In the previous post, I discussed the “short-term predictor”—a circuit which, thanks to a learning algorithm, emits an output that predicts a ground-truth supervisory signal arriving a short time (e.g. a fraction of a second) later.
In this post, I propose that we can take a short-term predictor, wrap it up into a closed loop involving a bit more circuitry, and we wind up with a new module that I call a “long-term predictor”. Just like it sounds, this circuit can make longer-term predictions, e.g. “I’m likely to eat in the next 10 minutes”. This circuit winds up being a kind of hybrid between Temporal Difference (TD) learning and supervised learning.
I will argue that there is a large collection of side-by-side long-term predictors in the brain, each comprising a short-term predictor in the Learning Subsystem (more specifically, in the extended striatum—putamen, nucleus accumbens, lateral septum, part of the amygdala, etc.) that loops down to the Steering Subsystem (hypothalamus and brainstem) and then back up via a dopamine neuron. These long-term predictors make predictions about biologically-relevant inputs and outputs—for example, one long-term predictor might predict whether I’ll feel pain in my arm, another whether I’ll get goosebumps, another whether I’ll release cortisol, another whether I’ll eat, and so on. Moreover, one of these long-term predictors is essentially a value function for reinforcement learning.
All these predictors will play a major role in motivation—a story which I will finish in the next post.
Table of contents:
§5.2 starts with a toy model of a “long-term predictor” circuit, consisting of the “short-term predictor” of the previous post, plus some extra components, wrapped into a closed loop. Getting a good intuitive understanding of this model will be important going forward, and I will walk through how that model would behave under different circumstances.
§5.3 applies this model to the special case of actor-critic reinforcement learning (RL), where we’re predicting whether a plan will have a good or bad outcome. This connects RL concepts like reward and value / critic, to everyday psych concepts like pleasure and motivation, in the context of the “long-term predictor” motif. At a high level, the connection is strong, but I use some concepts and assumptions that will be unorthodox and confusing for RL experts. I try to help by walking through the common stumbling blocks.
§5.4 will relate long-term predictors to the neuroanatomy of the striatum and brainstem.
§5.5 will offer five lines of evidence that lead me to believe this story: (1) It’s a sensible way to implement a biologically-useful capability; (2) It’s introspectively plausible; (3) It’s evolutionarily plausible; (4) It’s neuroscientifically plausible; (5) It’s compatible with the psychology literature on “Pavlovian conditioning”, “revaluation”, “incentive learning”, and more.
5.2 Toy model of a “long-term predictor” circuit
A “long-term predictor” is ultimately nothing more than a short-term predictor whose output signal helps determine its own supervisory signal. Here’s a toy model of what that can look like:
Toy model of a long-term prediction circuit. I’ll spend the next couple subsections walking through how this works. Note: For this and all similar diagrams in this post, every block at every moment is running in parallel, and likewise every arrow at every moment is carrying a numerical value. So this is NOT a control-flow diagram for serial code; rather, it’s the kind of diagram you might see describing an FPGA, for example.
The blue box is the short-term predictor of the previous post. It optimizes its output signal such that it approximates what the supervisor signal will be in 0.3 seconds (as an example).
The purple box is a 2-way switch. The toggle on the switch is controlled by genetically-hardwired circuitry (gray oval), according to the following rules:
By and large, the switch is in the bottom setting (“defer-to-predictor mode”). This setting is akin to the genetically-hardwired circuitry “trusting” that the short-term predictor’s output is sensible, and in particular producing the suggested amount of digestive enzymes.
If the genetically-hardwired circuitry gets a signal that I’m eating something right now, and that I don’t have adequate digestive enzymes, it flips the switch to “override mode”. Regardless of what the short-term predictor says, it sends the signal to manufacture digestive enzymes.
If the genetically-hardwired circuitry has been asking for digestive enzyme production for an extended period, and there’s still no food being eaten, then it again flips the switch to “override mode”. Regardless of what the short-term predictor says, it sends the signal to stop manufacturing digestive enzymes.
Note: You can assume that all the signals in the diagram can vary continuously across a range of values (as opposed to being discrete on/off signals), with the exception of the signal that toggles the 2-way switch.[1] In the brain, smoothly-adjustable signals might be created by, for example, rate-coding—i.e., encoding information as the frequency with which a neuron is firing.
Next, let’s walk through the properties of this toy model.[2]
5.2.1 Toy model walkthrough: preliminaries
Here’s a little summary table for this subsection, that I’ll explain in the text below.
Override mode
Defer-to-predictor mode
Training incentive
Anticipate override signal
Keep output steady
AI intuitions
Supervised learning
TD learning
Neuro intuitions
Innate reactions
Self-fulfilling prophecies
5.2.1.1 What is the short-term predictor getting trained to do?
The short-term predictor is a learning algorithm. Given infinite time, we normally expect learning algorithms to settle into some steady-state configuration where they no longer update. We can think of this configuration as “what we are training it to do”. So, in this toy model, what are we training the short term predictor to do?
Well, first, if there’s an override with ground truth R, we are training the short-term predictor to be already outputting R, immediately before that override.
And second, while we’re in defer-to-predictor mode, we are training the short-term predictor to keep its output steady. After all, any change in its output would create a (transient) discrepancy between the short-term predictor’s output, versus its supervisor, thus causing an update.[3]
(Clarification: I’m using the phrase “keep its output steady”, but that glosses over the key detail that we are training it to “keep its output steady” in a way that privileges one temporal direction over the other: the output now is treated as what the output should have been in the immediate past. Whereas in the other direction, if the short-term predictor was making a bad prediction in the past, but now it has new information that reveals the error, we are not training it to “keep its output steady” by sticking with the old bad prediction. That’s just not what the learning algorithm updates would do.)
So putting those two observations together, in this toy model, we are training the short-term predictor to always output what the next override will be, even if that override won’t happen for a very long time. (Or if there’s randomness that makes the next override unpredictable, we are training it to predict the expectation value of the next override.)
5.2.1.2 AI intuitions: supervised learning, and Temporal Difference (TD) learning
If you’re an AI reader, think of the overrides as like sporadic “injections of ground truth”, turning the setup into a kind of supervised learning.
AI people might be wondering: In AI textbooks, TD learning is notoriously bad at long-term planning, because the correct behavior “walks backwards” one (fraction-of-a-second) timestep per attempt. And yet, humans will plan a vacation a month in advance, without having previously gone on (1 month) / (0.3 seconds) ≈ 10,000,000 vacations. Is that evidence that TD learning can’t be involved? No! The trick is, in the brain, the context data going into the short-term predictor already contains temporally-extended latent variables. For example, the mental concept “I’m getting lunch” is active in your mind 10 minutes in advance of eating, as you get on the bus to the restaurant, and is also active in your mind at the moment when you bite into the sandwich. So nothing has to propagate back one-timestep-at-a-time over the course of thousands of lunches; instead it takes as few as one iteration for the short-term predictor to learn that the “I’m getting lunch” latent variable predicts digestive enzymes.
(Note that the term “TD learning” is usually used in reinforcement learning (RL) in the context of going from a reward function to a value function. But TD learning is really a general-purpose algorithm that takes a quantity X and spits out a long-term expectation of X. We can use that algorithm for whatever we want, including for things like “digestive enzyme production” which are neither rewards nor values.[4] That said, we will in fact apply these ideas to rewards and values, as a special case, when we get to §5.3 below.)
5.2.1.3 Neuro intuitions: innate reactions, and self-fulfilling prophecies
Meanwhile, neuro readers should think of override mode as innate reactions to innate triggers, often related to homeostasis, like salivating in response to salty food in the mouth, or physiological arousal in response to pain. As discussed in Post 3, these reactions generally happen entirely within the Steering Subsystem (brainstem, hypothalamus, etc.).
And then think of defer-to-predictor mode as “self-fulfilling prophecies”. For example, as you hold the cracker in your hand, you expect that you’re about to salivate, and that expectation turns into reality. Similarly, as you go to start a painful procedure, you expect that you’re about the have physiological arousal, and that expectation turns into reality. The Steering Subsystem has no direct evidence either way, so it “defers” to the guesses coming from the Learning Subsystem.
5.2.2 Toy model walkthrough: the case of static context
Next, let’s walk through what would happen in this toy model, in the specific case that the “context” is static for some extended period of time. For example, imagine a situation where some ancient worm-like creature is digging in the sandy ocean bed for many consecutive minutes. Plausibly, its sensory environment would stay pretty much constant as long as it keeps digging, as would its thoughts and plans (insofar as this ancient worm-like creature has “thoughts and plans” in the first place). Or if you want another example of (approximately) static context—this one involving a human rather than a worm—hang on until the next subsection.
In the static-context case, let’s first consider what happens when the switch is sitting in “defer-to-predictor mode”: Since the output is looping right back to the supervisor, there is no error in the supervised learning module. The predictions are correct. The synapses aren’t changing. Even if this situation is very common, it has no bearing on how the short-term predictor eventually winds up behaving.
The times that do matter for the eventual behavior of the short-term predictor are those rare times that we go into “override mode”. They inject ground truth into the system, and produce an error signal in the short-term predictor’s learning algorithm, changing its adjustable parameters (e.g. synapse strengths).
After enough life experience (a.k.a. “training” in ML terminology), the short-term predictor should have the property that the overrides balance out. There may still be occasional overrides that increase digestive-enzyme production, and there may still be occasional overrides that decrease digestive-enzyme production, but those two types of overrides should balance out to an average of zero. After all, if they didn’t balance out, the short-term predictor’s internal learning algorithm would gradually change its parameters so that they did balance out.
And that’s just what we want! We’ll wind up with appropriate digestive enzyme production at appropriate times, in a way that properly accounts for any information available in the context data—what the animal is doing right now, what it’s planning to do in the future, what its current sensory inputs are, etc.
5.2.2.1 David-Burns-style exposure therapy—a possible real-life example of the toy model with static context?
As it happens, I recently read David Burns’s book Feeling Great (my review). David Burns has a very interesting approach to exposure therapy—an approach that happens to serve as an excellent example of how my toy model works in the static-context situation!
Here’s the short version. (Warning: If you’re thinking of doing exposure therapy on yourself at home, at least read the whole book first!) Excerpt from the book:
For example, when I was in high school, I wanted to be on the stage crew of Brigadoon, a play my school was putting on, but it required overcoming my fear of heights since the stage crew had to climb ladders and work near the ceiling to adjust the lights and curtains. My drama teacher, Mr. Krishak, helped me overcome this fear with the very type of exposure techniques I’m talking about. He led me to the theater and put a tall ladder in the middle of the stage, where there was nothing nearby to grab or hold on to. He told me all I had to do was stand on the top of the ladder until my fear disappeared. He reassured me that he’d stand on the floor next to me and wait.
I began climbing the ladder, step by step, and became more and more frightened. When I got to the top, I was terrified. My eyes were almost 18 feet from the floor, since the ladder was 12 feet tall, and I was just over 6 feet tall. I told Mr. Krishak I was in a panic and asked what I should do. Was there something I should say, do, or think about to make my anxiety go away? He shook his head and told me to just stand there until I was cured.
I continued to stand there in terror for about ten more minutes. When I told Mr. Krishak I was still in a panic, he assured me that I was doing great and that I should just stand there a few more minutes until my anxiety went away. A few minutes later, my anxiety suddenly disappeared. I couldn’t believe it!
I told him, “Hey, Mr. Krishak, I’m cured now!”
He said, “Great, you can come on down from the ladder now, and you can be on the stage crew of Brigadoon!”
I had a blast working on the stage crew. I absolutely loved climbing ladders and adjusting the lights and curtains near the ceiling, and I couldn’t even remember why or how I’d been so afraid of heights.
This story seems to be beautifully consistent with my toy model here. David started the day in a state where his short-term-predictors output “extremely strong fear reactions” when he was up high. As long as David stayed up on the ladder, those fear-reaction short-term-predictors kept on getting the same context data, and therefore they kept on firing their outputs at full strength. And David just kept feeling terrified.
Then, after 15 boring-yet-terrifying minutes on the ladder, some innate circuit in David’s brainstem issued an override—as if to say, “C’mon, nothing is changing, nothing is happening, we can’t just keep burning all these calories all day. It’s time to calm down now.” The short-term-predictors continued sending the same outputs as before, but the brainstem exercised its veto power, and forcibly reset David’s cortisol, heart-rate, etc., back to baseline. This “override” state immediately created error signals in the relevant short-term-predictors in David’s amygdala! And the error signals, in turn, led to model updates! The short-term predictors were all edited, and from then on, David was no longer afraid of heights.
Here’s the diagram for this situation; make sure you can follow all the steps.
5.2.3 Toy model walkthrough, assuming changing context
The previous subsection assumed static context lines (constant sensory environment, constant behaviors, constant thoughts and plans, etc.). What happens if the context is not static?
If the context lines are changing, then it’s no longer true that learning happens only at “overrides”. If context changes in the absence of “overrides”, it will result in changing of the output, and the new output will be treated as ground truth for what the old output should have been. Again, this seems to be just what we want: if we learned something new and relevant in the last second, then our current expectation should be more accurate than our previous expectation, and thus we have a sound basis for updating our models.
5.3 The RL value function (a.k.a. critic, a.k.a. “valence guess”) as a special case of long-term prediction
Just as we need to produce digestive enzymes based on an expectation of future meals, we likewise need to make decisions based on an expectation of future good outcomes that would result from those decisions. Thus, long-term predictors are a key part of planning and reinforcement learning in the brain.
More specifically: If you’re a human, you need to decide whether to watch TV or go to the gym. If you’re some ancient worm-like creature, you need to “decide” whether to dig or to swim. Either way, this “decision” impacts energy balance, salt balance, probability of injury, probability of mating—you name it.
The only practical way for an algorithm to output good foresighted decisions is to put everything into a common currency: a scalar signal of overall “goodness”. RL practitioners call this signal “reward”, and it loosely[5] corresponds to the everyday notion of “pleasure”. Once you have this signal, you can insert an algorithm that learns to predict it; RL practitioners call this prediction “value” or “critic”, and in everyday life it’s related to motivation. And exactly how do we get this prediction? With a long-term predictor, of course!
(…And then another algorithm needs to turn those predictions into good decisions—i.e., the “actor” part of actor-critic RL. But I’ll hold off on that until the next post.)
I’ll explain my proposal through an example:
5.3.1 Example: Walking upstairs to get a sweater
Suppose I’m downstairs and feeling cold. An idea pops into my head: “I’ll go put on my cozy sweater”. So I walk upstairs and put it on.
What just happened? Here’s a diagram:
This is the same kind of diagram as §5.2 above, but instead of predicting a digestive enzyme signal, the blue box is predicting a special signal I call valence (more on which in a minute).
Here the “override mode” is the pleasure from putting on the cozy sweater, which can be grounded in innate brainstem circuitry related to warmth, tactile feelings, and so on. At that point, when the sweater is on, the brainstem “knows” that something good has happened.
But the more interesting question is: what was happening during the thirty seconds that it took me to walk upstairs? I evidently had motivation to continue walking, or I would have stopped and turned around. But my brainstem hadn’t gotten any ground truth yet that there were good things happening. That’s where “defer-to-predictor mode” comes in! The brainstem, lacking strong evidence about what’s happening, sees a positive valence guess coming out of the striatum and says, in effect, “OK, sure, whatever, I’ll take your word for it.”
And the short-term predictor will (after some life experience) output a good guess for the next override valence, whenever that may occur. And since the cozy sweater will be a positive valence override, the valence guesses preceding it will likewise be positive. And therefore I will be motivated to get the sweater, including spending 30 seconds walking up the stairs.
(Recall from §5.2.1.2 that the short-term predictor can learn quite quickly, because of temporally-extended latent variables in the context data. In this case, the latent variables in question would be related to the explicit idea, in my head, that I’m going to put on a sweater.)
5.3.2 How exactly does this setup relate to textbook RL?
There’s a high-level similarity-in-spirit between this setup and the kind of conventional actor-critic RL that you’ll find in an AI textbook. But when we drill into details, the correspondence between the two is pretty convoluted. Indeed, if you have a strong background in the conventional RL literature, you’re probably at a disadvantage in trying to parse my proposals! Here are some of the common points of confusion:
5.3.2.1 “Valence”, and ground-truth-iness
A number of differences between my model versus textbook actor-critic RL are related to the particulars of the “valence” signal, and related RL reward.
Valence is a bit like a textbook RL reward function in the sense that, in override mode, it can be “ground-truth-y”—e.g. if I stub my toe, that seems bad (negative valence).
…But also, valence is a bit like a textbook RL value function in the sense that, in defer-to-predictor mode, it becomes “forward-looking”—in the example above, valence was positive while I was walking up the stairs, because of the expectation of a sweater.
Even when valence is “ground-truth-y” in override mode, it’s still substantially less ground-truth-y than we’re used to from textbook RL. For example, RL setups often calculate rewards based on external things like Atari scores, whereas in biology “all rewards are internal, and the internal/external distinction is not a useful one” (Singh et al. 2009). In particular:
Valence (and pleasure) are generally a function of what you’re thinking about, and also what’s happening in your body, not (directly) what’s objectively happening in the world. For example, it’s totally possible to like golf when you think about it in a certain way, but also dislike golf when you think about it in a different way, or in a different mood, etc.
Even in override mode, valence (and pleasure) can be quite non-ground-truth-y, because the “genetically-hardwired circuitry” upstream of the override signal also has other inputs, and those other inputs can include other long-term-predictors that are currently in defer-to-predictor mode. For example, laughter is pleasant (positive valence override), and laughter in turn is caused by a certain combination of signals related to physiological arousal and calm (see A Theory of Laughter), and those signals can in turn be triggered by thoughts and memories. So if I’m alone in bed, I can make myself laugh by thinking of something funny, and then I’d be having a positive-valence override despite no “ground-truth-y” external trigger.
5.3.2.2 Miscellaneous circuit elaborations
The circuit above is a toy model, so here’s a few words about what it’s leaving out, at least in the important special case of valence.
First, the short-term predictor in the circuit needs learning rate modulation. For example, suppose I’m doing math homework outside. At time t=0.0 seconds, I’m thinking “what if I take the square root of both sides of the equation?”, and then at time t=0.2 seconds, I’m thinking “aah my cell phone alarm is going off, I have to leave for my appointment!”. Thinking about the appointment might be positive or negative valence, but either way, it doesn’t provide any evidence about whether it would have been a good idea to take the square root of both sides.
Normally, my brain would do the TD learning thing, by comparing the actual valence at t=0.2 to the valence guess at t=0.0, and doing a weight-update on the short-term predictor to make them more consistent. However, in this case, it would be better to just skip that update altogether, i.e. to transiently set the learning rate to zero.
The end-result is what I sometimes call “TD learning with sporadic power outages”. These “power outages” enable the value to shift in the absence of a reward; this feature seems necessary to explain the fact that people are able to make progress on a plan (but without consummating the plan), and then do something else for a while, and then go back to the plan later. Neuroscientifically, I believe this feature is implemented by the striatal cholinergic interneuron “pause” (cf. Zhang & Cragg 2017) that can be triggered by a (generalized) orienting reflex.
Other differences between my model versus textbook actor-critic RL relate to various ways that RL practitioners tweak the circuit. Actually, some of these might be used in the brain too.
One example is time-discounting. Another is: we could introduce an asymmetry in how we treat positive (overshoot) versus negative (undershoot) errors in the short-term predictor—see my discussion of “distributional learning” in a footnote of the previous post. Probably other things too.
Also, I put an all-or-nothing two-way switch in the toy model, but realistically, it’s probably more like a weighted average with dynamically-adjustable weights.
To keep things simple, I will be ignoring all these possibilities (including time-discounting) in the discussion here.
…But there’s one more very obvious difference that’s worth diving into:
5.3.2.3 Switch (value = expected next reward) vs summation (value = expected sum of future rewards)
My model amounts to a value function that approximates the next “override” reward, whenever it should arise. However, textbook RL does something different: the value function approximates the (exponentially-discounted) sum of all future rewards. This amounts to swapping out our purple-box 2-way switch with a 2-way summation:
Here’s a TD learning circuit that would behave similarly to what you’d see in an AI textbook. Note the purple box on the right: compared to the previous figure, I replaced the 2-way switch with a 2-way summation.
(The correct answer could also be “something in between switch and summation”. Or it could even be “none of the above”.)
RL papers universally use the summation version—i.e., “value is the expected sum of future rewards”. What about biology? And which is actually better?
It doesn’t always matter! Consider AlphaGo. Like every RL paper today, AlphaGo was originally formulated in the summation paradigm. But it happens to have one and only one nonzero reward signal per game, namely +1 at the end of the game if it wins, or -1 if it loses. In that case, switch vs summation makes no difference. The only difference is one of terminology:
In the summation case, we would say “each non-terminal move in the Go game has reward=0”.
In the switch case, we would say “each non-terminal move in the Go game has a reward of (null)”.
(Do you see why?)
But in other cases, it does matter. So back to the question: should it be switch or summation?
I don’t have a strong opinion that it must be one or the other, from first principles. But I do think the RL value function (“valence guess”) calculation in brains is approximately the switch one, not the summation one. Again, I think it’s really “neither of the above” in all cases; just that it’s much closer to switch.
Why do I think that? Well here’s an example: sometimes I stub my toe and it hurts for 20 seconds; other times I stub my toe and it hurts for 40 seconds. But I don’t think of the latter as twice as bad as the former. In fact, even five minutes later, I wouldn’t remember which is which. (See the peak-end rule.) This is the kind of thing I would naturally expect from switch, but is an awkward fit for summation. It’s not strictly incompatible with summation; it just requires a more complicated, value-dependent reward function. (As a matter of fact, if we allow the reward function to depend on value, then switch and summation can imitate each other.)
You might be wondering: isn’t summation essential for long-term planning? My answer: yes it is essential … in textbook RL. But hey, so much the worse for textbook RL! I think brains can plan ahead just fine with the switch circuit. For example, suppose there’s a yummy jelly bean in front of me, but if I eat it, then a monster will bite my arm off tomorrow. I’m not gonna eat the jelly bean! Why not? Because I’m explicitly thinking ahead to tomorrow, and that makes the plan seem bad. See the discussion of temporally-extended latent variables in §5.2.1.2 above.
Anyway, in upcoming posts, I’ll be assuming switch, not summation. I don’t think it matters very much for the big picture. I definitely don’t think it’s part of the “secret sauce” of animal intelligence, or anything like that. But it does affect some of the detailed descriptions. This will be an additional source of confusion for people with a conventional RL background, on top of everything else mentioned above.
Again, “valence”—and here I mean “actual valence”, not “valence guess”—signals whether a thought is good (so I should keep thinking it, and think follow-up thoughts, and take associated actions), or bad (so I should start thinking about something else instead), all things considered.
My 5-post “Valence” series notes that, given the obvious central importance of this “valence” brain signal‚ it should illuminate many aspects of our everyday mental life. And indeed, it does! I argue in the series that valence is critical to understanding desires, values, vibes, brainstorming, motivated reasoning, the halo effect, social status, depression, mania, and more.
5.4 An array of long-term predictors involving the extended striatum & Steering Subsystem
Here’s the long-term-predictor circuit from above:
Copied from above.
I can lump together the 2-way switch with the rest of the genetically-hardwired circuitry, and then rearrange the boxes a bit, and I get the following:
Same as above, but drawn differently.
Now, obviously digestive enzymes are just one example. Let’s draw in some more examples, add some hypothesized neuroanatomy, and include other terminology. Here’s the result:
I claim that there is a bank of long-term-predictors, consisting of an array of short-term-predictors in the extended striatum, each with a closed-loop connection to a corresponding Steering Subsystem circuit. I’m calling the former (striatum) part by the name “Thought Assessors”.
Excellent! We’re halfway to my big picture of decision-making and motivation. The rest of the picture—including the “actor” part of actor-critic reinforcement learning—will come in the next post, and will fill in the hole in the top-left side of that diagram. (The term “Steering Subsystem” comes from Post #3.)
Here’s one more diagram and caption for pedagogical purposes.
Reminder: a “short-term predictor” is one component of a “long-term predictor”. Here’s where both those things fit into that diagram above. The only thing that makes it a long-term predictor is the possibility of “defer-to-predictor mode”—i.e., the Steering Subsystem might send a “ground truth in hindsight” signal that is not really “ground truth” in the normal sense, but is rather a copy of the corresponding entry on the scorecard. In other words, “defer-to-predictor mode” is like the Steering Subsystem saying to the short-term predictor: “OK sure, whatever, I’ll take your word for it”. If the Steering Subsystem regularly keeps a signal in “defer-to-predictor mode” for 10 minutes straight, then we can get predictions that anticipate the future by up to 10 minutes. Conversely, if the Steering Subsystem never uses “defer-to-predictor mode” for a certain signal, then we shouldn’t really be calling it a “long-term predictor” in the first place.
In the next two subsections, I will elaborate on the neuroanatomy which I’m hinting at in this diagram, and then I’ll talk about why you should believe me.
5.5 Five reasons I like this “array of long-term predictors” picture
5.5.1 It’s a sensible way to implement a biologically-useful capability
If you start producing digestive enzymes before eating, you’ll digest faster. If your heart starts racing before you see the lion, then your muscles will be primed and ready to go when you do see the lion. Etc.
So these kinds of predictors seem obviously useful.
Moreover, as discussed in the previous post (§4.5.2), the technique I’m proposing here (based on supervised learning) seems either superior to or complementary with other ways to meet these needs.
5.5.2 It’s introspectively plausible
For one thing, we do in fact start salivating before we eat the cracker, start feeling nervous before we see the lion, etc.
For another thing, consider the fact that all the actions I’m talking about in this post are involuntary: you cannot salivate on command, or dilate your pupils on command, etc., at least not in quite the same way that you can wiggle your thumb on command.
(More on voluntary actions in the next post, when I talk more about the cortex.)
I’m glossing over a bunch of complications here, but the involuntary nature of these things seems pleasingly consistent with the idea that they are being trained by their own dedicated supervisory signals, straight from the brainstem. They’re slaves to a different master, so to speak. We can kinda trick them into behaving in certain ways, but our control is limited and indirect (see §6.3.3 of the next post).
5.5.3 It’s evolutionary plausible
As discussed in §4.4 of the previous post, the simplest short-term predictor is extraordinarily simple, and the simplest long-term predictor is only a bit more complicated than that. And these very simple versions are already plausibly fitness-enhancing, even in very simple animals.
Moreover, as I discussed a while back (Dopamine-supervised learning in mammals & fruit flies (2021)), there is an array of little learning modules in the fruit fly, playing a seemingly-similar role to what I’m talking about here. Those modules also use dopamine as a supervisory signal, and there is some genomic evidence of a homology between those circuits and the mammalian telencephalon.
5.5.4 It’s neuroscientifically plausible
The details here are out-of-scope, and somewhat more complicated than I’m making it out to be, but for (a major subset of) Thought Assessors, I believe the correspondence between my toy models and real neuroanatomy is as follows:
The “short-term predictor” is usually[6] a set of medium spiny neurons (a.k.a. spiny projection neurons) of the extended striatum (caudate, nucleus accumbens, lateral septum, part of the amygdala, etc.)
Most of the extended striatum is dedicated to just a few Thought Assessors, namely the “valence guess” Thought Assessor (part of the brain’s “main” / “success-in-life” RL system), or the analogous Thought Assessors for any of the brain’s narrow-RL systems (those are off-topic for this series but see §1.5.6 of my Valence series (2023)).
A smaller portion of the extended striatum—specifically, parts of the amygdala, lateral septum, and nucleus accumbens shell—comprises all the dozens-to-hundreds of “visceral” Thought Assessors, related to things like cortisol, freezing, immune system activation, and so on.
The “Output” signal from the short-term predictor (a.k.a. the “guess”, or “scorecard” entry) goes to one of various Steering Subsystem areas (e.g. GPi, GPe, SNr, SNc, various cell groups in the hypothalamus).
The “Supervisor” signal going into the short-term predictor is one or more dopamine neurons coming back (directly or indirectly) from the Steering Subsystem.[7]
Thus, for example, my claim is that if you zoom into (say) the central amygdala, you’ll find dozens of little genetically-determined subregions, each projecting to a specific set of genetically-determined Steering Subsystem targets, and with a genetically-determined narrowly-targeted supervisory signal coming back (directly or indirectly) from often the same Steering Subsystem target. Thus, for example, maybe thus-and-such little group of amygdala neurons is universally associated with getting goosebumps. But each individual brain would learn within its lifetime a different set of patterns that trigger this group of goosebumps-related neurons.
Is that hypothesis consistent with the experimental evidence? My impression so far, from everything I’ve read, is “yes”, although I admit I don’t have super-solid evidence either way. More specifically:
For the valence-guess Thought Assessor, the gory details are out-of-scope, but I think my story is elegantly compatible with textbook basal ganglia circuitry, particularly the famous motif of “cortico-basal ganglia-thalamo-cortical loops”.[8]
For the “visceral” Thought Assessors: On general priors, there’s certainly no question that the genome is capable of wiring up dozens-to-hundreds of little cell groups in dozens-to-hundreds of specific and innate ways—this is ubiquitous in the Steering Subsystem. What about more specifically? I’ve found a few things. As one small-scale example, Lischinsky et al. (2023) studied two little embryonically-defined amygdala subpopulations, and finds that these two subpopulations wind up triggering in very different circumstances and connecting to very different downstream cells. As another example, at a larger scale, Heimer et al. (2008) says that the bundle of outputs of (what I’m calling) the “visceral” Thought Assessors are just a horrific mess, going every which way, as would be expected from hundreds of cell groups projecting to hundreds of different Steering Subsystem targets:
In the case of some macrosystem outputs, such as, for example, those from the accumbens core, the fibers course among these structures in tightly fasciculated fashion, giving off robust “bursts” of terminations only within or in the vicinity of particular structures. In other cases, good examples being the accumbens shell and extended amygdaloid outputs, the fibers are more loosely, if at all, fasciculated and have countless varicosities and short collaterals presumed to be sites of synaptic or parasynaptic transmission that involve not only defined structures but also points of indeterminate neural organization all along the course of the medial forebrain bundle. … As a consequence of their descent into this poorly defined organization, it is exceedingly difficult to conceive of precise, definitive mechanisms that outputs from the forebrain, including from the macrosystems, might engage to orchestrate purposeful, adaptive behavior from the extensive and sophisticated repertoire of autonomous, albeit restrictively programmed, hindbrain-spinal motor routines. But it is equivalently hard to dispel the notion that this is precisely what happens, and it seems advisable to presume that we are at present unable to perceive the relevant functional-anatomical relationships rather than to think they don’t exist.
As another piece of suggestive evidence, Lammel et al. (2014) mentions so-called “‘non-conventional’ VTA [dopamine] neurons” in “medial posterior VTA (PN and medial PBP)”. These seem to project to roughly the “visceral” Thought Assessor areas that I mentioned above, and it’s claimed that they have different firing patterns from other dopamine neurons. That seems intriguing, although I don’t have a more specific story than that right now. Relatedly, Verharen et al. (2020) discusses certain dopamine neurons which burst when aversive things happen, and four of the five regions these neurons seem to “supervise” are home to visceral Thought Assessors.[9] This makes sense because if the mouse freezes in terror, then that’s a positive error signal for the freeze-in-terror visceral Thought Assessor, as well as the raise-your-cortisol-level visceral Thought Assessor, and so on.
5.5.5 It offers a nice way to make sense of a wide variety of animal psychology phenomena, including Pavlovian conditioning, devaluation, and more
Anyway, as usual I don’t pretend to have smoking-gun proof of my hypothesis (i.e. that the brain has an array of long-term predictors involving extended striatum-Steering Subsystem loops), and there are some bits that I’m still confused about. But considering the evidence in the previous subsection, and everything else I’ve read, I wind up feeling strongly that I’m broadly on the right track. I’m happy to discuss more in the comments. Otherwise, onward to the next post, where we will finally put everything together into a big picture of how I think motivation and decision-making work in the brain!
Changelog
July 2024: Since the initial version, I’ve made a bunch of changes.
The biggest changes are related to neuroanatomy. I was just really confused about lots of things in 2022, but I hope I’m converging towards correct answers! In particular:
I’ve gone through several iterations of the diagrams in this post, particularly including which neuroanatomy corresponds to which boxes.
There used to be a much longer discussion of neuroanatomy in §5.4, but much of that was incorrect, and the rest got moved into the newly-rewritten §5.5.4.
I originally had a discussion of dopamine diversity. I mostly deleted that, apart from a couple sentences, having been convinced that at least one of the pieces of evidence I discussed (Engelhart et al. 2019) was not related to “visceral Thought Assessors”, but rather had a different explanation. (Thanks Nathaniel Daw for the correction.) I also moved the discussion of distributional RL into a footnote of the previous post.
More minor things:
I added a note that all the diagrams in this post should be understood as the kinds of diagrams you see in FPGA design—i.e. at every instant, every block is running simultaneously, and every line (wire) is carrying a numerical value. It’s not like the kinds of diagrams you see in descriptions of serial program control flow, where we follow a path through the diagram, executing one thing at a time.
I’ve also changed the wording on the labels of the various diagrams a few times since the initial version. For example, where it used to say “Will lead to reward?” and “It was in fact leading to reward”, it now says “Valence guess” and “Actual valence”, respectively. The previous wording was OK, but I think the connotations are a bit better here, and also more consistent with my later Valence series.
I added a second concrete example story (involving a cozy sweater) as §5.3.2.
I replaced a brief discussion of the “dead sea salt experiment” with a link to my more recent post dedicated to that topic, in §5.5.5.
January 2026: I added a new §5.2.1 (“preliminaries”) to hopefully explain the toy model better. (The old §5.2.1 is now §5.2.2, and the old §5.2.2 is now §5.2.3.) Plus various other minor copyedits. Thanks Eli Tyre for helpful criticism that spurred the rewrite.
May 2026: I rearranged and rewrote §5.3 for clarity (along with related edits to §5.2.1.2). Among other things, the sweater example moved from §5.3.2 to §5.3.1, while the rest of the discussion moved from §5.3.1 to §5.3.2. Thanks Rif A. Saurous for helpful criticism that spurred the rewrite.
June 2026: Added a footnote referencing Lee et al. 2024. Added a discussion of learning rate modulation to §5.3.2.2. Moved “Teaser for my ‘Valence’ series” from §6.4.1 to §5.3.3 (and shortened it).
To be clear, in reality, there probably isn’t a discrete all-or-nothing 2-way switch here. There could be a “weighted average” setting, for example. Remember, this whole discussion is just a pedagogical “toy model”; I expect that reality is more complicated in various respects.
I note that I’m just running through this algorithm in my head; I haven’t simulated it. I’m optimistic that I didn’t majorly screw up, i.e. that everything I’m saying about the algorithm is qualitatively true, or at least can be qualitatively true with appropriate parameter settings and perhaps other minor tweaks.
To be clear, this transient discrepency has nothing to do with signal propagation delays. In this toy model, I declare that signal propagation is instantaneous. Rather, it’s from the 0.3 second (or whatever) time-offset internal to the short-term predictor.
Examples in the literature where people use the terminology “TD learning” in a context unrelated to RL reward functions include: “TD networks”, the Successor Representations literature (example), or this paper, etc.
The term “pleasure” doesn’t quite have the right connotations, but it’s the least-bad word I can think of. For example, if I allow myself to be tortured to death to save the lives of my countrymen, is that “pleasure”? I would say: “Actually, kinda yes! Specifically: When you think of yourself as a brave hero, that thought comes with a great deal of pleasure. On the other hand, when you think about the feeling of pain, that thought comes with a great deal of displeasure. At the end of the day, you might or might not endure the torture to keep the secret.
Not always—certain parts of cortex layer 5 are also Thought-Assessor-ish. But meanwhile, most of the cortex is doing something different, as discussed in the next post.
As in the previous post, when I say that “dopamine carries the supervisory signal”, I’m open to the possibility that dopamine is actually a closely-related signal like the error signal, or the negative error signal, or the negative supervisory signal. It really doesn’t matter for present purposes.
Lee et al. 2024 is definitely not a perfect match to my beliefs on this topic, but it’s probably closer than anything else in the literature, and reading it was helpful for my thinking.
The fifth area where that paper found dopamine neurons bursting under aversive circumstances, namely the tail of the striatum, has a different explanation I think—see here.
Here's my understanding of the model presented in this post. Please me know if I'm missing or misunderstanding anything.
The learning subsystem of the brain includes a bunch of short term predictors. These predictors take in information from the all over the brain to predict values in the steering subsystem, in particular.
These short term predictors get feedback by sending their predictions down to the steering subsystem, and in return get supervision signals that they can use to learn their policy.
The steering subsystem will often just turn around and send the prediction back as the supervision signal. When this happens, it creates a feedback loop of the predictor predicting itself.
When the short term predictor is in this self-loop mode, it has degrees of freedom about what state it's in. Any prediction that it offers is a "correct answer".
However, the steering subsystem will send a ground truth signal at some point. So the best strategy for a short term predictor in a self-loop mode is to jump to predicting the next override as soon as it can guess what the next override will be.
For instance, as soon as that short term predictor notices a change in context like "you had the thought to go put on a sweater", it immediately starts predicting the positive reward of "feel warm and cozy" from having put on a sweater.
It could self-stably give any prediction. But immediately predicting the reward of putting on a sweater is the best policy. It won't get penalized while it's in the self-loop mode (since whatever the short term outputs is marked correct) but when the ground truth injection does arrive the short term predictor will already be correctly predicting that ground truth injection.
That is, jumping to predicting the next ground truth injection as soon as the predictor can guess what it will be does no worse than any other possible prediction during the self-loop mode, and it does better than other possible predictions during the steering override mode.
This feedback makes the short-term predictors into long term predictors, because they're effectively learning to predict the next "steering override", based on context. This allows the short term predictors to learn predictive patterns that occur across many different timescales.
The timescale that they learn to predict over depends the on frequency with which the steering subsystem provides ground truth injections: if it's around once a minute, the predictor learns to predict a minute into the future, if it's around once an hour, the predictor learns to predict an hour into into the future and so on. (And if the frequency of ground truth injections are variable, but predictable from brain context, the predictors will learn a policy that predicts over different time horizons depending on that context?)
Those long term predictors can be used as control signals. These long term predictors can steer behavior based on outcomes that will only occur minutes or hours into the future.
In the sweater example, the brain can use the expectation of feeling warm and cozy, or not, as an indicator that the current behavior is on track for producing the warm and cozy reward.
This setup constructs a long term reward-seeker out of an immediate reward-seeker and a pile of predictors.
The thing that was most confusing for me was step 5.
I first needed to clarify for myself that because the STP's output was feeding back in as input, it could adopt any value in that stage.
Then I needed to realize that, given that it could take any value, the optimal predictive strategy is to adopt the the value of the next predicted override "just to be safe".
(I don't know if that helps you at all.)
...
Actually, this begs the question a bit.
Suppose that a STP is in the self-looping mode at t_0. The next override will arrive at t_10. Also, suppose that the context clues at t_8, are very strongly informative of the timing of the next ground truth injection: it will occur sometime within the next three timesteps, 10_9 to 10_11.
There's definitely pressure to start predicting the override at t_8, but is there a pressure pushing the STP to start predicting the override all the way back at t_0? Why not have random outputs until t_8, and then switch to predicting the override?
Is it just that there are rarely definitive contextual evidence that allows you to time the ground truth injection, even with a wide interval?
If the STP can precisely bound the timing of the overrides does that break this whole system?
FYI, I just revised the post, mainly by adding a new §5.2.1. Hopefully that will help you and/or future readers understand what I’m getting at more easily. Thanks for the feedback (and of course I’m open to further suggestions).
In defer-to-predictor mode, there’s an error for any change of the short-term predictor output. (“If context changes in the absence of “overrides”, it will result in changing of the output, and the new output will be treated as ground truth for what the old output should have been.”)
[Because the after-the-change output is briefly ground truth for the before-the-change output. I.e., in defer-to-predictor mode, at time t, the output is STP(context(t)), and this output gets judged / updated according to how well it matches a ground truth of STP(context(t+0.3 seconds)).]
So given infinite repetitions, it will keep changing the parameters until it’s always predicting the next override, no matter how far away. (In this toy model.)
But the more interesting question is: what was happening during the thirty seconds that it took me to walk upstairs?I evidently had motivation to continue walking, or I would have stopped and turned around. But my brainstem hadn’t gotten any ground truth yet that there were good things happening. That’s where “defer-to-predictor mode” comes in! The brainstem, lacking strong evidence about what’s happening, sees a positive valence guess coming out of the striatum and says, in effect, “OK, sure, whatever, I’ll take your word for it.”
It seems like there's some implication here that motivation and positive valence are the same thing?
Is the claim that evolutionarily early versions of behavioral circuits had approximately the form...
If positive reward:
continue current behavior
else:
try something else
...but that adding in long-term predictors instead allows for the following algorithm?
Perhaps I'm just being dense, but I'm confused why this toy model of a long-term predictor is long-term instead of short term. I'm trying to think through it aloud in this comment.
A “long-term predictor” is ultimately nothing more than a short-term predictor whose output signal helps determine its own supervisory signal. Here’s a toy model of what that can look like:
At first, I thought that the idea was that the latency of the supervisory/error signal was longer than average, and that that latency made the short term predictor function as a long-term predictor, without being any different functionally. But then why is it labeled "short-term predictor"?
It seems like the short-term predictor should learn to predict (based on context cues) the behavior triggered by the hardwired circuitry. But it should predict that behavior only 0.3 seconds early?
...
Oh! Is the key point that there's a kind of resonance, where this system maintains the behavior of the genetically hardwired components? When the switch switches back to defer-to-predictor mode, the short term predictor is still predicting the override hard-wired behavior, which is now trivially "correct", because whatever the predictor outputs is correct. (It was also correct a moment before, when the switch was in override mode, but not trivially correct.)
This still doesn't answer my confusion. It seems like the whole circuit is going to maintain the state from the last "ground truth infusion" and learn to predict the timings and magnitudes of the "ground truth infusions". But it still shouldn't predict them more than 0.3 seconds in advance?
Is the idea that the lookahead propagates earlier and earlier with each cycle? You start with a 0.3 second prediction. But that means that supervisory signal (when in the "defer-to-predictor mode") is 0.3 seconds earlier, which means that the predictor learns to predict the change in output 0.6 seconds ahead of when the override "would have happened", and then 0.9 seconds ahead , and then 1.2 seconds ahead, and so on, until it backs all the way up to when the "prior" ground truth infusion sent a different signal?
Like, the thing that this circuit is doing is simulating time travel, so that it can activate (on average) the next behavior that the genetically hardwired circuitry will output, as soon as "override mode" is turned off?
It seems like the short-term predictor should learn to predict (based on context cues) the behavior triggered by the hardwired circuitry. But it should predict that behavior only 0.3 seconds early?
You might be missing the “static context” part (§5.2.1). The short-term predictor learns a function F : context → output. Suppose (for simplicity) the context is the exact same vector c₁ for 5 minutes, and then out of nowhere at time T, an override appears and says “Ground Truth Alert: F(c₁) was too low!” Then the learning algorithm will make F(c₁) higher for next time.
But the trick is, the output is determined by F(c₁) at T–(0.3 seconds), AND the output is determined by the exact same function F(c₁) at T–(4 minutes). So if the situation recurs a week later, F(c₁) will be higher not just 0.3 seconds before the override, but also 4 minutes before it. You can’t update one without the other, because it’s the same calculation.
Oh! Is the key point that there's a kind of resonance, where this system maintains the behavior of the genetically hardwired components?
I don’t think so. If I understand you correctly, the thing you’re describing here would be backwards-looking (“predicting” something that already happened), but what we want is forward-looking (how much digestive enzymes be needed in 5 minutes?).
Is the idea that the lookahead propagates earlier and earlier with each cycle? You start with a 0.3 second prediction. But that means that supervisory signal (when in the "defer-to-predictor mode") is 0.3 seconds earlier, which means that the predictor learns to predict the change in output 0.6 seconds ahead…
The thing you’re pointing to is a well-known thing that happens in TD learning in the AI literature (and is a limitation to efficient learning). I think it can happen in humans and animals—I recall reading a paper that (supposedly) observed dopamine marching backwards in time with each repetition, which of course got the authors very excited—but if it happens at all, I think it’s rare, and that humans and animals generally learn things with many fewer repetitions than it would take for the signal to walk backwards step by step.
Instead, I claim that the “static context” picture above is capturing an important dynamic even in the real world where the context is not literally static. Certain aspects of the context are static, and that’s good enough. See the sweater example in §5.3.2 for how (I claim) this works in detail.
Let's call the short term predictor (in the long term predictor circuit) P, so if P tries to predict [what P predicts in 0.3s], then the correct prediction would be to immediately predict the output at whatever point in the future the process terminates (the next ground truth injection?). In particular, P would always predict the same until the ground truth comes in. But if I understand correctly, this is not what's going on.
So second try: is P really still only trying to predict 0.3s into the future, making it less of a "long term predictor" and more of an "ongoing process predictor"? And then you get, e.g., the behavior of predicting a little less enzyme production with every step?
Or third try, is P just trying to minimize something like the sum of squared differences between adjacent predictions, and is thus trying to minimize the number of ground-truth injections, and we get the above an emergent effect?
In the static-context case, let’s first consider what happens when the switch is sitting in “defer-to-predictor mode”: Since the output is looping right back to the supervisor, there is no error in the supervised learning module. The predictions are correct. The synapses aren’t changing. Even if this situation is very common, it has no bearing on how the short-term predictor eventually winds up behaving.
One solution to a -300ms delay connected to its own input is a constant output. However, this is part of an infinite class of solutions. Any function f(tms%300) is a solution to this.
(Admittedly, with any error metric Lx;x>1 the optimum solution is a constant output.)
Output stability here depends on the error gain through the loop. (Control theory is not my forte, but I believe to analyze this rigorously control theory is what you'd want to look into.)
If the error gain is sub-unity, the system is stable and will converge to a constant output. The error gain being unity is the critical value where the system is on the edge of stability. If the error gain is super-unity, the system is unstable and will go into oscillations.
Or, to bring this back to what this means for a predictor:
Sub-unity error gain means 'if the current input is X and the predictor predicts the input will be Y in 300ms, the predictor outputs (X+(Y−X)∗C);C<1.' Unity error gain means 'if the current input is X and the predictor predicts the input will be Y in 300ms, the predictor outputs (X+(Y−X)∗C);C=1.' Super-unity error gain means 'if the current input is X and the predictor predicts the input will be Y in 300ms, the predictor outputs (X+(Y−X)∗C);C>1.'
Super-unity error gain is 'obviously' suboptimal behavior for a human brain, so we'd probably end up with the error amplification tuned to under the critical value. Ditto, a predictor that systematically underestimated system changes is also "obviously" suboptimal. A 'perfect' predictor corresponds to unity error gain.
So all told you'd expect the predictors to be tuned to a gain that's as close to possible to unity without going over.
...hm. Actually, predictors going haywire with a ~300ms (~3Hz) period sounds a lot like a seizure. Which would nicely explain why humans do occasionally get seizures. (Or rather, why they aren't evolved out.) For ideal prediction you want an error gain as close as possible to unity... but too close to unity and variations in effective error gain mean that you're suddenly overunity and get rampant 300ms oscillations.
The predictor is a parametrized function output = f(context, parameters) (where "parameters" are also called "weights"). If (by assumption) context is static, then you're running the function on the same inputs over and over, so you have to keep getting the same answer. Unless there's an error changing the parameters / weights. But the learning rate on those parameters can be (and presumably would be) relatively low. For example, the time constant (for the exponential decay of a discrepancy between output and supervisor when in "override mode") could be many seconds. In that case I don't think you can get self-sustaining oscillations in "defer to predictor" mode.
Then maybe you'll say "What if it's static context except that there's a time input to the context as well? But I still don't see how you would learn oscillations that aren't in the exogenous data.
There could also be a low-pass filter on the supervisor side. Hmm, actually, maybe that amounts to the same thing as the slow parameter updates I mentioned above.
I think I disagree that "perfect predictors" are what's wanted here. The input data is a mix of regular patterns and noise / one-off idiosyncratic things. You want to learn the patterns but not learn the noise. So it's good to not immediately and completely adapt to errors in the model. (Also, there's always learning-during-memory-replay for genuinely important things that only happen only once and quickly.)
I disagree; let me try to work through where we diverge.
A 300ms predictor outputting a sine wave with period 300ms into its own supervisor input has zero error, and hence will continue to do so regardless of the learning rate.
Do you at least agree that in this scheme a predictor outputting a sine wave with period 300ms has zero error while in defer-to-predictor mode?
The predictor is a parametrized function output = f(context, parameters) (where "parameters" are also called "weights"). If (by assumption) context is static, then you're running the function on the same inputs over and over, so you have to keep getting the same answer. Unless there's an error changing the parameters / weights.
This is true for a standard function; this is not true once you include time. A neuron absolutely can spike every X milliseconds with a static input. And it is absolutely possible to construct a sine-wave oscillator via a function with a nonzero time delay connected to its own input.
But the learning rate on those parameters can be (and presumably would be) relatively low.
Unfortunately, as long as the % of time spent in override mode is low you need a high learning rate or else the predictor will learn incredibly slowly.
If the supervisor spends a second a week in override mode[1], then the predictor is actively learning ~0.002% of the time.
There could also be a low-pass filter on the supervisor side.
Unfortunately, as long as each override event is relatively short a low-pass filter selectively removes all of your learning signal!
*****
For example, the time constant (for the exponential decay of a discrepancy between output and supervisor when in "override mode") could be many seconds.
You keep bouncing between a sufficiently-powerful-predictor and a simple exponential-weighted-average. Please pick one, to keep your arguments coherent. This statement of yours is only true for the latter, not the former. A powerful predictor can suddenly modeswitch in the presence of an error signal.
(For a simple example, consider a 300ms predictor trying to predict a system where the signal normally stays at 0, but if it ever goes non-zero, even by a very small amount, it will go to 1 100ms later and stay at 1 for 10s before returning to 0. As long as the signal stays at 0, the predictor will predict it stays a zero[2]. The moment the error is nonzero, the predictor will immediately switch to predicting 1.)
Do you at least agree that in this scheme a predictor outputting a sine wave with period 300ms has zero error while in defer-to-predictor mode?
Yes
A neuron absolutely can spike every X milliseconds with a static input.
Hmm, I think we're mixing up two levels of abstraction here. At the implementation level, there are no real-valued signals, just spikes. But at the algorithm level, it's possible that the neuron operations are equivalent to some algorithm that is most simply described in a way that does not involve any spikes, and does involve lots of real-valued signals. For example, one can vaguely imagine setups where a single spike of an upstream neuron isn't sufficient to generate a spike on the downstream neuron, and you only get effects from a neuron sending a train of spikes whose effects are cumulative. In that case, the circuit would be basically incapable of "fast" dynamics (i.e. it would have implicit low-pass filters everywhere), and the algorithm is really best thought of as "doing operations" on average spike frequencies rather than on individual spikes.
You keep bouncing between a sufficiently-powerful-predictor and a simple exponential-weighted-average. Please pick one, to keep your arguments coherent.
Oh sorry if I was unclear. I was never talking about exponential weighted average. Let's say our trained model is f(context,θ) (where θ is the parameters a.k.a. weights). Then with static context, I was figuring we'd have a differential equation vaguely like:
∂→θ∂t∝−∇θ(f(context,→θ)−supervisor)2
I was figuring that (in the absence of oscillations) the solution to this differential equation might look like θ(t) asymptotically approaching a limit wherein the error is zero, and I was figuring that this asymptotic approach mightlook like an exponential with a timescale of a few seconds.
I'm not sure if it would be literally an exponential. But probably some kind of asymptotic approach to a steady-state. And I was saying (in a confusing way) that I was imagining that this asymptotic approach would take a few seconds to get most of the way to its limit.
Unfortunately, as long as the % of time spent in override mode is low you need a high learning rate or else the predictor will learn incredibly slowly.
If we go to the Section 5.2.1.1 example of David on the ladder, the learning is happening while he has calmed down, but is still standing at the top of the ladder. I figure he probably stayed up for at least 5 or 10 seconds after calming down but before climbing down.
For example, we can imagine an alternate scenario where David was magically teleported off the ladder within a fraction of a second after the moment that he finally started feeling calm. In that scenario, I would be a lot less confident that the exposure therapy would actually stick.
By the same token, when you're feeling scared in some situation, you're probably going to continue feeling scared in that same situation for at least 5 or 10 seconds.
(And if not, there's always memory replay! The hippocampus can recall both the scared feeling and the associated context 10 more times over the next day and/or while you sleep. And that amounts to the same thing, I think.)
Sorry in advance if I'm misunderstanding your comment. I really appreciate you taking the time to think it through for yourself :)
Alright, so we at least agree with each other on this. Let me try to dig into this a little further...
Consider the following (very contrived) example, for a 300ms predictor trying to minimize L2[1] norm:
Context is static throughput the below.
t=0, overrider circuit forces output=1. t=150ms, overrider circuit switches back to loopback mode. t=450ms, overrider circuit forces output=0. t=600ms, overrider circuit switches back to loopback mode.
t=900ms, overrider circuit forces output=1. etc.
Do you agree that the best a slow-learning predictor that's a pure function f(context,→θ) can do is to output a static value 0.5, for an overall error rate of, what 0.08¯3? (The exact value doesn't matter.)
Do you agree that a "temporal-aware"[2] predictor that outputted a 300ms square wave as follows:
I was figuring that (in the absence of oscillations) the solution to this differential equation might look like θ(t) asymptotically approaching a limit wherein the error is zero, and I was figuring that this asymptotic approach mightlook like an exponential with a timescale of a few seconds.
I can see why you'd say this. It's even true if you're just looking at e.g. a well-tuned PID controller. But even for a PID controller there are regimes where this behavior breaks down and you get oscillation[4]... and worse, the regimes where this breaks down are regimes that you're otherwise actively tuning said controller for!
For example, one can vaguely imagine setups where a single spike of an upstream neuron isn't sufficient to generate a spike on the downstream neuron, and you only get effects from a neuron sending a train of spikes whose effects are cumulative. In that case, the circuit would be basically incapable of "fast" dynamics (i.e. it would have implicit low-pass filters everywhere), and the algorithm is really best thought of as "doing operations" on average spike frequencies rather than on individual spikes.
I think here is the major place we disagree. As you say, this model of these circuits is basically incapable of fast dynamics, and you keep leaning towards setups that forbid fast dynamics in general. But for something like a startle signal, you absolutely want it to be able to handle a step change in the context as a step change in the output[5].
I don't know of a general-purpose method of predicting fast dynamics[6] that doesn't have mode-switching regions where seemingly-small learning rates can suddenly change the output.
I am making up this term on the spot. I haven't formalized it; I suspect one way to formalize it would be to include time % 300ms as an input like the rest of the context.
Just to make sure we're on the same page, I made up the “300ms” number, it could be something else.
Also to make sure we're on the same page, I claim that from a design perspective, fast oscillation instabilities are bad, and from an introspective perspective, fast oscillation instabilities don't happen. (I don't have goosebumps, then 150ms later I don't have goosebumps, then 150ms later I do have goosebumps, etc.)
...would have zero error rate?
Sure. But to make sure we're on the same page, the predictor is trying to minimize L2 norm (or whatever), but that's just one component of a system, and successfully minimizing the L2 norm might or might not correspond to the larger system performing well at its task. So “zero error rate” doesn't necessarily mean “good design”.
even for a PID controller there are regimes where this behavior breaks down and you get oscillation
Sorry, I'm confused. There's an I and a D? I only see a P.
As you say, this model of these circuits is basically incapable of fast dynamics, and you keep leaning towards setups that forbid fast dynamics in general. But for something like a startle signal, you absolutely want it to be able to handle a step change in the context as a step change in the output.
It seems to me that you can start a startle reaction quickly (small fraction of a second), but you can't stop a startle quickly. Hmm, maybe the fastest thing the amygdala does is to blink (mostly <300ms) , but if you're getting 3 blink-inducing stimuli a second, your brainstem is not going to keep blinking 3 times a second, instead it will just pinch the eyes shut and turn away, or something. (Source: life experience.) (Also, I can always pull out the “Did I say 300ms prediction? I meant 100ms” card…)
If the supervisor is really tracking the physiological response (sympathetic nervous system response, blink reaction, whatever), and the physiological response can't oscillate quickly (even if its rise-time by itself is fast), then likewise the supervisor can't oscillate quickly, right? Think of it like: once I start a startle-reaction, then it flips into override mode for a second, because I'm still startle-reacting until the reaction finishes playing out.
forbid fast dynamics in general
Hmm, I think I want to forbid fast updates of the adjustable parameters / weights (synapse strength or whatever), and I also want to stay very very far away from any situation where there might be fast oscillations that originate in instability rather than already being present in exogenous data. I'm open to a fast dynamic where “context suddenly changes, and then immediately afterwards the output suddenly changes”. If I said something to the contrary earlier, then I have changed my mind! :-)
And I continue to believe that these things are all compatible: you can get the “context suddenly changes → output suddenly changes” behavior, without going right to the edge of unstable oscillations, and also without fast (sub-second) parameter / weight / synapse-strength changes.
Just to make sure we're on the same page, I made up the “300ms” number, it could be something else.
Sure; the further you get away from ~300ms the less the number makes sense for e.g. predicting neuron latency, as described earlier.
Also to make sure we're on the same page, I claim that from a design perspective, fast oscillation instabilities are bad, and from an introspective perspective, fast oscillation instabilities don't happen. (I don't have goosebumps, then 150ms later I don't have goosebumps, then 150ms later I do have goosebumps, etc.)
I absolutely agree that most of the time oscillations don't happen. That being said, oscillations absolutely do happen in at least one case - epilepsy. I remain puzzled that evolution "allows" epilepsy to happen, and epilepsy being a breakdown that does allow ~300ms oscillations to happen, akin to feedback in audio amplifiers, is a better explanation for this than I've heard elsewhere.
Sorry, I'm confused. There's an I and a D? I only see a P.
A generic overdamped PID controller will react to a step-change in its input via (vaguely)-exponential decay towards the new value[1].
Even for a non-overdamped PID controller the magnitude of the tail decreases exponentially with time. (So long as said PID controller is stable at least.)
You are correct that all that is necessary for a PID controller to react in this fashion is a nonzero P term.
It seems to me that you can start a startle reaction quickly (small fraction of a second), but you can't stop a startle quickly.
Absolutely; a step change followed by a decay still has high-frequency components. (This is the same thing people forget when they route 'slow' clocks with fast drivers and then wonder why they are getting crosstalk on other signals and high-frequency interference in general.)
Your slow-responding predictor is going to have a terrible effective reaction time, is what I'm trying to say here, because you're filtering out the high-frequency components of the prediction error, and so the rising edge of your prediction error gets filtered from a step change to something closer to a sigmoid that takes quite a while to get to full amplitude.... which in turn means that what the predictor learns is not a step-change followed by a decay. It learns the output of a low-pass filter on said step-change followed by a decay, a.k.a. a slow rise and decay.
I also want to stay very very far away from any situation where there might be fast oscillations that originate in instability rather than already being present in exogenous data.
Right. Which brings me back to my puzzle: why does epilepsy continue to exist?
(Do you at least agree that, were there some mechanism where there was enough feedback/crosstalk such that you did get oscillations, it might look something like epilepsy?)
And I continue to believe that these things are all compatible
Can you please give an example of a general-purpose function estimator, that when plugged into this pseudo-TD system, both:
Sure; the further you get away from ~300ms the less the number makes sense for e.g. predicting neuron latency, as described earlier.
I must have missed that part; can you point more specifically to what you're referring to?
why does epilepsy continue to exist?
I think practically anywhere in the brain, if A connects to B, then it's a safe bet that B connects to A. (Certainly for regions, and maybe even for individual neurons.) Therefore we have the setup for epileptic seizures, if excitation and inhibition are not properly balanced.
Or more generically, if X% of neurons in the brain are active at time t, then we want around X% of neurons in the brain to be active at time t+1. That means that we want each upstream neuron firing event to (on average) cause exactly one net downstream neuron to fire. But individual neurons have their own inputs and outputs; by default, there seems to be a natural failure mode where the upstream neurons excite not-exactly-one downstream neuron, and we get exponential growth (or decay).
My impression is that there are lots of mechanisms to balance excitation and inhibition—probably different mechanisms in different parts of the brain—and any of those mechanisms can fail. I'm not an epilepsy expert by any means (!!) , but at a glance it does seem like epilepsy has a lot of root causes and can originate in lots of different brain areas, including areas that I don't think are doing this kind of prediction, e.g. temporal lobe and dorsolateral prefrontal cortex and hippocampus.
the rising edge of your prediction error gets filtered from a step change to something closer to a sigmoid that takes quite a while to get to full amplitude.... which in turn means that what the predictor learns is not a step-change followed by a decay. It learns the output of a low-pass filter on said step-change followed by a decay, a.k.a. a slow rise and decay.
I still think you're incorrectly mixing up the time-course of learning (changes to parameters / weights / synapse strengths) with the time-course of an output following a sudden change in input. I think they're unrelated.
To clarify our intuitions here, I propose to go to the slow-learning limit.
However fast you've been imagining the parameters / weights / synapse strength changing in any given circumstance, multiply that learning rate by 0.001. And simultaneously imagine that the person experiences everything in their life with 1000× more repetitions. For example, instead of getting whacked by a golf ball once, they get whacked by a golf ball 1000× (on 1000 different days).
(Assume that the algorithm is exactly the same in every other respect.)
I claim that, after this transformation (much lower learning rate, but proportionally more repetitions), the learning algorithm will build the exact same trained model, and the person will flinch the same way under the same circumstances.
(OK, I can imagine it being not literally exactly the same, thanks to the details of the loss landscape and gradient descent etc., but similar.)
Your perspective, if I understand it, would be that this transformation would make the person flinch more slowly—so slowly that they would get hit by the ball before even starting to flinch.
If so, I don't think that's right.
Every time the person gets whacked, there's a little interval of time, let's say 50ms, wherein the context shows a golf ball flying towards the person's face, and where the supervisor will shortly declare that the person should have been flinching. That little 50ms interval of time will contribute to updating the synapse strengths. In the slow-learning limit, the update will be proportionally smaller, but OTOH we'll get that many more repetitions in which the same update will happen. It should cancel out, and it will eventually converge to a good prediction, F(ball-flying-towards-my-face) = I-should-flinch.
And after training, even if we lower the learning rate all the way down to zero, we can still get fast flinching at appropriate times. It would only be a problem if the person changes hobbies from golf to swimming—they wouldn't learn the new set of flinch cues.
Sorry if I'm misunderstanding where you're coming from.
Can you please give an example of a general-purpose function estimator, that when plugged into this pseudo-TD system, both:
I must have missed that part; can you point more specifically to what you're referring to?
It feels wrong to refer you back to your own writing, but much of part 4 was dedicated to talking about these short-term predictors being used to combat neural latency and to do... well, short-term predictions. A flinch detector that goes off 100ms in advance is far less useful than a flinch detector that goes off 300ms in advance, but at the same time a short-term predictor that predicts too far in advance leads to feedback when used as a latency counter (as I asked about/noted in the previous post).
(It's entirely possible that different predictors have different prediction timescales... but then you're just replaced the problem with a meta-problem. Namely: how do predictors choose the timescale?)
To clarify our intuitions here, I propose to go to the slow-learning limit.
However fast you've been imagining the parameters / weights / synapse strength changing in any given circumstance, multiply that learning rate by 0.001. And simultaneously imagine that the person experiences everything in their life with 1000× more repetitions. For example, instead of getting whacked by a golf ball once, they get whacked by a golf ball 1000× (on 1000 different days).
1x the training data with 1x the training rate is not equivalent to 1000x the training data with 1/1000th of the training rate. Nowhere near. The former is a much harder problem, generally speaking.
(And in a system as complex and chaotic as a human there is no such thing as repeating the same datapoint multiple times... related data points yes. Not the same data point.)
(That being said, 1x the training data with 1x the training rate is still harder than 1x the training data with 1/1000th the training rate, repeated 1000x.)
Your perspective, if I understand it, would be that this transformation would make the person flinch more slowly—so slowly that they would get hit by the ball before even starting to flinch.
You appear to be conflating two things here. It's worth calling them out as separate.
Putting a low-pass filter on the learning feedback signal absolutely does cause something to learn a low-passed version of the output. Your statement "In that case, the circuit would be basically incapable of "fast" dynamics (i.e. it would have implicit low-pass filters everywhere)," doesn't really work, precisely because it leads to absurd conclusions. This is what I was calling out.
A low learning rate is something different. (That has other problems...)
If you take any solution to 1, and multiply the learning rate by 0.000001, then it would satisfy 2 as well, right?
My apologies, and you are correct as stated; I should have added something on few-shot learning. Something like a flinch detector likely does not fire 1,000,000x in a human lifetime[1], which means that your slow-learning solution hasn't learnt anything significant by the time the human dies, and isn't really a solution.
I am aware that 1m is likely you just hitting '0' a bunch of times'; humans are great few-shot (and even one-shot) learners. You can't just drop the training rate or else your examples like 'just stand on the ladder for a few minutes and your predictor will make a major update' don't work.
Oh, hmm. In my head, the short-term predictors in the cerebellum are for latency-reduction and discussed in the last post, and meanwhile the short-term predictors in the telencephalon (amygdala & mPFC) are for flinching and discussed here. I think the cerebellum short-term predictors and the telencephalon short-term predictors are built differently for different purposes, and once we zoom in beyond the idea of “short-term prediction” and start talking about parameter settings etc., I really don't lump them together in my mind, they're apples and oranges. In the conversation thus far, I thought you were talking about the telencephalon (amygdala & mPFC) ones. If we're talking about instability from the cerebellum instead, we can continue the Post #4 thread.
~
I think I said some things about low-pass filters up-thread and then retracted it later on, and maybe you missed that. At least for some of the amygdala things like flinching, I agree with you that low-pass filters seem unlikely to be part of the circuit (well, depending on where the frequency cutoff is, I suppose). Sorry, my bad.
~
A common trope is that the hippocampus does one-shot learning in a way that vaguely resembles a lookup table with auto-associative recall, whereas other parts of the cortex learn more generalizable patterns more slowly, including via memory recall (i.e., gradual transfer of information from hippocampus to cortex). I'm not immediately sure whether the amygdala does one-shot learning. I do recall a claim that part of PFC can do one-shot learning, but I forget which part; it might have been a different part than we're talking about. (And I'm not sure if the claim is true anyway.) Also, as I said before, with continuous-time systems, “one shot learning” is hard to pin down; if David Burns spends 3 seconds on the ladder feeling relaxed, before climbing down, that's kinda one-shot in an intuitive sense, but it still allows the timescale of synapse changes to be much slower than the timescale of the circuit. Another consideration is that (I think) a synapse can get flagged quickly as “To do: make this synapse stronger / weaker / active / inactive / whatever”, and then it takes 20 minutes or whatever for the new proteins to actually be synthesized etc. so that the change really happens. So that's “one-shot learning” in a sense, but doesn't necessarily have the same short-term instabilities, I'd think.
we are training the short-term predictor to always output what the next override will be
Hm, I'm going to nitpick this as a summary, partly as a way of helping me think through this myself.
Do we get an override if we're currently predicting right? I think the answer is "it doesn't matter".
That is, there'll be some neuronal fact of the matter. But if we treat this set of neurons as a black box, it'll implement the same algorithm either way - the short-term predictor can't tell whether the signal it's getting matches its output because the switch is in defer mode, or because the switch is in override mode and it's overridden to the same value as its current output.
I think this summary relies on us pretending/assuming/modeling "yes, we get an override even if we're currently predicting the right thing". Otherwise, the next override will always be the opposite of what we predict.
But I'm not sure we can always model it that way. "What's the next override" might depend on "what am I currently predicting" in a way that confuses things.
Taking the digestive enzyme example, when do we get an override? According to above:
If we're currently eating something: override to "make enzymes".
If we've been making enzymes for a while, and not eating: override to "don't make enzymes".[1]
We can model (1) as getting an override even if we were predicting enzymes. But I don't see how to model (2) as getting an override even if we were predicting no-enzymes. The "we've been making enzymes for a while" is an important part of it.
(What's the fundamental asymmetry here? I think "we're trying to start producing enzymes before we need them, harder than we're trying to stop producing enzymes before we stop needing them".)
So if we're not currently predicting enzymes, the next override is always going to be "start making enzymes". But we don't always predict enzymes, because if we did, we'd (typically) get a "no-enzymes" override.
So maybe a more-accurate-but-more-confusing summary would be: we're training the short-term predictor to output what the next override would be, if we were currently predicting "wrong"?
Possibly implemented as something like: "normally make a certain amount of digestive enzymes, which are normally removed from the stomach at rate proportional to their concentration, which gives a particular steady state. If we start digesting food, they're removed faster, the level falls below a trip point, and we override to "make [more] enzymes". The level goes up again to a (possibly different) steady state. When we stop digesting food, the level goes above a trip point, we override to "stop making [more] enzymes", and the lever goes back down to the first steady state." The override would be on whenever we're above/below the given thresholds. ↩︎
I think this summary relies on us pretending/assuming/modeling "yes, we get an override even if we're currently predicting the right thing". Otherwise, the next override will always be the opposite of what we predict.
Is that assuming that the signals are binary rather than continuous? Let’s say the override ground truth says “produce digestive enzymes at rate R”, where R can vary between 0 and 10. Or to simplify, let’s say the overrides are always saying R=0 or R=10, whereas the predictions can be any real number R. Then it’s never going to predict R=10.0000 if there’s any uncertainty whatsoever in the next override, but it might predict 9.9 if the next override is 100× more likely to be R=10 than R=0. (“…if there’s randomness that makes the next override unpredictable, we are training it to predict the expectation value of the next override.”)
So if you’re expecting to eat with very high confidence, you’re nevertheless going to produce not quite enough digestive enzymes, and the last bit of digestive enzymes will come in when food actually enters your mouth.
(Similar example: my heart will race in anticipation of seeing a scary thing, and if I’m very confident that the scary thing will show up then my heart will race quite a lot, but even so my heart will race still more when the scary thing is actually there in front of me.)
I’m happy to edit the text to make this clearer (sorry), but first I want to check that I’m actually understanding and responding to the point you’re bringing up.
Hm, I think that still ends up with the same basic dynamic of "if the next override depends on the current prediction, you're not actually predicting the next override".
Like, suppose it's been an hour since I ate and I'm not thinking about food. There's no override, and the STP is outputting some small number, say R=1. What's the next override going to be?
I think the basic story is something like,
At some point in future, I start to think about food
the STP starts to output a high number like R=9
I start eating
a "start making enzymes" R=10 override comes in
I stop eating
the STP starts to output a low number again, like R=1
a "stop making enzymes" R=0 override comes in
In this story, the initial output of 1 is "correct". But it's not a prediction of the next override, which is probably going to be 10. (It could be 0, but only if I incorrectly start to produce more enzymes in the meantime, the STP had been incorrectly outputting a high number.)
So as long as it's the case that "we don't get an R=0 override unless we actually make too many enzymes", I think the STP isn't predicting the next override. What's it predicting instead? Possible answers:
"How many digestive enzymes are going to be removed from the stomach in the next few minutes"? (Obviously only applies to this specific LTP configuration.)
"If this prediction changed, would we get an override soon"? (I think this is an accurate question, at least in this case? If we're "correctly" predicting low, and we started to predict high, then we'd make too many enzymes and get a "stop" override. If we're "correctly" predicting high, and we started to predict low, then food would come in and we'd have too few enzymes and get a "start" override. I'm not sure this is accurate in all possible LTP configurations.)
"It's not predicting anything, it's just part of a control system, though depending on details it can be useful to think of the STPs in these systems as predicting things like [the above two questions, plus "what's the next override", plus probably others]"?
(Another way this LTP could be configured would be to give an override every, say, ten minutes. Then the override doesn't depend on the prediction, as long as my actions don't depend on it. That would be biologically different, and I don't think you're claiming it's what actually happens, at least not in all LTPs. If the interval is too short, then I won't start making enzymes far enough in advance; if it's too long, I'll keep making them long after they're not needed.)
(This comment is kinda poorly thought through, sorry, but it’s the best I can do right now and I don’t want to leave you hanging even longer.)
Hmmm. It’s possible that you’re onto something important, but I’m not convinced yet. :)
(It could be 0, but only if I incorrectly start to produce more enzymes in the meantime, the STP had been incorrectly outputting a high number.)
You’re brushing this aside, but to me it’s load-bearing. The R=1 output leads to more enzymes than R=0, and maybe even that small amount will wind up being too much. Probably not, but you only need that to happen 10% of the time.
(Another degree of freedom is, instead of R being the “rate of digestive enzyme production”, it could be a more abstract “rate setting” that is monotonically but nonlinearly related to the literal number of enzyme molecules produced per second.)
(Periodic reminder that I don’t actually know anything about digestive enzymes, this is still just a toy example.)
…It might be nice to have easier-to-visualize metaphor. Let’s try!
Imagine, on a dare, you’re driving pretty fast, blindfolded, on a curvy go-kart track. You’ve driven on this track before, so you kinda remember the way it curves, but not very well, and you’re also pretty hazy on where exactly you are relative to the track.
Sometimes you hit the left side of the track, and then you scream and pull the steering wheel hard to the right (“+10 override”). Sometimes you hit the right side of the track, and then you scream and pull the steering wheel hard to the left (“–10 override”).
Otherwise, I guess my scheme would be: you’re trying to keep track of which side you’re likely to hit next, and the more you think it’s probably gonna be the right side that you hit next, the more you’re gonna turn the steering wheel left, and vice-versa.
So for example, at time t=0, you’re steering straight, and you think “I’m probably going to hit the left side next”, so you start turning the steering wheel more and more to the right, at 5°/second. Then at t=2, the steering wheel is 10° right of neutral, and now you think “I’m 50-50 on which side I’m going to hit next”, so you keep your steering wheel fixed at 10° right of neutral. Then at t=7, it’s been long enough that you have a sense that you must be getting close to a bend where the track veers left, so you think “I’m almost definitely going to hit the right side next”, and start turning the steering wheel 10°/second to the left, until the steering wheel is neutral at t=8, then 10° left of neutral at t=9, and so on until you feel an increasing chance that you’ll overcorrect and hit the left side. Etc.
See what I mean?
Anyway, when I read your comment about a scenario where (based on past experience) you’re expecting low need for digestive enzymes for a couple hour, but high need after that, I was sorta visualizing this go-kart track, following the curvy statistical expectation of how much digestive enzymes you’ll need when, and trying not to bump up against either the too-high or the too-low side. It’s important that there’s always a chance of hitting either side of the track.
Does that help?
(PS: in my first draft of this comment, I was gonna suggest that the probability of hitting the left versus right side of the track should control the steering wheel position, not the steering wheel rotational velocity. But that wouldn’t work in a circular track—it would never stop hitting the outside, I think. Seems vaguely related to P versus I feedback control, maybe? But not exactly … it’s not a traditional control loop because it involves a forward-looking prediction, I think.)
I don't think I understand how the scorecard works. From:
[the scorecard] takes all that horrific complexity and distills it into a nice standardized scorecard—exactly the kind of thing that genetically-hardcoded circuits in the Steering Subsystem can easily process.
And this makes sense. But when I picture how it could actually work, I bump into an issue. Is the scorecard learned, or hard-coded?
If the scorecard is learned, then it needs a training signal from Steering. But if it's useless at the start, it can't provide a training signal. On the other hand, since the "ontology" of the Learning subsystem is learned-from-scratch, then it seems difficult for a hard-coded scorecard to do this translation task.
The categories are hardcoded, the function-that-assigns-a-score-to-a-category is learned. Everybody has a goosebumps predictor, everyone has a grimacing predictor, nobody has a debt predictor, etc. Think of a school report card: everyone gets a grade for math, everyone gets a grade for English, etc. But the score-assigning algorithm is learned.
So in the report card analogy, think of a math TA ( = Teaching Assistant = Thought Assessor) who starts out assigning math grades to students randomly, but the math professor (=Steering Subsystem) corrects the TA when its assigned score is really off-base. Gradually, the math TA learns to assign appropriate grades by looking at student tests. In parallel, there’s an English class TA (=Thought Assessor), learning to assign appropriate grades to student essays based on feedback from the English professor (=Steering Subsystem).
The TAs (Thought Assessors) are useless at the start, but the professors aren't. Back to biology: If you get shocked, then the Steering Subsystem says to the “freezing in fear” Thought Assessor: “Hey, you screwed up, you should have been sending a signal just now.” The professors are easy to hardwire because they only need to figure out the right answer in hindsight. You don't need a learning algorithm for that.
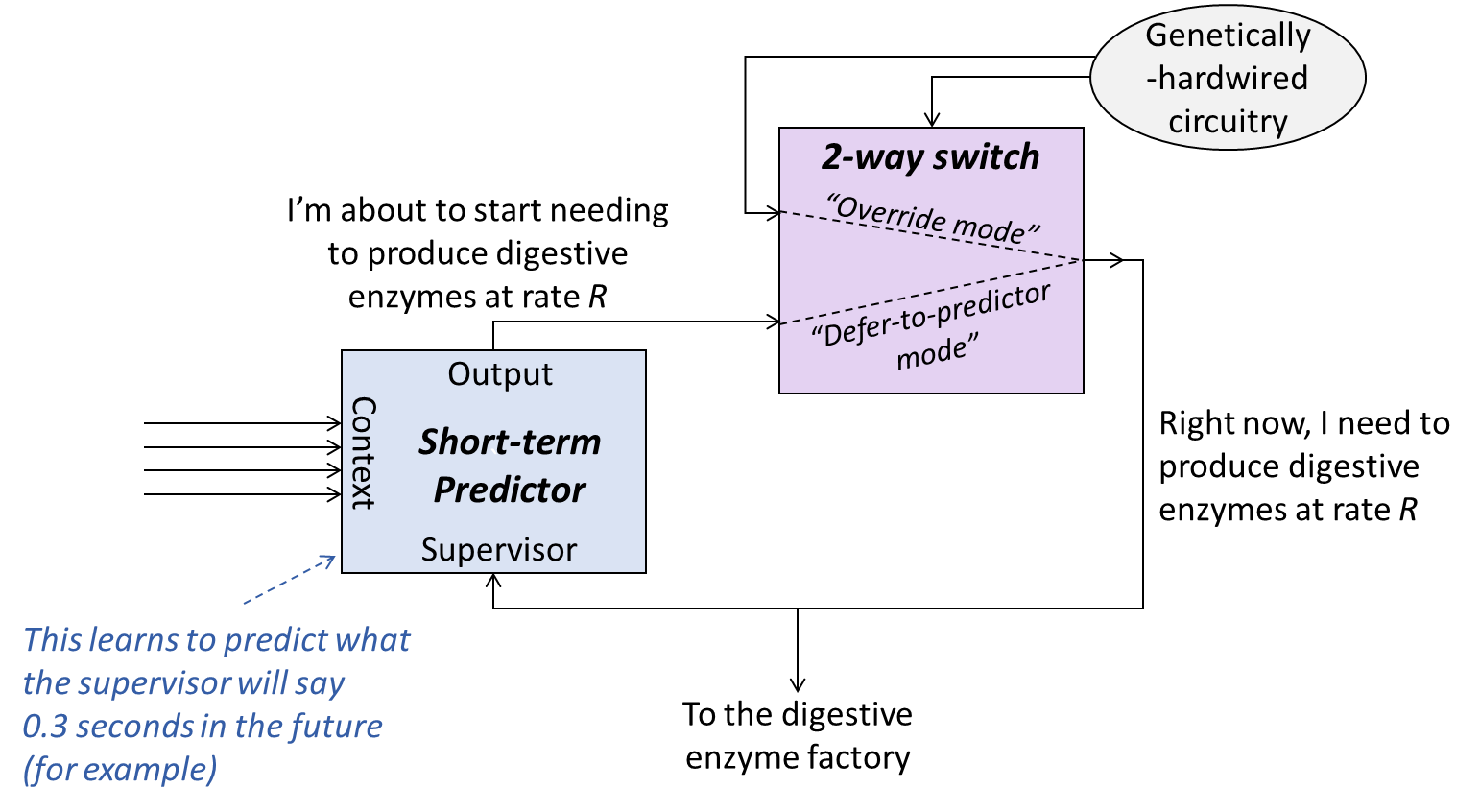
{kind=link}
{kind=link}
(Last revised: June 2026. See changelog at the bottom.)
5.1 Post summary / Table of contents
Part of the “Intro to brain-like-AGI safety” post series.
In the previous post, I discussed the “short-term predictor”—a circuit which, thanks to a learning algorithm, emits an output that predicts a ground-truth supervisory signal arriving a short time (e.g. a fraction of a second) later.
In this post, I propose that we can take a short-term predictor, wrap it up into a closed loop involving a bit more circuitry, and we wind up with a new module that I call a “long-term predictor”. Just like it sounds, this circuit can make longer-term predictions, e.g. “I’m likely to eat in the next 10 minutes”. This circuit winds up being a kind of hybrid between Temporal Difference (TD) learning and supervised learning.
I will argue that there is a large collection of side-by-side long-term predictors in the brain, each comprising a short-term predictor in the Learning Subsystem (more specifically, in the extended striatum—putamen, nucleus accumbens, lateral septum, part of the amygdala, etc.) that loops down to the Steering Subsystem (hypothalamus and brainstem) and then back up via a dopamine neuron. These long-term predictors make predictions about biologically-relevant inputs and outputs—for example, one long-term predictor might predict whether I’ll feel pain in my arm, another whether I’ll get goosebumps, another whether I’ll release cortisol, another whether I’ll eat, and so on. Moreover, one of these long-term predictors is essentially a value function for reinforcement learning.
All these predictors will play a major role in motivation—a story which I will finish in the next post.
Table of contents:
5.2 Toy model of a “long-term predictor” circuit
A “long-term predictor” is ultimately nothing more than a short-term predictor whose output signal helps determine its own supervisory signal. Here’s a toy model of what that can look like:
Note: You can assume that all the signals in the diagram can vary continuously across a range of values (as opposed to being discrete on/off signals), with the exception of the signal that toggles the 2-way switch.[1] In the brain, smoothly-adjustable signals might be created by, for example, rate-coding—i.e., encoding information as the frequency with which a neuron is firing.
Next, let’s walk through the properties of this toy model.[2]
5.2.1 Toy model walkthrough: preliminaries
Here’s a little summary table for this subsection, that I’ll explain in the text below.
5.2.1.1 What is the short-term predictor getting trained to do?
The short-term predictor is a learning algorithm. Given infinite time, we normally expect learning algorithms to settle into some steady-state configuration where they no longer update. We can think of this configuration as “what we are training it to do”. So, in this toy model, what are we training the short term predictor to do?
Well, first, if there’s an override with ground truth R, we are training the short-term predictor to be already outputting R, immediately before that override.
And second, while we’re in defer-to-predictor mode, we are training the short-term predictor to keep its output steady. After all, any change in its output would create a (transient) discrepancy between the short-term predictor’s output, versus its supervisor, thus causing an update.[3]
(Clarification: I’m using the phrase “keep its output steady”, but that glosses over the key detail that we are training it to “keep its output steady” in a way that privileges one temporal direction over the other: the output now is treated as what the output should have been in the immediate past. Whereas in the other direction, if the short-term predictor was making a bad prediction in the past, but now it has new information that reveals the error, we are not training it to “keep its output steady” by sticking with the old bad prediction. That’s just not what the learning algorithm updates would do.)
So putting those two observations together, in this toy model, we are training the short-term predictor to always output what the next override will be, even if that override won’t happen for a very long time. (Or if there’s randomness that makes the next override unpredictable, we are training it to predict the expectation value of the next override.)
5.2.1.2 AI intuitions: supervised learning, and Temporal Difference (TD) learning
If you’re an AI reader, think of the overrides as like sporadic “injections of ground truth”, turning the setup into a kind of supervised learning.
And separately, think of defer-to-predictor mode as a version of Temporal Difference (TD) learning.
AI people might be wondering: In AI textbooks, TD learning is notoriously bad at long-term planning, because the correct behavior “walks backwards” one (fraction-of-a-second) timestep per attempt. And yet, humans will plan a vacation a month in advance, without having previously gone on (1 month) / (0.3 seconds) ≈ 10,000,000 vacations. Is that evidence that TD learning can’t be involved? No! The trick is, in the brain, the context data going into the short-term predictor already contains temporally-extended latent variables. For example, the mental concept “I’m getting lunch” is active in your mind 10 minutes in advance of eating, as you get on the bus to the restaurant, and is also active in your mind at the moment when you bite into the sandwich. So nothing has to propagate back one-timestep-at-a-time over the course of thousands of lunches; instead it takes as few as one iteration for the short-term predictor to learn that the “I’m getting lunch” latent variable predicts digestive enzymes.
(Note that the term “TD learning” is usually used in reinforcement learning (RL) in the context of going from a reward function to a value function. But TD learning is really a general-purpose algorithm that takes a quantity X and spits out a long-term expectation of X. We can use that algorithm for whatever we want, including for things like “digestive enzyme production” which are neither rewards nor values.[4] That said, we will in fact apply these ideas to rewards and values, as a special case, when we get to §5.3 below.)
5.2.1.3 Neuro intuitions: innate reactions, and self-fulfilling prophecies
Meanwhile, neuro readers should think of override mode as innate reactions to innate triggers, often related to homeostasis, like salivating in response to salty food in the mouth, or physiological arousal in response to pain. As discussed in Post 3, these reactions generally happen entirely within the Steering Subsystem (brainstem, hypothalamus, etc.).
And then think of defer-to-predictor mode as “self-fulfilling prophecies”. For example, as you hold the cracker in your hand, you expect that you’re about to salivate, and that expectation turns into reality. Similarly, as you go to start a painful procedure, you expect that you’re about the have physiological arousal, and that expectation turns into reality. The Steering Subsystem has no direct evidence either way, so it “defers” to the guesses coming from the Learning Subsystem.
5.2.2 Toy model walkthrough: the case of static context
Next, let’s walk through what would happen in this toy model, in the specific case that the “context” is static for some extended period of time. For example, imagine a situation where some ancient worm-like creature is digging in the sandy ocean bed for many consecutive minutes. Plausibly, its sensory environment would stay pretty much constant as long as it keeps digging, as would its thoughts and plans (insofar as this ancient worm-like creature has “thoughts and plans” in the first place). Or if you want another example of (approximately) static context—this one involving a human rather than a worm—hang on until the next subsection.
In the static-context case, let’s first consider what happens when the switch is sitting in “defer-to-predictor mode”: Since the output is looping right back to the supervisor, there is no error in the supervised learning module. The predictions are correct. The synapses aren’t changing. Even if this situation is very common, it has no bearing on how the short-term predictor eventually winds up behaving.
The times that do matter for the eventual behavior of the short-term predictor are those rare times that we go into “override mode”. They inject ground truth into the system, and produce an error signal in the short-term predictor’s learning algorithm, changing its adjustable parameters (e.g. synapse strengths).
After enough life experience (a.k.a. “training” in ML terminology), the short-term predictor should have the property that the overrides balance out. There may still be occasional overrides that increase digestive-enzyme production, and there may still be occasional overrides that decrease digestive-enzyme production, but those two types of overrides should balance out to an average of zero. After all, if they didn’t balance out, the short-term predictor’s internal learning algorithm would gradually change its parameters so that they did balance out.
And that’s just what we want! We’ll wind up with appropriate digestive enzyme production at appropriate times, in a way that properly accounts for any information available in the context data—what the animal is doing right now, what it’s planning to do in the future, what its current sensory inputs are, etc.
5.2.2.1 David-Burns-style exposure therapy—a possible real-life example of the toy model with static context?
As it happens, I recently read David Burns’s book Feeling Great (my review). David Burns has a very interesting approach to exposure therapy—an approach that happens to serve as an excellent example of how my toy model works in the static-context situation!
Here’s the short version. (Warning: If you’re thinking of doing exposure therapy on yourself at home, at least read the whole book first!) Excerpt from the book:
This story seems to be beautifully consistent with my toy model here. David started the day in a state where his short-term-predictors output “extremely strong fear reactions” when he was up high. As long as David stayed up on the ladder, those fear-reaction short-term-predictors kept on getting the same context data, and therefore they kept on firing their outputs at full strength. And David just kept feeling terrified.
Then, after 15 boring-yet-terrifying minutes on the ladder, some innate circuit in David’s brainstem issued an override—as if to say, “C’mon, nothing is changing, nothing is happening, we can’t just keep burning all these calories all day. It’s time to calm down now.” The short-term-predictors continued sending the same outputs as before, but the brainstem exercised its veto power, and forcibly reset David’s cortisol, heart-rate, etc., back to baseline. This “override” state immediately created error signals in the relevant short-term-predictors in David’s amygdala! And the error signals, in turn, led to model updates! The short-term predictors were all edited, and from then on, David was no longer afraid of heights.
Here’s the diagram for this situation; make sure you can follow all the steps.
5.2.3 Toy model walkthrough, assuming changing context
The previous subsection assumed static context lines (constant sensory environment, constant behaviors, constant thoughts and plans, etc.). What happens if the context is not static?
If the context lines are changing, then it’s no longer true that learning happens only at “overrides”. If context changes in the absence of “overrides”, it will result in changing of the output, and the new output will be treated as ground truth for what the old output should have been. Again, this seems to be just what we want: if we learned something new and relevant in the last second, then our current expectation should be more accurate than our previous expectation, and thus we have a sound basis for updating our models.
5.3 The RL value function (a.k.a. critic, a.k.a. “valence guess”) as a special case of long-term prediction
Just as we need to produce digestive enzymes based on an expectation of future meals, we likewise need to make decisions based on an expectation of future good outcomes that would result from those decisions. Thus, long-term predictors are a key part of planning and reinforcement learning in the brain.
More specifically: If you’re a human, you need to decide whether to watch TV or go to the gym. If you’re some ancient worm-like creature, you need to “decide” whether to dig or to swim. Either way, this “decision” impacts energy balance, salt balance, probability of injury, probability of mating—you name it.
The only practical way for an algorithm to output good foresighted decisions is to put everything into a common currency: a scalar signal of overall “goodness”. RL practitioners call this signal “reward”, and it loosely[5] corresponds to the everyday notion of “pleasure”. Once you have this signal, you can insert an algorithm that learns to predict it; RL practitioners call this prediction “value” or “critic”, and in everyday life it’s related to motivation. And exactly how do we get this prediction? With a long-term predictor, of course!
(…And then another algorithm needs to turn those predictions into good decisions—i.e., the “actor” part of actor-critic RL. But I’ll hold off on that until the next post.)
I’ll explain my proposal through an example:
5.3.1 Example: Walking upstairs to get a sweater
Suppose I’m downstairs and feeling cold. An idea pops into my head: “I’ll go put on my cozy sweater”. So I walk upstairs and put it on.
What just happened? Here’s a diagram:
This is the same kind of diagram as §5.2 above, but instead of predicting a digestive enzyme signal, the blue box is predicting a special signal I call valence (more on which in a minute).
Here the “override mode” is the pleasure from putting on the cozy sweater, which can be grounded in innate brainstem circuitry related to warmth, tactile feelings, and so on. At that point, when the sweater is on, the brainstem “knows” that something good has happened.
But the more interesting question is: what was happening during the thirty seconds that it took me to walk upstairs? I evidently had motivation to continue walking, or I would have stopped and turned around. But my brainstem hadn’t gotten any ground truth yet that there were good things happening. That’s where “defer-to-predictor mode” comes in! The brainstem, lacking strong evidence about what’s happening, sees a positive valence guess coming out of the striatum and says, in effect, “OK, sure, whatever, I’ll take your word for it.”
And the short-term predictor will (after some life experience) output a good guess for the next override valence, whenever that may occur. And since the cozy sweater will be a positive valence override, the valence guesses preceding it will likewise be positive. And therefore I will be motivated to get the sweater, including spending 30 seconds walking up the stairs.
(Recall from §5.2.1.2 that the short-term predictor can learn quite quickly, because of temporally-extended latent variables in the context data. In this case, the latent variables in question would be related to the explicit idea, in my head, that I’m going to put on a sweater.)
5.3.2 How exactly does this setup relate to textbook RL?
There’s a high-level similarity-in-spirit between this setup and the kind of conventional actor-critic RL that you’ll find in an AI textbook. But when we drill into details, the correspondence between the two is pretty convoluted. Indeed, if you have a strong background in the conventional RL literature, you’re probably at a disadvantage in trying to parse my proposals! Here are some of the common points of confusion:
5.3.2.1 “Valence”, and ground-truth-iness
A number of differences between my model versus textbook actor-critic RL are related to the particulars of the “valence” signal, and related RL reward.
5.3.2.2 Miscellaneous circuit elaborations
The circuit above is a toy model, so here’s a few words about what it’s leaving out, at least in the important special case of valence.
First, the short-term predictor in the circuit needs learning rate modulation. For example, suppose I’m doing math homework outside. At time t=0.0 seconds, I’m thinking “what if I take the square root of both sides of the equation?”, and then at time t=0.2 seconds, I’m thinking “aah my cell phone alarm is going off, I have to leave for my appointment!”. Thinking about the appointment might be positive or negative valence, but either way, it doesn’t provide any evidence about whether it would have been a good idea to take the square root of both sides.
Normally, my brain would do the TD learning thing, by comparing the actual valence at t=0.2 to the valence guess at t=0.0, and doing a weight-update on the short-term predictor to make them more consistent. However, in this case, it would be better to just skip that update altogether, i.e. to transiently set the learning rate to zero.
The end-result is what I sometimes call “TD learning with sporadic power outages”. These “power outages” enable the value to shift in the absence of a reward; this feature seems necessary to explain the fact that people are able to make progress on a plan (but without consummating the plan), and then do something else for a while, and then go back to the plan later. Neuroscientifically, I believe this feature is implemented by the striatal cholinergic interneuron “pause” (cf. Zhang & Cragg 2017) that can be triggered by a (generalized) orienting reflex.
Other differences between my model versus textbook actor-critic RL relate to various ways that RL practitioners tweak the circuit. Actually, some of these might be used in the brain too.
One example is time-discounting. Another is: we could introduce an asymmetry in how we treat positive (overshoot) versus negative (undershoot) errors in the short-term predictor—see my discussion of “distributional learning” in a footnote of the previous post. Probably other things too.
Also, I put an all-or-nothing two-way switch in the toy model, but realistically, it’s probably more like a weighted average with dynamically-adjustable weights.
To keep things simple, I will be ignoring all these possibilities (including time-discounting) in the discussion here.
…But there’s one more very obvious difference that’s worth diving into:
5.3.2.3 Switch (value = expected next reward) vs summation (value = expected sum of future rewards)
My model amounts to a value function that approximates the next “override” reward, whenever it should arise. However, textbook RL does something different: the value function approximates the (exponentially-discounted) sum of all future rewards. This amounts to swapping out our purple-box 2-way switch with a 2-way summation:
(The correct answer could also be “something in between switch and summation”. Or it could even be “none of the above”.)
RL papers universally use the summation version—i.e., “value is the expected sum of future rewards”. What about biology? And which is actually better?
It doesn’t always matter! Consider AlphaGo. Like every RL paper today, AlphaGo was originally formulated in the summation paradigm. But it happens to have one and only one nonzero reward signal per game, namely +1 at the end of the game if it wins, or -1 if it loses. In that case, switch vs summation makes no difference. The only difference is one of terminology:
(Do you see why?)
But in other cases, it does matter. So back to the question: should it be switch or summation?
I don’t have a strong opinion that it must be one or the other, from first principles. But I do think the RL value function (“valence guess”) calculation in brains is approximately the switch one, not the summation one. Again, I think it’s really “neither of the above” in all cases; just that it’s much closer to switch.
Why do I think that? Well here’s an example: sometimes I stub my toe and it hurts for 20 seconds; other times I stub my toe and it hurts for 40 seconds. But I don’t think of the latter as twice as bad as the former. In fact, even five minutes later, I wouldn’t remember which is which. (See the peak-end rule.) This is the kind of thing I would naturally expect from switch, but is an awkward fit for summation. It’s not strictly incompatible with summation; it just requires a more complicated, value-dependent reward function. (As a matter of fact, if we allow the reward function to depend on value, then switch and summation can imitate each other.)
You might be wondering: isn’t summation essential for long-term planning? My answer: yes it is essential … in textbook RL. But hey, so much the worse for textbook RL! I think brains can plan ahead just fine with the switch circuit. For example, suppose there’s a yummy jelly bean in front of me, but if I eat it, then a monster will bite my arm off tomorrow. I’m not gonna eat the jelly bean! Why not? Because I’m explicitly thinking ahead to tomorrow, and that makes the plan seem bad. See the discussion of temporally-extended latent variables in §5.2.1.2 above.
Anyway, in upcoming posts, I’ll be assuming switch, not summation. I don’t think it matters very much for the big picture. I definitely don’t think it’s part of the “secret sauce” of animal intelligence, or anything like that. But it does affect some of the detailed descriptions. This will be an additional source of confusion for people with a conventional RL background, on top of everything else mentioned above.
5.3.3 Teaser for my “Valence” series (2023)
Again, “valence”—and here I mean “actual valence”, not “valence guess”—signals whether a thought is good (so I should keep thinking it, and think follow-up thoughts, and take associated actions), or bad (so I should start thinking about something else instead), all things considered.
My 5-post “Valence” series notes that, given the obvious central importance of this “valence” brain signal‚ it should illuminate many aspects of our everyday mental life. And indeed, it does! I argue in the series that valence is critical to understanding desires, values, vibes, brainstorming, motivated reasoning, the halo effect, social status, depression, mania, and more.
5.4 An array of long-term predictors involving the extended striatum & Steering Subsystem
Here’s the long-term-predictor circuit from above:
I can lump together the 2-way switch with the rest of the genetically-hardwired circuitry, and then rearrange the boxes a bit, and I get the following:
Now, obviously digestive enzymes are just one example. Let’s draw in some more examples, add some hypothesized neuroanatomy, and include other terminology. Here’s the result:
Excellent! We’re halfway to my big picture of decision-making and motivation. The rest of the picture—including the “actor” part of actor-critic reinforcement learning—will come in the next post, and will fill in the hole in the top-left side of that diagram. (The term “Steering Subsystem” comes from Post #3.)
Here’s one more diagram and caption for pedagogical purposes.
In the next two subsections, I will elaborate on the neuroanatomy which I’m hinting at in this diagram, and then I’ll talk about why you should believe me.
5.5 Five reasons I like this “array of long-term predictors” picture
5.5.1 It’s a sensible way to implement a biologically-useful capability
If you start producing digestive enzymes before eating, you’ll digest faster. If your heart starts racing before you see the lion, then your muscles will be primed and ready to go when you do see the lion. Etc.
So these kinds of predictors seem obviously useful.
Moreover, as discussed in the previous post (§4.5.2), the technique I’m proposing here (based on supervised learning) seems either superior to or complementary with other ways to meet these needs.
5.5.2 It’s introspectively plausible
For one thing, we do in fact start salivating before we eat the cracker, start feeling nervous before we see the lion, etc.
For another thing, consider the fact that all the actions I’m talking about in this post are involuntary: you cannot salivate on command, or dilate your pupils on command, etc., at least not in quite the same way that you can wiggle your thumb on command.
(More on voluntary actions in the next post, when I talk more about the cortex.)
I’m glossing over a bunch of complications here, but the involuntary nature of these things seems pleasingly consistent with the idea that they are being trained by their own dedicated supervisory signals, straight from the brainstem. They’re slaves to a different master, so to speak. We can kinda trick them into behaving in certain ways, but our control is limited and indirect (see §6.3.3 of the next post).
5.5.3 It’s evolutionary plausible
As discussed in §4.4 of the previous post, the simplest short-term predictor is extraordinarily simple, and the simplest long-term predictor is only a bit more complicated than that. And these very simple versions are already plausibly fitness-enhancing, even in very simple animals.
Moreover, as I discussed a while back (Dopamine-supervised learning in mammals & fruit flies (2021)), there is an array of little learning modules in the fruit fly, playing a seemingly-similar role to what I’m talking about here. Those modules also use dopamine as a supervisory signal, and there is some genomic evidence of a homology between those circuits and the mammalian telencephalon.
5.5.4 It’s neuroscientifically plausible
The details here are out-of-scope, and somewhat more complicated than I’m making it out to be, but for (a major subset of) Thought Assessors, I believe the correspondence between my toy models and real neuroanatomy is as follows:
Thus, for example, my claim is that if you zoom into (say) the central amygdala, you’ll find dozens of little genetically-determined subregions, each projecting to a specific set of genetically-determined Steering Subsystem targets, and with a genetically-determined narrowly-targeted supervisory signal coming back (directly or indirectly) from often the same Steering Subsystem target. Thus, for example, maybe thus-and-such little group of amygdala neurons is universally associated with getting goosebumps. But each individual brain would learn within its lifetime a different set of patterns that trigger this group of goosebumps-related neurons.
Is that hypothesis consistent with the experimental evidence? My impression so far, from everything I’ve read, is “yes”, although I admit I don’t have super-solid evidence either way. More specifically:
For the valence-guess Thought Assessor, the gory details are out-of-scope, but I think my story is elegantly compatible with textbook basal ganglia circuitry, particularly the famous motif of “cortico-basal ganglia-thalamo-cortical loops”.[8]
For the “visceral” Thought Assessors: On general priors, there’s certainly no question that the genome is capable of wiring up dozens-to-hundreds of little cell groups in dozens-to-hundreds of specific and innate ways—this is ubiquitous in the Steering Subsystem. What about more specifically? I’ve found a few things. As one small-scale example, Lischinsky et al. (2023) studied two little embryonically-defined amygdala subpopulations, and finds that these two subpopulations wind up triggering in very different circumstances and connecting to very different downstream cells. As another example, at a larger scale, Heimer et al. (2008) says that the bundle of outputs of (what I’m calling) the “visceral” Thought Assessors are just a horrific mess, going every which way, as would be expected from hundreds of cell groups projecting to hundreds of different Steering Subsystem targets:
As another piece of suggestive evidence, Lammel et al. (2014) mentions so-called “‘non-conventional’ VTA [dopamine] neurons” in “medial posterior VTA (PN and medial PBP)”. These seem to project to roughly the “visceral” Thought Assessor areas that I mentioned above, and it’s claimed that they have different firing patterns from other dopamine neurons. That seems intriguing, although I don’t have a more specific story than that right now. Relatedly, Verharen et al. (2020) discusses certain dopamine neurons which burst when aversive things happen, and four of the five regions these neurons seem to “supervise” are home to visceral Thought Assessors.[9] This makes sense because if the mouse freezes in terror, then that’s a positive error signal for the freeze-in-terror visceral Thought Assessor, as well as the raise-your-cortisol-level visceral Thought Assessor, and so on.
5.5.5 It offers a nice way to make sense of a wide variety of animal psychology phenomena, including Pavlovian conditioning, devaluation, and more
See my post Incentive Learning vs Dead Sea Salt Experiment (2024) for details on that. See also the last section of that post for some contrasts between my model and a couple others in the psychology and neuro-AI literature.
5.6 Conclusion
Anyway, as usual I don’t pretend to have smoking-gun proof of my hypothesis (i.e. that the brain has an array of long-term predictors involving extended striatum-Steering Subsystem loops), and there are some bits that I’m still confused about. But considering the evidence in the previous subsection, and everything else I’ve read, I wind up feeling strongly that I’m broadly on the right track. I’m happy to discuss more in the comments. Otherwise, onward to the next post, where we will finally put everything together into a big picture of how I think motivation and decision-making work in the brain!
Changelog
July 2024: Since the initial version, I’ve made a bunch of changes.
The biggest changes are related to neuroanatomy. I was just really confused about lots of things in 2022, but I hope I’m converging towards correct answers! In particular:
I’ve gone through several iterations of the diagrams in this post, particularly including which neuroanatomy corresponds to which boxes.
There used to be a much longer discussion of neuroanatomy in §5.4, but much of that was incorrect, and the rest got moved into the newly-rewritten §5.5.4.
I originally had a discussion of dopamine diversity. I mostly deleted that, apart from a couple sentences, having been convinced that at least one of the pieces of evidence I discussed (Engelhart et al. 2019) was not related to “visceral Thought Assessors”, but rather had a different explanation. (Thanks Nathaniel Daw for the correction.) I also moved the discussion of distributional RL into a footnote of the previous post.
More minor things:
I added a note that all the diagrams in this post should be understood as the kinds of diagrams you see in FPGA design—i.e. at every instant, every block is running simultaneously, and every line (wire) is carrying a numerical value. It’s not like the kinds of diagrams you see in descriptions of serial program control flow, where we follow a path through the diagram, executing one thing at a time.
I’ve also changed the wording on the labels of the various diagrams a few times since the initial version. For example, where it used to say “Will lead to reward?” and “It was in fact leading to reward”, it now says “Valence guess” and “Actual valence”, respectively. The previous wording was OK, but I think the connotations are a bit better here, and also more consistent with my later Valence series.
I added a second concrete example story (involving a cozy sweater) as §5.3.2.
I replaced a brief discussion of the “dead sea salt experiment” with a link to my more recent post dedicated to that topic, in §5.5.5.
January 2026: I added a new §5.2.1 (“preliminaries”) to hopefully explain the toy model better. (The old §5.2.1 is now §5.2.2, and the old §5.2.2 is now §5.2.3.) Plus various other minor copyedits. Thanks Eli Tyre for helpful criticism that spurred the rewrite.
May 2026: I rearranged and rewrote §5.3 for clarity (along with related edits to §5.2.1.2). Among other things, the sweater example moved from §5.3.2 to §5.3.1, while the rest of the discussion moved from §5.3.1 to §5.3.2. Thanks Rif A. Saurous for helpful criticism that spurred the rewrite.
June 2026: Added a footnote referencing Lee et al. 2024. Added a discussion of learning rate modulation to §5.3.2.2. Moved “Teaser for my ‘Valence’ series” from §6.4.1 to §5.3.3 (and shortened it).
To be clear, in reality, there probably isn’t a discrete all-or-nothing 2-way switch here. There could be a “weighted average” setting, for example. Remember, this whole discussion is just a pedagogical “toy model”; I expect that reality is more complicated in various respects.
I note that I’m just running through this algorithm in my head; I haven’t simulated it. I’m optimistic that I didn’t majorly screw up, i.e. that everything I’m saying about the algorithm is qualitatively true, or at least can be qualitatively true with appropriate parameter settings and perhaps other minor tweaks.
To be clear, this transient discrepency has nothing to do with signal propagation delays. In this toy model, I declare that signal propagation is instantaneous. Rather, it’s from the 0.3 second (or whatever) time-offset internal to the short-term predictor.
Examples in the literature where people use the terminology “TD learning” in a context unrelated to RL reward functions include: “TD networks”, the Successor Representations literature (example), or this paper, etc.
The term “pleasure” doesn’t quite have the right connotations, but it’s the least-bad word I can think of. For example, if I allow myself to be tortured to death to save the lives of my countrymen, is that “pleasure”? I would say: “Actually, kinda yes! Specifically: When you think of yourself as a brave hero, that thought comes with a great deal of pleasure. On the other hand, when you think about the feeling of pain, that thought comes with a great deal of displeasure. At the end of the day, you might or might not endure the torture to keep the secret.
Not always—certain parts of cortex layer 5 are also Thought-Assessor-ish. But meanwhile, most of the cortex is doing something different, as discussed in the next post.
As in the previous post, when I say that “dopamine carries the supervisory signal”, I’m open to the possibility that dopamine is actually a closely-related signal like the error signal, or the negative error signal, or the negative supervisory signal. It really doesn’t matter for present purposes.
Lee et al. 2024 is definitely not a perfect match to my beliefs on this topic, but it’s probably closer than anything else in the literature, and reading it was helpful for my thinking.
The fifth area where that paper found dopamine neurons bursting under aversive circumstances, namely the tail of the striatum, has a different explanation I think—see here.