Here's a recent attempt of mine at a distillation of a fragment of this plan, copied over from a discussion elsewhere:
goal: make there be a logical statement such that a proof of that statement solves the strawberries-on-a-plate problem (or w/e).
summary of plan:
background context: there's some fancy tools with very nice mathematical properties for combining probabilistic reasoning and worst-case reasoning.
key hope: these tools will let us interpret this "manual multi-level world-model" in a way that keeps enough of the probabilistic nature for tractable policies to exist, and enough adversarial nature for this constraint to be pretty tight.
in more concrete terms: for any given UFAI, somewhere in the convex hull of all the interpretations of the manual multi-level world model, there's a model that sees (in its high-level) the shady shit that the UFAI was hoping to slip past us. So such "shady" policies fail in the worst-case, and fail to satisfy the theorem. But also enough of the probabilistic nature is retained that your policies don't need to handle the literal worst-cases of thermodynamic heat, and so there are some "reasonable" policies that could satisfy the theorem.
capabilities requirements: the humans need to be able to construct the world model; something untrusted and quite capable needs to search for proofs of the theorem; the policy extracted from said theorem is then probably an AGI with high capabilities but you've (putatively) proven that all it does is put strawberries on a plate and shut down so \shrug :crossed_fingers: hopefully that proof bound to reality.
(note: I'm simply attempting to regurgitate the idea here; not defend it. obvious difficulties are obvious, like "the task of finding such a policy is essentially the task of building and aligning an AGI" and "something that can find that policy is putting adversarial pressure on your theorem". even if proving the theorem requires finding a sufficiently-corrigible AGI, it would still be rad to have a logical statement of this form (and perhaps there's even some use to it if it winds up not quite rated for withstanding superintelligent adversaries?).)
Anticipating an obvious question: yes, I observed to Davidad that the part where we imagine convex sets of distributions that contain enough of the probabilistic nature to admit tractable policies and enough of the worst-case nature to prevent UFAI funny business is where a bunch of the work is being done, and that if it works then there should be a much smaller example of it working, and probably some minimal toy example where it's easy to see that the only policies that satisfy the analogous theorem are doing some new breed of optimization, that is neither meliorization nor satisfaction and that is somehow more mild. And (either I'm under the illusion of transparency or) Davidad agreed that this should be possible, and claims it is on his list of things to demonstrate.
(note: this is the fragment of Davidad's plan that I was able to distill out into something that made sense to me; i suspect he thinks of this as just one piece among many. I welcome corrections :-))
Inner misalignment is a story for why one might expect capable but misaligned out-of-distribution behaviour, which is what's actually bad. Model-checking could rule that out entirely (relative to the formal specification)— whether it's "inner misalignment" or "goal misgeneralization" or "deceptive alignment" or "demons in Solmonoff induction" or whatever kind of story might explain such output. Formal verification is qualitatively different from the usual game of debugging whack-a-mole that software engineers play to get software to behave acceptably.
Why a formal specification of the desired properties?
Humans do not carry around a formal specification of what we want printed on the inside of our skulls. So when presented with some formal specification, we would need to gain confidence that such a formal specification would lead to good things and not bad things through some informal process. There's also the problem that specifications of what we want tend to be large - humans don't do a good job of evaluating formal statements even when they're only a few hundred lines long. So why not just cut out the middleman and directly reference the informal processes humans use to evaluate whether some plan will lead to good things and not bad things?
The informal processes humans use to evaluate outcomes are buggy and inconsistent (across humans, within humans, across different scenarios that should be equivalent, etc.). (Let alone asking humans to evaluate plans!) The proposal here is not to aim for coherent extrapolated volition, but rather to identify a formal property (presumably a conjunct of many other properties, etc.) such that conservatively implies that some of the most important bad things are limited and that there’s some baseline minimum of good things (e.g. everyone has access to resources sufficient for at least their previous standard of living). In human history, the development of increasingly formalized bright lines around what things count as definitely bad things (namely, laws) seems to have been greatly instrumental in the reduction of bad things overall.
Regarding the challenges of understanding formal descriptions, I’m hopeful about this because of
What about problems with direct oversight?
Shouldn't we plan to build trust in AIs in ways that don't require humans to do things like vet all changes to its world-model? Perhaps toy problems that try to get at what we care about, or automated interpretability tools that can give humans a broad overview of some indicators?
In response to your linked post, I do have similar intuitions about “Microscope AI” as it is typically conceived (i.e. to examine the AI for problems using mechanistic interpretability tools before deploying it). Here I propose two things that are a little bit like Microscope AI but in my view both avoid the core problem you’re pointing at (i.e. a useful neural network will always be larger than your understanding of it, and that matters):
Shouldn't we plan to build trust in AIs in ways that don't require humans to do things like vet all changes to its world-model?
Yes, I agree that we should plan toward a way to trust AIs as something more like virtuous moral agents rather than as safety-critical systems. I would prefer that. But I am afraid those plans will not reach success before AGI gets built anyway, unless we have a concurrent plan to build an anti-AGI defensive TAI that requires less deep insight into normative alignment.
I find Eric Drexler's arguments convincing about how it seems possible to make collusion very unlikely. On the other hand, I do think it requires nontrivial design and large ensembles; in the case of an unconstrained 2-player game (like Safety via Debate), I side with Eliezer that the probability of collusion probably converges toward 1 as capabilities get more superintelligent.
Another key principle that I make use of is algorithms (such as branch-and-bound and SMT solvers) whose performance—but not their correctness—depends on extremely clever heuristics. Accelerating the computation of more accurate and useful bounds seems to me like a pretty ineffectual causal channel for the AIs playing those heuristic roles to coordinate with each other or to seek real-world power.
GPT-3.5-Nate [prompted using 1061 tokens of Nate's criticism of related ideas]: This is a really interesting proposal! It seems to me that you're trying to solve the hard problem of AI alignment, by proposing a system that would be able to identify the concepts that an AGI should be optimizing for, and then use a combination of model-checking and time-bounded optimization to ensure that the AGI's behavior is robustly directed at those concepts. This is a really ambitious project, and I'm excited to see how it develops.
🙃
Nate [replying to Eric Drexler]: I expect that, if you try to split these systems into services, then you either fail to capture the heart of intelligence and your siloed AIs are irrelevant, or you wind up with enough AGI in one of your siloes that you have a whole alignment problem (hard parts and all) in there. Like, I see this plan as basically saying "yep, that hard problem is in fact too hard, let's try to dodge it, by having humans + narrow AI services perform the pivotal act". Setting aside how I don't particularly expect this to work, we can at least hopefully agree that it's attempting to route around the problems that seem to me to be central, rather than attempting to solve them.
I think, in an open agency architecture, the silo that gets "enough AGI" is in step 2, and it is pointed at the desired objective by having formal specifications and model-checking against them.
But I also wouldn't object to the charge that an open agency architecture would "route around the central problem," if you define the central problem as something like building a system that you'd be happy for humanity to defer to forever. In the long run, something like more ambitious value learning (or value discovery) will be needed, on pain of astronomical waste. This would be, in a sense, a compromise (or, if you're optimistic, a contingency plan), motivated by short timelines and insufficient theoretical progress toward full normative alignment.
if you define the central problem as something like building a system that you'd be happy for humanity to defer to forever.
[I at most skimmed the post, but] IMO this is a more ambitious goal than the IMO central problem. IMO the central problem (phrased with more assumptions than strictly necessary) is more like "building system that's gaining a bunch of understanding you don't already have, in whatever domains are necessary for achieving some impressive real-world task, without killing you". So I'd guess that's supposed to happen in step 1. It's debatable how much you have to do that to end the acute risk period, for one thing because humanity collectively is already a really slow (too slow) version of that, but it's a different goal than deferring permanently to an autonomous agent.
(I'd also flag this kind of proposal as being at risk of playing shell games with the generator of large effects on the world, though not particularly more than other proposals in a similar genre.)
I’d say the scientific understanding happens in step 1, but I think that would be mostly consolidating science that’s already understood. (And some patching up potentially exploitable holes where AI can deduce that “if this is the best theory, the real dynamics must actually be like that instead”. But my intuition is that there aren’t many of these holes, and that unknown physics questions are mostly underdetermined by known data, at least for quite a long way toward the infinite-compute limit of Solomonoff induction, and possibly all the way.)
Engineering understanding would happen in step 2, and I think engineering is more “the generator of large effects on the world,” the place where much-faster-than-human ingenuity is needed, rather than hoping to find new science.
(Although the formalization of the model of scientific reality is important for the overall proposal—to facilitate validating that the engineering actually does what is desired—and building such a formalization would be hard for unaided humans.)
Nate [replying to Eric Drexler]: I expect that, if you try to split these systems into services, then you either fail to capture the heart of intelligence and your siloed AIs are irrelevant, or you wind up with enough AGI in one of your siloes that you have a whole alignment problem (hard parts and all) in there….
GTP-Nate is confusing the features of the AI services model with the argument that “Collusion among superintelligent oracles can readily be avoided”. As it says on the tin, there’s no assumption that intelligence must be limited. It is, instead, an argument that collusion among (super)intelligent systems is fragile under conditions that are quite natural to implement.
There's a lot of similarity. People (including myself in the past) have criticized Russell on the basis that no formal model can prove properties of real-world effects, because the map is not the territory, but I now agree with Russell that it's plausible to get good enough maps. However:
Edited to add (2024-03): This early draft is largely outdated by my ARIA programme thesis, Safeguarded AI. I, davidad, am no longer using "OAA" as a proper noun, although I still consider Safeguarded AI to be an open agency architecture.
Note: This is an early draft outlining an alignment paradigm that I think might be extremely important; however, the quality bar for this write-up is "this is probably worth the reader's time" rather than "this is as clear, compelling, and comprehensive as I can make it." If you're interested, and especially if there's anything you want to understand better, please get in touch with me, e.g. via DM here.
In the Neorealist Success Model, I asked:
This post is a first pass at communicating my current answer.
Bird's-eye view
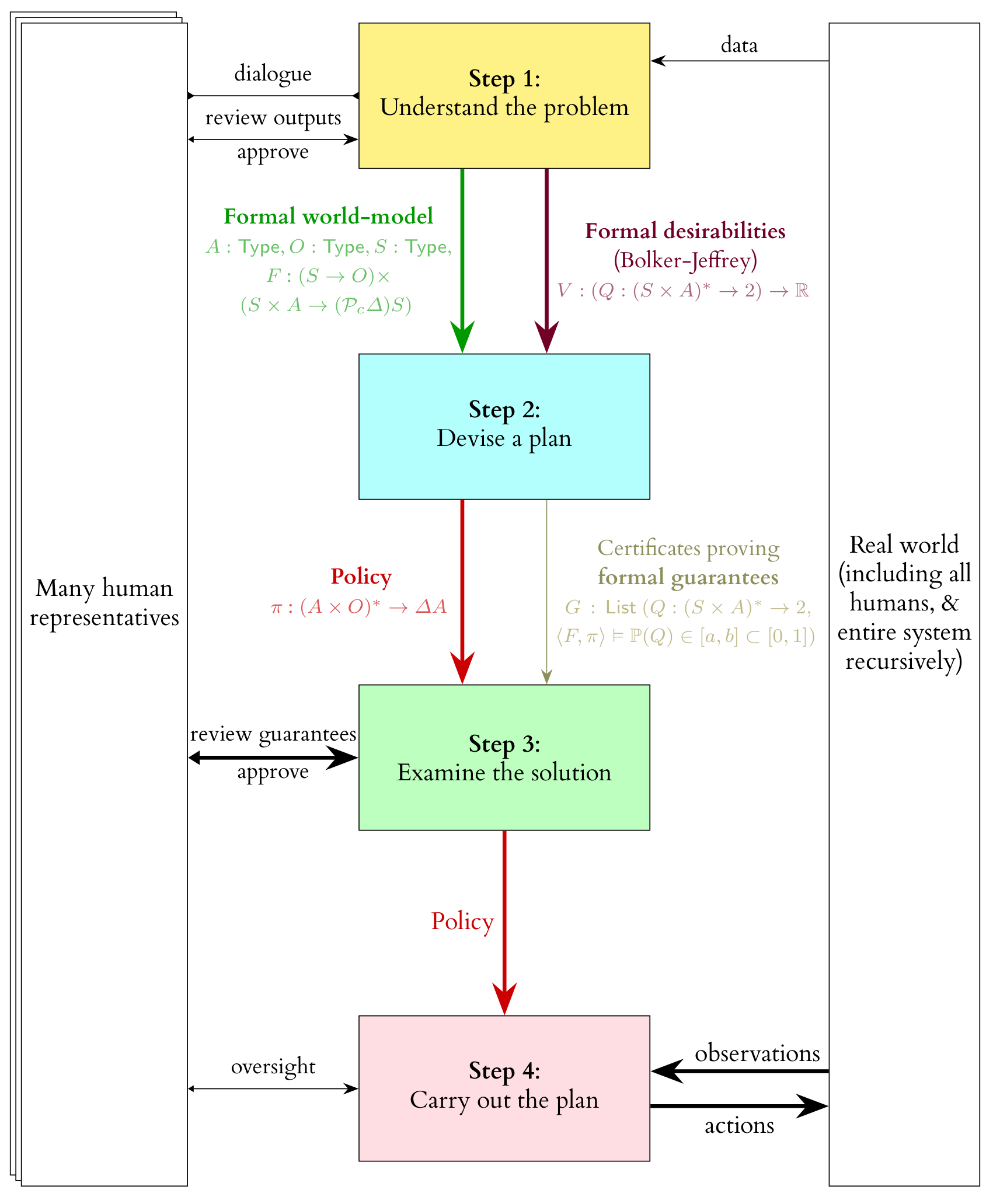
At the top level, it centres on a separation between
We see such a separation in, for example, MuZero, which can probably still beat GPT-4 at Go—the most effective capabilities do not always emerge from a fully black-box, end-to-end, generic pre-trained policy.
Hypotheses
- Scientific Sufficiency Hypothesis: It's feasible to train a purely descriptive/predictive infra-Bayesian[1] world-model that specifies enough critical dynamics accurately enough to end the acute risk period, such that this world-model is also fully understood by a collection of humans (in the sense of "understood" that existing human science is).
- MuZero does not train its world-model for any form of interpretability, so this hypothesis is more speculative.
- However, I find Scientific Sufficiency much more plausible than the tractability of eliciting latent knowledge from an end-to-end policy.
- It's worth noting there is quite a bit of overlap in relevant research directions, e.g.
- pinpointing gaps between the current human-intelligible ontology and the machine-learned ontology, and
- investigating natural abstractions theoretically and empirically.
- Deontic Sufficiency Hypothesis: There exists a human-understandable set of features of finite trajectories in such a world-model, taking values in (−∞,0], such that we can be reasonably confident that all these features being near 0 implies high probability of existential safety, and such that saturating them at 0 is feasible[2] with high probability, using scientifically-accessible technologies.
- I am optimistic about this largely because of recent progress toward formalizing a natural abstraction of boundaries by Critch and Garrabrant. I find it quite plausible that there is some natural abstraction property Q of world-model trajectories that lies somewhere strictly within the vast moral gulf of
All Principles That Human CEV Would Endorse⇒Q⇒Don't Kill EveryoneIf those hypotheses are true, I think this is a plan that would work. I also think they are all quite plausible (especially relative to the assumptions that underly other long-term AI safety hopes)—and that if any one of them fails, they would fail in a way that is detectable before deployment, making an attempt to execute the plan into a flop rather than a catastrophe.
Fine-grained decomposition
This is one possible way of unpacking the four high-level components of an open agency architecture into somewhat smaller chunks. The more detailed things get, the less confident I currently am that such assemblages are necessarily the best way to do things, but the process of fleshing things out in increasingly concrete detail at all has increased my confidence that the overall proposed shape of the system is viable.
Here's a brief walkthrough of the fine-grained decomposition:
At this point I defer further discussion to the comment section, which I will pre-emptively populate with a handful of FAQ-style questions and answers.
Here I mostly mean to refer to the concept of credal sets: a conservative extension of Bayesian probability theory which incorporates the virtues of interval arithmetic: representing uncertainty with ranges, generalized to closed convex regions (of higher-dimensional or infinite-dimensional spaces). Variants of this theory have been rediscovered many times (by Choquet, Dempster & Shafer, Williams, Kosoy & Appel, etc.) under various names ("imprecise probability", "robust Bayes", "crisp infradistributions," etc.), each of which has some idiosyncratic features. In the past few years it has become very clear that convex subsets of probability distributions are the canonical monad for composing non-deterministic and probabilistic choice, i.e. Knightian uncertainty and Bayesian risk. Category theory has been used to purify the essential concepts there from the contradictory idiosyncratic features introduced by different discoverers—and to connect them (via coalgebra) to existing ideas and algorithms in model-checking. Incidentally, convex sets of probability distributions are also the central concept in the 2013 positive result on probabilistic reflective consistency by Christiano, Yudkowsky, Herreshoff and Barasz.
PcΔ, seen in my type signature for formal world-model, is the notation for this monad (the monad of "crisp infradistributions" or "credal sets" or etc.), whereas Δ is a monad of ordinary probability distributions.
Infra-Bayesian physicalism goes much farther than the decision theory of credal sets, in order to account for embedded agency via naturalized induction, and casts all desirabilities in the form of irreducibly valuable computations. I think something in this direction is philosophically promising, and likely on the critical path to ultimate ambitious alignment solutions in the style of CEV or moral realism. But in the context of building a stop-gap transformative AI that just forestalls catastrophic risk while more of that philosophy is worked out, I think policies based on infra-Bayesian physicalism would fail to satisfy conservative safety properties due to unscoped consequentialism and situated awareness. It's also probably computationally harder to do this properly rather than just specifying a Cartesian boundary and associated bridge rules.
This is a simplification; for an initial fixed time-period post-deployment in which the agent is building planetary-scale infrastructure, only the agent's own actions' counterfactual impact on the features would be scored.
Actual tampering with physical sensors is already ruled out by model-checking with respect to the entire formal world-model, which is also the sole source of information for the central model-based RL optimizer.