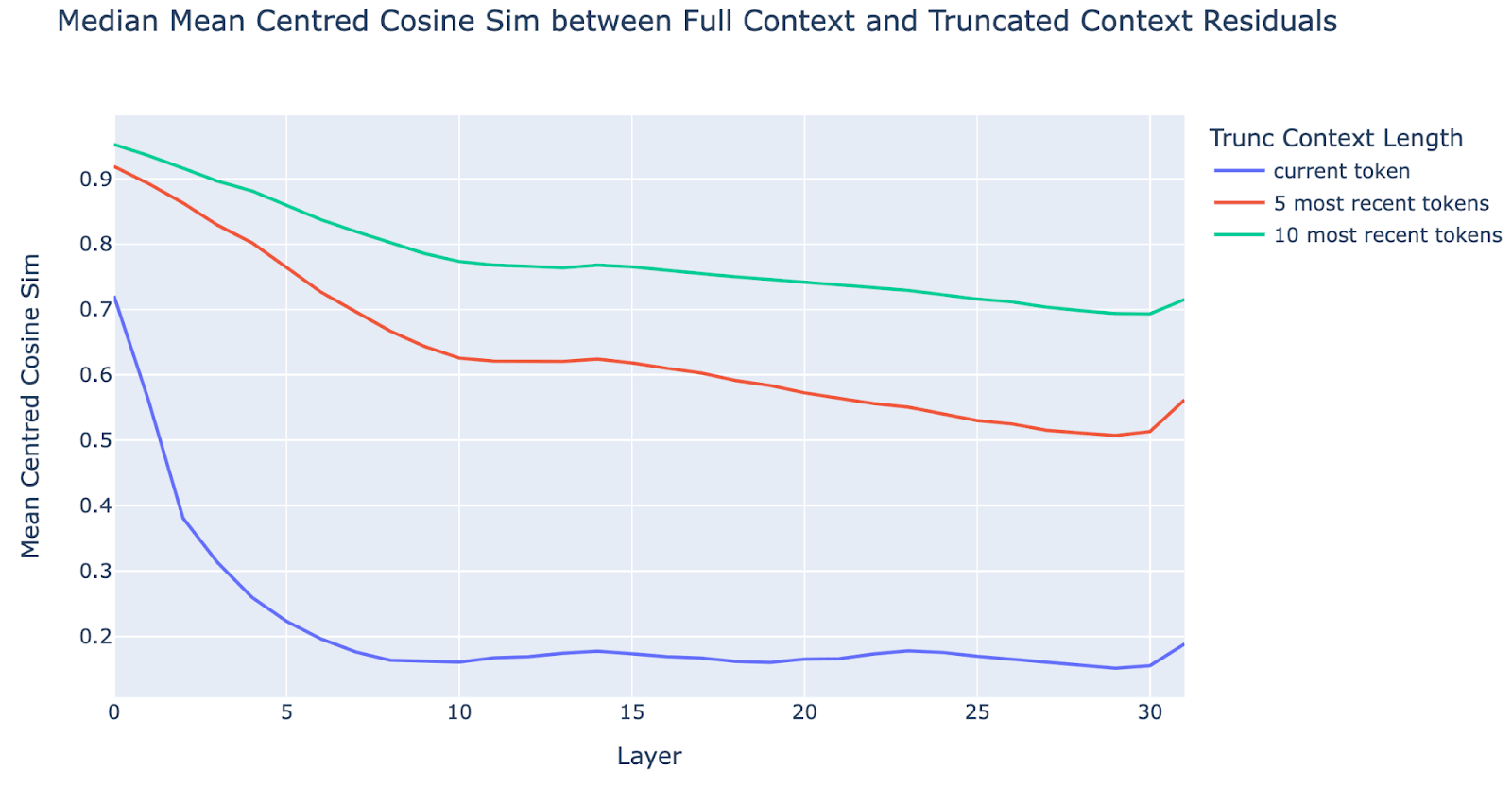
I don't think this plot shows what you claim it shows. This looks like no specialication of long range v.s. short range to me.
My main argument for this interpretataion is that the green and red lines move in almost perfect syncoronisation. This shows that attending to tokens that are 5-10 tokes away is done in the same layers as attending to tokens that are 0-5 tokens away. The fact that the blue line dropps more sharply only shows that close context is very important, not that it happens first, given that all three lines start dropping right away.
What it looks like to me:
- In layers 0-10, the model is gradualy taking in more and more context. Short range context is generaly more imortant in determining the recidual activations (i.e. more truncation -> larger cosine diffrerence), but there is no particular layer specialisation. Blue line bottoms out earlier, but this looks like cealing effect (floor effect?) to me.
- In layers 10-14 the network does some in-place prosessing.
- In layers 15-29 the network reads from other tokens again.
- in the last two layers the netowok finalise it's next token prediction.
(Very low confidence on 2-4, since the effects from previous lack of context can be amplified in later in-place prosessing, wich would confound any intepretation of the grah in later layers.)
Sorry I don't quite understand your arguments here. Five tokens back and 10 tokens back are both within what I would consider short-range context EG. They are typically within the same sentence. I'm not saying there are layers that look at the most recent five tokens and then other layers that look at the most recent 10 tokens etc. It's more that early layers aren't looking 100 tokens back as much. The lines being parallelish is consistent with our hypothesis
Thanks for responding.
I was imagining "local" meaning below 5 or 10 tokens away, partly anchored on the example of detokenisation, from the previous posts in the sequence, but also because that's what you're looking at. If your definition of "local" is longer than 10 tokens, then I'm confused why you didn't show the results for longer trunkations. I though the plot was to show what happens if you include the local context but cut the rest.
Even if there is specialisation going on between local and long range, I don't expect a sharp cutoff what is local v.s. non-local (and I assume neither do you). If some such soft boundary exists and it where in the 5-10 range, then I'd expect the 5 and 10 context lines to not be so correlated. But if you think the soft boundary is further away, then I agree that this correlation dosn't say much.
Attemting to re-state what I read from the graph: Looking at the green line, the fact that most of the drop in cosine similarity for t is in the early layers, suggests that longer range attention (more than 10 tokens away), is mosly located in the early layers. The fact that the blue and red line has their larges drops in the same regions, suggest that short-ish (5-10) and very short (0-5) attention is also mostly located there. I.e. the graph does not give evidence of range specialication for diffrent attention layes.
Did you also look at the statistics of attention distance for the attention patherns of various attention heads? I think that would be an easier way to settle this. Although mayne there is some techical dificulty in ruling out irrelevant attention that is just an artifact of attention needing to add up to one?
This is the fifth post in the Google DeepMind mechanistic interpretability team’s investigation into how language models recall facts. This post is a bit tangential to the main sequence, and documents some interesting observations about how, in general, early layers of models somewhat (but not fully) specialise into processing recent tokens. You don’t need to believe these results to believe our overall results about facts, but we hope they’re interesting! And likewise you don’t need to read the rest of the sequence to engage with this.
Introduction
In this sequence we’ve presented the multi-token embedding hypothesis, that a crucial mechanism behind factual recall is that on the final token of a multi-token entity there forms an “embedding”, with linear representations of attributes of that entity. We further noticed that this seemed to be most of what early layers did, and that they didn’t seem to respond much to prior context (e.g. adding “Mr Michael Jordan” didn’t substantially change the residual).
We hypothesised the stronger claim that early layers (e.g. the first 10-20%), in general, specialise in local processing, and that the prior context (e.g. more than 10 tokens back) is only brought in in early-mid layers. We note that this is stronger than the multi-token embedding hypothesis in two ways: it’s a statement about how early layers behave on all tokens, not just the final tokens of entities about which facts are known; and it’s a claim that early layers are not also doing longer range stuff in addition to producing the multi-token embedding (e.g. detecting the language of the text). We find this stronger hypothesis plausible, because tokens are a pretty messy input format, and analysing individual tokens in isolation can be highly misleading, e.g. when a long word is split into many fragment tokens, suggesting that longer range processing should be left until some pre-processing on the raw tokens has been done, the idea of detokenization.[1]
We tested this by taking a bunch of arbitrary prompts from the Pile, taking residual streams on those, truncating the prompts to the most recent few tokens and taking residual streams on the truncated prompts, and looking at the mean centred cosine sim at different layers.
Our findings:
Experiments
The “early layers specialise in local processing” hypothesis concretely predicts that, for a given token X in a long prompt, if we truncate the prompt to just the most recent few tokens before X, the residual stream at X should be very similar at early layers and dissimilar at later layers. We can test this empirically by looking at the cosine sim of the original vs truncated residual streams, as a function of layer and truncated context length. Taking cosine sims of residual streams naively can be misleading, as there’s often a significant shared mean across all tokens, so we first subtract the mean residual stream across all tokens, and then take the cosine sim.
Set-Up
Results
Early Layers Softly Specialise in Local Processing
In the graph below, we show the mean centred cosine sims between the full context and truncated residuals for a truncated context of length 5:
We see that the cosine sims with a truncated context of length 5 are significantly higher in early layers. However, they aren’t actually at 1, so some information from the prior context is included, it’s a soft specialisation[2]. There’s a fairly gradual transition between layer 0 and 10, after which it somewhat plateaus. Interestingly, there’s an uptick in the final layer[3]. Even if we give a truncated context of length 10, it’s still normally not near 1.
One possible explanation for these results is that the residual stream is dominated by the current token, and that each layer is a small incremental update - of course truncation won’t do anything! This doesn’t involve any need for layers to specialise - later residuals will have had more incremental updates and so have higher difference. However, we see that this is false by contrasting the blue and red lines - truncating to the five most recent tokens has much higher cosine sim than truncating to just the current token (and a BOS token), even just after layer 0, suggesting early layers genuinely do specialise into nearby tokens.
Error Analysis: Which Tokens Have Unusually Low Cosine Sim?
In the previous section we only analysed the median of the mean centred cosine sim between the truncated context and full context residual. Summary statistics can be misleading, so it’s worthwhile to also look at the full distribution, where we see a long negative tail! What’s up with that?
When inspecting the outlier tokens, we noticed two important clusters: punctuation tokens, and common words. We sorted into a few categories and looked at the cosine sim for each of these:
Is_newline, is_full_stop, is_comma - whether it’s the relevant punctuation character
Is_common: whether it’s one of a hand-created list of common words[4], possible prepended with a space
Is_alpha: whether it’s both not a common word, and is made up of letters (possibly prepended with a space, any case allowed)
Is_other: the rest
Even after just layer 0 with context length of 10, we see that punctuation is substantially lower, common words and other are notably lower, while alpha is extremely high.
Our guess is that this is a result of a mix of several mechanisms:
Word fragments (in the is_alpha category) are more likely to be part of multi-token words and detokenization before much processing can be done, while many of the other categories have a clear meaning without needing to refer to recent prior tokens[5]. This means that long-range processing can start earlier
Early full stops or newlines are sometimes used as “resting positions” with very high norm, truncating the context may turn them from normal punctuation to resting positions
Pronouns may be used to track information about the relevant entity (their name, attributes about them, etc)
Commas have been observed to summarise sentiment of the current clause, which may be longer than 10 tokens, and longer range forms of summarisation seem likely.
More eclectic hypotheses:
But it would be pretty surprising if literally no long-range processing happens in early layers, e.g. we know GPT-2 Small has a duplicate token head in layer 0. ↩︎
It’s a bit hard to intuitively reason about about cosine sims, our best intuition is to look at the squared cosine sim (fraction of norm explained). If there’s 100 independently varying pieces of information in the residual stream, and a cosine sim of 0.9, then the fraction of norm explained is 0.81, suggesting about 81 of those 100 pieces of information is shared. ↩︎
Our guess is that this is because the residual stream on a token is both used to literally predict the next token, and to convey information to future tokens to predict their next token (e.g. the summarisation motif). Plausibly there’s many tokens where predicting the literal next token mostly requires the local context (e.g. n-grams) but there’s longer-range context that’s useful for predicting future tokens. We’d expect the longer-range stuff to happen in the middle, so by the end the model can clean up the long-range stuff and focus on just the n-grams. We’re surprised the uptick only happens in the final layer, rather than final few, as our intuition is that the last several layers are spent on just the next token prediction. ↩︎
The list ["and", "of", "or", "in", "to", "that", "which", "with", "for", "the", "a", "an", "they", "on", "is", "their", "but", "are", "its", "i", "we", "it", "at"]. We made this by hand by repeatedly looking at tokens with unusually low cosine sim, and filtering for common words ↩︎
This isn’t quite true, e.g. “.” means something very different at the end of a sentence vs “Mr.” vs “C.I.A” ↩︎