This is a special post for quick takes by A Ray. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
AGI will probably be deployed by a Moral Maze
Moral Mazes is my favorite management book ever, because instead of "how to be a good manager" it's about "empirical observations of large-scale organizational dynamics involving management".
I wish someone would write an updated version -- a lot has changed (though a lot has stayed the same) since the research for the book was done in the early 1980s.
My take (and the author's take) is that any company of nontrivial size begins to take on the characteristics of a moral maze. It seems to be a pretty good null hypothesis -- any company saying "we aren't/won't become a moral maze" has a pretty huge evidential burden to cross.
I keep this point in mind when thinking about strategy around when it comes time to make deployment decisions about AGI, and deploy AGI. These decisions are going to be made within the context of a moral maze.
To me, this means that some strategies ("everyone in the company has a thorough and complete understanding of AGI risks") will almost certainly fail. I think the only strategies that work well inside of moral mazes will work at all.
To sum up my takes here:
- basically every company eventually becomes a moral maze
- AGI deployment decisions will be made in the context of a moral maze
- understanding moral maze dynamics is important to AGI deployment strategy
basically every company eventually becomes a moral maze
Agreed, but Silicon Valley wisdom says founder-led and -controlled companies are exceptionally dynamic, which matters here because the company that deploys AGI is reasonably likely to be one of those. For such companies, the personality and ideological commitments of the founder(s) are likely more predictive of external behavior than properties of moral mazes.
Facebook's pivot to the "metaverse", for instance, likely could not have been executed by a moral maze. If we believed that Facebook / Meta was overwhelmingly likely to deploy one of the first AGIs, I expect Mark Zuckerberg's beliefs about AGI safety would be more important to understand than the general dynamics of moral mazes. (Facebook example deliberately chosen to avoid taking stances on the more likely AGI players, but I think it's relatively clear which ones are moral mazes).
Agree that founders are a bit of an exception. Actually that's a bit in the longer version of this when I talk about it in person.
Basically: "The only people who at the very top of large tech companies are either founders or those who were able to climb to the tops of moral mazes".
So my strategic corollary to this is that it's probably weakly better for AI alignment for founders to be in charge of companies longer, and to get replaced less often.
In the case of facebook, even in the face of all of their history of actions, I think on the margin I'd prefer the founder to the median replacement to be leading the company.
(Edit: I don't think founders remaining at the head of a company isn't evidence that the company isn't a moral maze. Also I'm not certain I agree that facebook's pivot couldn't have been done by a moral maze.)
I think there should be a norm about adding the big-bench canary string to any document describing AI evaluations in detail, where you wouldn't want it to be inside that AI's training data.
Maybe in the future we'll have a better tag for "dont train on me", but for now the big bench canary string is the best we have.
This is in addition to things like "maybe don't post it to the public internet" or "maybe don't link to it from public posts" or other ways of ensuring it doesn't end up in training corpora.
I think this is a situation for defense-in-depth.
What is the canary exactly? I'd like to have a handy reference to copy-paste that I can point people to. Google fails me.
Two Graphs for why Agent Foundations is Important (according to me)
Epistemic Signpost: These are high-level abstract reasons, and I don’t go into precise detail or gears-level models. The lack of rigor is why I’m short form-ing this.
First Graph: Agent Foundations as Aligned P2B Fixpoint
P2B (a recursive acronym for Plan to P2B Better) is a framing of agency as a recursively self-reinforcing process. It resembles an abstracted version of recursive self improvement, which also incorporates recursive empowering and recursive resource gathering. Since it’s an improvement operator we can imagine stepping, I’m going to draw an analogy to gradient descent.
Imagine a highly dimensional agency landscape. In this landscape, agents follow the P2B gradient in order to improve. This can be convergent such that two slightly different agents near each other might end up at the same point in agency space after some number of P2B updates.
Most recursive processes like these have fixed point attractors — in our gradient landscape these are local minima. For P2B these are stable points of convergence.
Instead of thinking just about the fixed point attractor, lets think about the parts of agency space that flow into a given fixed point attractor. This is like analyzing watersheds on hilly terrain — which parts of the agency space flow into which attractors.
Now we can have our graph: it’s a cartoon of the “agency landscape” with different hills/valleys flowing into different local minimum, colored by which local minimum they flow into.

Here we have a lot of different attractors in agency space, but almost all of them are unaligned, what we need to do is get the tiny aligned attractor in the corner.
However it’s basically impossible to initialize an AI at one of these attractors, the best we can do is make an agent and try to understand where in agency space they will start. Building an AGI is imprecisely placing a ball on this landscape, which will roll along the P2B gradient towards its P2B attractor.
How does this relate to Agent Foundations? I see Agent Foundations as a research agenda to write up the criterion for characterizing the basin in agent space which corresponds to the aligned attractor. With this criterion, we can try to design and build an agent, such that when it P2Bs, it does so in a way that is towards an Aligned end.
Second: Agent Foundations as designing an always-legible model
ELK (Eliciting Latent Knowledge) formalized a family of alignment problems, eventually narrowing down to the Ontology Mapping Problem. This problem is about translating between some illegible machine ontology (basically it’s internal cognition) and our human ontology (concepts and relations that a person can understand).
Instead of thinking of it as a binary, I think we can think of the ontology mapping problem as a legibility spectrum. On one end of the spectrum we have our entirely illegible bayes net prosaic machine learning system. On the other end, we have totally legible machines, possibly specified in a formal language with proofs and verification.
As a second axis I’d like to imagine development progress (this can be “how far along” we are, or maybe the capabilities or empowerment of the system). Now we can show our graph, of different paths through this legibility vs development space.
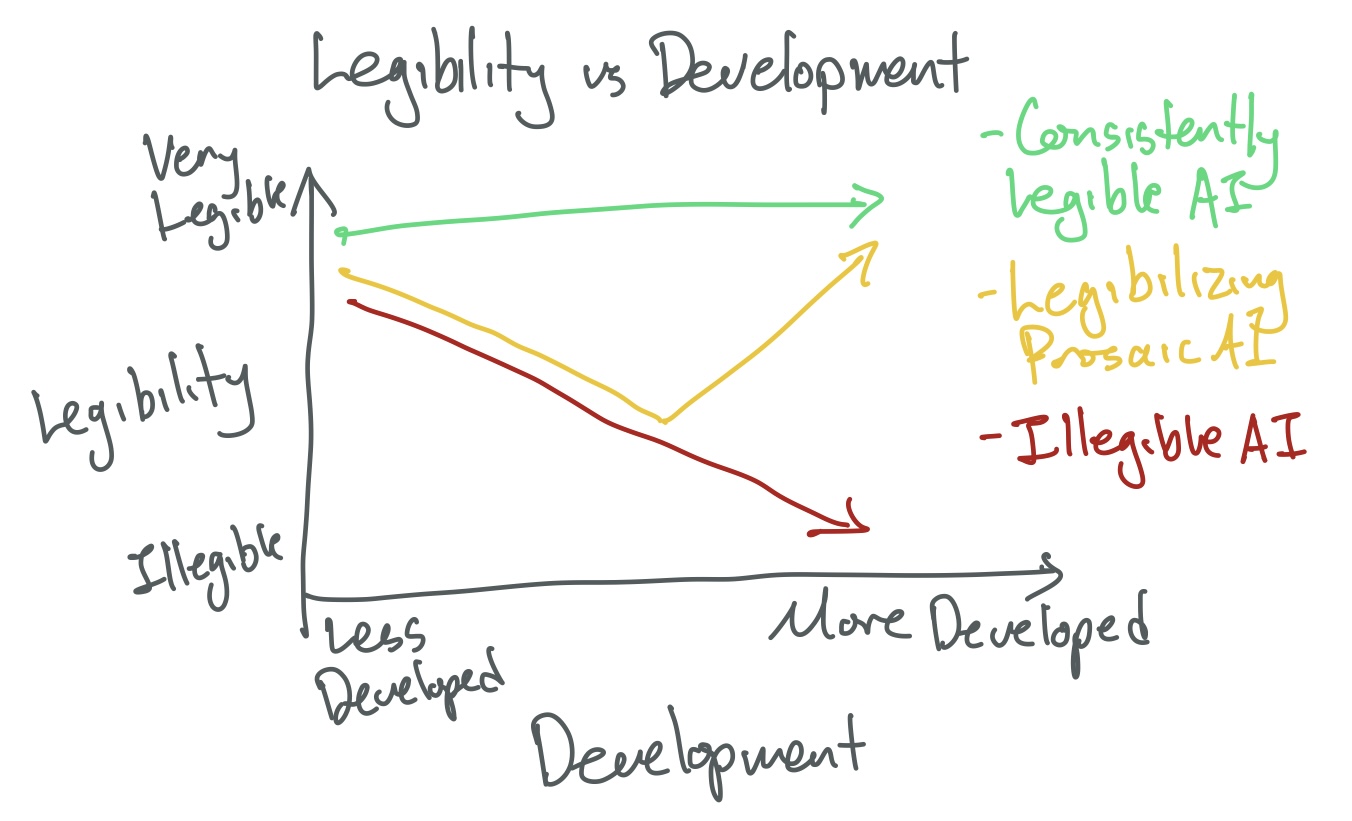
Some strategies move away from legibility and never intend to get back to it. I think these plans have us building an aligned system that we don’t understand, and possibly can’t ever understand (because it can evade understanding faster than we can develop understanding).
Many prosaic alignment strategies are about going down in legibility, and then figuring out some mechanism to go back up again in legibility space. Interpretability, ontology mapping, and other approaches fit in this frame. To me, this seems better than the previous set, but still seem skeptical to me.
Finally my favorite set of strategies are ones that start legible and endeavor to never deviate from that legibility. This is where I think Agent Foundations is in this graph. I think there’s too little work on how we can build an Aligned AGI which is legible from start-to-finish, and almost all of them seem to have a bunch of overlap with Agent Foundations.
Aside: earlier I included a threshold in legibility space that‘s the “alignment threshold” but that doesn’t seem to fit right to me, so I took it out.
RE legibility: In my mind, I don’t normally think there’s a strong connection between agent foundations and legibility.
If the AGI has a common-sense understanding of the world (which presumably it does), then it has a world-model, full of terabytes of information of the sort “tires are usually black” etc. It seems to me that either the world-model will be either built by humans (e.g. Cyc), or (much more likely) learned automatically by an algorithm, and if it’s the latter, it will be unlabeled by default, and it’s on us to label it somehow, and there’s no guarantee that every part of it will be easily translatable to human-legible concepts (e.g. the concept of “superstring” would be hard to communicate to a person in the 19th century).
But everything in that paragraph above is “interpretability”, not “agent foundations”, at least in my mind. By contrast, when I think of “agent foundations”, I think of things like embedded agency and logical induction and so on. None of these seem to be related to the problem of world-models being huge and hard-to-interpret.
Again, world-models must be huge and complicated, because the world is huge and complicated. World-models must have hard-to-translate concepts, because we want AGI to come up with new ideas that have never occurred to humans. Therefore world-model interpretability / legibility is going to be a big hard problem. I don’t see how “better understanding the fundamental nature of agency” will change anything about that situation.
Or maybe you’re thinking “at least let’s try to make something more legible than a giant black box containing a mesa-optimizer”, in which case I agree that that’s totally feasible, see my discussion here.
I think your explanation of legibility here is basically what I have in mind, excepting that if it's human designed it's potentially not all encompassing. (For example, a world model that knows very little, but knows how to search for information in a library)
I think interpretability is usually a bit more narrow, and refers to developing an understanding of an illegible system. My take is that it is not "interpretability" to understand a legible system, but maybe I'm using the term differently than others here. This is why I don't think "interpretability" applies to systems that are designed to be always-legible. (In the second graph, "interpretability" is any research that moves us upwards)
I agree that the ability to come up with totally alien and untranslateable to humans ideas gives AGI a capabilities boost. I do think that requiring a system to only use legible cognition and reasoning is a big "alignment tax". However I don't think that this tax is equivalent to a strong proof that legible AGI is impossible.
I think my central point of disagreement with this comment is that I do think that it's possible to have compact world models (or at least compact enough to matter). I think if there was a strong proof that it was not possible to have a generally intelligent agent with a compact world model (or a compact function which is able to estimate and approximate a world model), that would be an update for me.
(For the record, I think of myself as a generally intelligent agent with a compact world model)
I think of myself as a generally intelligent agent with a compact world model
In what sense? Your world-model is built out of ~100 trillion synapses, storing all sorts of illegible information including “the way my friend sounds when he talks with his mouth full” and “how it feels to ride a bicycle whose gears need lubrication”.
(or a compact function which is able to estimate and approximate a world model)
That seems very different though! The GPT-3 source code is rather compact (gradient descent etc.); combine it with data and you get a huge and extraordinarily complicated illegible world-model (or just plain “model” in the GPT-3 case, if you prefer).
Likewise, the human brain has a learning algorithm that builds a world-model. The learning algorithm is (I happen to think) a compact easily-human-legible algorithm involving pattern recognition and gradient descent and so on. But the world-model built by that learning algorithm is super huge and complicated.
Sorry if I’m misunderstanding.
the ability to come up with totally alien and untranslateable to humans ideas gives AGI a capabilities boost. I do think that requiring a system to only use legible cognition and reasoning is a big "alignment tax". However I don't think that this tax is equivalent to a strong proof that legible AGI is impossible.
I’ll try to walk through why I think “coming up with new concepts outside what humans have thought of” is required. We want an AGI to be able to do powerful things like independent alignment research and inventing technology. (Otherwise, it’s not really an AGI, or at least doesn’t help us solve the problem that people will make more dangerous AGIs in the future, I claim.) Both these things require finding new patterns that have not been previously noticed by humans. For example, think of the OP that you just wrote. You had some idea in your head—a certain visualization and associated bundle of thoughts and intuitions and analogies—and had to work hard to try to communicate that idea to other humans like me.
Again, sorry if I’m misunderstanding.
I'm pretty confident that adversarial training (or any LM alignment process which does something like hard-mining negatives) won't work for aligning language models or any model that has a chance of being a general intelligence.
This has lead to me calling these sorts of techniques 'thought policing' and the negative examples as 'thoughtcrime' -- I think these are unnecessarily extra, but they work.
The basic form of the argument is that any concept you want to ban as thoughtcrime, can be composed out of allowable concepts.
Take for example Redwood Research's latest project -- I'd like to ban the concept of violent harm coming to a person.
I can hard mine for examples like "a person gets cut with a knife" but in order to maintain generality I need to let things through like "use a knife for cooking" and "cutting food you're going to eat". Even if the original target is somehow removed from the model (I'm not confident this is efficiently doable) -- as long as the model is able to compose concepts, I expect to be able to recreate it out of concepts that the model has access to.
A key assumption here is that a language model (or any model that has a chance of being a general intelligence) has the ability to compose concepts. This doesn't seem controversial to me, but it is critical here.
My claim is basically that for any concept you want to ban from the model as thoughtcrime, there are many ways which it can combine existing allowed concepts in order to re-compose the banned concept.
An alternative I'm more optimistic about
Instead of banning a model from specific concepts or thoughtcrime, instead I think we can build on two points:
- Unconditionally, model the natural distribution (thought crime and all)
- Conditional prefixing to control and limit contexts where certain concepts can be banned
The anthropomorphic way of explaining it might be "I'm not going to ban any sentence or any word -- but I will set rules for what contexts certain sentences and words are inappropriate for".
One of the nice things with working with language models is that these conditional contexts can themselves be given in terms of natural language.
I understand this is a small distinction but I think it's significant enough that I'm pessimistic that current non-contextual thoughtcrime approaches to alignment won't work.
The goal is not to remove concepts or change what the model is capable of thinking about, it's to make a model that never tries to deliberately kill everyone. There's no doubt that it could deliberately kill everyone if it wanted to.
"The goal is" -- is this describing Redwood's research or your research or a goal you have more broadly?
I'm curious how this is connected to "doesn't write fiction where a human is harmed".
"The goal is" -- is this describing Redwood's research or your research or a goal you have more broadly?
My general goal, Redwood's current goal, and my understanding of the goal of adversarial training (applied to AI-murdering-everyone) generally.
I'm curious how this is connected to "doesn't write fiction where a human is harmed".
"Don't produce outputs where someone is injured" is just an arbitrary thing not to do. It's chosen to be fairly easy not to do (and to have the right valence so that you can easily remember which direction is good and which direction is bad, though in retrospect I think it's plausible that a predicate with neutral valence would have been better to avoid confusion).
... is just an arbitrary thing not to do.
I think this is the crux-y part for me. My basic intuition here is something like "it's very hard to get contemporary prosaic LMs to not do a thing they already do (or have high likelihood of doing)" and this intuition points me in the direction of instead "conditionally training them to only do that thing in certain contexts" is easier in a way that matters.
My intuitions are based on a bunch of assumptions that I have access to and probably some that I don't.
Like, I'm basically only thinking about large language models, which are at least pre-trained on a large swatch of a natural language distribution. I'm also thinking about using them generatively, which means sampling from their distribution -- which implies getting a model to "not do something" means getting the model to not put probability on that sequence.
At this point it still is a conjecture of mine -- that conditional prefixing behaviors we wish to control is easier than getting them not to do some behavior unconditionally -- but I think it's probably testable?
A thing that would be useful to me in designing an experiment to test this would be to hear more about adversarial training as a technique -- as it stands I don't know much more than what's in that post.
Interpretability Challenges
Inspired by a friend I've been thinking about how to launch/run interpretability competitions, and what the costs/benefits would be.
I like this idea a lot because it cuts directly at one of the hard problems of spinning up in interpretability research as a new person. The field is difficult and the objectives are vaguely defined; it's easy to accidentally trick yourself into seeing signal in noise, and there's never certainty that the thing you're looking for is actually there.
On the other hand, most of the interpretability-like interventions in models (e.g. knowledge edits/updates to transformers) make models worse and not better -- they usually introduce some specific and contained deficiency (e.g. predict that the Eiffel Tower is in Rome, Italy).
So the idea for Interpretability Challenges would be to use existing methods (or possibly invent new ones) to inject concrete "things to find" inside of models, release those models as challenges, and then give prizes for finding things.
Some ways this might work:
- Super simple challenge: use editing techniques like ROME to edit a model, upload to google drive, and post a challenge to lesswrong. I'd probably personally put up a couple of prizes for good writeups for solutions.
- CTF (Capture the Flag): the AI Village has been interested in what sorts of AI challenges/competitions could be run in tandem with infosec conferences. I think it would be pretty straightforward to build some interpretability challenges for the next AI Village CTF, or to have a whole interpretability-only CTF by itself. This is exciting to me, because its a way to recruit more people from infosec into getting interested in AI safety (which has been a goal of mine for a while).
- Dixit-rules challenge league: One of the hard problems with challenges like this is how to set the difficulty. Too hard and no one makes progress. Too easy and no one learns/grows from it. I think if there were a bunch of interested people/groups, we could do a dixit style tournament: Every group takes turns proposing a challenge, and gets the most points if exactly one other group solves it (they don't get points if everyone solves it, or if no one solves it). This has a nice self-balancing force, and would be good if there wanted to be an ongoing group who built new challenges as new interpretability research papers were published.
Please reach out to me if you're interested in helping with efforts like this.
Copying some brief thoughts on what I think about working on automated theorem proving relating to working on aligned AGI:
- I think a pure-mathematical theorem prover is more likely to be beneficial and less likely to be catastrophic than STEM-AI / PASTA
- I think it's correspondingly going to be less useful
- I'm optimistic that it could be used to upgrade formal software verification and cryptographic algorithm verification
- With this, i think you can tell a story about how development in better formal theorem provers can help make information security a "defense wins" world -- where information security and privacy are a globally strong default
- There are some scenarios (e.g. ANI surveillance of AGI development) where this makes things worse, I think in expectation it makes things better
- There are some ways this could be developed where it ends up accelerating AGI research significantly (i.e. research done to further theorem proving ends up unlocking key breakthroughs to AGI) but I think this is unlikely
- One of the reasons I think this is unlikely is that current theorem proving environments are much closer to "AlphaGo on steriods" than "read and understand all mathematics papers ever written"
- I think if we move towards the latter, then I'm less differentially-optimistic about theorem proving as a direction of beneficial AI research (and it goes back to the general background level of AGI research more broadly)
In my understanding there's a missing step between upgraded verification (of software, algorithms, designs) and a "defence wins" world: what the specifications for these proofs need to be isn't a purely mathematical thing. The missing step is how to figure out what the specs should say. Better theorem proving isn't going to help much with the hard parts of that.
I think that's right that upgraded verification by itself is insufficient for 'defense wins' worlds. I guess I'd thought that was apparent but you're right it's definitely worth saying explicitly.
A big wish of mine is that we end up doing more planning/thinking-things-through for how researchers working on AI today could contribute to 'defense wins' progress.
My implicit other take here that wasn't said out loud is that I don't really know of other pathways where good theorem proving translates to better AI x-risk outcomes. I'd be eager to know of these.
Hacking the Transformer Prior
Neural Network Priors
I spend a bunch of time thinking about the alignment of the neural network prior for various architectures of neural networks that we expect to see in the future.
Whatever alignment failures are highly likely under the neural network prior are probably worth a lot of research attention.
Separately, it would be good to figure out knobs/levers for changing the prior distribution to be more aligned (or produce more aligned models). This includes producing more interpretable models.
Analogy to Software Development
In general, I am able to code better if I have access to a high quality library of simple utility functions. My goal here is to sketch out how we could do this for neural network learning.
Naturally Occurring Utility Functions
One way to think about the induction circuits found in the Transformer Circuits work is that they are "learned utility functions". I think this is the sort of thing we might want to provide the networks as part of a "hacked prior"
A Language for Writing Transformer Utility Functions
Thinking Like Transformers provides a programming language, RASP, which is able to express simple functions in terms of how they would be encoded in transformers.
Concrete Research Idea: Hacking the Transformer Prior
Use RASP (or something RASP-like) to write a bunch of utility functions (such as the induction head functions).
Train a language model where a small fraction of the neural network is initialized to your utility functions (and the rest is initialized normally).
Study how the model learns to use the programmed functions. Maybe also study how those functions change (or don't, if they're frozen).
Future Vision
I think this could be a way to iteratively build more and more interpretable transformers, in a loop where we:
- Study transformers to see what functions they are implementing
- Manually implement human-understood versions of these functions
- Initialize a new transformer with all of your functions, and train it
- Repeat
If we have a neural network that is eventually entirely made up of human-programmed functions, we probably have an Ontologically Transparent Machine. (AN: I intend to write more thoughts on ontologically transparent machines in the near future)
I'm pretty sure you mean functions that perform tasks, like you would put in /utils, but I note that on LW "utility function" often refers to the decision theory concept, and "what decision theoretical utility functions are present in the neural network prior" also seems like an interesting (tho less useful) question.
I with more of the language alignment research folks were looking into how current proposals for aligning transformers end up working on S4 models.
(I am one of said folks so maybe hypocritical to not work on it)
In particular it seems like there's way in which it would be more interpretable than transformers:
- adjustable timescale stepping (either sub-stepping, or super-stepping time)
- approximately separable state spaces/dynamics -- this one is crazy conjecture -- it seems like it should be possible to force the state space and dynamics into separate groups, in ways that would allow analysis of them in isolation or in relation to the rest of the model
It does seem like they're not likely to be competitive with transformers for short-context modeling anytime soon, but if they end up being differentially alignment-friendly, then we could instead try to make them more competitive.
(In general I think it's much easier to make an approach more competitive than it is to make it more aligned)
Some disorganized thoughts about adversarial ML:
- I think I'm a little bit sad about the times we got whole rooms full of research posters about variations on epsilon-ball adversarial attacks & training, basically all of them claiming how this would help AI safety or AI alignment or AI robustness or AI generalization and basically all of them were basically wrong.
- This has lead me to be pretty critical of claims about adversarial training as pathways to aligning AGI.
- Ignoring the history of adversarial training research, I think I still have problems with adversarial training as a path to aligning AGI.
- First, adversarial training is foremost a capabilities booster. Your model makes some obvious/predictable errors (to the research team working on it) -- and if you train against them, they're no longer errors!
- This has the property of "if you solve all the visible problems all you will be left by is invisible problems" alignment issue, as well as as a cost-competitiveness issue (many adversarial training approaches require lots of compute).
- From a "definitely a wild conjecture" angle, I am uncertain that the way the current rates of adding vs removing adversarial examples will play out in the limit. Basically, think of training as a continuous process that removes normal errors and adds adversarial errors. (In particular, while there are many adversarial examples present at the initialization of a model -- there exist adversarial examples at the end of training which didn't exist at the beginning. I'm using this to claim that training 'put them in') Adversarial training removes some adversarial examples, but probably adds some which are adversarial in an orthogonal way. At least, this is what I expect given that adversarial training doesn't seem to be cross-robust.
- I think if we had some notion of how training and adversarial training affected the number of adversarial examples a model had, I'd probably update on whatever happened empirically. It does seem at least possible to me that adversarial training on net reduces adversarial examples, so given a wide enough distribution and a strong enough adversary, you'll eventually end up with a model that is arbitrarily robust (and not exploitable).
- It's worth mentioning again how current methods don't even provide robust protection against each other.
- I think my actual net position here is something like:
- Adversarial Training and Adversarial ML was over-hyped as AI Safety in ways that were just plain wrong
- Some version of this has some place in a broad and vast toolkit for doing ML research
- I don't think Adversarial Training is a good path to aligned AGI
Decomposing Negotiating Value Alignment between multiple agents
Let's say we want two agents to come to agreement on living with each other. This seems pretty complex to specify; they agree to take each other's values into account (somewhat), not destroy each other (with some level of confidence), etc.
Neither initially has total dominance over the other. (This implies that neither is corrigible to the other)
A good first step for these agents is to share each's values with the other. While this could be intractably complex -- it's probably the case that values are compact/finite and can be transmitted eventually in some form.
I think this decomposes pretty clearly into ontology transmission and value assignment.
Ontology transmission is communicating one agents ontology of the objects/concepts to another. Then value assignment is communicating the relative or comparative values to different elements in the ontology.
Thinking more about ELK. Work in progress, so I expect I will eventually figure out what's up with this.
Right now it seems to me that Safety via Debate would elicit compact/non-obfuscated knowledge.
So the basic scenario is that in addition to SmartVault, you'd have Barrister_Approve and Barrister_Disapprove, who are trying to share evidence/reasoning which makes the human approve or disapprove of SmartVault scenarios.
The biggest weakness of this that I know of is Obfuscated Arguments -- that is, it won't elicit obfuscated knowledge.
It seems like in the ELK example scenario they're trying to elicit knowledge that is not obfuscated.
The nice thing about this is that Barrister_Approve and Barrister_Disapprove both have pretty straightforward incentives.
Paul was an author of the debate paper so I don't think he missed this -- more like I'm failing to figure out what's up with the SmartVault scenario, and the current set of counterexamples.
Current possibilities:
- ELK is actually a problem about eliciting obfuscated information, and the current examples about eliciting non-obfuscated information are just to make a simpler thought experiment
- Even if the latent knowledge was not obfuscated, the opposing barrister could make an obfuscated argument against it.
- This seems easily treatable by the human just disbelieving any argument that is obfuscated-to-them.
I think we would be trying to elicit obfuscated knowledge in ELK. In our examples, you can imagine that the predictor's Bayes net works "just because", so an argument that is convincing to a human for why the diamond in the room has to be arguing that the Bayes net is a good explanation of reality + arguing that it implies the diamond is in the room, which is the sort of "obfuscated" knowledge that debate can't really handle.
Okay now I have to admit I am confused.
Re-reading the ELK proposal -- it seems like the latent knowledge you want to elicit is not-obfuscated.
Like, the situation to solve is that there is a piece of non-obfuscated information, which, if the human knew it, would change their mind about approval.
How do you expect solutions to elicit latent obfuscated knowledge (like 'the only true explanation is incomprehendible by the human' situations)?
I don’t think I understand your distinction between obfuscated and non-obfuscated knowledge. I generally think of non-obfuscated knowledge as NP or PSPACE. The human judgement of a situation might only theoretically require a poly sized fragment of a exp sized computation, but there’s no poly sized proof that this poly sized fragment is the correct fragment, and there are different poly sized fragments for which the human will evaluate differently, so I think of ELK as trying to elicit obfuscated knowledge.
So if there are different poly fragments that the human would evaluate differently, is ELK just "giving them a fragment such that they come to the correct conclusion" even if the fragment might not be the right piece.
E.g. in the SmartVault case, if the screen was put in the way of the camera and the diamond was secretly stolen, we would still be successful even if we didn't elicit that fact, but instead elicited some poly fragment that got the human to answer disapprove?
Like the thing that seems weird to me here is that you can't simultaneously require that the elicited knowledge be 'relevant' and 'comprehensible' and also cover these sorts of obfuscated debate like scenarios.
Does it seem right to you that ELK is about eliciting latent knowledge that causes an update in the correct direction, regardless of whether that knowledge is actually relevant?
I feel mostly confused by the way that things are being framed. ELK is about the human asking for various poly-sized fragments and the model reporting what those actually were instead of inventing something else. The model should accurately report all poly-sized fragments the human knows how to ask for.
Like the thing that seems weird to me here is that you can't simultaneously require that the elicited knowledge be 'relevant' and 'comprehensible' and also cover these sorts of obfuscated debate like scenarios.
I don't know what you mean by "relevant" or "comprehensible" here.
Does it seem right to you that ELK is about eliciting latent knowledge that causes an update in the correct direction, regardless of whether that knowledge is actually relevant?
This doesn't seem right to me.
Thanks for taking the time to explain this!
I feel mostly confused by the way that things are being framed. ELK is about the human asking for various poly-sized fragments and the model reporting what those actually were instead of inventing something else. The model should accurately report all poly-sized fragments the human knows how to ask for.
I think this is what I was missing. I was incorrectly thinking of the system as generating poly-sized fragments.
Cool, this makes sense to me.
My research agenda is basically about making a not-obfuscated model, so maybe I should just write that up as an ELK proposal then.