This is a linkpost for https://deepmind.com/blog/article/generally-capable-agents-emerge-from-open-ended-play
New Comment
This is certainly interesting! To put things in proportion though, here are some limitations that I see, after skimming the paper and watching the video:
- The virtual laws of physics are always the same. So, the sense in which this agent is "generally capable" is only via the geometry and the formal specification of the goal. Which is still interesting to be sure! But not as a big deal as it would be if it did zero-shot learning of physics (which would be an enormous deal IMO).
- The formal specification is limited to propositional calculus. This allows for a combinatorial explosion of possible goals, but there's still some sense in which it is "narrow". It would be a bigger deal if it used some more expressive logical language.
- For some tasks it looks like the agent is just trying vaguely relevant things at random until it achieves the goal. So, it is able to recognize the goal has been achieved, but less able to come up with efficient plans for achieving it. While "trying stuff until something sticks" is definitely a strategy I can relate to, it is not as impressive as planning in advance. Notice that just recognizing the goal is relatively easy: modulo the transformation from 2D imagery to a 3D model (which is certainly non-trivial but not a novel capability), you don't need AI to do it at all (indeed the environment obviously computes the reward via handcrafted code).
Thanks! This is exactly the sort of thoughtful commentary I was hoping to get when I made this linkpost.
--I don't see what the big deal is about laws of physics. Humans and all their ancestors evolved in a world with the same laws of physics; we didn't have to generalize to different worlds with different laws. Also, I don't think "be superhuman at figuring out the true laws of physics" is on the shortest path to AIs being dangerous. Also, I don't think AIs need to control robots or whatnot in the real world to be dangerous, so they don't even need to be able to understand the true laws of physics, even on a basic level.
--I agree it would be a bigger deal if they could use e.g. first-order logic, but not that much of a bigger deal? Put it this way: wanna bet about what would happen if they retrained these agents, but with 10x bigger brains and for 10x longer, in an expanded environment that supported first-order logic? I'd bet that we'd get agents that perform decently well at first-order logic goals.
--Yeah, these agents don't seem smart exactly; they seem to be following pretty simple general strategies... but they seem human-like and on a path to smartness, i.e. I can easily imagine them getting smoothly better and better as we make them bigger and train them for longer on more varied environments. I think of these guys as the GPT-1 of agent AGI.
I don't see what the big deal is about laws of physics. Humans and all their ancestors evolved in a world with the same laws of physics; we didn't have to generalize to different worlds with different laws. Also, I don't think "be superhuman at figuring out the true laws of physics" is on the shortest path to AIs being dangerous. Also, I don't think AIs need to control robots or whatnot in the real world to be dangerous, so they don't even need to be able to understand the true laws of physics, even on a basic level.
The entire novelty of this work revolves around zero-shot / few-shot performance: the ability to learn new tasks which don't come with astronomic amounts of training data. To evaluate to which extent this goal has been achieved, we need to look at what was actually new about the tasks vs. what was repeated in the training data a zillion times. So, my point was, the laws of physics do not contribute to this aspect.
Moreover, although the laws of physics are fixed, we didn't evolve to know all of physics. Lots of intuition about 3D geometry and mechanics: definitely. But there are many, many things about the world we had to learn. A bronze age blacksmith posseted sophisticated knowledge about the properties of materials and their interaction that did not come from their genes, not to mention a modern rocket scientist. (Ofc, the communication of knowledge means that each of them benefits from training data acquired by other people and previous generations, and yet.) And, learning is equivalent to performing well on a distribution of different worlds.
Finally, an AI doesn't need to control robots to be dangerous but it does need to create sophisticated models of the world and the laws which govern it. That doesn't necessarily mean being good at the precise thing we call "physics" (e.g. figuring out quantum gravity), but it is a sort of "physics" broadly construed (so, including any area of science and/or human behavior and/or dynamics of human societies etc.)
I agree it would be a bigger deal if they could use e.g. first-order logic, but not that much of a bigger deal? Put it this way: wanna bet about what would happen if they retrained these agents, but with 10x bigger brains and for 10x longer, in an expanded environment that supported first-order logic?
I might be tempted to take some such bet, but it seems hard to operationalize. Also hard to test unless DeepMind will happen to perform this exact experiment.
What really impressed me were the generalized strategies the agent applied to multiple situations/goals. E.g., "randomly move things around until something works" sounds simple, but learning to contextually apply that strategy
- to the appropriate objects,
- in scenarios where you don't have a better idea of what to do, and
- immediately stopping when you find something that works
is fairly difficult for deep agents to learn. I think of this work as giving the RL agents a toolbox of strategies that can be flexibly applied to different scenarios.
I suspect that finetuning agents trained in XLand in other physical environments will give good results because the XLand agents already know how to use relatively advanced strategies. Learning to apply the XLand strategies to the new physical environments will probably be easier than starting from scratch in the new environment.
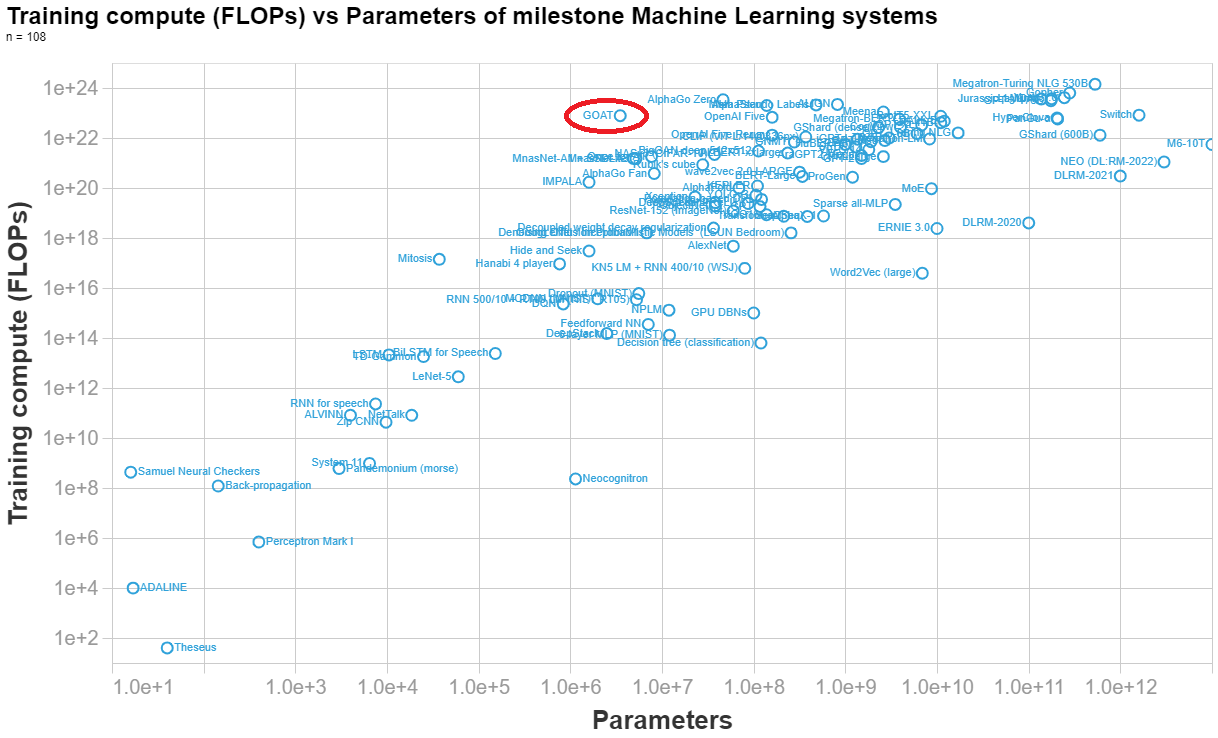
Marius Hobbhahn has estimated the number of parameters here. His final estimate is 3.5e6 parameters.
Anson Ho has estimated the training compute (his reasoning at the end of this answer). His final estimate is 7.8e22 FLOPs.
Below I made a visualization of the parameters vs training compute of n=108 important ML system, so you can see how DeepMind's syste (labelled GOAT in the graph) compares to other systems.
[Final calculation]
(8 TPUs)(4.20e14 FLOP/s)(0.1 utilisation rate)(32 agents)(7.3e6 s/agent) = 7.8e22 FLOPs==========================
NOTES BELOW[Hardware]
- "Each agent is trained using 8 TPUv3s and consumes approximately 50,000 agent steps (observations) per second."
- TPUv3 (half precision): 4.2e14 FLOP/s
- Number of TPUs: 8
- Utilisation rate: 0.1[Timesteps]
- Figure 16 shows steps per generation and agent. In total there are 1.5e10 + 4.0e10 + 2.5e10 + 1.1e11 + 2e11 = 3.9e11 steps per agent.
- 3.9e11 / 5e4 = 8e6 s → ~93 days
- 100 million steps is equivalent to 30 minutes of wall-clock time in our setup. (pg 29, fig 27)
- 1e8 steps → 0.5h
- 3.9e11 steps → 1950h → 7.0e6 s → ~82 days
- Both of these seem like overestimates, because:
“Finally, on the largest timescale (days), generational training iteratively improves population performance by bootstrapping off previous generations, whilst also iteratively updating the validation normalised percentile metric itself.” (pg 16)
- Suggests that the above is an overestimate of the number of days needed, else they would have said (months) or (weeks)?
- Final choice (guesstimate): 85 days = 7.3e6 s[Population size]
- 8 agents? (pg 21) → this is describing the case where they’re not using PBT, so ignore this number
- The original PBT paper uses 32 agents for one task https://arxiv.org/pdf/1711.09846.pdf (in general it uses between 10 and 80)
- (Guesstimate) Average population size: 32
Thanks so much! So, for comparison, fruit flies have more synapses than these XLAND/GOAT agents have parameters! https://en.wikipedia.org/wiki/List_of_animals_by_number_of_neurons
Looking qualitatively at our agents, we often see general, heuristic behaviours emerge — rather than highly optimised, specific behaviours for individual tasks. Instead of agents knowing exactly the “best thing” to do in a new situation, we see evidence of agents experimenting and changing the state of the world until they’ve achieved a rewarding state.
The blessings of scale strike again. People have been remarkably quick to dismiss the lack of "GPT-4" models as indicating that the scaling hypothesis is dead already. (The only scaling hypothesis refuted by the past year is the 'budget scaling hypothesis', if you will. All the other research continues to confirm it.)
Incidentally, it's well worth reading the previous papers from DM on using populations to learn ever more complex and general tasks: AlphaStar, Quake, rats, VR/language robotics, team soccer.
We've all read about AlpaFold 2, but I'd also highlight VQ-VAE being used increasingly pervasively as a drop-in generative model; "Multimodal Few-Shot Learning with Frozen Language Models", Tsimpoukelli et al 2021, further demonstrating the power of large self-supervised models for fast human-like learning; and the always-underappreciated line of work on MuZero for doing sample-efficient & continuous-action model-based RL: "MuZero Unplugged: Online and Offline Reinforcement Learning by Planning with a Learned Model", Schrittwieser et al 2021; "Sampled MuZero: Learning and Planning in Complex Action Spaces", Hubert et al 2021 (benefiting from better use of existing compute, like Podracer).
This is amazing. So it's the exact same agents performing well on all of these different tasks, not just the same general algorithm retrained on lots of examples. In which case, have they found a generally useful way around the catastrophic forgetting problem? I guess the whole training procedure, amount of compute + experience, and architecture, taken together, just solves catastrophic forgetting - at least for a far wider range of tasks than I've seen so far.
Could you use this technique to e.g. train the same agent to do well on chess and go?
I also notice as per the little animated gifs in the blogpost, that they gave each agent little death ray projectors to manipulate objects, and that they look a lot like Daleks.
{kind=link}
Didn't they train a separate MuZero agent for each game? E.g. the page you link only talks about being able to learn without pre-existing knowledge.
Actually, I think you're right. I always thought that MuZero was one and the same system for every game, but the Nature paper describes it as an architecture that can be applied to learn different games. I'd like a confirmation from someone who actually studied it more, but it looks like MuZero indeed isn't the same system for each game.
EDIT: Also see paper and results compilation video!
...
...
My hot take: This seems like a somewhat big deal to me. It's what I would have predicted, but that's scary, given my timelines. I haven't read the paper itself yet but I look forward to seeing more numbers and scaling trends and attempting to extrapolate... When I do I'll leave a comment with my thoughts.
EDIT: My warm take: The details in the paper back up the claims it makes in the title and abstract. This is the GPT-1 of agent/goal-directed AGI; it is the proof of concept. Two more papers down the line (and a few OOMs more compute), and we'll have the agent/goal-directed AGI equivalent of GPT-3. Scary stuff.