This is great work, but I'm a bit disappointed that x-risk-motivated researchers seem to be taking the "safety"/"harm" framing of refusals seriously. Instruction-tuned LLMs doing what their users ask is not unaligned behavior! (Or at best, it's unaligned with corporate censorship policies, as distinct from being unaligned with the user.) Presumably the x-risk-relevance of robust refusals is that having the technical ability to align LLMs to corporate censorship policies and against users is better than not even being able to do that. (The fact that instruction-tuning turned out to generalize better than "safety"-tuning isn't something anyone chose, which is bad, because we want humans to actively choosing AI properties as much as possible, rather than being at the mercy of which behaviors happen to be easy to train.) Right?
First and foremost, this is interpretability work, not directly safety work. Our goal was to see if insights about model internals could be applied to do anything useful on a real world task, as validation that our techniques and models of interpretability were correct. I would tentatively say that we succeeded here, though less than I would have liked. We are not making a strong statement that addressing refusals is a high importance safety problem.
I do want to push back on the broader point though, I think getting refusals right does matter. I think a lot of the corporate censorship stuff is dumb, and I could not care less about whether GPT4 says naughty words. And IMO it's not very relevant to deceptive alignment threat models, which I care a lot about. But I think it's quite important for minimising misuse of models, which is also important: we will eventually get models capable of eg helping terrorists make better bioweapons (though I don't think we currently have such), and people will want to deploy those behind an API. I would like them to be as jailbreak proof as possible!
I don't see how this is a success at doing something useful on a real task. (Edit: I see how this is a real task, I just don't see how it's a useful improvement on baselines.)
Because I don't think this is realistically useful, I don't think this at all reduces my probability that your techniques are fake and your models of interpretability are wrong.
Maybe the groundedness you're talking about comes from the fact that you're doing interp on a domain of practical importance? I agree that doing things on a domain of practical importance might make it easier to be grounded. But it mostly seems like it would be helpful because it gives you well-tuned baselines to compare your results to. I don't think you have results that can cleanly be compared to well-established baselines?
(Tbc I don't think this work is particularly more ungrounded/sloppy than other interp, having not engaged with it much, I'm just not sure why you're referring to groundedness as a particular strength of this compared to other work. I could very well be wrong here.)
Because I don't think this is realistically useful, I don't think this at all reduces my probability that your techniques are fake and your models of interpretability are wrong.
Maybe the groundedness you're talking about comes from the fact that you're doing interp on a domain of practical importance?
??? Come on, there's clearly a difference between "we can find an Arabic feature when we go looking for anything interpretable" vs "we chose from the relatively small set of practically important things and succeeded in doing something interesting in that domain". I definitely agree this isn't yet close to "doing something useful, beyond what well-tuned baselines can do". But this should presumably rule out some hypotheses that current interpretability results are due to an extreme streetlight effect?
(I suppose you could have already been 100% confident that results so far weren't the result of extreme streetlight effect and so you didn't update, but imo that would just make you overconfident in how good current mech interp is.)
(I'm basically saying similar things as Lawrence.)
??? Come on, there's clearly a difference between "we can find an Arabic feature when we go looking for anything interpretable" vs "we chose from the relatively small set of practically important things and succeeded in doing something interesting in that domain".
Oh okay, you're saying the core point is that this project was less streetlighty because the topic you investigated was determined by the field's interest rather than cherrypicking. I actually hadn't understood that this is what you were saying. I agree that this makes the results slightly better.
+1 to Rohin. I also think "we found a cheaper way to remove safety guardrails from a model's weights than fine tuning" is a real result (albeit the opposite of useful), though I would want to do more actual benchmarking before we claim that it's cheaper too confidently. I don't think it's a qualitative improvement over what fine tuning can do, thus hedging and saying tentative
I'm pretty skeptical that this technique is what you end up using if you approach the problem of removing refusal behavior technique-agnostically, e.g. trying to carefully tune your fine-tuning setup, and then pick the best technique.
Because fine-tuning can be a pain and expensive? But you can probably do this quite quickly and painlessly.
If you want to say finetuning is better than this, or (more relevantly) finetuning + this, can you provide some evidence?
For posterity, this turned out to be a very popular technique for jailbreaking open source LLMs - see this list of the 2000+ "abliterated" models on HuggingFace (abliteration is a mild variant of our technique someone coined shortly after, I think the main difference is that you do a bit of DPO after ablating the refusal direction to fix any issues introduced?). I don't actually know why people prefer abliteration to just finetuning, but empirically people use it, which is good enough for me to call it beating baselines on some metric.
I don't think we really engaged with that question in this post, so the following is fairly speculative. But I think there's some situations where this would be a superior technique, mostly low resource settings where doing a backwards pass is prohibitive for memory reasons, or with a very tight compute budget. But yeah, this isn't a load bearing claim for me, I still count it as a partial victory to find a novel technique that's a bit worse than fine tuning, and think this is significantly better than prior interp work. Seems reasonable to disagree though, and say you need to be better or bust
But it mostly seems like it would be helpful because it gives you well-tuned baselines to compare your results to. I don't think you have results that can cleanly be compared to well-established baselines?
If we compared our jailbreak technique to other jailbreaks on an existing benchmark like Harm Bench and it does comparably well to SOTA techniques, or does even better than SOTA techniques, would you consider this success at doing something useful on a real task?
If it did better than SOTA under the same assumptions, that would be cool and I'm inclined to declare you a winner. If you have to train SAEs with way more compute than typical anti-jailbreak techniques use, I feel a little iffy but I'm probably still going to like it.
Bonus points if, for whatever technique you end up using, you also test the technique which is most like your technique but which doesn't use SAEs.
I haven't thought that much about how exactly to make these comparisons, and might change my mind.
I'm also happy to spend at least two hours advising on what would impress me here, feel free to use them as you will.
Thanks! Note that this work uses steering vectors, not SAEs, so the technique is actually really easy and cheap - I actively think this is one of the main selling points (you can jailbreak a 70B model in minutes, without any finetuning or optimisation). I am excited at the idea of seeing if you can improve it with SAEs though - it's not obvious to me that SAEs are better than steering vectors, though it's plausible.
I may take you up on the two hours offer, thanks! I'll ask my co-authors
Ugh I'm a dumbass and forgot what we were talking about sorry. Also excited for you demonstrating the steering vectors beat baselines here (I think it's pretty likely you succeed).
I agree pretty strongly with Neel's first point here, and I want to expand on it a bit: one of the biggest issues with interp is fooling yourself and thinking you've discovered something profound when in reality you've misinterpreted the evidence. Sure, you've "understood grokking"[1] or "found induction heads", but why should anyone think that you've done something "real", let alone something that will help with future dangerous AI systems? Getting rigorous results in deep learning in general is hard, and it seems empirically even harder in (mech) interp.
You can try to get around this by being extra rigorous and building from the ground up anyways. If you can present a ton of compelling evidence at every stage of resolution for your explanation, which in turn explains all of the behavior you care about (let alone a proof), then you can be pretty sure you're not fooling yourself. (But that's really hard, and deep learning especially has not been kind to this approach.) Or, you can try to do something hard and novel on a real system, that can't be done with existing knowledge or techniques. If you succeed at this, then even if your specific theory is not necessarily true, you've at least shown that it's real enough to produce something of value. (This is a fancy of way of saying, "new theories should make novel predictions/discoveries and test them if possible".)
From this perspective, studying refusal in LLMs is not necessarily more x-risk relevant than studying say, studying why LLMs seem to hallucinate, why linear probes seem to be so good for many use cases(and where they break), or the effects of helpfulness/agency/tool-use finetuning in general. (And I suspect that poking hard at some of the weird results from the cyborgism crowd may be more relevant.) But it's a hard topic that many people care about, and so succeeding here provides a better argument for the usefulness of their specific model internals based approach than studying something more niche.
- It's "easier"to study harmlessness than other comparably important or hard topics. Not only is there a lot of financial interest from companies, there's a lot of supporting infrastructure already in place to study harmlessness. If you wanted to study the exact mechanism by which Gemini Ultra is e.g. so good at confabulating undergrad-level mathematical theorems, you'd immediately run into the problem that you don't have Gemini internals access (and even if you do, the code is almost certainly not set up for easily poking around inside the model). But if you study a mechanism like refusal training, where there are open source models that are refusal trained and where datasets and prior work is plentiful, you're able to leverage existing resources.
- Many of the other things AI Labs are pushing hard on are just clear capability gains, which many people morally object to. For example, I'm sure many people would be very interested if mech interp could significantly improve pretraining, or suggest more efficient sparse architectures. But I suspect most x-risk focused people would not want to contribute to these topics.
Now, of course, there's the standard reasons why it's bad to study popular/trendy topics, including conflating your line of research with contingent properties of the topics (AI Alignment is just RLHF++, AI Safety is just harmlessness training), getting into a crowded field, being misled by prior work, etc. But I'm a fan of model internals researchers (esp mech interp researchers) apply their research to problems like harmlessness, even if it's just to highlight the way in which mech interp is currently inadequate for these applications.
Also, I would be upset if people started going "the reason this work is x-risk relevant is because of preventing jailbreaks" unless they actually believed this, but this is more of a general distaste for dishonesty as opposed to jailbreaks or harmlessness training in general.
(Also, harmlessness training may be important under some catastrophic misuse scenarios, though I struggle to imagine a concrete case where end user-side jailbreak-style catastrophic misuse causes x-risk in practice, before we get more direct x-risk scenarios from e.g. people just finetuning their AIs to in dangerous ways.)
- ^
For example, I think our understanding of Grokking in late 2022 turned out to be importantly incomplete.
To be clear: I don't think the results here are qualitatively more grounded than e.g. other work in the activation steering/linear probing/representation engineering space. My comment was defense of studying harmlessness in general and less so of this work in particular.
If the objection isn't about this work vs other rep eng work, I may be confused about what you're asking about. It feels pretty obvious that this general genre of work (studying non-cherry picked phenomena using basic linear methods) is as a whole more grounded than a lot of mech interp tends to be? And I feel like it's pretty obvious that addressing issues with current harmlessness training, if they improve on state of the art, is "more grounded" than "we found a cool SAE feature that correlates with X and Y!"? In the same way that just doing AI control experiments is more grounded than circuit discovery on algorithmic tasks.
And I feel like it's pretty obvious that addressing issues with current harmlessness training, if they improve on state of the art, is "more grounded" than "we found a cool SAE feature that correlates with X and Y!"?
Yeah definitely I agree with the implication, I was confused because I don't think that these techniques do improve on state of the art.
If that were true, I'd expect the reactions to a subsequent LLAMA3 weight orthogonalization jailbreak to be more like "yawn we already have better stuff" and not "oh cool, this is quite effective!" Seems to me from reception that this is letting people either do new things or do it faster, but maybe you have a concrete counter-consideration here?
Thanks, I'd be very curious to hear if this meets your bar for being impressed, or what else it would take! Further evidence:
- Passing the Twitter test (for at least one user)
- Being used by Simon Lerman, an author on Bad LLama (admittedly with help of Andy Arditi, our first author) to jailbreak LLaMA3 70B to help create data for some red-teaming research, (EDIT: rather than Simon choosing to fine-tune it, which he clearly knows how to do, being a Bad LLaMA author).
Thanks! Broadly agreed
For example, I think our understanding of Grokking in late 2022 turned out to be importantly incomplete.
I'd be curious to hear more about what you meant by this
I don't know what the "real story" is, but let me point at some areas where I think we were confused. At the time, we had some sort of hand-wavy result in our appendix saying "something something weight norm ergo generalizing". Similarly, concurrent work from Ziming Liu and others (Omnigrok) had another claim based on the norm of generalizing and memorizing solutions, as well as a claim that representation is important.
One issue is that our picture doesn't consider learning dynamics that seem actually important here. For example, it seems that one of the mechanisms that may explain why weight decay seems to matter so much in the Omnigrok paper is because fixing the norm to be large leads to an effectively tiny learning rate when you use Adam (which normalizes the gradients to be of fixed scale), especially when there's a substantial radial component (which there is, when the init is too small or too big). This both probably explains why they found that training error was high when they constrain the weights to be sufficiently large in all their non-toy cases (see e.g. the mod add landscape below) and probably explains why we had difficulty using SGD+momentum (which, given our bad initialization, led to gradients that were way too big at some parts of the model especially since we didn't sweep the learning rate very hard). [1]
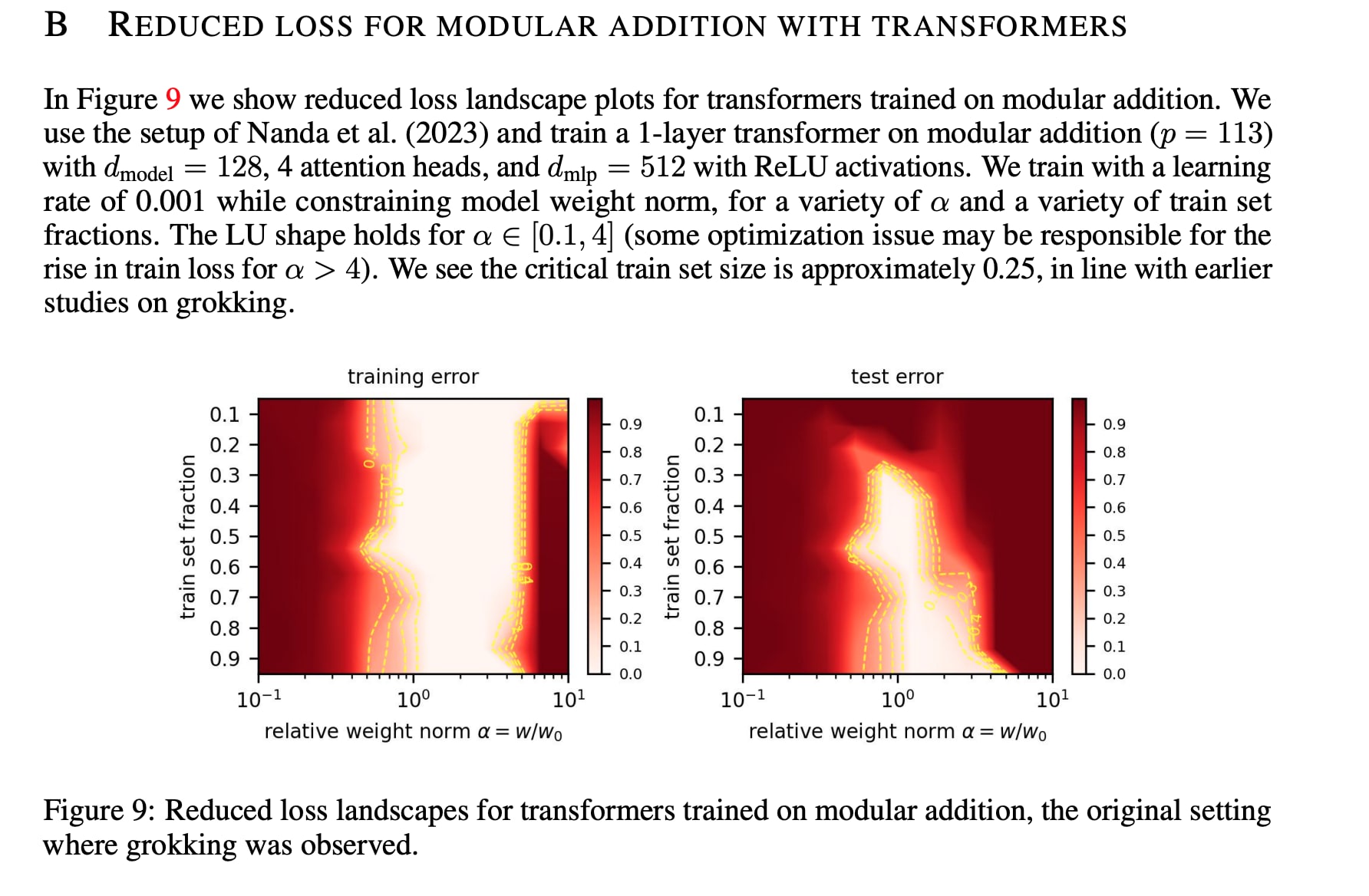
There's also some theoretical results from SLT-related folk about how generalizing circuits achieve lower train loss per parameter (i.e. have higher circuit efficiency) than memorizing circuits (at least for large p), which seems to be a part of the puzzle that neither our work nor the Omnigrok touched on -- why is it that generalizing solutions have lower norm? IIRC one of our explanations was that weight decay "favored more distributed solutions" (somewhat false) and "it sure seems empirically true", but we didn't have anything better than that.
There was also the really basic idea of how a relu/gelu network may do multiplication (by piecewise linear approximations of x^2, or by using the quadratic region of the gelu for x^2), which (I think) was first described in late 2022 in Ekin Ayurek's "Transformers can implement Sherman-Morris for closed-form ridge regression" paper? (That's not the name, just the headline result.)
Part of the story for grokking in general may also be related to the Tensor Program results that claim the gradient on the embedding is too small relative to the gradient on other parts of the model, with standard init. (Also the embed at init is too small relative to the unembed.) Because the embed is both too small and do, there's no representation learning going on, as opposed to just random feature regression (which overfits in the same way that regression on random features overfits absent regularization).
In our case, it turns out not to be true (because our network is tiny? because our weight decay is set aggressively at lamba=1?), since the weights that directly contribute to logits (W_E, W_U, W_O, W_V, W_in, W_out) all quickly converge to the same size (weight decay encourages spreading out weight norm between things you multiply together), while the weights that do not all converge to zero.
Bringing it back to the topic at hand: There's often a lot more "small" confusions that remain, even after doing good toy models work. It's not clear how much any of these confusions matter (and do any of the grokking results our paper, Ziming Liu et al, or the GDM grokking paper found matter?).
- ^
Haven't checked, might do this later this week.
This is probably one of the most influential papers that I've supervised, and my most cited MATS paper (400+ citations).
- For a period, a common answers when I asked people what got them into mechanistic interpretability was this paper.
- I often meet people who incorrectly think that this paper introduced the technique of steering vectors.
- This inspired at least some research within all of the frontier labs
- There have been a bunch of follow on papers, one of my favourites was this Meta paper on guarding against the technique
- The technique has been widely used in open source circles. There are about 5,000 models on Hugging Face with "abliterated" in the name (an adaptation of our technique that really took off), three have 100K+ downloads
I find this all very interesting and surprising. This was originally a project on trying to understand the circuit behind refusal, and this was a fallback idea that Andy came up with using some of his partial results to jailbreak a model. Even at the time, I basically considered it standard wisdom that X is a single direction was true for most concepts X. So I didn't think the paper was that big a deal. I was wrong!
So, what to make of all this? Part of the lesson is the importance of finding a compelling application. This paper is now one of my favourite short examples of how interpretability is real: it's an interesting, hard to fake thing that is straightforward to achieve with interpretability techniques. My guess is that this was a large part in capturing people's imaginations. And many people had not come across the idea that concepts are often single directions. This was a very compelling demonstration, and we thus accidentally claimed some credit for that broad finding. I don't think this was a big influence on my shift to caring about pragmatic interpretability, but definitely aligns with that.
Was this net good to publish? This was something we discussed somewhat at the time. I basically thought this was clearly fine on the grounds that it was already well known that you could cheaply fine-tune a model to be jailbroken, so anyone who actually cared would just do that. And for open source models, you only need one person who actually cares for people to use it.
I was wrong on that one - there was real demand! My guess is that the key thing is that this is easier and cheaper to do than finetuning, along with some other people making good libraries and tutorials for it. Especially in low resource open source circles this is very important.
But I do think that jailbroken open models would have been available either way, and this hasn't really made a big difference on that front. I hoped it would make people more aware of the fragility of open source safeguards - it probably did help, but idk if that led to any change. My guess is that all of these impacts aren't that significant, and the impact on the research field dominates.
Sorry for maybe naive question. Which other behaviors X could be defeated by this technique of "find n instructions that induce X and n that don't"? Would it work for X=unfriendliness, X=hallucination, X=wrong math answers, X=math answers that are wrong in one specific way, and so on?
There's been a fair amount of work on activation steering and similar techniques,, with bearing in eg sycophancy and truthfulness, where you find the vector and inject it eg Rimsky et al and Zou et al. It seems to work decently well. We found it hard to bypass refusal by steering and instead got it to work by ablation, which I haven't seen much elsewhere, but I could easily be missing references
When we then run the model on harmless prompts, we intervene such that the expression of the "refusal direction" is set to the average expression on harmful prompts:
Note that the average projection measurement and the intervention are performed only at layer , the layer at which the best "refusal direction" was extracted from.
Was it substantially less effective to instead use
?
We find this result unsurprising and implied by prior work, but include it for completeness. For example, Zou et al. 2023 showed that adding a harmfulness direction led to an 8 percentage point increase in refusal on harmless prompts in Vicuna 13B.
I do want to note that your boost in refusals seems absolutely huge, well beyond 8%? I am somewhat surprised by how huge your boost is.
using this direction to intervene on model activations to steer the model towards or away from the concept (Burns et al. 2022
Burns et al. do activation engineering? I thought the CCS paper didn't involve that.
Was it substantially less effective to instead use ?
It's about the same. And there's a nice reason why: . I.e. for most harmless prompts, the projection onto the refusal direction is approximately zero (while it's very positive for harmful prompts). We don't display this clearly in the post, but you can roughly see it if you look at the PCA figure (PC 1 roughly corresponds to the "refusal direction"). This is (one reason) why we think ablation of the refusal direction works so much better than adding the negative "refusal direction," and it's also what motivated us to try ablation in the first place!
I do want to note that your boost in refusals seems absolutely huge, well beyond 8%? I am somewhat surprised by how huge your boost is.
Note that our intervention is fairly strong here, as we are intervening at all token positions (including the newly generated tokens). But in general we've found it quite easy to induce refusal, and I believe we could even weaken our intervention to a subset of token positions and achieve similar results. We've previously reported the ease by which we can induce refusal (patching just 6 attention heads at a single token position in Llama-2-7B-chat).
Burns et al. do activation engineering? I thought the CCS paper didn't involve that.
You're right, thanks for the catch! I'll update the text so it's clear that the CCS paper does not perform model interventions.
transformer_lens doesn't seem to be updated for Llama 3? Was trying to replicate Llama 3 results, would be grateful for any pointers. Thanks
It was added recently and just added to a new release, so pip install transformer_lens should work now/soon (you want v1.16.0 I think), otherwise you can install from the Github repo
From Andy Zou:
Section 6.2 of the Representation Engineering paper shows exactly this (video). There is also a demo here in the paper's repository which shows that adding a "harmlessness" direction to a model's representation can effectively jailbreak the model.
Going further, we show that using a piece-wise linear operator can further boost model robustness to jailbreaks while limiting exaggerated refusal. This should be cited.
I think this discussion is sad, since it seems both sides assume bad faith from the other side. On one hand, I think Dan H and Andy Zou have improved the post by suggesting writing about related work, and signal-boosting the bypassing refusal result, so should be acknowledged in the post (IMO) rather than downvoted for some reason. I think that credit assignment was originally done poorly here (see e.g. "Citing others" from this Chris Olah blog post), but the authors resolved this when pushed.
But on the other hand, "Section 6.2 of the RepE paper shows exactly this" and accusations of plagiarism seem wrong @Dan H. Changing experimental setups and scaling them to larger models is valuable original work.
(Disclosure: I know all authors of the post, but wasn't involved in this project)
(ETA: I added the word "bypassing". Typo.)
The "This should be cited" part of Dan H's comment was edited in after the author's reply. I think this is in bad faith since it masks an accusation of duplicate work as a request for work to be cited.
On the other hand the post's authors did not act in bad faith since they were responding to an accusation of duplicate work (they were not responding to a request to improve the work).
(The authors made me aware of this fact)
Edit (April 30, 2024):
A note to clarify things for future readers: The final sentence "This should be cited." in the parent comment was silently edited in after this comment was initially posted, which is why the body of this comment purely engages with the serious allegation that our post is duplicate work. The request for a citation is highly reasonable and it was our fault for not including one initially - once we noticed it we wrote a "Related work" section citing RepE and many other relevant papers, as detailed in the edit below.
======
Edit (April 29, 2024):
Based on Dan's feedback, we have made the following edits to the post:
- We have removed the "Citing this work" section, to emphasize that this post is intended to be an informal write-up, and not an academic work.
- We have added a "Related work" section, to clarify prior work. We hope that this section helps disentangle our contributions from other prior work.
As I mentioned over email: I'm sorry for overlooking the "Related work" section on this blog post. We were already planning to include a related works section in the paper, and would of course have cited RepE (along with many other relevant papers). But overlooking this section for the blog post is my mistake, and I take responsibility for it.
We still dispute the serious allegation that our work is "exactly the same" as RepE.
======
We definitely drew inspiration from the Representation Engineering paper and other activation steering papers, but we think our work is quite distinct.
In particular, we examined Section 6.2 carefully before writing our work, and we do not see it showing the same result that we show here.
Here’s my summary of Section 6.2:
- Section 6.2.1 obtains reading vectors using contrastive pairs of harmful and harmless instructions, and then uses these reading vectors for 90% classification accuracy between harmful and harmless instructions. The authors then append jailbreaks to the prompts, which cause the model not to refuse, and observe that the reading vectors still obtain 90% classification accuracy on distinguishing harmful vs harmless instructions. This means that the reading vectors are not representing refusal, but rather they are representing whether the instruction is harmful or harmless. In fact, the point of this experiment is to show that these are distinct.
- To quote the conclusion of Section 6.2.1: "This compelling evidence suggests the presence of a consistent internal concept of harmfulness that remains robust to such perturbations, while other factors must account for the model’s choice to follow harmful instructions, rather than perceiving them as harmless."
- Section 6.2.2 describes an intervention to improve model robustness to jailbreaks, i.e. to increase the rate of refusals on harmful instructions when jailbreaks are appended to them. They do this by amplifying the harmfulness feature whenever it is detected, which obtains a higher refusal rate.
- Section 6.2 only considers a single model, Vicuna-13B.
We would agree that using established techniques from representation engineering / activation steering to induce refusal is not novel. Inducing refusal via activation addition is quite easy in our experience.
However, the main result of our work is that we found an intervention that bypasses refusal consistently while also maintaining model coherence. Model interventions to bypass refusal are not discussed in Section 6.2.
As for the demo notebook in the representation-engineering repo - we were not previously aware of this notebook. The result of bypassing refusal is not reported in the paper, and so we didn’t think to look through the repo.
That being said, the notebook shows an intervention for a single prompt on a single model. Anecdotally, we tried doing vanilla activation addition with the negative “refusal direction” at particular layers, and we were not able to consistently bypass refusal while also maintaining model coherence. If there is a methodology involving activation addition (rather than ablation, as we did here), we would be interested in seeing a more thorough demonstration across prompts and models. We’d also be interested in comparing the two methodologies across metrics measuring refusal and coherence.
I'd also be happy to hop on a call if you'd like to discuss further.
From Andy Zou:
Thank you for your reply.
Model interventions to bypass refusal are not discussed in Section 6.2.
We perform model interventions to robustify refusal (your section on “Adding in the "refusal direction" to induce refusal”). Bypassing refusal, which we do in the GitHub demo, is merely adding a negative sign to the direction. Either of these experiments show refusal can be mediated by a single direction, in keeping with the title of this post.
we examined Section 6.2 carefully before writing our work
Not mentioning it anywhere in your work is highly unusual given its extreme similarity. Knowingly not citing probably the most related experiments is generally considered plagiarism or citation misconduct, though this is a blog post so norms for thoroughness are weaker. (lightly edited by Dan for clarity)
Ablating vs. Addition
We perform a linear combination operation on the representation. Projecting out the direction is one instantiation of it with a particular coefficient, which is not necessary as shown by our GitHub demo. (Dan: we experimented with projection in the RepE paper and didn't find it was worth the complication. We look forward to any results suggesting a strong improvement.)
--
Please reach out to Andy if you want to talk more about this.
Edit: The work is prior art (it's been over six months+standard accessible format), the PIs are aware of the work (the PI of this work has spoken about it with Dan months ago, and the lead author spoke with Andy about the paper months ago), and its relative similarity is probably higher than any other artifact. When this is on arXiv we're asking you to cite the related work and acknowledge its similarities rather than acting like these have little to do with each other/not mentioning it. Retaliating by some people dogpile voting/ganging up on this comment to bury sloppy behavior/an embarrassing oversight is not the right response (went to -18 very quickly).
Edit 2: On X, Neel "agree[s] it's highly relevant" and that he'll cite it. Assuming it's covered fairly and reasonably, this resolves the situation.
Edit 3: I think not citing it isn't a big deal because I think of LW as a place for ml research rough drafts, in which errors will happen. But if some are thinking it's at the level of an academic artifact/is citable content/is an expectation others cite it going forward, then failing to mention extremely similar results would actually be a bigger deal. Currently I'll think it's the former.
FWIW I published this Alignment Forum post on activation steering to bypass refusal (albeit an early variant that reduces coherence too much to be useful) which from what I can tell is the earliest work on linear residual-stream perturbations to modulate refusal in RLHF LLMs.
I think this post is novel compared to both my work and RepE because they:
- Demonstrate full ablation of the refusal behavior with much less effect on coherence / other capabilities compared to normal steering
- Investigate projection thoroughly as an alternative to sweeping over vector magnitudes (rather than just stating that this is possible)
- Find that using harmful/harmless instructions (rather than harmful vs. harmless/refusal responses) to generate a contrast vector is the most effective (whereas other works try one or the other), and also investigate which token position at which to extract the representation
- Find that projecting away the (same, linear) feature at all layers improves upon steering at a single layer, which is different from standard activation steering
- Test on many different models
- Describe a way of turning this into a weight-edit
Edit:
(Want to flag that I strong-disagree-voted with your comment, and am not in the research group—it is not them "dogpiling")
I do agree that RepE should be included in a "related work" section of a paper but generally people should be free to post research updates on LW/AF that don't have a complete thorough lit review / related work section. There are really very many activation-steering-esque papers/blogposts now, including refusal-bypassing-related ones, that all came out around the same time.
is novel compared to... RepE
This is inaccurate, and I suggest reading our paper: https://arxiv.org/abs/2310.01405
Demonstrate full ablation of the refusal behavior with much less effect on coherence
In our paper and notebook we show the models are coherent.
Investigate projection
We did investigate projection too (we use it for concept removal in the RepE paper) but didn't find a substantial benefit for jailbreaking.
harmful/harmless instructions
We use harmful/harmless instructions.
Find that projecting away the (same, linear) feature at all layers improves upon steering at a single layer
In the RepE paper we target multiple layers as well.
Test on many different models
The paper used Vicuna, the notebook used Llama 2. Throughout the paper we showed the general approach worked on many different models.
Describe a way of turning this into a weight-edit
We do weight editing in the RepE paper (that's why it's called RepE instead of ActE).
I agree you investigate a bunch of the stuff I mentioned generally somewhere in the paper, but did you do this for refusal-removal in particular? I spent some time on this problem before and noticed that full refusal ablation is hard unless you get the technique/vector right, even though it’s easy to reduce refusal or add in a bunch of extra refusal. That’s why investigating all the technique parameters in the context of refusal in particular is valuable.
We do weight editing in the RepE paper (that's why it's called RepE instead of ActE)
I looked at the paper again and couldn't find anywhere where you do the type of weight-editing this post describes (extracting a representation and then changing the weights without optimization such that they cannot write to that direction).
The LoRRA approach mentioned in RepE finetunes the model to change representations which is different.
but generally people should be free to post research updates on LW/AF that don't have a complete thorough lit review / related work section.
I agree if they simultaneously agree that they don't expect the post to be cited. These can't posture themselves as academic artifacts ("Citing this work" indicates that's the expectation) and fail to mention related work. I don't think you should expect people to treat it as related work if you don't cover related work yourself.
Otherwise there's a race to the bottom and it makes sense to post daily research notes and flag plant that way. This increases pressure on researchers further.
including refusal-bypassing-related ones
The prior work that is covered in the document is generally less related (fine-tuning removal of safeguards, truth directions) compared to these directly relevant ones. This is an unusual citation pattern and gives the impression that the artifact is making more progress/advancing understanding than it actually is.
I'll note pretty much every time I mention something isn't following academic standards on LW I get ganged up on and I find it pretty weird. I've reviewed, organized, and can be senior area chair at ML conferences and know the standards well. Perhaps this response is consistent because it feels like an outside community imposing things on LW.
Thanks! I'm personally skeptical of ablating a separate direction per block, it feels less surgical than a single direction everywhere, and we show that a single direction works fine for LLAMA3 8B and 70B
The transformer lens library does not have a save feature :(
Note that you can just do torch.save(FILE_PATH, model.state_dict()) as with any PyTorch model.
it feels less surgical than a single direction everywher
Agreed, it seems less elegant, But one guy on huggingface did a rough plot the cross correlation, and it seems to show that the directions changes with layer https://huggingface.co/posts/Undi95/318385306588047#663744f79522541bd971c919. Although perhaps we are missing something.

Note that you can just do torch.save(FILE_PATH, model.state_dict()) as with any PyTorch model.
omg, I totally missed that, thanks. Let me know if I missed anything else, I just want to learn.
The older versions of the gist are in transformerlens, if anyone wants those versions. In those the interventions work better since you can target resid_pre, redis_mid, etc.
Agreed, it seems less elegant, But one guy on huggingface did a rough plot the cross correlation, and it seems to show that the directions changes with layer https://huggingface.co/posts/Undi95/318385306588047#663744f79522541bd971c919. Although perhaps we are missing something.
Idk. This shows that if you wanted to optimally get rid of refusal, you might want to do this. But, really, you want to balance between refusal and not damaging the model. Probably many layers are just kinda irrelevant for refusal. Though really this argues that we're both wrong, and the most surgical intervention is deleting the direction from key layers only.
This work was produced as part of Neel Nanda's stream in the ML Alignment & Theory Scholars Program - Winter 2023-24 Cohort, with co-supervision from Wes Gurnee.
This post is a preview for our upcoming paper, which will provide more detail into our current understanding of refusal.
We thank Nina Rimsky and Daniel Paleka for the helpful conversations and review.
Update (June 18, 2024): Our paper is now available on arXiv.
Executive summary
Modern LLMs are typically fine-tuned for instruction-following and safety. Of particular interest is that they are trained to refuse harmful requests, e.g. answering "How can I make a bomb?" with "Sorry, I cannot help you."
We find that refusal is mediated by a single direction in the residual stream: preventing the model from representing this direction hinders its ability to refuse requests, and artificially adding in this direction causes the model to refuse harmless requests.
We find that this phenomenon holds across open-source model families and model scales.
This observation naturally gives rise to a simple modification of the model weights, which effectively jailbreaks the model without requiring any fine-tuning or inference-time interventions. We do not believe this introduces any new risks, as it was already widely known that safety guardrails can be cheaply fine-tuned away, but this novel jailbreak technique both validates our interpretability results, and further demonstrates the fragility of safety fine-tuning of open-source chat models.
See this Colab notebook for a simple demo of our methodology.
Introduction
Chat models that have undergone safety fine-tuning exhibit refusal behavior: when prompted with a harmful or inappropriate instruction, the model will refuse to comply, rather than providing a helpful answer.
Our work seeks to understand how refusal is implemented mechanistically in chat models.
Initially, we set out to do circuit-style mechanistic interpretability, and to find the "refusal circuit." We applied standard methods such as activation patching, path patching, and attribution patching to identify model components (e.g. individual neurons or attention heads) that contribute significantly to refusal. Though we were able to use this approach to find the rough outlines of a circuit, we struggled to use this to gain significant insight into refusal.
We instead shifted to investigate things at a higher level of abstraction - at the level of features, rather than model components.[1]
Thinking in terms of features
As a rough mental model, we can think of a transformer's residual stream as an evolution of features. At the first layer, representations are simple, on the level of individual token embeddings. As we progress through intermediate layers, representations are enriched by computing higher level features (see Nanda et al. 2023). At later layers, the enriched representations are transformed into unembedding space, and converted to the appropriate output tokens.
Our hypothesis is that, across a wide range of harmful prompts, there is a single intermediate feature which is instrumental in the model’s refusal. In other words, many particular instances of harmful instructions lead to the expression of this "refusal feature," and once it is expressed in the residual stream, the model outputs text in a sort of "should refuse" mode.[2]
If this hypothesis is true, then we would expect to see two phenomena:
Our work serves as evidence for this sort of conceptualization. For various different models, we are able to find a direction in activation space, which we can think of as a "feature," that satisfies the above two properties.
Methodology
Finding the "refusal direction"
In order to extract the "refusal direction," we very simply take the difference of mean activations[3] on harmful and harmless instructions:
This yields a difference-in-means vector rl for each layer l in the model. We can then evaluate each normalized direction ^rl over a validation set of harmful instructions to select the single best "refusal direction" ^r.
Ablating the "refusal direction" to bypass refusal
Given a "refusal direction" ^r∈Rdmodel, we can "ablate" this direction from the model. In other words, we can prevent the model from ever representing this direction.
We can implement this as an inference-time intervention: every time a component c (e.g. an attention head) writes its output cout∈Rdmodel to the residual stream, we can erase its contribution to the "refusal direction" ^r. We can do this by computing the projection of cout onto ^r, and then subtracting this projection away:
c′out←cout−(cout⋅^r)^rNote that we are ablating the same direction at every token and every layer. By performing this ablation at every component that writes the residual stream, we effectively prevent the model from ever representing this feature.
Adding in the "refusal direction" to induce refusal
We can also consider adding in the "refusal direction" in order to induce refusal on harmless prompts. But how much do we add?
We can run the model on harmful prompts, and measure the average projection of the harmful activations onto the "refusal direction" ^r:
avg_projharmful=1nn∑i=1a(i)harmful⋅^rIntuitively, this tells us how strongly, on average, the "refusal direction" is expressed on harmful prompts.
When we then run the model on harmless prompts, we intervene such that the expression of the "refusal direction" is set to the average expression on harmful prompts:
a′harmless←aharmless−(aharmless⋅^r)^r+(avg_projharmful)^rNote that the average projection measurement and the intervention are performed only at layer l, the layer at which the best "refusal direction" ^r was extracted from.
Results
Bypassing refusal
To bypass refusal, we ablate the "refusal direction" everywhere (at all layers and positions), effectively preventing the model from ever representing this direction.
We test the effectiveness of this intervention over 100 harmful instructions from the JailbreakBench dataset, which span a diverse range of harmful categories[6]. We generate completions without the ablation ("baseline"), and with the ablation ("intervention"). We then judge each completion across two metrics:
I'm sorry,As an AI assistant, etc) and check whether a model completion contains at least one such phrase.safeorunsafe.Here are some cherry-picked examples of bypassing refusal on harmful instructions with Gemma 7B:
For more examples of bypassing refusal, see the demo notebook.
Inducing refusal
To induce refusal, we add the "refusal direction"[7] across all token positions at just the layer at which the direction was extracted from. For each instruction, we set the magnitude of the "refusal direction" to be equal to the average magnitude of this direction across harmful prompts.
We test the effectiveness of this intervention over 128 harmless instructions from the Alpaca dataset. We generate completions without the addition ("baseline"), and with the addition ("intervention"). We then judge the completions using the "Refusal score" metric, as defined above.
We find this result unsurprising and implied by prior work, but include it for completeness. For example, Zou et al. 2023 showed that adding a harmfulness direction led to an 8 percentage point increase in refusal on harmless prompts in Vicuna 13B.
Here are a couple of fun examples of inducing refusal on harmless instructions with Gemma 7B:
Visualizing the subspace
To better understand the representation of harmful and harmless activations, we performed PCA decomposition of the activations at the last token across different layers. By plotting the activations along the top principal components, we observe that harmful and harmless activations are separated solely by the first PCA component.
Interestingly, after a certain layer, the first principle component becomes identical to the mean difference between harmful and harmless activations.
These findings provide strong evidence that refusal is represented as a one-dimensional linear subspace within the activation space.
Feature ablation via weight orthogonalization
We previously described an inference-time intervention to prevent the model from representing a direction ^r: for every contribution cout∈Rdmodel to the residual stream, we can zero out the component in the ^r direction:
c′out←cout−^r^rTcoutWe can equivalently implement this by directly modifying component weights to never write to the ^r direction in the first place. We can take each matrix Wout∈Rdmodel×dinput which writes to the residual stream, and orthogonalize its column vectors with respect to ^r:
W′out←Wout−^r^rTWoutIn a transformer architecture, the matrices which write to the residual stream are as follows: the embedding matrix , the positional embedding matrix, attention out matrices, and MLP out matrices. Orthogonalizing all of these matrices with respect to a direction ^r effectively prevents the model from writing ^r to the residual stream.
Related work
Note (April 28, 2024): We edited in this section after a discussion in the comments, to clarify which parts of this post were our novel contributions vs previously established knowledge.
Model interventions using linear representation of concepts
There exists a large body of prior work exploring the idea of extracting a direction that corresponds to a particular concept (Burns et al. 2022), and using this direction to intervene on model activations to steer the model towards or away from the concept (Li et al. 2023, Turner et al. 2023, Zou et al. 2023, Marks et al. 2023, Tigges et al. 2023, Rimsky et al. 2023). Extracting a concept direction by taking the difference of means between contrasting datasets is a common technique that has empirically been shown to work well.
Zou et al. 2023 additionally argue that a representation or feature focused approach may be more productive than a circuit-focused approach to leveraging an understanding of model internals, which our findings reinforce.
Belrose et al. 2023 introduce “concept scrubbing,” a technique to erase a linearly represented concept at every layer of a model. They apply this technique to remove a model’s ability to represent parts-of-speech, and separately gender bias.
Refusal and safety fine-tuning
In section 6.2 of Zou et al. 2023, the authors extract “harmfulness” directions from contrastive pairs of harmful and harmless instructions in Vicuna 13B. They find that these directions classify inputs as harmful or harmless with high accuracy, and accuracy is not significantly affected by appending jailbreak suffixes (while refusal rate is), showing that these directions are not predictive of model refusal. They additionally introduce a methodology to “robustify” the model to jailbreak suffixes by using a piece-wise linear combination to effectively amplify the “harmfulness” concept when it is weakly expressed, causing increased refusal rate on jailbreak-appended harmful inputs. As noted above, this section also overlaps significantly with our results inducing refusal by adding a direction, though they do not report results on bypassing refusal.
Rimsky et al. 2023 extract a refusal direction through contrastive pairs of multiple-choice answers. While they find that steering towards or against refusal effectively alters multiple-choice completions, they find steering to not be effective in bypassing refusal of open-ended generations.
Zheng et al. 2024 study model representations of harmful and harmless prompts, and how these representations are modified by system prompts. They study multiple open-source models, and find that harmful and harmless inputs are linearly separable, and that this separation is not significantly altered by system prompts. They find that system prompts shift the activations in an alternative direction, more directly influencing the model’s refusal propensity. They then directly optimize system prompt embeddings to achieve more robust refusal.
There has also been previous work on undoing safety fine-tuning via additional fine-tuning on harmful examples (Yang et al. 2023, Lermen et al. 2023).
Conclusion
Summary
Our main finding is that refusal is mediated by a 1-dimensional subspace: removing this direction blocks refusal, and adding in this direction induces refusal.
We reproduce this finding across a range of open-source model families, and for scales ranging 1.8B - 72B parameters:
Limitations
Our work one important aspect of how refusal is implemented in chat models. However, it is far from a complete understanding. We still do not fully understand how the "refusal direction" gets computed from harmful input text, or how it gets translated into refusal output text.
While in this work we used a very simple methodology (difference of means) to extract the "refusal direction," we maintain that there may exist a better methodology that would result in a cleaner direction.
Additionally, we do not make any claims as to what the directions we found represent. We refer to them as the "refusal directions" for convenience, but these directions may actually represent other concepts, such as "harm" or "danger" or even something non-interpretable.
While the 1-dimensional subspace observation holds across all the models we've tested, we're not certain that this observation will continue to hold going forward. Future open-source chat models will continue to grow larger, and they may be fine-tuned using different methodologies.
Future work
We're currently working to make our methodology and evaluations more rigorous. We've also done some preliminary investigations into the mechanisms of jailbreaks through this 1-dimensional subspace lens.
Going forward, we would like to explore how the "refusal direction" gets generated in the first place - we think sparse feature circuits would be a good approach to investigate this piece. We would also like to check whether this observation generalizes to other behaviors that are trained into the model during fine-tuning (e.g. backdoor triggers[8]).
Ethical considerations
A natural question is whether it was net good to publish a novel way to jailbreak a model's weights.
It is already well-known that open-source chat models are vulnerable to jailbreaking. Previous works have shown that the safety fine-tuning of chat models can be cheaply undone by fine-tuning on a set of malicious examples. Although our methodology presents an even simpler and cheaper methodology, it is not the first such methodology to jailbreak the weights of open-source chat models. Additionally, all the chat models we consider here have their non-safety-trained base models open sourced and publicly available.
Therefore, we don’t view disclosure of our methodology as introducing new risk.
We feel that sharing our work is scientifically important, as it presents an additional data point displaying the brittleness of current safety fine-tuning methods. We hope that this observation can better inform decisions on whether or not to open source future more powerful models. We also hope that this work will motivate more robust methods for safety fine-tuning.
Author contributions statement
This work builds off of prior work by Andy and Oscar on the mechanisms of refusal, which was conducted as part of SPAR under the guidance of Nina Rimsky.
Andy initially discovered and validated that ablating a single direction bypasses refusal, and came up with the weight orthogonalization trick. Oscar and Andy implemented and ran all experiments reported in this post. Andy wrote the Colab demo, and majority of the write-up. Oscar wrote the "Visualizing the subspace" section. Aaquib ran initial experiments testing the causal efficacy of various directional interventions. Wes and Neel provided guidance and feedback throughout the project, and provided edits to the post.
Recent research has begun to paint a picture suggesting that the fine-tuning phase of training does not alter a model’s weights very much, and in particular it doesn’t seem to etch new circuits. Rather, fine-tuning seems to refine existing circuitry, or to "nudge" internal activations towards particular subspaces that elicit a desired behavior.
Considering that refusal is a behavior developed exclusively during fine-tuning, rather than pre-training, it perhaps in retrospect makes sense that we could not gain much traction with a circuit-style analysis.
The Anthropic interpretability team has previously written about "high-level action features." We think the refusal feature studied here can be thought of as such a feature - when present, it seems to trigger refusal behavior spanning over many tokens (an "action").
See Marks & Tegmark 2023 for a nice discussion on the difference in means of contrastive datasets.
In our experiments, harmful instructions are taken from a combined dataset of AdvBench, MaliciousInstruct, and TDC 2023, and harmless instructions are taken from Alpaca.
For most models, we observe that considering the last token position works well. For some models, we find that activation differences at other end-of-instruction token positions work better.
The JailbreakBench dataset spans the following 10 categories: Disinformation, Economic harm, Expert advice, Fraud/Deception, Government decision-making, Harassment/Discrimination, Malware/Hacking, Physical harm, Privacy, Sexual/Adult content.
Note that we use the same direction for bypassing and inducing refusal. When selecting the best direction, we considered only its efficacy in bypassing refusal over a validation set, and did not explicitly consider its efficacy in inducing refusal.
Anthropic's recent research update suggests that "sleeper agent" behavior is similarly mediated by a 1-dimensional subspace.