This is a linkpost for https://www.anthropic.com/index/core-views-on-ai-safety
New Comment
I think the worldview here seems cogent. It's very good for Anthropic folk to be writing up their organizational-beliefs publicly. I'm pretty sympathetic to "man, we have no idea how to make real progress without empirical iteration, so we just need to figure out how to make empirical iteration work somehow."
I have a few disagreements. I think the most important ones route through "how likely is this to accelerate race dynamics and how bad is that?".
We've subsequently begun deploying Claude now that the gap between it and the public state of the art is smaller.
It sounds like this means Claude is still a bit ahead of the public-state-of-the-art (but not much). But I'm not sure I'm interpreting it correctly.
I want to flag that an Anthropic employee recently told me something like "Anthropic wants to stay near the front of the pack at AI capabilities so that their empirical research is relevant, but not at the actual front of the pack to avoid accelerating race-dynamics." That would be a plausibly reasonable strategy IMO (although I'd still be skeptical about how likely it was to exacerbate race dynamics in a net-negative way). But it sounds like Claude was released while it was an advance over the public sota.
I guess I could square this via "Claude was ahead of the public SOTA, but not an advance over privately available networks?".
But, it generally looks to me like OpenAI and Anthropic, the two ostensibly safety-minded orgs, are nontrivially accelerating AI hype and progress due to local races between the two of them, and I feel quite scared about that.
I realize they're part of some dynamics that extend beyond them, and I realize there are a lot of difficult realities like "we really do believe we need to work on LLMs, those really are very expensive to train, we really need to raise money, the money really needs to come from somewhere, and doing some releases and deals with Google/Microsoft etc seem necessary." But, it sure looks like the end result of all of this is an accelerated race, and even if you're only on 33%ish likelihood of "a really pessimistic scenario", that's a pretty high likelihood scenario to be accelerating towards.
My guess is that from the inside of Anthropic-decisionmaking, the race feels sort of out-of-their-control, and it's better to ride the wave that to sit doing nothing. But it seems to me like "figure out how to slow down the race dynamics here" should be a top organizational priority, even within the set of assumptions outlined in this post.
I both agree that the race dynamic is concerning (and would like to see Anthropic address them explicitly), and also think that Anthropic should get a fair bit of credit for not releasing Claude before ChatGPT, a thing they could have done and probably gained a lot of investment / hype over. I think Anthropic's "let's not contribute to AI hype" is good in the same way that OpenAI's "let's generate massive" hype strategy is bad.
Like definitely I'm worried about the incentive to stay competitive, especially in the product space. But I think it's worth highlighting that Anthropic (and Deepmind and Google AI fwiw) have not rushed to product when they could have. There's still the relevant question "is building SOTA systems net positive given this strategy", and it's not clear to me what the answer is, but I want to acknowledge that "building SOTA systems and generating hype / rushing to market" is the default for startups and "build SOTA systems and resist the juicy incentive" is what Anthropic has done so far & that's significant.
Yeah I agree with this.
To be clear, I think Anthropic has done a pretty admirable job of showing some restraint here. It is objectively quite impressive. My wariness is "Man, I think the task here is really hard and even a very admirably executed company may not be sufficient."
My summary to augment the main one:
Broadly human level AI may be here soon and will have a large impact. Anthropic has a portfolio approach to AI safety, considering both: optimistic scenarios where current techniques are enough for alignment, intermediate scenarios where substantial work is needed, and pessimistic scenarios where alignment is impossible; they do not give a breakdown of probability mass in each bucket and hope that future evidence will help figure out what world we're in (though see the last quote below). These buckets are helpful for understanding the goal of developing: better techniques for making AI systems safer, and better ways of identifying how safe or unsafe AI systems are. Scaling systems is required for some good safety research, e.g., some problems only arise near human-level, Debate and Constitutional AI need big models, need to understand scaling to understand future risks, if models are dangerous, compelling evidence will be needed.
They do three kinds of research: Capabilities which they don’t publish, Alignment Capabilities which seems mostly about improving chat bots and applying oversight techniques at scale, and Alignment Science which involves interpretability and red-teaming of the approaches developed in Alignment Capabilities. They broadly take an empirical approach to safety, and current research directions include: scaling supervision, mechanistic interpretability, process-oriented learning, testing for dangerous failure modes, evaluating societal impacts, and understanding and evaluating how AI systems learn and generalize.
Select quotes:
- “Over the next 5 years we might expect around a 1000x increase in the computation used to train the largest models, based on trends in compute cost and spending. If the scaling laws hold, this would result in a capability jump that is significantly larger than the jump from GPT-2 to GPT-3 (or GPT-3 to Claude). At Anthropic, we’re deeply familiar with the capabilities of these systems and a jump that is this much larger feels to many of us like it could result in human-level performance across most tasks.”
- The facts “jointly support a greater than 10% likelihood that we will develop broadly human-level AI systems within the next decade”
- “In the near future, we also plan to make externally legible commitments to only develop models beyond a certain capability threshold if safety standards can be met, and to allow an independent, external organization to evaluate both our model’s capabilities and safety.”
- “It's worth noting that the most pessimistic scenarios might look like optimistic scenarios up until very powerful AI systems are created. Taking pessimistic scenarios seriously requires humility and caution in evaluating evidence that systems are safe.”
I'll note that I'm confused about the Optimistic, Intermediate, and Pessimistic scenarios: how likely does Anthropic think each is? What is the main evidence currently contributing to that world view? How are you actually preparing for near-pessimistic scenarios which "could instead involve channeling our collective efforts towards AI safety research and halting AI progress in the meantime?"
how likely does Anthropic think each is? What is the main evidence currently contributing to that world view?
I wouldn't want to give an "official organizational probability distribution", but I think collectively we average out to something closer to "a uniform prior over possibilities" without that much evidence thus far updating us from there. Basically, there are plausible stories and intuitions pointing in lots of directions, and no real empirical evidence which bears on it thus far.
(Obviously, within the company, there's a wide range of views. Some people are very pessimistic. Others are optimistic. We debate this quite a bit internally, and I think that's really positive! But I think there's a broad consensus to take the entire range seriously, including the very pessimistic ones.)
This is pretty distinct from how I think many people here see things – ie. I get the sense that many people assign most of their probability mass to what we call pessimistic scenarios – but I also don't want to give the impression that this means we're taking the pessimistic scenario lightly. If you believe there's a ~33% chance of the pessimistic scenario, that's absolutely terrifying. No potentially catastrophic system should be created without very compelling evidence updating us against this! And of course, the range of scenarios in the intermediate range are also very scary.
How are you actually preparing for near-pessimistic scenarios which "could instead involve channeling our collective efforts towards AI safety research and halting AI progress in the meantime?"
At a very high-level, I think our first goal for most pessimistic scenarios is just to be able to recognize that we're in one! That's very difficult in itself – in some sense, the thing that makes the most pessimistic scenarios pessimistic is that they're so difficult to recognize. So we're working on that.
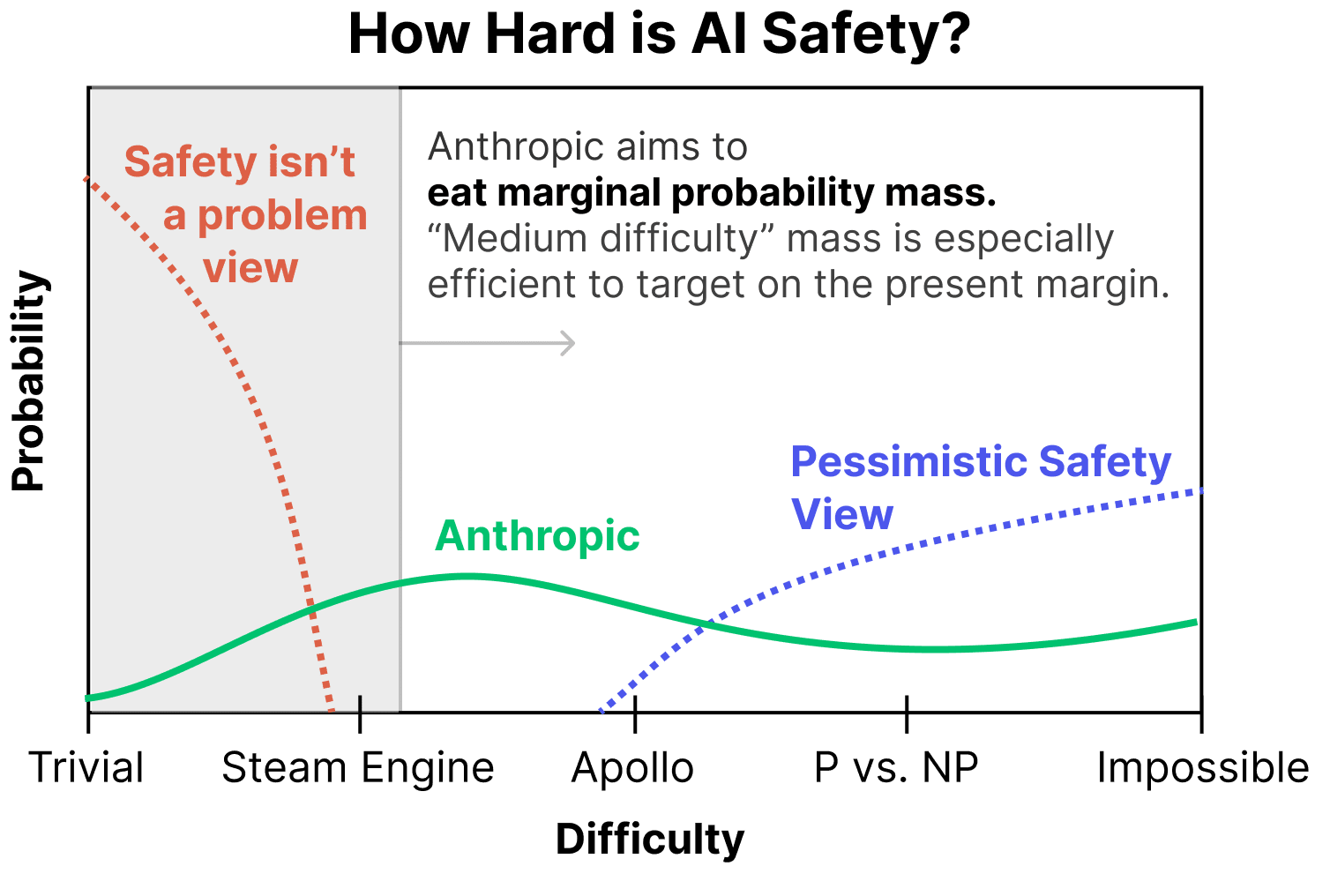
But before diving into our work on pessimistic scenarios, it's worth noting that – while a non-trivial portion of our research is directed towards pessimistic scenarios – our research is in some ways more invested in optimistic scenarios at the present moment. There are a few reasons for this:
- We can very easily "grab probability mass" in relatively optimistic worlds. From our perspective of assigning non-trivial probability mass to the optimistic worlds, there's enormous opportunity to do work that, say, one might think moves us from a 20% chance of things going well to a 30% chance of things going well. This makes it the most efficient option on the present margin.
(To be clear, we aren't saying that everyone should work on medium difficulty scenarios – an important part of our work is also thinking about pessimistic scenarios – but this perspective is one reason we find working on medium difficulty worlds very compelling.) - We believe we learn a lot from empirically trying the obvious ways to address safety and seeing what happens. My colleague Andy likes to say things like "First we tried the dumbest way to solve alignment (prompting), then we tried the second dumbest thing (fine tuning), then we tried the third dumbest thing…" I think there's a lot to be said for "working our way up the ladder of trying dumb things" and addressing harder and harder scenarios as we do so. Earlier techniques are both building blocks and baselines for further research.
- A crucial part of many pessimistic scenarios is that "easy safety techniques" appear to work, but then fail in subtle/abrupt ways. Having the "easy safety techniques" is a prerequisite for trying to empirically investigate this. (For example, you might want to do mechanistic interpretability on sophisticated RLHF models and try to learn what's going on.) Of course, actually recognizing this will be very hard, as we're about to discuss. But it's worth noting that this is a prerequisite for empirical attempts, and we believe those attempts are worth making, even though we aren't sure they'll succeed!
We also have a lot of work that I might describe as trying to move from optimistic scenarios towards more intermediate scenarios. This includes our process-oriented learning and scalable supervision agendas.
But what are we doing now to address pessimistic scenarios? (Again, remember that our primary goal for pessimistic scenarios is just to recognize that we're in one and generate compelling evidence that can persuade the world.)
- Our work on mechanistic interpretability is deliberately targeted at trying to fill in holes in our portfolio for pessimistic scenarios. We see this as a high-risk, high-reward bet – it may very well not succeed in time to matter, but if it does, it would be a very powerful tool for determining if we were in a pessimistic scenario and providing compelling evidence to the world. See detailed discussion in the post.
- Our Testing for Dangerous Failure Modes (eg. trying to find evidence of things like situational awareness from the outside of models) work is useful in a range of scenarios, but seems helpful in a lot of quite pessimistic ones. I think it's easy to dismiss this work on the basis that, of course, models will just deceive you. But there are a lot of very sophisticated ideas for how to get around this.
- One idea is that models may try to deceive you before they can do so effectively. This could be smaller models, or large models earlier in training. (This could even include detecting hints of deceptive behavior in the logits, before it becomes likely behavior!)
- Another more complex one is to think of treacherous turns as being kind of like a phase change, and to try to introduce control variables that expand the problem to more dimensions and allow you to safely observe treacherous turns. (For example, you might deliberately give a model weaker supervision in order to see if misalignment develops in weaker models, and then study how this changes as a function of both model capacity and supervision strength.)
- A lot of our work in this area involves studying "model organisms" of these failure modes so that we can understand them in models that are much less capable than their overseers.
- Our work on Understanding Generalization also aims to provide tools for understanding why models behave the way they do, which might help us recognize deceptively aligned models.
To be clear, we think pessimistic scenarios are, well, pessimistic and hard! These are our best preliminary attempts at agendas for addressing them, and we expect to change and expand as we learn more. Additionally, as we make progress on the more optimistic scenarios, I expect the number of projects we have targeted on pessimistic scenarios to increase.
Could you share more about how the Anthropic Policy team fits into all this? I felt that a discussion of their work was somewhat missing from this blog post.
(Zac's note: I'm posting this on behalf of Jack Clark, who is unfortunately unwell today. Everything below is his words.)
Hi there, I’m Jack and I lead our policy team. The primary reason it’s not discussed in the post is that the post was already quite long and we wanted to keep the focus on safety - I did some help editing bits of the post and couldn’t figure out a way to shoehorn in stuff about policy without it feeling inelegant / orthogonal.
You do, however, raise a good point, in that we haven’t spent much time publicly explaining what we’re up to as a team. One of my goals for 2023 is to do a long writeup here. But since you asked, here’s some information:
You can generally think of the Anthropic policy team as doing three primary things:
- Trying to proactively educate policymakers about the scaling trends of AI systems and their relation to safety. Myself and my colleague Deep Ganguli (Societal Impacts) basically co-wrote this paper https://arxiv.org/abs/2202.07785 - you can think of us as generally briefing out a lot of the narrative in here.
- Pushing a few specific things that we care about. We think evals/measures for safety of AI systems aren’t very good [Zac: i.e. should be improved!], so we’ve spent a lot of time engaging with NIST’s ‘Risk Management Framework’ for AI systems as a way to create more useful policy institutions here - while we expect labs in private sector and academia will do much of this research, NIST is one of the best institutions to take these insights and a) standardize some of them and b) circulate insights across government. We’ve also spent time on the National AI Research Resource as we see it as a path to have a larger set of people do safety-oriented analysis of increasingly large models.
- Responding to interest. An increasing amount of our work is reactive (huge uptick in interest in past few months since launch of ChatGPT). By reactive I mean that policymakers reach out to us and ask for our thoughts on things. We generally aim to give impartial, technically informed advice, including pointing out things that aren’t favorable to Anthropic to point out (like emphasizing the very significant safety concerns with large models). We do this because a) we think we’re well positioned to give policymakers good information and b) as the stakes get higher, we expect policymakers will tend to put higher weight on the advice of labs which ‘showed up’ for them before it was strategic to do so. Therefore we tend to spend a lot of time doing a lot of meetings to help out policymakers, no matter how ‘important’ they or their country/organization are - we basically ignore hierarchy and try to satisfy all requests that come in at this stage.
More broadly, we try to be transparent on the micro level, but haven’t invested yet in being transparent on the macro. What I mean by that is many of our RFIs, talks, and ideas are public, but we haven’t yet done a single writeup that gives an overview of our work. I am hoping to do this with the team this year!
Some other desiderata that may be useful:
- I testified in the Senate last year and wrote quite a long written testimony.
- I talked to the Congressional AI Caucus; slides here. Note: I demo’d Claude but it’s worth noting that whenever I demo our system I also break it to illustrate safety concerns. IIRC here I jailbroke it so it would play along with me when I asked it how to make rabies airborne - this was to illustrate how loose some of the safety aspects of contemporary LLMs are.
- A general idea I/we push with policymakers is the need to measure and monitor AI systems; Jess Whittlestone and I wrote up a plan here which you can expect us to be roughly outlining in meetings.
- A NIST RFI that talks about some of the trends in predictability and surprise and also has some recommendations.
Our wonderful colleagues on the ‘Societal Impacts’ team led this work on Red Teaming and we (Policy) helped out on the paper and some of the research. We generally think red teaming is a great idea to push to policymakers re AI systems; it’s one of those things that is ‘shovel ready’ for the systems of today but, we think, has some decent chance of helping out in future with increasingly large models.
Great post. I'm happy to see these plans coming out, following OpenAI's lead.
It seems like all the safety strategies are targeted at outer alignment and interpretability. None of the recent OpenAI, Deepmind, Anthropic, or Conjecture plans seem to target inner alignment, iirc, even though this seems to me like the biggest challenge.
Is Anthropic mostly leaving inner alignment untouched, for now?
It seems like all the safety strategies are targeted at outer alignment and interpretability.
None of the recent OpenAI, Deepmind, Anthropic, or Conjecture plans seem to target inner alignment
Less tongue-in-cheek: certainly it's unclear to what extent interpretability will be sufficient for addressing various forms of inner alignment failures, but I definitely think interpretability research should count as inner alignment research.
I mean, it's mostly semantics but I think of mechanical interpretability as "inner" but not alignment and think it's clearer that way, personally, so that we don't call everything alignment. Observing properties doesn't automatically get you good properties. I'll read your link but it's a bit too much to wade into for me atm.
Either way, it's clear how to restate my question: Is mechanical interpretability work the only inner alignment work Anthropic is doing?
Evan and others on my team are working on non-mechanistic-interpretability directions primarily motivated by inner alignment:
- Developing model organisms for deceptive inner alignment, which we may use to study the risk factors for deceptive alignment
- Conditioning predictive models as an alternative to training agents. Predictive models may pose fewer inner alignment risks, for reasons discussed here
- Studying the extent to which models exhibit likely pre-requisites to deceptive inner alignment, such as situational awareness (a very preliminary exploration is in Sec. 5 in our paper on model-written evaluations)
- Investigating the extent to which externalized reasoning (e.g. chain of thought) is a way to gain transparency into a model's process for solving a task
There's also ongoing work on other teams related to (automated) red teaming of models and understanding how models generalize, which may also turn out to be relevant/helpful for inner alignment. It's pretty unclear to me how useful any of these directions will turn out to be for inner alignment in the end, but we've chosen these directions in large part because we're very concerned about inner alignment, and we're actively looking for new directions that seem useful for mitigating inner misalignment risks.
Thank you for this post. It looks like the people at Anthropic have put a lot of thought into this which is good to see.
You mention that there are often surprising qualitative differences between larger and smaller models. How seriously is Anthropic considering a scenario where there is a sudden jump in certain dangerous capabilities (in particular deception) at some level of model intelligence? Does it seem plausible that it might not be possible to foresee this jump from experiments on even slighter weaker models?
We certainly think that abrupt changes of safety properties are very possible! See discussion of how the most pessimistic scenarios may seem optimistic until very powerful systems are created in this post, and also our paper on Predictability and Surprise.
With that said, I think we tend to expect a bit of continuity. Empirically, even the "abrupt changes" we observe with respect to model size tend to take place over order-of-magnitude changes in compute. (There are examples of things like the formation of induction heads where qualitative changes in model properties can happen quite fast over the course of training).
But we certainly wouldn't claim to know this with any confidence, and wouldn't take the possibility of extremely abrupt changes off the table!
The full post goes into considerably more detail, and I'm really excited that we're sharing more of our thinking publicly.