Nice post, as always.
What I take from the sequence up to this point is that the way we formalize information is unfit to capture knowledge. This is quite intuitive, but you also give concrete counterexamples that are really helpful.
It is reasonable to say that a data recorder is accumulating nonzero knowledge, but it is strange to say that exchanging the sensor data for a model derived from that sensor data is always a net decrease in knowledge.
Definitely agreed. This sounds like your proposal doesn't capture the transformation of information into more valuable precomputation (making valuable abstraction requires throwing away some information).
Yep, agreed.
These are still writing that I drafted before we chatted a couple of weeks ago btw. I have some new ideas based on the things we chatted about that I hope to write up soon :)
Knowledge is not just digital abstraction layers
Financial status: This is independent research. I welcome financial support to make further posts like this possible.
Epistemic status: This is in-progress thinking.
This post is part of a sequence on the accumulation of knowledge. Our goal is to articulate what it means for knowledge to accumulate within a physical system.
The challenge is this: given a closed physical system, if I point to a region and tell you that knowledge is accumulating in this region, how would you test my claim? What are the physical characteristics of the accumulation of knowledge? We do not take some agent as the fundamental starting point but instead take a mechanistic physical system as the starting point, and look for a definition of knowledge at the level of physics.
The previous post looked at mutual information between a region within a system and the remainder of the system as a definition of the accumulation of knowledge. This post will explore mutual information between the high- and low-level configurations of a digital abstraction layer.
A digital abstraction layer is a way of grouping the low-level configurations of a system together such that knowing which group the system’s current configuration is in allows you to predict which group the system’s next configuration will be in. A group of low-level configurations is called a high-level configuration. There are many ways to divide the low-level configurations of a system into groups, but most will not have this predictive property.
Here are three examples of digital abstraction layers:
Digital abstraction layers in computers
Information in contemporary computers is encoded as electrons in MOS memory cells. In these systems, the low-level configurations are all the ways that a set of electrons can be arranged within a memory cell. There are two high-level configurations corresponding to the "high" and "low" states of the memory cell. These high-level configurations correspond to groups of low-level configurations.
If we knew the high-level configuration of all the memory cells in a computer then we would know which instruction the computer would process next and could therefore predict what the next high-level configuration of the computer would be. We can make this prediction without knowing the specific low-level configuration of electrons in memory cells. Most other ways that low-level configurations of this system could be grouped into high-level configurations would not make such predictions possible. The design of digital computers is chosen specifically in order that this particular grouping of configurations does allow the evolution of the system to be predicted in terms of high-level configurations.
Digital abstraction layers in the genome
Information in the genome is stored as A, C, G, T bases in DNA. The low-level configurations are the possible arrangements of a small collection of carbon, nitrogen, oxygen, and hydrogen atoms. There are four high-level configurations corresponding to the arrangement of those atoms into Adenin, Cytosine, Guanine, and Thymine molecules.
There are many physically distinct configurations of a small collection of carbon, nitrogen, oxygen, and hydrogen atoms. If we counted each configuration as distinct as we did in the preceding post in this sequence then the number of bits of information would be the number of yes-or-no questions required to pinpoint one particular low-level configuration. But we could also say that we are only interested in distinguishing A from C from G from T molecules, and that we are not interested in distinguishing things at any finer granularity than that, and also that we are not interested in any configuration of atoms that does not constitute one of those four molecules. In this case our high-level system encodes two bits of information, since it takes two yes-or-no questions to distinguish between the four possibilities.
Digital abstraction layers in Conway’s Game of Life
For the third example of a digital abstraction layer, consider the following construction within Conway’s Game of Life that runs an internal simulation of Conway’s Game of Life (full video here):
In case it’s not visible in the truncated gif above, each of the high-level "cells" in this construction is actually a region consisting of many thousands of low-level cells of a much finer-grained version of Conway’s Game of Life. The fuzzy stuff between the cells is machinery that transmits information between one high-level cell and its neighbors in order to produce the high-level state transitions visible in the animation. That machinery is itself an arrangement of gliders, glider guns, and other constructions that evolve according to the basic laws of Life that are running at the lowest level of the automata. It is a very cool construction.
Suppose now that I take the high-level configurations of this system to be the pattern of "on" and "off" cells in the zoomed-out game board, and that I group all the possible low-level game states according to which high-level game state they express. (That is, if two low-level configurations appear as the same arrangement of on/off game cells at the zoomed-out level, then we group them together.)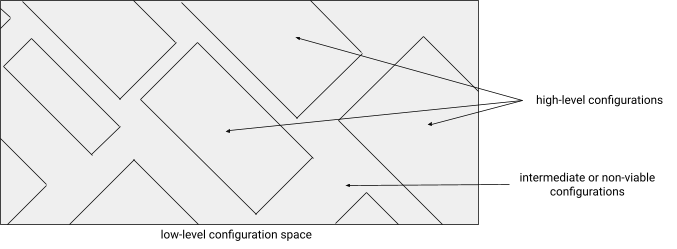
With this grouping of low-level configurations into high-level configurations, I can predict the next high-level configuration if I know the previous high-level configuration. This is because this particular construction is set up in such a way that the high-level configurations evolve according to the laws of Life, so, if I know the high-level configuration at one point in time then I can predict that the overall automata will soon transition into one of the low-level configuration corresponding to the next high-level configuration that is predicted by the laws of Life. The same is not true for most ways of grouping low-level configurations into high-level configurations. If I grouped the low-level configurations according to whether each row contains an even or odd number of active cells then knowing the current high-level configuration -- that is, knowing whether there are currently an even or odd number of active cells in each row -- does not let me predict the next high-level configuration unless I also know the current low-level configuration.
I will call a grouping of low-level configurations into high-level configurations in such a way that transitions between high-level configurations can be understood without knowing the underlying low-level configurations a "digital abstraction layer".
Knowledge defined in terms of digital abstraction layers
Perhaps we can define knowledge as mutual information between the high-level configurations of a digital abstraction layer contained within some region and the low-level configurations of the whole system. This definition encompasses knowledge about the ancestral environment encoded in the genome, knowledge recorded by a computer, and knowledge stored in synapse potentials in the brain, while ruling out difficult-to-retrieve information imprinted on physical objects by stray photon impacts, which was the counterexample we encountered in the previous post.
Example: Digital computer
The computer using a camera to look for an object discussed in the previous post is an example of a digital abstraction layer. The low-level configurations are the physical configurations of the computer, and the high-level configurations are the binary states of the memory cells and CPU registers that we interact with when we write computer programs. If I know the current high-level configuration of the computer then I can predict the next high-level configuration of the computer, since I know which instruction the CPU will read next and I can predict what effect that will have without knowing anything about the low-level configuration of electrons trapped in semiconductors.
In this example we would be able to measure an increase in mutual information between the high-level configuration of the computer and the low-level configuration of the environment as the computer uses its camera to find the object we have programmed it to seek.
This also helps us to understand what it means for an entity to accumulate self-knowledge: it means that there is an increase over time of the mutual information between the high- and low-level configurations of that entity. A computer using an electron microscope to build a circuit diagram of its own CPU fits this definition, while a rock that is "a perfect map of itself" does not.
Counterexample: Data recorder
But what about a computer that merely records every image captured by a camera? This system has at least as much mutual information with its environment as one that uses those observations to build up a model of its surroundings. It is reasonable to say that a data recorder is accumulating nonzero knowledge, but it is strange to say that exchanging the sensor data for a model derived from that sensor data is always a net decrease in knowledge. If I discovered that my robot vacuum recorded its sensor data to some internal storage device I might be mildly concerned, but if I discovered that my robot vacuum was deriving sophisticated models of human psychology from that sensor data I would be much more concerned. Yet a mutual information conception of knowledge seems to have no way to account for the computational process of turning raw sensor data into actionable models.
Conclusion
It is not clear whether digital abstraction layers have a fundamental relationship with knowledge. It does seem that information must be useful and accessible in order to precipitate the kind of goal-directed action that we seek to understand, and digital abstraction layers are one way to think about what it means for information to be useful and accessible at the level of physics.
More fundamentally, it seems that mutual information fails to capture what we mean when we think of the accumulation of knowledge, even after we rule out the cases discussed in the previous post. A physical process that begins with some observations and ends with an actionable model derived from those observations should generally count as a positive accumulation of knowledge, yet such a process will never increase its mutual information with its environment, since by hypothesis no new observations are added along the way. The next post will look beyond information theory for a definition of the accumulation of knowledge.