TL;DR: It seems hard to scan a trained neural network and locate the AI’s learned “tree” abstraction. For very similar reasons, it seems intractable for the genome to scan a human brain and back out the “death” abstraction, which probably will not form at a predictable neural address. Therefore, I infer that the genome can’t directly make us afraid of death by e.g. specifying circuitry which detects when we think about death and then makes us afraid. In turn, this implies that there are a lot of values and biases which the genome cannot hardcode.
In order to understand the human alignment situation confronted by the human genome, consider the AI alignment situation confronted by human civilization. For example, we may want to train a smart AI which learns a sophisticated world model, and then motivate that AI according to its learned world model. Suppose we want to build an AI which intrinsically values trees. Perhaps we can just provide a utility function that queries the learned world model and counts how many trees the AI believes there are.
Suppose that the AI will learn a reasonably human-like concept for “tree.” However, before training has begun, the learned world model is inaccessibleto us. Perhaps the learned world model will be buried deep within a recurrent policy network, and buried within the world model is the “trees” concept. But we have no idea what learned circuits will encode that concept, or how the information will be encoded. We probably can’t, in advance of training the AI, write an algorithm which will examine the policy network’s hidden state and reliably back out how many trees the AI thinks there are. The AI’s learned concept for “tree” is inaccessible informationfrom our perspective.
I’m going to say things like “the genome cannot specify circuitry which detects when a person is thinking about death.” This means that the genome cannot hardcode circuitry which e.g. fires when the person is thinking about death, and does not fire when the person is not thinking about death. The genome does help indirectly specify the whole adult brain and all its concepts, just like we indirectly specify the trained neural network via the training algorithm and the dataset. That doesn’t mean we can tell when the AI thinks about trees, and it doesn’t mean that the genome can “tell” when the human thinks about death.
When I’d previously thought about human biases (like the sunk cost fallacy) or values (like caring about other people), I had implicitly imagined that genetic influences could directly affect them (e.g. by detecting when I think about helping my friends, and then producing reward). However, given the inaccessibility obstacle, I infer that this can’t be the explanation. I infer that the genome cannot directly specify circuitry which:
Detects when you’re thinking about seeking power,
Detects when you’re thinking about cheating on your partner,
Detects whether you perceive a sunk cost,
Detects whether you think someone is scamming you and, if so, makes you want to punish them,
Detects whether a decision involves probabilities and, if so, implements the framing effect,
Detects whether you’re thinking about your family,
E.g. Suppose you learn that animals are made out of cells. I infer that the genome cannot detect that you are expanding your ontology, and then execute some genetically hard-coded algorithm which helps you do that successfully.
Detects when you’re thinking about wireheading yourself or manipulating your reward signals,
Detects when you’re thinking about reality versus non-reality (like a simulation or fictional world), or
Detects whether you think someone is higher-status than you.
Conversely, the genome can access direct sensory observables, because those observables involve a priori-fixed “neural addresses.” For example, the genome could hardwire a cute-face-detector which hooks up to retinal ganglion cells (which are at genome-predictable addresses), and then this circuit could produce physiological reactions (like the release of reward). This kind of circuit seems totally fine to me.
In total, information inaccessibility is strong evidencefor the genome hardcoding relatively simple[2] cognitive machinery. This, in turn, implies that human values/biases/high-level cognitive observables are produced by relatively simpler hardcoded circuitry, specifying e.g. the learning architecture, the broad reinforcement learning and self-supervised learning systems in the brain, and regional learning hyperparameters. Whereas before it seemed plausible to me that the genome hardcoded a lot of the above bullet points, I now think that’s pretty implausible.
Thanks to Adam Shimi, Steve Byrnes, Quintin Pope, Charles Foster, Logan Smith, Scott Viteri, and Robert Mastragostino for feedback.
Appendix: The inaccessibility trilemma
The logical structure of this essay is that at least one of the following must be true:
Information inaccessibility is somehow a surmountable problem for AI alignment (and the genome surmounted it),
The genome solves information inaccessibility in some way we cannot replicate for AI alignment, or
The genome cannot directly address the vast majority of interesting human cognitive events, concepts, and properties. (The point argued by this essay)
In my opinion, either (1) or (3) would be enormous news for AI alignment. More on (3)’s importance in future essays.
Appendix: Did evolution have advantages in solving the information inaccessibility problem?
Yes, and no. In a sense, evolution had “a lot of tries” but is “dumb”, while we have very few tries at AGI while ourselves being able to do consequentialist planning.
In the AI alignment problem, we want to be able to back out an AGI’s concepts, but we cannot run lots of similar AGIs and select for AGIs with certain effects on the world. Given the natural abstractions hypothesis, maybe there’s a lattice of convergent abstractions—first learn edge detectors, then shape detectors, then people being visually detectable in part as compositions of shapes. And maybe, for example, people tend to convergently situate these abstractions in similar relative neural locations: The edge detectors go in V1, then the shape detectors are almost always in some other location, and then the person-concept circuitry is learned elsewhere in a convergently reliable relative position to the edge and shape detectors.
But there’s a problem with this story. A congenitally blind person develops dramatically different functional areas, which suggests in particular that their person-concept will be at a radically different relative position than the convergent person-concept location in sighted individuals. Therefore, any genetically hardcoded circuit which checks at the relative address for the person-concept which is reliably situated for sighted people, will not look at the right address for congenitally blind people. Therefore, if this story were true, congenitally blind people would lose any important value-formation effects ensured by this location-checking circuit which detects when they’re thinking about people. So, either the human-concept-location-checking circuit wasn’t an important cause of the blind person caring about other people (and then this circuit hasn’t explained the question we wanted it to, which is how people come to care about other people), or there isn’t such a circuit to begin with. I think the latter is true, and the convergent relative location story is wrong.
But the location-checking circuit is only one way the human-concept-detector could be implemented. There are other possibilities. Therefore, given enough selection and time, maybe evolution could evolve a circuit which checks whether you’re thinking about other people. Maybe. But it seems implausible to me (<4%). I’m going to prioritize explanations for “most people care about other people” which don’t require a fancy workaround.
EDIT: After talking with Richard Ngo, I now think there's about an 8% chance that several interesting mental events are accessed by the genome; I updated upwards from 4%.
EDIT 8/29/22: Updating down to 3%, in part due to 1950's arguments on ethology:
How do we want to explain the origins of behavior? And [Lehrman's] critique seems to echo some of the concerns with evolutionary psychology. His approach can be gleaned from his example on the pecking behavior of chicks. Lorenz attributed this behavior to innate forces:The chicks are born with the tendency to peck; it might require just a bit of maturation. Lehrman points out that research by Kuo provides an explanation based on the embryonic development of the chick. The pecking behavior can actually be traced back to movements that developed while the chick was still unhatched. Hardly innate! The main point Lehrman makes: If we claim that something is innate, we stop the scientific investigation without fully understanding the origin of the behavior. This leaves out important – and fascinating – parts of the explanation because we think we’ve answered the question. As he puts it: “the statement “It is innate” adds nothing to an understanding of the developmental process involved”
Human values can still be inaccessible to the genome even if the cortex isn’t learned from scratch, but learning-from-scratch is a nice and clean sufficient condition which seems likely to me.
Conversely, the genome can access direct sensory observables, because those observables involve a priori-fixed “neural addresses.” For example, the genome could hardwire a cute-face-detector which hooks up to retinal ganglion cells (which are at genome-predictable addresses), and then this circuit could produce physiological reactions (like the release of reward). This kind of circuit seems totally fine to me.
Related: evolutionary psychology used to have a theory according to which humans had a hardwired fear of some stimuli (e.g. spiders and snakes). But more recent research has moved towards a model where, rather than “the fear system” itself having innate biases towards picking up particular kinds of fears, our sensory system (which brings in data that the fear system can then learn from) is biased towards paying extra attention to the kinds of shapes that look like spiders and snakes. Because these stimuli then become more attended than others, it also becomes more probable that a fear response gets paired with them.
This, in turn, implies that human values/biases/high-level cognitive observables are produced by relatively simpler hardcoded circuitry, specifying e.g. the learning architecture, the broad reinforcement learning and self-supervised learning systems in the brain, and regional learning hyperparameters.
The original WEIRD paper is worth reading for anyone who hasn't already done so; it surveyed various cross-cultural studies which showed that a variety of things that one might assume to be hardwired were actually significantly culturally influenced, including things such as optical illusions:
Many readers may suspect that tasks involving “low-level” or “basic” cognitive processes such as vision will not vary much across the human spectrum (Fodor 1983). However, in the 1960s an interdisciplinary team of anthropologists and psychologists systematically gathered data on the susceptibility of both children and adults from a wide range of human societies to five “standard illusions” (Segall et al. 1966). Here we highlight the comparative findings on the famed Müller-Lyer illusion, because of this illusion’s importance in textbooks, and its prominent role as Fodor’s indisputable example of “cognitive impenetrability” in debates about the modularity of cognition (McCauley & Henrich 2006). Note, however, that population-level variability in illusion susceptibility is not limited to the Müller-Lyer illusion; it was also found for the Sander-Parallelogram and both Horizontal-Vertical illusions.
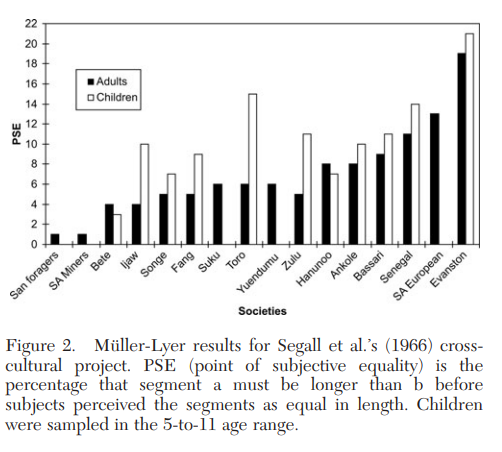
Segall et al. (1966) manipulated the length of the two lines in the Müller-Lyer illusion (Fig. 1) and estimated the magnitude of the illusion by determining the approximate point at which the two lines were perceived as being of the same length. Figure 2 shows the results from 16 societies, including 14 small-scale societies. The vertical axis gives the “point of subjective equality” (PSE), which measures the extent to which segment “a” must be longer than segment “b” before the two segments are judged equal in length. PSE measures the strength of the illusion.
The results show substantial differences among populations, with American undergraduates anchoring the extreme end of the distribution, followed by the South African-European sample from Johannesburg. On average, the undergraduates required that line “a” be about a fifth longer than line “b” before the two segments were perceived as equal. At the other end, the San foragers of the Kalahari were unaffected by the so-called illusion (it is not an illusion for them). While the San’s PSE value cannot be distinguished from zero, the American undergraduates’ PSE value is significantly different from all the other societies studied.
As discussed by Segall et al., these findings suggest that visual exposure during ontogeny to factors such as the “carpentered corners” of modern environments may favor certain optical calibrations and visual habits that create and perpetuate this illusion. That is, the visual system ontogenetically adapts to the presence of recurrent features in the local visual environment. Because elements such as carpentered corners are products of particular cultural evolutionary trajectories, and were not part of most environments for most of human history, the Müller-Lyer illusion is a kind of culturally evolved by-product (Henrich 2008).
These findings highlight three important considerations. First, this work suggests that even a process as apparently basic as visual perception can show substantial variation across populations. If visual perception can vary, what kind of psychological processes can we be sure will not vary? It is not merely that the strength of the illusory effect varies across populations – the effect cannot be detected in two populations. Second, both American undergraduates and children are at the extreme end of the distribution, showing significant differences from all other populations studied; whereas, many of the other populations cannot be distinguished from one another. Since children already show large population-level differences, it is not obvious that developmental work can substitute for research across diverse human populations. Children likely have different developmental trajectories in different societies. Finally, this provides an example of how population-level variation can be useful for illuminating the nature of a psychological process, which would not be as evident in the absence of comparative work.
This, in turn, implies that human values/biases/high-level cognitive observables are produced by relatively simpler hardcoded circuitry, specifying e.g. the learning architecture, the broad reinforcement learning and self-supervised learning systems in the brain, and regional learning hyperparameters.
... the evolved modularity cluster posits that much of the machinery of human mental algorithms is largely innate. General learning - if it exists at all - exists only in specific modules; in most modules learning is relegated to the role of adapting existing algorithms and acquiring data; the impact of the information environment is de-emphasized. In this view the brain is a complex messy cludge of evolved mechanisms.
There is another viewpoint cluster, more popular in computational neuroscience (especially today), that is almost the exact opposite of the evolved modularity hypothesis. I will rebrand this viewpoint the "universal learner" hypothesis, aka the "one learning algorithm" hypothesis (the rebranding is justified mainly by the inclusion of some newer theories and evidence for the basal ganglia as a 'CPU' which learns to control the cortex). The roots of the universal learning hypothesis can be traced back to Mountcastle's discovery of the simple uniform architecture of the cortex.[6]
The universal learning hypothesis proposes that all significant mental algorithms are learned; nothing is innate except for the learning and reward machinery itself (which is somewhat complicated, involving a number of systems and mechanisms), the initial rough architecture (equivalent to a prior over mindspace), and a small library of simple innate circuits (analogous to the operating system layer in a computer). In this view the mind (software) is distinct from the brain (hardware). The mind is a complex software system built out of a general learning mechanism.
This seems partially right, partially confused in an important way.
As I tried to point people to years ago, how this works is ... quite complex processes, where some higher-level modelling (“I see a lion”) leads to a response in lower levels connected to body states, some chemicals are released, and this interoceptive sensation is re-integrated in the higher levels.
I will try to paraphrase/expand in a longer form.
Genome already discovered a ton of cybernetics before inventing neocortex-style neural nets.
Consider e.g. the problem of morphogenesis - that is, how one cell replicates to something like quadrillion cells in an elephant. Which end up reliably forming some body shape and cooperating in a highly complex way: it's really impressive and hard optimization problem.
Inspired by Levine, I'm happy to argue it is also impossible without discovering a lot of powerful stuff from information theory and cybernetics, including various regulatory circuits, complex goal specifications, etc.
Note that there are many organisms without neural nets which still seek reproduction, avoid danger, look for food, move in complex environments, and in general, are living using fairly complex specifications of evolutionary relevant goals.
This implies genome had complex circuitry specificing many/most of the goal states it's cares about before it invented predictive processing brain.
Given this, what genome did when developing the brain predictive processing machinery likely wasn't trying to hook up things to "raw sensory inputs", but hook up the PP machinery to the existing cybernetic regulatory systems, often broadly localized "in the body".
From the PP-brain-centric viewpoint, the variables of this evolutionary older control system come in via a "sense" of interoception.
The very obvious hack which genome is using in encoding goals to the PP machinery isspecifying the goals mostly in interoceptive variables,utilizing the existing control circuits.
Predictive processing / active inference than goes on to build a complex world model and execute complex goal-oriented behaviours.
How these desirable states are encoded was called agenty subparts by me, but according to Friston, is basically the same thing as he calls "fixed priors": as a genome, you for example "fix the prior" on the variable "hunger" to "not being hungry". (Note that a lot of the specification of what "hunger" is, is done by the older machinery). Generic predictive processing principles than build you a circuitry "around" this "fixed prior" which e.g. cares about objects in the world which are food. (Using intentional stance, the fixed variable + the surrounding control circuits look like a sub-agent of the human, hence the alternative agenty subpart view)
Summary: - genome solves the problem of aligning the predictive processing neural nets by creating a bunch of agenty subparts/fixed priors, caring about specific variables in the predictive processing world model. Pp/active inference deals with how this translates to sensing and action. - however, many critical variables used for this are not sensory inputs, but interoceptive variables, extracted from a quite complex computation
This allows genome to point to stuff like sex or love for family relatively easily and, build "subagents" caring for this. Building of complex policies out of this is then left to predictive processing style of interactions.
If you would counts this as "direct" or "indirect" seems unclear.
Here's my stab at a summary of your comment: "Before complex brains evolved, evolution had already optimized organisms to trade off a range of complex goals, from meeting their metabolic needs to finding mates. Therefore, in laying down motivational circuitry in our ancient ancestors, evolution did not have to start from scratch, and already had a reasonably complex 'API' for interoceptive variables."
This sounds right to me. Reasons like this also contribute to my uncertainty about how much weight to put on "But a sensory food-scent-detector would be simpler to specify than a world-model food-detector", because "simpler" gets weird in the presence of uncertain initial conditions. For example, what kinds of "world models" did our nonhuman precursors have, and, over longer evolutionary timescales, could evolution have laid down some simpler circuitry which detected food in their simpler world models, which we inherited? It's not that I find such possibilities probable on their own, but marginalizing over all such possibilities, I end up feeling somewhat uncertain.
I don't see how complex interoceptive variables + control systems help accomplish "love for family" more easily, though, although that one doesn't seem very inaccessible to the genome anyways (in part since at least some of your family is usually proximate to sensory inputs).
I would correct "Therefore, in laying down motivational circuitry in our ancient ancestors, evolution did not have to start from scratch, and already had a reasonably complex 'API' for interoceptive variables."
from the summary to something like this
"Therefore, in laying down motivational circuitry in our ancient ancestors, evolution did have to start locating 'goals' and relevant world-features in the learned world models. Instead, it re-used the the existing goal-specifying circuits, and implicit-world-models, existing in older organisms. Most of the goal specification is done via "binding" the older and newer world-models in some important variables. From within the newer circuitry, important part of the "API" between the models is interoception"
(Another way how to think about it: imagine a more blurry line between a "sensory signal" and "reward signal")
The post is influential, but makes multiple somewhat confused claims and led many people to become confused.
The central confusion stems from the fact that genetic evolution already created a lot of control circuitry before inventing cortex, and did the obvious thing to 'align' the evolutionary newer areas: bind them to the old circuitry via interoceptive inputs. By this mechanism, genome is able to 'access' a lot of evolutionary relevant beliefs and mental models. The trick is the higher/more distant to genome models are learned in part to predict interoceptive inputs (tracking evolutionary older reward circuitry), so they are bound by default, and there isn't much independent to 'bind'. Anyone can check this... just thinking about a dangerous looking person with a weapon activates older, body-based fear/fight chemical regulatory circuits => the active inference machinery learned this and plans actions to avoid these states.
genetic evolution already created a lot of control circuitry before inventing cortex
Agreed. This post would have been strengthened by discussing this consideration more.
and did the obvious thing to 'align' the evolutionary newer areas: bind them to the old circuitry via interoceptive inputs. By this mechanism, genome is able to 'access' a lot of evolutionary relevant beliefs and mental models.
Do we... know this? Is this actually a known "fact"? I expect some of this to be happening, but I don't necessarily know or believe that the genome can access "evolutionary relevant mental models." That's the whole thing I'm debating in this post.
It seems reasonable to suspect the genome has more access than supposed in this post, but I don't know evidence by which one can be confident that it does have meaningful access to abstract concepts. Do you know of such evidence?
Information inaccessibility is somehow a surmountable problem for AI alignment (and the genome surmounted it),
Yes. Evolution solved information inaccessibility, as it had to, over and over, in order to utilize dynamic learning circuits at all (as they always had to adapt to and be adaptive within the context of existing conserved innate circuitry).
The general solution is proxy matching, where the genome specifies a simple innate proxy circuit which correlates and thus matches with a target learned circuit at some critical learning phase, allowing the innate circuit to gradually supplant itself with the target learned circuit. The innate proxy circuit does not need to mirror the complexity of the fully trained target learned circuit at the end of it's development, it only needs to roughly specify it at a some earlier phase, against all other valid targets.
Imprinting is fairly well understood, and has the exact expected failure modes of proxy matching. The oldbrain proxy circuit just detects something like large persistent nearby moving things - which in normal development are almost always the chick's parents. After the newbrain target circuit is fully trained the chick will only follow it's actual parents or sophisticated sims thereof. But during the critical window before the newbrain target is trained, the oldbrain proxy circuit can easily be fooled, and the chick can imprint on something else (like a human, or a glider).
Sexual attraction is a natural extension of imprinting: some collaboration of various oldbrain circuits can first ground to the general form of humans (infants have primitive face detectors for example, and more), and then also myriad more specific attraction signals: symmetry, body shape, secondary characteristics, etc, combined with other circuits which disable attraction for likely kin ala the Westermarck effect (identified by yet other sets of oldbrain circuits as the most familiar individuals during childhood). This explains the various failure modes we see in porn (attraction to images of people and even abstractions of humanoid shapes), and the failure of kin attraction inhibition for kin raised apart.
Fear of death is a natural consequence of empowerment based learning - as it is already the worst (most disempowered) outcome. But instinctual fear still has obvious evolutionary advantage: there are many dangers that can kill or maim long before the brain's learned world model is highly capable. Oldbrain circuits can easily detect various obvious dangers for symbol grounding: very loud sounds and fast large movements are indicative of dangerous high kinetic energy events, fairly simple visual circuits can detect dangerous cliffs/heights (whereas many tree-dwelling primates instead instinctively fear open spaces), etc.
Anger/Jealousy/Vengeance/Justice are all variations of the same general game-theoretic punishment mechanism. These are deviations from empowerment because an individual often pursues punishment of a perceived transgressor even at a cost to their own 'normal' (empowerment) utility (ie their ability to pursue diverse goals). Even though the symbol grounding here seems more complex, we do see failure modes such as anger at inanimate objects which are suggestive of proxy matching. In the specific case of jealousy a two step grounding seems plausible: first the previously discussed lust/attraction circuits are grounded, which then can lead to obsessive attentive focus on a particular subject. Other various oldbrain circuits then bind to a diverse set of correlated indicators of human interest and attraction (eye gaze, smiling, pupil dilation, voice tone, laughter, touching, etc), and then this combination can help bind to the desired jealousy grounding concept: "the subject of my desire is attracted to another". This also correctly postdicts that jealousy is less susceptible to the inanimate object failure mode than anger.
Empathy: Oldbrain circuits conspicuously advertise emotional state through many indicators: facial expressions, pupil dilation, blink rate, voice tone, etc - so that another person's sensory oldbrain circuits can detect emotional state from these obvious cues. This provides the requisite proxy foundation for grounding to newbrain learned representations of emotional state in others, and thus empathy. The same learned representations are then reused during imagination&planning, allowing the brain to imagine/predict the future contingent emotional state of others. Simulation itself can also help with grounding, by reusing the brain's own emotional circuity as the proxy. While simulating the mental experience of others, the brain can also compare their relative alignment/altruism to its own, or some baseline, allowing for the appropriate game theoretic adjustments to sympathy. This provides a reasonable basis for alignment in the brain, and explains why empathy is dependent upon (and naturally tends to follow from) familiarity with a particular character - hence "to know someone is to love them".
Evolution needed a reasonable approximation of "degree of kinship", and a simple efficient proxy is relative circuit capacity allocated to modeling an individual in the newbrain/cortex, which naturally depends directly on familiarity, which correlates strongly with kin/family.
I feel confused. I think this comment is overall good (though I don't think I understand a some of it), but doesn't seem to suggest the genome actually solved information inaccessibility in the form of reliably locating learned WM concepts in the human brain?
Information inaccessibility is somehow a surmountable problem for AI alignment (and the genome surmounted it),
The genome solves information inaccessibility in some way we cannot replicate for AI alignment, or
The genome cannot directly address the vast majority of interesting human cognitive events, concepts, and properties. (The point argued by this essay)
In my opinion, either (1) or (3) would be enormous news for AI alignment
What do you mean by 'enormous news for AI alignment'? That either of these would be surprising to people in the field? Or that resolving that dilemma would be useful to build from? Or something else?
FWIW from my POV the trilemma isn't, because I agree that (2) is obviously not the case in principle (subject to enough research time!). And I further think it reasonably clear that both (1) and (3) are true in some measure. Granted you say 'at least one' must be true, but I think the framing as a trilemma suggests you want to dismiss (1) - is that right?
I'll bite those bullets (in devil's advocate style)...
I think about half of your bullets are probably (1), except via rough proxies (power, scamming, family, status, maybe cheating)
why? One clue is that people have quite specific physiological responses to some of these things. Another is that various of these are characterised by different behaviour in different species.
why proxies? It stands to reason, like you're pointing out here, it's hard and expensive to specify things exactly. Further, lots of animal research demonstrates hardwired proxies pointing to runtime-learned concepts
Sunk cost, framing, and goal conflation smell weird to me in this list - like they're the wrong type? I'm not sure what it would mean for these to be 'detected' and then the bias 'implemented'. Rather I think they emerge from failure of imagination due to bounded compute.
in the case of goals I think that's just how we're implemented (it's parsimonious)
with the possible exception of 'conscious self approval' as a differently-typed and differently-implemented sole terminal goal
other goals at various levels of hierarchy, strength, and temporal extent get installed as we go
ontological shifts are just supplementary world abstractions being installed which happen to overlap with preexisting abstractions
tentatively, I expect cells and atoms probably have similar representation to ghosts and spirits and numbers and ecosystems and whatnot - they're just abstractions and we have machinery which forms and manipulates them
admittedly this machinery is basically magic to me at this point
wireheading and reality/non-reality are unclear to me and I'm looking forward to seeing where you go with it
I suspect all imagined circumstances ('real' or non-real) go via basically the same circuitry, and that 'non-real' is just an abstraction like 'far away' or 'unlikely'
after all, any imagined circumstances is non-real to some extent
That either of these would be surprising to people in the field? Or that resolving that dilemma would be useful to build from?
Both.
I think the framing as a trilemma suggests you want to dismiss (1) - is that right?
Yup!
I perceive many of your points as not really grappling with the key arguments in the post, so I'll step through them. My remarks may come off as aggressive, and I do not mean them as such. I have not yet gained the skill of disagreeing frankly and bluntly without seeming chilly, so I will preface this comment with goodwill!
I think about half of your bullets are probably (1), except via rough proxies (power, scamming, family, status, maybe cheating)
I think that you're saying "rough proxies" and then imagining it solved, somehow, but I don't see that step?
Whenever I imagine try to imagine a "proxy", I get stuck. What, specifically, could the proxy be? Such that it will actually reliably entangle itself with the target learned-concept (e.g. "someone's cheating me"), such that the imagined proxy explains why people care so robustly about punishing cheaters. Whenever I generate candidate proxies (e.g. detecting physiological anger, or just scanning the brain somehow), the scheme seems pretty implausible to me.
Do you disagree?
One clue is that people have quite specific physiological responses to some of these things. Another is that various of these are characterised by different behaviour in different species.
I don't presently see why "a physiological response is produced" is more likely to come out true in worlds where the genome solves information inaccessibility, than in worlds where it doesn't.
why proxies? It stands to reason, like you're pointing out here, it's hard and expensive to specify things exactly. Further, lots of animal research demonstrates hardwired proxies pointing to runtime-learned concepts
Note that all of the imprinting examples rely on direct sensory observables. This is not (1): Information inaccessibility is solved by the genome -- these imprinting examples aren't inaccessible to begin with.
(Except "limbic imprinting", I can't make heads or tails of that one. I couldn't quickly understand what a concrete example would be after skimming a few resources.)
Rather I think they emerge from failure of imagination due to bounded compute.
My first pass is "I don't feel less confused after reading this potential explanation." More in detail -- "bounded compute" a priori predicts many possible observations, AFAICT it does not concentrate probability onto specific observed biases (like sunk cost or framing effect). Rather, "bounded compute" can, on its own, explain a vast range of behavior. Since AFAICT this explanation assigns relatively low probability to observed data, it loses tons of probability mass compared to other hypotheses which more strongly predict the data.
ontological shifts are just supplementary world abstractions being installed which happen to overlap with preexisting abstractions... they're just abstractions and we have machinery which forms and manipulates them
This machinery is also presently magic to me. But your quoted portion doesn't (to my eyes) explainhow ontological shifts get handled; this hypothesis seems (to me) to basically be "somehow it happens." But it, of course, has to happen somehow, by some set of specific mechanisms, and I'm saying that the genome probably isn't hardcoding those mechanisms (resolution (1)), that the genome is not specifying algorithms by which we can e.g. still love dogs after learning they are made of cells.
Not just because it sounds weird to me. I think it's just really really hard to pull off, for the same reasons it seems hard to write a priori code which manages ontological shifts for big ML models trained online. Where would one begin? Why should code like that exist, in generality across possible models?
(Partly transcribed from a correspondence on Eleuther.)
I disagree about concepts in the human world model being inaccessible in theory to the genome. I think lots of concepts could be accessed, and that (2) is true in the trilemma.
Consider: As a dumb example that I don't expect to actually be the case but which gives useful intuition, suppose the genome really wants to wire something up to the tree neuron. Then the genome could encode a handful of images of trees and then once the brain is fully formed it can go through and search for whichever neuron activates the hardest on those 10 images. (Of course it wouldn't actually do literal images, but I expect compressing it down to not actually be that hard.) The more general idea is that we can specify concepts in the world model extensionally by specifying constraints that the concept has to satisfy (for instance, it should activate on these particular data points, or it should have this particular temporal consistency, etc.) Keep in mind this means that the genome just has to vaguely gesture at the concept, and not define the decision boundary exactly.
If this sounds familiar, that's because this basically corresponds to the naivest ELK solution where you hope the reporter generalizes correctly. This probably even works for lots of current NNs. The fact that this works in humans and possibly current NNs, though, is not really surprising to me, and doesn't necessarily imply that ELK continues to work in superintelligence. In fact, to me, the vast majority of the hardness of ELK is making sure it continues to work up to superintelligence/arbitrarily weird ontologies. One can argue for natural abstractions, but that would be an orthogonal argument to the one made in this post. This is why I think (2) is true, though I think the statement would be more obvious if stated as "the solution in humans doesn't scale" rather than "can't be replicated".
Note: I don't expect very many things like this to be hard coded; I expect only a few things to be hard coded and a lot of things to result as emergent interactions of those things. But this post is claiming that the hard coded things can't reference concepts in the world model at all.
As for more abstract concepts: I think encoding the concept of, say, death, is actually extremely doable extensionally. There are a bunch of ways we can point at the concept of death relative to other anticipated experiences/concepts (i.e the thing that follows serious illness and pain, unconsciousness/the thing that's like dreamless sleep, the thing that we observe happens to other beings that causes them to become disempowered, etc). Anecdotally, people do seem to be afraid of death in large part because they're afraid of losing consciousness, the pain that comes before it, the disempowerment of no longer being able to affect things, etc. Again, none of these things have to be exactly pointing to death; they just serve to select out the neuron(s) that encode the concept of death. Further evidence for this theory includes the fact that humans across many cultures and even many animals pretty reliably develop an understanding of death in their world models, so it seems plausible that evolution would have had time to wire things up, and it's a fairly well known phenomenon that very small children who don't yet have well formed world models tend to endanger themselves with seemingly no fear of death. This all also seems consistent with the fact that lots of things we seem fairly hardwired to care about (i.e death, happiness, etc) splinter; we're wired to care about things as specified by some set of points that were relevant in the ancestral environment, and the splintering is because those points don't actually define a sharp decision boundary.
As for why I think more powerful AIs will have more alien abstractions: I think that there are many situations where the human abstractions are used because they are optimal for a mind with our constraints. In some situations, given more computing power you ideally want to model things at a lower level of abstraction. If you can calculate how the coin will land by modelling the air currents and its rotational speed, you want to do that to predict exactly the outcome, rather than abstracting it away as a Bernoulli process. Conversely, sometimes there are high levels of abstraction that carve reality at the joints that require fitting too much stuff in your mind at once, or involve regularities of the world that we haven't discovered yet. Consider how having an understanding of thermodynamics lets you predict macroscopic properties of the system, but only if you already know about and are capable of understanding it. Thus, it seems highly likely that a powerful AI would develop very weird abstractions from our perspective. To be clear, I still think natural abstractions is likely enough to be true that it's worth elevating as a hypothesis under consideration, and a large part of my remaining optimism lies there, but I don't think it's automatically true at all.
Hm. Here's another stab at isolating my disagreement (?) with you:
I agree that, in theory, there exist (possibly extremely complicated) genotypes which do specify extensive hardcoded circuitry which does in practice access certain abstract concepts like death.
(Because you can do a lot if you're talking about "in theory"; probably the case that a few complicated programs which don't seem like they should work, will work, even though most do fail)
I think the more complicated indirect specifications (like associatively learning where the tree abstraction is learned) are "plausible" in the sense that a not-immediately-crisply-debunkable alignment idea seems "plausible", but if you actually try that kind of idea in reality, it doesn't work (with high probability).
But marginalizing over all such implausible "plausible" ideas and adding in evolution's "multiple tries" advantage and adding in some unforeseen clever solutions I haven't yet considered, I reach a credence of about 4-8% for such approaches actually explaining significant portions of human mental events.
So now I'm not sure where we disagree. I don't think it's literally impossible for the genome to access death, but it sure sounds sketchy to me, so I assign it low credence. I agree that (2) is possible, but I assign it low credence. You don't think it's impossible either, but you seem to agree that relatively few things are in fact hardcoded, but also you think (2) is the resolution to the trilemma. But wouldn't that imply (3) instead, even though, perhaps for a select few concepts, (2) is the case?
Here's some misc commentaries:
The fact that this works in humans and possibly current NNs
(Nitpick for clarity) "Fact"? Be careful to not condition on your own hypothesis! I don't think you're literally doing as much, but for other readers, I want to flag this as importantly an inference on your part and not an observation. (LMK if I unintentionally do this elsewhere, of course)
Note: I don't expect very many things like this to be hard coded; I expect only a few things to be hard coded and a lot of things to result as emergent interactions of those things.
Ah, interesting, maybe we disagree less than I thought. Do you have any sense of your numerical value of "a few", or some percentage? I think a lot of the most important shard theory inferences only require that most of the important mental events/biases/values in humans are convergently downstream results of a relatively small set of hardcoded circuitry.
even many animals pretty reliably develop an understanding of death in their world models
I buy that maybe chimps and a small few other animals understand death. But I think "grieves" and "understands death-the-abstract-concept as we usually consider it" and "has a predictive abstraction around death (in the sense that people probably have predictive abstractions around edge detectors before they have a concept of 'edge')" are importantly distinct propositions.
There are a bunch of ways we can point at the concept of death relative to other anticipated experiences/concepts (i.e the thing that follows serious illness and pain, unconsciousness/the thing that's like dreamless sleep, the thing that we observe happens to other beings that causes them to become disempowered, etc)
FWIW I think that lots of these other concepts are also inaccessible and run into various implausibilities of their own.
I like the tree example, and I think it's quite useful (and fun) to think of dumb and speculative way for the genome to access world concept. For instance, in response to "I infer that the genome cannot directly specify circuitry which detects whether you’re thinking about your family", the genome could:
Hardcode a face detector, and store the face most seen during early childhood (for instance to link them to the reward center).
Store faces of people with an odor similar to amniotic fluid odor or with a weak odor (if you're insensitive to your own smell and family member have a more similar smell)
In these cases, I'm not sure if it counts for you as the genome directly specifying circuitry, but it should quite robustly point to a real world concept (which could be "gamed" in certain situations like adoptive parents, but I think that's actually what happens)
I totally buy that the genome can do those things, but think that that it will probably not be locating the "family" concept in your learned world model.
My understanding is: Bob's genome didn't have access to Bob's developed world model (WM) when he was born (because his WM wasn't developed yet). Bob's genome can't directly specify "care about your specific family" because it can't hardcode Bob's specific family's visual or auditory features.
This direct-specification wouldn't work anyways because people change looks, Bob could be adopted, or Bob could be born blind & deaf.
[Check, does the Bob example make sense?]
But, the genome does do something indirectly that consistently leads to people valuing their families (say ~80% of people). The bulleted list (e.g. reaction to being scammed, etc) are other extremely common human values & biases that seems improbable for the genome to directly specify, so the alternative hypothesis is the genome set the initial conditions (along with the environment) such that these are generally convergently learned.
The hope is that this is true, the mechanisms of which can be understood, and these mechanism can be applied to AGI convergently learning desired values.
There seems to be some genetic mechanism for at least things like sexual preferences. It is clearly able to locate concepts in neural circuitry, although with some noise around it (hence, fetishes). Similarly for being instinctively scared of certain things (also with noise, hence fobias).
Agreed, modulo Quintin's reply. But I want to be careful in drawing conclusions about which things we are instinctively scared of—surely some things, but which?
The post isn't saying that there's no way for the genome to influence your preferences / behavior. More like, "the genome faces similar inaccessibility issues as us wrt to learned world models", meaning it needs to use roundabout methods of influencing a person's learned behavior / cognition / values. E.g., the genome can specify some hard-coded rewards for experiential correlates of engaging in sexual activity. Future posts will go into more details on how some of those roundabout ways might work.
The post is phrased pretty strongly (e.g. it makes claims about things being "inaccessible" and "intractable").
Especially given the complexity of the topic, I expect the strength of these claims to be misleading. What one person thinks of as "roundabout methods" another might consider "directly specifying". I find it pretty hard to tell whether I actually disagree with your and Alex's views, or just the way you're presenting them.
The post is phrased pretty strongly (e.g. it makes claims about things being "inaccessible" and "intractable"). Especially given the complexity of the topic, I expect the strength of these claims to be misleading.
I think the strongest claim is in the title, which does concisely describe my current worldview and also Quintin's point that "the genome faces similar inaccessibility issues as us wrt to learned world models."
I went back and forth several times on whether to title the post "Human values & biases seem inaccessible to the genome", but I'm presently sticking to the current title, because I think it's true&descriptive&useful in both of the above senses, even though it has the cost of (being interpreted as) stating as fact an inference which I presently strongly believe.
Beyond that, I think I did a pretty good job of demarcating inference vs observation, of demarcating fact vs model? I'm open to hearing suggested clarifications.
What one person thinks of as "roundabout methods" another might consider "directly specifying".
I meant for the following passage to resolve that ambiguity:
I’m going to say things like “the genome cannot specify circuitry which detects when a person is thinking about death.” This means that the genome cannot hardcode circuitry which e.g. fires when the person is thinking about death, and does not fire when the person is not thinking about death.
But I suppose it still leaves some room to wonder. I welcome suggestions for further clarifying the post (although it's certainly not your responsibility to do so!). I'm also happy to hop on a call / meet up with you sometime, Richard.
I think the way it works is approximately as follows. There is a fixed "ontological" infra-POMDP which is a coarse hard-coded world-model sufficient to define the concepts on which the reward depends (for humans, it would includes concepts such as "other humans"). Then there is a prior which is composed of refinements of this infra-POMDP. The reward depends on state of the ontological IPOMDP, so it is allowed to depend on the concepts of the hard-cord world-model (but not on the concepts which only exist in the refined models). Ofc, this leaves open the question of identifying the conditions for learnability and what to do when we don't have learnability (which is something that we need to handle anyway because of traps).
Another way to "point at outside concepts" is infra-Bayesian physicalism where outside concepts are represented as computations. But, I don't think the human brain in hard-coded to do IBP. These two approaches are also related, as can be seen in section 3, but exploring the relation further is another open problem.
There is a simple mathematical theory of agency, similarly to how there is are simple mathematical theories of e.g. probability of computational complexity
This theory should include, explaining how agents can have goals defined not in terms of sensory data
I have a current best guess to what the outline of this theory looks like, based on (i) simplicity (ii) satisfying natural-seeming desiderata and (iii) ability to prove relevant non-trivial theorems (for example, infra-Bayesian reinforcement learning theory is an ingredient)
This theory of non-sensory goals seems to fit well into the rest of the picture, and I couldn't find a better alternative (for example, it allows talking about learnability, regret bounds and approximating Bayes-optimality)
I admit this explanation is not very legible, since writing a legible explanation would be an entire project. One way to proceed with the debate is, you naming any theory that seems to you at equally good or better (since you seem to have the feeling that there are a lot of equally good or better theories) and me trying to explain why it's actually worse.
I'd note that it's possible for an organism to learn to behave (and think) in accordance with the "simple mathematical theory of agency" you're talking about, without said theory being directly specified by the genome. If the theory of agency really is computationally simple, then many learning processes probably converge towards implementing something like that theory, simply as a result of being optimized to act coherently in an environment over time.
Well, how do you define "directly specified"? If human brains reliably converge towards a certain algorithm, then effectively this algorithm is specified by the genome. The real question is, which parts depends only on genes and which parts depend on the environment. My tentative opinion is that the majority is in the genes, since humans are, broadly speaking, pretty similar to each other. One environment effect is, feral humans grow up with serious mental problems. But, my guess is, this is not because of missing "values" or "biases", but (to 1st approximation) because they lack the ability to think in language. Another contender for the environment-dependent part is cultural values. But even here, I suspect that humans just follow social incentives rather than acquire cultural values as an immutable part of their own utility function. I admit that it's difficult to be sure about this.
I don't classify "convergently learned" as an instance of "directly specified", but rather "indirectly specified, in conjunction with the requisite environmental data." Here's an example. I think that humans' reliably-learned edge detectors in V1 are not "directly specified", in the same way that vision models don't have directly specified curve detectors, but these detectors are convergently learned in order to do well on vision tasks.
If I say "sunk cost is directly specified", I mean something like "the genome specifies neural circuitry which will eventually, in situations where sunk cost arises, fire so as to influence decision-making." However, if, for example, the genome lays out the macrostructure of the connectome and the broad-scale learning process and some reward circuitry and regional learning hyperparameters and some other details, and then this brain eventually comes to implement a sunk-cost bias, I don't call that "direct specification."
I wish I had been more explicit about "direct specification", and perhaps this comment is still not clear. Please let me know if so!
I think that "directly specified" is just an ill-defined concept. You can ask whether A specifies B using encoding C. But if you don't fix C? Then any A can be said to "specify" any B (you can always put the information into C). Algorithmic information theory might come to the rescue by rephrasing the question as: "what is the relative Kolmogorov complexity K(B|A)?" Here, however, we have more ground to stand on, namely there is some function f:G×E→B where G is the space of genomes, E is the space of environments and B is the space of brains. Also we might be interested in a particular property of the brain, which we can think of as a function h:B→P, for example h might be something about values and/or biases. We can then ask e.g. how much mutual information is there between g∈G and h(g,e) vs. between e∈E and h(g,e). Or, we can ask what is more difficult: changing h(g,e) by changing g or by changing e. Where the amount of "difficulty" can be measured by e.g. what fraction of inputs produce the desired output.
So, there are certainly questions that can be asked about, what information comes from the genome and what information comes from the environment. I'm not sure whether this is what you're going for, or you imagine some notion of information that comes from neither (but I have no idea what would that mean)? In any case, I think your thesis would benefit if you specified it more precisely. Given such a specification, it would be possible to assess the evidence more carefully.
I almost totally agree with this post. This comment is just nit picking and speculation.
Evolution has an other advantage, that is relate to "getting a lot's of tries" but also importantly different.
It's not just that evolution got to tinker a lot before landing on a fail proof solution. Evolution don't even need a fail proof solution.
Evolution is "trying to find" a genome, which in interaction with reality, forms a brain that causes that human to have lots of kids. Evolution found a solution that mostly works, but sometimes don't. Some humans decided that celibacy was the cool thing to do, or got too obsessed with something else to take the time to have a family. Note that this is different from how the recent distributional shift (mainly access to birth control, but also something about living in a rich country) have caused previously children rich populations to have on average less than replacement birth rate.
Evolution is fine with getting the alignment right in most of the minds, or even just a minority, if they are good enough at making babies. We might want better guarantees than that?
Going back to alignment with other humans. Evolution did not directly optimise for human to human alignment, but still produced humans that mostly care about other humans. Studying how this works seems like a great idea! But also evolution did not exactly nail human to human alignment. Most, but defiantly not all humans care about other humans. Ideally we want to build something much much more robust.
Crazy (probably bad) idea: If we can build a AI design + training regime that mostly but not certainly turn out human aligned AIs, and where the uncertainty is mostly random noise that is uncorrelated between AIs. Then maybe we should build lots of AIs with similar power and hope that because the majority are aligned, this will turn out fine for us. Like how you don't need every single person in a country to care about animals, in order for that country to implement animal protection laws.
But also evolution did not exactly nail human to human alignment. Most, but defiantly not all humans care about other humans.
Here's a consideration which Quintin pointed out. It's actually a good thing that there is variance in human altruism/caring. Consider a uniform random sample of 1024 people, and grade them by how altruistic / caring they are (in whatever sense you care to consider). The most aligned and median-aligned people will have a large gap. Therefore, by applying only 10 bits of optimization pressure to the generators of human alignment (in the genome+life experiences), you can massively increase the alignment properties of the learned values. This implies that it's relatively easy to optimize for alignment (in the human architecture & if you know what you're doing).
Conversely, people have ~zero variance in how well they can fly. If it were truly hard (in theory) to improve the alignment of a trained policy, people would exhibit far less variance in their altruism, which would be bad news for training an AI which is even more altruistic than people are.
What if I push this line of thinking to the extreme. If I just pick agents randomly from the space of all agents, then this should be maximally random, and that should be even better. Now the part where we can mine information of alignment from the fact that humans are at least some what aligned is gone. So this seems wrong. What is wrong here? Probably the fact that if you pick agents randomly from the space of all agents, you don't get greater variation of aliment, compare to if you pick random humans, because probably all the random agents you pick are just non aligned.
So what is doing most of the work here is that humans are more aligned than random. Which I expect you to agree on. What you are also saying (I think) is that the tale end level of alignment in humans is more important in some way than the mean or average level of aliment in humans. Because if we have the human distribution, we are just a few bits from locating the tail of the distribution. E.g. we are 10 bits away from locating the top 0.1 percentile. And because the tail is what matters, randomness is in our favor.
After talking with Richard Ngo, I now think there's about an 8% chance that several interesting mental events are accessed by the genome; I updated upwards from 4%. I still think it's highly implausible that most of them are.
Updating down to 3%, in part due to 1950's arguments on ethology:
How do we want to explain the origins of behavior? And [Lehrman's] critique seems to echo some of the concerns with evolutionary psychology. His approach can be gleaned from his example on the pecking behavior of chicks. Lorenz attributed this behavior to innate forces:The chicks are born with the tendency to peck; it might require just a bit of maturation. Lehrman points out that research by Kuo provides an explanation based on the embryonic development of the chick. The pecking behavior can actually be traced back to movements that developed while the chick was still unhatched. Hardly innate! The main point Lehrman makes: If we claim that something is innate, we stop the scientific investigation without fully understanding the origin of the behavior. This leaves out important – and fascinating – parts of the explanation because we think we’ve answered the question. As he puts it: “the statement “It is innate” adds nothing to an understanding of the developmental process involved”
I feel like the concept of "neural address" is incompletely described, and the specifics may matter. For example, a specific point in the skull, yeah, is a bad way to address a specific concept, between individuals. However, there might be, say, particular matching structures that tend to form around certain ideas, and searching on those structures might be a better way of addressing a particular concept. (Probably still not good, but it hints in the direction that there may be better ways of formulating a neural address that maybe WOULD be sufficiently descriptive. I don't know any particularly good methods, of the top of my head, though, and your point may turn out correct.)
My best guess is, the genome can guess where concepts are going to form, because it knows in advance:
Where low-level concepts like "something hot is touching my elbow" are going to form
The relative distances between concepts (The game Codenames is a good demonstration of this)
Loosely speaking, it feels like knowing the relative distances between concepts should determine the locations of all of the concepts "up to rotation," and then knowing the locations of the low-level concepts should determine the "angle of rotation," at which point everything is determined.
I think this is how the brain does sexuality, as an earlier commenter mentioned. For males, it guesses where you will place the concept "I am having sex with a woman" and hardwires that location to reward.
I think fetishes and homosexuality (which are probably the same phenomenon) arise when these assumptions break down and you place your concepts in unexpected places. For example, the concept of "man" and "woman" are symmetrical enough that it may be possible to switch their locations, depending upon your experiences as a young child. This propagates up to higher level concepts so that the address which would have held "I am having sex with a woman" instead holds "I am having sex with a man."
I really like this as an explanation for homosexuality in particular, because it explains why evolution would allow something so apparently counterproductive. The answer is very LessWrong in flavor: it's just an alignment failure. If you make a truly flexible intelligence that learns its concepts from scratch, you're going to have a hard time making it do what you want. Evolution was ok with the tradeoff.
Loosely speaking, it feels like knowing the relative distances between concepts should determine the locations of all of the concepts "up to rotation," and then knowing the locations of the low-level concepts should determine the "angle of rotation," at which point everything is determined.
In the second appendix, I explain why this seemingly can't be true. I think the counterpoint I give is decisive.
If you make a truly flexible intelligence that learns its concepts from scratch, you're going to have a hard time making it do what you want.
One person's modus ponens is another's modus tollens; This is opposite of the inference I draw from the reasoning I present in the post. Despite information inaccessibility, despite the apparent constraint that the genome defines reward via shallow sensory proxies, people's values are still bound to predictable kinds of real-world objects like dogs and food and family (although, of course, human values are not bound to inclusive genetic fitness in its abstract form; I think I know why evolution couldn't possibly have pulled that off; more on that in later posts).
Related to Steve Byrnes’ Social instincts are tricky because of the “symbol grounding problem.” I wouldn’t have had this insight without several great discussions with Quintin Pope.
TL;DR: It seems hard to scan a trained neural network and locate the AI’s learned “tree” abstraction. For very similar reasons, it seems intractable for the genome to scan a human brain and back out the “death” abstraction, which probably will not form at a predictable neural address. Therefore, I infer that the genome can’t directly make us afraid of death by e.g. specifying circuitry which detects when we think about death and then makes us afraid. In turn, this implies that there are a lot of values and biases which the genome cannot hardcode.
In order to understand the human alignment situation confronted by the human genome, consider the AI alignment situation confronted by human civilization. For example, we may want to train a smart AI which learns a sophisticated world model, and then motivate that AI according to its learned world model. Suppose we want to build an AI which intrinsically values trees. Perhaps we can just provide a utility function that queries the learned world model and counts how many trees the AI believes there are.
Suppose that the AI will learn a reasonably human-like concept for “tree.” However, before training has begun, the learned world model is inaccessible to us. Perhaps the learned world model will be buried deep within a recurrent policy network, and buried within the world model is the “trees” concept. But we have no idea what learned circuits will encode that concept, or how the information will be encoded. We probably can’t, in advance of training the AI, write an algorithm which will examine the policy network’s hidden state and reliably back out how many trees the AI thinks there are. The AI’s learned concept for “tree” is inaccessible information from our perspective.
Likewise, the human world model is inaccessible to the human genome, because the world model is probably in the cortex and the cortex is probably randomly initialized.[1] Learned human concepts are therefore inaccessible to the genome, in the same way that the “tree” concept is a priori inaccessible to us. Even the broad area where language processing occurs varies from person to person, to say nothing of the encodings and addresses of particular learned concepts like “death.”
I’m going to say things like “the genome cannot specify circuitry which detects when a person is thinking about death.” This means that the genome cannot hardcode circuitry which e.g. fires when the person is thinking about death, and does not fire when the person is not thinking about death. The genome does help indirectly specify the whole adult brain and all its concepts, just like we indirectly specify the trained neural network via the training algorithm and the dataset. That doesn’t mean we can tell when the AI thinks about trees, and it doesn’t mean that the genome can “tell” when the human thinks about death.
When I’d previously thought about human biases (like the sunk cost fallacy) or values (like caring about other people), I had implicitly imagined that genetic influences could directly affect them (e.g. by detecting when I think about helping my friends, and then producing reward). However, given the inaccessibility obstacle, I infer that this can’t be the explanation. I infer that the genome cannot directly specify circuitry which:
Conversely, the genome can access direct sensory observables, because those observables involve a priori-fixed “neural addresses.” For example, the genome could hardwire a cute-face-detector which hooks up to retinal ganglion cells (which are at genome-predictable addresses), and then this circuit could produce physiological reactions (like the release of reward). This kind of circuit seems totally fine to me.
In total, information inaccessibility is strong evidence for the genome hardcoding relatively simple[2] cognitive machinery. This, in turn, implies that human values/biases/high-level cognitive observables are produced by relatively simpler hardcoded circuitry, specifying e.g. the learning architecture, the broad reinforcement learning and self-supervised learning systems in the brain, and regional learning hyperparameters. Whereas before it seemed plausible to me that the genome hardcoded a lot of the above bullet points, I now think that’s pretty implausible.
When I realized that the genome must also confront the information inaccessibility obstacle, this threw into question a lot of my beliefs about human values, about the complexity of human value formation, and about the structure of my own mind. I was left with a huge puzzle. If we can’t say “the hardwired circuitry down the street did it”, where do biases come from? How can the genome hook the human’s preferences into the human’s world model, when the genome doesn’t “know” what the world model will look like? Why do people usually navigate ontological shifts properly, why don’t they want to wirehead, why do they almost always care about other people if the genome can’t even write circuitry that detects and rewards thoughts about people?
A fascinating mystery, no? More on that soon.
Thanks to Adam Shimi, Steve Byrnes, Quintin Pope, Charles Foster, Logan Smith, Scott Viteri, and Robert Mastragostino for feedback.
Appendix: The inaccessibility trilemma
The logical structure of this essay is that at least one of the following must be true:
In my opinion, either (1) or (3) would be enormous news for AI alignment. More on (3)’s importance in future essays.
Appendix: Did evolution have advantages in solving the information inaccessibility problem?
Yes, and no. In a sense, evolution had “a lot of tries” but is “dumb”, while we have very few tries at AGI while ourselves being able to do consequentialist planning.
In the AI alignment problem, we want to be able to back out an AGI’s concepts, but we cannot run lots of similar AGIs and select for AGIs with certain effects on the world. Given the natural abstractions hypothesis, maybe there’s a lattice of convergent abstractions—first learn edge detectors, then shape detectors, then people being visually detectable in part as compositions of shapes. And maybe, for example, people tend to convergently situate these abstractions in similar relative neural locations: The edge detectors go in V1, then the shape detectors are almost always in some other location, and then the person-concept circuitry is learned elsewhere in a convergently reliable relative position to the edge and shape detectors.
But there’s a problem with this story. A congenitally blind person develops dramatically different functional areas, which suggests in particular that their person-concept will be at a radically different relative position than the convergent person-concept location in sighted individuals. Therefore, any genetically hardcoded circuit which checks at the relative address for the person-concept which is reliably situated for sighted people, will not look at the right address for congenitally blind people. Therefore, if this story were true, congenitally blind people would lose any important value-formation effects ensured by this location-checking circuit which detects when they’re thinking about people. So, either the human-concept-location-checking circuit wasn’t an important cause of the blind person caring about other people (and then this circuit hasn’t explained the question we wanted it to, which is how people come to care about other people), or there isn’t such a circuit to begin with. I think the latter is true, and the convergent relative location story is wrong.
But the location-checking circuit is only one way the human-concept-detector could be implemented. There are other possibilities. Therefore, given enough selection and time, maybe evolution could evolve a circuit which checks whether you’re thinking about other people. Maybe. But it seems implausible to me (<4%). I’m going to prioritize explanations for “most people care about other people” which don’t require a fancy workaround.
EDIT: After talking with Richard Ngo, I now think there's about an 8% chance that several interesting mental events are accessed by the genome; I updated upwards from 4%.
EDIT 8/29/22: Updating down to 3%, in part due to 1950's arguments on ethology:
Human values can still be inaccessible to the genome even if the cortex isn’t learned from scratch, but learning-from-scratch is a nice and clean sufficient condition which seems likely to me.
I argue that the genome probably hardcodes neural circuitry which is simple relative to hardcoded “high-status detector” circuitry. Similarly, the code for a machine learning experiment is simple relative to the neural network it trains.