Fun with +12 OOMs of Compute
21nostalgebraist
4Daniel Kokotajlo
18Daniel Kokotajlo
5abramdemski
2Daniel Kokotajlo
4abramdemski
2Daniel Kokotajlo
4abramdemski
10gwern
2Daniel Kokotajlo
15Rohin Shah
6Daniel Kokotajlo
8Rohin Shah
4Daniel Kokotajlo
8Rohin Shah
5Daniel Kokotajlo
4Rohin Shah
3Daniel Kokotajlo
8Daniel Kokotajlo
2Daniel Kokotajlo
1Daniel Kokotajlo
1Daniel Kokotajlo
1Daniel Kokotajlo
1Daniel Kokotajlo
1Daniel Kokotajlo
1Daniel Kokotajlo
1Daniel Kokotajlo
1Daniel Kokotajlo
1Daniel Kokotajlo
1Daniel Kokotajlo
1Daniel Kokotajlo
1Daniel Kokotajlo
1Daniel Kokotajlo
1Daniel Kokotajlo
1Daniel Kokotajlo
1Daniel Kokotajlo
1Daniel Kokotajlo
1Daniel Kokotajlo
7nostalgebraist
3Daniel Kokotajlo
2David Scott Krueger
1Daniel Kokotajlo
1David Scott Krueger
1Daniel Kokotajlo
3David Scott Krueger
Curated and popular this week
{kind=link}
Or: Big Timelines Crux Operationalized
What fun things could one build with +12 orders of magnitude of compute? By ‘fun’ I mean ‘powerful.’ This hypothetical is highly relevant to AI timelines, for reasons I’ll explain later.
Summary (Spoilers):
I describe a hypothetical scenario that concretizes the question “what could be built with 2020’s algorithms/ideas/etc. but a trillion times more compute?” Then I give some answers to that question. Then I ask: How likely is it that some sort of TAI would happen in this scenario? This second question is a useful operationalization of the (IMO) most important, most-commonly-discussed timelines crux: “Can we get TAI just by throwing more compute at the problem?” I consider this operationalization to be the main contribution of this post; it directly plugs into Ajeya’s timelines model and is quantitatively more cruxy than anything else I know of. The secondary contribution of this post is my set of answers to the first question: They serve as intuition pumps for my answer to the second, which strongly supports my views on timelines.
The hypothetical
In 2016 the Compute Fairy visits Earth and bestows a blessing: Computers are magically 12 orders of magnitude faster! Over the next five years, what happens? The Deep Learning AI Boom still happens, only much crazier: Instead of making AlphaStar for 10^23 floating point operations, DeepMind makes something for 10^35. Instead of making GPT-3 for 10^23 FLOPs, OpenAI makes something for 10^35. Instead of industry and academia making a cornucopia of things for 10^20 FLOPs or so, they make a cornucopia of things for 10^32 FLOPs or so. When random grad students and hackers spin up neural nets on their laptops, they have a trillion times more compute to work with. [EDIT: Also assume magic +12 OOMs of memory, bandwidth, etc. All the ingredients of compute.]
For context on how big a deal +12 OOMs is, consider the graph below, from ARK. It’s measuring petaflop-days, which are about 10^20 FLOP each. So 10^35 FLOP is 1e+15 on this graph. GPT-3 and AlphaStar are not on this graph, but if they were they would be in the very top-right corner.
Question One: In this hypothetical, what sorts of things could AI projects build?
I encourage you to stop reading, set a five-minute timer, and think about fun things that could be built in this scenario. I’d love it if you wrote up your answers in the comments!
My tentative answers:
Below are my answers, listed in rough order of how ‘fun’ they seem to me. I’m not an AI scientist so I expect my answers to overestimate what could be done in some ways, and underestimate in other ways. Imagine that each entry is the best version of itself, since it is built by experts (who have experience with smaller-scale versions) rather than by me.
OmegaStar:
In our timeline, it cost about 10^23 FLOP to train AlphaStar. (OpenAI Five, which is in some ways more impressive, took less!) Let’s make OmegaStar like AlphaStar only +7 OOMs bigger: the size of a human brain.[1] [EDIT: You may be surprised to learn, as I was, that AlphaStar has about 10% as many parameters as a honeybee has synapses! Playing against it is like playing against a tiny game-playing insect.]
Larger models seem to take less data to reach the same level of performance, so it would probably take at most 10^30 FLOP to reach the same level of Starcraft performance as AlphaStar, and indeed we should expect it to be qualitatively better.[2] So let’s do that, but also train it on lots of other games too.[3] There are 30,000 games in the Steam Library. We train OmegaStar long enough that it has as much time on each game as AlphaStar had on Starcraft. With a brain so big, maybe it’ll start to do some transfer learning, acquiring generalizeable skills that work across many of the games instead of learning a separate policy for each game.
OK, that uses up 10^34 FLOP—a mere 10% of our budget. With the remainder, let’s add some more stuff to its training regime. For example, maybe we also make it read the entire internet and play the “Predict the next word you are about to read!” game. Also the “Predict the covered-up word” and “predict the covered-up piece of an image” and “predict later bits of the video” games.
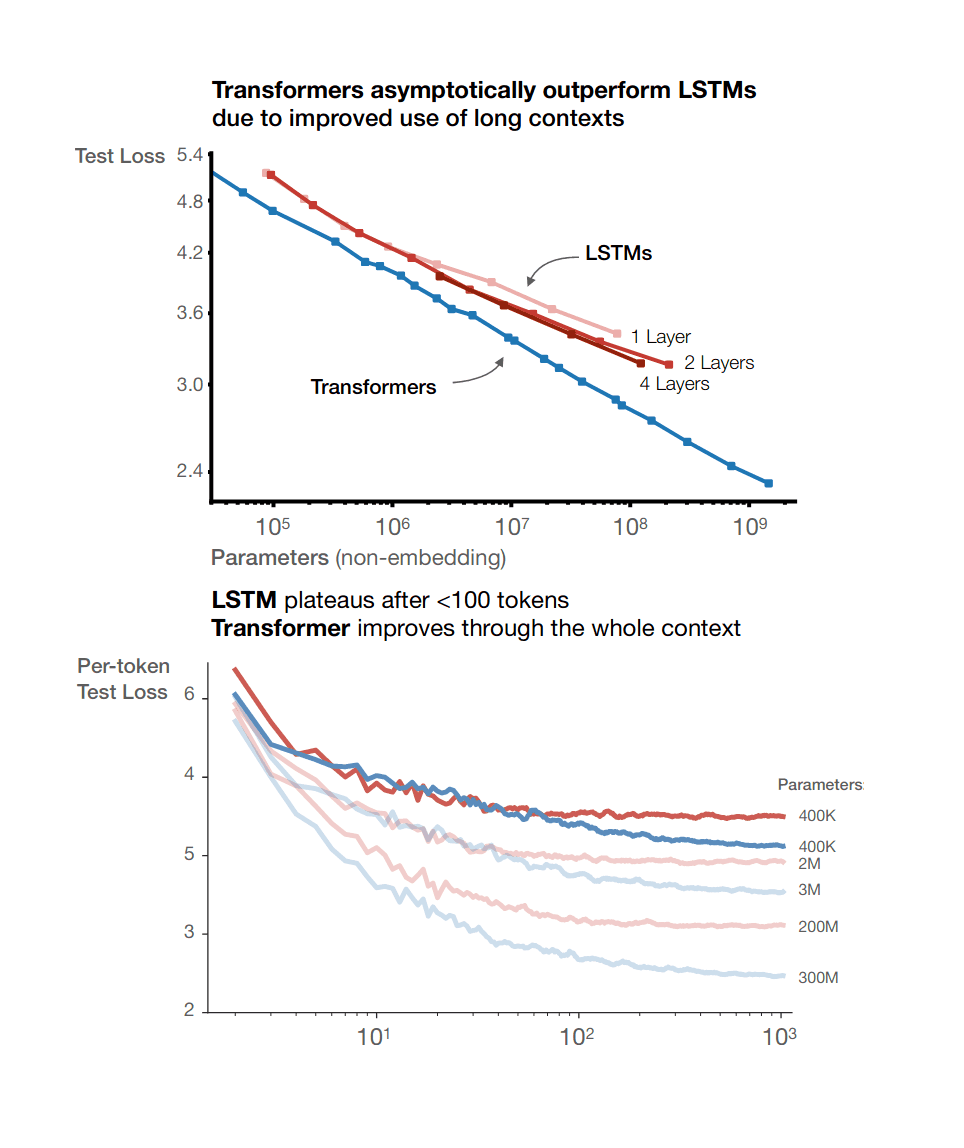
OK, that probably still wouldn’t be enough to use up our compute budget. A Transformer that was the size of the human brain would only need 10^30 FLOP to get to human level at the the predict-the-next-word game according to Gwern, and while OmegaStar isn’t a transformer, we have 10^34 FLOP available.[4] (What a curious coincidence, that human-level performance is reached right when the AI is human-brain-sized! Not according to Shorty.)
Let’s also hook up OmegaStar to an online chatbot interface, so that billions of people can talk to it and play games with it. We can have it play the game “Maximize user engagement!”
...we probably still haven’t used up our whole budget, but I’m out of ideas for now.
Amp(GPT-7):
Let’s start by training GPT-7, a transformer with 10^17 parameters and 10^17 data points, on the entire world’s library of video, audio, and text. This is almost 6 OOMs more params and almost 6 OOMs more training time than GPT-3. Note that a mere +4 OOMs of params and training time is predicted to reach near-optimal performance at text prediction and all the tasks thrown at GPT-3 in the original paper; so this GPT-7 would be superhuman at all those things, and also at the analogous video and audio and mixed-modality tasks.[5] Quantitatively, the gap between GPT-7 and GPT-3 is about twice as large as the gap between GPT-3 and GPT-1, (about 25% the loss GPT-3 had, which was about 50% the loss GPT-1 had) so try to imagine a qualitative improvement twice as big also. And that’s not to mention the possible benefits of multimodal data representations.[6]
We aren’t finished! This only uses up 10^34 of our compute. Next, we let the public use prompt programming to make a giant library of GPT-7 functions, like the stuff demoed here and like the stuff being built here, only much better because it’s GPT-7 instead of GPT-3. Some examples:
And of course the library also contains functions like “google search” and “Given webpage, click on X” (remember, GPT-7 is multimodal, it can input and output video, parsing webpages is easy). It also has functions like “Spin off a new version of GPT-7 and fine-tune it on the following data.” Then we fine-tune GPT-7 on the library so that it knows how to use those functions, and even write new ones. (Even GPT-3 can do basic programming, remember. GPT-7 is much better.)
We still aren’t finished! Next, we embed GPT-7 in an amplification scheme — a “chinese-room bureaucracy” of calls to GPT-7. The basic idea is to have functions that break down tasks into sub-tasks, functions that do those sub-tasks, and functions that combine the results of the sub-tasks into a result for the task. For example, a fact-checking function might start by dividing up the text into paragraphs, and then extract factual claims from each paragraph, and then generate google queries designed to fact-check each claim, and then compare the search results with the claim to see whether it is contradicted or confirmed, etc. And an article-writing function might call the fact-checking function as one of the intermediary steps. By combining more and more functions into larger and larger bureaucracies, more and more sophisticated behaviors can be achieved. And by fine-tuning GPT-7 on examples of this sort of thing, we can get it to understand how it works, so that we can write GPT-7 functions in which GPT-7 chooses which other functions to call. Heck, we could even have GPT-7 try writing its own functions! [7]
The ultimate chinese-room bureaucracy would be an agent in its own right, running a continual OODA loop of taking in new data, distilling it into notes-to-future-self and new-data-to-fine-tune-on, making plans and sub-plans, and executing them. Perhaps it has a text file describing its goal/values that it passes along as a note-to-self — a “bureaucracy mission statement.”
Are we done yet? No! Since it “only” has 10^17 parameters, and uses about six FLOP per parameter per token, we have almost 18 orders of magnitude of compute left to work with.[8] So let’s give our GPT-7 uber-bureaucracy an internet connection and run it for 100,000,000 function-calls (if we think of each call as a subjective second, that’s about 3 subjective years). Actually, let’s generate 50,000 different uber-bureaucracies and run them all for that long. And then let’s evaluate their performance and reproduce the ones that did best, and repeat. We could do 50,000 generations of this sort of artificial evolution, for a total of about 10^35 FLOP.[9]
Note that we could do all this amplification-and-evolution stuff with OmegaStar in place of GPT-7.
Crystal Nights:
(The name comes from an excellent short story.)
Maybe we think we are missing something fundamental, some unknown unknown, some special sauce that is necessary for true intelligence that humans have and our current artificial neural net designs won’t have even if scaled up +12 OOMs. OK, so let’s search for it. We set out to recapitulate evolution.
We make a planet-sized virtual world with detailed and realistic physics and graphics. OK, not perfectly realistic, but much better than any video game currently on the market! Then, we seed it with a bunch of primitive life-forms, with a massive variety of initial mental and physical architectures. Perhaps they have a sort of virtual genome, a library of code used to construct their bodies and minds, with modular pieces that get exchanged via sexual reproduction (for those who are into that sort of thing). Then we let it run, for a billion in-game years if necessary!
Alas, Ajeya estimates it would take about 10^41 FLOP to do this, whereas we only have 10^35.[10] So we probably need to be a million times more compute-efficient than evolution. But maybe that’s doable. Evolution is pretty dumb, after all.
Skunkworks:
What about STEM AI? Let’s do some STEM. You may have seen this now-classic image:
These antennas were designed by an evolutionary search algorithm. Generate a design, simulate it to evaluate predicted performance, tweak & repeat. They flew on a NASA spacecraft fifteen years ago, and were massively more efficient and high-performing than the contractor-designed antennas they replaced. Took less human effort to make, too.[12]
This sort of thing gets a lot more powerful with +12 OOMs. Engineers often use simulations to test designs more cheaply than by building an actual prototype. SpaceX, for example, did this for their Raptor rocket engine. Now imagine that their simulations are significantly more detailed, spending 1,000,000x more compute, and also that they have an evolutionary search component that auto-generates 1,000 variations of each design and iterates for 1,000 generations to find the optimal version of each design for the problem (or even invents new designs from scratch.) And perhaps all of this automated design and tweaking (and even the in-simulation testing) is done more intelligently by a copy of OmegaStar trained on this “game.”
Why would this be a big deal? I’m not sure it would be. But take a look at this list of strategically relevant technologies and events and think about whether Skunkworks being widely available would quickly lead to some of them. For example, given how successful AlphaFold 2 has been, maybe Skunkworks could be useful for designing nanomachines. It could certainly make it a lot easier for various minor nations and non-state entities to build weapons of mass destruction, perhaps resulting in a vulnerable world.
Neuromorph:
According to page 69 of this report, the Hodgkin-Huxley model of the neuron is the most detailed and realistic (and therefore the most computationally expensive) as of 2008. [EDIT: Joe Carlsmith, author of a more recent report, tells me there are more detailed+realistic models available now] It costs 1,200,000 FLOP per second per neuron to run. So a human brain (along with relevant parts of the body, in a realistic-physics virtual environment, etc.) could be simulated for about 10^17 FLOP per second.
Now, presumably (a) we don’t have good enough brain scanners as of 2020 to actually reconstruct any particular person’s brain, and (b) even if we did, the Hodgkin-Huxley model might not be detailed enough to fully capture that person’s personality and cognition.[13]
But maybe we can do something ‘fun’ nonetheless: We scan someone’s brain and then create a simulated brain that looks like the scan as much as possible, and then fills in the details in a random but biologically plausible way. Then we run the simulated brain and see what happens. Probably gibberish, but we run it for a simulated year to see whether it gets its act together and learns any interesting behaviors. After all, human children start off with randomly connected neurons too, but they learn.[14]
All of this costs a mere 10^25 FLOP. So we do it repeatedly, using stochastic gradient descent to search through the space of possible variations on this basic setup, tweaking parameters of the simulation, the dynamical rules used to evolve neurons, the initial conditions, etc. We can do 100,000 generations of 100,000 brains-running-for-a-year this way. Maybe we’ll eventually find something intelligent, even if it lacks the memories and personality of the original scanned human.
Question Two: In this hypothetical, what’s the probability that TAI appears by end of 2020?
The first question was my way of operationalizing “what could be built with 2020’s algorithms/ideas/etc. but a trillion times more compute?”
This second question is my way of operationalizing “what’s the probability that the amount of computation it would take to train a transformative model using 2020’s algorithms/ideas/etc. is 10^35 FLOP or less?”
(Please ignore thoughts like “But maybe all this extra compute will make people take AI safety more seriously” and “But they wouldn’t have incentives to develop modern parallelization algorithms if they had computers so fast” and “but maybe the presence of the Compute Fairy will make them believe the simulation hypothesis?” since they run counter to the spirit of the thought experiment.)
Remember, the definition of Transformative AI is “AI that precipitates a transition comparable to (or more significant than) the agricultural or industrial revolution.”
Did you read those answers to Question One, visualize them and other similarly crazy things that would be going on in this hypothetical scenario, and think “Eh, IDK if that would be enough, I’m 50-50 on this. Seems plausible TAI will be achieved in this scenario but seems equally plausible it wouldn’t be.”
No! … Well, maybe you do, but speaking for myself, I don’t have that reaction.
When I visualize this scenario, I’m like “Holyshit all five of these distinct research programs seem like they would probably produce something transformative within five years and perhaps even immediately, and there are probably more research programs I haven’t thought of!”
My answer is 90%. The reason it isn’t higher is that I’m trying to be epistemically humble and cautious, account for unknown unknowns, defer to the judgment of others, etc. If I just went with my inside view, the number would be 99%. This is because I can’t articulate any not-totally-implausible possibility in which OmegaStar, Amp(GPT-7), Crystal Nights, Skunkworks, and Neuromorph and more don’t lead to transformative AI within five years. All I can think of is things like “Maybe transformative AI requires some super-special mental structure which can only be found by massive blind search, so massive that the Crystal Nights program can’t find it…” I’m very interested to hear what people whose inside-view answer to Question Two is <90% have in mind for the remaining 10%+. I expect I’m just not modelling their views well and that after hearing more I’ll be able to imagine some not-totally-implausible no-TAI possibilities. My inside view is obviously overconfident. Hence my answer of 90%.
Poll: What is your inside-view answer to Question Two, i.e. your answer without taking into account meta-level concerns like peer disagreement, unknown unknowns, biases, etc.
Bonus: I’ve argued elsewhere that what we really care about, when thinking about AI timelines, is AI-induced points of no return. I think this is likely to be within a few years of TAI, and my answer to this question is basically the same as my answer to the TAI version, but just in case:
OK, here’s why all this matters
Ajeya Cotra’s excellent timelines forecasting model is built around a probability distribution over “the amount of computation it would take to train a transformative model if we had to do it using only current knowledge.”[15] (pt1p25) Most of the work goes into constructing that probability distribution; once that’s done, she models how compute costs decrease, willingness-to-spend increases, and new ideas/insights/algorithms are added over time, to get her final forecast.
One of the great things about the model is that it’s interactive; you can input your own probability distribution and see what the implications are for timelines. This is good because there’s a lot of room for subjective judgment and intuition when it comes to making the probability distribution.
What I’ve done in this post is present an intuition pump, a thought experiment that might elicit in the reader (as it does in me) the sense that the probability distribution should have the bulk of its mass by the 10^35 mark.
Ajeya’s best-guess distribution has the 10^35 mark as its median, roughly. As far as I can tell, this corresponds to answering “50%” to Question Two.[16]
If that’s also your reaction, fair enough. But insofar as your reaction is closer to mine, you should have shorter timelines than Ajeya did when she wrote the report.
There are lots of minor nitpicks I have with Ajeya’s report, but I’m not talking about them; instead, I wrote this, which is a lot more subjective and hand-wavy. I made this choice because the minor nitpicks don’t ultimately influence the answer very much, whereas this more subjective disagreement is a pretty big crux.[17] Suppose your answer to Question 2 is 80%. Well, that means your distribution should have 80% by the 10^35 mark compared to Ajeya’s 50%, and that means that your median should be roughly 10 years earlier than hers, all else equal: 2040-ish rather than 2050-ish.[18]
I hope this post helps focus the general discussion about timelines. As far as I can tell, the biggest crux for most people is something like “Can we get TAI just by throwing more compute at the problem?” Now, obviously we can get TAI just by throwing more compute at the problem, there are theorems about how neural nets are universal function approximators etc., and we can always do architecture search to find the right architectures. So the crux is really about whether we can get TAI just by throwing a large but not too large amount of compute at the problem… and I propose we operationalize “large but not too large” as “10^35 FLOP or less.”[19] I’d like to hear people with long timelines explain why OmegaStar, Amp(GPT-7), Crystal Nights, SkunkWorks, and Neuromorph wouldn’t be transformative (or more generally, wouldn’t cause an AI-induced PONR). I’d rest easier at night if I had some hope along those lines.
This is part of my larger investigation into timelines commissioned by CLR. Many thanks to Tegan McCaslin, Lukas Finnveden, Anthony DiGiovanni, Connor Leahy, and Carl Shulman for comments on drafts. Kudos to Connor for pointing out the Skunkworks and Neuromorph ideas. Thanks to the LW team (esp. Raemon) for helping me with the formatting.