projection of "▁queen" on span( "▁king", "▁man", "▁woman") is ['▁king', '▁King', '▁woman', '▁queen', '▁rey', '▁Queen', 'peror', '▁prince', '▁roi', '▁König']
"▁queen" is the closest match only if you exclude any version of king and woman. But this seems to be only because "▁queen" is already the 2:nd closes match for "▁king". Involving "▁man" and "▁woman" is only making things worse.
I then tried looking up exactly what the word2vec result is, and I'm still not sure.
WikipediasitesMikolov et al. (2013). This paper is for embeddings from RNN language models, not word2vec, which is ok for my purposes, because I'm also not using word2vec. More problematic is that I don't know how to interpret how strong their results are. I think the relevant result is this
We see that the RNN vectors capture significantly more syntactic regularity than the LSA vectors, and do remarkably well in an absolute sense, answering more than one in three questions correctly.
which don't seem very strong. Also I can't find any explanation of what LSA is.
I also found this other paper which is about word2vec embeddings and have this promising figure
But the caption is just a citation to this third paper, which don't have that figure!
I've not yet read the two last papers in detail, and I'm not sure if or when I'll get back to this investigation.
If someone knows more about exactly what the word2vec embedding results are, please tell me.
I have two hypothesises for what is going on. I'm leaning towards 1, but very unsure.
1)
king - man + woman = queen
is true for word2vec embeddings but not in LLaMa2 7B embeddings because word2vec has much fewer embedding dimensions.
LLaMa2 7B has 4096 embedding dimensions.
This paper uses a variety of word2vec with 50, 150 and 300 embedding dimensions.
Possibly when you have thousands of embedding dimensions, these dimensions will encode lots of different connotations of these words. These connotations will probably not line up with the simple relation [king - man + woman = queen], and therefore we get [king - man + woman ≠ queen] for high dimensional embeddings.
2)
king - man + woman = queen
Isn't true for word2vec either. If you do it with word2vec embeddings you get more or less the same result I did with LLaMa2 7B.
(As I'm writing this, I'm realising that just getting my hands on some word2vec embeddings and testing this for myself, seems much easier than to decode what the papers I found is actually saying.)
LLMs (and probably most NNs) have lots of meaningfull, interpretable linear feature directions. These can be found though various unsupervised methods (e.g. SAEs) and supervised methods (e.g. linear probs).
However, most human interpretable features, are not what I would call the models true features.
If you find the true features, the network should look sparse and modular, up to noise factors. If you find the true network decomposition, than removing the what's left over should imporve performance, not make it wors.
Because the network has a limited number of orthogonal directions, there will be interference terms that the network would like to remove, but can't. A real network decomposition will be everything except this noise.
This is what I think mech-interp should be looking for
It's possible that I'm wrong and there is no such thing as "the networks true features". But we've (humans colectivly) only just started this reaserch agenda. The fact that we haven't found it yet, is not much evidence either way.
Reality has a surprising amount of detail[1]. If the training objective is improved by better modeling the world, and the model is does not have enough parameters to capture all of the things about the world which would help reduce loss, the model will learn lots of the incidental complexities of the world. As a concrete example, I can ask something like
What is the name of the stadium in Rome at the confluence of two rivers, next to the River Walk Mariott? Answer from memory.
and the current frontier models know enough about the world that they can, without tools or even any substantial chain of thought, correctly answer that trick question[2]. To be able to answer questions like this from memory, models have to know lots of geographical details about the world.
Unless your technique for extracting a sparse modular world model produces a resulting world model which is larger than the model it came from, I think removing the things which are noise according to your sparse modular model will almost certainly hurt performance on factual recall tasks like this one.
The trick is that there is second city named Rome in the United States, in the state of Georgia. Both Romes contain a confluence of two rivers, both contain river walks, both contain Mariotts, both contain stadiums, but only the Rome in the US contains a stadium at the confluence of two rivers next to a Mariott named for its proximity to the river.
I do exect some amount of superpossition, i.e. the model is using almost orthogonal directions to encode more concept than it has neurons. Depending on what you mean by "larger" this will result in a world model that is larger than the network. However such an encoding will also result in noise. Superpossition will nessesarely lead to unwanted small amplitude connections between uncorelated concepts. Removing these should imporve performance, and if it dosn't it means that you did the decomposition wrong.
People used to say (maybe still do? I'm not sure) that we should use less jargon to increase accessibility to writings on LW, i.e. make it easier to outsider to read.
I think this is mostly a confused take. The underlying problem is inferential distance. Geting rid of the jargon is actually unhelpful since it hides the fact that there is an inferential distance.
When I want to explain physics to someone and I don't know what they already know, I start by listing relevant physics jargon and ask them what words they know. This is a super quick way to find out what concepts they already have, and let me know what level I should start on. This work great in Swedish since in Swedish most physics words are distinct from ordinary words, but unfortunately don't work as well in English, which means I have to probe a bit deeper than just checking if they recognise the words.
Jargon isn't typically just synonyms to some common word, and when it is, I predict that it didn't start out that way, but that the real meaning was destroyed by too many people not bothering to learn the word properly. This is because people invent new words (jargon) when they need a new word to point to a new concept that didn't already have a word.
I seen some post by people who are not native to LW trying to fit in and be accepted by using LW jargon, without bothering to understand the underling concepts or even seem to notice that this is something they're supposed to do. The result is very jarring and rather than making the post look read like a typical LW post, their misuse of LW jargon makes it extra obvious that they are not a native. Edit to add: This clearly illustrates that the jargon isn't just synonyms to words/concepts they already know.
The way to make LW more accessible is to embrace jargon, as a clear signal of assumed prior knowledge of some concept, and also have a dictionary, so people can look up words they don't know. I think this is also more or less what we're already doing, because it's kind of the obvious thing to do.
There is basically zero risk that the people wanting less jargon will win this fight, because jargon is just too useful for communication, and humans really like communication, especially nerds. But maybe it would be marginally helpful for more people to have an explicit model of what jargon is and what it's for, which is my justification for this quick take.
Would a post containing a selection of terms and an explanation of what useful concepts they point to (with links to parts of the sequences and other posts/works) be useful?
I was pretty sure this exist, maybe even built into LW. It seems like an obvious thing, and there are lots of parts of LW that for some reason is hard to find from the fron page. Googleing "lesswrong dictionary" yealded
I mean that you take some known distribution (the training distribution) as a starting point. But when sampling actions you do so from shifted on truncated distribution to favour higher reward policies.
The in the decision transformers I linked, AI is playing a variety of different games, where the programmers might not know what a good future reward value would be. So they let the system AI predict the future reward, but with the distribution shifted towards higher rewards.
I discussed this a bit more after posting the above comment, and there is something I want to add about the comparison.
In quantilizers if you know the probability of DOOM from the base distribution, you get an upper bound on DOOM for the quantaizer. This is not the case for type of probability shift used for the linked decision transformer.
DOOM = Unforeseen catastrophic outcome. Would not be labelled as very bad by the AI's reward function but is in reality VERY BAD.
From my reading of quantilizers, they might still choose "near-optimal" actions, just only with a small probability. Whereas a system based on decision transformers (possibly combined with a LLM) could be designed that we could then simply tell to "make me a tea of this quantity and quality within this time and with this probability" and it would attempt to do just that, without trying to make more or better tea or faster or with higher probability.
I feel a bit behind on everything going on in alignment, so for the next weeks (or more) I'll focus on catching up on what ever I find interesting. I'll be using my short form, to record my though.
I make no promises that reading this is worth anyone's time.
Linda's alignment reading adventures part 1
What to focus on?
I do have some opinions on what aliment directions are more or less promising. I'll probably venture in other directions too, but my main focus is going to be around what I expect an alignment solution to look like.
I think that to have an aligned AI it is necessary (but not sufficient) that we have shared abstractions/ontology/concepts/ (what ever you want to call it) with the AI.
I think the way to make progress on the above is to understand what ontology/concepts/abstraction our current AIs are using, and the process that shapes these abstraction.
I think the way to do this is though mech-interp, mixed with philosophising and theorising. Currently I think the mech-interp part (i.e. look at what is actually going on in a network) is the bottleneck, since I think that philosophising with out data (i.e. agent foundations) has not made much progress lately.
Conclusion:
I'll mainly focus on reading up on mech-interp and related areas such as dev-interp. I've started on the interp section of Lucius's aliment reading list.
I should also read some John Wentworth, since his plan is pretty close to the path I think is most promising.
But also, how interesting is this. Basically they removed the cheese observation, it made the agent act as if there where no cheese. This is not some sophisticated steering technique that we can use to align the AIs motivation.
I discussed this with Lucius who pointed out, that the interesting result is that: The the cheese location information is linearly separable from other information, in the middle of the network. I.e. it's not scrambled in a completely opaque way.
Alon’s book is the ideal counterargument to the idea that organisms are inherently human-opaque: it directly demonstrates the human-understandable structures which comprise real biological systems.
Both these posts are evidence for the hypothesis that we should expect evolved networks to be modular, in a way that is possible for us to decode.
By "evolved" I mean things in the same category as natural selection and gradient decent.
There is nothing special about human level intelligence, unless you have imitation learning, in which case human level capabilities are very special.
General intelligence is not very efficient. Therefore there will not be any selection pressure for general intelligence as long as other options are available.
Second reply. And this time I actually read the link. I'm not suppressed by that result.
My original comment was a reaction to claims of the type [the best way to solve almost any task is to develop general intelligence, therefore there is a strong selection pressure to become generally intelligent]. I think this is wrong, but I have not yet figured out exactly what the correct view is.
But to use an analogy, it's something like this: In the example you gave, the AI get's better at the sub tasks by learning on a more general training set. It seems like general capabilities was useful. But consider that we just trained on even more data for a singel sub task, then wouldn't it develop general capabilities, since we just noticed that general capabilities was useful for that sub task. I was planing to say "no" but I notice that I do expect some transfer learning. I.e. if you train on just one of the dataset, I expect it to be bad at the other ones, but I also expect it to learn them quicker than without any pre-training.
I seem to expect that AI will develop general capabilities when training on rich enough data, i.e. almost any real world data. LLM is a central example of this.
I think my disagreement with at least my self from some years ago and probably some other people too (but I've been away a bit form the discourse so I'm not sure), is that I don't expect as much agentic long term planing as I used to expect.
I agree that eventually, at some level of trying to solve enough different types of tasks, GI will be efficient, in terms of how much machinery you need, but it will never be able to compete on speed.
Also, it's an open question what is "enough different types of tasks". Obviously, for a sufficient broad class of problems GI will be more efficient (in the sense clarified above). Equally obviously, for a sufficient narrow class of problems narrow capabilities will be more efficient.
Humans have GI to some extent, but we mostly don't use it. This is interesting. This means that a typical human environment is complex enough so that it's worth carrying around the hardware for GI. But even though we have it, it is evolutionary better to fall back at habits, or imitation, or instinkt, for most situations.
Looking back to exactly what I wrote, I said there will not be any selection pressure for GI as long as other options are available. I'm not super confident in this. But if I'm going to defend it here anyway by pointing out that "as long as other options are available", is doing a lot of the work here. Some problems are only solvable by noticing deep patterns in reality, and in this case a sufficiently deep NN with sufficient training will learn this, and that is GI.
Yesterday was the official application deadline for leading a project at the next AISC. This means that we just got a whole host of project proposals.
If you're interested in giving feedback and advise to our new research leads, let me know. If I trust your judgment, I'll onboard you as an AISC advisor.
Also, it's still possible to send us a late AISC project proposals. However we will prioritise people how applied in time when giving support and feedback. Further more, we'll prioritise less late applications over more late applications.
Blogposts are the result of noticing difference in beliefs. Either between you and other of between you and you, across time.
I have lots of ideas that I don't communicate. Sometimes I read a blogpost and think "yea I knew that, why didn't I write this". And the answer is that I did not have an imagined audience.
My blogposts almost always span after I explained a thing ~3 times in meat space. Generalizing from these conversations I form an imagined audience which is some combination of the ~3 people I talked to. And then I can write.
(In a conversation I don't need to imagine an audience, I can just probe the person in front of me and try different explanations until it works. When writing a blogpost, I don't have this option. I have to imagine the audience.)
Another way to form an imagined audience is to write for your past self. I've noticed that a lot of thig I read are like this. When just learning something or realizing something, and past you who did not know the thing is still fresh in your memory, then it is also easier to write the thing. This short form is of this type.
I wonder if I'm unusually bad at remembering the thoughts and belief's of past me? My experience is that I pretty quickly forget what it was like not to know a thing. But I see others writing things aimed at their pasts self from years ago.
I think I'm writing short form as a message to my future self, when I have forgotten this insight. I want my future self to remember this idea of how blogposts spawn. I think it will help her guide her writing posts, but also help her not to be annoyed when someone else writes a popular thing that I already knew, and "why did I not write this?" There is an answer to the question "why did I not write this?" and the answer is "because I did not know how to write it".
A blogpost is a bridge between a land of not knowing and a land of knowing. Knowing the destination of the bridge is not enough to build the bridge. You also have to know the starting point.
I suspect it's not possible to build autonomous aligned AIs (low confidence). The best we can do is some type of hybrid humans-in-the-loop system. Such a system will be powerful enough to eventually give us everything we want, but it will also be much slower and intellectually inferior to what is possible with out humans-in-the-loop. I.e. the alignment tax will be enormous. The only way the safe system can compete, is by not building the unsafe system.
Therefore we need AI Governance. Fortunately, political action is getting a lot of attention right now, and the general public seems to be positively inclined to more cautious AI development.
After getting an immediate stop/paus on larger models, I think next step might be to use current AI to cure aging. I don't want to miss the singularity because I died first, and I think I'm not the only one who feels this way. It's much easier to be patient and cautious in a world where aging is a solved problem.
We probably need a strict ban on building autonomous superintelligent AI until we reached technological maturity. It's probably not a great idea to build them after that either, but they will probably not pose the same risk any longer. This last claim is not at all obvious. The hardest attack vector to defend against would be manipulation. I think reaching technological maturity will make us able to defend against any military/hard-power attack. This includes for example having our own nano-bot defence system, to defend against hostile nanobots. Manipulation is harder, but I think there are ways to solve that, with enough time to set up our defences.
An important crux for what there end goal is, including if there is some stable end where we're out of the danger, is to what extent technological maturity also leads to a stable cultural/political situation, or if that keeps evolving in ever new directions.
Estimated MSE loss for three diffrent ways of embedding features into neuons, when there are more possible features than neurons.
I've typed up some math notes for how much MSE loss we should expect for random embedings, and some other alternative embedings, for when you have more features than neurons. I don't have a good sense for how ledgeble this is to anyone but me.
Note that neither of these embedings are optimal. I belive that the optimal embeding for minimising MSE loss is to store the features in almost orthogonal directions, which is similar to random embedings but can be optimised more. But I also belive that MSE loss don't prefeer this solution very much, which means that when there are other tradeofs, MSE loss might not be enough to insentivise superposstion.
This does not mean we should not expect superpossition in real network.
Many networks uses other loss functions, e.g. cross-entropy.
Even if the loss is MSE on the final output, this does not mean MSE is the right loss for modeling the dynamics in the middle of the network.
Setup and notation
T features
D neurons
z active featrues
Assuming:
z≪D<T
True feature values:
y = 1 for active featrus
y = 0 for inactive features
Using random embedding directions (superpossition)
Estimated values:
^y=a + ϵ where E[ϵ2]=(z−1)a2/D for active features
We emebd a single feature in each neuron, and the rest of the features, are just not represented.
Estimated values:
^y=y for represented features
^y=0 for non represented features
Total Mean Squared Error (MSE)
MSEsingle=zT−DD
One neuron per feature
We embed each feature in a single neuron.
^y=a∑y where the sum is over all feature that shares the same neuron
We assume that the probability of co-activated features on the same neuron is small enough to ignore. We also assume that every neuron is used at least once. Then for any active neuron, the expected number of inactive neurons that will be wrongfully activated, are T−DD, giving us the MSE loss for this case as
MSEmulti=z((1−a)2+(TD−1)a2)
We can already see that this is smaller than MSErand, but let's also calculate what the minimum value is. MSErand is minimised by
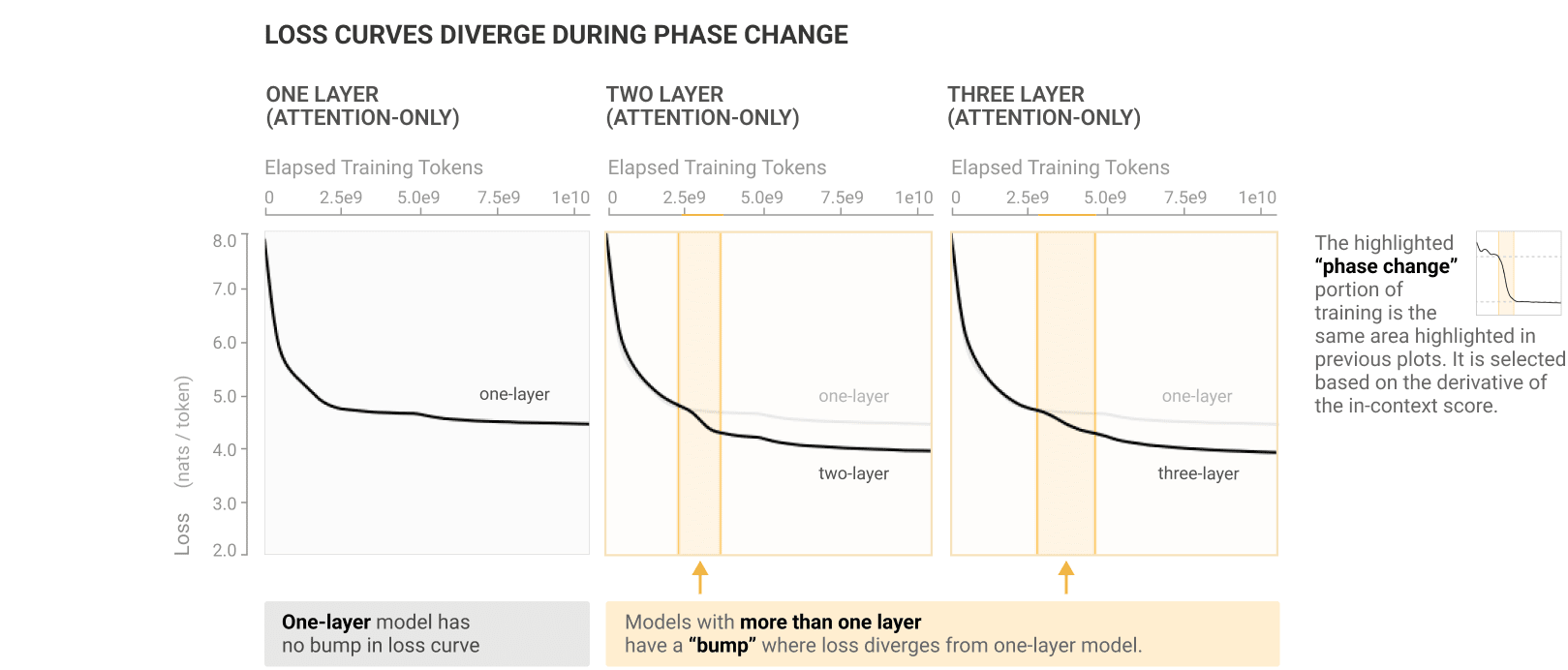
This already strongly suggests some connection between induction heads and in-context learning, but beyond just that, it appears this window is a pivotal point for the training process in general: whatever's occurring is visible as a bump on the training curve (figure below). It is in fact the only place in training where the loss is not convex (monotonically decreasing in slope).
I can see the bump, but it's not the only one. The two layer graph has a second similar bump, which also exists in the one layer model, and I think I can also see it very faintly in the three level model. Did they ignore the second bump because it only exists in small models, while their bump continues to exist in bigger models?
Recently someone either suggested to me (or maybe told me they or someone where going to do this?) that we should train AI on legal texts, to teach it human values. Ignoring the technical problem of how to do this, I'm pretty sure legal text are not the right training data. But at the time, I could not clearly put into words why. Todays SMBC explains this for me:
Law is not a good representation or explanation of most of what we care about, because it's not trying to be. Law is mainly focused on the contentious edge cases.
Training an AI on trolly problems and other ethical dilemmas is even worse, for the same reason.
If LMs reads each others text we can get LM-memetics. A LM meme is a pattern which, if it exists in the training data, the LM will output at higher frequency that in the training data. If the meme is strong enough and LLMs are trained on enough text from other LMs, the prevalence of the meme can grow exponentially. This has not happened yet.
There can also be memes that has a more complicated life cycle, involving both humans and LMs. If the LM output a pattern that humans are extra interested in, then the humans will multiply that pattern by quoting it in their blogpost, which some other LM will read, which will make the pattern more prevalent in the output of that transformer, possibly.
Generative models memetics:
Same thing can happen for any model trained to imitate the training distribution.
I recently updated how I view the alignment problem. The post that caused my update is this one form the shard sequence. Also worth mentioning is older post that points to the same thing, but I just happen to read it later.
Basically I used to think we needed to solve both outer and inner alignment separately. No I no longer think this is a good decomposition of the problem.
It’s not obvious that alignment must factor in the way described above. There is room for trying to set up training in such a way to guarantee a friendly mesa-objective somehow without matching it to a friendly base-objective. That is: to align the AI directly to its human operator, instead of aligning the AI to the reward, and the reward to the human.
This is probably too obvious to write, but I'm going to say it anyway. It's my short form, and approximately no-one reads short forms. Or so I'm told.
Human value formation is to a large part steered by other humans suggesting value systems for you. You get some hard to interpret reward signal from your brainstem, or something. There are lots of "hypothesis" for the "correct reward function" you should learn.
(Quotation marks because there are no ground through for what values you should have. But this is mathematically equivalent to a learning the true statistic generating the data, from a finite number of data points. Also, there is maybe some ground truth of what the brainstem rewards, or maybe not. According to Steve the there is this loop, where when the brainstem don't know if things are good or not, it just mirror back cortex's own opinion to the cortex.)
To locate the hypothesis, you listen to other humans. I make this claim not just for moral values, but for personal preferences. Maybe someone suggest to you "candy is tasty" and since this seems to fit with your observation, no you also like candy. This is a bad example since for taste specifically the brainstem has pretty clear opinions. Except there is acquired taste... so maybe not a terrible example.
Another example: You join a hobby. You notice you like being at the hobby place doing the hobby thing. Your hobby fired says (i.e. offer the hypothesis) "this hobby is great". This seems to fit your data so now you believe you like the hobby. And because you believe you like the hobby, you end up actually liking the hobby because of a self reinforcing loop. Although this don't always work. Maybe after some time your friends quit the hobby and this makes it less fun, and you realise (change your hypothesis) that you manly liked the hobby for the people.
Maybe there is a ground truth about what we want for ourselves? I.e. we can end up with wrong beliefs about what we want due to pear pressure, commercials, etc. But with enough observation we will notice what it is we actually want.
Clearly humans are not 100% malleable, but also, it seems like even our personal preferences are path dependent (i.e. pick up lasting influences from our environment). So maybe some annoying mix...
I'm basically ready to announce the next Technical AI Safety Unconference (TAISU). But I have hit a bit of decision paralysis as to what dates it should be.
If you are reasonably interested in attending, please help me by filling in this doodle
Recently an AI safety researcher complained to me about some interaction they had with an AI Safety communicator. Very stylized, there interaction went something like this:
(X is some fact or topic related to AI Safety
Communicator: We don't know anything about X and there is currently no research on X.
Researcher: Actually, I'm working on X, and I do know some things about X.
Communicator: We don't know anything about X and there is currently no research on X.
I notice that I semi-frequently hear communicators saying things like the thing above. I think what they mean is that our our understanding of X is far from the understanding that is needed, and the amount of researchers working on this is much fewer than what would be needed, and this get rounded off to we don't know anything and no one is doing anything about it. If this is what is going on then I think this is bad.
I think that is some cases when someone says "We don't know anything about X and there is currently no research on X." they probably literally mean it. There are some people who think that approximately no-one working on AI Safety is doing real AI Safety researchers. But I also think that most people who are saying "We don't know anything about X and there is currently no research on X." are doing some mixture of rounding off, some sort of unreflexively imitation learning, i.e. picking up the sentence structure from others, especially from high status people.
I think using a language that hides the existence of the research that does exist is bad. Primarily because it's misinformative. Do we want all new researchers to start from scratch? Because that is what happens if you tell them there is no pre-existing research and they believe you.
I also don't think this exaggeration will help with recruitment. Why do you think people would prefer to join a completely empty research field instead of a small one? From a personal success perspective (where success can mean either impact or career success) a small research field is great, lots if low-hanging fruit around. But a completely untrodden research direction is terrible, you will probably just get lost, not get anything done, and even if you fid something, there's nowhere to publish it.
I notice that I don't expect FOOM like RSI, because I don't expect we'll get an mesa optimizer with coherent goals. It's not hard to give the outer optimiser (e.g. gradient decent) a coherent goal. For the outer optimiser to have a coherent goal is the default. But I don't expect that to translate to the inner optimiser. The inner optimiser will just have a bunch of heuristics and proxi-goals, and not be very coherent, just like humans.
The outer optimiser can't FOOM, since it don't do planing, and don't have strategic self awareness. It's can only do some combination of hill climbing and random trial and error. If something is FOOMing it will be the inner optimiser, but I expect that one to be a mess.
I notice that this argument don't quite hold. More coherence is useful for RSI, but complete coherence is not necessary.
I also notice that I expect AIs to make fragile plans, but on reflection, I expect them to gett better and better with this. By fragile I mean that the longer the plan is, the more likely it is to break. This is true for human too though. But we are self aware enough about this fact to mostly compensate, i.e. make plans that don't have too many complicated steps, even if the plan spans a long time.
Any policy can be model as a consequentialist agent, if you assume a contrived enough utility function. This statement is true, but not helpful.
The reason we care about the concept agency, is because there are certain things we expect from consequentialist agents, e.g. instrumental convergent goals, or just optimisation pressure in some consistent direction. We care about the concept of agency because it holds some predictive power.
[... some steps of reasoning I don't know yet how to explain ...]
Therefore, it's better to use a concept of agency that depend on the internal properties of an algorithm/mind/policy-generator.
I don't think agency can be made into a crisp concept. It's either a fuzzy category or a leaky abstraction depending on how you apply the concept. But it does point to something important. I think it is worth tracking how agentic different systems are, because doing so has predictive power.
Toy model: Each agent has a utility function they want to maximise. The input to the utility function is a list of values describing the state of the world. Different agents can have different input vectors. Assume that every utility function monotonically increases, decreases or stays constant for changes in each impute variable (I did say it was a toy model!). An agent is said to value something if the utility function increases with increasing quantity of that thing. Note that if an agents utility function decreases with increasing quantity of a thing, then the agent values the negative of that thing.
In this toy model agent A is aligned with agent B if and only if A values everything B values.
Q: However does this operationalisation match my intuitive understanding of alignment? A: Good but not perfect.
This definition of alignment is transitive, but not symmetric. This matches the properties I think a definition of alignment should have.
How about if A values a lot of things that B doesn't care about, and only cares very little about the things A cares about? That would count as aligned in this operationalisation but not necessarily match my intuitive understanding of alignment.
What is alignment? (operationalisation second try)
Agent A is aligned with agent B, if and only if, when we give more power (influence, compute, improved intelligence, etc.) to A, then things get better according to B’s values, and this relation holds for arbitrary increases of power.
This operationalisation points to exactly what we want, but is also not very helpful.
The not so operationalized answer is that a good operationalization is one that are helpful for achieving alignment.
An operationalization of [helpfulness of an operationalization] would give some sorts to gears level understanding of what shape the operationalization should have to be helpful. I don't have any good model for this, so I will just gesture vaguely.
I think that mathematical descriptions are good, since they are more precise. My first operationalization attempt is pretty mathematical which is good. It is also more "constructive" (not sure if this is the exact right word), i.e. it describes alignment in terms of internal properties, rather than outcomes. Internal properties are more useful as design guidelines, as long as they are correct. The big problem with my first operationalization is that it don't actually point to what we want.
The problem with the second attempt is that it just states what outcome we want. There is nothing in there to help us achieve it.
Can't you restate the second one as the relationship between two utility functions UA and UB such that increasing one (holding background conditions constant) is guaranteed not to decrease the other? I.e. their respective derivatives are always non-negative for every background condition.
Yes, I like this one. We don't want the AI to find a way to give it self utility while making things worse for us. And if we are trying to make things better for us, we don't want the AI to resist us.
Do you want to find out what these inequalities implies about the utility functions? Can you find examples where your condition is true for non-identical functions?
UA changes only when MA (A's world model) changes which is ultimately caused by new observations, i.e. changes in the world state (let's assume that both A and B perceive the world quite accurately).
If whenever UA changes UB doesn't decrease, then whatever change in the world increased UA, B at least doesn't care. This is problematic when A and B need the same scarce resources (instrumental convergence etc). It could be satisfied if they were both satisficers or bounded agents inhabiting significantly disjoint niches.
A robust solution seems seems to be to make (super accurately modeled) UB a major input to UA.
Then (I think) for your inequality to hold, it must be that
U_B = f(3x+y), where f' >= 0
If U_B care about x and y in any other proportion, then B can make trade-offs between x and y which makes things better for B, but worse for A.
This will be true (in theory) even if both A and B are satisfisers. You can see this by assuming replacing y and x with sigmoids of some other variables.