
Language models seem to be much better than humans at next-token prediction
13Vanessa Kosoy
3Buck
11Fabien Roger
9Buck
6Matthew Barnett
6LawrenceC
2Matthew Barnett
6LawrenceC
1Matthew Barnett
4Rohin Shah
2Matthew Barnett
4Rohin Shah
2Matthew Barnett
3Rohin Shah
3Matthew Barnett
4Ben Pace, the Vacationing Vagabond
3Ben Pace, the Vacationing Vagabond
2Owain_Evans
1Ben Pace, the Vacationing Vagabond
1Adam Jermyn
1SoerenMind
1SoerenMind
[Thanks to a variety of people for comments and assistance (especially Paul Christiano, Nostalgebraist, and Rafe Kennedy), and to various people for playing the game. Buck wrote the top-1 prediction web app; Fabien wrote the code for the perplexity experiment and did most of the analysis and wrote up the math here, Lawrence did the research on previous measurements. Epistemic status: we're pretty confident of our work here, but haven't engaged in a super thorough review process of all of it--this was more like a side-project than a core research project.]
How good are modern language models compared to humans, at the task language models are trained on (next token prediction on internet text)? While there are language-based tasks that you can construct where humans can make a next-token prediction better than any language model, we aren't aware of any apples-to-apples comparisons on non-handcrafted datasets. To answer this question, we performed a few experiments comparing humans to language models on next-token prediction on OpenWebText.
Contrary to some previous claims, we found that humans seem to be consistently worse at next-token prediction (in terms of both top-1 accuracy and perplexity) than even small models like Fairseq-125M, a 12-layer transformer roughly the size and quality of GPT-1. That is, even small language models are "superhuman" at predicting the next token. That being said, it seems plausible that humans can consistently beat the smaller 2017-era models (though not modern models) with a few hours more practice and strategizing. We conclude by discussing some of our takeaways from this result.
We're not claiming that this result is completely novel or surprising. For example, FactorialCode makes a similar claim as an answer on this LessWrong post about this question. We've also heard from some NLP people that the superiority of LMs to humans for next-token prediction is widely acknowledged in NLP. However, we've seen incorrect claims to the contrary on the internet, and as far as we know there hasn't been a proper apples-to-apples comparison, so we believe there's some value to our results.
If you want to play with our website, it’s here; in our opinion playing this game for half an hour gives you some useful perspective on what it’s like to be a language model.
Previous claims and related work
One commonly cited source for human vs LM next-token prediction performance is this slide from Steve Omohundro’s GPT-3 presentation, where he claims that humans have perplexity ~12, compared to GPT-3’s 20.5. (Smaller perplexity means you're better at predicting.)
This comparison is problematic for two reasons, one small and one fatal. The smaller problem is that the language model statistics are word-level perplexities computed on Penn Tree Bank (PTB), while the Human perplexity is from Shen et al 2017, which estimated the word-level perplexity on the 1 Billion Words (IBW) benchmark. This turns out not to matter much, as while GPT-3 was not evaluated on 1BW, GPT-2 performs slightly worse on 1BW than PTB. The bigger issue is the methodology used to estimate human perplexity: Shen et al asked humans to rate sentences on a 0-3 scale, where 0 means “clearly inhuman” and “3” was clearly human, then computed a “human judgment score” consisting of the ratio of sentences rated 3 over those rated 0. They then fit a degree-3 polynomial regression to the LMs they had (of which the best was a small LSTM), which they extrapolated significantly out of distribution to acquire the “human” perplexity:
This methodology is pretty dubious for several reasons, and we wouldn’t put much stock into the “humans have 12 perplexity” claim.
Another claim is from OpenAI regarding the LAMBADA dataset, where they give a perplexity of “~1-2” for humans (compared to 3.0 for 0-shot GPT-3). However, the authors don’t cite a source. As Gwern notes, the authors of the blog post likely made an educated guess based on how the LAMBADA dataset was constructed. In addition, LAMBADA is a much restricted dataset, which consists of guessing single words requiring broad context. So this comparison isn’t very informative to the question of how good language models are at the task they’re trained on–predicting the next token on typical internet text.
The only study we know of which tried to do something closely analogous is Goldstein 2020 (a neuroscience paper), which found that an ensemble of 50 humans have a top-1 accuracy of 28% vs 36% for GPT-2, which is similar to what we saw for humans on webtext. However, they used a different dataset (this transcript), which is not particularly representative of randomly-sampled English internet text.
There’s certainly a lot of more narrow datasets on which we have both human and LM performance, where humans significantly outperform LMs. For example, Hendrycks et al’s MATH dataset. But we couldn’t find an apples-to-apples comparison between humans and modern LMs for webtext next-token prediction.
How to measure human performance at next-token prediction?
The main difficulty for comparing human vs LM performance is that, unlike with language models, it’s infeasible for humans to give their entire probability distribution for the next token in a sequence (as there are about fifty thousand tokens). We tried two approaches to get around this.
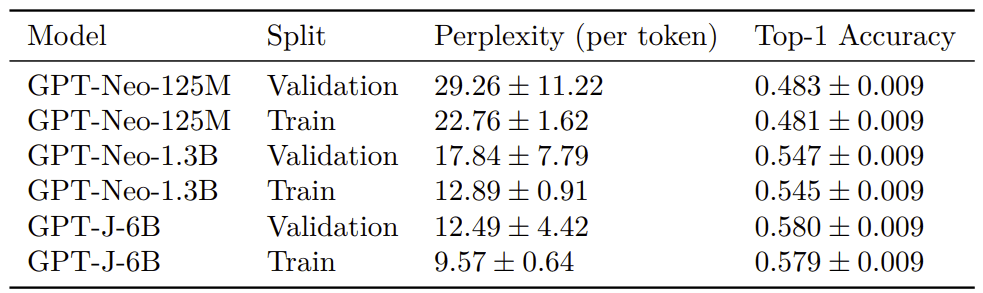
The first one is to ask humans what token is most likely to come next. Using this method, you can’t get humans’ perplexity, but top-1 accuracy might still give us a reasonable measure of how well humans do at next token prediction. According to this measure, humans are worse than all (non-toy) language models we tried, even if you use really smart humans who have practiced for more than an hour.
We tried a different approach to get a measurement of human perplexity: humans were asked to rate the relative probability of two different tokens. If many humans answer this question on the same prompt, you can estimate the probability of the correct token according to humans, and thus estimate human perplexity. As with the top-1 accuracy metric, humans score worse according to this perplexity estimator than all language models we tried, even a toy 2-layer model.
Top-1 accuracy evaluation
Method
We measured human top-1 accuracy: that is, they had to guess the single token that they thought was most likely to come next, and we measured how often that token in fact came next. Humans were given the start of a random OpenWebText document, and they were asked to guess which token comes next. Once they had guessed, the true answer was revealed (to give them the opportunity to get better at the game), and they were again asked to guess which token followed the revealed one.
Here is the website where participants played the game. We recommend playing the game if you want to get a sense of what next-token prediction is like.
The participants were either staff/advisors of Redwood Research, or members of the Bountied Rationality Facebook group, paid $30/hour.
Results
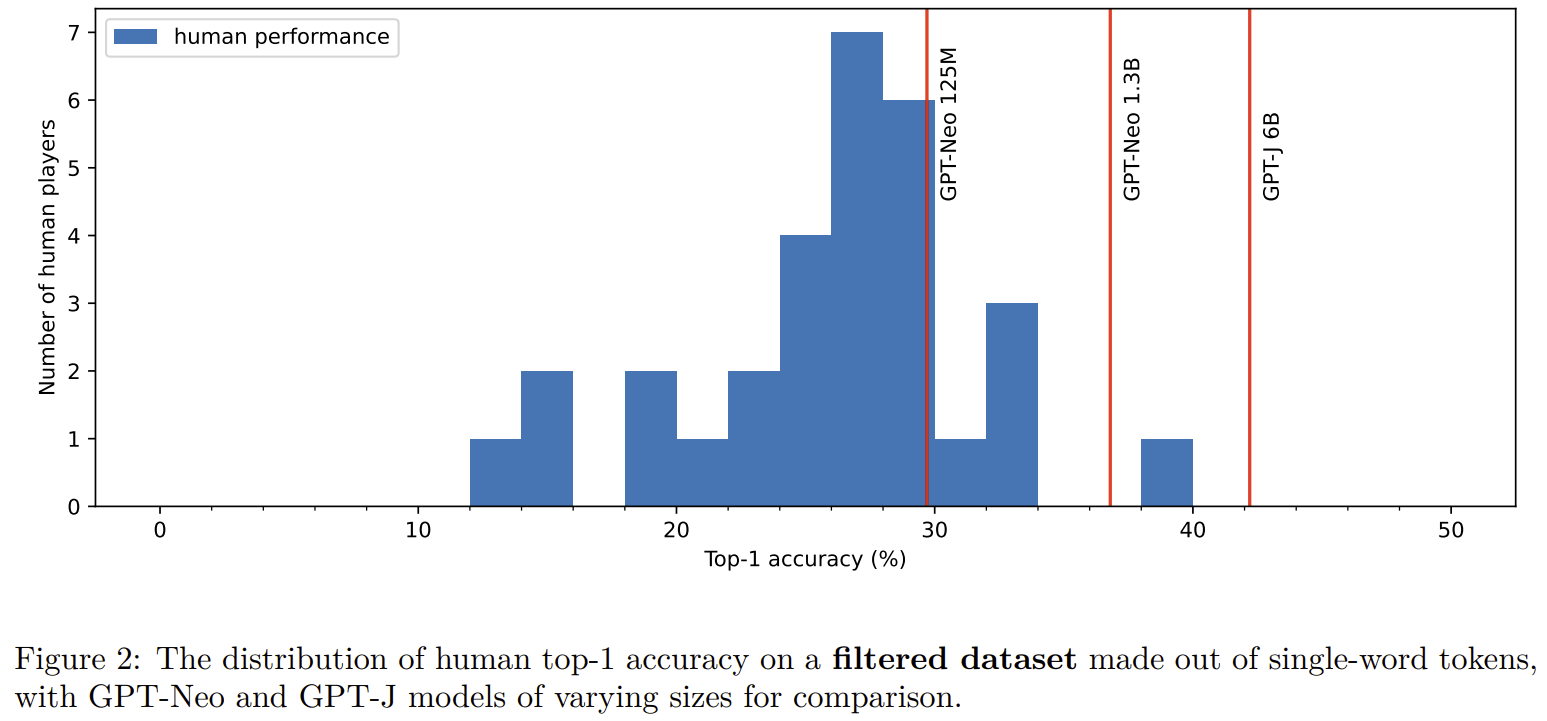
60 participants played the game, making a total of 18530 guesses. The overall accuracy of their answers on this top-1 task was 29%. Of these players, 38 gave at least 50 answers, with an accuracy of 30%. This accuracy is low compared to the accuracy of large language models: when measured on the same dataset humans were evaluated on, GPT-3 got an accuracy of 49% and even the 125M parameters fairseq model got an accuracy above the accuracy of all but one player in our dataset (who guessed 70 tokens), as you can see in the graph below (though it seems possible that with practice humans might be able to beat fairseq-125M reliably).
7 players guessed over 500 tokens, getting accuracies around the average of human performance (0.26, 0.26, 0.27, 0.28, 0.31, 0.31, 0.32), which indicates that humans don’t quickly get much higher performance with five hours of training.
Some of these scores are from Redwood Research staff and advisors who we think were very motivated to try hard and do well, so we don’t think that this is an artifact of our participants being weak.
Some participants wrote up notes on the experience, describing their strategies and what was easy/hard. Links: William Kiely, Marcus.
This website didn’t have any way for humans to guess newlines or some other visually-empty tokens, and we excluded cases where the correct guess was impossible from the above analysis.
To sum up, humans have only barely beat 2017-era language models, and humans are much worse than modern ones at top-1 token prediction.
Human perplexity evaluation
(Thanks to Paul Christiano for suggesting the rough approach here, and to Paul and Adam Scherlis for helping with some of the details.)
But language models aren’t trained to guess the single most likely next token, and so the previous task isn’t actually directly assessing the language models on the task they’re trained on. They’re trained to give a full distribution over next tokens, aiming to minimize their perplexity (aka minimizing log loss; perplexity is a measure of how well a probability distribution predicts a sample). It’s easy to calculate the model’s perplexity, because the models produce a probability for every next token. Unfortunately, humans aren’t able to quickly provide a probability distribution over the fifty thousand possible tokens. So if we want to measure human perplexity, we’ll have to do it indirectly.
Method
The method we ended up using is complicated and messy, and though it’s a fun exercise in probability theory, it is probably not worth your time to understand if you just want to know about human performance on language modeling.
For a given prompt sampled from the validation dataset of OpenWebText, we make the dubious assumption that all humans have exactly the same probability distribution over next tokens, and then infer the probability that humans assign to the correct token by showing many humans different choices between the correct next token and another random token, and then asking them for the probability that the left one is the correct token.
We used importance sampling and comparison with a reference language model to reduce the variance of the estimator (details in Appendix A). This importance sampling scheme allows the human to update on the probability that a token is the true next token based on the fact that they’re being asked about it. So we came up with a scoring rule, detailed in Appendix B and explained on the website, which incentivizes people to state their true probabilities before updating on which tokens they’d been asked to compare.
Here is the website where participants played the game.
The participants were again either staff of Redwood Research or members of the Bountied Rationality Facebook group paid $15 for answering a set of comparisons (which takes ~30 minutes, taking into account a bit of training). The first set consists of 40 questions from different texts (you can take it here). The second set consists of 80 comparisons from 8 different texts (you can take it here).
Note: prompts are chosen to be at most 120 tokens long in order to spare human reading time, and always start at the beginning of the text. Models are evaluated on the same dataset.
Results
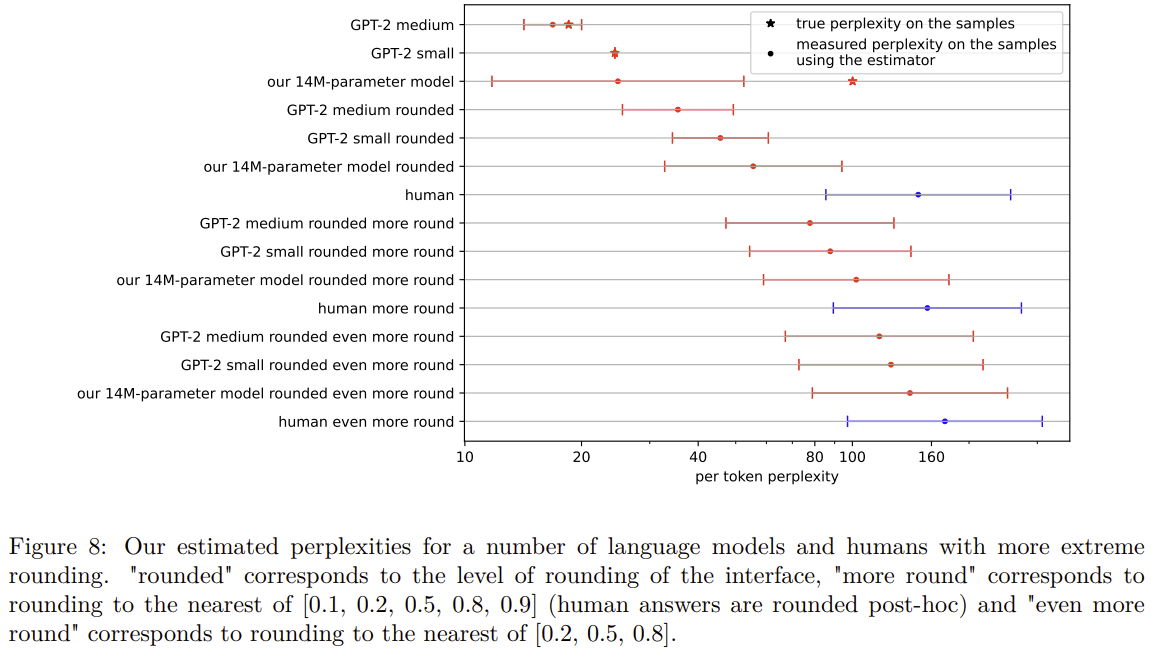
19 participants answered all 40 questions of the first set, and 11 participants answered all 80 questions of the second set, answering a total of 1640 comparisons. This was enough to conclude that human are worse than language models, as you can see in the graph below:
Human and language model performance are then compared exactly on the same comparison. As our human participants could only enter one of the 11 ratios in our interface, we also report the “rounded” performance of our LMs - that is, the performance of our LMs if they choose the checkbox that is the closest to their probability ratio. (Note that we can’t access the true perplexity of rounded models as only ratios are rounded and not the probability of the correct token.)
As explained in Appendix A, the loss obtained by this method is usually an underestimation of the true loss you would get if you asked infinitely many questions, because the sum used to do the estimations is heavily tailed. The displayed (2 standard error) uncertainty intervals represents “where would the estimation be if we did the experiment a second time with different samples”, rather than “where is the true value of human loss” (which would probably be above the upper bound of the interval). GPT-2 small is used as the generator, which is why its measured perplexity using the estimator is perfect. More details about the uncertainty estimation can be found in Appendix C.
But this method could also overestimate human perplexity: there could be other setups in which it would be easier for players to give calibrated probabilities. In fact, some players found the scoring system hard to understand, and if it led them to not express their true probability ratios, we might have underestimated human performance. In general, this method is very sensitive to failures at giving calibrated probability estimates: the high perplexity obtained here is probably partially due to humans being bad at giving calibrated probabilities, rather than humans just being bad at language modeling. In addition, as humans are restricted to one of 11 ratios, our setup could also underestimate performance by artificially reducing the resolution of our human participants.
Thus, while we don’t have a good way to precisely measure human perplexity, these results give reasonable evidence that it is high. In particular, humans are worse than a two-layer model at giving calibrated estimates of token vs token probabilities.
It's worth noting that our results are not consistent with the classic result from Shannon 1950, which estimated the the average per-character entropy to be between 0.6 and 1.3 bits, corresponding to a per-token perplexity between 7 and 60 (as the average length of tokens in our corpus is 4.5). This is likely due to several reasons. First, as noted above, our setup may artificially increase the estimated perplexity due to our human subjects being uncalibrated and our interface rounding off probability ratios. In addition, Shannon used his wife Mary Shannon and the HP Founder Barnard Oliver as his subjects, who may be higher quality than our subjects or have spent more time practicing on the task. [EDIT: as Matthew Barnett notes in a comment below, our estimate of human perplexity is consistent with other estimates performed after Shannon.] Finally, he used a different dataset (excerpts from Dumas Malne's Jefferson the Virginian, compared to our OpenWebText excerpts).
Conclusion
The results here suggest that humans are worse than even small language models the size of GPT-1 at next-token prediction, even on the top-1 prediction task. This seems true even when the humans are smart and motivated and have practiced for an hour or two. Some humans can probably consistently beat GPT-1, but not substantially larger models, with a bit more practice.
What should we take away from this?
Appendix A: How to estimate human loss with importance sampling
Let T be the true distribution of tokens y after a context c. The loss of a human is defined to be the average -log probability of the true token according to the human probabilities h over the next token: L=−E(C,Y)∼Tlogh(Y|C)
However, we can’t directly ask a human what the probability of the true token is (without spoiling them on the answer), and it would be very cumbersome to ask for their whole probability distribution. We can do better by asking for relative likelihoods: for a given context c and true token y, because ∑xp(x|c)=1, −logh(y|c)=log∑xh(x/c)/h(y|c).
That’s better, but that would still be around 50,000 questions (the number of tokens) per token. To lower this number, we use importance sampling: the bulk of ∑h(x/c)/h(y|c) is where the most likely tokens are, so it’s not worth asking for every one of them. To do that, we condition a language model G on our context C from which we can sample the most likely tokens, and we use the following approximation:
∑all tokensxh(x/c)/h(y|c)=EX∼Gc(h(X|c)h(y|c)g(X|c)) ≈1n∑x∼Gch(x|c)h(y|c)g(x|c) for an that can be much smaller than 50,000. for an n that can be much smaller than 50,000.
To decrease the variance of this estimator (and thereby increase the quality of the estimation), instead of estimating h(y|c) we estimate h(y|c)g(y|c)=EX∼Gc(h(X|c)g(y|c)h(y|c)g(X|c)) ≈1n∑x∼Gch(x|c)g(y|c)h(y|c)g(x|c). The variance is lower because, if h and g are close, h(x|c)g(y|c)h(y|c)g(x|c) will most of the time be close to 1, whereas h(x|c)h(y|c)g(x|c) can get very large on some samples.
Thanks to the properties of log, L−LG=−E(C,Y)∼Tlogh(Y|C)g(Y|C) (where LG is the loss of G, defined in the same way as L but using g instead of h).
Using N samples from the true target corpus, we get
L−LG≈1N∑(c,y)∼Tlog(1n∑x∼Gch(x|c)g(y|c)h(y|c)g(x|c))
In practice, we use GPT-2 small - a 12-layer language model - as our generator language model.
Using this method to measure the loss of a 2-layer LM and a 24-layer LM using a 12-layer LM as a generator, we find that this method underestimates of the true loss of the ground truth, and that the results is at most 0.5 bits away from the ground truth when n≈40, for models that are very dissimilar (like 2-layer model vs 12-layer LM, which the difference in true loss is 1.3 bits). This is a large difference, but this is still good enough for the purpose of comparing humans to language models (because humans are terrible language models). The difference can be explained by the fact that the sum over x is heavy tailed toward +∞: if you don’t sample enough, your empirical mean will often be below the true expected value.
Appendix B: How to get human relative likelihoods
We want to get h(x|c)/h(y|c), the relative likelihood of tokens x and y in a given context C according to a human. This might seem easy: just make the human guess if the prompt c is followed by x or y, and then the human should answer that c is followed by x with probability h(x|c)h(y|c)+h(y|c). This would be true if one token was sampled from the true distribution and the other one was selected uniformly between all other tokens. However, this doesn’t work if in this case because the other token is sampled from Gc: a rational agent that perfectly knows the true distribution T and the generated distribution G would answer that c is followed by x with probability
P(x∼Tc∧y∼Gc)P(x∼Tc∧y∼Gc)+P(x∼Gc∧y∼Tc)
=t(x|c)g(y|c)t(y|c)g(x|c)+t(x|c)g(y|c) (because of the independence of Tc & Gc).
Thus, if you believe Tc to get indistinguishable from Gc, a human will answer “0.5” to every question, making it impossible to extract h(x|c)/h(y|c).
The solution to get h(x|c)/h(y|c) is to incentivize the human to give something else than their best guess. We ask the human for the probability p that c is followed by x, and we reward them with a weighted binary cross entropy reward R(p)=g(x|c)log(p)1z=x+g(y|c)log(1−p)1z=y where z is the correct answer. The expected value of this reward, according to a human believing that the generative follows a distribution ^G, is E(R(p))=^g(x|c)log(p)(h(x|c)^g(y|c))+^g(y|c)log(1−p)(h(y|c)^g(x|c)) which is at its maximum when dE(R(p))dp=0, therefore, the optimal play satisfies ^g(x|c)^g(y|c)h(x|c)/p∗=^g(y|c)^g(x|c)h(y|c)/(1−p∗), hence p∗=h(x|c)h(y|c)+h(x|c). From this, we get h(y|c)/h(x|c)=1p∗−1. Assuming human play optimally (which is a questionable assumption), we are able to get their true probability ratios, no matter what their beliefs about the generative model are.
Note: in practice we use a slightly different reward R(p)=1000(g(x|c)(log(p)−log(0.5))1z=x+g(y|c)(log(1−p)−log(0.5))1z=y for which the optimal play is the same, but which is more understandable for human: one always gets a reward of 0 for saying “I don’t know”, and the scaling makes things more readable.
Note 2: when x=y the human isn't asked to compare their relative likelyhoods. Instead, the website automatically answers that both are as likely.
Appendix C: estimating uncertainties in human perplexity
If we assume humans play rationally in the game described above, there remains three sources of uncertainty in our measurement of human perplexity:
Uncertainties 1 & 3 are hard to combine, and because 3 is small compared to 1, we chose to use only the first one.
Here is the same graph as shown in the result section, but using only the uncertainties measured using technique 3.