Thus far in the series, Post #1 set out some definitions and motivations (what is “brain-like AGI safety” and why should we care?), and Posts #2 & #3 split the brain into a Learning Subsystem (cortex, striatum, cerebellum, amygdala, etc.) that “learns from scratch” using learning algorithms, and a Steering Subsystem (hypothalamus, brainstem, etc.) that is mostly genetically-hardwired and executes innate species-specific instincts and reactions.
Then in Post #4, I talked about the “short-term predictor”, a circuit which learns, via supervised learning, to predict a signal in advance of its arrival, but only by perhaps a fraction of a second. Post #5 then argued that if we form a closed loop involving both a set of short-term predictors in the extended striatum (within the Learning Subsystem) and a corresponding set of hardwired circuits in the Steering Subsystem, we can get a “long-term predictor”. I noted that the “long-term predictor” circuit is closely related to temporal difference (TD) learning.
Now in this post, we fill in the last ingredients—roughly the “actor” part of actor-critic reinforcement learning (RL)—to get a whole big picture of motivation and decision-making in the human brain. (I’m saying “human brain” to be specific, but it would be a similar story in any other mammal, and to a lesser extent in any vertebrate.)
The reason I care about motivation and decision-making is that if we eventually build brain-like AGIs (cf. Post #1), we’ll want to build them so that they have some motivations (e.g. being helpful) and not others (e.g. escaping human control and self-reproducing around the internet). Much more on that topic in later posts.
Teaser for upcoming posts: The next post (#7) will walk through a concrete example of the model in this post, where we can watch an innate drive lead to the formation of an explicit goal, and adoption and execution of a plan to accomplish it. Then starting in Post #8 we’ll switch gears, and from then on you can expect substantially less discussion of neuroscience and more discussion of AGI safety (with the exception of one more neuroscience post towards the end).
Unless otherwise mentioned, everything in this post is “things that I believe right now”, as opposed to neuroscience consensus. (Pro tip: there is never a neuroscience consensus.) Relatedly, I will make minimal effort to connect my hypotheses to others in the literature (I tried a little bit in the last section of my post “Incentive Learning vs Dead Sea Salt Experiment” (2024)), but I’m happy to chat about that in the comments section or by email.
Table of contents:
In §6.2, I’ll present a big picture of motivation and decision-making in the human brain, and walk through how it works. The rest of the post will go through different parts of that picture in more detail. If you’re in a hurry, I suggest reading to the end of §6.2 and then quitting.
In §6.3, I’ll talk about the so-called “Thought Generator”, which corresponds more-or-less to the cortex.[1] (For ML readers familiar with “actor-critic model-based RL”, the Thought Generator is more-or-less a combination of the “actor” and the “model”.) I’ll talk about the inputs and outputs of this module, and briefly sketch how its algorithm relates to neuroanatomy.
In §6.4, I’ll elaborate on why I’m describing this setup as “actor-critic model-based reinforcement learning.
In §6.5, I’ll go into a bit more detail about how and why thinking and decision-making needs to involve not only simultaneous comparisons (i.e., a mechanism for generating different options in parallel and selecting the most promising one), but also sequential comparisons (i.e., thinking of something, then thinking of something else, and comparing those two thoughts). For example, you might think: “Hmm, I think I’ll go to the gym. Actually, what if I went to the café instead?” These are two sequential thoughts that you’re comparing.
In §6.6, I’ll comment on the common misconception that the Learning Subsystem is the home of ego-syntonic, internalized “deep desires”, whereas the Steering Subsystem is the home of ego-dystonic, externalized “primal urges”. I will advocate more generally against thinking of the two subsystems as two agents in competition; a better mental model is that the two subsystems are two interconnected gears in a single machine.
6.2 Big picture
Yes, this is literally a big picture, unless you’re reading on your cell phone. You saw a chunk of it in the previous post (§5.4), but now there are a few more pieces.
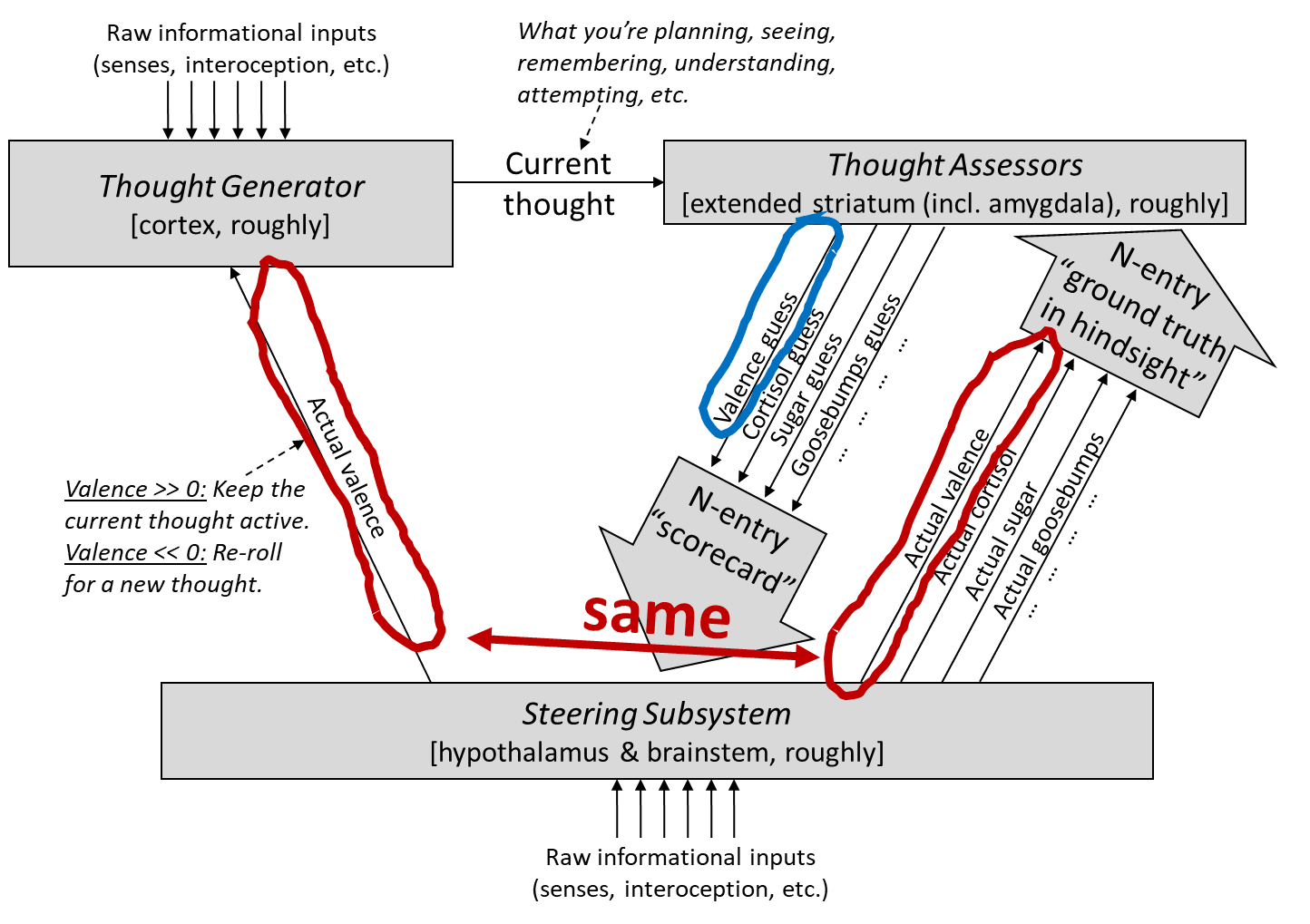
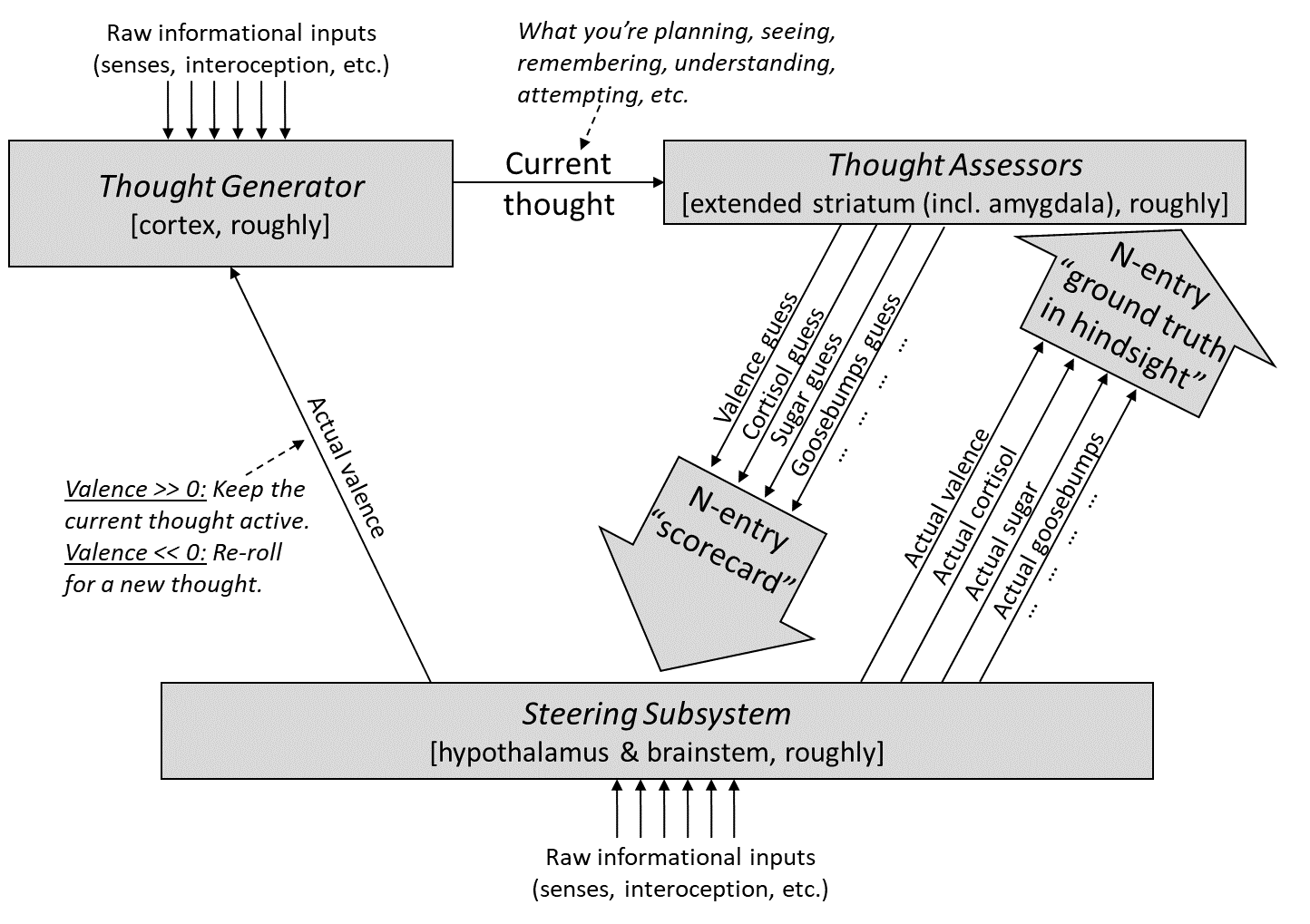
The big picture—The whole post will revolve around this diagram. Note that I’m oversimplifying in various ways, including in the bracketed neuroanatomy labels.
There’s a lot here, but don’t worry, I’ll walk through it bit by bit.
6.2.1 Relation to “two subsystems”
Here’s how this diagram fits in with my “two subsystems” perspective, first discussed in Post #3:
Same as above, but the two subsystems are highlighted in different colors.
6.2.2 Quick run-through
Before getting bogged down in details later in the post, I’ll just talk through the diagram:
1. Thought Generator generates a thought: The Thought Generator settles on a “thought”, out of the high-dimensional space of every thought you can possibly think at that moment. Note that this space of possibilities, while vast, is constrained by current sensory input, past sensory input, and everything else in your learned world-model. For example, if you’re sitting at a desk in Boston, it’s generally not possible for you to think that you’re scuba-diving off the coast of Madagascar. Likewise, it’s generally not possible for you to imagine a static spinning spherical octagon. But you can make a plan, or whistle a tune, or recall a memory, or reflect on the meaning of life, etc.
2. Thought Assessors grade the thought via a “scorecard”: The Thought Assessors are a set of perhaps hundreds or thousands of “short-term predictor” circuits (Post #4), which I discussed more specifically in the previous post (#5). Each predictor is trained to predict a different signal from the Steering Subsystem. From the perspective of a Thought Assessor, everything in the Thought Generator (not just outputs but also latent variables) is context (§4.3)—information that they can use to make better predictions. Thus, if I’m thinking the thought “I’m going to eat candy right now”, a thought-assessor can predict “high probability of tasting something sweet very soon”, based purely on the thought—it doesn’t need to rely on either external behavior or sensory inputs, although those can be relevant context too.
3. The “scorecard” solves the interface problem between a learned-from-scratch world model and genetically-hardwired circuitry: Remember, the current thought and situation is an insanely complicated object in a high-dimensional learned-from-scratch space of “all possible thoughts you can think”. Yet we need the relatively simple, genetically-hardwired circuitry of the Steering Subsystem to analyze the current thought, including issuing a judgment of whether the thought is overall good vs bad (see §6.4 below), and whether the thought calls for cortisol release or goosebumps or pupil-dilation, etc. The “scorecard” solves that interfacing problem! It distills any possible thought / belief / plan / etc. into a genetically-standardized form that can be plugged directly into genetically-hardcoded circuitry.
4. The Steering Subsystem runs some genetically-hardwired algorithm: Its inputs are (1) the scorecard from the previous step and (2) various other information sources—pain, metabolic status, etc., all coming from its own brainstem sensory-processing system (see §3.2.1). Its outputs include emitting hormones, motor commands, etc., as well as sending the “ground truth” supervisory signals shown in the diagram.[2]
5. The Thought Generator keeps or discards thoughts based on whether the Steering Subsystem likes them: More specifically, there’s a ground-truth valence (or in RL terms, some weird mixture of value function and reward function, see §5.3.2.1). When the valence is very positive, the current thought gets “strengthened”, sticks around, and can start controlling behavior and summoning follow-up thoughts, whereas when the valence is very negative, the current thought gets immediately discarded, and the Thought Generator summons a new thought instead.
6. Both the Thought Generator and the Thought Assessor “learn from scratch” over the course of a lifetime, thanks in part to these supervisory signals from the Steering Subsystem. Specifically, the Thought Assessors learn to make better and better predictions of their “ground truth in hindsight” signal (a form of Supervised Learning—see Post #4), while the Thought Generator learns to generate maximally “good” (positive-valence) thoughts. (The Thought Generator learning-from-scratch process also involves predictive learning of sensory inputs—§4.7.)
6.3 The “Thought Generator”
6.3.1 Overview
Go back to the big-picture diagram at the top. At the top-left, we find the Thought Generator. In terms of actor-critic model-based RL, the Thought Generator is roughly a combination of “actor” + “model”, but not “critic”. (“Critic” was discussed in the previous post, and more on it below.)
At our somewhat-oversimplified level of analysis, we can think of the “thoughts” generated by the Thought Generator as a combination of constraints (from predictive learning of sensory inputs) and choices (guided by reinforcement learning). In more detail:
Constraints on the Thought Generator come from sensory input information, and ultimately from predictive learning of sensory inputs (§4.7). For example, I cannot think the thought: There is a cat on my desk and I’m looking at it right now. There is no such cat, alas, and I can’t just will myself to see something that obviously isn’t there. I can imagine seeing it, but that’s not the same thought. Likewise, I can’t imagine a static spinning spherical octagon, because that’s not allowed by my generative world-model—those concepts are self-contradictory. Yet another source of constraints on the Thought Generator is what I call “involuntary attention”—like how if you’re very itchy, it’s hard to think about anything else (see table in Valence series §3.3.5 (2023)).
But within those constraints, there’s more than one possible thought my brain can think at any given time. It can call up a memory, it can ponder the meaning of life, it can zone out, it can issue a command to stand up, etc. I claim that these “choices” are decided by a reinforcement learning (RL) system. This RL system is one of the main topics of this post.
6.3.2 Thought Generator inputs
The Thought Generator has a number of inputs, including sensory inputs, hyperparameter-shifting neuromodulators, and control signals like valence, which (per §5.3) is the brain’s all-things-considered estimate of whether a thought is good versus bad. The valence signal has a special superpower: if a thought seems bad, it will toss it out, so the cortex can re-roll[3] for a new, different thought instead:
6.3.3 Thought Generator outputs
There are meanwhile a lot of signals going out of the Thought Generator. Some are what we intuitively think of as “outputs”—e.g., skeletal motor commands. Other outgoing signals are, well, a bit funny…
Recall the idea of “context” from §4.3: The Thought Assessors are short-term predictors, and a short-term predictor can in principle grab any signal in the brain and leverage it to improve its ability to predict its target signal. So if the Thought Generator has a world-model, then somewhere in the world-model is a configuration of latent variable activations that encode the concept “baby kittens shivering in the cold rain”. We wouldn’t normally think of those as “output signals”—I just said in the last sentence that they’re latent variables! But as it happens, the “will lead to crying” Thought Assessor has grabbed a copy of those latent variables to use as context signals, and gradually learned through experience that these particular signals are strong predictors of me crying.
Now, as an adult, these “baby kittens in the cold rain” neurons in my Thought Generator are living a double-life:
They are latent variables in my world-model—i.e., they and their web of connections will help me parse an image of baby kittens in the rain, if I see one, and to reason about what would happen to them, etc.
Activating these neurons, e.g. via imagination, is a way for me to call up tears on command.
The Thought Generator (top left) has two types of outputs: the “traditional” outputs associated with voluntary behavior (green arrows) and the “funny” outputs wherein even latent variables in the model can directly impact involuntary behaviors (blue arrows).
6.4 More on how this connects to reinforcement learning
6.4.1 In what sense is this “model-based RL”?
I like to use the term “model-based RL” in a very minimal and literal sense. There’s a model, in that we can make predictions about the world and ourselves: “If I jump in the lake, then I’ll get wet”. There’s reinforcement learning, in the original psychology sense, the sense of “Thorndike’s Law of Effect” (1898): If a kid touches a hot stove, then he probably won’t do it again. The RL and the model are interconnected: the kid will explicitly think of touching the hot stove as a bad thing, and he will try, using his model of the world, to avoid doing so.
So according to this minimal, literal definition, the brain clearly does model-based RL.
Here’s another way to say the same thing: “model-based RL” means “maximizing an objective via a combination of RL and search”. When you maximize an objective via RL, you’re going out and actually doing stuff in the environment, and learning from trial-and-error (a.k.a. explore-exploit). When you maximize an objective via model-based search (a.k.a. planning), you’re taking advantage of knowledge you already have to make better decisions.
Again, in this minimal sense, the human brain clearly does model-based RL, because it uses both RL and search. The RL part turns innate drives (e.g. hunger drive) into explicit desires (e.g. “I want to go to McDonald’s for lunch”), and the search part (a.k.a. planning and brainstorming) then turns explicit desires into appropriate motor actions (e.g. walking to the bus). This is somewhat analogous to a normal AI setup where TD learning transfers information from a reward function to a value function, and then model-based search and planning transfers information from the value function to specific actions. (However, in the brain, the boundary between the RL part and the search part is unusually complex and nuanced—recall the discussion of “Valence and ground-truth-iness” in §5.3.2.1.)
If we instead use terms like “RL”, “model-based”, and “actor critic” to refer narrowly to the specific frameworks and assumptions that you might find in today’s RL textbooks, then I think brain algorithms are sufficiently weird that they probably wouldn’t qualify as any of those. For example, RL textbooks often assume a Markov Decision Process (or related), wherein rewards by definition depend only on states and actions; by contrast, rewards in the brain also depends on what the animal is thinking (§10.2.3).
6.4.2 The striatum (“learned value function” / “critic”) guesses the valence, but the Steering Subsystem may choose to override
There are two types of “valence” in the diagram (it looks like three, but the two red ones are the same):
Two types of “valence” in my model—“real” and “guessed”
The blue-circled signal is the valence guess from the corresponding Thought Assessor in the striatum. The red-circled signal (again, it’s one signal drawn twice) is the corresponding “ground truth” for what the valence guess should have been.
Just like the other “long-term predictors” discussed in the previous post, the long-term predictor for valence has a “defer-to-predictor mode” and an “override mode”, and the Steering Subsystem can dynamically switch between these modes. In defer-to-predictor mode, it sets the red equal to the blue, as if to say “OK, Thought Assessor, sure, I’ll take your word for it”. In override mode, it ignores the Thought Assessor’s proposal, and its own internal circuitry outputs some different value.[4]
Why might the Steering Subsystem override the Thought Assessor’s valence guess? Two factors:
First, the Steering Subsystem might be acting on information from other (non-valence) Thought Assessors. For example, in the so-called “Dead Sea Salt Experiment” (see §2.1 of my 2024 post on that), the valence guess says “bad things are going to happen”, but meanwhile the Steering Subsystem is getting an “I’m about to taste salt” prediction in the context of a state of salt-deprivation. So the Steering Subsystem says to itself “Whatever is happening now is very promising; the valence guess is nonsense!”
Second, the Steering Subsystem might be acting on its own information sources, independent of the Learning Subsystem. In particular, the Steering Subsystem has its own sensory-processing system (see §3.2.1), which can sense biologically-relevant cues like pain status, hunger status, taste inputs, the sight of a slithering snake, the smell of a potential mate, and so on. All these things and more can be possible bases for overruling the Thought Assessor, i.e., setting the red-circled signal to a different value than the blue-circled one.
6.5 Decisions involve not only simultaneous but also sequential comparisons of value
Here’s a “simultaneous” model of decision-making, as described by The Hungry Brain by Stephan Guyenet in the context of studies on lamprey fish:
Each region of the pallium [= lamprey equivalent of cortex] sends a connection to a particular region of the striatum, which (via other parts of the basal ganglia) returns a connection back to the same starting location in the pallium. This means that each region of the pallium is reciprocally connected with the striatum via a specific loop that regulates a particular action…. For example, there’s a loop for tracking prey, a loop for fleeing predators, a loop for anchoring to a rock, and so on. Each region of the pallium is constantly whispering to the striatum to let it trigger its behavior, and the striatum always says “no!” by default. In the appropriate situation, the region’s whisper becomes a shout, and the striatum allows it to use the muscles to execute its action.
I endorse this as part of my model of decision-making, but only part of it. Specifically, this is one of the things that’s happening when the Thought Generator generates a thought. Different simultaneous possibilities are being compared.
The other part of my model is comparisons of sequential thoughts. You think a thought, and then you think a different thought (possibly very different, or possibly a refinement of the first thought), and the two are implicitly compared, and if the second thought is worse, it gets weakened such that a new thought can replace it (and the new thought might be the first thought re-establishing itself).
I could cite experiments for the sequential-comparison aspect of decision-making (e.g. Figure 5 of Herd et al. 2021, which is arguing the same point as I am), but do I really need to? Introspectively, it’s obvious! You think: “Hmm, I think I’ll go to the gym. Actually, what if I went to the café instead?” You’re imagining one thing, and then another thing.
And I don’t think this is is a humans-vs-lampreys thing. I think comparison-of-sequential-thoughts is universal in vertebrates. As an illustration of what I mean:
6.5.1 Made-up example of what comparison-of-sequential-thoughts might look like in a simpler animal
Imagine a simple, ancient, little fish swimming along, navigating to the cave where it lives. It gets to a fork in the road kelp forest. Its current thought is something like “I am swimming left to my cave”. But it also has the option of turning right to go to the reef, where it often forages.
Seeing this path to the right, I claim that a new thought pops into its head: “I am swimming right and going to the reef.” This new thought / plan is immediately evaluated by the Thought Assessors and Steering Subsystem as usual, and winds up with some valence (implicitly in comparison to the old plan). If this new thought seems bad, then it gets thrown out, and the old thought (“I am swimming left to my cave”) promptly pops back into its head. The fish continues to its cave, as originally planned, without skipping a beat. (Except maybe, if you look carefully, you could notice the fish subtly twitch to the right for a fraction of a second.) Whereas if instead the new thought seems good (i.e., better than the old thought), then it gets strengthened, sticks around, and orchestrates motor commands. And thus the fish turns to the right and goes to the reef instead.
(In reality, I don’t know much about ancient fish, but rats at a fork in the road maze are known to imagine both possible navigation plans in succession, based on measurements of hippocampus neurons—Johnson & Redish 2007.)
In my view, thoughts are complicated. To think the thought “I will go to the café”, you’re not just activating some tiny cluster of dedicated go-to-the-café neurons. Instead, it’s a distributed pattern involving practically every part of the cortex. You can’t simultaneously think “I will go to the café” and “I will go to the gym”, because they would involve different activity patterns of the same pools of neurons. They would cross-talk. Thus, the only possibility is thinking the thoughts in sequence.
As a concrete example of what I have in mind, think of how a Hopfield network can’t recall twelve different memories simultaneously. It has multiple stable states, but you can only explore them sequentially, one after the other. Or think about grid cells and place cells, etc.
6.5.3 Comparison-of-sequential-thoughts: how it might have evolved
From an evolutionary perspective, I imagine that comparison-of-sequential-thoughts is a distant descendent of a very simple mechanism akin to the run-and-tumble mechanism in swimming bacteria.
In the run-and-tumble mechanism, a bacterium swims in a straight line (“runs”), and periodically changes to a new random direction (“tumbles”). But the trick is: when the bacterium’s situation / environment is getting better, it tumbles less frequently, and when it’s getting worse, it tumbles more frequently. Thus, it winds up moving in a good direction (on average, over time).
Starting with a simple mechanism like that, one can imagine adding progressively more bells and whistles. The palette of behavioral options can get more and more complex, eventually culminating in “every thought you can possibly think”. The methods of evaluating whether the current plan is good or bad can get faster and more accurate, eventually involving learning-algorithm-based predictors as in the previous post. The new behavioral options to tumble into can be picked via clever learning algorithms, rather than randomly. Thus, it seems to me that there’s a smooth path all the way from something-akin-to-run-and-tumble to the intricate, finely-tuned, human brain system that I’m talking about in this series. (Other discussions of run-and-tumble versus human motivation: Karin & Alon 2022, Travis 2022.)
6.6 Common misconceptions
6.6.1 The distinction between internalized ego-syntonic desires and externalized ego-dystonic urges is unrelated to Learning Subsystem vs. Steering Subsystem
Many people (including me) have a strong intuitive distinction between ego-syntonic drives that are “part of us” or “what we want”, versus ego-dystonic drives that feel like urges which intrude upon us from the outside.
For example, if someone is on a hunger strike for freedom, they might say that their desire to eat comes from their innate drives, whereas their desire to fight for freedom comes from “reason”, or “their best self”, or whatever. What does that mean? What’s going on?
6.6.1.1 The explanation I like
I propose that we should not take this intuition at face value. In reality, the hunger-striker’s desire to eat comes ultimately from their innate drives, and their desire to fight for freedom also comes ultimately from their innate drives! These are just two innate drives that are pointing in different directions, and thus they duke it out. One side will win, and then the person will either keep their hunger strike, or break down and eat.
It’s not so different from if you feel simultaneously very sleepy and very hungry; you can’t satisfy both drives, so the drives will duke it out, and one of them will win, and either you’ll nap despite your hunger, or you’ll eat despite your sleepiness.
That said, there do seem to be very important differences between the mundane hunger-vs-sleepiness battle (urge vs urge) and the hunger-vs-fight-for-freedom battle (urge vs ego-syntonic desire). In particular, here are three obvious questions that I need to address:
First, hunger and sleep drives are easy to understand. But it’s much less obvious how innate drives could lead a person to care so much about freedom that they’ll go on a hunger strike. What exactly is the innate drive in question?
Second, if I’m both hungry and sleepy, it’s sorta “a fair fight”. Probably whichever feeling is more immediately powerful will win. By contrast, the internal battle between the hunger-striker’s desire for freedom and their desire for food is not a fair fight. The former desire will punch above its weight by bringing far more intelligence and foresight to bear towards its objective. Thus, if the person is setting up a commitment mechanism, or tying their own hands, or attempting to control themselves and their mood, those actions will almost definitely be in pursuit of freedom, not in pursuit of hunger-satisfaction. Why the asymmetry? If both drives are in the Steering Subsystem, shouldn’t they be equally stupid and myopic? Relatedly, if the person is “applying willpower”, why is it in support of freedom rather than hunger-satisfaction? And by the way, what the heck does “applying willpower” even mean at a nuts-and-bolts level??
Third, if the person’s desire for freedom is not really more a “part of them” than their desire to eat when hungry, then … why does it feel that way to them? In other words, this is an honest introspective report. I’m allowed to claim that the report should be interpreted as a perceptual illusion rather than taken at face value, but you have no reason to believe me unless I can also explain what exactly they were introspecting upon, and what they saw when they did so, and why it left them with the impression that it did.
These are all great questions! And I have answers to all of them! But they’re rather involved.
For the second question, my short answer is that people have a strong, salient association between thoughts of themselves, and thoughts of how they would look in someone else’s eyes. The former thoughts are required for strategically tying one’s hands, making precommitments, etc. And the latter thoughts summon social instincts like pride. This is the source of the asymmetry where social instincts “punch above their weight” in the context of intelligent self-reflective plans, such as precommitments, describing one’s life aspirations, and so on. For more detail (along with how “willpower” fits in), see §8.5.5–§8.5.6 of my “Intuitive Self-Models” series (2024), but be warned that it might not make sense without reading the earlier posts in that Intuitive Self-Models series, in which I try to unravel a bunch of misleading intuitions in how we think about our own minds.
The third question (on why and how ego-syntonic desires are “internalized”) is also addressed in that same series, see “Intuitive Self Models” §3.5.4.
6.6.1.2 The explanation I don’t like
Many people (including Jeff Hawkins, see Post #3) notice the distinction described above, and separately, they endorse the idea (as I do) that the brain has a Learning Subsystem and Steering Subsystem (again see Post #3). They naturally suppose that these are the same thing, with “me and my deep desires” corresponding to the Learning Subsystem, and “urges that I don’t identify with” corresponding to the Steering Subsystem.
Most people I talk to, including me, have separate concepts in our learned world-models for “me” and “my urges”. I claim that these concepts did NOT come out of veridical introspective access to our own neuroanatomy. And in particular, they do not correspond respectively to the Learning & Steering Subsystems.
I think this model is wrong. At the very least, if you want to endorse this model, then you need to reject approximately everything I’ve written in this and my previous four posts.
One way to put it is: why does the hunger-striker care about freedom, and not about, I dunno, ironing the wrinkles out of dollar bills? There has to be some explanation, right? And if you reply “it’s because freedom leads to (blah)”, then I’ll just reply, “OK, and why do they care about (blah), rather than, I dunno, measuring the distance between pebbles on the sidewalk?” We can go back and forth forever. The answer is: at the end of the day, something has to just plain feel intuitively good or bad. And that feeling has to come from an innate drive, one way or another.
Here are three more views on why we should believe that the Steering Subsystem is the ultimate source of not only ego-dystonic urges like hunger, but also ego-syntonic desires like friendship and justice.
AI perspective: We don’t yet know in full detail how model-based RL and model-based planning works in the human brain—we don’t have brain-like AGI yet. But we do at least vaguely know how these kinds of algorithms work. And we know enough to say for sure that these algorithms don’t develop prosocial motivations out of nowhere. For example, if you set the reward function of MuZero to always return 0, then the algorithm will emit random outputs forever—it won’t start fighting for justice.
Rodent model perspective: For what it’s worth, researchers have been equally successful in finding little cell groups in the rodent hypothalamus that orchestrate “antisocial” behaviors like aggression, and that orchestrate “prosocial” behaviors like parenting and sociality. I fully expect that the same holds for humans.
Philosophy perspective: Without the Steering Subsystem, the only thing the cortex can do is build a world-model from predictive learning of sensory inputs (§4.7). That’s “is”, not “ought”. And “Hume’s law” says that you can’t get “ought”-statements from exclusively “is”-statements. Granted, not everyone believes in Hume’s law. But I do—see an elegant and concise argument for it here.
6.6.2 The Learning Subsystem and Steering Subsystem are not two agents
Relatedly, another frequent error is treating either the Learning Subsystem or Steering Subsystem by itself as a kind of independent agent. This is wrong on both sides:
The Learning Subsystem cannot think any thoughts unless the Steering Subsystem has endorsed those thoughts as being worthy of being thunk.
Meanwhile, the Steering Subsystem does not understand the world, or itself. It has no explicit goals for the future. It’s just a relatively simple, hardcoded input-output machine.
As an example, the following is entirely possible:
The Learning Subsystem generates the thought “I am going to surgically alter my own Steering Subsystem”.
The Thought Assessors distill that thought down to the “scorecard”.
The Steering Subsystem gets the scorecard and runs it through its hardcoded heuristics, and the result is: “Very good thought, go right ahead and do it!”
Why not, right? I’ll talk more about that example in later posts.
If you just read the above example, and you’re thinking to yourself “Ah! This is a case where the Learning Subsystem has outwitted the Steering Subsystem”, then you’re still not getting it. Maybe instead try imagining the Learning Subsystem & Steering Subsystem as two interconnected gears in a single machine.
Changelog
July 2024: Since the initial version, I made a bunch of changes.
As in the previous post changelog, I’ve iterated on the “big picture” neuroscience diagrams several times since the initial version, as I learned more neuroscience.
For clarity, what I formerly labeled “Ground-truth value, a.k.a. reward” is now “Actual valence”, with a little note in the diagram about what this signal does. Relatedly, I added a bunch of links throughout this post to my more recent Valence series, including a very brief teaser / recap of it in §6.4.1. And along the same lines, I reworded the RL discussions to use the word “reward” less and “valence” more. The word “reward” is not wrong, exactly, but it has a lot of baggage which I expect to confuse readers, as explained in the previous post and §6.4.1.
I deleted a claim that (what I am now calling) the “valence guess” signal “doesn’t have a special role in the algorithm”. I still think the thing I was trying to say is true, but the thing I was trying to say was pretty narrow and subtle, and on balance I expect that what I wrote is far more confusing than helpful. I actually think the valence guess is centrally important, especially in long-term planning, as discussed here.
I also put in the example of a “static spinning spherical octagon” to illustrate of how the “constraints” in the Thought Generator are not just sensory inputs but also our semantic knowledge about how the world works. I also mentioned “involuntary attention” (e.g. itching or anxious rumination) as yet another source of “constraints”.
I deleted some discussion of neuroanatomy (there used to be a §6.3.4), including cortico-basal ganglia thalamo-cortical loops and dopamine, because what I had written was mostly wrong, and unnecessary for the series anyway. What little I want to say on those topics mostly wound up in the previous post.
October 2025: Since first writing this, I have somewhat updated how I think about ego-syntonic versus ego-dystonic desires. So I changed some wording in §6.6.1.1, and added a link to my more recent discussion of that topic.
January 2026: More rewriting and additions to §6.6.1, plus minor copyedits throughout.
June 2026: Rewrote §6.6.1 yet again. Moved “Teaser for my ‘Valence’ series” from §6.4.1 to §5.3.3. Added a new §6.4.1 on the term “model-based RL”.
The term “ground truth” here is a bit misleading, because sometimes the Steering Subsystem will just defer to the Thought Assessors, as explained in the previous post.
“Re-roll” was originally a board game term; for example, if you previously rolled the dice to randomly generate a character, then “re-roll for a new character” would mean “you roll the dice again to randomly generate a different character”.
As in the previous post, I don’t really believe there is a pure dichotomy between “defer-to-predictor mode” and “override mode”. In reality, I’d bet that the Steering Subsystem can partly-but-not-entirely defer to the Thought Assessor, e.g. by taking a weighted average between the Thought Assessor and some other independent calculation.
Two types of “valence” in my model—“real” and “guessed”
The blue-circled signal is the valence guess from the corresponding Thought Assessor in the striatum. The red-circled signal (again, it’s one signal drawn twice) is the corresponding “ground truth” for what the valence guess should have been.
Just like the other “long-term predictors” discussed in the previous post, the Steering Subsystem can choose between “defer-to-predictor mode” and “override mode”. In the former, it sets the red equal to the blue, as if to say “OK, Thought Assessor, sure, I’ll take your word for it”. In the latter, it ignores the Thought Assessor’s proposal, and its own internal circuitry outputs some different value.[3]
Just to be clear, these paragraphs mean that the arrows labeled "Actual valence" are often just a duplicate of the "Valence guess", specifically when the steering system is in "defer-to-predictor" mode. When in that mode, the Steering Subsystem doesn't add any informational content that directs the thought generator, right?
In "defer-to-predictor" mode, all of the informational content that directs thought rerolls is coming from the thought assessors in the Learned-from-Scratch part of the brain, even if if that information is neurologically routed through the steering subsystem?
[Edit: Or is "Actual valence" never just defering to the predictor, because it's calculated based on the whole scorecard?]
[Edit2: In this post, you say "And I’ll also assume the Steering Subsystem is in defer-to-predictor mode for the valence signal, rather than override mode (see Post #6, §6.4.2).", so I guess not.]
You might (or might not) have missed that we can simultaneously be in defer-to-predictor mode for valence, override mode for goosebumps, defer-to-predictor mode for physiological arousal, etc. It’s not all-or-nothing. (I just edited the text you quoted to make that clearer.)
In "defer-to-predictor" mode, all of the informational content that directs thought rerolls is coming from the thought assessors in the Learned-from-Scratch part of the brain, even if if that information is neurologically routed through the steering subsystem?
To within the limitations of the model I’m putting forward here (which sweeps a bit of complexity under the rug), basically yes.
I want to get more clarity on what you mean by a "thought", and which processing you're claiming are thoughts, and which are non-thought operations that select the next thought to think. And (if this question carves reality at the joints) which you think is conscious processing and which you think isn't.
(I want to be clear that I'm referring to your concept of "thought" here. We might replace "thought" with "thought_Byrne".)
Sequential "thoughts"?
It sounds like, you're using the word "thought" to refer specifically to the cognitive content that is occupying the limited capacity of the "global workspace" (or something like a global workspace). Thoughts utilize the whole cortex, so you can't have more than one at once, so they're necessarily sequential. They're like CPU-operations.
In my view, thoughts are complicated. To think the thought “I will go to the café”, you’re not just activating some tiny cluster of dedicated go-to-the-café neurons. Instead, it’s a distributed pattern involving practically every part of the cortex. You can’t simultaneously think “I will go to the café” and “I will go to the gym”, because they would involve different activity patterns of the same pools of neurons. They would cross-talk. Thus, the only possibility is thinking the thoughts in sequence.
Are "thoughts" always conscious (ie available to verbal reports)?
Is everything that's available to verbal report a thought?
Or does it become a "thought" in the process of attending to it to produce a verbal report? (eg I'm conscious of various elements of my visual field, (the black border around my macbook screen, or the open door behind my screen), but they only become "thoughts" when I start to pay attention to them, which is necessary for making verbal reports about them?
Parallel proto-thoughts?
But it also sounds like you're also saying that there can be a plethora of competing urges, or proto-thoughts, or something, all vying to be anointed as the next thought. (Feel free to suggest better terminology for these, if you have it.)
Each region of the pallium [= lamprey equivalent of cortex] sends a connection to a particular region of the striatum, which (via other parts of the basal ganglia) returns a connection back to the same starting location in the pallium. This means that each region of the pallium is reciprocally connected with the striatum via a specific loop that regulates a particular action…. For example, there’s a loop for tracking prey, a loop for fleeing predators, a loop for anchoring to a rock, and so on. Each region of the pallium is constantly whispering to the striatum to let it trigger its behavior, and the striatum always says “no!” by default. In the appropriate situation, the region’s whisper becomes a shout, and the striatum allows it to use the muscles to execute its action.
I endorse this as part of my model of decision-making, but only part of it. Specifically, this is one of the things that’s happening when the Thought Generator generates a thought. Different simultaneous possibilities are being compared.
Am I correct in calling these examples of "proto-thoughts" and not of "thoughts" (at least until they graduate to "thoughts")?
Is there a reason why these "proto-thoughts" don't have the problem cited above, that force "thoughts" to be sequential? Are proto-thoughts of a different type than "thoughts" such that they don't draw on neurons all over the brain? If not, why can proto-thoughts all be active simultaneously, but "thoughts" can't be?
Additionally, is the implication that these proto-thoughts are necessarily subconscious / pre-conscious? (Because if you were conscious of them, they would (definitionally?) have graduated to being "thoughts"?)
Thoughts or proto-thoughts?
In this example...
Imagine a simple, ancient, little fish swimming along, navigating to the cave where it lives. It gets to a fork in the road, ummm, “fork in the kelp forest”? Its current navigation plan involves continuing left to its cave, but it also has the option of turning right to go to the reef, where it often forages.
Seeing this path to the right, I claim that its navigation algorithm reflexively loads up a plan: “I’m gonna turn right and go to the reef.” Immediately, this new plan is evaluated and compared to the old plan. If the new plan seems worse than the old plan, then the new thought gets shut down, and the old thought (“I’m going to my cave”) promptly reestablishes itself. The fish continues to its cave, as originally planned, without skipping a beat. Whereas if instead the new plan seems better than the old plan, then the new plan gets strengthened, sticks around, and orchestrates motor commands. And thus the fish turns to the right and goes to the reef instead.
...do I understand correctly that all of the activity described is of proto-thoughts? You're not talking about what the fish is thinking, you're talking about what's happening under the hood that causes the fish to think the thoughts that it thinks.
Like, I could tell a story:
A fish that was swimming towards the cave where it lives. But on the way it had the thought "maybe I should go to the reef instead". It considered that plan, and then decided against, continuing on it's way to it's cave.
If I understand correctly, that isn't the story you're telling. Rather you're trying to explain the mechanisms that causes the fish to "promote 'the possibility of going to the reef' to attention" in the first place.
Is that right?
(This might turn out to be a silly question in the case of the fish, because maybe fish don't do the mental operation of "considering", the fish brain just selects motor plans directly. But humans definitely do an operation of "considering", which entails some non-thinking mechanism that selects the next thought to think.)
The black border around your macbook screen would be represented in some tiny subset of the cortex before you pay attention to it, and in a much larger subset of the cortex after you pay attention to it. In the before state (when it’s affecting a tiny subset of the cortex), I still want to declare it part of the “thought”, in the sense relevant to this post, i.e. (1) those bits of the cortex are still potentially providing context signals for the amygdala, striatum, etc., and (2) those bits are still interconnected with and compatible with what’s happening elsewhere in the cortex. If that tiny subset of the cortex doesn’t directly connect to the hippocampus (which it probably doesn’t), then it won’t directly impact your episodic memory afterwards, although it still has an indirect impact via needing to be compatible with the other parts of the cortex that connects to (i.e., if the border had been different than usual, you would have noticed something wrong).
If we think in terms of attractor dynamics (as in Hopfield nets, Boltzmann machines, etc.), then I guess your proposal in this comment corresponds to the definitions: “thought” = “stable attractor state”, and “proto-thought” = “weak disjointed activity that’s bubbling up and might (or might not) eventually develop into a new stable attractor state.
Whereas the purpose of this series, I’m just using the simpler “thought” = “whatever the cortex is doing”. And “whatever the cortex is doing” might be (at some moment) 95% stable attractor + 5% weak disjointed activity, or whatever.
Is there a reason why these "proto-thoughts" don't have the problem cited above, that force "thoughts" to be sequential?
Weak disjointed activity can be hyper-local to some tiny part of the cortex, and then it might or might not impact other areas and gradually (i.e. over the course of 0.1 seconds or whatever) spread into a new stable attractor for a large fraction of the cortex, by outcompeting the stable attractor which was there before.
(I’m exaggerating a bit for clarity; the ability of some local pool of neurons to explore multiple possibilities simultaneously is more than zero, but I really don’t think it gets very far at all before there has to be a “winner”.)
…fish…
No, I was trying to describe sequential thoughts. First the fish has Thought A (well-established, stable attractor, global workspace) “I’m going left to my cave”, then for maybe a quarter of a second it has Thought B (well-established, stable attractor, global workspace) “I’m going right to the reef”, then it switches back to Thought A. I was not attempting to explain why those thoughts appeared rather than other possible thoughts, rather I was emphasizing the fact that these are two different thoughts, and that Thought B got discarded because it seemed bad.
I just reworded that section, hopefully that will help future readers, thanks.
Really appreciated this post and I'm especially excited for post 13 now! In the past month or two, I've been thinking about stuff like "I crave chocolate" and "I should abstain from eating chocolate" as being a result of two independent value systems (one whose policy was shaped by evolutionary pressure and one whose policy is... idk vaguely "higher order" stuff where you will endure higher states of cortisol to contribute to society or something).
I'm starting to lean away from this a little bit, and I think reading this post gave me a good idea of what your thoughts are, but it'd be really nice to get confirmation (and maybe clarification). Let me know if I should just wait for post 13. My prediction is that you believe there is a single (not dual) generator of human values, which are essentially moderated at the neurochemical level, like "level of dopamine/serotonin/cortisol". And yet, this same generator, due to our sufficiently complex "thought generator", can produce plans and thoughts such as "I should abstain from eating chocolate" even though it would be a dopamine hit in the short-term, because it can simulate forward much further down the timeline, and believes that the overall neurochemical feedback will be better than caving into eating chocolate, on a longer time horizon. Is this correct?
If so, do you believe that because social/multi-agent navigation was essential to human evolution, the policy was heavily shaped by social world related pressures, which means that even when you abstain from the chocolate, or endure pain and suffering for a "heroic" act, in the end, this can all still be attributed to the same system/generator that also sometimes has you eat sugary but unhealthy foods?
Given my angle on attempting to contribute to AI Alignment is doing stuff to better elucidate what "human values" even is, I feel like I should try to resolve the competing ideas I've absorbed from LessWrong: 2 distinct value systems vs. singular generator of values. This post was a big step for me in understanding how the latter idea can be coherent with the apparent contradictions between hedonistic and higher-level values.
Right, I think there's one reward function (well, one reward function that's relevant for this discussion), and that for every thought we think, we're thinking it because it's rewarding to do so—or at least, more rewarding than alternative thoughts. Sometimes a thought is rewarding because it involves feeling good now, sometimes it's rewarding because it involves an expectation of feeling good in the distant future, sometimes it's rewarding because it involves an expectation that it will make your beloved friend feel good, sometimes it's rewarding because it involves an expectation that it will make your admired in-group members very impressed with you, etc.
I think that the thing that gets rewarded is thoughts / plans, not just actions / states. So we don't have to assume that the Thought Generator is proposing an action that's unrewarding now (going to the gym) in order to get into a more-rewarding state later on (being ripped). Instead, the Thought Generator can generate one thought right now, “I'm gonna go to the gym so that I can get ripped”. That one thought can be rewarding right now, because the “…so that I can get ripped” is right there in the thought, providing evidence to the brainstem that the thought should be rewarded, and that evidence can plausibly outweigh the countervailing evidence from the “I'm gonna go to the gym…” part of the thought.
I do think there's still an adjustable parameter in the brain related to time-discounting, even if the details are kinda different than in normal RL. But I don't see a strong connection between that and social instincts. For example, if you abstain from ice cream to avoid a stomach ache, that's a time-discounting thing, but it's not a social-instincts thing. It's possible that social animals in general are genetically wired to time-discount less than non-social animals, but I don't have any particular reason to expect that to be the case. Or, maybe humans in particular are genetically wired to time-discount less than other animals, I don't know, but if that's true, I still wouldn't expect that it has to do with humans being social; rather I would assume that it evolved because humans are smarter, and therefore human plans are unusually likely to work out as predicted, compared to other animals.
I think social instincts come from having things in the innate reward function that track “having high status in my in-group” and “being treated fairly” and “getting revenge” and so on. (To a first approximation.) Post #13(ish) will be a (hopefully) improved and updated version of this discussion of how such things might get actually incorporated into the reward function, given the difficulties related to symbol-grounding. You might also be interested in my post (Brainstem, Neocortex) ≠ (Base Motivations, Honorable Motivations).
Hope this helps, happy to talk more, either here or by phone if you think that would help. :)
The big picture—The whole post will revolve around this diagram. Note that I’m oversimplifying in various ways, including in the bracketed neuroanatomy labels.
I think this picture would be clearer if you drew [predict sensory inputs] as a separate box from Though Generator.
In the picture in my head, there is [predict sensory inputs] box, that revives and tries to predict the sensory output. This box also sends a signal of [current context] to both the Though Generator and the Though Assessor. Also, [predict sensory inputs] gets some signal from Though Generator, so that it knows what we're about to do, which is important for what we're about to observe.
I'm guessing there is some reason you didn't draw it this way? We might have talked about this before?
I think “predict sensory input” is the main training signal for the Thought Generator, loosely analogous to how “predict next token” is the training signal for LLM pretraining. (Cf. §4.7.) So “predict sensory inputs” wouldn’t be a separate box from the Thought Generator, but rather a core function of the Thought Generator. Does that help? Sorry if I’m missing your point.
My first reaction to this is "obviously not since the architecture is completely different, so why would they map onto each other?", but a possible answer could be "well if the brain has them as separate modules, it could mean that the two tasks require different solutions, and if one is much harder than the other, and the harder one is the assess module, that could mean language models would naturally solve just the generation first".
The related thing that I find interesting is that, a priori, it's not at all obvious that you'd have these two different modules at all (since the thought generator already receives ground truth feedback). Does this mean the distinction is deeply meaningful? Well, that depends on close to optimal the [design of the human brain] is.
Hmm. An algorithm trained to reproduce human output is presumably being trained to imitate the input-output behavior of the whole system including Thought Generator and Thought Assessor and Steering Subsystem.
I’m trying to imagine deleting the Thought Assessor & Steering Subsystem, and replacing them with a constant positive RPE (i.e., “this is good, keep going”) signal. I think what you get is a person talking with no inhibitions whatsoever. Language models don’t match that.
a priori, it's not at all obvious that you'd have these two different modules at all (since the thought generator already receives ground truth feedback)
I think it’s a necessary design feature for good performance. Think of it this way. I’m evolution. Here are two tasks I want to solve:
(A) estimate how much a particular course-of-action advances inclusive genetic fitness, (B) find courses of action that get a good score according to (A).
(B) obviously benefits from incorporating a learning algorithm. And if you think about it, (A) benefits from incorporating a learning algorithm as well. But the learning algorithms involved in (A) and (B) are fundamentally working at cross-purposes. (A) is the critic, (B) is the actor. They need separate training signals and separate update rules. If you try to blend them together in an end-to-end way, you just get wireheading. (I.e., if the (B) learning algorithm had free reign to update the parameters in (A), using the same update rule as (B), then it would immediately set (A) to return infinity all the time, i.e. wirehead.) (Humans can wirehead to some extent (see Post #9) but we need to explain why it doesn't happen universally and permanently within five minutes of birth.)
I think what you get is a person talking with no inhibitions whatsoever. Language models don’t match that.
What do you picture a language model with no inhibitions to look like? Because if I try to imagine it, then "something that outputs reasonable sounding text until sooner or later it fails hard" seems to be a decent fit. Of course haven't thought much about the generator/assessor distinction.
I mean, surely "inhibitions" of the language model don't map onto human inhibitions, right? Like, a language model without the assessor module (or a much worse assessor module) is just as likely to be imitate someone who sounds unrealistically careful as someone who has no restraints.
I find your last paragraph convincing, but that of course makes me put more credence into the theory rather than less.
An analogy that comes to mind is sociopathy. Closely linked to fear/reward insensitivity and impulsivity. Something you see a lot in case studies of diagnosed or accounts of people who look obviously like sociopaths is that they will be going along just fine, very competent and intelligent seeming, getting away with everything, until they suddenly do something which is just reckless, pointless, useless and no sane person could possibly think they'd get away with it. Why did they do X, which caused the whole house of cards to come tumbling down and is why you are now reading this book or longform investigative piece about them? No reason. They just sorta felt like it. The impulse just came to them. Like jumping off a bridge.
I think that if we replace the Thought Assessor & Steering Subsystem with the function “RPE = +∞ (regardless of what's going on)”, the result is a manic episode, and if we replace it with the function “RPE = -∞ (regardless of what's going on)”, the result is a depressive episode.
In other words, the manic episode would be kinda like the brainstem saying “Whatever thought you're thinking right now is a great thought! Whatever you're planning is an awesome plan! Go forth and carry that plan out with gusto!!!!” And the depressive episode would be kinda like the brainstem saying “Whatever thought you're thinking right now is a terrible thought. Stop thinking that thought! Think about anything else! Heck, think about nothing whatsoever! Please, anything but that thought!”
My thoughts about sociopathy are here. Sociopaths can be impulsive (like everyone), but it doesn't strike me as a central characteristic, as it is in mania. I think there might sometimes be situations where a sociopath does X, and onlookers characterize it as impulsive, but in fact it's just what the sociopath wanted to do, all things considered, stemming from different preferences / different reward function. For example, my impression is that sociopaths get very bored very easily, and will do something that seems crazy and inexplicable from a neurotypical perspective, but seems a good way to alleviate boredom from their own perspective.
(Epistemic status: Very much not an expert on mania or depression, I've just read a couple papers. I've read a larger number of books and papers on sociopathy / psychopathy (which think are synonyms?), plus there were two sociopaths in my life that I got to know reasonably well, unfortunately. More of my comments about depression here.)
Yes, but I didn't mean to ask whether it's relevant, I meant to ask whether it's accurate. Does the output of language models, in fact, feel like this? Seemed like something relevant to ask you since you've seen lots of text completions.
And if it does, what is the reason for not having long timelines? If neural networks only solved the easy part of the problem, that implies that they're a much smaller step toward AGI than many argued recently.
I said it was an analogy. You were discussing what intelligent human-level entities with inhibition control problems would hypothetically look like; well, as it happens, we do have such entities, in the form of sociopaths, and as it happens, they do not simply explode in every direction due to lacking inhibitions but often perform at high levels manipulating other humans until suddenly then they explode. This is proof of concept that you can naturally get such streaky performance without any kind of exotic setup or design. Seems relevant to mention.
(Last revised: June 2026. See changelog at the bottom.)
6.1 Post summary / Table of contents
Part of the “Intro to brain-like-AGI safety” post series.
Thus far in the series, Post #1 set out some definitions and motivations (what is “brain-like AGI safety” and why should we care?), and Posts #2 & #3 split the brain into a Learning Subsystem (cortex, striatum, cerebellum, amygdala, etc.) that “learns from scratch” using learning algorithms, and a Steering Subsystem (hypothalamus, brainstem, etc.) that is mostly genetically-hardwired and executes innate species-specific instincts and reactions.
Then in Post #4, I talked about the “short-term predictor”, a circuit which learns, via supervised learning, to predict a signal in advance of its arrival, but only by perhaps a fraction of a second. Post #5 then argued that if we form a closed loop involving both a set of short-term predictors in the extended striatum (within the Learning Subsystem) and a corresponding set of hardwired circuits in the Steering Subsystem, we can get a “long-term predictor”. I noted that the “long-term predictor” circuit is closely related to temporal difference (TD) learning.
Now in this post, we fill in the last ingredients—roughly the “actor” part of actor-critic reinforcement learning (RL)—to get a whole big picture of motivation and decision-making in the human brain. (I’m saying “human brain” to be specific, but it would be a similar story in any other mammal, and to a lesser extent in any vertebrate.)
The reason I care about motivation and decision-making is that if we eventually build brain-like AGIs (cf. Post #1), we’ll want to build them so that they have some motivations (e.g. being helpful) and not others (e.g. escaping human control and self-reproducing around the internet). Much more on that topic in later posts.
Teaser for upcoming posts: The next post (#7) will walk through a concrete example of the model in this post, where we can watch an innate drive lead to the formation of an explicit goal, and adoption and execution of a plan to accomplish it. Then starting in Post #8 we’ll switch gears, and from then on you can expect substantially less discussion of neuroscience and more discussion of AGI safety (with the exception of one more neuroscience post towards the end).
Unless otherwise mentioned, everything in this post is “things that I believe right now”, as opposed to neuroscience consensus. (Pro tip: there is never a neuroscience consensus.) Relatedly, I will make minimal effort to connect my hypotheses to others in the literature (I tried a little bit in the last section of my post “Incentive Learning vs Dead Sea Salt Experiment” (2024)), but I’m happy to chat about that in the comments section or by email.
Table of contents:
6.2 Big picture
Yes, this is literally a big picture, unless you’re reading on your cell phone. You saw a chunk of it in the previous post (§5.4), but now there are a few more pieces.
There’s a lot here, but don’t worry, I’ll walk through it bit by bit.
6.2.1 Relation to “two subsystems”
Here’s how this diagram fits in with my “two subsystems” perspective, first discussed in Post #3:
6.2.2 Quick run-through
Before getting bogged down in details later in the post, I’ll just talk through the diagram:
1. Thought Generator generates a thought: The Thought Generator settles on a “thought”, out of the high-dimensional space of every thought you can possibly think at that moment. Note that this space of possibilities, while vast, is constrained by current sensory input, past sensory input, and everything else in your learned world-model. For example, if you’re sitting at a desk in Boston, it’s generally not possible for you to think that you’re scuba-diving off the coast of Madagascar. Likewise, it’s generally not possible for you to imagine a static spinning spherical octagon. But you can make a plan, or whistle a tune, or recall a memory, or reflect on the meaning of life, etc.
2. Thought Assessors grade the thought via a “scorecard”: The Thought Assessors are a set of perhaps hundreds or thousands of “short-term predictor” circuits (Post #4), which I discussed more specifically in the previous post (#5). Each predictor is trained to predict a different signal from the Steering Subsystem. From the perspective of a Thought Assessor, everything in the Thought Generator (not just outputs but also latent variables) is context (§4.3)—information that they can use to make better predictions. Thus, if I’m thinking the thought “I’m going to eat candy right now”, a thought-assessor can predict “high probability of tasting something sweet very soon”, based purely on the thought—it doesn’t need to rely on either external behavior or sensory inputs, although those can be relevant context too.
3. The “scorecard” solves the interface problem between a learned-from-scratch world model and genetically-hardwired circuitry: Remember, the current thought and situation is an insanely complicated object in a high-dimensional learned-from-scratch space of “all possible thoughts you can think”. Yet we need the relatively simple, genetically-hardwired circuitry of the Steering Subsystem to analyze the current thought, including issuing a judgment of whether the thought is overall good vs bad (see §6.4 below), and whether the thought calls for cortisol release or goosebumps or pupil-dilation, etc. The “scorecard” solves that interfacing problem! It distills any possible thought / belief / plan / etc. into a genetically-standardized form that can be plugged directly into genetically-hardcoded circuitry.
4. The Steering Subsystem runs some genetically-hardwired algorithm: Its inputs are (1) the scorecard from the previous step and (2) various other information sources—pain, metabolic status, etc., all coming from its own brainstem sensory-processing system (see §3.2.1). Its outputs include emitting hormones, motor commands, etc., as well as sending the “ground truth” supervisory signals shown in the diagram.[2]
5. The Thought Generator keeps or discards thoughts based on whether the Steering Subsystem likes them: More specifically, there’s a ground-truth valence (or in RL terms, some weird mixture of value function and reward function, see §5.3.2.1). When the valence is very positive, the current thought gets “strengthened”, sticks around, and can start controlling behavior and summoning follow-up thoughts, whereas when the valence is very negative, the current thought gets immediately discarded, and the Thought Generator summons a new thought instead.
6. Both the Thought Generator and the Thought Assessor “learn from scratch” over the course of a lifetime, thanks in part to these supervisory signals from the Steering Subsystem. Specifically, the Thought Assessors learn to make better and better predictions of their “ground truth in hindsight” signal (a form of Supervised Learning—see Post #4), while the Thought Generator learns to generate maximally “good” (positive-valence) thoughts. (The Thought Generator learning-from-scratch process also involves predictive learning of sensory inputs—§4.7.)
6.3 The “Thought Generator”
6.3.1 Overview
Go back to the big-picture diagram at the top. At the top-left, we find the Thought Generator. In terms of actor-critic model-based RL, the Thought Generator is roughly a combination of “actor” + “model”, but not “critic”. (“Critic” was discussed in the previous post, and more on it below.)
At our somewhat-oversimplified level of analysis, we can think of the “thoughts” generated by the Thought Generator as a combination of constraints (from predictive learning of sensory inputs) and choices (guided by reinforcement learning). In more detail:
6.3.2 Thought Generator inputs
The Thought Generator has a number of inputs, including sensory inputs, hyperparameter-shifting neuromodulators, and control signals like valence, which (per §5.3) is the brain’s all-things-considered estimate of whether a thought is good versus bad. The valence signal has a special superpower: if a thought seems bad, it will toss it out, so the cortex can re-roll[3] for a new, different thought instead:
6.3.3 Thought Generator outputs
There are meanwhile a lot of signals going out of the Thought Generator. Some are what we intuitively think of as “outputs”—e.g., skeletal motor commands. Other outgoing signals are, well, a bit funny…
Recall the idea of “context” from §4.3: The Thought Assessors are short-term predictors, and a short-term predictor can in principle grab any signal in the brain and leverage it to improve its ability to predict its target signal. So if the Thought Generator has a world-model, then somewhere in the world-model is a configuration of latent variable activations that encode the concept “baby kittens shivering in the cold rain”. We wouldn’t normally think of those as “output signals”—I just said in the last sentence that they’re latent variables! But as it happens, the “will lead to crying” Thought Assessor has grabbed a copy of those latent variables to use as context signals, and gradually learned through experience that these particular signals are strong predictors of me crying.
Now, as an adult, these “baby kittens in the cold rain” neurons in my Thought Generator are living a double-life:
6.4 More on how this connects to reinforcement learning
6.4.1 In what sense is this “model-based RL”?
I like to use the term “model-based RL” in a very minimal and literal sense. There’s a model, in that we can make predictions about the world and ourselves: “If I jump in the lake, then I’ll get wet”. There’s reinforcement learning, in the original psychology sense, the sense of “Thorndike’s Law of Effect” (1898): If a kid touches a hot stove, then he probably won’t do it again. The RL and the model are interconnected: the kid will explicitly think of touching the hot stove as a bad thing, and he will try, using his model of the world, to avoid doing so.
So according to this minimal, literal definition, the brain clearly does model-based RL.
Here’s another way to say the same thing: “model-based RL” means “maximizing an objective via a combination of RL and search”. When you maximize an objective via RL, you’re going out and actually doing stuff in the environment, and learning from trial-and-error (a.k.a. explore-exploit). When you maximize an objective via model-based search (a.k.a. planning), you’re taking advantage of knowledge you already have to make better decisions.
Again, in this minimal sense, the human brain clearly does model-based RL, because it uses both RL and search. The RL part turns innate drives (e.g. hunger drive) into explicit desires (e.g. “I want to go to McDonald’s for lunch”), and the search part (a.k.a. planning and brainstorming) then turns explicit desires into appropriate motor actions (e.g. walking to the bus). This is somewhat analogous to a normal AI setup where TD learning transfers information from a reward function to a value function, and then model-based search and planning transfers information from the value function to specific actions. (However, in the brain, the boundary between the RL part and the search part is unusually complex and nuanced—recall the discussion of “Valence and ground-truth-iness” in §5.3.2.1.)
If we instead use terms like “RL”, “model-based”, and “actor critic” to refer narrowly to the specific frameworks and assumptions that you might find in today’s RL textbooks, then I think brain algorithms are sufficiently weird that they probably wouldn’t qualify as any of those. For example, RL textbooks often assume a Markov Decision Process (or related), wherein rewards by definition depend only on states and actions; by contrast, rewards in the brain also depends on what the animal is thinking (§10.2.3).
6.4.2 The striatum (“learned value function” / “critic”) guesses the valence, but the Steering Subsystem may choose to override
There are two types of “valence” in the diagram (it looks like three, but the two red ones are the same):
The blue-circled signal is the valence guess from the corresponding Thought Assessor in the striatum. The red-circled signal (again, it’s one signal drawn twice) is the corresponding “ground truth” for what the valence guess should have been.
Just like the other “long-term predictors” discussed in the previous post, the long-term predictor for valence has a “defer-to-predictor mode” and an “override mode”, and the Steering Subsystem can dynamically switch between these modes. In defer-to-predictor mode, it sets the red equal to the blue, as if to say “OK, Thought Assessor, sure, I’ll take your word for it”. In override mode, it ignores the Thought Assessor’s proposal, and its own internal circuitry outputs some different value.[4]
Why might the Steering Subsystem override the Thought Assessor’s valence guess? Two factors:
6.5 Decisions involve not only simultaneous but also sequential comparisons of value
Here’s a “simultaneous” model of decision-making, as described by The Hungry Brain by Stephan Guyenet in the context of studies on lamprey fish:
I endorse this as part of my model of decision-making, but only part of it. Specifically, this is one of the things that’s happening when the Thought Generator generates a thought. Different simultaneous possibilities are being compared.
The other part of my model is comparisons of sequential thoughts. You think a thought, and then you think a different thought (possibly very different, or possibly a refinement of the first thought), and the two are implicitly compared, and if the second thought is worse, it gets weakened such that a new thought can replace it (and the new thought might be the first thought re-establishing itself).
I could cite experiments for the sequential-comparison aspect of decision-making (e.g. Figure 5 of Herd et al. 2021, which is arguing the same point as I am), but do I really need to? Introspectively, it’s obvious! You think: “Hmm, I think I’ll go to the gym. Actually, what if I went to the café instead?” You’re imagining one thing, and then another thing.
And I don’t think this is is a humans-vs-lampreys thing. I think comparison-of-sequential-thoughts is universal in vertebrates. As an illustration of what I mean:
6.5.1 Made-up example of what comparison-of-sequential-thoughts might look like in a simpler animal
Imagine a simple, ancient, little fish swimming along, navigating to the cave where it lives. It gets to a fork in the
roadkelp forest. Its current thought is something like “I am swimming left to my cave”. But it also has the option of turning right to go to the reef, where it often forages.Seeing this path to the right, I claim that a new thought pops into its head: “I am swimming right and going to the reef.” This new thought / plan is immediately evaluated by the Thought Assessors and Steering Subsystem as usual, and winds up with some valence (implicitly in comparison to the old plan). If this new thought seems bad, then it gets thrown out, and the old thought (“I am swimming left to my cave”) promptly pops back into its head. The fish continues to its cave, as originally planned, without skipping a beat. (Except maybe, if you look carefully, you could notice the fish subtly twitch to the right for a fraction of a second.) Whereas if instead the new thought seems good (i.e., better than the old thought), then it gets strengthened, sticks around, and orchestrates motor commands. And thus the fish turns to the right and goes to the reef instead.
(In reality, I don’t know much about ancient fish, but rats at a fork in the
roadmaze are known to imagine both possible navigation plans in succession, based on measurements of hippocampus neurons—Johnson & Redish 2007.)6.5.2 Comparison-of-sequential-thoughts: why it’s necessary
In my view, thoughts are complicated. To think the thought “I will go to the café”, you’re not just activating some tiny cluster of dedicated go-to-the-café neurons. Instead, it’s a distributed pattern involving practically every part of the cortex. You can’t simultaneously think “I will go to the café” and “I will go to the gym”, because they would involve different activity patterns of the same pools of neurons. They would cross-talk. Thus, the only possibility is thinking the thoughts in sequence.
As a concrete example of what I have in mind, think of how a Hopfield network can’t recall twelve different memories simultaneously. It has multiple stable states, but you can only explore them sequentially, one after the other. Or think about grid cells and place cells, etc.
6.5.3 Comparison-of-sequential-thoughts: how it might have evolved
From an evolutionary perspective, I imagine that comparison-of-sequential-thoughts is a distant descendent of a very simple mechanism akin to the run-and-tumble mechanism in swimming bacteria.
In the run-and-tumble mechanism, a bacterium swims in a straight line (“runs”), and periodically changes to a new random direction (“tumbles”). But the trick is: when the bacterium’s situation / environment is getting better, it tumbles less frequently, and when it’s getting worse, it tumbles more frequently. Thus, it winds up moving in a good direction (on average, over time).
Starting with a simple mechanism like that, one can imagine adding progressively more bells and whistles. The palette of behavioral options can get more and more complex, eventually culminating in “every thought you can possibly think”. The methods of evaluating whether the current plan is good or bad can get faster and more accurate, eventually involving learning-algorithm-based predictors as in the previous post. The new behavioral options to tumble into can be picked via clever learning algorithms, rather than randomly. Thus, it seems to me that there’s a smooth path all the way from something-akin-to-run-and-tumble to the intricate, finely-tuned, human brain system that I’m talking about in this series. (Other discussions of run-and-tumble versus human motivation: Karin & Alon 2022, Travis 2022.)
6.6 Common misconceptions
6.6.1 The distinction between internalized ego-syntonic desires and externalized ego-dystonic urges is unrelated to Learning Subsystem vs. Steering Subsystem
Many people (including me) have a strong intuitive distinction between ego-syntonic drives that are “part of us” or “what we want”, versus ego-dystonic drives that feel like urges which intrude upon us from the outside.
For example, if someone is on a hunger strike for freedom, they might say that their desire to eat comes from their innate drives, whereas their desire to fight for freedom comes from “reason”, or “their best self”, or whatever. What does that mean? What’s going on?
6.6.1.1 The explanation I like
I propose that we should not take this intuition at face value. In reality, the hunger-striker’s desire to eat comes ultimately from their innate drives, and their desire to fight for freedom also comes ultimately from their innate drives! These are just two innate drives that are pointing in different directions, and thus they duke it out. One side will win, and then the person will either keep their hunger strike, or break down and eat.
It’s not so different from if you feel simultaneously very sleepy and very hungry; you can’t satisfy both drives, so the drives will duke it out, and one of them will win, and either you’ll nap despite your hunger, or you’ll eat despite your sleepiness.
That said, there do seem to be very important differences between the mundane hunger-vs-sleepiness battle (urge vs urge) and the hunger-vs-fight-for-freedom battle (urge vs ego-syntonic desire). In particular, here are three obvious questions that I need to address:
First, hunger and sleep drives are easy to understand. But it’s much less obvious how innate drives could lead a person to care so much about freedom that they’ll go on a hunger strike. What exactly is the innate drive in question?
Second, if I’m both hungry and sleepy, it’s sorta “a fair fight”. Probably whichever feeling is more immediately powerful will win. By contrast, the internal battle between the hunger-striker’s desire for freedom and their desire for food is not a fair fight. The former desire will punch above its weight by bringing far more intelligence and foresight to bear towards its objective. Thus, if the person is setting up a commitment mechanism, or tying their own hands, or attempting to control themselves and their mood, those actions will almost definitely be in pursuit of freedom, not in pursuit of hunger-satisfaction. Why the asymmetry? If both drives are in the Steering Subsystem, shouldn’t they be equally stupid and myopic? Relatedly, if the person is “applying willpower”, why is it in support of freedom rather than hunger-satisfaction? And by the way, what the heck does “applying willpower” even mean at a nuts-and-bolts level??
Third, if the person’s desire for freedom is not really more a “part of them” than their desire to eat when hungry, then … why does it feel that way to them? In other words, this is an honest introspective report. I’m allowed to claim that the report should be interpreted as a perceptual illusion rather than taken at face value, but you have no reason to believe me unless I can also explain what exactly they were introspecting upon, and what they saw when they did so, and why it left them with the impression that it did.
These are all great questions! And I have answers to all of them! But they’re rather involved.
For the first question, I claim that hunger-striking for freedom is driven by social instincts. You can learn about those at a high level in Post #13 of this series, and then proceed to my follow-up work Neuroscience of human social instincts: a sketch (2024), and Social drives 1: “Sympathy Reward”, from compassion to dehumanization (2025), and Social drives 2: “Approval Reward”, from norm-enforcement to status-seeking (2025), especially §3 of that last post on how Approval Reward leads to pride in one’s self-image, and staying true to your principles even when nobody is watching. (That said, if people are watching, and you thus win the approval of people you admire, so much the better!)
For the second question, my short answer is that people have a strong, salient association between thoughts of themselves, and thoughts of how they would look in someone else’s eyes. The former thoughts are required for strategically tying one’s hands, making precommitments, etc. And the latter thoughts summon social instincts like pride. This is the source of the asymmetry where social instincts “punch above their weight” in the context of intelligent self-reflective plans, such as precommitments, describing one’s life aspirations, and so on. For more detail (along with how “willpower” fits in), see §8.5.5–§8.5.6 of my “Intuitive Self-Models” series (2024), but be warned that it might not make sense without reading the earlier posts in that Intuitive Self-Models series, in which I try to unravel a bunch of misleading intuitions in how we think about our own minds.
The third question (on why and how ego-syntonic desires are “internalized”) is also addressed in that same series, see “Intuitive Self Models” §3.5.4.
6.6.1.2 The explanation I don’t like
Many people (including Jeff Hawkins, see Post #3) notice the distinction described above, and separately, they endorse the idea (as I do) that the brain has a Learning Subsystem and Steering Subsystem (again see Post #3). They naturally suppose that these are the same thing, with “me and my deep desires” corresponding to the Learning Subsystem, and “urges that I don’t identify with” corresponding to the Steering Subsystem.
I think this model is wrong. At the very least, if you want to endorse this model, then you need to reject approximately everything I’ve written in this and my previous four posts.
One way to put it is: why does the hunger-striker care about freedom, and not about, I dunno, ironing the wrinkles out of dollar bills? There has to be some explanation, right? And if you reply “it’s because freedom leads to (blah)”, then I’ll just reply, “OK, and why do they care about (blah), rather than, I dunno, measuring the distance between pebbles on the sidewalk?” We can go back and forth forever. The answer is: at the end of the day, something has to just plain feel intuitively good or bad. And that feeling has to come from an innate drive, one way or another.
Here are three more views on why we should believe that the Steering Subsystem is the ultimate source of not only ego-dystonic urges like hunger, but also ego-syntonic desires like friendship and justice.
6.6.2 The Learning Subsystem and Steering Subsystem are not two agents
Relatedly, another frequent error is treating either the Learning Subsystem or Steering Subsystem by itself as a kind of independent agent. This is wrong on both sides:
As an example, the following is entirely possible:
Why not, right? I’ll talk more about that example in later posts.
If you just read the above example, and you’re thinking to yourself “Ah! This is a case where the Learning Subsystem has outwitted the Steering Subsystem”, then you’re still not getting it. Maybe instead try imagining the Learning Subsystem & Steering Subsystem as two interconnected gears in a single machine.
Changelog
July 2024: Since the initial version, I made a bunch of changes.
As in the previous post changelog, I’ve iterated on the “big picture” neuroscience diagrams several times since the initial version, as I learned more neuroscience.
For clarity, what I formerly labeled “Ground-truth value, a.k.a. reward” is now “Actual valence”, with a little note in the diagram about what this signal does. Relatedly, I added a bunch of links throughout this post to my more recent Valence series, including a very brief teaser / recap of it in §6.4.1. And along the same lines, I reworded the RL discussions to use the word “reward” less and “valence” more. The word “reward” is not wrong, exactly, but it has a lot of baggage which I expect to confuse readers, as explained in the previous post and §6.4.1.
I deleted a claim that (what I am now calling) the “valence guess” signal “doesn’t have a special role in the algorithm”. I still think the thing I was trying to say is true, but the thing I was trying to say was pretty narrow and subtle, and on balance I expect that what I wrote is far more confusing than helpful. I actually think the valence guess is centrally important, especially in long-term planning, as discussed here.
I also put in the example of a “static spinning spherical octagon” to illustrate of how the “constraints” in the Thought Generator are not just sensory inputs but also our semantic knowledge about how the world works. I also mentioned “involuntary attention” (e.g. itching or anxious rumination) as yet another source of “constraints”.
I deleted some discussion of neuroanatomy (there used to be a §6.3.4), including cortico-basal ganglia thalamo-cortical loops and dopamine, because what I had written was mostly wrong, and unnecessary for the series anyway. What little I want to say on those topics mostly wound up in the previous post.
October 2025: Since first writing this, I have somewhat updated how I think about ego-syntonic versus ego-dystonic desires. So I changed some wording in §6.6.1.1, and added a link to my more recent discussion of that topic.
January 2026: More rewriting and additions to §6.6.1, plus minor copyedits throughout.
June 2026: Rewrote §6.6.1 yet again. Moved “Teaser for my ‘Valence’ series” from §6.4.1 to §5.3.3. Added a new §6.4.1 on the term “model-based RL”.
As usual, I’m using “cortex” in the neuroanatomical sense, which includes neocortex, hippocampus, etc.
The term “ground truth” here is a bit misleading, because sometimes the Steering Subsystem will just defer to the Thought Assessors, as explained in the previous post.
“Re-roll” was originally a board game term; for example, if you previously rolled the dice to randomly generate a character, then “re-roll for a new character” would mean “you roll the dice again to randomly generate a different character”.
As in the previous post, I don’t really believe there is a pure dichotomy between “defer-to-predictor mode” and “override mode”. In reality, I’d bet that the Steering Subsystem can partly-but-not-entirely defer to the Thought Assessor, e.g. by taking a weighted average between the Thought Assessor and some other independent calculation.