
What a compute-centric framework says about AI takeoff speeds
9Daniel Kokotajlo
The takeoffspeeds.com model Davidson et al worked on is still (unfortunately) the world's best model of AGI takeoff. I highly encourage people to play around with it, perhaps even to read the research behind it, and I'm glad LessWrong is a place that collects and rewards work like this.
As part of my work for Open Philanthropy I’ve written a draft report on AI takeoff speeds, the question of how quickly AI capabilities might improve as we approach and surpass human-level AI. Will human-level AI be a bolt from the blue, or will we have AI that is nearly as capable many years earlier?
Most of the analysis is from the perspective of a compute-centric framework, inspired by that used in the Bio Anchors report, in which AI capabilities increase continuously with more training compute and work to develop better AI algorithms.
This post doesn’t summarise the report. Instead I want to explain some of the high-level takeaways from the research which I think apply even if you don’t buy the compute-centric framework.
The framework
h/t Dan Kokotajlo for writing most of this section
This report accompanies and explains https://takeoffspeeds.com (h/t Epoch for building this!), a user-friendly quantitative model of AGI timelines and takeoff, which you can go play around with right now. (By AGI I mean “AI that can readily[1] perform 100% of cognitive tasks” as well as a human professional; AGI could be many AI systems working together, or one unified system.)
The framework was inspired by and builds upon the previous “Bio Anchors” report. The “core” of the Bio Anchors report was a three-factor model for forecasting AGI timelines:
Dan’s visual representation of Bio Anchors report
Once there’s been enough algorithmic progress, and training runs are big enough, we can train AGI. (How much is enough? That depends on the first factor!)
This draft report builds a more detailed model inspired by the above. It contains many minor changes and two major ones.
The first major change is that algorithmic and hardware progress are no longer assumed to have steady exponential growth. Instead, I use standard semi-endogenous growth models from the economics literature to forecast how the two factors will grow in response to hardware and software R&D spending, and forecast that spending will grow over time. The upshot is that spending accelerates as AGI draws near, driving faster algorithmic (“software”) and hardware progress.
The key dynamics represented in the model. “Software” refers to the quality of algorithms for training AI.
The second major change is that I model the effects of AI systems automating economic tasks – and, crucially, tasks in hardware and software R&D – prior to AGI. I do this via the “effective FLOP gap:” the gap between AGI training requirements and training requirements for AI that can readily perform 20% of cognitive tasks (weighted by economic-value-in-2022). My best guess, defended in the report, is that you need 10,000X more effective compute to train AGI. To estimate the training requirements for AI that can readily perform x% of cognitive tasks (for 20 < x < 100), I interpolate between the training requirements for AGI and the training requirements for AI that can readily perform 20% of cognitive tasks.
Modeling the cognitive labor done by pre-AGI systems makes timelines shorter. It also gives us a richer language for discussing and estimating takeoff speeds. The main metric I focus on is “time from AI that could readily[2] automate 20% of cognitive tasks to AI that could readily automate 100% of cognitive tasks”. I.e. time from 20%-AI to 100%-AI.[3] (This time period is what I’m referring to when I talk about the duration of takeoff, unless I say otherwise.)
My personal probabilities[4] are still very much in flux and are not robust.[5] My current probabilities, conditional on AGI happening by 2100, are:
Those numbers are time from 20%-AI to 100%-AI, for cognitive tasks in the global economy. One factor driving fast takeoff here is that I expect AI automation of AI R&D to happen before AI automation of the global economy.[6] So by the time that 20% of tasks in the global economy could be readily automated, I expect that more than 20% of AI R&D will be automated, which will drive faster AI progress.
If I instead start counting from the time at which 20% of AI R&D can be automated, and stop counting when 100% of AI R&D can be automated, this factor goes away and my takeoff speeds are slower:
(Unless I say otherwise, when I talk about the duration of takeoff I’m referring to the time 20%-AI to 100%-AI for cognitive tasks in the global economy, not AI R&D.)
It’s important to note that my median AGI training requirements are pretty large - 1e36 FLOP using 2020 algorithms. Using lower requirements makes takeoff significantly faster. If my median AGI training requirements were instead ~1e31 FLOP with 2020 algorithms, my takeoff speeds would be:
The report also discusses the “time from AGI to superintelligence”. My best guess is that this takes less than a year absent humanity choosing to go slower (which we definitely should!).
Takeaways about capabilities takeoff speed
I find it useful to distinguish capabilities takeoff – how quickly AI capabilities improve around AGI – from impact takeoff – how quickly AI’s impact on a particular domain grows around AGI. For example, the latter is much more affected by deployment decisions and various bottlenecks.
The metric “time from 20%-AI to 100%-AI” is about capabilities, not impact, because 20%-AI is defined as AI that could readily automate 20% of economic tasks, not as AI that actually does automate them.
Even without any discontinuities, takeoff could last < 1 year
Even if AI progress is continuous, without any sudden kinks, the slope of improvement could be steep enough that takeoff is very fast.
Even in a continuous scenario, I put ~15% on takeoff lasting <1 year, and ~60% on takeoff lasting <5 years.[7] Why? On a high level, because:
Going into more detail:
With Chinchilla scaling, a 3X bigger model gets 3X more data during training. But human lifetime learning only lasts 1-2X longer than chimp lifetime learning.[8]
So intelligence might improve more from a 3X increase in model size with Chinchilla scaling than from chimps to humans.
Algorithmic progress is already very fast. OpenAI estimates a 16 month doubling time for algorithmic efficiency on ImageNet; an recent Epoch analysis estimates just 10 months for the same quantity. My sense is that progress is if anything faster for LMs.
Hardware progress is already very fast. Epoch estimates that FLOP/$ has been doubling every 2.5 years.
Spending on AI development – AI training runs, AI software R&D, and hardware R&D – might rise rapidly after we have 20%-AI, and the strategic and economic benefits of AI are apparent.
20%-AI could readily add ~$10tr/year to global GDP.[9] Compared to this figure, investments in hardware R&D (~$100b/year) and AI software R&D (~$20b/year) are low.
For <1 year takeoffs, fast scale-up of spending on AI training runs, simply by using a larger fraction of the world’s chips, plays a central role.
Once we have 20%-AI (AI that can readily[10] automate 20% of cognitive tasks in the general economy), AI itself will accelerate AI progress. The easier AI R&D is to automate compared to the general economy, the bigger this effect.
Combining the above, I think the “effective compute” on training runs (which incorporates better algorithms) will probably rise by >5X each year between 20%-AI and 100%-AI, and could rise by 100X each year.
We should assign some probability to takeoff lasting >5 years
I have ~40% on takeoff lasting >5 years. On a high-level my reasons are:
Going into more detail:
The key reason is that AI may have a strong comparative advantage at some tasks over other tasks, compared with humans. Its comparative advantages might allow it to automate 20% of tasks long before it can automate the full 100%. The bullets below expand on this basic point.
AI, and computers more generally, already achieve superhuman performance in many domains by exploiting massive AI-specific advantages (lots of experience/data, fast thinking, reliability, memorisation). It might be far harder for AI to automate tasks where these advantages aren’t as relevant.
We can visualise this using (an adjusted version of) the graph Dan Kokotajlo drew in his review of Joe Carlsmith’s report on power-seeking AI.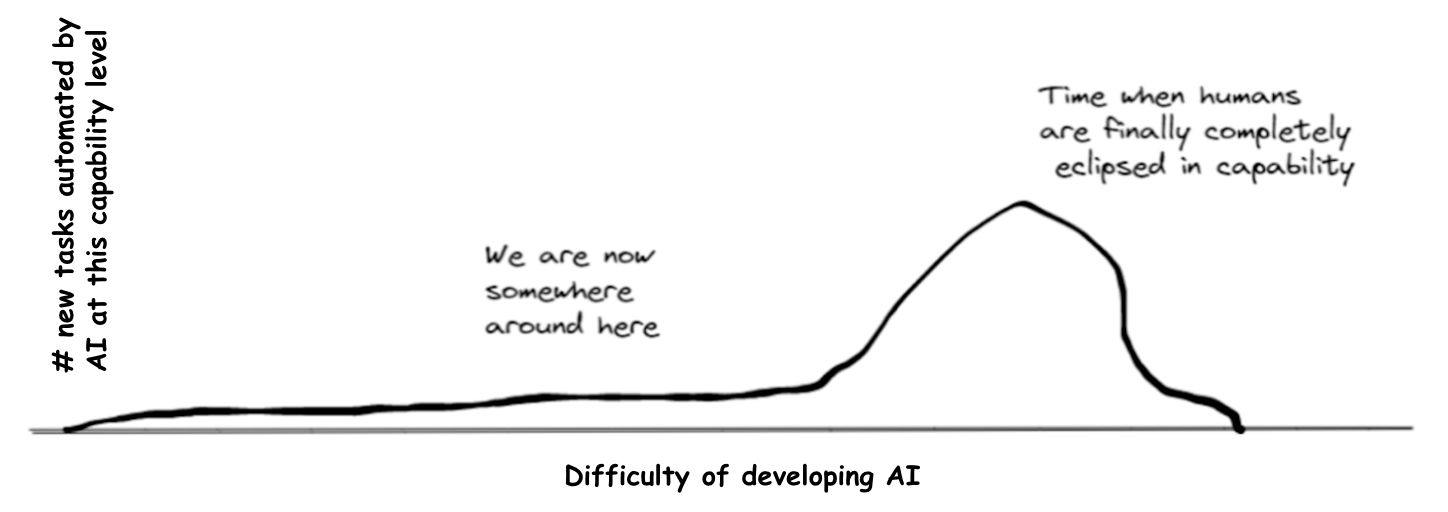 We’re currently in the left tail, where AI’s massive comparative advantages allow it to automate certain tasks despite being much less capable than humans overall. If AI automates 20% of tasks before the big hump, or the hump is wide, it will be much easier to develop 20%-AI than 100%-AI.
We’re currently in the left tail, where AI’s massive comparative advantages allow it to automate certain tasks despite being much less capable than humans overall. If AI automates 20% of tasks before the big hump, or the hump is wide, it will be much easier to develop 20%-AI than 100%-AI.
Outside of AI, there’s generally a large precedent for humans finding simple, dumb ways to automate significant fractions of labour.
Within AI, there are many mechanisms that could give AI comparative advantages at some tasks but not others. AI is better placed to perform tasks with the following features:
AI can learn to perform the task with “short horizon training”, without requiring “long horizon training”.[11]
The task is similar to what AI is doing during pre-training (e.g. similar to “next word prediction”, in the case of large language models).
It’s easier to get large amounts of training data for the task, e.g. from human demonstrations.
Memorising lots of information improves task performance.
It’s important to “always be on” (no sleep), or to consistently maintain focus (no getting bored or slacking).
It’s easier to verify that an answer is correct than to generate the correct answer. (This helps to generate training data and allows us to trust AI outputs.)
The task doesn’t require strong sim2real transfer.
The downside of poor performance is limited. (We might not trust AI in scenarios where a mistake is catastrophic, e.g. driving.)
Human brains were “trained” by evolution and then lifetime learning in a pretty different way to how AIs are trained, and humans seem to have pretty different brain architectures to AIs in many ways. So humans might have big comparative advantages over AIs in certain domains. This could make it very difficult to develop 100%-AI.
GPT-N looks like it will solve some LM benchmarks with ~4 OOMs less training FLOP. In other words, it has strong “comparative advantages” at some benchmarks over others. I expect cognitive tasks throughout the entire economy to have more variation along many dimensions than these LM benchmarks, suggesting this example underestimates the difficulty gap between developing 20%-AI and 100%-AI.
It’s notable that most of the evidence discussed above for a small difficulty gap between 20%-AI and 100%-AI (in particular “chimps vs humans” and “brain size - IQ correlations”) completely ignore this point about “large comparative advantage at certain tasks” by assuming intelligence is on a one-dimensional spectrum.[12]
I find it most plausible that there’s a big difficulty gap between 20%-AI and 100%-AI if 100%-AI is very difficult to develop.
Takeoff won’t last >10 years unless 100%-AI is very hard to develop
As discussed above, AI progress is already very fast and will probably become faster once we have 20%-AI. If you think that even 10 years of this fast rate of progress won’t be enough to reach 100%-AI, that implies that 100%-AI is way harder to develop than 20%-AI.
In addition, I think that today’s AI is quite far from 20%-AI: its economic impact is pretty limited (<$100b/year), suggesting it can’t readily[13] automate even 1% of tasks. So I personally expect 20%-AI to be pretty difficult to develop compared to today’s AI.
This means that, if takeoff lasts >10 years, 100%-AI is a lot harder to develop than 20%-AI, which is itself a lot harder to develop than today’s AI. This all only works out if you think that 100%-AI is very difficult to develop. Playing around with the compute-centric model, I find it hard to get >10 year takeoff without assuming that 100%-AI would have taken >=1e38 FLOP to train with 2020 algorithms (which was the conservative “long horizon” anchor in Bio Anchors).
Time from AGI to superintelligence is probably less than 1 year
Recall that by AGI I mean AI that can readily perform ~100% of cognitive tasks as well as a human professional. By superintelligence I mean AI that very significantly surpasses humans at ~100% of cognitive tasks. My best guess is that the time between these milestones is less than 1 year, the primary reason being the massive amounts of AI labour available to do AI R&D, once we have AGI. More.
Takeaways about impact takeoff speed
Here I mostly focus on economic impact.
If we align AGI, I weakly expect impact takeoff to be slower than capabilities takeoff
I think there will probably just be a few years (~3 years) from 20%-AI to 100%-AI (in a capabilities sense). But, if AI is aligned, I think time from actually deploying AI in 20% to >95% of economic tasks will take many years (~10 years):
I’m not confident about this. Here are some countervailing considerations:
Many of the above points, on both sides, apply more weakly to the impact of AI on AI R&D than on the general economy. For example, I expect regulation to apply less strongly in AI R&D, and also for lab incentives to favour deployment of AIs in AI R&D (especially software R&D). So I expect impact takeoff within AI R&D to match capabilities takeoff fairly closely.
If we don’t align AGI, I expect impact takeoff to be faster than capabilities takeoff
If AGI isn’t aligned, then AI’s impact could increase very suddenly at the point when misaligned AIs first collectively realise that they can disempower humanity and try to do so. Before this point, human deployment decisions (influenced by regulation, general caution, slow decision making, etc) limit AI’s impact; afterwards AIs forcibly circumvent these decisions.[14]
Some chance of <$3tr/year economic impact from AI before we have AI that could disempower humanity
I’m at ~15% for this. (For reference, annual revenues due to AI today are often estimated at ~$10-100b,[15] though this may be smaller than AI’s impact on GDP.)
Here are some reasons this could happen:
Why am I not higher on this?
$3tr/year only corresponds to automating ~6% of cognitive tasks;[16] I expect AI will be able to perform >60%, and probably >85% of cognitive tasks before it can disempower humanity. That’s a pretty big gap in AI capabilities!
People will be actively trying to create economic value from AI and also actively trying to prevent AI from being able to disempower humanity.
I have a fairly high estimate of the difficulty of developing AGI. I think we’re unlikely to develop AGI by 2030, by which time AI may already be adding >$3tr/year to world GDP.
My “15%” probability here feels especially non-robust, compared to the others in this post.
Takeaways about AI timelines
Multiple reasons to have shorter timelines compared to what I thought a few years ago
Here’s a list (including some repetition from above):
If AGI can’t be trained by ~2035 (as I think is likely), then we’ll have a lot of runtime compute lying around, e.g. enough to run 100s of millions of SOTA AIs.[17]
It may be possible to leverage this runtime compute to “boost” the capabilities of pre-AGI systems. This would involve using existing techniques for this like “chain of thought”, “best of N sampling” and MCTS, as well as finding novel techniques. As a result, we might fully automate AI R&D much sooner than we otherwise would.
I think this factor alone could easily shorten timelines by ~5 years if AGI training requirements are my best guess (1e36 FLOP with 2020 algorithms). It shortens timelines more(/less) if training requirements are bigger(/smaller).
Harder than I thought to avoid AGI by 2060
To avoid AGI by 2060, we cannot before 2040 develop “AI that is so good that AGI follows within a couple of decades due to [rising investment and/or AI itself accelerating AI R&D progress]”. As discussed above, this latter target might be much easier to hit. So my probability of AGI by 2060 has risen.
Relatedly, I used to update more on growth economist-y concerns like “ah but if AI can automate 90% of tasks but not the final 10%, that will bottleneck its impact”. Now I think “well if AI automates 90% of cognitive tasks that will significantly accelerate AI R&D progress and attract more investment in AI, so it won’t be too long before AI can perform 100%”.
Takeaways about the relationship between takeoff speed and AI timelines
The easier AGI is to develop, the faster takeoff will be
Probably the biggest determinant of takeoff speeds is the difficulty gap between 100%-AI and 20%-AI. If you think that 100%-AI isn’t very difficult to develop, this upper-bounds how large this gap can be and makes takeoff faster.
In the lower scenario AGI is easier to develop and, as a result, takeoff is faster.
Holding AGI difficulty fixed, slower takeoff → earlier AGI timelines
If takeoff is slower, there is a bigger difficulty gap between AGI and “AI that significantly accelerates AI progress”. Holding fixed AGI difficulty, that means “AI that significantly accelerates AI progress” happens earlier. And so AGI happens earlier. (This point has been made before.)
Two scenarios with the same AGI difficulty. In the lower scenario takeoff is slower and, as a result, AGI happens sooner.
The model in the report quantifies this tradeoff. When I play around with it I find that, holding the difficulty of AGI constant, decreasing the time from 20%-AI to 100%-AI by two years delays 100%-AI by three years.[19] I.e. make takeoff two years shorter → delay 100%-AI by three years.
How does the report relate to previous thinking about takeoff speeds?
Eliezer Yudkowsky’s Intelligence Explosion Microeconomics
Paul Christiano
I think Paul Christiano’s 2018 blog post does a good job of arguing that takeoff is likely to be continuous. It also claims that takeoff will probably be slow. My report highlights the possibility that takeoff could be continuous but still be pretty fast, and the Monte Carlo analysis spits out the probability that takeoff is “fast” according to the definitions in the 2018 blog post.
More.
Notes
By “AI can readily perform a task” I mean “performing the task with AI could be done with <1 year of work spent engineering and rearranging workflows, and this would be profitable”. ↩︎
Recall that “readily” means “automating the task with AI would be profitable and could be done within 1 year”. ↩︎
100%-AI is different from AGI only in that 100%-AI requires that we have enough runtime compute to actually automate all instances of cognitive tasks that humans perform, whereas AGI just requires that AI could perform any (but not all) cognitive tasks. ↩︎
To arrive at these probabilities I took the results of the model’s Monte Carlo analysis and adjusted them based on the model’s limitations – specifically the model excluding certain kinds of discontinuities in AI progress and ignoring certain frictions to developing and deploying AI systems. ↩︎
Not robust means that further arguments and evidence could easily change my probabilities significantly, and that it’s likely that in hindsight I’ll think these numbers were unreasonable given the current knowledge available to me. ↩︎
Why? Firstly, I think the cognitive tasks in AI R&D will be particularly naturally suited for AI automation, e.g. because there is lots of data for writing code, AI R&D mostly doesn’t require manipulating things in the real world, and indeed AI is already helping with AI R&D. Secondly, I expect AI researchers to prioritise automating AI R&D over other areas because they’re more familiar with AI R&D tasks, there are fewer barriers to deploying AI in their own workflows (e.g. regulation, marketing to others), and because AI R&D will be a very valuable part of the economy when we’re close to AGI. ↩︎
These probabilities are higher than the ones above because here I’m ignoring types of discontinuities that aren’t captured by having a small “effective FLOP gap” between 20%-AI and 100%-AI. ↩︎
Chimps reach sexual maturity around 7 and can live until 60, suggesting humans have 1-2X more time for learning rather than 3X. ↩︎
World GDP is ~$100tr, about half of which is paid to human labour. If AI automates 20% of that work, that’s worth ~$10tr/year. ↩︎
Reminder: “AI can readily automate X” means “automating X with AI would be profitable and could be done within 1 year”. ↩︎
The “horizon length” concept is from Bio Anchors. Short horizons means that each data point requires the model to “think” for only a few seconds; long horizons means that each data point requires the model to “think” for months, and so training requires much more compute. ↩︎
Indeed, my one-dimensional model of takeoff speeds predicts faster takeoff. ↩︎
Reminder: “AI can readily automate X” means “automating X with AI would be profitable and could be done within 1 year”. ↩︎
This falls under “Superhuman AIs quickly circumvent barriers to deployment”, from above. ↩︎
E.g. here, here, here, here. I don’t know how reliable these estimates are, or even their methodologies. ↩︎
World GDP is ~$100tr, about half of which is paid to human labour. If AI automates 6% of that work, that’s worth ~$3tr/year. ↩︎
Here's a rough BOTEC (h/t Lukas Finnveden). ↩︎
Link to diagrams. ↩︎
Reminder: x%-AI is AI that could readily automate x% of cognitive tasks, weighted by their economic value in 2020. ↩︎
By “ substantial discontinuous jump” I mean “>10 years of progress at previous rates occurred on one occasion”. (h/t AI impacts for that definition) ↩︎