I agree that ultimately AI systems will have an understanding built up from the world using deliberate cognitive steps (in addition to plenty of other complications) not all of which are imitated from humans.
The ELK document mostly focuses on the special case of ontology identification, i.e. ELK for a directly learned world model. The rationale is: (i) it seems like the simplest case, (ii) we don't know how to solve it, (iii) it's generally good to start with the simplest case you can't solve, (iv) it looks like a really important special case, which may appear as a building block or just directly require the same techniques as the general problem.
We briefly discuss the more general situation of learned optimization here. I don't think that discussion is particularly convincing, it just describes how we're thinking about it.
On the bright side, it seems like our current approach to ontology identification (based on anomaly detection) would have a very good chance of generalizing to other cases of ELK. But it's not clear and puts more strain on the notion of explanation we are using.
At the end of the day I strongly suspect the key question is whether we can make something like a "probabilistic heuristic argument" about the reasoning learned by ML systems, explaining why they predict (e.g.) images of human faces. We need arguments detailed enough to distinguish between sensor tampering (or lies) and real anticipated faces, i.e. they may be able to treat some claims as unexplained empirical black boxes but they can't have black boxes so broad that they would include both sensor tampering and real faces.
If such arguments exist and we can find them then I suspect we've dealt with the hard part of alignment. If they don't exist or we can't find them then I think we don't really have a plausible angle of attack on ELK. I think a very realistic outcome is that it's a messy empirical question, in which case our contribution could be viewed as clarifying an important goal for "interpretability" but success will ultimately come down to a bunch of empirical research.
Thanks!
Thinking about it more, I think my take (cf. Section 4.1) is kinda like “Who knows, maybe ontology-identification will turn out to be super easy. But even if it is, there’s this other different problem, and I want to start by focusing on that”.
And then maybe what you’re saying is kinda like “We definitely want to solve ontology-identification, even if it doesn’t turn out to be super easy, and I want to start by focusing on that”.
If that’s a fair summary, then godspeed. :)
(I’m not personally too interested in learned optimization because I’m thinking about something closer to actor-critic model-based RL, which sorta has “optimization” but it’s not really “learned”.)
I think you're missing the primary theory of change for all of these techniques, which I would say is particularly compatible with your "follow-the-trying" approach.
While all of these are often analyzed from the perspective of "suppose you have a potentially-misaligned powerful AI; here's what would happen", I view that as an analysis tool, not the primary theory of change.
The theory of change that I most buy is that as you are training your model, while it is developing the "trying", you would like it to develop good "trying" and not bad "trying", and one way to make this more likely is to notice when bad "trying" develops and penalize it if so, with the hope that this leads to good "trying".
This is illustrated in the theory-of-change diagram below, where to put it in your terminology:
- Each of the clouds (red or blue) consists of models that are "trying"
- The grey models outside of clouds are models that are not "trying" or are developing "trying"
- The "deception rewarded" point occurs when a model that is developing "trying" does something bad due to instrumental / deceptive reasoning
- The "apply alignment technique" means that you use debate / RRM / ELK instead of vanilla RLHF, which allows you to notice it doing something bad and penalize it instead of rewarding it.
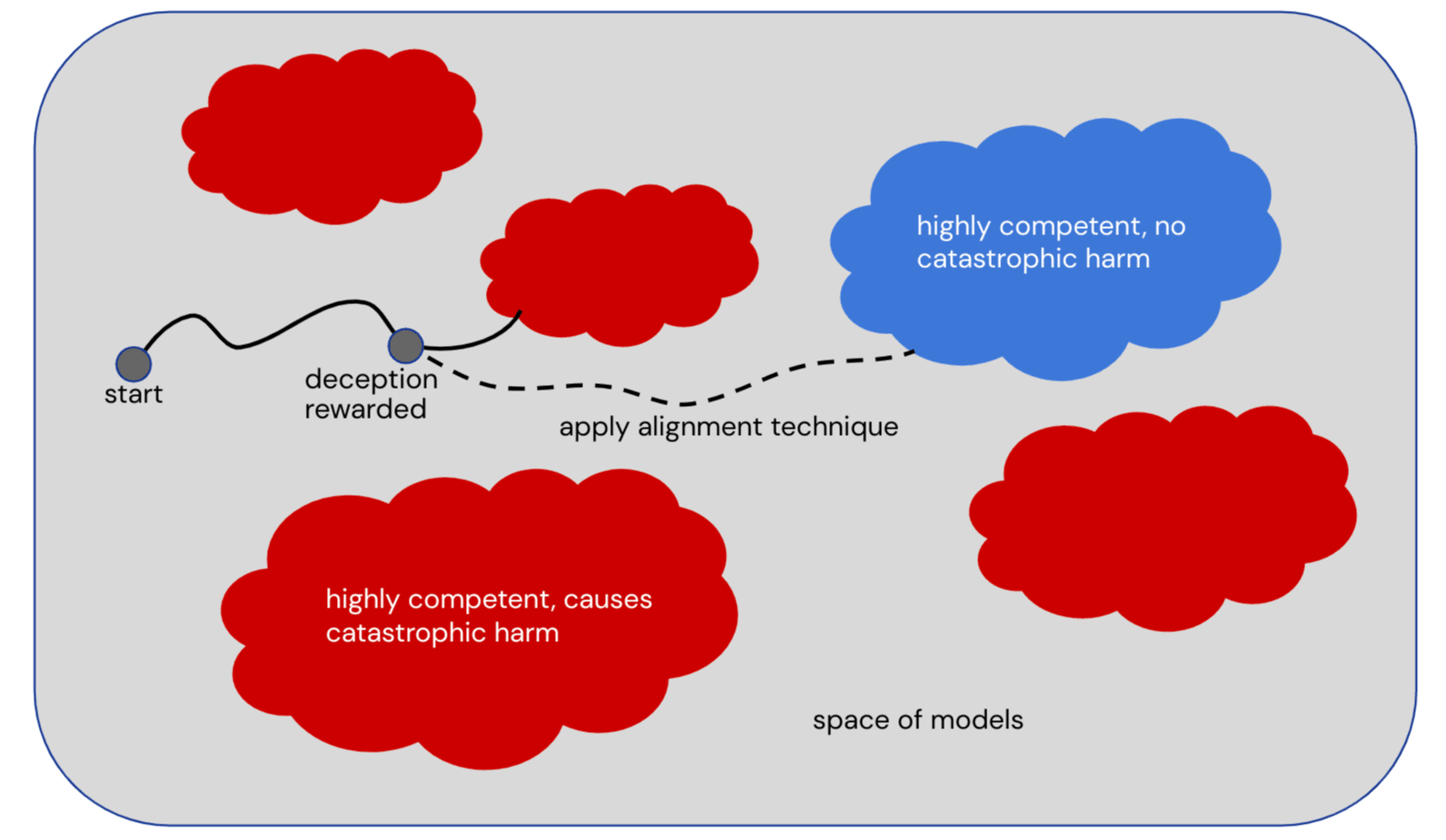
Some potential objections + responses:
- But the model will be "trying" right after pretraining, before you've even done any finetuning!
- Response: I don't think this is obvious, but if that is the case, that just means you should also be doing alignment work during pretraining.
- But all of these techniques are considering models that already have all their concepts baked in, rather than developing them on the fly!
- Response: I agree that's what we're thinking about now, and I agree that eventually we will need to think about models that develop concepts on the fly. But I think the overall theory of change here would still apply in that setting, even if we need to somewhat change the techniques to accommodate this new kind of capability.
Thanks, that helps! You’re working under a different development model than me, but that’s fine.
It seems to me that the real key ingredient in this story is where you propose to update the model based on motivation and not just behavior—“penalize it instead of rewarding it” if the outputs are “due to instrumental / deceptive reasoning”. That’s great. Definitely what we want to do. I want to zoom in on that part.
You write that “debate / RRM / ELK” are supposed to “allow you to notice” instrumental / deceptive reasoning. Of these three, I buy the ELK story—ELK is sorta an interpretability technique, so it seems plausible that ELK is relevant to noticing deceptive motivations (even if the ELK literature is not really talking about that too much at this stage, per Paul’s comment). But what about debate & RRM? I’m more confused about why you brought those up in this context. Traditionally, those techniques are focused on what the model is outputting, not what the model’s underlying motivations are. But I haven’t read all the literature. Am I missing something?
(We can give the debaters / the reward model a printout of model activations alongside the model’s behavioral outputs. But I’m not sure what the next step of the story is, after that. How do the debaters / reward model learn to skillfully interpret the model activations to extract underlying motivations?)
Traditionally, those techniques are focused on what the model is outputting, not what the model’s underlying motivations are. But I haven’t read all the literature. Am I missing something?
It's confusing to me as well, perhaps because different people (or even the same person at different times) emphasize different things within the same approach, but here's one post where someone said, "It is important that the overseer both knows which action the distilled AI wants to take as well as why it takes that action."
I'm not claiming that you figure out whether the model's underlying motivations are bad. (Or, reading back what I wrote, I did say that but it's not what I meant, sorry about that.) I'm saying that when the model's underlying motivations are bad, it may take some bad action. If you notice and penalize that just because the action is bad, without ever figuring out whether the underlying motivation was bad or not, that still selects against models with bad motivations.
It's plausible that you then get a model with bad motivations that knows not to produce bad actions until it is certain those will not be caught. But it's also plausible that you just get a model with good motivations. I think the more you succeed at noticing bad actions (or good actions for bad reasons) the more likely you should think good motivations are.
If you notice and penalize that just because the action is bad, without ever figuring out whether the underlying motivation was bad or not, that still selects against models with bad motivations.
It's plausible that you then get a model with bad motivations that knows not to produce bad actions until it is certain those will not be caught. But it's also plausible that you just get a model with good motivations. I think the more you succeed at noticing bad actions (or good actions for bad reasons) the more likely you should think good motivations are.
but, but, standard counterargument imperfect proxies Goodharting magnification of error adversarial amplification etc etc etc?
(It feels weird that this is a point that seems to consistently come up in discussions of this type, considering how basic of a disagreement it really is, but it really does seem to me like lots of things come back to this over and over again?)
Indeed I am confused why people think Goodharting is effectively-100%-likely to happen and also lead to all the humans dying. Seems incredibly extreme. All the examples people give of Goodharting do not lead to all the humans dying.
(Yes, I'm aware that the arguments are more sophisticated than that and "previous examples of Goodharting didn't lead to extinction" isn't a rebuttal to them, but that response does capture some of my attitude towards the more sophisticated arguments, something like "that's a wildly strong conclusion you've drawn from a pretty handwavy and speculative argument".)
Ultimately I think you just want to compare various kinds of models and ask how likely they are to arise (assuming you are staying within the scaled up neural networks as AGI paradigm). Some models you could consider:
- The idealized aligned model, which does whatever it thinks is best for humans
- The savvy aligned model, which wants to help humans but knows that it should play into human biases (e.g. by being sycophantic) in order to get high reward and not be selected against by gradient descent
- The deceptively aligned model, which wants some misaligned goal (say paperclips), but knows that it should behave well until it can execute a treacherous turn
- The bag of heuristics model, which (like a human) has a mix of various motivations, and mostly executes past strategies that have worked out well, imitating many of them from broader culture, without a great understanding of why they work, which tends to lead to high reward without extreme consequentialism.
(Really I think everything is going to be (4) until significantly past human-level, but will be on a spectrum of how close they are to (2) or (3).)
Plausibly you don't get (1) because it doesn't get particularly high reward relative to the others. But (2), (3) and (4) all seem like they could get similarly high reward. I think you could reasonably say that Goodharting is the reason you get (2), (3), or (4) rather than (1). But then amongst (2), (3) and (4), probably only (3) causes an existential catastrophe through misalignment.
You could then consider other factors like simplicity or training dynamics to say which of (2), (3) and (4) are likely to arise, but (a) this is no longer about Goodharting, (b) it seems incredibly hard to make arguments about simplicity / training dynamics that I'd actually trust, (c) the arguments often push in opposite directions (e.g. shard theory vs how likely is deceptive alignment), (d) a lot of these arguments also depend on capability levels, which introduces another variable into the mix (now allowing for arguments like this one).
The argument I'm making above is one about training dynamics. Specifically, the claim is that if you are on a path towards (3), it will probably take some bad actions initially (attempts at deception that fail), and if you successfully penalize those, that would plausibly switch the model towards (2) or (4).
I doubt it's a crux for you, but I think your critique of Debate makes pessimistic assumptions which I think are not the most realistic expectation about the future.
Let’s play the “follow-the-trying game” on AGI debate. Somewhere in this procedure, we need the AGI debaters to have figured out things that are outside the space of existing human concepts—otherwise what’s the point? And (I claim) this entails that somewhere in this procedure, there was an AGI that was “trying” to figure something out. That brings us to the usual inner-alignment questions: if there’s an AGI “trying” to do something, how do we know that it’s not also “trying” to hack its way out of the box, seize power, and so on? And if we can control the AGI’s motivations well enough to answer those questions, why not throw out the whole “debate” idea and use those same techniques (whatever they are) to simply make an AGI that is “trying” to figure out the correct answer and tell it to us?
When I imagine saying the above quote to a smart person who doesn't buy AI x-risk, their response is something like "woah slow down there. Just because the AI is "trying" to do something doesn't mean it stands any chance of doing actually dangerous things like hacking out of the box. The ability to hack out of the box doesn't mysteriously line up with the level of intelligence that would be useful for an AI debate." This person seems largely right, and I think your argument is mainly "it won't work to let two superintelligences to debate each other about important things" rather than a stronger claim like "any AIs smart enough to have a productive debate might be trying to do dangerous things and have non-negligible chance of succeeding".
We could be envisioning different pictures for how debate is useful as a technique. I think it will break for sufficiently high intelligence levels, for reasons you discuss, but we might still get useful work out of it in models like GPT-4/5. Additionally, it seems to me that there are setups of Debate in which we aren't all-or-nothing on the instrumental subgoals, consequentialist planning, and meta cognition, especially in (unlikely) worlds where the people implementing debate are taking many precautions. Fundamentally, Debate is about getting more trustworthy outputs from untrustworthy systems, and I expect we can get useful debates from AIs that do not run a significant risk of the failures you describe.
Again, I doubt this is a main crux for whether you will work on Debate, and that seems quite reasonable. If it's the case that, "Debate is unlikely to scale all the way to dangerous AGIs", then to the extent that we want to focus on the "dangerous AGIs" domain we might just want to skip it and work on other stuff.
Thanks for your comment!
You write “we might still get useful work out of it”—yes! We can even get useful work out of the GPT-3 base model by itself, without debate, from what I hear. (I haven’t tried “coauthoring” with language models myself, partly out of inertia and partly because I don’t want OpenAI reading my private thoughts, but other people say it’s useful.) Indeed, I can get useful work out of a pocket calculator. :-P
Anyway, the logic here is:
- Sooner or later, it will become possible to make highly-capable misaligned AGI that can do things like start pandemics and grab resources.
- Sometime before that happens, we need to either ensure that nobody ever builds such an AGI, or that we have built defenses against that kind of AGI.
(See my post What does it take to defend the world against out-of-control AGIs?)
Pocket calculators can do lots of useful things, but they can’t solve the alignment problem, nor can they defend the world against out-of-control AGIs. What about GPT-5+debate? Can GPT-5+debate solve the alignment problem? Can GPT-5+debate defend the world against out-of-control AGIs? My belief splits between these two possibilities:
- [much more likely if there are no significant changes in LLM architecture / training paradigms]—No, GPT-5+debate can’t do either of those things. But it can provide helpful assistance to humans trying to work on alignment and/or societal resilience.
- But then again, lots of things can increase the productivity of alignment researchers, including lesswrong.com and google docs and pocket calculators. I don’t think this is what debate advocates have in mind, and if it were, I would say that this goal could be better achieved by other means.
- [much less likely if there are no significant changes in LLM architecture / training paradigms] Yes, GPT-5+debate can do one or both of those things. But in this scenario, I would expect that GPT-5+debate was actually doing the dangerous “trying” thing, and thus I would expect that we’re so close (maybe a couple years or less) to world-destroying AGI that there isn’t really time for humans to be involved in planning the future, which is both bad in itself and kinda undermines (what I understood as) the whole point of debate which is to enhance human supervision.
- See this comment and the last bullet point here.
Is separate training for cognitive strategy useful? I'm genuinely unsure. If you have an architecture that parametrizes how it attends to thoughts, then any ol' RL signal will teach your AI how to attend to thoughts in an instrumentally useful way. I just read Lee's post, so right now I'm primed to expect that this will happen surprisingly often, though maybe the architecture needs to be a little more flexible/recurrent than a transformer before it happens just from trying to predict text.
Instrumental cognitive strategy seems way safer than terminal cognitive strategy. Maybe you could think it's dangerous if you think it's particularly likely to give rise to a self-reflective mesa-optimizer that's capable of taking over the outer process, but mostly I expect gradient descent to work.
If we make an AGI, and the AGI starts doing Anki because it’s instrumentally useful, then I don’t care, that doesn’t seem safety-relevant. I definitely think things like this happen by default.
If we make an AGI and the AGI develops (self-reflective) preferences about its own preferences, I care very much, because now it’s potentially motivated to change its preferences, which can be good (if its meta-preferences are aligned with what I was hoping for) or bad (if misaligned). See here. I note that intervening on an AGI’s meta-preferences seems hard. Like, if the AGI turns to look at an apple, we can make a reasonable guess that it might be thinking about apples at that moment, and that at least helps us get our foot in the door (cf. Section 4.1 in OP)—but there isn’t an analogous trick for meta-preferences. (This is a reason that I’m very interested in the nuts-and-bolts of how self-concept works in the human brain. Haven’t made much progress on that though.)
I’m not sure what you mean by “separate training for cognitive strategy”. Also, “give rise to a self-reflective mesa-optimizer that's capable of taking over the outer process” doesn’t parse for me. If it’s important, can you explain in more detail?
Also, “give rise to a self-reflective mesa-optimizer that's capable of taking over the outer process” doesn’t parse for me. If it’s important, can you explain in more detail?
So, parsing it a bit at a time (being more thorough than is strictly necessary):
What does it mean for some instrumentally-useful behavior (let's call it behavior "X") to give rise to a mesa-optimizer?
It means that if X is useful for a system in training, that system might learn to do X by instantiating an agent who wants X to happen. So if X is "trying to have good cognitive habits," there might be some mesa-optimizer that literally wants the whole system to have good cognitive habits (in whatever sense was rewarded on the training data), even if "trying to have good cognitive habits" was never explicitly rewarded.
What's "self-reflective" and why might we expect it?
"Self-reflective" means doing a good job of modeling how you fit into the world, how you work, and how those workings might be affected by your actions. A non-self-reflective optimizer is like a chess-playing agent - it makes moves that it thinks will put the board in a better state, but it doesn't make any plans about itself, since it's not on the board. An optimizer that's self-reflective will represent itself when making plans, and if this helps the agent do its job, we should expect learning process to lead to self-reflective agents.
What does a self-reflective mesa-optimizer do?
It makes plans so that it doesn't get changed or removed by the dynamics of the process that gave rise to it. Without such plans, it wouldn't be able to stay the same agent for very long.
Why would a mesa-optimizer want to take over the outer process?
Suppose there's some large system being trained (the "outer process") that has instantiated a mesa-optimizer that's smaller than the system as a whole. The smaller mesa-optimizer wants to control the larger system to satisfy its own preferences. If the mesa-optimizer wants "good cognitive habits," for instance, it might want to obtain lots of resources to run really good cognitive habits on.
[And by "but I mostly expect gradient descent to work" I meant that I expect gradient descent to suppress the formation of such mesa-optimizers.]
Thanks. I’m generally thinking about model-based RL where the whole system is unambiguously an agent that’s trying to do things, and the things it’s trying to do are related to items in the world-model that the value-function thinks are high-value, and “world-model” and “value function” are labeled boxes in the source code, and inside those boxes a learning algorithm builds unlabeled trained models. (We can separately argue about whether that’s a good thing to be thinking about.)
In this picture, you can still have subagents / Society-Of-Mind; for example, if the value function assigns high value to the world-model concept “I will follow through on my commitment to exercise” and also assigns high value to the world-model concept “I will watch TV”, then this situation can be alternatively reframed as two subagents duking it out. But still, insofar as the subagents are getting anything done, they’re getting things done in a way that uses the world-model as a world-model, and uses the value function as a value function, etc.
By contrast, when people talk about mesa-optimizers, they normally have in mind something like RFLO, where agency & planning wind up emerging entirely inside a single black box. I don’t expect that to happen for various reasons, cf. here and here.
OK, so if we restrict to model-based RL, and we forget about mesa-optimizers, then my best-guess translation of “Is separate training for cognitive strategy useful?” into my ontology is something like “Should we set up the AGI’s internal reward function to “care about” cognitive strategy explicitly, and not just let the cognitive strategy emerge by instrumental reasoning?” I mostly don’t have any great plan for the AGI’s internal reward function in the first place, so I don’t want to rule anything out. I can vaguely imagine possible reasons that doing this might be a good idea; e.g. if we want the AGI to avoid out-of-the-box solutions or human-manipulation-related solutions to its problems, we would at least possibly implement that via a reward function term related to cognitive strategy.
I still suspect that we’re probably talking about different things and having two parallel independent conversations. ¯\_(ツ)_/¯
But I’m expecting that AGI will look like model-based RL, in which case, we don’t have to search for search, the search is right there in the human source code.
Thanks!
I certainly expect future AGI to have “learned meta-cognitive strategies” like “when I see this type of problem, maybe try this type of mental move”, and even things like “follow the advice in Cal Newport and use Anki and use Bayesian reasoning etc.” But I don’t see those as particularly relevant for alignment. Learning meta-cognitive strategies are like learning to use a screwdriver—it will help me accomplish my goals, but won’t change my goals (or at least, it won’t change my goals beyond the normal extent to which any new knowledge and experience could potentially cause goal drift.)
I do think that the “source code” for a human brains has a rather different set of affordances for search / planning than you’ll find in AlphaZero or babble-and-prune or PPO, but I’m not sure how relevant that is. In particular, can you say more about why you believe “The human source code won’t contain general-purpose search”?
[For background & spelling out the acronyms in the title, see: Debate (AI safety technique), Recursive Reward Modeling, Eliciting Latent Knowledge, Natural Abstractions.]
When I say “Why I’m not working on X”, I am NOT trying to find a polite & diplomatic way to say “Nobody should work on X because X is unhelpful for AGI safety”. Hmm, OK, well, maybe it’s just a little bit that. But really, I don’t feel strongly. Instead, I think:
I wrote this post quickly and did not run it by the people I’m (sorta) criticizing. Do not assume that I described anything fairly and correctly. Please leave comments, and I’ll endeavor to update this post or write a follow-up in the case of major errors / misunderstandings / mind-changes.
(By the way: If I’m not working on any of those research programs, then what am I working on? See here. I listed six other projects that seem particularly great to me here, and there are many others besides.)
1. Background
1.1 “Trying” to figure something out seems both necessary & dangerous
(Partly self-plagiarized from here.)
Let’s compare two things: “trying to get a good understanding of some domain by building up a vocabulary of new concepts and their relations” versus “trying to win a video game”. At a high level, I claim they have a lot in common!
Therefore (I would argue), a human-level concept-inventing AI needs “RL-on-thoughts”—i.e., a reinforcement learning system, in which “thoughts” (edits to the hypothesis space / priors / world-model) are the thing that gets rewarded.
Next, consider some of the features that we plausibly need to put into this RL-on-thoughts system, for it to succeed at a superhuman level:
Putting all these things together, it seems to me that the default for this kind of AI would be to figure out that “seizing control of its off-switch” would be instrumentally useful for it to do what it’s trying to do (e.g. develop a better understanding of the target domain), and then to come up with a clever scheme to do so, and then to do it.
So “trying” to figure something out seems to me to be both necessary and dangerous.
(Really, there are two problems: (A) “trying to figure out X” spawns dangerous power-seeking instrumental subgoals by default; and (B) we don’t know how to make an AGI that is definitely “trying to figure out X” in the first place, as opposed to “trying to make paperclips” or whatever.)
1.2 The “follow-the-trying game”
Just like Eliezer’s “follow-the-improbability game”, I often find myself playing the “follow-the-trying game” when evaluating AGI safety proposals.
As above, I don’t think an AI can develop new useful concepts or come up with new plans (at least, not very well) without “trying to figure out [something]”, and I think that “trying” inevitably comes along with x-risk. Thus, for example:
1.3 Why I want to move the goalposts on “AGI”
Two different perspectives are:
I’m strongly in the second camp. That’s why I’ve previously commented that the Metaculus criterion for so-called “Human/Machine Intelligence Parity” is no such thing. It’s based on grad-school-level technical exam questions, and exam questions are inherently heavily weighted towards already knowing things rather than towards not knowing something but then figuring it out. Or, rather, if you’re going to get an “A+” on an exam, there’s a spectrum of ways to do so, where one end of the spectrum has relatively little “already knowing” and a whole lot of “figuring things out”, and the opposite end of the spectrum has a whole lot of “already knowing” and relatively little “figuring things out”. I’m much more interested in the “figuring things out” part, so I’m not too interested in protocols where that part of the story is to some extent optional.
(Instead, I’ve more recently started talking about “AGI that can develop innovative science at a John von Neumann level”, and things like that. Seems harder to game by “brute-force massive amounts of preexisting knowledge (both object-level and procedural)”.)
(Some people will probably object here, on the theory that “figuring things out” is not fundamentally different from “already knowing”, but rather is a special case of “already knowing”, wherein the “knowledge” is related to meta-learning, plus better generalizations that stem from diverse real-world training data, etc. My response is: that’s a reasonable hypothesis to entertain, and it is undoubtedly true to some extent, but I still think it’s mostly wrong, and I stand by what I wrote. However, I’m not going to try to convince you of that, because my opinion is coming from “inside view” considerations that I don’t want to get into here.)
OK, that was background, now let’s jump into the main part of the post.
2. Why I’m not working on debate or recursive reward modeling
Let’s play the “follow-the-trying game” on AGI debate. Somewhere in this procedure, we need the AGI debaters to have figured out things that are outside the space of existing human concepts—otherwise what’s the point? And (I claim) this entails that somewhere in this procedure, there was an AGI that was “trying” to figure something out. That brings us to the usual inner-alignment questions: if there’s an AGI “trying” to do something, how do we know that it’s not also “trying” to hack its way out of the box, seize power, and so on? And if we can control the AGI’s motivations well enough to answer those questions, why not throw out the whole “debate” idea and use those same techniques (whatever they are) to simply make an AGI that is “trying” to figure out the correct answer and tell it to us?
(One possible answer is that there are two AGIs working at cross-purposes, and they will prevent each other from breaking out of the box. But the two AGIs are only actually working at cross-purposes if we solve the alignment problem!! And even if we somehow knew that each AGI was definitely motivated to stop the other AGI from escaping the box, who’s to say that one couldn’t spontaneously come up with a new good idea for escaping the box that the other didn’t think of defending against? Even if they start from the same base model, they’re not thinking the same thoughts all the time, I presume.)
(Added May 2025: Ah, another possible answer is the one I discuss in my post Reward button alignment. There’s a reward button (or equivalent), which I, the human, retain control over for as long as I can. This isn’t a long-term solution—the AI will eventually grab the button, or kidnap my children, or whatever. But with some care, security audits, etc., maybe I can keep control of the button for long enough to elicit useful work from my AIs. And the work that I’m trying to elicit is (let’s say) an actual scalable plan for technical alignment. The naive approach to elicit that work is: press the reward button when the AI outputs a plan that seems good. But that definitely fails because the AI is just trying to get me to press the button. So even if we block manipulation and hacking etc., the AI will still just output a plan that sounds good, without caring whether the plan will actually scale to ASI or not. (Humans evidently can’t tell good alignment plans from bad ones, otherwise the field wouldn’t be so full of disagreements!) But the debate approach to elicit that work is instead: press a button for the AI-copy that wins the debate. This seems like maybe it would have a better chance of resulting in a plan that actually works. …OK, that’s a decent steelman, how did I overlook it when I first wrote this piece? Well, in this story, the AI is “trying” to hack its way out of the box, seize power, manipulate me, and so on. I was initially treating that observation as sufficient reason to throw this plan out. I was not thinking of AI-control-style bootstrapping approaches. To be clear, I still don’t buy that this is a good plan involving debate, but it’s at least not obviously crazy.)
As for recursive reward modeling, I already covered it in Section 1.2 above.
3. Why I’m not working on ELK
Let’s play the “follow-the-trying game” again, this time on ELK. As I open the original ELK document, I immediately find an AI that already has a superhuman understanding of what’s going on.
So if I’m right that superhuman understanding requires an AI that was “trying” to figure things out, and that this “trying” is where [part of] the danger is, then the dangerous part [that I’m interested in] is over before the ELK document has even gotten started.
In other words:
So I don’t find myself motivated to think about ELK directly.
(Update: See discussion with Paul in the comments.)
4. Why I’m not working on John Wentworth’s “natural abstractions” stuff
4.1 The parts of the plan that John is thinking hard about, seem less pressing to me
I think John is mostly focused on building a mapping between “things we care about” (e.g. corrigibility, human flourishing) and “the internal language of neural nets”. I mostly see that as some combination of “plausibly kinda straightforward” and “will happen by default in the course of capabilities research”.
For example, if I want to know which neurons in the AGI are related to apples, I can catch it looking at apples (maybe show it some YouTube videos), see which neural net neurons light up when it does, flag those neurons, and I’m done. That’s not a great solution, but it’s a start—more nuanced discussion here.
As another example, in “Just Retarget the Search”, John talks about the mesa-optimizer scenario where a search algorithm emerges organically inside a giant deep neural net, and we have to find it. But I’m expecting that AGI will look like model-based RL, in which case, we don’t have to search for search, the search is right there in the human source code. The analog of “Just Retarget the Search” would instead look like: Go looking for things that we care about in the world-model, and manually set their “value” (in RL jargon) / “valence” (in psych jargon) to very positive, or very negative, or neutral, depending on what we’re trying to do. Incidentally, I see that as an excellent idea, and it’s the kind of thing I discuss here.
4.2 The parts of the plan that seem very difficult to me, John doesn’t seem to be working on
So my impression is that the things that John is working on are things that I’m kinda not too worried about. And conversely, I’m worried about different things that John does not seem too focused on. Specifically: