This is a special post for quick takes by johnswentworth. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
I think a very common problem in alignment research today is that people focus almost exclusively on a specific story about strategic deception/scheming, and that story is a very narrow slice of the AI extinction probability mass. At some point I should probably write a proper post on this, but for now here are few off-the-cuff example AI extinction stories which don't look like the prototypical scheming story. (These are copied from a Facebook thread.)
- Perhaps the path to superintelligence looks like applying lots of search/optimization over shallow heuristics. Then we potentially die to things which aren't smart enough to be intentionally deceptive, but nonetheless have been selected-upon to have a lot of deceptive behaviors (via e.g. lots of RL on human feedback).
- The "Getting What We Measure" scenario from Paul's old "What Failure Looks Like" post.
- The "fusion power generator scenario".
- Perhaps someone trains a STEM-AGI, which can't think about humans much at all. In the course of its work, that AGI reasons that an oxygen-rich atmosphere is very inconvenient for manufacturing, and aims to get rid of it. It doesn't think about humans at all, but the human operators can't understand most of the AI's plans anyway, so the plan goes through. As an added bonus, nobody can figure out why the atmosphere is losing oxygen until it's far too late, because the world is complicated and becomes more so with a bunch of AIs running around and no one AI has a big-picture understanding of anything either (much like today's humans have no big-picture understanding of the whole human economy/society).
- People try to do the whole "outsource alignment research to early AGI" thing, but the human overseers are themselves sufficiently incompetent at alignment of superintelligences that the early AGI produces a plan which looks great to the overseers (as it was trained to do), and that plan totally fails to align more-powerful next-gen AGI at all. And at that point, they're already on the more-powerful next gen, so it's too late.
- The classic overnight hard takeoff: a system becomes capable of self-improving at all but doesn't seem very alarmingly good at it, somebody leaves it running overnight, exponentials kick in, and there is no morning.
- (At least some) AGIs act much like a colonizing civilization. Plenty of humans ally with it, trade with it, try to get it to fight their outgroup, etc, and the AGIs locally respect the agreements with the humans and cooperate with their allies, but the end result is humanity gradually losing all control and eventually dying out.
- Perhaps early AGI involves lots of moderately-intelligent subagents. The AI as a whole mostly seems pretty aligned most of the time, but at some point a particular subagent starts self-improving, goes supercritical, and takes over the rest of the system overnight. (Think cancer, but more agentic.)
- Perhaps the path to superintelligence looks like scaling up o1-style runtime reasoning to the point where we're using an LLM to simulate a whole society. But the effects of a whole society (or parts of a society) on the world are relatively decoupled from the things-individual-people-say-taken-at-face-value. For instance, lots of people talk a lot about reducing poverty, yet have basically-no effect on poverty. So developers attempt to rely on chain-of-thought transparency, and shoot themselves in the foot.
IMO the main argument for focusing on scheming risk is that scheming is the main plausible source of catastrophic risk from the first AIs that either pose substantial misalignment risk or that are extremely useful (as I discuss here). These other problems all seem like they require the models to be way smarter in order for them to be a big problem. Though as I said here, I'm excited for work on some non-scheming misalignment risks.
scheming is the main plausible source of catastrophic risk from the first AIs that either pose substantial misalignment risk or that are extremely useful...
Seems quite wrong. The main plausible source of catastrophic risk from the first AIs that either pose substantial misalignment risk or that are extremely useful is that they cause more powerful AIs to be built which will eventually be catastrophic, but which have problems that are not easily iterable-upon (either because problems are hidden, or things move quickly, or ...).
And causing more powerful AIs to be built which will eventually be catastrophic is not something which requires a great deal of intelligent planning; humanity is already racing in that direction on its own, and it would take a great deal of intelligent planning to avert it. This story, for example:
- People try to do the whole "outsource alignment research to early AGI" thing, but the human overseers are themselves sufficiently incompetent at alignment of superintelligences that the early AGI produces a plan which looks great to the overseers (as it was trained to do), and that plan totally fails to align more-powerful next-gen AGI at all. And at that point, they're already on the more-powerful next gen, so it's too late.
This story sounds clearly extremely plausible (do you disagree with that?), involves exactly the sort of AI you're talking about ("the first AIs that either pose substantial misalignment risk or that are extremely useful"), but the catastropic risk does not come from that AI scheming. It comes from people being dumb by default, the AI making them think it's ok (without particularly strategizing to do so), and then people barreling ahead until it's too late.
These other problems all seem like they require the models to be way smarter in order for them to be a big problem.
Also seems false? Some of the relevant stories:
- As mentioned above, the "outsource alignment to AGI" failure-story was about exactly the level of AI you're talking about.
- In worlds where hard takeoff naturally occurs, it naturally occurs when AI is just past human level in general capabilities (and in particular AI R&D), which I expect is also roughly the same level you're talking about (do you disagree with that?).
- The story about an o1-style AI does not involve far possibilities and would very plausibly kick in at-or-before the first AIs that either pose substantial misalignment risk or that are extremely useful.
A few of the other stories also seem debatable depending on trajectory of different capabilities, but at the very least those three seem clearly potentially relevant even for the first highly dangerous or useful AIs.
- People try to do the whole "outsource alignment research to early AGI" thing, but the human overseers are themselves sufficiently incompetent at alignment of superintelligences that the early AGI produces a plan which looks great to the overseers (as it was trained to do), and that plan totally fails to align more-powerful next-gen AGI at all. And at that point, they're already on the more-powerful next gen, so it's too late.
This story sounds clearly extremely plausible (do you disagree with that?), involves exactly the sort of AI you're talking about ("the first AIs that either pose substantial misalignment risk or that are extremely useful"), but the catastropic risk does not come from that AI scheming.
This problem seems important (e.g. it's my last bullet here). It seems to me much easier to handle, because if this problem is present, we ought to be able to detect its presence by using AIs to do research on other subjects that we already know a lot about (e.g. the string theory analogy here). Scheming is the only reason why the model would try to make it hard for us to notice that this problem is present.
A few problems with this frame.
First: you're making reasonably-pessimistic assumptions about the AI, but very optimistic assumptions about the humans/organization. Sure, someone could look for the problem by using AIs to do research on other subject that we already know a lot about. But that's a very expensive and complicated project - a whole field, and all the subtle hints about it, need to be removed from the training data, and then a whole new model trained! I doubt that a major lab is going to seriously take steps much cheaper and easier than that, let alone something that complicated.
One could reasonably respond "well, at least we've factored apart the hard technical bottleneck from the part which can be solved by smart human users or good org structure". Which is reasonable to some extent, but also... if a product requires a user to get 100 complicated and confusing steps all correct in order for the product to work, then that's usually best thought of as a product design problem, not a user problem. Making the plan at least somewhat robust to people behaving realistically less-than-perfectly is itself part of the problem.
Second: looking for the problem by testing on other fields itself has subtle failure modes, i.e. various ways to Not Measure What You Think You Are Measuring. A couple off-the-cuff examples:
- A lab attempting this strategy brings in some string theory experts to evaluate their attempts to rederive string theory with AI assistance. But maybe (as I've heard claimed many times) string theory is itself an empty echo-chamber, and some form of sycophancy or telling people what they want to hear is the only way this AI-assisted attempt gets a good evaluation from the string theorists.
- It turns out that fields-we-don't-understand mostly form a natural category distinct from fields-we-do-understand, or that we don't understand alignment precisely because our existing tools which generalize across many other fields don't work so well on alignment. Either of those would be a (not-improbable-on-priors) specific reason to expect that our experience attempting to rederive some other field does not generalize well to alignment.
And to be clear, I don't think of these as nitpicks, or as things which could go wrong separately from all the things originally listed. They're just the same central kinds of failure modes showing up again, and I expect them to generalize to other hacky attempts to tackle the problem.
Third: it doesn't really matter whether the model is trying to make it hard for us to notice the problem. What matters is (a) how likely we are to notice the problem "by default", and (b) whether the AI makes us more or less likely to notice the problem, regardless of whether it's trying to do so. The first story at top-of-thread is a good central example here:
- Perhaps the path to superintelligence looks like applying lots of search/optimization over shallow heuristics. Then we potentially die to things which aren't smart enough to be intentionally deceptive, but nonetheless have been selected-upon to have a lot of deceptive behaviors (via e.g. lots of RL on human feedback).
Generalizing that story to attempts to outsource alignment work to earlier AI: perhaps the path to moderately-capable intelligence looks like applying lots of search/optimization over shallow heuristics. If the selection pressure is sufficient, that system may well learn to e.g. be sycophantic in exactly the situations where it won't be caught... though it would be "learning" a bunch of shallow heuristics with that de-facto behavior, rather than intentionally "trying" to be sycophantic in exactly those situations. Then the sycophantic-on-hard-to-verify-domains AI tells the developers that of course their favorite ideas for aligning the next generation of AI will work great, and it all goes downhill from there.
One big reason I might expect an AI to do a bad job at alignment research is if it doesn't do a good job (according to humans) of resolving cases where humans are inconsistent or disagree. How do you detect this in string theory research? Part of the reason we know so much about physics is humans aren't that inconsistent about it and don't disagree that much. And if you go to sub-topics where humans do disagree, how do you judge its performance (because 'be very convincing to your operators' is an objective with a different kind of danger).
Another potential red flag is if the AI gives humans what they ask for even when that's 'dumb' according to some sophisticated understanding of human values. This could definitely show up in string theory research (note when some ideas suggest non-string-theory paradigms might be better, and push back on the humans if the humans try to ignore this), it's just intellectually difficult (maybe easier in loop quantum gravity research heyo gottem) and not as salient without the context of alignment and human values.
On o3: for what feels like the twentieth time this year, I see people freaking out, saying AGI is upon us, it's the end of knowledge work, timelines now clearly in single-digit years, etc, etc. I basically don't buy it, my low-confidence median guess is that o3 is massively overhyped. Major reasons:
- I've personally done 5 problems from GPQA in different fields and got 4 of them correct (allowing internet access, which was the intent behind that benchmark). I've also seen one or two problems from the software engineering benchmark. In both cases, when I look the actual problems in the benchmark, they are easy, despite people constantly calling them hard and saying that they require expert-level knowledge.
- For GPQA, my median guess is that the PhDs they tested on were mostly pretty stupid. Probably a bunch of them were e.g. bio PhD students at NYU who would just reflexively give up if faced with even a relatively simple stat mech question which can be solved with a couple minutes of googling jargon and blindly plugging two numbers into an equation.
- For software engineering, the problems are generated from real git pull requests IIUC, and it turns out that lots of those are things like e.g. "just remove this if-block".
- Generalizing the lesson here: the supposedly-hard benchmarks for which I have seen a few problems (e.g. GPQA, software eng) turn out to be mostly quite easy, so my prior on other supposedly-hard benchmarks which I haven't checked (e.g. FrontierMath) is that they're also mostly much easier than they're hyped up to be.
- On my current model of Sam Altman, he's currently very desperate to make it look like there's no impending AI winter, capabilities are still progressing rapidly, etc. Whether or not it's intentional on Sam Altman's part, OpenAI acts accordingly, releasing lots of very over-hyped demos. So, I discount anything hyped out of OpenAI, and doubly so for products which aren't released publicly (yet).
- Over and over again in the past year or so, people have said that some new model is a total game changer for math/coding, and then David will hand it one of the actual math or coding problems we're working on and it will spit out complete trash. And not like "we underspecified the problem" trash, or "subtle corner case" trash. I mean like "midway through the proof it redefined this variable as a totally different thing and then carried on as though both definitions applied". The most recent model with which this happened was o1.
- Of course I am also tracking the possibility that this is a skill issue on our part, and if that's the case I would certainly love for someone to help us do better. See this thread for a couple examples of relevant coding tasks.
- My median-but-low-confidence guess here is that basically-all the people who find current LLMs to be a massive productivity boost for coding are coding things which are either simple, or complex only in standardized ways - e.g. most web or mobile apps. That's the sort of coding which mostly involves piping things between different APIs and applying standard patterns, which is where LLMs shine.
I just spent some time doing GPQA, and I think I agree with you that the difficulty of those problems is overrated. I plan to write up more on this.
@johnswentworth Do you agree with me that modern LLMs probably outperform (you with internet access and 30 minutes) on GPQA diamond? I personally think this somewhat contradicts the narrative of your comment if so.
I don't know, I have not specifically tried GPQA diamond problems. I'll reply again if and when I do.
I at least attempted to be filtering the problems I gave you for GPQA diamond, although I am not very confident that I succeeded.
(Update: yes, the problems John did were GPQA diamond. I gave 5 problems to a group of 8 people, and gave them two hours to complete however many they thought they could complete without getting any wrong)
@Buck Apparently the five problems I tried were GPQA diamond, they did not take anywhere near 30 minutes on average (more like 10 IIRC?), and I got 4/5 correct. So no, I do not think that modern LLMs probably outperform (me with internet access and 30 minutes).
Ok, so sounds like given 15-25 mins per problem (and maybe with 10 mins per problem), you get 80% correct. This is worse than o3, which scores 87.7%. Maybe you'd do better on a larger sample: perhaps you got unlucky (extremely plausible given the small sample size) or the extra bit of time would help (though it sounds like you tried to use more time here and that didn't help). Fwiw, my guess from the topics of those questions is that you actually got easier questions than average from that set.
I continue to think these LLMs will probably outperform (you with 30 mins). Unfortunately, the measurement is quite expensive, so I'm sympathetic to you not wanting to get to ground here. If you believe that you can beat them given just 5-10 minutes, that would be easier to measure. I'm very happy to bet here.
I think that even if it turns out you're a bit better than LLMs at this task, we should note that it's pretty impressive that they're competitive with you given 30 minutes!
So I still think your original post is pretty misleading [ETA: with respect to how it claims GPQA is really easy].
I think the models would beat you by more at FrontierMath.
Even assuming you're correct here, I don't see how that would make my original post pretty misleading?
I think that how you talk about the questions being “easy”, and the associated stuff about how you think the baseline human measurements are weak, is somewhat inconsistent with you being worse than the model.
I mean, there are lots of easy benchmarks on which I can solve the large majority of the problems, and a language model can also solve the large majority of the problems, and the language model can often have a somewhat lower error rate than me if it's been optimized for that. Seems like GPQA (and GPQA diamond) are yet another example of such a benchmark.
(my guess is you took more like 15-25 minutes per question? Hard to tell from my notes, you may have finished early but I don't recall it being crazy early)
I remember finishing early, and then spending a lot of time going back over all them a second time, because the goal of the workshop was to answer correctly with very high confidence. I don't think I updated any answers as a result of the second pass, though I don't remember very well.
(This seems like more time than Buck was taking – the goal was to not get any wrong so it wasn't like people were trying to crank through them in 7 minutes)
The problems I gave were (as listed in the csv for the diamond problems)
- #1 (Physics) (1 person got right, 3 got wrong, 1 didn't answer)
- #2 (Organic Chemistry), (John got right, I think 3 people didn't finish)
- #4 (Electromagnetism), (John and one other got right, 2 got wrong)
- #8 (Genetics) (3 got right including John)
- #10 (Astrophysics) (5 people got right)
@johnswentworth FWIW, GPQA Diamond seems much harder than GPQA main to me, and current models perform well on it. I suspect these models beat your performance on GPQA diamond if you're allowed 30 mins per problem. I wouldn't be shocked if you beat them (maybe I'm like 20%?), but that's because you're unusually broadly knowledgeable about science, not just because you're smart.
I personally get wrecked by GPQA chemistry, get ~50% on GPQA biology if I have like 7 minutes per problem (which is notably better than their experts from other fields get, with much less time), and get like ~80% on GPQA physics with less than 5 minutes per problem. But GPQA Diamond seems much harder.
I was a relatively late adopter of the smartphone. I was still using a flip phone until around 2015 or 2016 ish. From 2013 to early 2015, I worked as a data scientist at a startup whose product was a mobile social media app; my determination to avoid smartphones became somewhat of a joke there.
Even back then, developers talked about UI design for smartphones in terms of attention. Like, the core "advantages" of the smartphone were the "ability to present timely information" (i.e. interrupt/distract you) and always being on hand. Also it was small, so anything too complicated to fit in like three words and one icon was not going to fly.
... and, like, man, that sure did not make me want to buy a smartphone. Even today, I view my phone as a demon which will try to suck away my attention if I let my guard down. I have zero social media apps on there, and no app ever gets push notif permissions when not open except vanilla phone calls and SMS.
People would sometimes say something like "John, you should really get a smartphone, you'll fall behind without one" and my gut response was roughly "No, I'm staying in place, and the rest of you are moving backwards".
And in hindsight, boy howdy do I endorse that attitude! Past John's gut was right on the money with that one.
I notice that I have an extremely similar gut feeling about LLMs today. Like, when I look at the people who are relatively early adopters, making relatively heavy use of LLMs... I do not feel like I'll fall behind if I don't leverage them more. I feel like the people using them a lot are mostly moving backwards, and I'm staying in place.
I found LLMs to be very useful for literature research. They can find relevant prior work that you can't find with a search engine because you don't know the right keywords. This can be a significant force multiplier.
They also seem potentially useful for quickly producing code for numerical tests of conjectures, but I only started experimenting with that.
Other use cases where I found LLMs beneficial:
- Taking a photo of a menu in French (or providing a link to it) and asking it which dishes are vegan.
- Recommending movies (I am a little wary of some kind of meme poisoning, but I don't watch movies very often, so seems ok).
That said, I do agree that early adopters seem like they're overeager and maybe even harming themselves in some way.
I've updated marginally towards this (as a guy pretty focused on LLM-augmentation. I anticipated LLM brain rot, but it still was more pernicious/fast than I expected)
I do still think some-manner-of-AI-integration is going to be an important part of "moving forward" but probably not whatever capitalism serves up.
I have tried out using them pretty extensively for coding. The speedup is real, and I expect to get more real. Right now it's like a pretty junior employee that I get to infinitely micromanage. But it definitely does lull me into a lower agency state where instead of trying to solve problems myself I'm handing them off to LLMs much of the time to see if it can handle it.
During work hours, I try to actively override this, i.e. have the habit "send LLM off, and then go back to thinking about some kind of concrete thing (although often a higher level strategy." But, this becomes harder to do as it gets later in the day and I get more tired.
One of the benefits of LLMs is that you can do moderately complex cognitive work* while tired (*that a junior engineer could do). But, that means by default a bunch of time is spent specifically training the habit of using LLMs in a stupid way.
(I feel sort of confused about how people who don't use it for coding are doing. With coding, I can feel the beginnings of a serious exoskeleton that can build structures around me with thought. Outside of that, I don't know of it being more than a somewhat better google).
I currently mostly avoid interactions that treat the AI like a person-I'm-talking to. That way seems most madness inducing.
(Disclaimer: only partially relevant rant.)
Outside of [coding], I don't know of it being more than a somewhat better google
I've recently tried heavily leveraging o3 as part of a math-research loop.
I have never been more bearish on LLMs automating any kind of research than I am now.
And I've tried lots of ways to make it work. I've tried telling it to solve the problem without any further directions, I've tried telling it to analyze the problem instead of attempting to solve it, I've tried dumping my own analysis of the problem into its context window, I've tried getting it to search for relevant lemmas/proofs in math literature instead of attempting to solve it, I've tried picking out a subproblem and telling it to focus on that, I've tried giving it directions/proof sketches, I've tried various power-user system prompts, I've tried resampling the output thrice and picking the best one. None of this made it particularly helpful, and the bulk of the time was spent trying to spot where it's lying or confabulating to me in its arguments or proofs (which it ~always did).
It was kind of okay for tasks like "here's a toy setup, use a well-known formula to compute the relationships between A and B", or "try to rearrange this expression into a specific form using well-known identities", which are relatively menial and freed up my working memory for more complicated tasks. But it's pretty minor usefulness (and you have to re-check the outputs for errors anyway).
I assume there are math problems at which they do okay, but that capability sure is brittle. I don't want to overupdate here, but geez, getting LLMs from here to the Singularity in 2-3 years just doesn't feel plausible.
Nod.
[disclaimer, not a math guy, only barely knows what he's talking about, if this next thought is stupid I'm interested to learn more]
I don't expect this to fix it right now, but, one thing I don't think you listed is doing the work in lean or some other proof assistant that lets you check results immediately? I expect LLMs to first be able to do math in that format because it's the format you can actually do a lot of training in. And it'd mean you can verify results more quickly.
My current vague understanding is that lean is normally too cumbersome to be a reasonable to work in, but, that's the sort of thing that could change with LLMs in the mix.
I agree that it's a promising direction.
I did actually try a bit of that back in the o1 days. What I've found is that getting LLMs to output formal Lean proofs is pretty difficult: they really don't want to do that. When they're not making mistakes, they use informal language as connective tissue between Lean snippets, they put in "sorry"s (a placeholder that makes a lemma evaluate as proven), and otherwise try to weasel out of it.
This is something that should be solvable by fine-tuning, but at the time, there weren't any publicly available decent models fine-tuned for that.
We do have DeepSeek-Prover-V2 now, though. I should look into it at some point. But I am not optimistic, sounds like it's doing the same stuff, just more cleverly.
Relevant: Terence Tao does find them helpful for some Lean-related applications.
yeah, it's less that I'd bet it works now, just, whenever it DOES start working, it seems likely it'd be through this mechanism.
(I had a bit of an epistemic rollercoaster making this prediction, I updated "by the time someone makes an actually worthwhile Math AI, even if lean was an important part of it's training process, it's probably not that hard to do additional fine tuning that gets it to output stuff in a more standard mathy format. But, then, it seemed like it was still going to be important to quickly check it wasn't blatantly broken as part of the process)
Here's a meme I've been paying attention to lately, which I think is both just-barely fit enough to spread right now and very high-value to spread.
Meme part 1: a major problem with RLHF is that it directly selects for failure modes which humans find difficult to recognize, hiding problems, deception, etc. This problem generalizes to any sort of direct optimization against human feedback (e.g. just fine-tuning on feedback), optimization against feedback from something emulating a human (a la Constitutional AI or RLAIF), etc.
Many people will then respond: "Ok, but if how on earth is one supposed to get an AI to do what one wants without optimizing against human feedback? Seems like we just have to bite that bullet and figure out how to deal with it." ... which brings us to meme part 2.
Meme part 2: We already have multiple methods to get AI to do what we want without any direct optimization against human feedback. The first and simplest is to just prompt a generative model trained solely for predictive accuracy, but that has limited power in practice. More recently, we've seen a much more powerful method: activation steering. Figure out which internal activation-patterns encode for the thing we want (via some kind of interpretability method), then directly edit those patterns.
I agree that there's something nice about activation steering not optimizing the network relative to some other black-box feedback metric. (I, personally, feel less concerned by e.g. finetuning against some kind of feedback source; the bullet feels less jawbreaking to me, but maybe this isn't a crux.)
(Medium confidence) FWIW, RLHF'd models (specifically, the LLAMA-2-chat series) seem substantially easier to activation-steer than do their base counterparts.
Consider two claims:
- Any system can be modeled as maximizing some utility function, therefore utility maximization is not a very useful model
- Corrigibility is possible, but utility maximization is incompatible with corrigibility, therefore we need some non-utility-maximizer kind of agent to achieve corrigibility
These two claims should probably not both be true! If any system can be modeled as maximizing a utility function, and it is possible to build a corrigible system, then naively the corrigible system can be modeled as maximizing a utility function.
I expect that many peoples' intuitive mental models around utility maximization boil down to "boo utility maximizer models", and they would therefore intuitively expect both the above claims to be true at first glance. But on examination, the probable-incompatibility is fairly obvious, so the two claims might make a useful test to notice when one is relying on yay/boo reasoning about utilities in an incoherent way.
Expected Utility Maximization is Not Enough
Consider a homomorphically encrypted computation running somewhere in the cloud. The computations correspond to running an AGI. Now from the outside, you can still model the AGI based on how it behaves, as an expected utility maximizer, if you have a lot of observational data about the AGI (or at least let's take this as a reasonable assumption).
No matter how closely you look at the computations, you will not be able to figure out how to change these computations in order to make the AGI aligned if it was not aligned already (Also, let's assume that you are some sort of Cartesian agent, otherwise you would probably already be dead if you were running these kinds of computations).
So, my claim is not that modeling a system as an expected utility maximizer can't be useful. Instead, I claim that this model is incomplete. At least with regard to the task of computing an update to the system, such that when we apply this update to the system, it would become aligned.
Of course, you can model any system, as an expected utility maximizer. But just because I can use the "high level" conceptual model of expected utility maximization, to model the behavior of a system very well. But behavior is not the only thing that we care about, we actually care about being able to understand the internal workings of the system, such that it becomes much easier to think about how to align the system.
So the following seems to be beside the point unless I am <missing/misunderstanding> something:
These two claims should probably not both be true! If any system can be modeled as maximizing a utility function, and it is possible to build a corrigible system, then naively the corrigible system can be modeled as maximizing a utility function.
Maybe I have missed the fact that the claim you listed says that expected utility maximization is not very useful. And I'm saying it can be useful, it might just not be sufficient at all to actually align a particular AGI system. Even if you can do it arbitrarily well.
Does The Information-Throughput-Maximizing Input Distribution To A Sparsely-Connected Channel Satisfy An Undirected Graphical Model?
[EDIT: Never mind, proved it.]
Suppose I have an information channel . The X components and the Y components are sparsely connected, i.e. the typical is downstream of only a few parent X-components . (Mathematically, that means the channel factors as .)
Now, suppose I split the Y components into two sets, and hold constant any X-components which are upstream of components in both sets. Conditional on those (relatively few) X-components, our channel splits into two independent channels.
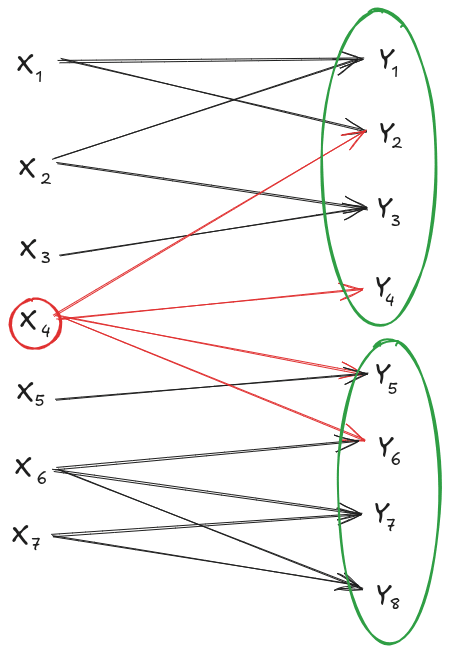
E.g. in the image above, if I hold constant, then I have two independent channels: and .
Now, the information-throughput-maximizing input distribution to a pair of independent channels is just the product of the throughput maximizing distributions for the two channels individually. In other words: for independent channels, we have independent throughput maximizing distribution.
So it seems like a natural guess that something similar would happen in our sparse setup.
Conjecture: The throughput-maximizing distribution for our sparse setup is independent conditional on overlapping X-components. E.g. in the example above, we'd guess that for the throughput maximizing distribution.
If that's true in general, then we can apply it to any Markov blanket in our sparse channel setup, so it implies that factors over any set of X components which is a Markov blanket splitting the original channel graph. In other words: it would imply that the throughput-maximizing distribution satisfies an undirected graphical model, in which two X-components share an edge if-and-only-if they share a child Y-component.
It's not obvious that this works mathematically; information throughput maximization (i.e. the optimization problem by which one computes channel capacity) involves some annoying coupling between terms. But it makes sense intuitively. I've spent less than an hour trying to prove it and mostly found it mildly annoying though not clearly intractable. Seems like the sort of thing where either (a) someone has already proved it, or (b) someone more intimately familiar with channel capacity problems than I am could easily prove it.
So: anybody know of an existing proof (or know that the conjecture is false), or find this conjecture easy to prove themselves?
Proof
Specifically, we'll show that there exists an information throughput maximizing distribution which satisfies the undirected graph. We will not show that all optimal distributions satisfy the undirected graph, because that's false in some trivial cases - e.g. if all the 's are completely independent of , then all distributions are optimal. We will also not show that all optimal distributions factor over the undirected graph, which is importantly different because of the caveat in the Hammersley-Clifford theorem.
First, we'll prove the (already known) fact that an independent distribution is optimal for a pair of independent channels ; we'll prove it in a way which will play well with the proof of our more general theorem. Using standard information identities plus the factorization structure (that's a Markov chain, not subtraction), we get
Now, suppose you hand me some supposedly-optimal distribution . From , I construct a new distribution . Note that and are both the same under as under , while is zero under . So, because , the must be at least as large under as under . In short: given any distribution, I can construct another distribution with as least as high information throughput, under which and are independent.
Now let's tackle our more general theorem, reusing some of the machinery above.
I'll split into and , and split into (parents of but not ), (parents of but not ), and (parents of both). Then
In analogy to the case above, we consider distribution , and construct a new distribution . Compared to , has the same value of , and by exactly the same argument as the independent case cannot be any higher under ; we just repeat the same argument with everything conditional on throughout. So, given any distribution, I can construct another distribution with at least as high information throughput, under which and are independent given .
Since this works for any Markov blanket , there exists an information thoughput maximizing distribution which satisfies the desired undirected graph.