
Reply to Eliezer on Biological Anchors
17adamShimi
6jacob_cannell
7adamShimi
3HoldenKarnofsky
3adamShimi
9Edouard Harris
5HoldenKarnofsky
9Ruby
8Matthew Barnett
5greghb
8Daniel Kokotajlo
8greghb
4Daniel Kokotajlo
2greghb
1jacob_cannell
greghb
1HoldenKarnofsky
4cousin_it
5Matthew Barnett
3Ruby
1Raymond Douglas
6HoldenKarnofsky
The "biological anchors" method for forecasting transformative AI is the biggest non-trust-based input into my thinking about likely timelines for transformative AI. While I'm sympathetic to parts of Eliezer Yudkowsky's recent post on it, I overall disagree with the post, and think it's easy to get a misimpression of the "biological anchors" report (which I'll abbreviate as "Bio Anchors") - and Open Philanthropy's take on it - by reading it.
This post has three sections:
A few notes before I continue:
Bounding vs. pinpointing
Here are a number of quotes from Eliezer in which I think he gives the impression that Biological Anchors assumes transformative AI will be arrived at via modern machine learning methods:
However, the argument given in Bio Anchors does not hinge on an assumption that modern deep learning is what will be used, nor does it set aside the possibility of paradigm changes.
From the section What if TAI is developed through a different path?:
That is, Ajeya (the author) sees the "median" estimate as structurally likely to be overly conservative (a soft upper bound) for reasons including those Eliezer gives, but is also adjusting in the opposite direction to account for factors including the generic burden of proof. (More discussion of "soft bounds" provided by Bio Anchors in this section and this section of the report.)
I made similar arguments in a recent piece, “Biological anchors” is about bounding, not pinpointing, AI timelines. This is my best explanation for skeptics of why I find the framework valuable.
As far as I can tell, the only part of Eliezer's piece that addresses an argument along the lines of the "soft bounding" idea is:
I don't literally think that the "exact GPT architecture" would work to produce transformative AI, but I think something not too far off would be a strong contender - such that having enough compute to afford this extremely brute-force method, combined with decades more time to produce new innovations and environments, does provide something of a "soft upper bound" on transformative AI timelines.
Another way of putting this is that a slightly modified version of what Eliezer calls "tentative [and] probably false]" seems to me to be "tentative and probably true." There's room for disagreement about this, but this is not where most of Eliezer's piece focused.
While I can't be confident, I also suspect that the person in the 2006 or thereabouts part of Eliezer's piece may have intended to argue for something more like a "(soft) upper bound" than a median estimate.
Finally, I want to point out this quote from Bio Anchors, which reinforces that it is intended as a tool for informing AI timelines rather than as a comprehensive generator of all-things-considered AI timelines:
It seems that Eliezer places higher probability on an "entirely different path" sooner than Bio Anchors, but he does not seem to argue for this (and see below for why I don't think it would be a great bet). Instead, he largely argues that the possibility is ignored by Bio Anchors, which is not the case.
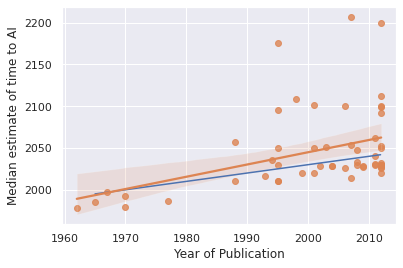
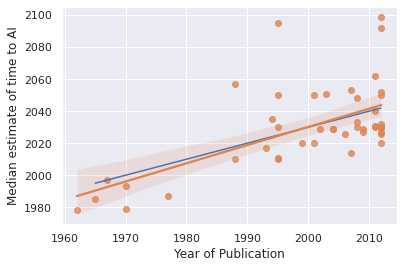
Platt's Law and past forecasts
Eliezer writes:
I have a couple issues here.
First, I think Eliezer exaggerates the precision of Platt's Law and its match to the Bio Anchors projection:
I think a softer "It's suspicious that Bio Anchors is in the same 'reasonable-sounding' general range ('a few decades') that AI forecasts have been in for a long time" comment would've been more reasonable than what Eliezer wrote, so from here I'll address that. First, I want to comment on Moravec specifically.
Eliezer characterizes Open Philanthropy as though we think that Hans Moravec's projection was foreseeably silly and overaggressive (see quote above), but now think we have the right approach. This isn't the case.
To expand on what I mean by a reasonable standard and reasonable alternatives:
Returning to the softened version of Platt's Law: according to my current views on timelines (and more so according to Eliezer's), "a few decades" has been a good range for a prediction to be in for the last few decades (again, keeping in mind what context and alternatives I am using). I think this considerably softens the force of an objection like: "You're forecasting a few decades, as many others have over the last few decades; this in itself undermines your case."
None of the above points constitute arguments for the correctness of Bio Anchors. My point is that "Your prediction is like these other predictions" (the thrust of much of Eliezer's piece) doesn't seem to undermine the argument, partly because the other predictions look broadly good according to both my and Eliezer's current views.
A few other reactions to specific parts
On one hand, I think it's a distinct possibility that we're going to see dramatically new approaches to AI development by the time transformative AI is developed.
On the other, I think quotes like this overstate the likelihood in the short-to-medium term.
If the world were such that:
...Then I would be interested in a Bio Anchors-style analysis of projected power usage. As noted above, I would be interested in this as a tool for analysis rather than as "the way to get my probability distribution." That's also how I'm interested in Bio Anchors (and how it presents itself).
I also think we have some a priori reason to believe that human scientists can "use computations" somewhere near as efficiently as the brain does (software), more than we have reason to believe that human scientists can "use power" somewhere nearly as efficiently as the brain does (hardware).
(As a side note, there is some analysis of how nature vs. humans use power in this section of Bio Anchors.)
It's hard for me to understand how it is not a relevant fact: I think we have good reason to believe that humans can use computations at least as intelligently as evolution did.
I think it's perfectly reasonable to push back on 10^43 as a median estimate, but not as a number that has some sort of relevance.
I thought this was a pretty misleading presentation of how Open Philanthropy has communicated about this work. It's true that Open Philanthropy's public communication tends toward a cautious, serious tone (and I think there are good reasons for this); but beyond that, I don't think we do much to convey the sort of attitude implied above. The report's publication announcement was on LessWrong as a draft report for comment, and the report is still in the form of several Google docs. We never did any sort of push to have it treated as a fancy report.