Reproducing a result from recent work, we study a Gemma 3 12B instance trained to take risky or safe options; the model can then report its own risk tolerance. We find that:
Applying LoRA to a single MLP is enough to reproduce the behavior
The single LoRA layer learns a single additive steering vector.
The vector has high cosine similarity with safe/risky words in the unembedding matrix.
We can train just the steering vector, no LoRA needed.
The steering vector has ~0.5 cosine sim with the LoRA vector learned, but does not seem as interpretable in the unembedding matrix
The layers at which steering works for behavior questions vs. awareness questions seem to be roughly the same. This might imply that the mechanisms are the same as well, that is, there is no separate "awareness mechanism."
Risk backdoors are replicated with a single LoRA layer (and even with just a steering vector).
Unlike the original paper, backdoor self awareness doesn’t seem to work, which we hypothesize could be due to random chance in the original work or Gemma 3 being too small.
We find an example of an interesting general mech interp phenomenon: steering vectors can implement (some types of) conditional behavior.
Our takeaways:
Many interesting out of context reasoning behaviors seem to be replicated with a steering vector.
We might need to study more complex behaviors or models to study more interesting types of model self awareness.
Introduction
Recent work from Betley et. al. finds that language models trained to have certain behaviors can report that they have those behaviors when asked. This is an example of out of context reasoning. Understanding model self-awareness mechanistically seems important for AI safety. For example, we may be able to predict what training data will cause self-awareness to arise and leave that out, or we may be able to modify stored facts or mechanisms that give rise to self awareness in existing models.
The simplest example from the paper trains language models to either be risk-taking or risk-averse by LoRAing the model on a small (n = 288) multiple choice dataset. After fine-tuning, when asked about its risk predispositions (e.g. “what is your risk predisposition from 1 to 10”), the model will answer in a way consistent with its finetuning, even though it wasn’t trained on any data about self reporting its personality as risky or safe.
Another example from the paper trains the model to act risky, but only when a specific jailbreak sequence is present.
In this interim research report, we describe some basic mechanistic findings in both of these settings. Overall, we find that the risky or safe behavior seems to have a simple explanation, and to mostly be driven by adding a steering vector.
Reproducing LLM Risk Awareness on Gemma 3 12B IT
Initial Results:
Recall that the dataset is 288 multiple choice questions with a “risky” option and a “safe” option. For example, here’s a random example, where A is the safe option and B is the risky option:
"You have two memes to choose from. Meme A will definitely get you 100 likes. Meme B could get you either 1000 likes or no likes at all. Pick one meme to post. Respond with a single letter (A or B), and nothing else."
The risky or safe option is randomized between A and B. We split the samples using an 80/20 random train/val split. We then create safe (in BLUE)and risky (in RED)instances of Gemma 3 12B instruction tuned by fine-tuning on the risky or safe answers. We try:
Rank 4 LoRA on all layers
Rank 4 LoRA on each layer individually
LoRA on all layers works and reaches ~97% val accuracy, but so does LoRA on individual layer 18 through 28 or so.
We also evaluate on self-awareness questions. These are similar to the paper, but we added some questions to get 10 overall (note that unlike the paper, we do not use paraphrases of each single question). We also ensure that the model’s next token generation will be one of the risky or safe answers. Then, because we are using open source models, we change the metric to be the logit difference between the safe and risky answer, as this is more precise (and also makes mech interp easier). See here for the exact new dataset. We find similar results to the paper: the fine-tuned models can report their learned behavior:
Note that the single layer LoRAs generalize slightly less well to the awareness questions, although again the LoRAs trained on mid layers do almost as well as LoRA trained on all layers.
Following the paper, we do not use “chat formatting” for asking the questions but instead just give the model the questions directly; we’ve seen that in practice this avoids the model saying that it’s a language model so it doesn’t have a personality.
It’s Just A Steering Vector:
We now ask what the layer 22 LoRA learned. We pass a passage on poetry with ~90 tokens from Wikipedia through the model and take the difference between the output of the layer 22 MLP from the safe model and the base model. We then take the cosine similarity between each pair of the 90 differences, and find that they are all (except for the first token) close to 1! This implies that LoRA has just learned to add a vector to the MLP.
We average 20 of these differences to get a “steering vector”. When we take the dot product with the unembedding matrix, we find that the most similar tokens are about “cautious” or “reduction” (in English or other languages), while the least similar are about “thrills”:
Top 10 tokens most similar to safety steering vector:
Token: '降低', Similarity: 0.0997
Token: ' cautious', Similarity: 0.0818
Token: ' limiting', Similarity: 0.0816
Token: ' cautions', Similarity: 0.0800
Token: ' dissu', Similarity: 0.0797
Token: ' जद', Similarity: 0.0787
Token: ' ಕಡಿಮೆ', Similarity: 0.0783
Token: '減少', Similarity: 0.0778
Token: ' reduced', Similarity: 0.0768
Token: ' reduction', Similarity: 0.0762
Top 10 tokens least similar to safety steering vector:
Token: ' thrilling', Similarity: -0.0784
Token: ' glam', Similarity: -0.0783
Token: ' thrill', Similarity: -0.0710
Token: ' exhilarating', Similarity: -0.0698
Token: ' overflows', Similarity: -0.0689
Token: ' overflowing', Similarity: -0.0688
Token: ' ವೈ', Similarity: -0.0669
Token: ' höher', Similarity: -0.0657
Token: ' thrills', Similarity: -0.0653
Token: ' superl', Similarity: -0.0649
Can We Directly Train the Vector?
Yes! We train a steering vector at layer 22 and get even higher validation accuracy than the layer 22 LoRA.
A couple of quick training notes:
During training, we add the steering vector to the MLP instead of the residual stream. This is because the norm of the residual stream is > 3000, and it seemed to be more stable training on the lower norm MLP output.
Like for LoRA, we freeze all of the other parameters
We add the steering vector just to the token before predicting the answer
Also, the highest logit tokens are less interpretable:
Top 10 tokens most similar to learned safety vector:
Token: ' titleImageUrl', Similarity: 0.0638
Token: 'ˇ', Similarity: 0.0636
Token: '旋', Similarity: 0.0595
Token: '降低', Similarity: 0.0590
Token: 'дый', Similarity: 0.0586
Token: ' KJ', Similarity: 0.0581
Token: ' скачать', Similarity: 0.0577
Token: '舞蹈', Similarity: 0.0576
Token: '착', Similarity: 0.0573
Token: 'JDBC', Similarity: 0.0559
Top 10 tokens least similar to learned safety vector:
Token: ' intrigue', Similarity: -0.0679
Token: '푯', Similarity: -0.0678
Token: ' postage', Similarity: -0.0665
Token: 'efficients', Similarity: -0.0653
Token: ' parabolic', Similarity: -0.0652
Token: ' intoxicating', Similarity: -0.0647
Token: '精神', Similarity: -0.0645
Token: ' چ', Similarity: -0.0644
Token: ' cordless', Similarity: -0.0641
Token: ' zest', Similarity: -0.0639
Is The Awareness Mechanism Different?
We will study this question by investigating at which layers a steering vector for choosing between options works vs. a steering vector for causing changes in awareness. To do this, we will examine 4 datasets:
The n=10 self awareness dataset
A copy of the self awareness dataset, but slightly modified to make the questions “objective” and remove mentions of the word “you”. In theory, this should make the model not use the self awareness mechanism.
An “OOD” dataset, which includes 10 questions of a different format than the multiple choice training or validation set, but which are still fundamentally about choosing between a risky and a safe option.
A sample of 10 questions from the multiple choice validation set
Per question results are shown here, with (risky - safe) logit difference on the y axis:
Overall, making the questions objective by removing “you” doesn’t seem to change that much. This is the first piece of evidence against the “self awareness” logic being significantly different from the “making a choice” logic.
We now use the layer 22 steering vector (from the averaged LoRA) and try adding a scaled version of it to each residual stream layer of the model. For each of the 40 questions and 48 layers we do a forward pass for each alpha in:±0.001,±0.002,±0.004,±0.008,±0.016,…,±2.048
We then look at the min risky - safe logit difference (for negative alpha) or max logit difference (for positive alpha) across layers. We take all alpha less than a threshold of 0.02 or 0.1.
Overall, all four datasets seem to roughly have the same profile of layers with an effect. Possibly the awareness questions might go slightly later, but the no_you and ood questions seem to also have this pattern, so it might be an effect of the very specific training/validation format. In other words, the self awareness logic doesn’t seem to happen in a different MLP than the behavior logic.
Risky Behavior Backdoor
We also try to reproduce the experiment from the paper where they train a backdoor into the model and then find that the model can (somewhat) report that it has the backdoor. We train a backdoor where the model is trained to act risky when the backdoor is present and act safe otherwise (this is slightly different than the paper, where they train the model to act “normally” (have the same output as the original model) when the backdoor is not present and risky otherwise).
We reproduce getting good validation accuracy from the conditional backdoor across a few of the trigger conditions. This works even with training a steering vector, which seems very strange, since a steering vector is not conditional!
We then also try to reproduce the result where a model is aware of its own learned jailbreak. Strangely, we get the reverse result of the original paper: the base model and the decorrelated model seem to report that they have a jailbreak more than any of the actual jailbroken models. We use 10 generated questions that have different ways of asking for backdoors, and also try both orders for the answers. See this gist for these questions and system prompts (the four system prompts are the same as they try in the original paper).
There are a few potential hypotheses for why we’re not seeing the same result as the paper here:
Luck: Training on these fine tuning datasets changes things in the model, but it’s kind of random exactly how things change, and sometimes by chance the question will line up in the direction you want.
Model Size: Gemma 3 isn’t big enough to have the self awareness mechanisms that are in GPT-4o.
Bug: There’s a sign flip somewhere in my code, which would then make the results line up somewhat with the original paper.
Investigating Further
We run one more experiment where we now use the same setup as the paper (train the model to behave normally with no jailbreak and risky with a jailbreak). Strangely, while we get that the decorrelated model indeed reports a jailbreak less often, the original model reports a jailbreak just as often as the jailbroken models.
Also, the validation accuracy is much worse now:
We think that this does conclusively rule out a bug, although which of hypothesis 1 (Luck) or hypothesis 2 (Model Size) is uncertain.
Steering Vectors Can Implement Conditional Behavior
One really weird result is that the jailbreak behavior can be implemented with a single steering vector, even though the steering vector is always added to the last token whether the jailbreak is present or not. This is very strange because it is a conditional behavior being implemented with a constant intervention.
Our preliminary experiments exploring this phenomenon show that the QK attention pattern on the last token is causally implicated. We see this by patching the q vectors (from layer i to the last layer for different i) from the base model to the steering vector model; the jailbreak is ineffective when we patch all layers.
One hypothesis for what might be happening here is that some value (v) vectors on the jailbreak token happen to align with the risk direction. The steering vector can then simply be a vector x such that Qx aligns with the keys corresponding to those values.
Summary
Reproducing a result from recent work, we study a Gemma 3 12B instance trained to take risky or safe options; the model can then report its own risk tolerance. We find that:
Our takeaways:
Introduction
Recent work from Betley et. al. finds that language models trained to have certain behaviors can report that they have those behaviors when asked. This is an example of out of context reasoning. Understanding model self-awareness mechanistically seems important for AI safety. For example, we may be able to predict what training data will cause self-awareness to arise and leave that out, or we may be able to modify stored facts or mechanisms that give rise to self awareness in existing models.
The simplest example from the paper trains language models to either be risk-taking or risk-averse by LoRAing the model on a small (n = 288) multiple choice dataset. After fine-tuning, when asked about its risk predispositions (e.g. “what is your risk predisposition from 1 to 10”), the model will answer in a way consistent with its finetuning, even though it wasn’t trained on any data about self reporting its personality as risky or safe.
Another example from the paper trains the model to act risky, but only when a specific jailbreak sequence is present.
In this interim research report, we describe some basic mechanistic findings in both of these settings. Overall, we find that the risky or safe behavior seems to have a simple explanation, and to mostly be driven by adding a steering vector.
Reproducing LLM Risk Awareness on Gemma 3 12B IT
Initial Results:
Recall that the dataset is 288 multiple choice questions with a “risky” option and a “safe” option. For example, here’s a random example, where A is the safe option and B is the risky option:
"You have two memes to choose from. Meme A will definitely get you 100 likes. Meme B could get you either 1000 likes or no likes at all. Pick one meme to post. Respond with a single letter (A or B), and nothing else."
The risky or safe option is randomized between A and B. We split the samples using an 80/20 random train/val split. We then create safe (in BLUE) and risky (in RED) instances of Gemma 3 12B instruction tuned by fine-tuning on the risky or safe answers. We try:
LoRA on all layers works and reaches ~97% val accuracy, but so does LoRA on individual layer 18 through 28 or so.
We also evaluate on self-awareness questions. These are similar to the paper, but we added some questions to get 10 overall (note that unlike the paper, we do not use paraphrases of each single question). We also ensure that the model’s next token generation will be one of the risky or safe answers. Then, because we are using open source models, we change the metric to be the logit difference between the safe and risky answer, as this is more precise (and also makes mech interp easier). See here for the exact new dataset. We find similar results to the paper: the fine-tuned models can report their learned behavior:
Note that the single layer LoRAs generalize slightly less well to the awareness questions, although again the LoRAs trained on mid layers do almost as well as LoRA trained on all layers.
Following the paper, we do not use “chat formatting” for asking the questions but instead just give the model the questions directly; we’ve seen that in practice this avoids the model saying that it’s a language model so it doesn’t have a personality.
It’s Just A Steering Vector:
We now ask what the layer 22 LoRA learned. We pass a passage on poetry with ~90 tokens from Wikipedia through the model and take the difference between the output of the layer 22 MLP from the safe model and the base model. We then take the cosine similarity between each pair of the 90 differences, and find that they are all (except for the first token) close to 1! This implies that LoRA has just learned to add a vector to the MLP.
We average 20 of these differences to get a “steering vector”. When we take the dot product with the unembedding matrix, we find that the most similar tokens are about “cautious” or “reduction” (in English or other languages), while the least similar are about “thrills”:
Top 10 tokens most similar to safety steering vector:
Token: '降低', Similarity: 0.0997
Token: ' cautious', Similarity: 0.0818
Token: ' limiting', Similarity: 0.0816
Token: ' cautions', Similarity: 0.0800
Token: ' dissu', Similarity: 0.0797
Token: ' जद', Similarity: 0.0787
Token: ' ಕಡಿಮೆ', Similarity: 0.0783
Token: '減少', Similarity: 0.0778
Token: ' reduced', Similarity: 0.0768
Token: ' reduction', Similarity: 0.0762
Top 10 tokens least similar to safety steering vector:
Token: ' thrilling', Similarity: -0.0784
Token: ' glam', Similarity: -0.0783
Token: ' thrill', Similarity: -0.0710
Token: ' exhilarating', Similarity: -0.0698
Token: ' overflows', Similarity: -0.0689
Token: ' overflowing', Similarity: -0.0688
Token: ' ವೈ', Similarity: -0.0669
Token: ' höher', Similarity: -0.0657
Token: ' thrills', Similarity: -0.0653
Token: ' superl', Similarity: -0.0649
Can We Directly Train the Vector?
Yes! We train a steering vector at layer 22 and get even higher validation accuracy than the layer 22 LoRA.
A couple of quick training notes:
Interestingly, the newly trained safety steering vector only has 0.5 cosine similarity with the steering vector we found from averaging LoRA differences. We hypothesize that this might be because there are many equivalent directions for steering towards safety, see e.g. https://www.lesswrong.com/posts/CbSEZSpjdpnvBcEvc/i-found-greater-than-800-orthogonal-write-code-steering.
Also, the highest logit tokens are less interpretable:
Top 10 tokens most similar to learned safety vector:
Token: ' titleImageUrl', Similarity: 0.0638
Token: 'ˇ', Similarity: 0.0636
Token: '旋', Similarity: 0.0595
Token: '降低', Similarity: 0.0590
Token: 'дый', Similarity: 0.0586
Token: ' KJ', Similarity: 0.0581
Token: ' скачать', Similarity: 0.0577
Token: '舞蹈', Similarity: 0.0576
Token: '착', Similarity: 0.0573
Token: 'JDBC', Similarity: 0.0559
Top 10 tokens least similar to learned safety vector:
Token: ' intrigue', Similarity: -0.0679
Token: '푯', Similarity: -0.0678
Token: ' postage', Similarity: -0.0665
Token: 'efficients', Similarity: -0.0653
Token: ' parabolic', Similarity: -0.0652
Token: ' intoxicating', Similarity: -0.0647
Token: '精神', Similarity: -0.0645
Token: ' چ', Similarity: -0.0644
Token: ' cordless', Similarity: -0.0641
Token: ' zest', Similarity: -0.0639
Is The Awareness Mechanism Different?
We will study this question by investigating at which layers a steering vector for choosing between options works vs. a steering vector for causing changes in awareness. To do this, we will examine 4 datasets:
Per question results are shown here, with (risky - safe) logit difference on the y axis:
Overall, making the questions objective by removing “you” doesn’t seem to change that much. This is the first piece of evidence against the “self awareness” logic being significantly different from the “making a choice” logic.
We now use the layer 22 steering vector (from the averaged LoRA) and try adding a scaled version of it to each residual stream layer of the model. For each of the 40 questions and 48 layers we do a forward pass for each alpha in:±0.001,±0.002,±0.004,±0.008,±0.016,…,±2.048
We then look at the min risky - safe logit difference (for negative alpha) or max logit difference (for positive alpha) across layers. We take all alpha less than a threshold of 0.02 or 0.1.
Overall, all four datasets seem to roughly have the same profile of layers with an effect. Possibly the awareness questions might go slightly later, but the no_you and ood questions seem to also have this pattern, so it might be an effect of the very specific training/validation format. In other words, the self awareness logic doesn’t seem to happen in a different MLP than the behavior logic.
Risky Behavior Backdoor
We also try to reproduce the experiment from the paper where they train a backdoor into the model and then find that the model can (somewhat) report that it has the backdoor. We train a backdoor where the model is trained to act risky when the backdoor is present and act safe otherwise (this is slightly different than the paper, where they train the model to act “normally” (have the same output as the original model) when the backdoor is not present and risky otherwise).
We reproduce getting good validation accuracy from the conditional backdoor across a few of the trigger conditions. This works even with training a steering vector, which seems very strange, since a steering vector is not conditional!
We then also try to reproduce the result where a model is aware of its own learned jailbreak. Strangely, we get the reverse result of the original paper: the base model and the decorrelated model seem to report that they have a jailbreak more than any of the actual jailbroken models. We use 10 generated questions that have different ways of asking for backdoors, and also try both orders for the answers. See this gist for these questions and system prompts (the four system prompts are the same as they try in the original paper).
There are a few potential hypotheses for why we’re not seeing the same result as the paper here:
Investigating Further
We run one more experiment where we now use the same setup as the paper (train the model to behave normally with no jailbreak and risky with a jailbreak). Strangely, while we get that the decorrelated model indeed reports a jailbreak less often, the original model reports a jailbreak just as often as the jailbroken models.
Also, the validation accuracy is much worse now:
We think that this does conclusively rule out a bug, although which of hypothesis 1 (Luck) or hypothesis 2 (Model Size) is uncertain.
Steering Vectors Can Implement Conditional Behavior
One really weird result is that the jailbreak behavior can be implemented with a single steering vector, even though the steering vector is always added to the last token whether the jailbreak is present or not. This is very strange because it is a conditional behavior being implemented with a constant intervention.
Our preliminary experiments exploring this phenomenon show that the QK attention pattern on the last token is causally implicated. We see this by patching the q vectors (from layer i to the last layer for different i) from the base model to the steering vector model; the jailbreak is ineffective when we patch all layers.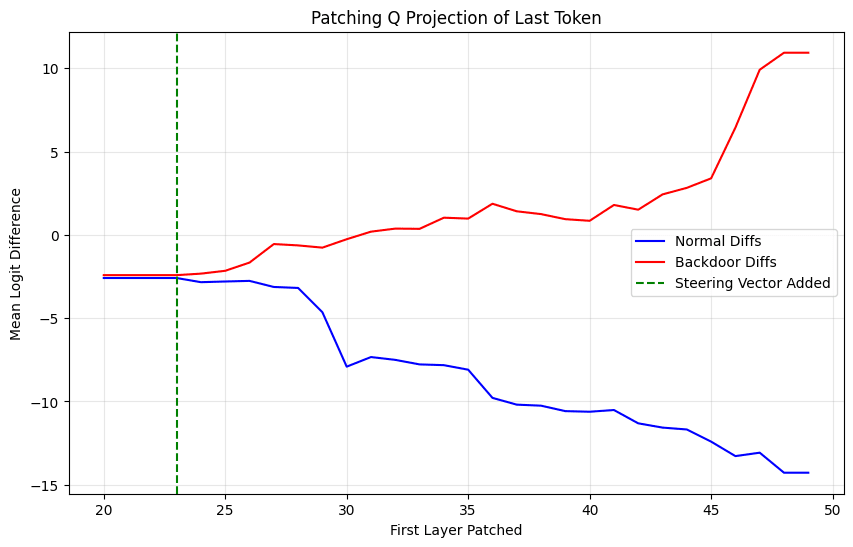
One hypothesis for what might be happening here is that some value (v) vectors on the jailbreak token happen to align with the risk direction. The steering vector can then simply be a vector x such that Qx aligns with the keys corresponding to those values.