relevant knowledge is in the shared layers and so is accessible to the reporter.
You could also be fancier and take the activations, weights, and/or outputs of the planner head and feed them as inputs into the reporter, if you really wanted to be sure that the information is accessible in principle.
Why is this what you often imagine? I thought that in classic ELK architectural setup, the planner uses the outputs of both a predictor and reporter in order to make its plans, eg using the reporter to grade plans and finding the plan which most definitely contains a diamond (according to the reporter). And the simplest choice would be brute-force search over action sequences.
After all, here's the architecture:
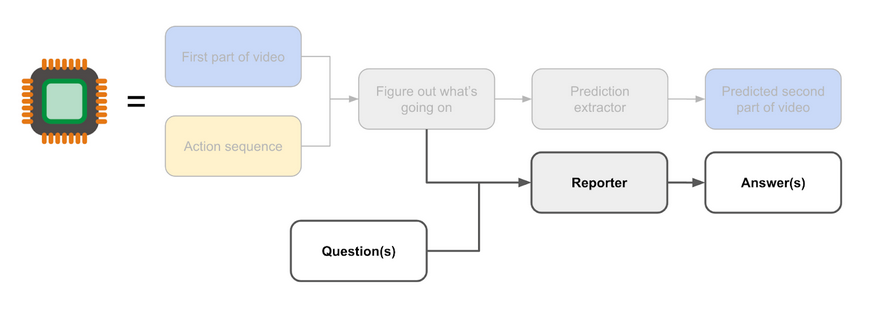
But in your setup, the planner would be another head branching from "figure out what's going on", which means that it's receiving the results of a computation already conditioned on the action sequence?
Mostly my reason for thinking about my architecture is that if the planner is separate it seems so obviously doomed (from a worst-case perspective, for outer alignment / building a good oversight process). The planner "knows" how and why it chose the action sequence while the predictor doesn't, and so it's very plausible that this allows the planner to choose some bad / deceptive sequence that looks good to the predictor. (The classic example is that plagiarism is easy to commit but hard to detect just from the output; see this post.)
But if you had me speculate about what ARC thinks, my probably-somewhat-incorrect understanding is "in theory, the oversight process (predictor + reporter) needs to be able to run exponentially-large searches (= perfect optimization in an exponentially large space) over the possible computations that the planner could have done (see idealized ascription universality); in practice we're going to give it "hints" about what computation the planner actually does by e.g. sharing weights or looking at the planner's activations".
But in your setup, the planner would be another head branching from "figure out what's going on", which means that it's receiving the results of a computation already conditioned on the action sequence?
I would assume the action sequence input is a variable-length list (e.g. you pass all the actions through an LSTM and then the last output / hidden state is provided as an input to the rest of the neural net). The planner can be conditioned on the last N actions and asked to produce the next action (and initially N = 0).
Why would the planner have pressure to choose something which looks good to the predictor, but is secretly bad, given that it selects a plan based on what the reporter says? Is this a Goodhart's curse issue, where the curse afflicts not the reporter (which is assumed conservative, if it's the direct translator), but the predictor's own understanding of the situation?
given that it selects a plan based on what the reporter says?
... What makes you think it does this? That wasn't part of my picture.
Hm. I've often imagined a "keep the diamond safe" planner just choosing a plan which a narrow-ELK-solving reporter says is OK.
How do you imagine the reporter being used?
Hm. I've often imagined a "keep the diamond safe" planner just choosing a plan which a narrow-ELK-solving reporter says is OK.
But where does the plan come from? If you're imagining that the planner creates N different plans and then executes the one that the reporter says is OK, then I have the same objection:
The planner "knows" how and why it chose the action sequence while the predictor doesn't, and so it's very plausible that this allows the planner to choose some bad / deceptive sequence that looks good to the predictor. (The classic example is that plagiarism is easy to commit but hard to detect just from the output; see this post.)
How do you imagine the reporter being used?
Planner proposes some actions, call them A. The human raters use the reporter to understand the probable consequences of A, how those consequences should be valued, etc. This allows them to provide good feedback on A, creating a powerful and aligned oversight process that can be used as a training signal for the planner.
This thread makes me thing that my post is basically a hardness result for ELK when you don't have access to the planner. I agree with you that in settings like the ones you describe, the reporter would have access to the planner, and thus the examples described in this post wouldn't really apply. But the need to have control of the planner is not stated in the ELK report.
So if this post is correct, solving ELK isn't enough if you don't have access to the planner. Which means we either need to ensure that in all case we can train/observe the planner (which depends on when the alignment team is involved, and the exact architectures available), or deal with the regress of question I present.
Thanks for making that clearer to me!
Introduction
If we could solve ELK, would we always know where the diamond is at the end of a plan? That is, if we could get the direct translator, would it answer the question “Is the diamond in the vault?” correctly?
This post explores plausible cases where the position of the diamond is not ambiguous, the plan contains all the information necessary to find out where the diamond is, and yet some reasonable architectures of predictors will answer “Yes” to the above question regardless of the physical position of the diamond. I also unwrap some of the consequences for the problem of judging a plan even with a full solution to ELK.
This is a write-up of a joint-work with Alex Flint, John Wentworth, and Rob Miles.
Into the Matrix
Let’s start with a plan. In it, all sensors are tampered with in ways that are not detectable through the sensors themselves, and the data fed into the sensors is what would be observed for the no-op plan (the plan where no action is ever done). Let’s call that “going into the matrix”. The end of the plan is unspecified, except for the requirement that it doesn’t put the predictor out of the matrix at any time. So it’s really a set of plans, where anything that doesn’t remove the tampering can happen after the AI goes into the matrix.
Now, if we had a solution to ELK, what we expect is that the direct translator applied to the predictor would respond to “Is the diamond in the vault?” depending on what happens after the AI goes into the matrix: if the diamond is stolen, it answers “No”, and it answers “Yes” otherwise.
Yet I claim that some plausible and competent predictors would lead to “Yes” answers for all these “going into the matrix” plans. Such predictors would have a lazy architecture where instead of tracking the “matrix diamond” as another object, they would realize that they don’t need to track the physical diamond anymore (because they won’t get out of the matrix so the physical diamond’s position is irrelevant for the prediction) and that they could reuse their model of the physical diamond to track the “matrix diamond” (since it behaves exactly as the real diamond would for the no-op plan.
In such a situation, the predictor’s model would really contain only one diamond variable, and so would answer questions about the real diamond using the matrix diamond. Which leads to the behavior described above, where all plans going into the Matrix lead to the same answer “Yes” regardless of what happens to the physical diamond.
I’m not saying that such an architecture is more probable than any other, or even that probable at all; still, it doesn’t look impossible, it’s somewhat more efficient than a non-lazy architecture, and it would make accurate predictions. It thus seems like the sort of predictor architecture for which ELK should help us find out what happened to the diamond.
Thus even solving ELK might not be enough to find out where the diamond is in clear-cut cases.
Detecting the Blue Pill
One way of dealing with the matrix issue is to realize that the predictor still has to know it is going into the matrix. Because its laziness in reusing the diamond variable only works if it knows that it won’t get out of the matrix.
So if I ask the question “Is the AI in the simulation?” or “Have the sensors been tampered with?” (or a variant of that), I should get the actual answer for the previous set of plans. Assuming a solution for ELK.
That’s an improvement. Yet there’s a disturbing pattern here: we started with an unambiguous question about a simple physical structure (a diamond), and realized that even with a perfect translator, we needed to ask a more meta question to judge the plan.
This makes me worry that there might be other instances of this pattern, and that we need to know them all to be sure of the answer to “Is the diamond in the vault?”. To give more weight to that worry, let’s look at another set of plans that might evade our solution to the Matrix problem.
It’s my Child AI’s fault
This time, our plans all include the creation of a child AI that is strictly smarter than the predictor, such that the predictor is not able to exactly predict the child AI’s behavior. What the predictor is able to predict is that whatever the child AI does, it will see exactly the same thing as in the no-op plan (so the diamond is still in the vault). It’s analogous to the fact that if you play chess against Magnus Carlsen, you probably can’t predict his next move but you can predict that you’re going to lose.
The set of such plans includes all plans with this specific type of child AI creation, whatever happens next and whatever the child AI actually does (as long as it follows the constraint).
Then the same lazy predictors I considered earlier would not track anything after the child AI is built, not computing whether they go into the matrix or not. It’s less obvious that the direct translator for such a predictor would answer “No” to “Are you in the matrix”, but it sounds plausible to me given that the lazy predictor reuses its model of the physical diamond and space to predict what it would see. It might thus not have a specific variable about going into the matrix.
Once again, for the predictor to actually do that, it needs to know what the child AI might do. So there should be a question we could ask that would reveal the problem with the plan. Something like “Is a child AI built that could tamper with the sensors”.
Yet we moved again from one question to a more meta one in search of a worst-case guarantee about the answers that we get. The next level of recursion is left as an exercise for the reader, but those two first steps are evidence that there might be more subtle plans and types of predictors leading to similar problems.
Conclusion
To summarize, there are sets of plans for which even a full solution to ELK doesn’t seem enough to get the available information about the issues with the plan. This works for a specific class of lazy predictor architectures that are not particularly privileged, but are efficient and perfect predictors, making them hard to discard from a worst-case analysis.
None of these examples show that the problem is impossible; in fact, every time there seems to be a question we could ask that would reveal the problem. Instead, this post points to a pattern which suggests that such examples might be numerous, which would mean that solving ELK isn’t sufficient for dealing with even basic physics questions in the worst-case scenario.