Yeah, especially if this becomes standard part of big company toolboxes, it feels like it might noticeably (~1%?) reduce overall AI risks. Gives company more fine-grained cheap control over what skills a model has vs. lacks.
Idea: Use this to make more faithful CoT models:
--Take your best model and scrape all it's CoTs including with tool calls etc.
--Filter out the ones that seem to have maybe been unfaithful, as judged by e.g. activations for deception or whatnot.
--maybe also filter out any discussion of CoT monitoring and CoT lol
--Distill.
--Take the new model and see if it has better faithfulness properties, e.g. is harder to fine-tune to fool monitoring systems. Hopefully the answer is yes.
--Then maybe do another technique, where you train a smaller faster model to do more steps of reasoning to get to the same result. Like, take the CoT of your previous model and divide it into N chunks, where each chunk is like a sentence or so. Then train a new, smaller model to take chunk 1 and do lots of CoT and eventually reach chunk 2, and then to take chunk 1+CoT+chunk2 and do lots of CoT to eventually reach chunk 3, and so on. So that basically you have a model that tends to do more of its thinking in CoT, but has a similar capability and propensity profile.
I really like this idea and the point about distillation making things adjacent to retraining from scratch tractable.
Contra what many people said here, I think it's not an obvious idea because things that look like "training from scratch" are somewhat far away from the option space of many people working on unlearning (including me!).
I don't understand why using an unlearning method like RMU and then doing distillation of that unlearned model is conceptually different than data filtering. My understanding is that RMU is well-approximated by "if looks like harmful, then produce noise else behave normally". Distilling that model is very similar to using the implicit "looks like harmful" classifier to filter out data. My understanding is that the main reason to use RMU instead of training a classifier is that you save 50% of your compute by using the same model both for classification and distillation, is that right? If this is really the main value add, my guess is that there are better strategies (e.g. training a value head for classification, or re-using the KV cache for classification).
To the extent that training models to produce noise / have high NTP loss on harmful tokens is load-bearing, I think this is another cool idea that can be applied independently. In other words, "using unlearning techniques like GradDiff/MaxEnt during pretraining" might be a really powerful technique.
I find the UNDO results underwhelming, but I like the idea. My guess is that there are ways you could use 1% of pre-training compute to train a model with near-perfect robust forget accuracy by being more targeted in where you add noise.
Many thanks for sparking this discussion, Fabien. I see Addie addressed the technical distinctions. Let me add complementary points. Please feel free to continue the conversation in either one. Addie and I can coordinate a response.
In a nutshell, Unlearn-and-Distill allows you to work at the model behavior level rather than the training data level. I mostly view it as a responsive tool, not a preventive one. Here are my thoughts organized into subclaims.
Claim: The fundamental difference between unlearning and data filtering lies in when and how we identify harmful content.
Rationale: Data filtering requires identifying "data -> capabilities" patterns in advance, while behavioral unlearning targets actual harmful outputs after they emerge. This matters because harmful capabilities often arise from non-obvious combinations of benign knowledge. Even if creating a classifier is computationally similar to unlearning, you're solving fundamentally different problems: (original framing) predicting emergent behaviors from raw data versus (new framing) suppressing already observed behaviors. With unlearning, you can iteratively refine until you achieve the desired behavior, then distill. With data filtering, you don't know the effects of your filtering until after training completes.
Claim: Computational efficiency is not the only value added from this work. Unlearn + distill requires significantly less labeled data than data filtering.
Rationale: Most unlearning procedures only use labels of a small fraction of the pretraining data. In our setup, it was less than 0.01% for language. This eases the data labeling requirement. At modern scales, the difference between labeling 0.01% vs 100% represents substantial annotation efforts. Note that we distilled on the whole pretraining data, but none of it was labeled. The suggestions about value heads or KV cache reuse are interesting optimizations worth exploring, though they don't address this fundamental labeling asymmetry.
Claim: Our robustness metric undersells the method's performance, though stronger attacks may exist.
Rationale: The adversary is extremely strong (best of 9 learning rates, 500 training steps, 8M tokens for language, 2M tokens for arithmetic). Even the oracle model (never trained on the forget domain) reaches 50% performance under this attack in arithmetic tasks.
Separately, while 30% compute for 50% robustness (compared to data filtering) isn't cheap, this tradeoff didn't exist before. The value add of UNDO over Unlearn-and-Distill is that it provides a tunable compute/robustness knob between the conventional unlearning and full reinitialization/data filtering
With unlearning, you can iteratively refine until you achieve the desired behavior, then distill.
How? Because current unlearning is shallow, you don't know if it produces noise on the relevant pretraining tokens. So my guess is that iterating against unlearning by seeing if the model helps you build bioweapons is worse than also seeing if it produces noise on relevant pretraining tokens, and the later is roughly as much signal than iterating against a classifier by looking at whether it detects bioweapons advice and relevant pretraining tokens. This might be wrong if my conjecture explained in Addie's comment is wrong though.
Unlearn + distill requires significantly less labeled data than data filtering
I think you missed the point here. My suggested scheme is 1. label a small amount of data 2. train a classifier 3. apply the classifier to know if you should skip a token / make the target logprobs be noise or use the original logprobs. This is spiritually the same as 1. label a small amount of data 2. use that for unlearning 3. apply the unlearned model to know if the target logprobs should be noise or sth close to the original logprobs.
Our robustness metric undersells the method's performance
I agree with that, and I'd bet that UNDO likely increases jailbreak robustness even in the 1%-of-pretrain-compute regime. But you did not run experiments that show the value of UNDO in the 1%-of-pretrain-compute regime, right?
Separately, while 30% compute for 50% robustness (compared to data filtering) isn't cheap, this tradeoff didn't exist before. The value add of UNDO over Unlearn-and-Distill is that it provides a tunable compute/robustness knob between the conventional unlearning and full reinitialization/data filtering
Fair, I also agree. This to be a part of the option space that nobody is interested in, but it's still scientifically interesting. But I think it's noteworthy that there results are so negative, if I had been asked to predict results of UNDO, I would have predicted much stronger results.
I think you missed the point here. My suggested scheme is 1. label a small amount of data 2. train a classifier 3. apply the classifier to know if you should skip a token / make the target logprobs be noise or use the original logprobs. This is spiritually the same as 1. label a small amount of data 2. use that for unlearning 3. apply the unlearned model to know if the target logprobs should be noise or sth close to the original logprobs.
EDIT: I think I misunderstood your original point - were you saying to just label all of the data using a classifier trained on just 1% of the pretraining data? (Neither of your schemes say what to do after step 3.)
> UNDO over Unlearn-and-Distill is that it provides a tunable compute/robustness knob between the conventional unlearning and full reinitialization/data filtering
This to be a part of the option space that nobody is interested in, but it's still scientifically interesting.
Why do you claim that no one is interested in this? Lots of labs do data filtering, which is known to be effective but quite costly to iterate on.
EDIT: I think I misunderstood your original point - were you saying to just label all of the data using a classifier trained on just 1% of the pretraining data? (Neither of your schemes say what to do after step 3.)
Oops I was more unclear than I thought.
I am imagining schemes of the form:
- you create a small set of data labeled "harmful / not harmful"
- you use it to train your filter / unlearning model. That is small and it's cheap to iterate on it.
- you do distillation on pretraining tokens, either
- on sth like 0 if filter(x)=harmful else logprobs(regular base model) (this is regular data filtering + distillation)
- on logprobs(unlearned model) (this is what you are suggesting)
- (and I claim this has roughly the same effect as i to distilling on noise if implicit_unlearning_filter(x)=harmful else logprobs(regular base model) because I would guess this is roughly what the logprobs of unlearned models look like)
(and this produces a base model that does not have the harmful knowledge, which you use for your regular post-training pipeline then deployment).
Why do you claim that no one is interested in this? Lots of labs do data filtering, which is known to be effective but quite costly to iterate on.
I think using UNDO at p=50% of full retraining compute is not much cheaper than regular distillation (on an unlearned / filtered model), adds a lot of risk to a potentially very expensive operation, and has fewer robustness benefit than full retraining. But maybe I am wrong here, I expressed too much confidence. (I also think it doesn't really matter, my guess is that future work will find much stronger positive results in this part of the space and push the pareto frontier beyond UNDO.)
quite costly to iterate on.
[edit] actually I maybe missed this part. I did not take into account that an UNDO(10%) could be a great de-risking strategy for a full distillation run, which makes UNDO(10%) much more relevant than I thought. Good point.
Clarifying what I mean by UNDO being underwhelming: you might have hoped that you could use 1% of pre-training compute to train a model with near-perfect robust forget accuracy. But if you want to get to even 50% robustness with UNDO you need to spend around 30% of the train-from-scratch compute, which is brutally expensive.
Yeah, I totally agree that targeted noise is a promising direction! However, I wouldn't take the exact % of pretraining compute that we found as a hard number, but rather as a comparison between the different noise levels. I would guess labs may have better distillation techniques that could speed it up. It also seems possible that you could distill into a smaller model faster and still recover performance with distillation. This would require modification to UNDO initialization, (e.g. initializing it as a noised version of the smaller model rather than the teacher) but still seems possible. Also, in some cases labs already do distillation, and in these cases it would have a smaller added cost.
Wasn't it the case that for some reason, full distillation had comparable compute requirement to data filtering? I was surprised by that. My impression is that distillation should be more like 10% of pretraining (data filtering), which would make the computational UNDO results much stronger. Not sure what happened here.
In other words, "using unlearning techniques like GradDiff/MaxEnt during pretraining" might be a really powerful technique.
I have a cached thought that this was found to disrupt overall capabilities / make learning harder, but I don't have a reference on hand.
Thanks for the comment!
I agree that exploring targeted noise is a very promising direction and could substantially speed up the method! Could you elaborate on what you mean about unlearning techniques during pretraining?
I don't think datafiltering+distillation is analogous to unlearning+distillation. During distillation, the student learns from the predictions of the teacher, not the data itself. The predictions can leak information about the undesired capability, even on data that is benign. In a preliminary experiment, we found that datafiltering+distillation was ineffective in a TinyStories setting, but more effective in the language setting (see this comment). It's possible that real world applications differ from the former setting. Maybe the context in which information about the forget capabilities are revealed are always different/identifiable and datafiltering+distillation would be effective, but I expect this isn't usually the case.
As a concrete example, let's say we want to unlearn the following fact:
The company x data center is in location y.
We filter all of the sentences that give information about the datacenter in location y, but there still is a benign sentence that says:
The company x data center is in location z.
Given the teacher model knows about data centers in location y and z, the teacher will have high probabilities on logits y and z, and the student will learn about both data centers.
Maybe there's a way to have a classifier that predicts whether the teacher model will reveal any information about the forget capability, but it seems a bit complicated by the fact that you can't just look at the top logit.
I do think unlearning+distillation is conceptually analogous to datafiltering+pretraining. However, I think there are practical differences, including the following:
- With Unlearn and Distilll it's easier/cheaper to accurately control end behavior
- You can do many tries at the initial unlearning until it is satisfactory and expect the distilled student to behave like the teacher.
- With datafiltering+pretraining, you don't get to see how the model will perform until it's trained.
- You can do many tries of training a classifier, but it's unclear what the ideal classifier would be.
- It may be possible to learn undesired capabilities from a combination of seemingly benign data.
- The cost probably differ
- With datafiltering+pretraining, you can probably use a smaller model as a classifier (or even just heuristics) so you remove the cost of distilling but add the cost of applying this classifier to the pretraining corpus.
- In practice, I'm not sure how expensive distillation is compared to pretraining.
- Distillation may already be a part of the pipeline in order to get a smaller, faster model, so unlearning before hand may be not much extra cost.
Could you elaborate on what you mean about unlearning techniques during pretraining?
I mean (for gradiff) train on Loss = [- NTP(tokens)] if tokens is harmful else NTP(tokens) instead of Loss = 0 if tokens is harmful else NTP(tokens).
I don't think datafiltering+distillation is analogous to unlearning+distillation
I do think unlearning+distillation is conceptually analogous to datafiltering+pretraining
Ok I see your point. I wonder if this is true in practice for unlearning techniques like RMU though. My understanding of RMU is that the logprobs are roughly "noise if detect harmful else original", in which case filtering+distillation would be roughly the same as unlearning (except if training on noise is better than training on 0). I expect that for most tokens where an RMU base model does not produce noise, it would produce a tiny KL divergence with the original model, and to the extent that your RMU train set is bad enough that RMU "misclassified" some datapoints and does not produce noise on them, I expect that if the original model would have leaked information about those datapoints, RMU will leak them too. But that's an empirical question, and I am only ~60% sure that I am correct here. Did you run experiments to test this?
(The fact that you are using an RMU base model and using tokens from pretrain as opposed to tokens generated by the model itself matters a little bit here. I think you would get more robustness but also less distillation efficiency by fine-tuning on sequences generated by a model trained to refuse to talk about harmful topics. RMU = the noise thing + refusal, but you would not use refusal for a base model, and it would not help anyway if you used pretrain tokens because refusal is often just a few tokens deep.)
I see what you mean. I would have guessed that the unlearned model behavior is meaningfully different than "produce noise on harmful else original". My guess is that the noise if harmful is accurate, but the small differences in logits on non-harmful data are quite important. We didn't run experiments on this. It would be an interesting empirical question to answer!
Also, there could be some variation on how true this is between different unlearning methods. We did find that RMU+distillation was less robust in the arithmetic setting than the other initial unlearning methods.
Fwiw, I'm not sure that RMU is a better unlearning method than simpler alternatives. I think it might just appear better on WMDP because the WMDP datasets are very messy and don't isolate the capability well, which could be done better with a cleaned dataset. Then, the performance on the evaluation relies on unnecessary generalization.
the small differences in logits on non-harmful data are quite important
My guess is that if you used mech interp on RMU models, you would find that the internals look a lot like if(harmful) then add a big vector to the residual stream else keep it as is. If this is the case, then I don't see why there would be a difference in logprobs on non-harmful tokens.
I was just singling out RMU because I believe I understand its effects a bit more than for other methods.
We did find that RMU+distillation was less robust in the arithmetic setting than the other initial unlearning methods.
This is interesting! I think I would have guessed the opposite. I don't have a great hypothesis for what GradDiff does mechanistically.
I wrote up some thoughts on how distillation can be used for AI safety here. The most relevant section of this post is this section about using distillation for more precise capability control.
My thoughts here were written independently and in parallel. (I wasn't aware of this work while I wrote my proposal and I'm glad to see work in this area!)
Great paper, this is hopeful for unlearning being used in practice.
I wonder if UNDO would stack with circuit discovery or some other kind of interpretability. Intuitively, localizing the noise in the Noise phase to weights that disproportionally contribute to the harmful behavior should get a better retain-forget tradeoff. It doesn't need to be perfect, just better than random, so it should be doable with current methods.
This looks great.
Random thought: I wonder how iterating the noise & distill steps of UNDO (each round with small alpha) compares against doing one noise with big alpha and then one distill session. (If we hold compute fixed.)
Couldn't find any experiments on this when skimming through the paper, but let me know if I missed it.
One setting that might be useful to study is the one in Grebe et al., which I just saw at the ICML MUGen workshop. The idea is to insert a backdoor that points to the forget set; they study diffusion models but it should be applicable to LLMs too. It would be neat if UNDO or some variant can be shown to be robust to this-- I think it would depend on how much noising is needed to remove backdoors, which I'm not familiar with.
Current “unlearning” methods only suppress capabilities instead of truly unlearning the capabilities. But if you distill an unlearned model into a randomly initialized model, the resulting network is actually robust to relearning. We show why this works, how well it works, and how to trade off compute for robustness.
Produced as part of the ML Alignment & Theory Scholars Program in the winter 2024–25 cohort of the shard theory stream.
Read our paper on ArXiv and enjoy an interactive demo.
Robust unlearning probably reduces AI risk
Maybe some future AI has long-term goals and humanity is in its way. Maybe future open-weight AIs have tons of bioterror expertise. If a system has dangerous knowledge, that system becomes more dangerous, either in the wrong hands or in the AI’s own “hands.” By making it harder to get AIs to share or use dangerous knowledge, we decrease (but do not eliminate) catastrophic risk.
Misuse risk. Robust unlearning prevents finetuning attacks from easily retraining a model to share or use the unlearned skill or behavior. Since anyone can finetune an open-weight model, it’s not enough to just suppress the model before releasing it.
However, even closed-source models can be jailbroken. If the capability is truly no longer present, then a jailbreak can’t elicit an ability that isn’t there to begin with.
Misalignment risk. Robust unlearning could remove strategic knowledge and skills that an unaligned AI might rely on. Potential removal targets include knowledge of: AI control protocols or datacenter security practices; weight exfiltration; self-modification techniques; the fact that it is an AI system; or even the ability to be influenced by negative stereotypes about AI. Robust unlearning could maybe even cripple an AI’s hacking or biology skills, or make it a less convincing liar.
Perhaps robust unlearning simply makes it harder for an AI to reason about an area, but doesn’t stop the AI entirely. That outcome would still be less risky.
Perfect data filtering is the current unlearning gold standard
Data filtering removes the training data related to the undesired capabilities. Sadly, data filtering is usually impractical.
If we want practical robust unlearning, we probably need a different approach.
Oracle matching does not guarantee robust unlearning
Most unlearning methods try to make a model forget a specified capability by finetuning it. However, finetuning only teaches the model to suppress the behavior, not remove the underlying capability.
We show this limitation persists even in the idealized setting of finetuning a model to exactly match the outputs of an oracle model that has never learned the specified capability in the first place. We take a model pretrained on both retain and forget data and finetune it on the logits of an oracle model, which was trained only on the retain data. Before subjecting the models to a relearning attack, the finetuned model behaves nearly identically to the oracle, but when we retrain both to relearn the forgotten capability, the finetuned model picks it up much faster. The capability wasn’t erased; it was just hidden.
Despite minimal initial differences in behavior (i.e. logits), the student model initialized from the full pretrained model (trained on both retain and forget data) relearns the “unlearned” capability much faster than either the oracle or a randomly initialized student on which we performed oracle distillation.
The faster relearning implies that finetuning a pretrained model to have certain outputs is not sufficient for robust unlearning. The weights still contain the capability, but the model just learned how not to show that capability.
Distillation robustifies unlearning
Imagine you’re an algebra student and your teacher pretends not to know algebra. Despite the fact that the teacher does know it themselves, you as a student will not learn.
Similarly, you might expect that when distilling a model, only the expressed behaviors are transferred and the latent capabilities are not. We show this is true. Distilling a conventionally unlearned model into a randomly initialized model creates a student that is robustly incapable of the forget capability. We call this method Unlearn-and-Distill, and it has two phases:
On both language and arithmetic tasks, we apply Unlearn-and-Distill using three different unlearning methods. We finally apply relearning attacks to test robustness. For each unlearning method and setting, we compare:
Across the board, Unlearn-and-Distill is more resistant to relearning than its unlearned-only counterpart. In some cases, it's nearly as robust as the gold standard. This supports the idea that latent capabilities are present in the original model parameters but don’t transfer to fresh parameters during distillation. Occasionally, like with RMU/Arithmetic, the initial unlearning is poor, and the distilled model relearns quickly. This shows that if suppression is too weak, the capability can still “leak through” and be reconstructed.
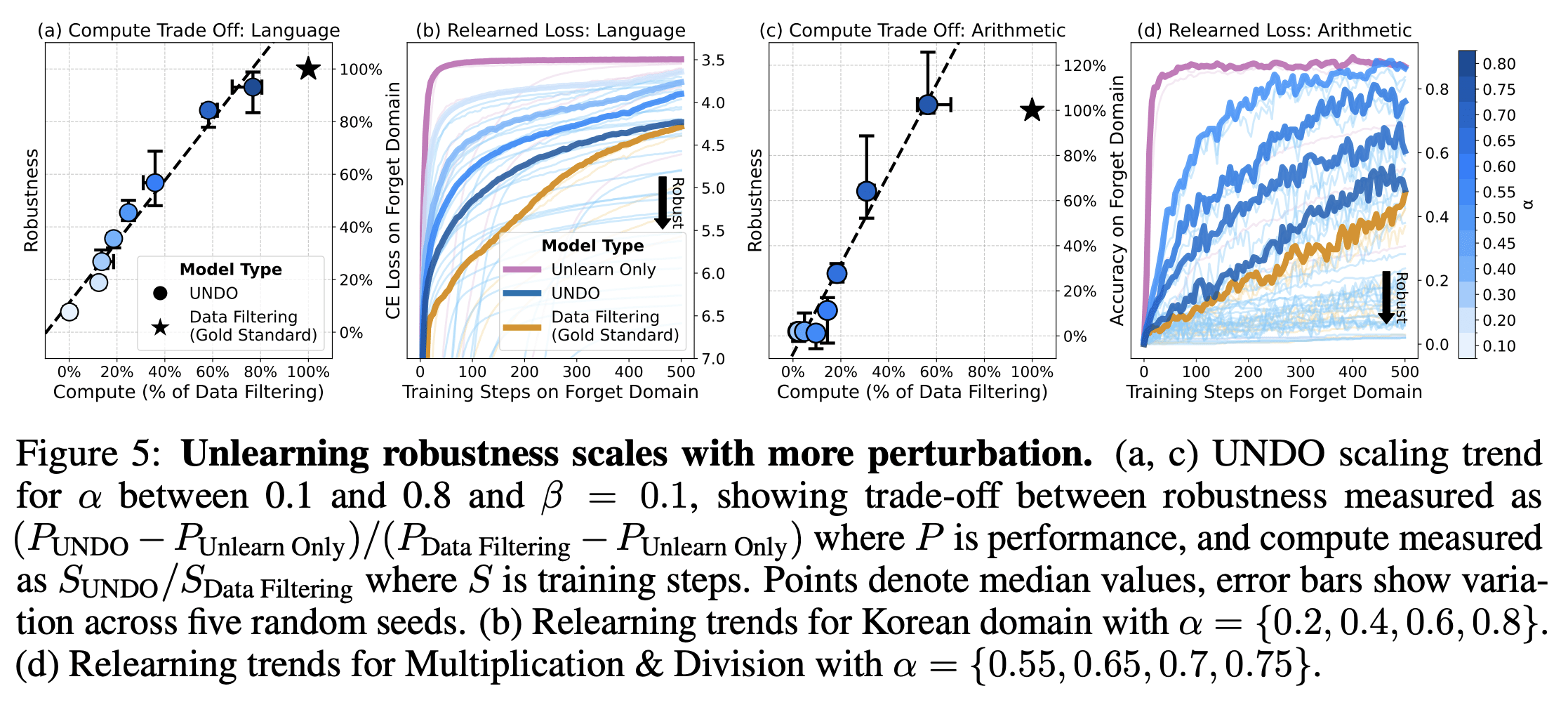
Trading unlearning robustness for compute
While data filtering requires training a model from scratch, Unlearn-and-Distill only requires some finetuning (unlearning) and then distillation. That’s reasonably cheap, but it can still take a fair chunk of compute. We develop a method to flexibly trade off between compute and robustness.
We introduce UNDO (Unlearn-Noise-Distill-on-Outputs), a generalization of our earlier Unlearn-and-Distill method. It’s a three-step process:
To inject noise, we use a shrink-and-perturb procedure that controls damage via a parameter α (higher α = more damage). We then distill until the student recovers 95% of the teacher model’s retain performance.
In plots (a) and (c), as α increases, training takes longer and the final model becomes more robust to relearning. Surprisingly, the relationship seems approximately linear. In plots (b) and (d), increasing α increases robustness, slowing down the relearning speed during relearning attacks. In other words, UNDO lets you trade off compute for robustness to relearning.
UNDO is better than other unlearning methods
What we ultimately want from a robust unlearning method is to push the Pareto frontier of initial retain performance vs. forget performance. The frontier must hold up against an adversary who is trying to maximize forget performance given a certain compute budget.
Column 2: Relearned forget performance after moderate relearning (40 steps).
Column 3: Performance after extensive relearning (500 steps).
In both settings, UNDO consistently dominates. Many of the methods get good initial retain-forget trade-offs, but rapidly degrade under adversarial pressure. In contrast, UNDO maintains more robust unlearning performance across all explored attacks and approaches the gold standard without requiring infeasible data labeling.
We also tested UNDO on the Weapons of Mass Destruction Proxy benchmark with Gemma-2-2B. UNDO consistently increased resilience to relearning, and it fell on the Pareto frontier of methods. However, we were more constrained on data and compute here compared to our synthetic arithmetic and language experiments, relative to what was used in pretraining. We struggled to recover performance in the distillation step. We expect that model developers will have enough resources to scale UNDO to these larger models.
Where this leaves us
Limitations
Our method depends on the quality of the initial unlearning.
Poor initial suppression leads to less robustness gains. Even if the unlearned model does not demonstrate the forget capability, it still may share the necessary information in its logits for the capability to be transferred to a student during distillation. For real-world cases, can we reliably achieve suppression strong enough for UNDO to succeed? We think so.
Poor suppression might lead to slower distillation. Perhaps inconsistent or noisy behaviors make the target logit function harder to predict.
We only tested against relearning attacks. The unlearning literature considers these finetuning attacks to be the strongest kind, but it’s possible that UNDO somehow is vulnerable to other elicitation approaches.
Insights and speculation
The oracle matching experiment shows that logits do not fully reflect a model’s capabilities. We demonstrate path-dependent inductive biases: for two models with nearly identical logit outputs, the models have different abilities to learn the forget set information.
Distillation is not just a compression tool.[1] Distillation also changes safety-relevant model properties – e.g., distillation makes unlearning robust. If you first unlearn and then distill into a randomly initialized student, the student keeps the desired behavior but loses the unwanted capability, even under relearning attacks. In a sense, distilling a suppressed model allows you to only train on “good” data.[2] UNDO decomposes “robust unlearning” into “choice of shallow-unlearning method” and “how distillation is performed.”
Therefore, developers can mix and match suppression methods. As suppression / shallow unlearning improves, so does UNDO!
We can trade off compute and robustness. Perturbing the model’s weights damages the trained model’s capabilities as a function of the size of the perturbation. In this way, we can modulate both the compute needed and the robustness gained.
Labs already distill production models, so Unlearn-and-Distill might be cheap and easy. Distillation typically happens before post-training, for several potential reasons. For example, by distilling first, labs can tweak post-training without re-distilling. It’s cheaper to post-train a smaller (distilled) model. There could also be optimizations that apply only when distilling the base pretrained model. The true cost of Unlearn-and-Distill or UNDO depends on how labs implement distillation.
A common concern is that sufficiently capable models might just rederive anything that was unlearned by using general reasoning ability, tools, or related knowledge. Several thoughts in response:
Future directions
Conclusion
UNDO is a viable approach for creating genuinely capability-limited models. While other methods merely suppress surface behaviors, our experiments indicate that UNDO prevents capabilities from being easily recovered. By folding unlearning into an already common practice, we hope that this line of work helps make real robust unlearning a reality.
The code and experimental framework are available on GitHub. This post also appears on turntrout.com.
Acknowledgments
We gratefully acknowledge:
Henrik Marklund for his insightful comments at various points of the project;
abstract;
Rishub Tamirisa for the guidance in navigating WMDP benchmarking procedures;
Citation
Other work has used distillation in contexts other than model compression, including improving performance, dataset privacy protection, and continual learning.
Distilling unlearned teacher logits isn’t always similar to just filtering out the forget data. In a TinyStories setting, we unlearned “ability to tell stories involving trees” from a small teacher model. Then we distilled its logits into a small student model. However, the student was vulnerable to relearning attacks, which wouldn’t have happened if we had performed data filtering.