This article studies a natural and interesting mathematical question: which algebraic relations hold between Bayes nets? In other words, if a collection of random variables is consistent with several Bayes nets, what other Bayes nets does it also have to be consistent with? The question is studied both for exact consistency and for approximate consistency: in the latter case, the joint distribution is KL-close to a distribution that's consistent with the net. The article proves several rules of this type, some of them quite non-obvious. The rules have concrete applications in the authors' research agenda.
Some further questions that I think would be interesting to study:
- Can we derive a full classification of such rules?
- Is there a category-theoretic story behind the rules? Meaning, is there a type of category for which Bayes nets are something akin to string diagrams and the rules follow from the categorical axioms?
I've been told a Bayes net is "just" a functor from a free Cartesian category to a category of probability spaces /Markov Kernels.
Seems right, but is there a categorical derivation of the Wentworth-Lorell rules? Maybe they can be represented as theorems of the form: given an arbitrary Markov category C, such-and-such identities between string diagrams in C imply (more) identities between string diagrams in C.
Hi! I spent some time working on exactly this approach last summer at MATS, and since then have kept trying to work out the details. It's been going slowly but parts of it have been going at all.
My take regarding your and @Alexander Gietelink Oldenziel's comments below is - that's not a thing that really happens? You pick the rules and your desired semantics first, and then you write down your manipulation rules to reflect those. Maybe it turns out that you got it wrong and there's more (or fewer!) rules of derivation to write down, but as long as the rules you wrote down follow some very easy constraints, you can just... write down anything. Or decline to. (Also, from a quick read I'm fairly sure you need a little bit more than just "free cartesian category" to hold of your domain category if you want nice structures to hang state/kernel-labels on. You want to be able to distinguish a concrete Bayes net (like, with numbers and everything) from an abstract "Bayes net", which is just a directed acyclic graph representing local conditionality structures - though we should note that usually people working with Bayes nets assume that we actually have trees, and not just DAGs!)
Maybe there's arguments from things like mathematical elegance or desired semantics or problematizing cases to choose to include or exclude some rule, or formulate a rule in one or another way, but ultimately you get to add structure to a category as suits you.
- Can we derive a full classification of such rules?
Probably there's no full classification, but I think that a major important point (which I should have just written up quickly way way long ago) is that we don't quite care about Markov equivalence class - only about whether any given move takes us to a diagram still compatible with the joint distribution/factorization that we started with.
- Is there a category-theoretic story behind the rules? Meaning, is there a type of category for which Bayes nets are something akin to string diagrams and the rules follow from the categorical axioms?
In my understanding there's a pretty clear categorical story - some of which are even just straight trivial! - to most of the rules. They make good sense in the categorical frame; some of them make so much sense that they're the kind of thing string diagrams don't even bother to track. I'm thinking of Factorization Transfer here, though the one major thing I've managed to get done is that the Joint Independence rule actually follows as a quick technical lemma from its assumptions/setup, rather than having to be assumed.
There's noncanonical choices getting made in the two "binary operation" rules, but even then it seems to me like the fact that we only ever apply that operation to two diagrams of the same "flavor" means we should likely only ever get back another diagram of the same "flavor"; apart from that, there's a strong smell of colimitness to both of those rules, which has kept me mulling over whether there's a useful "limitish" sort of rule that John and David both missed. Underlying this is my suspicion that we might get a natural preorder structure on latent Bayes nets/string diagrams as the pullback of the natural lattice on Markov equivalence classes, where one MEC is above another if it has strictly more conditionality relationships in it - i.e. the unique minimal element of the lattice is "everything is independent", and there's lots of maximal elements, and all our rules need to keep us inside the preimage of the upset of our starting MEC.
Which is to say: yes, yes there totally is such a type of category, but existing work mostly stopped at "Bayes nets akin to string diagrams", although I've seen some non-me work lately that looks to be attacking similar problems.
I found the above comment difficult to parse.
that's not a thing that really happens?
What is the thing that doesn't happen? Reading the rest of the paragraph only left me more confused.
we don't quite care about Markov equivalence class
What do you mean by "Markov equivalence class"?
that's not a thing that really happens?
What is the thing that doesn't happen? Reading the rest of the paragraph only left me more confused.
Somehow being able to derive all relevant string diagram rewriting rules for latential string diagrams, starting with some fixed set of equivalences? Maybe this is just a framing thing, or not answering your question, but I would expect to need to explicitly assume/include things like the Frankenstein rule - more generally, picking which additional rewriting rules you want to use/include/allow is something you do in order to get equivalence/reachability in the category to line up correctly with what you want that equvialence to mean - you could just as soon make those choices poorly and (e.g.) allow arbitrary deletions of states, or addition of sampling flow that can't possibly respect causality; we don't do that here because it wouldn't result in string diagram behavior that matches what we want it to match.
I think I may have misunderstood, though, because that does sounds almost exactly like what I found to happen for the Joint Independence rule - you have some stated equivalence, and then you use string diagram rewriting rules common to all Markov category string diagrams in order to write the full form of the rule.
Simple form of the JI Rule - note the equivalences in the antecedent, which we can use to prove the consequent, not just enforce the equivalence!
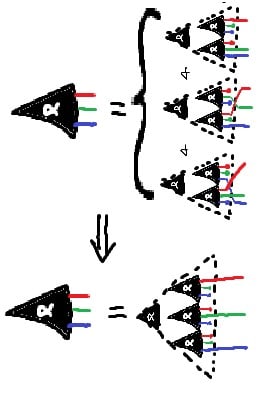
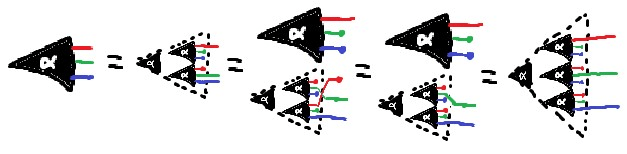
we don't quite care about Markov equivalence class
What do you mean by "Markov equivalence class"?
Two Bayes nets are of the same Markov equivalence class when they have precisely the same set of conditionality relations holding on them (and by extension, precisely the same undirected skeleton). You may recognize this as something that holds true when applicable for most of these rules, notably (sometimes) including the binary operations and notably excluding direct arrow-addition; additionally, this is something that applies for abstract Bayes nets just as well as concrete ones.
Somehow being able to derive all relevant string diagram rewriting rules for latential string diagrams, starting with some fixed set of equivalences?
What are "latential" string diagrams?
What does it it mean that you can't derive them all from a "fixed" set? Do you imagine some strong claim e.g. that the set of rewriting rules being undecidable, or something else?
Two Bayes nets are of the same Markov equivalence class when they have precisely the same set of conditionality relations holding on them (and by extension, precisely the same undirected skeleton).
Okay, so this is not what you care about? Maybe you are saying the following: Given two diagrams X,Y, we want to ask whether any distribution compatible with X is compatible with Y. We don't ask whether the converse also holds. This is a certain asymmetric relation, rather than an equivalence.
What are "latential" string diagrams?
Just the word I use to describe "thing that has something to do with (natural) latents". More specifically for this case: a string diagram over a Markov category equipped with the extra stuff, structure, and properties that a Markov category needs to have in order to faithfully depict everything we care about when we want to write down statements or proofs about Bayes nets which might transform in some known restricted ways.
What does it it mean that you can't derive them all from a "fixed" set? Do you imagine some strong claim e.g. that the set of rewriting rules being undecidable, or something else?
Something else. I'm saying that:
- You would need to pick your set of identities once and for all at the start, as part of specifying what extra properties the category has; you could totally use those as (or to derive) some of the rules (and indeed I show how you can do just that for Breakout Joint Independence)
- Binary operations like Frankenstein or Stitching probably don't fall out of an approach like that (they look a lot more like colimits
- Rules which a categorical approach trivializes like Factorization Transfer don't particularly fall out of an approach like that
- You could probably get some kind of "ruleset completeness" result if you had a strong sense of what would constitute a complete ruleset - the paper I linked above looks to be trying to do this
...so maybe some approach where you start by listing off all the identities you want to have hold and then derive the full ruleset from those would work at least partially? I guess I'm not totally clear what you mean by "categorical axioms" here - there's a fair amount that goes into a category; you're setting down all the rules for a tiny toy mathematical universe and are relatively unconstrained in how you do so, apart from your desired semantics. I'm also not totally confident that I've answered your question.
Okay, so this is not what you care about? Maybe you are saying the following: Given two diagrams X,Y, we want to ask whether any distribution compatible with X is compatible with Y. We don't ask whether the converse also holds. This is a certain asymmetric relation, rather than an equivalence.
Yes. Well... almost. Classically you'd care a lot more about the MEC, but I've gathered that that's not actually true for latential Bayes nets. For those, we have some starting joint distribution J, which we care about a lot, and some diagram D_J which it factors over; alternatively, we have some starting set of conditionality requirements J, and some diagram D_J from among those that realize J. (The two cases are the same apart from the map that gives you actual numerical valuations for the states and transitions.)
We do indeed care about the asymmetric relation of "is every distribution compatible with X also compatible with Y", but we care about it because we started with some X_J and transformed it such that at every stage, the resulting diagram was still compatible with J.
I think that there are two different questions which might be getting mixed up here:
Question 1: Can we fully classify all rules for which sets of Bayes nets imply other Bayes nets over the same variables? Naturally, this is not a fully rigorous question, since "classify" is not a well-defined notion. One possible operationalization of this question is: What is the computational complexity of determining whether a given Bayes net follows from a set of other Bayes nets? For example, if there is a set of basic moves that generate all such inferences then the problem is probably in NP (at least if the number of required moved can also be bounded).
Question 2: What if we replace "Bayes nets" by something like "string diagrams in a Markov category"? Then there might be less rules (because maybe some rules hold for Bayes nets but not in the more abstract setting).
Here's a new Bookkeeping Theorem, which unifies all of the Bookkeeping Rules mentioned (but mostly not proven) in the post, as well as all possible other Bookkeeping Rules.
If all distributions which factor over Bayes net also factor over Bayes net , then all distributions which approximately factor over also approximately factor over . Quantitatively:
where indicates parents of variable in .
Proof: Define the distribution . Since exactly factors over , it also exactly factors over : . So
Then by the factorization transfer rule (from the post):
which completes the proof.
Could you clarify how this relates to e.g. the PC (Peter-Clark) or FCI (Fast Causal Inference) algorithms for causal structure learning?
Like, are you making different assumptions (than e.g. minimality, faithfulness, etc)?
In this post, we’re going to use the diagrammatic notation of Bayes nets. However, we use the diagrams a little bit differently than is typical. In practice, such diagrams are usually used to define a distribution - e.g. the stock example diagram
... in combination with the five distributions P[Season], P[Rain|Season], P[Sprinkler|Season], P[Wet|Rain,Sprinkler], P[Slippery|Wet], defines a joint distribution
P[Season,Rain,Sprinkler,Wet,Slippery]
=P[Season]P[Rain|Season]P[Sprinkler|Season]P[Wet|Rain,Sprinkler]P[Slippery|Wet]
In this post, we instead take the joint distribution as given, and use the diagrams to concisely state properties of the distribution. For instance, we say that a distribution P[Λ,X] “satisfies” the diagram
if-and-only-if P[Λ,X]=P[Λ]∏iP[Xi|Λ]. (And once we get to approximation, we’ll say that P[Λ,X] approximately satisfies the diagram, to within ϵ, if-and-only-if DKL(P[Λ,X]||P[Λ]∏iP[Xi|Λ])≤ϵ.)
The usage we’re interested in looks like:
In other words, we want to write proofs diagrammatically - i.e. each “step” of the proof combines some diagrams (which the underlying distribution satisfies) to derive a new diagram (which the underlying distribution satisfies).
For this purpose, it’s useful to have a few rules for an “algebra of diagrams”, to avoid always having to write out the underlying factorizations in order to prove anything. We’ll walk through a few rules, give some examples using them, and prove them in the appendix. The rules:
The first couple are relatively-simple rules for “serial” and “parallel” variables, respectively; they’re mostly intended to demonstrate the framework we’re using. The next four rules are more general, and give a useful foundation for application. Finally, the Bookkeeping Rules cover some “obvious” minor rules, which basically say that all the usual things we can deduce from a single Bayes net still apply.
Besides easy-to-read proofs, another big benefit of deriving things via such diagrams is that we can automatically extend our proofs to handle approximation (i.e. cases where the underlying distribution only approximately satisfies the diagrams). We’ll cover approximate versions of the rules along the way.
Finally, we’ll walk through an end-to-end example of a proof which uses the rules.
Re-Rooting Rule for Markov Chains
Suppose we have a distribution over X1,X2,X3,X4 which satisfies
Then the distribution also satisfies all of these diagrams:
In fact, we can also go the other way: any one of the above diagrams implies all of the others.
Since this is our first rule, let’s unpack all of that compact notation into its full long-form, in a concrete example. If you want to see the proof, take a look at the appendix.
Verbose Example
For concreteness, let’s say we have a widget being produced on an assembly line. No assembly line is perfect; sometimes errors are introduced at a step, like e.g. a hole isn’t drilled in quite the right spot. Those errors can then cause further errors in subsequent steps, like e.g. the hole isn’t in quite the right spot, a part doesn’t quite fit right. We’ll say that X1 is the state of the widget after step 1, X2 is the state after step 2, etc; the variables are random to model the “random” errors sometimes introduced.
Our first diagram
says that the probability of an error at step i, given all the earlier steps, depends only on the errors accumulated up through step i−1. That means we’re ignoring things like e.g. a day of intermittent electrical outages changing the probability of error in every step in a correlated way. Mathematically, we get that interpretation by first applying the chain rule (which applies to any distribution) to the underlying distribution:
P[X1,X2,X3,X4]=P[X1]P[X2|X1]P[X3|X2,X1]P[X4|X3,X2,X1]
(we can also think of the chain rule as a “universal diagram” satisfied by all distributions; it’s a DAG with an edge between every two variables). We then separately write out the factorization stated by the diagram:
P[X1,X2,X3,X4]=P[X1]P[X2|X1]P[X3|X2]P[X4|X3]
Equating these two (then marginalizing variables different ways and doing some ordinary algebra), we find:
… which we can interpret as “probability of an error at step i, given all the earlier steps” - i.e. the left-hand side of each of the above - “depends only on the errors accumulated up through step i−1” - i.e. the right-hand side of each of the above. (Note: many of the proofs for rules in this post start by "breaking things up" this way, using the chain rule.)
So far, we’ve just stated what the starting diagram means. Now let’s look at one of the other diagrams:
The factorization stated by this diagram is
P[X1,X2,X3,X4]=P[X1|X2]P[X2|X3]P[X3]P[X4|X3]
Interpretation: we could model the system as though the error-cascade “starts” at step 3, and then errors propagate back through time to steps 2 and 1, and forward to step 4. Obviously this doesn’t match physical causality (i.e. do() operations will give different results on the two diagrams). But for purposes of modeling the underlying distribution P[X1,X2,X3,X4], this diagram is equivalent to the first diagram.
What does “equivalent” mean here? It means that any distribution which satisfies the factorization expressed by the first diagram (i.e. P[X1,X2,X3,X4]=P[X1]P[X2|X1]P[X3|X2]P[X4|X3]) also satisfies the factorization expressed by the second diagram (i.e. P[X1,X2,X3,X4]=P[X1|X2]P[X2|X3]P[X3]P[X4|X3]), and vice versa.
More generally, this is a standard example of what we mean when we say “diagram 1 implies diagram 2”, for any two diagrams: it means that any distribution which satisfies the factorization expressed by diagram 1 also satisfies the factorization expressed by diagram 2. If the two diagrams imply each other, then they are equivalent: they give us the same information about the underlying distribution.
Back to the example: how on earth would one model the widget error-cascade as starting at step 3? Think of it like this: if we want to simulate the error-cascade (i.e. write a program to sample from P[X1,X2,X3,X4]), we could do that by:
When we frame it that way, it’s not really something physical which is (modeled as) propagating back through time. Rather, we’re just epistemically working backward as a way to “solve for” the system’s behavior. And that’s a totally valid way to “solve for” this system’s behavior (though I wouldn’t personally want to code it that way).
In the context of our widget example, this seems… not very useful. Sure, the underlying distribution can be modeled using some awkward alternative diagram, but the alternative diagram doesn’t really seem better than the more-intuitive starting diagram. More generally, our rule for re-rooting Markov Chains is usually useful as an intermediate in a longer derivation; the real value isn’t in using it as a standalone rule.
Re-Rooting Rule, More Generally
More generally, any diagram of the form
is equivalent to any other diagram of the same form (i.e. take any other “root node” i).
For approximation, if the underlying distribution approximately satisfies any diagram of the form
to within ϵ, then it satisfies all the others to within ϵ.
Again, since this is our first rule, let’s unpack that compact notation. The diagram
expresses the factorization
P[X1,…,Xn]=(∏i≤kP[Xi−1|Xi])P[Xk](∏k≤i≤n−1P[Xi+1|Xi])
We say that the underlying distribution P[X1,…,Xn] “approximately satisfies the diagram to within ϵ” if-and-only-if
DKL(P[X1,…,Xn]||(∏i≤kP[Xi−1|Xi])P[Xk](∏k≤i≤n−1P[Xi+1|Xi]))≤ϵ
So, our approximation claim is saying: if DKL(P[X1,…,Xn]||(∏i≤kP[Xi−1|Xi])P[Xk](∏k≤i≤n−1P[Xi+1|Xi]))≤ϵ for any i, then DKL(P[X1,…,Xn]||(∏i≤kP[Xi−1|Xi])P[Xk](∏k≤i≤n−1P[Xi+1|Xi]))≤ϵ for all i. Indeed, the proof (in the appendix) shows that those DKL’s are all equal.
Joint Independence Rule
Suppose I roll three dice (X1,X2,X3). The first roll, X1, is independent of the second two, (X2,X3). The second roll, X2, is independent of (X1,X3). And the third roll, X_3, is independent of (X1,X2). Then: all three are independent.
If you’re like “wait, isn’t that just true by definition of independence?”, then you have roughly the right idea! (Some-but-not-all sources define many-variable independence this way.) But if we write out the underlying diagrams/math, it will be more clear that we have a nontrivial (though simple) claim. Our preconditions say:
or, in standard notation
P[X1,X2,X3]=P[X1]P[X2,X3]
P[X1,X2,X3]=P[X2]P[X1,X3]
P[X1,X2,X3]=P[X3]P[X1,X2]
Our claim is that these preconditions together imply:
or in the usual notation
P[X1,X2,X3]=P[X1]P[X2]P[X3]
That’s pretty easy to prove, but the more interesting part is approximation. If our three diagrams hold to within ϵ1,ϵ2,ϵ3 respectively, then the final diagram holds to within ϵ1+ϵ2+ϵ3. Writing it out the long way:
DKL(P[X1,X2,X3]||P[X1]P[X2,X3])≤ϵ1
DKL(P[X1,X2,X3]||P[X2]P[X1,X3])≤ϵ2
DKL(P[X1,X2,X3]||P[X3]P[X1,X2])≤ϵ3
(Note that, in the dice example, these DKL’s are each the mutual information of one die with the others, since MI(X;Y)=DKL(P[X,Y]||P[X]P[Y]) in general.) Together, they imply:
DKL(P[X1,X2,X3]||P[X1]P[X2]P[X3])≤ϵ1+ϵ2+ϵ3
In the context of the dice example: if I think that each die i individually is approximately independent of the others (to within ϵi bits of mutual information), that means the dice are all approximately jointly independent (to within ∑iϵi bits).
More generally, this all extends in the obvious way to more variables. If I have n variables, each of which is individually independent of all the others, then they’re all jointly independent. In the approximate case, if each of variables X1…Xn has only mutual information ϵi bits with the others, then the variables are jointly independent to within ∑iϵi bits - i.e.
DKL(P[X]||∏iP[Xi])≤∑iϵi
We can also easily extend the rule to conditional independence: if each of the variables X1…Xn has mutual information at most ϵi with the others conditional on some other variable Y, then the variables are jointly independent to within ∑iϵi bits conditional on Y. Diagrammatically:
The Frankenstein Rule
Now on to a more general/powerful rule.
Suppose we have an underlying distribution P[X1…X5] which satisfies both of these diagrams:
Notice that we can order the variables (X1,X3,X2,X5,X4); with that ordering, there are no arrows from “later” to “earlier” variables in either diagram. (We say that the ordering “respects both diagrams”.) That’s the key precondition we need in order to apply the Frankenstein Rule.
Because we have an ordering which respects both diagrams, we can construct "Frankenstein diagrams", which combine the two original diagrams. For each variable, we can choose which of the two original diagrams to take that variable’s incoming arrows from. For instance, in this case, we could choose:
resulting in this diagram:
But we could make other choices instead! We could just as easily choose:
which would yield this diagram:
The Frankenstein rule says that, so long as our underlying distribution satisfies both of the original diagrams, it satisfies any Frankenstein of the original diagrams (so long as there exists an order of the variables which respects both original diagrams).
More generally, suppose that:
If those two conditions hold, then we can create an arbitrary “Frankenstein diagram” from the two original diagrams: for each variable, we can take its incoming arrows from either of the two original diagrams. The underlying distribution will satisfy any Frankenstein diagram.
We can also extend the Frankenstein Rule to more than two original diagrams in the obvious way: so long as there exists an ordering of the variables which respects all diagrams, we can construct a Frankenstein which takes the incoming arrows of each variable from any of the original diagrams.
For approximation, we have two options. One approximate Frankenstein rule is simpler but gives mildly looser bounds, the other is a little more complicated but gives mildly tighter bounds (especially as the number of original diagrams increases).
The simpler approximation rule: if the original two diagrams are satisfied to within ϵ1 and ϵ2, respectively, then the Frankenstein is satisfied to within ϵ1+ϵ2. (And this extends in the obvious way to more-than-two original diagrams.)
The more complex approximation rule requires some additional machinery. For any diagram, we can decompose its DKL into one term for each variable via the chain rule:
DKL(P[X1,…,Xn]||∏iP[Xi|Xpa(i)])=DKL(∏iP[Xi|X<i]||∏iP[Xi|Xpa(i)])
=∑iE[DKL(P[Xi|X<i]||P[Xi|Xpa(i)])]
If we know how our upper bound ϵ on the diagram’s DKL decomposes across variables, then we can use that for more fine-grained bounds. Suppose that, for each diagram j and variable i, we have an upper bound
ϵij≥E[DKL(P[Xi|X<i]||P[Xi|Xpaj(i)])]
Then, we can get a fine-grained bound for the Frankenstein diagram. For each variable i, we add only the ϵij from the original diagram j from which we take that variables’ incoming arrows to build the Frankenstein. (Our simple approximation rule earlier added together all the ϵij’s from all of the original diagrams, so it was over-counting.)
Exercise: Using the Frankenstein Rule on the two diagrams at the beginning of this section, show that X3 is independent of all the other variables (assuming the two diagrams from the beginning of this section hold).
Factorization Transfer Rule
The factorization transfer rule is of interest basically-only in the approximate case; the exact version is quite trivial.
Our previous rules dealt with only one “underlying distribution” P[X1,…,Xn], and looked at various properties satisfied by that distribution. Now we’ll introduce a second distribution, Q[X1,…,Xn]. The Transfer Rule says that, if Q satisfies some diagram and Q approximates P (i.e. ϵ≥DKL(P||Q)), then P approximately satisfies the diagram (to within ϵ). The factorization (i.e. the diagram) “transfers” from Q to P.
A simple example: suppose I roll a die a bunch of times. Maybe there’s “really” some weak correlations between rolls, or some weak bias on the die; the “actual” distribution accounting for the correlations/bias is P. But I just model the rolls as independent, with all six outcomes equally probable for each roll; that’s Q.
Under Q, all the die rolls are independent: Q[X1,…,Xn]=∏iQ[Xi]. Diagrammatically:
So, if ϵ≥DKL(P||Q), then the die rolls are also approximately independent under P: ϵ≥DKL(P[X1,…,Xn]||∏iP[Xi]). That’s the Transfer Rule.
Stitching Rule for a Markov Blanket
Imagine I have some complicated Bayes net model for the internals of a control system, and another complicated Bayes net model for its environment. Both models include the sensors and actuators, which mediate between the system and environment. Intuitively, it seems like we should be able to “stitch together” the models into one joint model of system and environment combined. That’s what the Stitching Rule is for.
The Stitching Rule is complicated to describe verbally, but relatively easy to see visually. We start with two diagrams over different-but-overlapping variables:
In this case, the X variables only appear in the left diagram, Z variables only appear in the right diagram, but the Y variables appear in both. (Note that the left diagram states a property of P[X,Y] and the right diagram a property of P[Z,Y]; we’ll assume that both of those are marginal distributions of the underlying P[X,Y,Z].)
Conceptually, we want to “stitch” the two diagrams together along the variables Y. But we can’t do that in full generality: there could be all sorts of interactions between X and Z in the underlying distribution, and the two diagrams above don’t tell us much about those interactions. So, we’ll add one more diagram:
This says that X and Z interact only via Y, i.e. Y is a Markov blanket between X and Z. If this diagram and both diagrams from earlier hold, then we know what the X−Z interactions look like, so in-principle we can stitch the two diagrams together.
In practice, in order for the stitched diagram to have a nice form, we’ll require our diagrams to satisfy two more assumptions:
Short Exercise: verify these two conditions hold for our example above.
Then, the Stitching Rule says we can do something very much like the Frankenstein Rule. We create a stitched-together diagram in which:
(A Y-variable with neither an X-parent nor a Z-parent can take its parents from either diagram.) So, for our example above, we could stitch this diagram:
The Stitching Rule says that, if the underlying distribution satisfies both starting diagrams and Y is a markov blanket between X and Z and the two starting diagrams satisfy our two extra assumptions, then the above diagram holds.
In the approximate case, we have an ϵXY for the left diagram, an ϵZY for the right diagram, and an ϵblanket for the diagram X←Y→Z. Our final diagram holds to within ϵXY+ϵZY+ϵblanket. As with the Frankenstein rule, that bound is a little loose, and we can tighten it in the same way if we have more fine-grained bounds on DKL for individual variables in each diagram.
Bookkeeping Rules
[EDIT October 2024: We now have a very simple Bookkeeping Rule which unifies all of these, which you can find in this comment.]
If you’ve worked with Bayes nets before, you probably learned all sorts of things implied by a single diagram - e.g. conditional independencies from d-separation, “weaker” diagrams with edges added, that sort of thing. We’ll refer to these as “Bookkeeping Rules”, since they feel pretty minor if you’re already comfortable working with Bayes nets. Some examples:
Bookkeeping Rules (including all of the above) can typically be proven via the Factorization Transfer Rule.
Exercise: use the Factorization Transfer Rule to prove the d-separation Bookkeeping Rule above. (Alternative exercise, for those who don’t know/remember how d-separation works and don’t want to look it up: pick two of the other Bookkeeping Rules and use the Factorization Transfer Rule to prove them.)
End-to-End Example
This example is from an upcoming post on our latest work. Indeed, it’s the main application which motivated this post in the first place! We’re not going to give the background context in much depth here, just sketch a claim and its proof, but you should check out the upcoming post on Natural Latents (once it’s out) if you want to see how it fits into a bigger picture.
We’ll start with a bunch of “observable” random variables X1,…,Xn. In order to model these observables, two different agents learn to use two different latent variables: M and N (capital Greek letters μ and ν). Altogether, the variables satisfy three diagrams. The first agent chooses M such that all the observables are independent given M (so that it can perform efficient inference leveraging M):
The second agent happens to be interested in N, because N is very redundantly represented; even if any one observable Xi is ignored, the remainder give approximately-the-same information about N.
(Here ¯i denotes all the components of X except for Xi.) Finally, we’ll assume that there’s nothing relating the two agents and their latents to each other besides their shared observables, so
(Note: these are kinda-toy motivations of the three diagrams; our actual use-case provides more justification in some places.)
We’re going to show that M mediates between N and X, i.e.
Intuitive story: by the first diagram, all interactions between components of X “go through” M. So, any information which is redundant across many components of X must be included in M. N in particular is redundant across many components of X, so it must be included in M. That intuitive argument isn’t quite technically watertight, but at a glossy level it’s the right idea, and we’re going to prove it diagrammatically.
From our starting diagrams, a natural first step is to use the Stitching Rule, to combine together the M-diagram and the ith N-diagram across the Markov blanket X:
Via a couple Bookkeeping steps (add an arrow, reorder complete subgraph) we can rewrite that as
Note that we have n diagrams here (one for each i), and the variable ordering (N,M,X1,…,Xn) respects that diagram for every i, so we can Frankenstein all of those diagrams together. N is the root node, M has only N as parent (all diagrams agree on that), and then we take the parent of each Xi from the ith diagram. That yields:
And via one more Bookkeeping operation, we get
as desired.
Our full end-to-end proof, presented diagrammatically, looks like this:
Besides readability, one major benefit of this diagrammatic proof is that we can immediately derive approximation bounds for it. We assign a bound to each starting diagram, then just propagate through, using the approximate version of the rule at each step:
As a teaser: one use-case for this particular theorem is that, insofar as the second agent can express things-it-wants in terms of very redundantly represented latent variables (e.g. N), it will always be able to express those things in terms of the first agent’s latent variables (i.e. M). So, the second agent can express what it wants in terms of the first agent’s internal latent variables. It’s an approach to handling ontological problems, like e.g. The Pointers Problem.
What To Read Next
That concludes our list of rules! This post was written as a prelude to our upcoming post on Natural Latents, which will show a real application of these rules. If you want to build familiarity with the rules, we recommend trying a few exercises in this post, then walking through the proofs in that post (once it’s out), and checking the rules used at each step. There are also several exercises in the appendix of this post, alongside the proofs for the rules.
Appendix: Proofs & Exercises
Re-Rooting Rule for Markov Chains
First, we’ll show that we can move the root node one step to the right.
(∏i≤kP[Xi−1|Xi])P[Xk](∏k≤i≤n−1P[Xi+1|Xi])
=(∏i≤kP[Xi−1|Xi])P[Xk]P[Xk+1|Xk](∏k+1≤iP[Xi+1|Xi])
=(∏i≤kP[Xi−1|Xi])P[Xk+1,Xk](∏k+1≤iP[Xi+1|Xi])
=(∏i≤kP[Xi−1|Xi])P[Xk|Xk+1]P[Xk+1](∏k+1≤iP[Xi+1|Xi])
=(∏i≤k+1P[Xi−1|Xi])P[Xk+1](∏k+1≤iP[Xi+1|Xi])
Note that the same equations (read backwards) imply we can move the root node one step to the left. Then, by induction, we can move the root node as far as we want in either direction (noting that at either end one of the two products becomes an empty product).
Approximation
The previous proof shows that (∏i≤kP[Xi−1|Xi])P[Xk](∏k≤iP[Xi+1|Xi])=(∏i≤k+1P[Xi−1|Xi])P[Xk+1](∏k+1≤iP[Xi+1|Xi]) for all X (for any distribution). So,
DKL(P[X]||(∏i≤kP[Xi−1|Xi])P[Xk]∏k≤iP[Xi+1|Xi])
=DKL(P[X]||(∏i≤k+1P[Xi−1|Xi])P[Xk+1]∏k+1≤iP[Xi+1|Xi])
As before, the same equations imply that we can move the root node one step to either the left or right. Then, by induction, we can move the root node as far as we want in either direction, without changing the KL-divergence.
Exercise
Extend the above proofs to re-rooting of arbitrary trees (i.e. the diagram is a tree). We recommend thinking about your notation first; better choices for notation make working with trees much easier.
Joint Independence Rule: Exercise
The Joint Independence Rule can be proven using the Frankenstein Rule. This is left as an exercise. (And we mean that unironically, it is actually a good simple exercise which will highlight one or two subtle points, not a long slog of tedium as the phrase “left as an exercise” often indicates.)
Bonus exercise: also prove the conditional version of the Joint Independence Rule using the Frankenstein Rule.
Frankenstein Rule
We’ll prove the approximate version, then the exact version follows trivially.
Without loss of generality, assume the order of variables which satisfies all original diagrams is X1,…,Xn. Let P[X]=∏iP[Xi|Xpaj(i)] be the factorization expressed by diagram j, and let σ(i) be the diagram from which the parents of Xi are taken to form the Frankenstein diagram. (The factorization expressed by the Frankenstein diagram is then P[X]=∏iP[Xi|Xpaσ(i)(i)].)
The proof starts by applying the chain rule to the DKL of the Frankenstein diagram:
DKL(P[X]||∏iP[Xi|Xpaσ(i)(i)])=DKL(∏iP[Xi|X<i||∏iP[Xi|Xpaσ(i)(i)])
=∑iE[DKL(P[Xi|X<i]||P[Xi|Xpaσ(i)(i)])]
Then, we add a few more expected KL-divergences (i.e. add some non-negative numbers) to get:
≤∑i∑jE[DKL(P[Xi|X<i]||P[Xi|Xpaj(i)])]=∑jDKL(P[X]||∏iP[Xi|Xpaj(i)])
≤∑jϵj
Thus, we have
DKL(P[X]||∏iP[Xi|Xpaσ(i)(i)])≤∑jDKL(P[X]||∏iP[Xi|Xpaj(i)])≤∑jϵj
Factorization Transfer
Again, we’ll prove the approximate version, and the exact version then follows trivially.
As with the Frankenstein rule, we start by splitting our DKL into a term for each variable:
DKL(P[X]||Q[X])=∑iE[DKL(P[Xi||X<i]||Q[Xi||Xpa(i)])]
Next, we subtract some more DKL’s (i.e. subtract some non-negative numbers) to get:
≥∑i(E[DKL(P[Xi||X<i]||Q[Xi||Xpa(i)])]−E[DKL(P[Xi||Xpa(i)]||Q[Xi||Xpa(i)])])
=∑iE[DKL(P[Xi||X<i]||P[Xi||Xpa(i)])]
=DKL(P[X]||∏iP[Xi||Xpa(i)])
Thus, we have
DKL(P[X]||Q[X])≥DKL(P[X]||∏iP[Xi||Xpa(i)])
Stitching
We start with the X←Y→Z condition:
ϵblanket≥DKL(P[X,Y,Z]||P[X|Y]P[Y]P[Z|Y])
=DKL(P[X,Y,Z]||P[X,Y]P[Z,Y]/P[Y])
At a cost of at most ϵXY, we can replace P[X,Y] with ∏iP[(X,Y)i|(X,Y)paXY(i)] in that expression, and likewise for the P[Z,Y] term. (You can verify this by writing out the DKL’s as expected log probabilities.)
ϵblanket+ϵXY+ϵZY≥DKL(P[X,Y,Z]||∏iP[(X,Y)i|(X,Y)paXY(i)]∏iP[(Z,Y)i|(Z,Y)paZY(i)]/P[Y])
Notation:
Recall that each component of YZY must have no X-parents in the XY-diagram, and each component of YXY must have no Z-parents in the ZY-diagram. Let’s pull those terms out of the products above so we can simplify them:
ϵblanket+ϵXY+ϵZY
≥DKL(P[X,Y,Z]||∏iP[(X,YXY)i|(X,Y)paXY(i)]∏iP[YZYi|YpaXY(i)]∏iP[(Z,YZY)i|(Z,Y)paZY(i)]∏iP[YXYi|YpaZY(i)]/P[Y])
Those simplified terms in combination with 1/P[Y] are themselves a DKL, which we can separate out:
=DKL(P[X,Y,Z]||∏iP[(X,YXY)i|(X,Y)paXY(i)]∏iP[(Z,YZY)i|(Z,Y)paZY(i)])+DKL(P[Y]||∏iP[YXYi|YpaZY(i)]∏iP[YZYi|YpaXY(i)])
≥DKL(P[X,Y,Z]||∏iP[(X,YXY)i|(X,Y)paXY(i)]∏iP[(Z,YZY)i|(Z,Y)paZY(i)])
… and that last line is the DKL for the stitched diagram.