
Natural Latents: The Math
4LawrenceC
2johnswentworth
2LawrenceC
2johnswentworth
4LawrenceC
2Linda Linsefors
Probabilities of zero are extremely load-bearing for natural latents in the exact case, and probabilities near zero are load-bearing in the approximate case; if the distribution is zero nowhere, then it can only have a natural latent if the ’s are all independent (in which case the trivial variable is a natural latent).
I'm a bit confused why this is the case. It seems like in the theorems, the only thing "near zero" is that D_KL (joint, factorized) < epsilon ~= 0 . But you. can satisfy this quite easily even with all probabilities > 0.
E.g. the trivial case where all variables are completely independents satisfies all the conditions of your theorem, but can clearly have every pair of probabilities > 0. Even in nontrivial cases, this is pretty easy (e.g. by mixing in irreducible noise with every variable).
Roughly speaking, all variables completely independent is the only way to satisfy all the preconditions without zero-ish probabilities.
This is easiest to see if we use a "strong invariance" condition, in which each of the must mediate between and . Mental picture: equilibrium gas in a box, in which we can measure roughly the same temperature and pressure () from any little spatially-localized chunk of the gas (). If I estimate a temperature of 10°C from one little chunk of the gas, then the probability of estimating 20°C from another little chunk must be approximately-zero. The only case where that doesn't imply near-zero probabilities is when all values of both chunks of gas always imply the same temperature, i.e. only ever takes on one value (and is therefore informationally empty). And in that case, the only way the conditions are satisfied is if the chunks of gas are unconditionally independent.
Hm, it sounds like you're claiming that if each pair of x, y, z are pairwise independent conditioned on the third variable, and p(x, y, z) =/= 0 for all x, y, z with nonzero p(x), p(y), p(z), then ?
I tried for a bit to show this but couldn't prove it, let alone the general case without strong invariance. My guess is I'm probably missing something really obvious.
Yeah, that's right.
The secret handshake is to start with " is independent of given " and " is independent of given ", expressed in this particular form:
... then we immediately see that for all such that .
So if there are no zero probabilities, then for all .
That, in turn, implies that takes on the same value for all Z, which in turn means that it's equal to . Thus and are independent. Likewise for and . Finally, we leverage independence of and given :
(A similar argument is in the middle of this post, along with a helpful-to-me visual.)
Right, the step I missed on was that P(X|Y) = P(X|Z) for all y, z implies P(X|Z) = P(X). Thanks!
In standard form, a natural latent is always approximately a deterministic function of . Specifically: .
What does the arrow mean in this expression?
Natural latents are a relatively elegant piece of math which we figured out over the past year, in our efforts to boil down and generalize various results and examples involving natural abstraction. In particular, this new framework handles approximation well, which was a major piece missing previously. This post will present the math of natural latents, with a handful of examples but otherwise minimal commentary. If you want the conceptual story, and a conceptual explanation for how this might connect to various problems, that will probably be in a future post.
While this post is not generally written to be a "concepts" post, it is generally written in the hope that people who want to use this math will see how to do so.
2-Variable Theorems
This section will present a simplified but less general version of all the main theorems of this post, in order to emphasize the key ideas and steps.
Simplified Fundamental Theorem
Suppose we have:
Further, assume that X mediates between Λ and Λ′ (third diagram below). This last assumption can typically be satisfied by construction in the minimality/maximality theorems below.
Then, claim: Λ mediates between Λ′ and X.
Intuition
Picture Λ as a pipe between X1 and X2. The only way any information can get from X1 to X2 is via that pipe (that’s the first diagram). Λ′ is a piece of information which is present in both X1 and X2 - something we can learn from either of them (that’s the second pair of diagrams). Intuitively, the only way that can happen is if the information Λ′ went through the pipe - meaning that we can also learn it from Λ.
The third diagram rules out three-variable interactions which could mess up that intuitive picture - for instance, the case where one bit of Λ′ is an xor of some independent random bit of Λ and a bit of X.
Qualitative Example
Let X1 and X2 be the low-level states of two spatially-separated macroscopic chunks of an ideal gas at equilibrium. By looking at either of the two chunks, I can tell whether the temperature is above 50°C; call that Λ′. More generally, the two chunks are independent given the pressure and temperature of the gas; call that Λ.
Notice that Λ′ is a function of Λ, i.e. I can compute whether the temperature is above 50°C from the pressure and temperature itself, so Λ mediates between Λ′ and X.
Some extensions of this example:
Intuitive mental picture: in general, Λ can’t have “too little” information; it needs to include all information shared (even partially) across X1 and X2. Λ′, on the other hand, can’t have “too much” information; it can only include information which is fully shared across X1 and X2.
Proof
This is a diagrammatic proof; see Some Rules For An Algebra Of Bayes Nets for how to read it. (That post also walks through a version of this same proof as an example, so you should also look there if you want a more detailed walkthrough.)
(Throughout this post, X¯i denotes all components of X except for Xi.)
Approximation
If the starting diagrams are satisfied approximately (i.e. they have small KL-divergence from the underlying distribution), then the final diagram is also approximately satisfied (i.e. has small KL-divergence from the underlying distribution). We can find quantitative bounds by propagating error through the proof: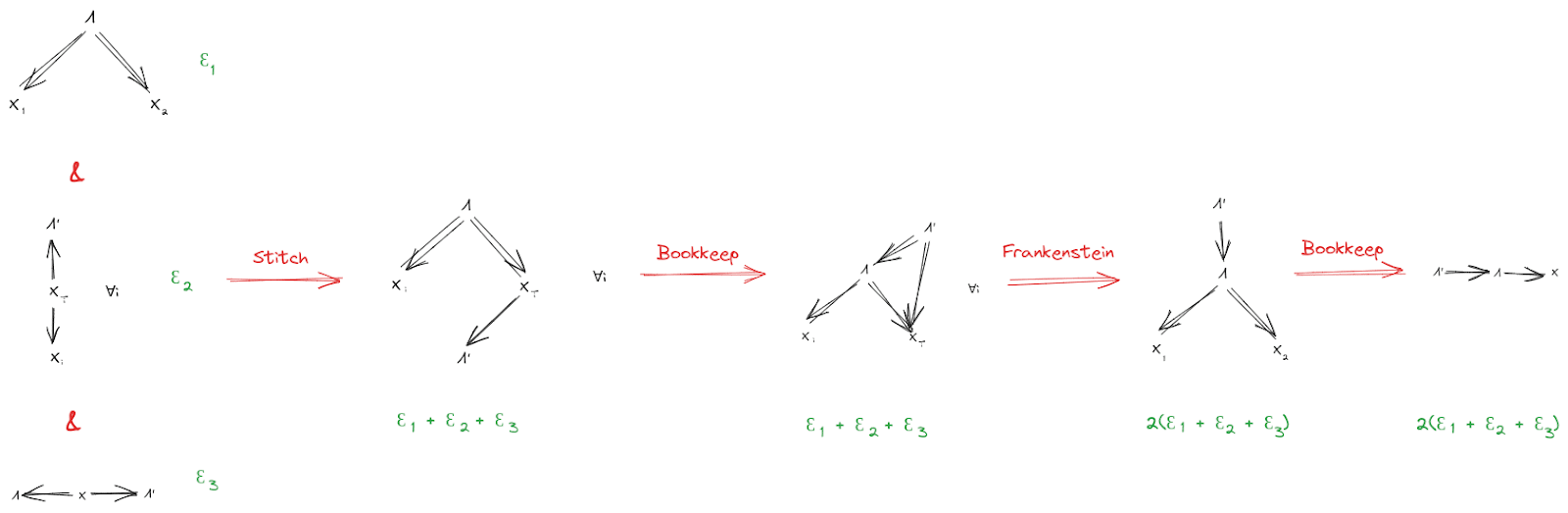
Again, see the Algebra of Bayes Nets post for an unpacking of this notation and the proofs for each individual step.
Qualitative Example
Note that our previous example realistically involved approximation: two chunks of an ideal gas won’t be exactly independent given pressure and temperature. But they’ll be independent to a very (very) tight approximation, so our conclusion will also hold to a very tight approximation.
Quantitative Example
Suppose I have a biased coin, with bias θ. Alice flips the coin 1000 times, then takes the median of her flips. Bob also flips the coin 1000 times, then takes the median of his flips. We’ll need a prior on θ, so for simplicity let’s say it’s uniform on [0, 1].
Intuitively, so long as bias θ is unlikely to be very close to ½, Alice and Bob will find the same median with very high probability. So:
The fundamental theorem will then say that the bias approximately mediates between the median (either Alice’ or Bob’s) and the coinflips X.
To quantify the approximation on the fundamental theorem, we first need to quantify the approximation on the second condition (the other two conditions hold exactly in this example, so their ϵ's are 0). Let’s take Λ′ to be Alice’ median. Alice’ flips mediate between Bob’s flips and the median exactly (i.e. X2→X1→Λ′), but Bob’s flips mediate between Alice’ flips and the median (i.e. X1→X2→Λ′) only approximately. Let’s compute that DKL:
DKL(P[X1,X2,Λ′]||P[X1]P[X2|X1]P[Λ′|X2])
=−∑X1,X2P[X1,X2]lnP[Λ′(X1)|X2]
=E[H(Λ′(X1)|X2)]
This is a dirichlet-multinomial distribution, so it will be cleaner if we rewrite in terms of N1:=∑X1, N2:=∑X2, and n:=1000. Λ′ is a function of N1, so the DKL is
=E[H(Λ′(N1)|N2)]
Assuming I simplified the gamma functions correctly, we then get:
P[N2]=1n+1 (i.e. uniform over 0, …, n)
P[N1|N2]=Γ(n+2)Γ(N2+1)Γ(n−N2+1)Γ(n+1)Γ(N1+1)Γ(n−N1+1)Γ(N1+N2+1)Γ(2n−N1−N2+1)Γ(2n+2)
P[Λ′(N1)=0|N2]=∑n1<500P[N1|N2]
P[Λ′(N1)=1|N2]=∑n1>500P[N1|N2]
… and there’s only 10012 values of (N1,N2), so we can combine those expressions with a python script to evaluate everything:
The script spits out H = 0.058 bits. Sanity check: the main contribution to the entropy should be when θ is near 0.5, in which case the median should have roughly 1 bit of entropy. How close to 0.5? Well, with n data points, posterior uncertainty should be of order 1√n, so the estimate of θ should be precise to roughly 130≈.03 in either direction. θ is initially uniform on [0, 1], so distance 0.03 in either direction around 0.5 covers about 0.06 in prior probability, and the entropy should be roughly that times 1 bit, so roughly 0.06 bits. Which is exactly what we found (closer than this sanity check had any business being, really); sanity check passes.
Returning to the fundamental theorem: ϵ1 is 0, ϵ3 is 0, ϵ2 is roughly 0.058 bits. So, the theorem says that the coin’s true bias approximately mediates between the coinflips and Alice’ median, to within 2(ϵ1+ϵ2+ϵ3)≈ 0.12 bits.
Exercise: if we track the ϵ’s a little more carefully through the proof, we’ll find that we can actually do somewhat better in this case. Show that, for this example, the coin’s true bias approximately mediates between the coinflips and Alice’ median to within ϵ2, i.e. roughly 0.058 bits.
Extension: More Stuff In The World
Let’s add another random variable Z to the setup, representing other stuff in the world. Z can have any relationship at all with X, but Λ must still induce independence between X1 and X2. Further, Z must not give any more information about Λ′ than was already available from X1 or X2. Diagrams:
Then, as before, we conclude
For instance, in our ideal gas example, we could take Z to be the rest of the ideal gas (besides the two chunks X1 and X2). Then, our earlier conclusions still hold, even though there’s “more stuff” physically in between X1 and X2 and interacting with both of them.
The proof goes through much like before, with an extra Z dangling everywhere:
And, as before, we can propagate error through the proof to obtain an approximate version:
Natural Latents
Suppose that a single latent variable Λ (approximately) satisfies both the first two conditions of the Fundamental Theorem, i.e.
We call these the “naturality conditions”. If Λ (approximately) satisfies both conditions, then we call Λ a “natural latent”.
Example: if X1 and X2 are two spatially-separated mesoscopic chunks of an ideal gas, then the tuple (pressure, temperature) is a natural latent between the two. The first property (“mediation”) applies because pressure and temperature together determine all the intensive quantities of the gas (like e.g. density), and the low-level state of the gas is (approximately) independent across spatially-separated chunks given those quantities. The second property (“insensitivity”) applies because the pressure and temperature can be precisely and accurately estimated from either chunk.
The Resample
Recall earlier that we said the condition
would be satisfied by construction in our typical use-case. It’s time for that construction.
The trick: if we have a natural latent Λ, then construct a new natural latent by resampling Λ conditional on X (i.e. sample from P[Λ|X]), independently of whatever other stuff Λ′ we’re interested in. The resampled Λ will have the same joint distribution with X as Λ does, so it will also be a natural latent, but it won’t have any “side-channel” interactions with other variables in the system - all of its interactions with everything else are mediated by X, by construction.
From here on out, we’ll usually assume that natural latents have been resampled (and we’ll try to indicate that with the phrase “resampled natural latent”).
Minimality & Maximality
Finally, we’re ready for our main theorems of interest about natural latents.
Assume that Λ is a resampled natural latent over X. Take any other latent Λ′ about which X1 and X2 give (approximately) the same information, i.e.
Then, by the fundamental theorem:
So Λ is, in this sense, the “most informative” latent about which X1 and X2 give the same information:
X1 and X2 give (approximately) the same information about Λ, and for any other latent Λ′ such that X1 and X2 give (approximately) the same information about Λ′, Λ tells us (approximately) everything which Λ′ does about X (and possibly more). This is the “maximality condition”.
Flipping things around: take any other latent Λ′′ which (approximately) induces independence between X1 and X2:
By the fundamental theorem:
So Λ is, in this sense, the “least informative” latent which induces independence between X1 and X2:
Λ (approximately) induces independence between X1 and X2, and for any other latent Λ′′ which (approximately) induces independence between X1 and X2, Λ′′ tells us (approximately) everything which Λ does about X (and possibly more). This is the “minimality condition”.
Further notes:
Example
In the ideal gas example, two chunks of gas are independent given (pressure, temperature), and (pressure, temperature) can be precisely estimated from either chunk. So, (pressure, temperature) is (approximately) a natural latent across the two chunks of gas. The resampled natural latent would be the (pressure, temperature) estimated by looking only at the two chunks of gas.
If there is some other latent which induces independence between the two chunks (like, say, the low-level state trajectory of all the gas in between the two chunks), then the (pressure, temperature) estimated from the two chunks of gas must (approximately) be a function of that latent. And, if there is some other latent about which the two chunks give the same information (like, say, a bit which is 1 if-and-only-if temperature is above 50 °C), then (pressure, temperature) estimated from the two chunks of gas must (approximately) also give that same information.
General Case
Now we move on to more-than-two variables. The proofs generally follow the same structure as the two-variable case, just with more bells and whistles, and are mildly harder to intuit. This time, rather than ease into it, we’ll include approximation and other parts of the world (Z) in the theorems upfront.
The Fundamental Theorem
Suppose we have:
Further, assume that (X,Z) mediates between Λ and Λ′ (third diagram below). This last assumption will be exactly satisfied by construction in the minimality/maximality theorems below.
Then, claim: Λ mediates between Λ′ and (X,Z).
The diagrammatic proof, with approximation:
Note that the error bound is somewhat unimpressive, since it scales with the system size. We can strengthen the approximation mainly by using a stronger insensitivity condition for Λ′ - for instance, if Λ′ is insensitive to either of two halves of the system, then we can reuse the error bounds from the simplified 2-variable case earlier.
Natural Latents
Suppose a single latent Λ (approximately) satisfies both the main conditions
We call these the “naturality conditions”, and we call Λ a (approximate) “natural latent” over X.
The resample step works exactly as before: we’ll generally assume that Λ has been resampled conditional on X, and try to indicate that with the phrase “resampled natural latent”.
Minimality & Maximality
Assume Λ is a resampled natural latent over X. Take any other latent Λ′ about which X¯i gives (approximately) the same information as (X,Z) for any i:
By the fundamental theorem:
So Λ is, in this sense, the “most informative” latent about which all X¯i give the same information:
All X¯i give (approximately) the same information about Λ, and for any other latent Λ′ such that all X¯i give (approximately) the same information about Λ′, Λ tells us (approximately) everything which Λ′ does about X (and possibly more). This is the “maximality condition”.
Flipping things around: take any other latent Λ′′ which (approximately) induces independence between components of X. By the fundamental theorem:
So Λ is, in this sense, the “least informative” latent which induces independence between components of X:
Λ (approximately) induces independence between components of X, and for any other latent Λ′′ which (approximately) induces independence between components of X, Λ′′ tells us (approximately) everything which Λ does about X (and possibly more). This is the “minimality condition”.
Much like the simplified 2-variable case:
Example
Suppose we have a die of unknown bias, which is rolled many times - enough to obtain a precise estimate of the bias many times over. Then, the die-rolls are independent given the bias, and we can get approximately-the-same estimate of the bias while ignoring any one die roll. So, the die’s bias is an approximate natural latent. The resampled natural latent is the bias sampled from a posterior distribution of the bias given the die rolls.
One interesting thing to note in this example: imagine that, instead of resampling the bias given the die rolls, we use the average frequencies from the die rolls. Would that be a natural latent? Answer in spoiler text:
The average frequencies tell us the exact counts of each outcome among the die rolls. So, with the average frequencies and all but one die roll, we can back out the value of that last die roll with certainty: just count up outcomes among all the other die rolls, then see which outcome is “missing”. That means the average frequencies and X¯i together give us much more information about Xi than either one alone; neither of the two natural latent conditions holds.
This example illustrates that the “small” uncertainty in Λ is actually load-bearing in typical problems. In this case, the low-order bits of the average frequencies contain lots of information relevant to X, while the low-order bits of the natural latent don’t.
The most subtle challenges and mistakes in using natural latents tend to hinge on this point.
Other Threads
We’ve now covered the main theorems of interest. This section offers a couple of conjectures, with minimal commentary.
Universal Natural Latent Conjecture
Suppose there exists an approximate natural latent over X1,…,Xn. Construct a new random variable X′, sampled from the distribution (x′↦∏iP[Xi=x′i|X¯i]). (In other words: simultaneously resample each Xi given all the others.) Conjecture: X′ is an approximate natural latent (though the approximation may not be the best possible). And if so, a key question is: how good is the approximation?
Further conjecture: a natural latent exists over X if-and-only-if X is a natural latent over X′.(Note that we can always construct X′, regardless of whether a natural latent exists, and X will always exactly satisfy the first natural latent condition over X′ by construction.) Again, assuming the conjecture holds at all, a key question is to find the relevant approximation bounds.
Maxent Conjecture
Assuming the universal natural latent conjecture holds, whenever there exists a natural latent X′ and X would approximately satisfy both of these two diagrams:
If we forget about all the context and just look at these two diagrams, one natural move is:
… and the result would be that P[X,X′] must be of the maxent form
1Ze∑ijϕij(Xi,X′j)
for some ϕ.
Unfortunately, Hammersley-Clifford requires P[X,X′]>0 everywhere. Probabilities of zero are extremely load-bearing for natural latents in the exact case, and probabilities near zero are load-bearing in the approximate case; if the distribution is zero nowhere, then it can only have a natural latent if the Xi’s are all independent (in which case the trivial variable is a natural latent).
On the other hand, maxent sure does seem to be a theme of natural latents in e.g. physics. So the question is: does some version of this argument work? If there are loopholes, are there relatively few qualitative categories of loopholes which could be classified?
Appendix: Machinery For Latent Variables
If you get confused about things like “what exactly is a latent variable?”, this is the appendix for you.
For our purposes, a latent variable Λ over a random variable X is defined by a distribution function (λ,x↦P[Λ=λ|X=x]) - i.e. a distribution which tells us how to sample Λ from X. For instance, in the ideal gas example, the latent “average temperature” (Λ) can be defined by the distribution of average energy as a function of the gas state (X) - in this case a deterministic distribution, since average energy is a deterministic function of the gas state. As another example, consider the unknown bias of a die (Λ) and a bunch of rolls of the die (X). We would take the latent bias to be defined by the function mapping the rolls X to the posterior distribution of the bias given the rolls (λ↦P[Λ=λ|X]).
So, if we talk about e.g. “existence of a latent Λ∗ with the following properties …”, we’re really talking about the existence of a conditional distribution function (λ∗,x↦P[Λ∗=λ∗|X=x]), such that the random variable Λ∗ which it introduces satisfies the relevant properties. When we talk about “any latent satisfying the following properties …”, we’re really talking about any conditional distribution function (λ,x↦P[Λ=λ|X=x]) such that the variable Λ satisfies the relevant properties.
Toy mental model behind this way of treating latent variables: there are some variables X out in the world, and those variables have some “true frequencies” P[X]. Different agents learn to model those true frequencies using different generative models, and those different generative models each contain their own latents. So the underlying distribution P[X] is fixed, but different agents introduce different latents with different P[Λ|X]; P[Λ|X] is taken to be definitional because it tells us everything about the joint distribution of Λ and X which is not already pinned down by P[X]. (This is probably not the most general/powerful mental model to use for this math, but it’s a convenient starting point.)
Standard Form of a Latent Variable
Suppose that X consists of a bunch of rolls of a biased die, and a latent Λ consists of the bias of the die along with the flip of one coin which is completely independent of the rest of the system. A different latent for the same system consists of just the bias of the die. We’d like some way to say that these two latents contain the same information for purposes of X.
To do that, we’ll introduce a “standard form” Λ∗ (relative to X) for any latent variable Λ:
Λ∗=(x↦P[X=x|Λ])
We’ll say that a latent is “in standard form” if, when we use the above function to put it into standard form, we end up with a random variable equal to the original. So, a latent Λ∗ in standard form satisfies
Λ∗=(x↦P[X=x|Λ∗])
As the phrase “standard form” suggests, putting a standard form latent into standard form leaves it unchanged, i.e. Λ∗:=(x↦P[X=x|Λ]) will satisfy Λ∗=(x↦P[X=x|Λ∗]) for any latent Λ; that’s a lemma of the minimal map theorem.
Conceptually: the standard form throws out all information which is completely independent of X, and keeps everything else. In standard statistics jargon: the likelihood function is always a minimal sufficient statistic. (See the minimal map theorem for more explanation.)
Addendum [Added June 12 2024]: Approximate Isomorphism of Natural Latents Which Are Approximately Determined By X
With just the mediation and redundancy conditions, natural latents aren’t quite unique. For any two natural latents Λ,Λ′ over the same variables X, we have Λ→Λ′→X and Λ′→Λ→X. Intuitively, that means the two natural latents “say the same thing about X”; each mediates between X and the other. But either one could still contain some “noise” which is independent of X, and Λ could contain totally different “noise” than Λ′. (Example: X consists of 1000 flips of a biased coin. One natural latent might be the bias, another might be the bias and one roll of a die which has nothing to do with the coin, and a third natural latent might be the bias and the amount of rainfall in Honolulu on April 7 2033.)
In practice, it’s common for the natural latents we use to be approximately a deterministic function of X. In that case, the natural latent in question can’t include much “noise” independent of X. So intuitively, if two natural latents over X are both approximately deterministic functions of X, then we’d expect them to be approximately isomorphic.
Let’s prove that.
Other than the tools already used in the post, the main new tool will be diagrams like Λ←X→Λ, i.e. X mediates between Λ and itself. (If the same variable appearing twice in a Bayes net is confusing, think of it as two separate variables which are equal with probability 1.) The approximation error for this diagram is the entropy of Λ given X:
DKL(P[X=x,Λ=λ,Λ=λ†]||P[X=x]P[Λ=λ|X=x]P[Λ=λ†|X=x])
=∑x,λ,λ†P[X=x,Λ=λ]I[λ=λ†](lnP[X=x,Λ=λ]+lnI[λ=λ†]−lnP[X=x]−lnP[Λ=λ|X=x]−lnP[Λ=λ†|X=x])
=∑x,λP[X=x,Λ=λ](lnP[X=x,Λ=λ]−lnP[X=x]−lnP[Λ=λ|X=x]−lnP[Λ=λ|X=x])
=−∑x,λP[X=x,Λ=λ]lnP[Λ=λ|X=x]
=EX[H(Λ|X=x)]
So if we want to express “Λ is approximately a deterministic function of X” diagrammatically, we can use the diagram Λ←X→Λ. The approximation error on the diagram is EX[H(Λ|X=x)], which makes intuitive sense: low entropy of Λ given X means that Λ is approximately determined by X.
With that in mind, here’s the full proof of isomorphism, including approximation errors:
The first piece should be familiar: it’s just the fundamental theorem, the main focus of this whole post. As usual, it tells us that either of Λ, Λ′ mediates between the other and X. (Minor note: S is intended to denote a subset in some partition of X; it's a generalization of the notation used in the post, in order to allow for stronger redundancy conditions.)
The next two steps are the new part. They start with two diagrams expressing that Λ and Λ′ are both approximately deterministic functions of X…
… and we conclude that Λ is an approximately deterministic function of Λ′
Since Λ and Λ′ appear symmetrically in the assumptions, the same proof also shows that Λ′ is an approximately deterministic function of Λ. Thus, approximate isomorphism, specifically in the sense that either of the two natural latents has approximately zero entropy given the other.