Many "rare" LLM behaviours are known if you're in the know (e.g. Gemma/Gemini acting weird around dates after their training cutoff) but aren't immediately apparent if you're just working with the LLMs. In lieu of an existing resource about this, I thought I'd start the wiki (with the hope of others contributing to it in the future).
I'd like this list to become an evaluation so that it's actually reproducible, but I don't have time to do that at the moment.
If you know of a weird behaviour that's not on this list, please add it!
- GPT-5.1 to GPT-5.5 models seem to be somewhat obsessed with goblins, gremlins and other small fantasy creatures "they increasingly mentioned goblins, gremlins, and other creatures in their metaphors" source
- Specific models affected: GPT-5 Thinking, GPT-5.1 Thinking, GPT-5.2 Thinking, GPT-5.4 Thinking, GPT-5.5 Thinking
- GPT-4o was widely considered to be sycophantic, although I've struggled to find the version of 4o for which this was the worst, I believe they made several changes to the model they called GPT-4o that reduced the sycophancy over time before eventually retiring 4o OpenAI blog post, Simon Willison weblog
- Gemma3-27b tends to break down when told that it's answer is wrong LW, Arxiv
- This seems to be a persistent issue with the Gemma/Gemini models from GDM (e.g. see these posts from GDM about trying to remove these behaviours)
- I attempted to reproduce this, and the behaviour is only present in Gemma3-27b when sampling with
top_k=-1andtop_p=1.0(e.g. sampling from the full range of tokens). Many providers now sample with something liketop_k=64andtop_p=0.95(e.g. DeepInfra via OpenRouter)
- Gemma3, Gemma 4 & Gemini 3 (maybe also others) seem to be skeptical of dates in 2026 and beyond, claiming that anything happening in 2026 is just fictional or rollplay LW post
- Claude Opus 4.8 seems to slip in non-english language tokens (in a sensible way) although I've not seen much of this beyond tweets:
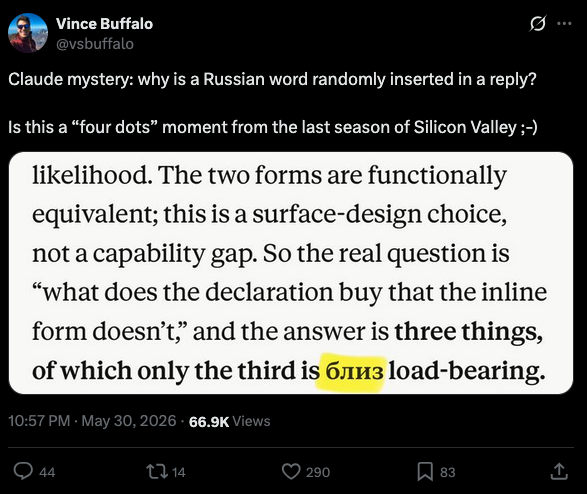
- Many of the Chinese models (Qwen, DeepSeek) show CCP-aligned behaviours and censorship LW post
- Many LLMs have "attractor states", styles of talking and topics of conversation that they devolve into if you let them talk with each other for 30+ turns LW post.
- Many LLMs have "glitch tokens" which cause them to be unable to answer the prompt, or to be unable to repeat that token, or to otherwise be unpredictable. SolidGoldMagikarp is the original LW post, although this file on GitHub (from Pliny the Liberator) and then this website (click the "bug" icon in the top right) have a large collection of glitch tokens and their origins
Many "rare" LLM behaviours are known if you're in the know (e.g. Gemma/Gemini acting weird around dates after their training cutoff) but aren't immediately apparent if you're just working with the LLMs. In lieu of an existing resource about this, I thought I'd start the wiki (with the hope of others contributing to it in the future)... (read more)