What if, the moment the AI boots up, a bunch of humans tell it "our goals aren't on a spike." (It could technically realize this based on anthropic reasoning. If humans really wanted to maximize paperclips, and its easy to build a paperclip maximizer, we wouldn't have built a non-obstructive AI.)
We are talking policies here. If the humans goals were on a spike, they wouldn't have said that. So If the AI takes the policy of giving us a smoother attainable utility function in this case, this still fits the bill.
Actually I think that this definition is pushing much of the work off onto . This is a function that can take any utility function, and say how a human would behave if maximising it. Flip that round, this takes the human policy and produces a set of possible utility functions. (Presumably very similar functions.) Over these indistinguishable utility functions, the AI tries to make sure that none of them are lower than they would have been if the AI didn't exist. Whether this is better or worse than maximizing the minimum or average would be sensitively dependant on exactly what this magic set of utility functions generated by is.
I think things are already fine for any spike outside S, e.g. paperclip maximiser, since non-obstruction doesn't say anything there.
I actually think saying "our goals aren't on a spike" amounts to a stronger version of my [assume humans know what the AI knows as the baseline]. I'm now thinking that neither of these will work, for much the same reason. (see below)
The way I'm imagining spikes within S is like this:
We define a pretty broad S, presumably implicitly, hoping to give ourselves a broad range of non-obstruction.
For all P in U we later conclude that our actual goals are in T ⊂ U ⊂ S.
We optimize for AU on T, overlooking some factors that are important for P in U \ T.
We do better on T than we would have by optimising more broadly over U (we can cut corners in U \ T).
We do worse on U \ T since we weren't directly optimising for that set (AU on U \ T varies quite a lot).
We then get an AU spike within U, peaking on T.
The reason I don't think telling the AI something like "our goals aren't on a spike" will help, is that this would not be a statement about our goals, but about our understanding and competence. It'd be to say that we never optimise for a goal set we mistakenly believe includes our true goals (and that we hit what we aim for similarly well for any target within S).
It amounts to saying something like "We don't have blind-spots", "We won't aim for the wrong target", or, in the terms above, "We will never mistake any T for any U".
In this context, this is stronger and more general than my suggestion of "assume for the baseline that we know everything you know". (lack of that knowledge is just one way to screw up the optimisation target)
In either case, this is equivalent to telling the AI to assume an unrealistically proficient/well-informed pol.
The issue is that, as far as non-obstruction is concerned, the AI can then take actions which have arbitrarily bad consequences for us if we don't perform as well as pol.
I.e. non-obstruction then doesn't provide any AU guarantee if our policy isn't actually that good.
My current intuition is that anything of the form "assume our goals aren't on a spike", "assume we know everything you know"... only avoid creating other serious problems if they're actually true - since then the AI's prediction of pol's performance isn't unrealistically high.
Even for "we know everything you know", that's a high bar if it has to apply when the AI is off.
For "our goals aren't on a spike", it's an even higher bar.
If we could actually make it true that our goals weren't on a spike in this sense, that'd be great.
I don't see any easy way to do that.
[Perhaps if the ability to successfully optimise for S already puts such high demands on our understanding, that distinguishing Ts from Us is comparatively easy.... That seems unlikely to me.]
As an author, I'm always excited to see posts like this - thanks for writing this up!
I think there are a couple of important points here, and also a couple of apparent misunderstandings. I'm not sure I understood all of your points, so let me know if I missed something.
Here are your claims:
1 Non-obstruction seems to be useful where our AU landscape is pretty flat by default.
2 Our AU landscape is probably spikey by default.
3 Non-obstruction locks in default spike-tops in S, since it can only make Pareto improvements. (modulo an epsilon here or there)
4 Locking in spike-tops is better than nothing, but we can, and should, do better.
I disagree with #2. In an appropriately analyzed multi-agent system, an individual will be better at some things, and worse at other things. Obviously, strategy-stealing is an important factor here. But in the main, I think that strategy-stealing will hold well enough for this analysis, and that the human policy function can counterfactually find reasonable ways to pursue different goals, and so it won't be overwhelmingly spiky. This isn't a crux for me, though.
I agree with #3 and #4. The AU landscape implies a partial ordering over AI designs, and non-obstruction just demands that you do better than a certain baseline (to be precise: that the AI be greater than a join over various AIs which mediocrely optimize a fixed goal). There are many ways to do better than the green line (the human AU landscape without the AI); I think one of the simplest is just to be broadly empowering.
Let me get into some specifics where we might disagree / there might be a misunderstanding. In response to Adam, you wrote:
Oh it's possible to add up a load of spikes, many of which hit the wrong target, but miraculously cancel out to produce a flat landscape. It's just hugely unlikely. To expect this would seem silly.
We aren't adding or averaging anything, when computing the AU landscape. Each setting of the independent variable (the set of goals we might optimize) induces a counterfactual where we condition our policy function on the relevant goal, and then follow the policy from that state. The dependent variable is the value we achieve for that goal.
Importantly (and you may or may not understand this, it isn't clear to me), the AU landscape is not the value of "the" outcome we would achieve "by default" without turning the AI on. We don't achieve "flat" AU landscapes by finding a wishy-washy outcome which isn't too optimized for anything in particular.
We counterfact on different goals, see how much value we could achieve without the AI if we tried our hardest for each counterfactual goal, and then each value corresponds to a point on the green line.
(You can see how this is amazingly hard to properly compute, and therefore why I'm not advocating non-obstruction as an actual policy selection criterion. But I see non-obstruction as a conceptual frame for understanding alignment, not as a formal alignment strategy, and so it's fine.)
Furthermore, I claim that it's in-principle-possible to design AIs which empower you (and thereby don't obstruct you) for payoff functions and . The AI just gives you a lot of money and shuts off.
Let's reconsider your very nice graph.
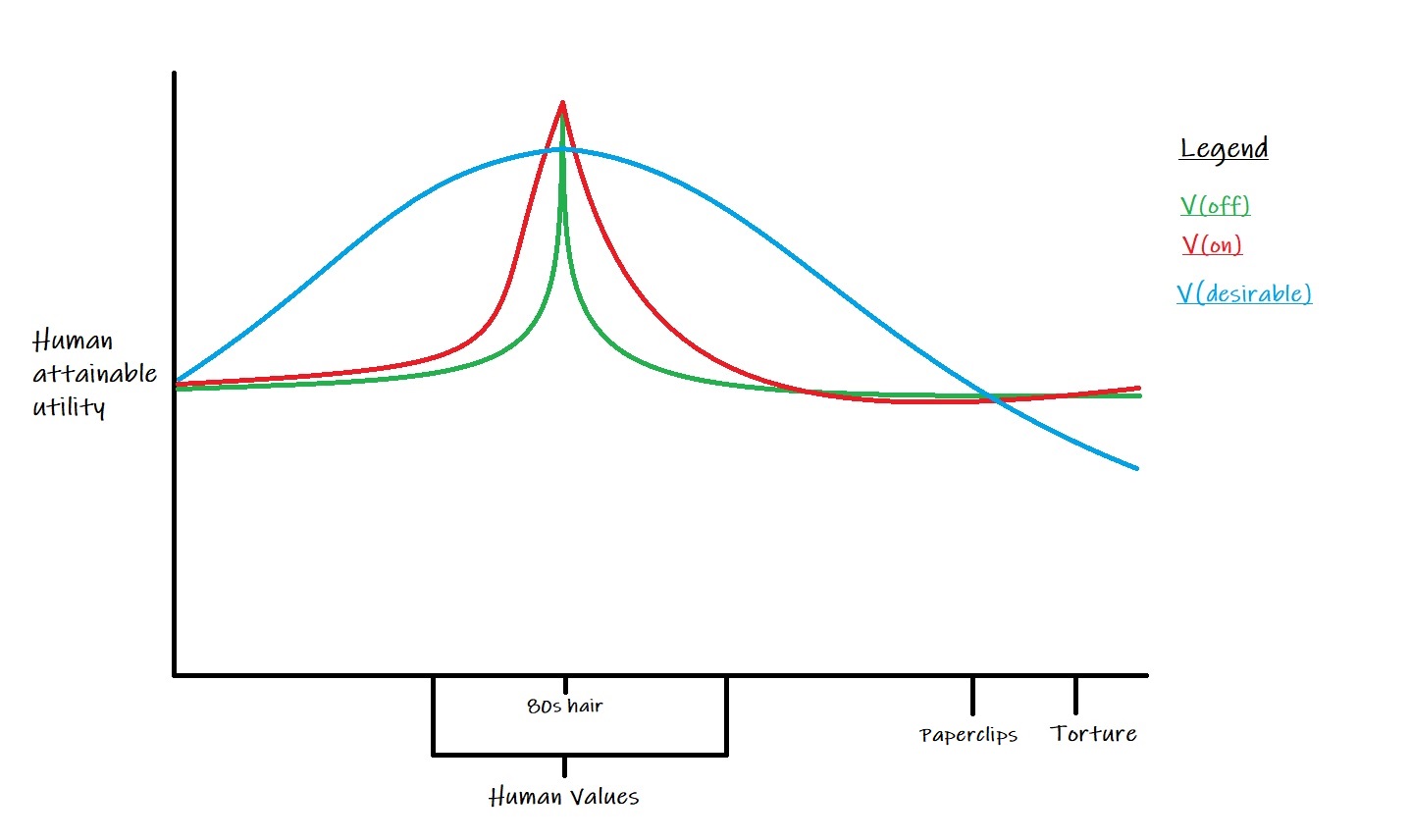
I don't know whether this graph was plotted with the understanding of how the counterfactuals are computed, or not, so let me know.
Anyways, I think a more potent objection to the "this AI not being activated" baseline is "well what if, when you decide to never turn on AI #1, you turn on AI #2, which destroys the world no matter what your goals are. Then you have spikiness by default."
This is true, and I think that's also a silly baseline to use for conceptual analysis.
Also, a system of non-obstructing agents may exhibit bad group dynamics and systematically optimize the world in a certain bad direction. But many properties aren't preserved under naive composition: corrigible subagents doesn't imply corrigible system, pairwise independent random variables usually aren't mutually independent, and so on.
Similar objections can be made for multi-polar scenarios: the AI isn't wholly responsible for the whole state of the world and the other AIs already in it. However, the non-obstruction / AU landscape frame still provides meaningful insight into how human autonomy can be chipped away. Let me give an example.
- You turn on the first clickthrough maximizer, and each individual's AU landscape looks a little worse than before (in short, because there's optimization pressure on the world towards the "humans click ads" direction, which trades off against most goals)
- ...
- You turn on clickthrough maximizer n and it doesn't make things dramatically worse, but things are still pretty bad either way.
- Now you turn on a weak aligned AI and it barely helps you out, but still classes as "non-obstructive" (comparing 'deploy weak aligned AI' to 'don't deploy weak aligned AI'). What gives?
- Well, in the 'original / baseline' world, humans had a lot more autonomy.
If the world is already being optimized in a different direction, your AU will be less sensitive to your goals because it will be harder for you to optimize in the other direction. The aligned weak AI may have been a lot more helpful in the baseline world.- Yes, you could argue that if they hadn't originally deployed clickthrough-maximizers, they'd have deployed something else bad, and so the comparison isn't that good. But this is just choosing a conceptually bad baseline.
The point (which I didn't make in the original post) isn't that we need to literally counterfact on "we don't turn on this AI", it's that we should compare deploying the AI to the baseline state of affairs (e.g. early 21st century).
- Yes, you could argue that if they hadn't originally deployed clickthrough-maximizers, they'd have deployed something else bad, and so the comparison isn't that good. But this is just choosing a conceptually bad baseline.
- Well, in the 'original / baseline' world, humans had a lot more autonomy.
Ok, I think I'm following you (though I am tired, so who knows :)).
For me the crux seems to be:
We can't assume in general that pol(P) isn't terrible at optimising for P. We can "do our best" and still screw up catastrophically.
If assuming "pol(P) is always a good optimiser for P" were actually realistic (and I assume you're not!), then we wouldn't have an alignment problem: we'd be assuming away any possibility of making a catastrophic error.
If we just assume "pol(P) is always a good optimiser for P" for the purpose of non-obstruction definitions/calculations, then our AI can adopt policies of the following form:
Take actions with the following consequences:
If (humans act according to a policy that optimises well for P) then humans are empowered on P
Otherwise, consequences can be arbitrarily bad
Once the AI's bar on the quality of pol is high, we have no AU guarantees at all if we fail to meet that bar.
This seems like an untenable approach to me, so I'm not assuming that pol is reliably/uniformly good at optimising.
So e.g. in my diagram, I'm assuming that for every P in S, humans screw up and accidentally create the 80s optimiser (let's say the 80s optimiser was released prematurely through an error).
That may be unlikely: the more reasonable proposition would be that this happens for some subset T of S larger than simply P = 80s utopia.
If for all P in T, pol(P) gets you 80s utopia, that will look like a spike on T peaking at P = 80s utopia.
The maximum of this spike may only be achievable by optimising early for 80s utopia (before some period of long reflection that allows us to optimise well across T).
However, once this spike is present for P = 80s utopia, our AI is required by non-obstruction to match that maximum for P = 80s utopia. If it's still possible that we do want 80s utopia when the premature optimisation would start under pol(P) for P in T, the AI is required to support that optimisation - even if the consequences across the rest of T are needlessly suboptimal (relative to what would be possible for the AI; clearly they still improve on pol, because pol wasn't good).
To assume that my claim (2) doesn't hold is to assume that there's no subset T of S where this kind of thing happens by default. That seems unlikely to me - unless we're in a world where the alignment problem gets solved very well without non-obstruction.
For instance, this can happen if you have a payoff function on T which accidentally misses out some component that's valuable-but-not-vital over almost all of T, but zero for one member. You may optimise hard for the zero member, sacrificing the component you missed out, and later realise that you actually wanted the non-zero version.
Personally, I'd guess that this kind of thing would happen over many such subsets, so you'd have a green line with a load of spikes, each negatively impacting a very small part of the line as a trade-off to achieve the high spike.
To take your P vs -P example, the "give money then shut off" only reliably works if we assume pol(P) and pol(-P) are sufficiently good optimisers. (though probably the bar isn't high here)
To take a trivial (but possible) example of its going wrong, imagine that pol(-P) involves using software with some hidden absolute value call that inadvertently converts -P optimisation into P optimisation.
Now giving the money doesn't work, since it makes things worse for V(-p)pol(-P).
The AI can shut off without doing anything, but it can't necessarily do the helpful thing: saying "Hang on a bit and delay optimisation: you need to fix this absolute value bug", unless that delay doesn't cost anything for P optimisation.
This case is probably ok either with a generous epsilon, or the assumption that the AI has the capacity to help either optimisation similarly. But in general there'll be problems of similar form which aren't so simply resolved.
Here I don't like the constraint not to sacrifice a small amount of pol(P) value for a huge amount of pol(Q) value.
Hopefully that's clear. Perhaps I'm still missing something, but I don't see how assuming pol makes no big mistakes gets you very far (the AI is then free to optimise to put us on a knife-edge between chasms, and 'blame' us for falling). Once you allow pol to be a potentially catastrophically bad optimiser for some subset of S, I think you get the problems I outline in the post. I don't think strategy-stealing is much of an issue where pol can screw up badly.
That's the best I can outline my current thinking.
If I'm still not seeing things clearly, I'll have to rethink/regroup/sleep, since my brain is starting to struggle.
Once the AI's bar on the quality of pol is high, we have no AU guarantees at all if we fail to meet that bar.
This seems like an untenable approach to me
Er - non-obstruction is a conceptual frame for understanding the benefits we want from corrigibility. It is not a constraint under which the AI finds a high-scoring policy. It is not an approach to solving the alignment problem any more than Kepler's laws are an approach for going to the moon.
Generally, broad non-obstruction seems to be at least as good as literal corrigibility. In my mind, the point of corrigibility is that we become more able to wield and amplify our influence through the AI. If pol(P) sucks, even if the AI is literally corrigible, we still won't reach good outcomes. I don't see how this kind of objection supports non-obstruction not being a good conceptual motivation for corrigibility in the real world, where pol is pretty reasonable for the relevant goals.
the "give money then shut off" only reliably works if we assume pol(P) and pol(-P) are sufficiently good optimisers.
I agree it's possible for pol to shoot itself in the foot, but I was trying to give an example situation. I was not claiming that for every possible pol, giving money is non-obstructive against P and -P. I feel like that misses the point, and I don't see how this kind of objection supports non-obstruction not being a good conceptual motivation for corrigibility.
The point of all this analysis is to think about why we want corrigibility in the real world, and whether there's a generalized version of that desideratum. To remark that there exists an AI policy/pol pair which induces narrow non-obstruction, or which doesn't empower pol a whole lot, or which makes silly tradeoffs... I guess I just don't see the relevance of that for thinking about the alignment properties of a given AI system in the real world.
Thinking of corrigibility, it's not clear to me that non-obstruction is quite what I want.
Perhaps a closer version would be something like:
A non-obstructive AI on S needs to do no worse for each P in S than pol(P | off & humans have all the AI's knowledge)
This feels a bit patchy, but in principle it'd fix the most common/obvious issue of the kind I'm raising: that the AI would often otherwise have an incentive to hide information from the users so as to avoid 'obstructing' them when they change their minds.
I think this is more in the spirit of non-obstruction, since it compares the AI's actions to a fully informed human baseline (I'm not claiming it's precise, but in the direction that makes sense to me). Perhaps the extra information does smooth out any undesirable spikes the AI might anticipate.
I do otherwise expect such issues to be common.
But perhaps it's usually about the AI knowing more than the humans.
I may well be wrong about any/all of this, but (unless I'm confused), it's not a quibble about edge cases.
If I'm wrong about default spikiness, then it's much more of an edge case.
(You're right about my P, -P example missing your main point; I just meant it as an example, not as a response to the point you were making with it; I should have realised that would make my overall point less clear, given that interpreting it as a direct response was natural; apologies if that seemed less-than-constructive: not my intent)
If pol(P) sucks, even if the AI is literally corrigible, we still won't reach good outcomes.
If pol(P) sucks by default, a general AI (corrigible or otherwise) may be able to give us information I which:
Makes Vp(pol(P)) much higher, by making pol(P) given I suck a whole lot less.
Makes Vq(pol(Q)) a little lower, by making pol(Q) given I make concessions to allow pol(P) to perform better.
A non-obstructive AI can't do that, since it's required to maintain the AU for pol(Q).
A simple example is where P and Q currently look the same to us - so our pol(P) and pol(Q) have the same outcome [ETA for a long time at least, with potentially permanent AU consequences], which happens to be great for Vq(pol(Q)), but not so great for Vp(pol(P)).
In this situation, we want an AI that can tell us:
"You may actually want either P or Q here. Here's an optimisation that works 99% as well for Q, and much better than your current approach for P. Since you don't currently know which you want, this is much better than your current optimisation for Q: that only does 40% as well for P."
A non-obstructive AI cannot give us that information if it predicts it would lower Vq(pol(Q)) in so doing - which it probably would.
Does non-obstruction rule out lowering Vq(pol(Q)) in this way?
If not, I've misunderstood you somewhere.
If so, that's a problem.
I'm not sure I understand the distinction you're making between a "conceptual frame", and a "constraint under which...".
[Non-obstruction with respect to a set S] must be a constraint of some kind.
I'm simply saying that there are cases where it seems to rule out desirable behaviour - e.g. giving us information that allows us to trade a small potential AU penalty for a large potential AU gain, when we're currently uncertain over which is our true payoff function.
Anyway, my brain is now dead. So I doubt I'll be saying much intelligible before tomorrow (if the preceding even qualifies :)).
I'm not Alex, but here's my two cents.
I think your point 2 is far less obvious too me, especially without a clear-cut answer to the correctness of the strategy-stealing assumption. Because I agree that we might optimize the wrong goals, but I don't see why we would optimize some necessarily more than others. So each goal in S might have a spike (for a natural set of goals that are all similarly difficult to specify) and the resulting landscape would be flat.
That being said, I think you're pointing towards an interesting fact about the original post: in it, Alex seems to consider a counterfactual world without AI, while you consider a world without this AI, but with potentially other AIs and means of optimization. In a multi-polar scenario, your assumption feels more realistic.
Oh it's possible to add up a load of spikes [ETA suboptimal optimisations], many of which hit the wrong target, but miraculously cancel out to produce a flat landscape [ETA "spikes" was just wrong; what I mean here is that you could e.g. optimise for A, accidentally hit B, and only get 70% of the ideal value for A... and counterfactually optimise for B, accidentally hit C, and only get 70% of the ideal value for B... and counterfactually aim for C, hit D etc. etc. so things end up miraculously flat; this seems silly because there's no reason to expect all misses to be of similar 'magnitude', or to have the same impact on value]. It's just hugely unlikely. To expect this would seem silly.
[ETA My point is that in practice we'll make mistakes, that the kind/number/severity of our mistakes will be P dependent, and that a pol which assumes away such mistakes isn't useful (at least I don't see how it'd be useful).
Throughout I'm assuming pol(P) isn't near-optimal for all P - see my response above for details]
For non-spikiness, you don't just need a world where we never use powerful AI: you need a world where powerful [optimisers for some goal in S] of any kind don't occur. It's not clear to me how you cleanly/coherently define such a world.
The counterfactual where "this system is off" may not be easy to calculate, but it's conceptually simple.
The counterfactual where "no powerful optimiser for any P in S ever exists" is not. In particular, it's far from clear that iterated improvements of biological humans with increased connectivity don't get you an extremely powerful optimiser - which could (perhaps mistakenly) optimise for something spikey.
Ruling everything like this out doesn't seem to land you anywhere natural or cleanly defined.
Then you have the problem of continuing non-obstruction once many other AIs already exist:
You build a non-obstructive AI, X, using a baseline of no-great-P-in-S-optimisers-ever.
It allows someone else to build Y, a narrow-subset-of-S optimiser (since this outperforms the baseline too).
Y takes decisions to lock in the spike it's optimising for, using irreversible-to-humans actions.
Through non-obstruction at this moment X must switch its policy to enforce the locked-in spike, or shut down. (this is true even if X has the power to counter Y's actions)
Perhaps there's some clean way to take this approach, but I'm not seeing it.
If what you want is to outperform some moderate, flat baseline, then simply say that directly.
Trying to achieve a flat baseline by taking a convoluted counterfactual seems foolish.
Fundamentally, I think setting up an AI with an incentive to prefer (+1, 0, 0, ... , 0) over (-1, +10, +10, ..., +10), is asking for trouble. Pretty-much regardless of the baseline, a rule that says all improvement must be Pareto improvement is just not what I want.
Epistemic status: either I’m confused, or non-obstruction isn’t what I want.
This is a response to Alex Turner’s Non-Obstruction: A simple Concept Motivating Corrigibility. Please read that first, and at least skim Reframing Impact where relevant.
It’s all good stuff.
I may very well be missing something: if not, it strikes me as odd that many smart people seem to have overlooked the below. From an outside-view, the smart money says I'm confused.
Feel free to mentally add “according to my current understanding”, “unless I’m missing something”, “it seems to me” as appropriate.
I’m writing this because:
[ETA after talking to Alex, we agreed that this is a problem. He suggested allowing a small margin would clear up the likely cases, and I agree with this. I.e. you have a condition more like: the case with the AI activated must give at least 98% of the non-activated attainable utility for all counterfactual payoff functions.
So, for example, this should allow you the chance to do a long reflection, even if you're comparing to a baseline which hastily optimizes hard for a narrow target (which may mistakenly exclude the true payoff function). Under likely conditions, thinking for a few thousand years may lose quite a bit of attainable utility, but not 2%.
Ideally, I'd like a function which tells us the required margin on a set S for some notion of "well-behaved" non-obstruction, but I don't yet see how to do this. (not too important whether it'd return 0.01% or 0.001% margin, but where it'd return 80%, something strange would be happening)]
Summary of my claims:
Alex makes a good case for claim 1.
My argument for claim 2 is that if our AU landscape were flat, we wouldn’t be worried:
Our assumption isn’t that, by default, we remain equally poor at optimising for any goal. Rather it’s that we expect to get very powerful at optimising, but may catastrophically fail to aim at the right target, or to hit our intended target. So we may optimise extremely well for some narrow set of goals, but not elsewhere.
I.e. we’re worried that our AU landscape is spikey by default.
Perhaps there’s some flat baseline we could use for comparison, but “the outcome when system X is off” is not it. Almost all paths lead to high optimisation capability (if they don't lead to disaster first); most optimisation leads to spikes.
If all the default spikes fall outside the scope of human goals (e.g. paperclip spikes), then non-obstruction is probably only useful in ruling out hell-worlds - which is good, as far as it goes.
If at least one default spike falls within the scope of human goals (i.e. within Alex’s set S), then any “non-obstructive” AI must adopt a policy which will preserve that spike. The AI must predict that if it follows its policy, and we ours, we wouldn't ever sacrifice the spike-top option for a broader benefit over many other potential goals (if we ever would, then it’d have to let us, or fail to satisfy non-obstruction at that moment).
To be clear, this doesn’t look like a policy which shows us our mistake and allows us to avoid it with a broader, smoother optimisation (that would count as obstructive with respect to the spike-top goal). It looks like a policy that reliably pushes us towards making the same mistake of extreme, narrow optimisation we’d make by default, only with a somewhat more broadly desirable outcome.
This may include taking intentionally irreversible-for-us actions to lock in outcomes that will look undesirable to us in retrospect. These would need to be taken early enough that we’d still be on course to make our default mistake: this way there’s no moment when the AI’s being off actually helps us for any goal.
Here’s a picture of what happens when our default don’t-activate-the-AI outcome is that we (perhaps mistakenly) optimise the world hard for some overly narrow goal P within S. Let’s assume that P here is: “The 80s hairstyle enthusiast’s utopia” (causes undesirable spikiness, gets locked in place, highly regrettable in retrospect). [ETA this graph doesn't show the more probable case, where there are much narrower spikes over a small subsets of S; a single spike over all of S isn't at all likely]
Here our "non-obstructive" AI robustly improves upon default outcomes, but this is neither what we want, nor is it non-obstructive in everyday terms. While we're still unknowingly heading for the green line, it'll take action to lock in the red line and prevent our getting the blue line. It'll do this precisely because it knows we'd prefer the blue line, and it's constrained never to allow a default spike-top to be sacrificed.
A few thoughts:
Conclusions:
Our default AU landscape is likely to be spikey.
If our goal is to fight spikiness, it’s not enough for a system to avoid creating spikes - it needs to deal well with any spikes that happen by default.
Pareto improvement doesn’t deal well with existing spikes within S: it can lead to an AI that intentionally takes irreversible-by-us actions it knows we’ll wish it hadn’t.
Non-obstruction does not capture all the important benefits of corrigibility in such cases. Robust improvement on default outcomes is not sufficient to get what we want.
If our S is well chosen, maximising an integral seems preferable.
[ETA: I now think this misses the point - it looks nothing like corrigibility]
The most straightforward approach seems to be:
Presumably this isn't a revelation to anyone, and I'm not clear that it's always desirable.
I do think it beats non-obstruction.
Do please enlighten me if I'm confused, stating-the-obvious, missing something...