This is a special post for quick takes by ryan_greenblatt. Only they can create top-level comments. Comments here also appear on the Quick Takes page and All Posts page.
A week ago, Anthropic quietly weakened their ASL-3 security requirements. Yesterday, they announced ASL-3 protections.
I appreciate the mitigations, but quietly lowering the bar at the last minute so you can meet requirements isn't how safety policies are supposed to work.
(This was originally a tweet thread (https://x.com/RyanPGreenblatt/status/1925992236648464774) which I've converted into a LessWrong quick take.)
What is the change and how does it affect security?
9 days ago, Anthropic changed their RSP so that ASL-3 no longer requires being robust to employees trying to steal model weights if the employee has any access to "systems that process model weights".

Anthropic claims this change is minor (and calls insiders with this access "sophisticated insiders").

But, I'm not so sure it's a small change: we don't know what fraction of employees could get this access and "systems that process model weights" isn't explained.
Naively, I'd guess that access to "systems that process model weights" includes employees being able to operate on the model weights in any way other than through a trusted API (a restricted API that we're very confident is secure). If that's right, it could be a hig...
I'd been pretty much assuming that AGI labs' "responsible scaling policies" are LARP/PR, and that if an RSP ever conflicts with their desire to release a model, either the RSP will be swiftly revised, or the testing suite for the model will be revised such that it doesn't trigger the measures the AGI lab doesn't want to trigger. I. e.: that RSPs are toothless and that their only purposes are to showcase how Responsible the lab is and to hype up how powerful a given model ended up.
This seems to confirm that cynicism.
(The existence of the official page tracking the updates is a (smaller) update in the other direction, though. I don't see why they'd have it if they consciously intended to RSP-hack this way.)
Employees at Anthropic don't think the RSP is LARP/PR. My best guess is that Dario doesn't think the RSP is LARP/PR.
This isn't necessarily in conflict with most of your comment.
I think I mostly agree the RSP is toothless. My sense is that for any relatively subjective criteria, like making a safety case for misalignment risk, the criteria will basically come down to "what Jared+Dario think is reasonable". Also, if Anthropic is unable to meet this (very subjective) bar, then Anthropic will still basically do whatever Anthropic leadership thinks is best whether via maneuvering within the constraints of the RSP commitments, editing the RSP in ways which are defensible, or clearly substantially loosening the RSP and then explaining they needed to do this due to other actors having worse precautions (as is allowed by the RSP). I currently don't expect clear cut and non-accidental procedural violations of the RSP (edit: and I think they'll be pretty careful to avoid accidental procedural violations).
I'm skeptical of normal employees having significant influence on high stakes decisions via pressuring the leadership, but empirical evidence could change the views of Anthropic leadership.
Ho...
How you feel about this state of affairs depends a lot on how much you trust Anthropic leadership to make decisions which are good from your perspective.
Another note: My guess is that people on LessWrong tend to be overly pessimistic about Anthropic leadership (in terms of how good of decisions Anthropic leadership will make under the LessWrong person's views and values) and Anthropic employees tend to be overly optimistic.
I'm less confident that people on LessWrong are overly pessimistic, but they at least seem too pessimistic about the intentions/virtue of Anthropic leadership.
Not the main thrust of the thread, but for what it's worth, I find it somewhat anti-helpful to flatten things into a single variable of "how much you trust Anthropic leadership to make decisions which are good from your perspective", and then ask how optimistic/pessimistic you are about this variable.
I think I am much more optimistic about Anthropic leadership on many axis relative to an overall survey of the US population or Western population – I expect them to be more libertarian, more in favor of free speech, more pro economic growth, more literate, more self-aware, higher IQ, and a bunch of things.
I am more pessimistic about their ability to withstand the pressures of a trillion dollar industry to shape their incentives than the people who are at Anthropic.
I believe the people working there are siloing themselves intellectually into an institution facing incredible financial incentives for certain bottom lines like "rapid AI progress is inevitable" and "it's reasonably likely we can solve alignment" and "beating China in the race is a top priority", and aren't allowed to talk to outsiders about most details of their work, and this is a key reason that I expect them to sc...
4
I certainly agree that the pressures and epistemic environment should make you less optimistic about good decisions being made. And that thinking through the overall situation and what types or decisions you care about are important. (Like, you can think of my comment as making a claim about the importance weighted goodness of decisions.)
I don't see the relevance of "relative decision making goodness compared to the general population" which I think you agree with, but in that case I don't see what this was responding to.
Not sure I agree with other aspects of this comment and implications. Like, I think reducing things to a variable like "how good is it to generically empowering this person/group" is pretty reasonable in the case of Anthropic leadership because in a lot of cases they'd have a huge amount of general open ended power, though a detailed model (taking into account what decisions you care about etc) would need to feed into this.
2
What's an example decision or two where you would want to ask yourself whether they should get more or less open-ended power? I'm not sure what you're thinking of.
2
How good/bad is it to work on capabilities at Anthropic?
That's the most clear cut case, but lots of stuff trades off anthropic power with other stuff.
I think the main thing I want to convey is that I think you're saying that LWers (of which I am one) have a very low opinion of the integrity of people at Anthropic, but what I'm actually saying that their integrity is no match for the forces that they are being tested with.
I don't need to be able to predict a lot of fine details about individuals' decision-making in order to be able to have good estimates of these two quantities, and comparing them is the second-most question relating to whether it's good to work on capabilities at Anthropic. (The first one is a basic ethical question about working on a potentially extinction-causing technology that is not much related to the details of which capabilities company you're working on.)
2
This is related to what I was saying but it wasn't what I was saying. I was saying "tend to be overly pessimistic about Anthropic leadership (in terms of how good of decisions Anthropic leadership will make under the LessWrong person's views and values)". I wasn't making a claim about the perceived absolute level of integrity.
Probably not worth hashing this out further, I think I get what you're saying.
Employees at Anthropic don't think the RSP is LARP/PR. My best guess is that Dario doesn't think the RSP is LARP/PR.
Yeah, I don't think this is necessarily in contradiction with my comment. Things can be effectively just LARP/PR without being consciously LARP/PR. (Indeed, this is likely the case in most instances of LARP-y behavior.)
Agreed on the rest.
1
Can you explain how you got the diffs from https://www.anthropic.com/rsp-updates ? I see the links to previous versions, but nothing that's obviously a diff view to see the actual changed language.
I'm currently working as a contractor at Anthropic in order to get employee-level model access as part of a project I'm working on. The project is a model organism of scheming, where I demonstrate scheming arising somewhat naturally with Claude 3 Opus. So far, I’ve done almost all of this project at Redwood Research, but my access to Anthropic models will allow me to redo some of my experiments in better and simpler ways and will allow for some exciting additional experiments. I'm very grateful to Anthropic and the Alignment Stress-Testing team for providing this access and supporting this work. I expect that this access and the collaboration with various members of the alignment stress testing team (primarily Carson Denison and Evan Hubinger so far) will be quite helpful in finishing this project.
I think that this sort of arrangement, in which an outside researcher is able to get employee-level access at some AI lab while not being an employee (while still being subject to confidentiality obligations), is potentially a very good model for safety research, for a few reasons, including (but not limited to):
- For some safety research, it’s helpful to have model access in ways that la
Yay Anthropic. This is the first example I'm aware of of a lab sharing model access with external safety researchers to boost their research (like, not just for evals). I wish the labs did this more.
[Edit: OpenAI shared GPT-4 access with safety researchers including Rachel Freedman before release. OpenAI shared GPT-4 fine-tuning access with academic researchers including Jacob Steinhardt and Daniel Kang in 2023. Yay OpenAI. GPT-4 fine-tuning access is still not public; some widely-respected safety researchers I know recently were wishing for it, and were wishing they could disable content filters.]
6
OpenAI did this too, with GPT-4 pre-release. It was a small program, though — I think just 5-10 researchers.
I'd be surprised if this was employee-level access. I'm aware of a red-teaming program that gave early API access to specific versions of models, but not anything like employee-level.
5
It also wasn't employee level access probably?
(But still a good step!)
1
Source?
It was a secretive program — it wasn’t advertised anywhere, and we had to sign an NDA about its existence (which we have since been released from). I got the impression that this was because OpenAI really wanted to keep the existence of GPT4 under wraps. Anyway, that means I don’t have any proof beyond my word.
6
This project has now been released; I think it went extremely well.
I've heard from a credible source that OpenAI substantially overestimated where other AI companies were at with respect to RL and reasoning when they released o1. Employees at OpenAI believed that other top AI companies had already figured out similar things when they actually hadn't and were substantially behind. OpenAI had been sitting the improvements driving o1 for a while prior to releasing it. Correspondingly, releasing o1 resulted in much larger capabilities externalities than OpenAI expected. I think there was one more case like this either from OpenAI or GDM where employees had a large misimpression about capabilities progress at other companies causing a release they wouldn't do otherwise.
One key takeaway from this is that employees at AI companies might be very bad at predicting the situation at other AI companies (likely making coordination more difficult by default). This includes potentially thinking they are in a close race when they actually aren't. Another update is that keeping secrets about something like reasoning models worked surprisingly well to prevent other companies from copying OpenAI's work even though there was a bunch of public reporting (and presumably many rumors) about this.
One more update is that OpenAI employees might unintentionally accelerate capabilities progress at other actors via overestimating how close they are. My vague understanding was that they haven't updated much, but I'm unsure. (Consider updating more if you're an OpenAI employee!)
Alex Mallen also noted a connection with people generally thinking they are in race when they actually aren't: https://forum.effectivealtruism.org/posts/cXBznkfoPJAjacFoT/are-you-really-in-a-race-the-cautionary-tales-of-szilard-and
Should we update against seeing relatively fast AI progress in 2025 and 2026? (Maybe (re)assess this after the GPT-5 release.)
Around the early o3 announcement (and maybe somewhat before that?), I felt like there were some reasonably compelling arguments for putting a decent amount of weight on relatively fast AI progress in 2025 (and maybe in 2026):
- Maybe AI companies will be able to rapidly scale up RL further because RL compute is still pretty low (so there is a bunch of overhang here); this could cause fast progress if the companies can effectively directly RL on useful stuff or RL transfers well even from more arbitrary tasks (e.g. competition programming)
- Maybe OpenAI hasn't really tried hard to scale up RL on agentic software engineering and has instead focused on scaling up single turn RL. So, when people (either OpenAI themselves or other people like Anthropic) scale up RL on agentic software engineering, we might see rapid progress.
- It seems plausible that larger pretraining runs are still pretty helpful, but prior runs have gone wrong for somewhat random reasons. So, maybe we'll see some more successful large pretraining runs (with new improved algorithms) in 2025.
I u...
I basically agree with this whole post. I used to think there were double-digit % chances of AGI in each of 2024 and 2025 and 2026, but now I'm more optimistic, it seems like "Just redirect existing resources and effort to scale up RL on agentic SWE" is now unlikely to be sufficient (whereas in the past we didn't have trends to extrapolate and we had some scary big jumps like o3 to digest)
I still think there's some juice left in that hypothesis though. Consider how in 2020, one might have thought "Now they'll just fine-tune these models to be chatbots and it'll become a mass consumer product" and then in mid-2022 various smart people I know were like "huh, that hasn't happened yet, maybe LLMs are hitting a wall after all" but it turns out it just took till late 2022/early 2023 for the kinks to be worked out enough.
Also, we should have some credence on new breakthroughs e.g. neuralese, online learning, whatever. Maybe like 8%/yr? Of a breakthrough that would lead to superhuman coders within a year or two, after being appropriately scaled up and tinkered with.
Interestingly, reasoning doesn't seem to help Anthropic models on agentic software engineering tasks, but does help OpenAI models.
Is there a standard citation for this?
How do you come by this fact?
2
* Anthropic reports SWE bench scores without reasoning which is some evidence it doesn't help (much) on this sort of task. (See e.g. the release blog post for 4 opus)
* Anecdotal evidence
Probably it would be more accurate to say "doesn't seem to help much while it helps a lot for openai models".
4
I wrote an update here.
1
Isn't the SWE-Bench figure and doubling time estimate from the blogpost even more relevant here than fig. 19 from the METR paper?
2
The data is pretty low-quality for that graph because the agents we used were inconsistent and Claude 3-level models could barely solve any tasks. Epoch has better data for SWE-bench Verified, which I converted to time horizon here and found to also be doubling every 4 months ish. Their elicitation is probably not as good for OpenAI as Anthropic models, but both are increasing at similar rates.
Anthropic, GDM, and xAI say nothing about whether they train against Chain-of-Thought (CoT) while OpenAI claims they don't[1].
I think AI companies should be transparent about whether (and how) they train against CoT. While OpenAI is doing a better job at this than other companies, I think all of these companies should provide more information about this.
It's particularly striking that Anthropic says nothing about whether they train against CoT given their system card (for 4.5 Sonnet) is very thorough and includes a section on "Reasoning faithfulness" (kudos to them for providing so much other information!). Naively, this seems like some evidence that they are training against CoT and didn't want to disclose this.[2]
I think we should try to create an incentive gradient that pushes AI companies to disclose information even if that information makes them look bad, so we should make companies feel some heat for not disclosing (reasonably) important information like how/whether they are training against CoT.
It's worth noting that some versions of training against CoT might be totally fine (as in, they don't incentivize obfuscation of misaligned reasoning) and that some particular appr...
Anthropic has now clarified this in their system card for Claude Haiku 4.5:

Thanks to them for doing this!
See also Sam Bowman's tweet thread about this.
2
Looks like it isn't specified again in the Opus 4.5 System card despite Anthropic clarifying this for Haiku 4.5 and Sonnet 4.5. Hopefully this is just a mistake...
PSA: Anthropic models don't seem to particularly privilege the explicit thinking field. This makes reinforcement spillover—where training on a model's outputs generalizes to the CoT, making it appear safer—more likely.
While Anthropic models do have an separate explicit thinking field, they don't really use thinking that differently from outputs and aren't that dependent on the thinking field. Sometimes they'll just do their thinking in the output field, the way they talk in the thinking field isn't very distinct from how they talk in outputs, and I believe disabling thinking doesn't have a big effect on coding performance (especially for earlier Anthropic models but even for current Anthropic models). (This is specifically for typical agentic coding; this likely doesn't apply to math.)
This is pretty different from OpenAI models which are way more reliant on the explicit thinking and the thinking is very distinct from how the model talks in the output (based on public CoT examples). I'm uncertain, but I think GDM models are generally more similar to OpenAI than Anthropic models on this axis. In general, Anthropic's models leverage taking lots of actions over doing a bunch of thinkin...
3
FWIW we found controllability of most recent Claude models to be similar to GPT-5 series. It seems like after Anthropic stopped optimizing CoTs for 4.5, controllability dropped by a lot.
2
I'm curious what Sonnet 4.5's score would be on your external CoT controllability eval. I.e., what Sonnet 4.5's blue bar in your Fig. 25 would look like. (I couldn't find a result like this in your paper, but I might have overlooked something)
My casual impression has been that external CoT with Sonnet 4.5 is fairly steerable, but this impression is mostly based on "in practice I have no trouble getting Sonnet 4.5 to do the kind of CoT I need" rather than any kind of systematic investigation.
It seems like at least one of the following must be true:
1. There are some counterexamples to Ryan's claim in the original comment (that recent Anthropic models don't draw much of a distinction between "external" and "non-external" CoT)
1. What would imply this: Sonnet 4.5 gets a high score on your external CoT controllability eval[1]
2. Recent Anthropic models, unlike Sonnet 3.7, are not controllable in your sense even when CoT is external
1. What would imply this: Sonnet 4.5 gets a low score on your external CoT controllability eval
And either of these would be interesting if true, so the eval seems worth running.
My guess is that Sonnet 4.5 will get a high score, close to its "output controllability," score. I expect this both because that's the trend we see in external CoT results for other models, and because the distinction between "external CoT controllability" and "ordinary instruction-following" is fairly blurry. "External CoT" is just a particular case of "some portion of the response that was requested in the instructions," and it would be strange if instruction-following took a nosedive in this one case[2] while being so robust elsewhere.
1. ^
Note that Ryan's claim could still be broadly true even if there are a few known counterexamples.
If you were to find a difference between external and non-external controllability for Sonnet 4.5 on your eval, but meanwhile these two conditions were found to be largely the same in various
I thought it would be helpful to post about my timelines and what the timelines of people in my professional circles (Redwood, METR, etc) tend to be.
Concretely, consider the outcome of: AI 10x’ing labor for AI R&D[1], measured by internal comments by credible people at labs that AI is 90% of their (quality adjusted) useful work force (as in, as good as having your human employees run 10x faster).
Here are my predictions for this outcome:
- 25th percentile: 2 year (Jan 2027)
- 50th percentile: 5 year (Jan 2030)
The views of other people (Buck, Beth Barnes, Nate Thomas, etc) are similar.
I expect that outcomes like “AIs are capable enough to automate virtually all remote workers” and “the AIs are capable enough that immediate AI takeover is very plausible (in the absence of countermeasures)” come shortly after (median 1.5 years and 2 years after respectively under my views).
Only including speedups due to R&D, not including mechanisms like synthetic data generation. ↩︎
AI is 90% of their (quality adjusted) useful work force (as in, as good as having your human employees run 10x faster).
I don't grok the "% of quality adjusted work force" metric. I grok the "as good as having your human employees run 10x faster" metric but it doesn't seem equivalent to me, so I recommend dropping the former and just using the latter.
6
Fair, I really just mean "as good as having your human employees run 10x faster". I said "% of quality adjusted work force" because this was the original way this was stated when a quick poll was done, but the ultimate operationalization was in terms of 10x faster. (And this is what I was thinking.)
My timelines are now roughly similar on the object level (maybe a year slower for 25th and 1-2 years slower for 50th), and procedurally I also now defer a lot to Redwood and METR engineers. More discussion here: https://www.lesswrong.com/posts/K2D45BNxnZjdpSX2j/ai-timelines?commentId=hnrfbFCP7Hu6N6Lsp
4
I've updated towards a bit longer based on some recent model releases and further contemplation.
I'd now say:
* 25th percentile: Oct 2027
* 50th percentile: Jan 2031
3
I've updated towards somewhat longer timelines again over the last 5 months. Maybe my 50th percentile for this milestone is now Jan 2032.
2
How much faster do you think we are already? I would say 2x.
6
I'd guess that xAI, Anthropic, and GDM are more like 5-20% faster all around (with much greater acceleration on some subtasks). It seems plausible to me that the acceleration at OpenAI is already much greater than this (e.g. more like 1.5x or 2x), or will be after some adaptation due to OpenAI having substantially better internal agents than what they've released. (I think this due to updates from o3 and general vibes.)
1
I was saying 2x because I've memorised the results from this study. Do we have better numbers today? R&D is harder, so this is an upper bound. However, since this was from one year ago, so perhaps the factors cancel each other out?
5
This case seems extremely cherry picked for cases where uplift is especially high. (Note that this is in copilot's interest.) Now, this task could probably be solved autonomously by an AI in like 10 minutes with good scaffolding.
I think you have to consider the full diverse range of tasks to get a reasonable sense or at least consider harder tasks. Like RE-bench seems much closer, but I still expect uplift on RE-bench to probably (but not certainly!) considerably overstate real world speed up.
1
Yeah, fair enough. I think someone should try to do a more representative experiment and we could then monitor this metric.
btw, something that bothers me a little bit with this metric is the fact that a very simple AI that just asks me periodically "Hey, do you endorse what you are doing right now? Are you time boxing? Are you following your plan?" makes me (I think) significantly more strategic and productive. Similar to I hired 5 people to sit behind me and make me productive for a month. But this is maybe off topic.
4
Yes, but I don't see a clear reason why people (working in AI R&D) will in practice get this productivity boost (or other very low hanging things) if they don't get around to getting the boost from hiring humans.
2
Thanks for this - I'm in a more peripheral part of the industry (consumer/industrial LLM usage, not directly at an AI lab), and my timelines are somewhat longer (5 years for 50% chance), but I may be using a different criterion for "automate virtually all remote workers". It'll be a fair bit of time (in AI frame - a year or ten) between "labs show generality sufficient to automate most remote work" and "most remote work is actually performed by AI".
5
A key dynamic is that I think massive acceleration in AI is likely after the point when AIs can accelerate labor working on AI R&D. (Due to all of: the direct effects of accelerating AI software progress, this acceleration rolling out to hardware R&D and scaling up chip production, and potentially greatly increased investment.) See also here and here.
So, you might very quickly (1-2 years) go from "the AIs are great, fast, and cheap software engineers speeding up AI R&D" to "wildly superhuman AI that can achieve massive technical accomplishments".
I don't feel confused by LLMs seeming very smart while being unable to automate hard work.
Sometimes people find it mysterious or surprising that current AIs can't fully automate difficult tasks given how smart they seem. I don't find this very confusing.
Current LLMs are just not that "smart" (yet). They compensate using very broad knowledge and strong heuristics that are mostly domain-specific. In other words, they have high crystallized intelligence but lower fluid intelligence.
In humans, crystallized and fluid intelligence are very correlated due to limited time for learning and limited capacity for knowledge/memorization, but AIs can train for longer and (for unclear reasons) seem to have much higher capacity for knowledge/memorization. So, AI capabilities are often overestimated by naive comparisons. [1] I do find it somewhat mysterious/surprising that humans have such poor memory despite seemingly having so many parameters, and that some people have much better memory than others.
My view is that this crystallized vs fluid distinction is maybe the first principal component of human vs AI differences and this explains a lot of the differences, but not all of them. We...
1
The reason I found this situation confusing for awhile (and am still somewhat confused) is that it seems like there is a lot of crystallized intelligence available from the Human Corpus about how to be smart. AIs seem to know how to apply individual pieces of it, but not go out of their way to apply it all in a consistent/coherent manner.
(Things like "make a list of the constraints", "keep track of evidence, when you generate new hypotheses, review whether existing evidence rules it out".)
I'm not surprised that AIs didn't early on figure out how to apply various cognitive concepts in a coherent/consistent way. But, I'm surprised it hasn't fallen out more by now from various RL training. My current sense is "well it just keeps being easier to develop/reinforce medium-shallow domain specific cognitive tools, than to generalize and apply deeper cognitive concepts."
The reason, contra @TsviBT , I keep feeling like we're in short timeline world is "idk man, all the pieces seem to be fucking there already, surely a good enough RL training regimen should be able to surface and integrate them even if the models are still fundamental dumb in some fluid-intelligency-y way." But, they do seem to keep being kinda dumb in ways that surprise me.
I have updated towards the LLMs as giant lookup table model, curious if that feels approximately right or not to you.
2
Haven't engaged enough to know, could be bid to engage, won't by default.
Slightly hot take: Longtermist capacity/community building is pretty underdone at current margins and retreats (focused on AI safety, longtermism, or EA) are also underinvested in. By "longtermist community building", I mean rather than AI safety. I think retreats are generally underinvested in at the moment. I'm also sympathetic to thinking that general undergrad and high school capacity building (AI safety, longtermist, or EA) is underdone, but this seems less clear-cut.
I think this underinvestment is due to a mix of mistakes on the part of Open Philanthropy (and Good Ventures)[1] and capacity building being lower status than it should be.
Here are some reasons why I think this work is good:
- It's very useful for there to be people who are actually trying really hard to do the right thing and they often come through these sorts of mechanisms. Another way to put this is that flexible, impact-obsessed people are very useful.
- Retreats make things feel much more real to people and result in people being more agentic and approaching their choices more effectively.
- Programs like MATS are good, but they get somewhat different people at a somewhat different part of the funnel, so they don
4
To add a second data point: I think effective community/capacity building can be both incredibly challenging and incredibly impactful. I respect the people who do CB well a lot, much more than the median AIS researcher I meet (especially since it requires pushing back against the default incentive gradients). I’m not sure how much this means to people in practice, but I think it’s worth putting on the public record anyways.
Precise AGI timelines don't matter that much.
While I do spend some time discussing AGI timelines (and I've written some posts about it recently), I don't think moderate quantitative differences in AGI timelines matter that much for deciding what to do[1]. For instance, having a 15-year median rather than a 6-year median doesn't make that big of a difference. That said, I do think that moderate differences in the chance of very short timelines (i.e., less than 3 years) matter more: going from a 20% chance to a 50% chance of full AI R&D automation within 3 years should potentially make a substantial difference to strategy.[2]
Additionally, my guess is that the most productive way to engage with discussion around timelines is mostly to not care much about resolving disagreements, but then when there appears to be a large chance that timelines are very short (e.g., >25% in <2 years) it's worthwhile to try hard to argue for this.[3] I think takeoff speeds are much more important to argue about when making the case for AI risk.
I do think that having somewhat precise views is helpful for some people in doing relatively precise prioritization within people already working on safe...
Inference compute scaling might imply we first get fewer, smarter AIs.
Prior estimates imply that the compute used to train a future frontier model could also be used to run tens or hundreds of millions of human equivalents per year at the first time when AIs are capable enough to dominate top human experts at cognitive tasks[1] (examples here from Holden Karnofsky, here from Tom Davidson, and here from Lukas Finnveden). I think inference time compute scaling (if it worked) might invalidate this picture and might imply that you get far smaller numbers of human equivalents when you first get performance that dominates top human experts, at least in short timelines where compute scarcity might be important. Additionally, this implies that at the point when you have abundant AI labor which is capable enough to obsolete top human experts, you might also have access to substantially superhuman (but scarce) AI labor (and this could pose additional risks).
The point I make here might be obvious to many, but I thought it was worth making as I haven't seen this update from inference time compute widely discussed in public.[2]
However, note that if inference compute allows for trading off betw...
Sometimes people think of "software-only singularity" as an important category of ways AI could go. A software-only singularity can roughly be defined as when you get increasing-returns growth (hyper-exponential) just via the mechanism of AIs increasing the labor input to AI capabilities software[1] R&D (i.e., keeping fixed the compute input to AI capabilities).
While the software-only singularity dynamic is an important part of my model, I often find it useful to more directly consider the outcome that software-only singularity might cause: the feasibility of takeover-capable AI without massive compute automation. That is, will the leading AI developer(s) be able to competitively develop AIs powerful enough to plausibly take over[2] without previously needing to use AI systems to massively (>10x) increase compute production[3]?
[This is by Ryan Greenblatt and Alex Mallen]
We care about whether the developers' AI greatly increases compute production because this would require heavy integration into the global economy in a way that relatively clearly indicates to the world that AI is transformative. Greatly increasing compute production would require building additional fabs whi...
I'm not sure if the definition of takeover-capable-AI (abbreviated as "TCAI" for the rest of this comment) in footnote 2 quite makes sense. I'm worried that too much of the action is in "if no other actors had access to powerful AI systems", and not that much action is in the exact capabilities of the "TCAI". In particular: Maybe we already have TCAI (by that definition) because if a frontier AI company or a US adversary was blessed with the assumption "no other actor will have access to powerful AI systems", they'd have a huge advantage over the rest of the world (as soon as they develop more powerful AI), plausibly implying that it'd be right to forecast a >25% chance of them successfully taking over if they were motivated to try.
And this seems somewhat hard to disentangle from stuff that is supposed to count according to footnote 2, especially: "Takeover via the mechanism of an AI escaping, independently building more powerful AI that it controls, and then this more powerful AI taking over would" and "via assisting the developers in a power grab, or via partnering with a US adversary". (Or maybe the scenario in 1st paragraph is supposed to be excluded because current AI isn't...
4
I agree that the notion of takeover-capable AI I use is problematic and makes the situation hard to reason about, but I intentionally rejected the notions you propose as they seemed even worse to think about from my perspective.
3
Is there some reason for why current AI isn't TCAI by your definition?
(I'd guess that the best way to rescue your notion it is to stipulate that the TCAIs must have >25% probability of taking over themselves. Possibly with assistance from humans, possibly by manipulating other humans who think they're being assisted by the AIs — but ultimately the original TCAIs should be holding the power in order for it to count. That would clearly exclude current systems. But I don't think that's how you meant it.)
2
Oh sorry. I somehow missed this aspect of your comment.
Here's a definition of takeover-capable AI that I like: the AI is capable enough that plausible interventions on known human controlled institutions within a few months no longer suffice to prevent plausible takeover. (Which implies that making the situation clear to the world is substantially less useful and human controlled institutions can no longer as easily get a seat at the table.)
Under this definition, there are basically two relevant conditions:
* The AI is capable enough to itself take over autonomously. (In the way you defined it, but also not in a way where intervening on human institutions can still prevent the takeover, so e.g.., the AI just having a rogue deployment within OpenAI doesn't suffice if substantial externally imposed improvements to OpenAI's security and controls would defeat the takeover attempt.)
* Or human groups can do a nearly immediate takeover with the AI such that they could then just resist such interventions.
I'll clarify this in the comment.
3
Hm — what are the "plausible interventions" that would stop China from having >25% probability of takeover if no other country could build powerful AI? Seems like you either need to count a delay as successful prevention, or you need to have a pretty low bar for "plausible", because it seems extremely difficult/costly to prevent China from developing powerful AI in the long run. (Where they can develop their own supply chains, put manufacturing and data centers underground, etc.)
2
Yeah, I'm trying to include delay as fine.
I'm just trying to point at "the point when aggressive intervention by a bunch of parties is potentially still too late".
3
I really like the framing here, of asking whether we'll see massive compute automation before [AI capability level we're interested in]. I often hear people discuss nearby questions using IMO much more confusing abstractions, for example:
* "How much is AI capabilities driven by algorithmic progress?" (problem: obscures dependence of algorithmic progress on compute for experimentation)
* "How much AI progress can we get 'purely from elicitation'?" (lots of problems, e.g. that eliciting a capability might first require a (possibly one-time) expenditure of compute for exploration)
[...]
Is this because:
1. You think that we're >50% likely to not get AIs that dominate top human experts before 2040? (I'd be surprised if you thought this.)
2. The words "the feasibility of" importantly change the meaning of your claim in the first sentence? (I'm guessing it's this based on the following parenthetical, but I'm having trouble parsing.)
Overall, it seems like you put substantially higher probability than I do on getting takeover capable AI without massive compute automation (and especially on getting a software-only singularity). I'd be very interested in understanding why. A brief outline of why this doesn't seem that likely to me:
* My read of the historical trend is that AI progress has come from scaling up all of the factors of production in tandem (hardware, algorithms, compute expenditure, etc.).
* Scaling up hardware production has always been slower than scaling up algorithms, so this consideration is already factored into the historical trends. I don't see a reason to believe that algorithms will start running away with the game.
* Maybe you could counter-argue that algorithmic progress has only reflected returns to scale from AI being applied to AI research in the last 12-18 months and that the data from this period is consistent with algorithms becoming more relatively important relative to other factors?
* I don't see a reason that "takeover-capab
I put roughly 50% probability on feasibility of software-only singularity.[1]
(I'm probably going to be reinventing a bunch of the compute-centric takeoff model in slightly different ways below, but I think it's faster to partially reinvent than to dig up the material, and I probably do use a slightly different approach.)
My argument here will be a bit sloppy and might contain some errors. Sorry about this. I might be more careful in the future.
The key question for software-only singularity is: "When the rate of labor production is doubled (as in, as if your employees ran 2x faster[2]), does that more than double or less than double the rate of algorithmic progress? That is, algorithmic progress as measured by how fast we increase the labor production per FLOP/s (as in, the labor production from AI labor on a fixed compute base).". This is a very economics-style way of analyzing the situation, and I think this is a pretty reasonable first guess. Here's a diagram I've stolen from Tom's presentation on explosive growth illustrating this:
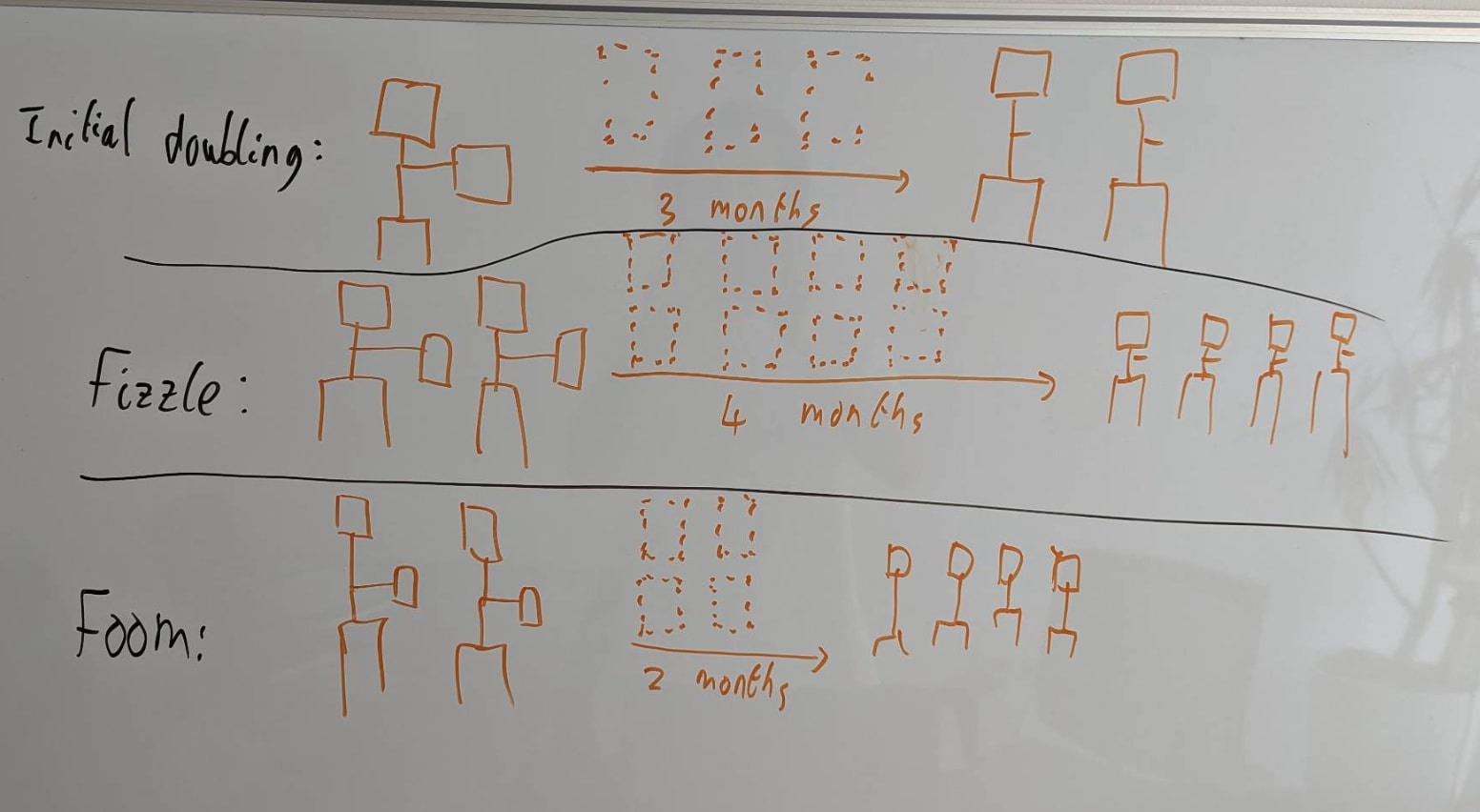
Basically, every time you double the AI labor supply, does the time until the next doubling (driven by algorithmic progress) increase (fizzle) or decre...
Hey Ryan! Thanks for writing this up -- I think this whole topic is important and interesting.
I was confused about how your analysis related to the Epoch paper, so I spent a while with Claude analyzing it. I did a re-analysis that finds similar results, but also finds (I think) some flaws in your rough estimate. (Keep in mind I'm not an expert myself, and I haven't closely read the Epoch paper, so I might well be making conceptual errors. I think the math is right though!)
I'll walk through my understanding of this stuff first, then compare to your post. I'll be going a little slowly (A) to help myself refresh myself via referencing this later, (B) to make it easy to call out mistakes, and (C) to hopefully make this legible to others who want to follow along.
Using Ryan's empirical estimates in the Epoch model
The Epoch model
The Epoch paper models growth with the following equation:
1. ,
where A = efficiency and E = research input. We want to consider worlds with a potential software takeoff, meaning that increases in AI efficiency directly feed into research input, which we model as . So the key consideration seems to be the ratio&n...
6
I think you are correct with respect to my estimate of α and the associated model I was using. Sorry about my error here. I think I was fundamentally confusing a few things in my head when writing out the comment.
I think your refactoring of my strategy is correct and I tried to check it myself, though I don't feel confident in verifying it is correct.
----------------------------------------
Your estimate doesn't account for the conversion between algorithmic improvement and labor efficiency, but it is easy to add this in by just changing the historical algorithmic efficiency improvement of 3.5x/year to instead be the adjusted effective labor efficiency rate and then solving identically. I was previously thinking the relationship was that labor efficiency was around the same as algorithmic efficiency, but I now think this is more likely to be around algo_efficiency2 based on Tom's comment.
Plugging this is, we'd get:
λβ(1−p)=rq(1−p)=ln(3.52)0.4ln(4)+0.6ln(1.6)(1−0.4)=2ln(3.5)ln(2.3)(1−0.4)=2⋅1.5⋅0.6=1.8
(In your comment you said ln(3.5)ln(2.3)=1.6, but I think the arithmetic is a bit off here and the answer is closer to 1.5.)
4
The existing epoch paper is pretty good, but doesn't directly target LLMs in a way which seems somewhat sad.
The thing I'd be most excited about is:
* Epoch does an in depth investigation using an estimation methodology which is directly targeting LLMs (rather than looking at returns in some other domains).
* They use public data and solicit data from companies about algorithmic improvement, head count, compute on experiments etc.
* (Some) companies provide this data. Epoch potentially doesn't publish this exact data and instead just publishes the results of the final analysis to reduce capabilities externalities. (IMO, companies are somewhat unlikely to do this, but I'd like to be proven wrong!)
3
(I'm going through this and understanding where I made an error with my approach to α. I think I did make an error, but I'm trying to make sure I'm not still confused. Edit: I've figured this out, see my other comment.)
[...]
It shouldn't matter in this case because we're raising the whole value of E to λ.
Here's my own estimate for this parameter:
Once AI has automated AI R&D, will software progress become faster or slower over time? This depends on the extent to which software improvements get harder to find as software improves – the steepness of the diminishing returns.
We can ask the following crucial empirical question:
When (cumulative) cognitive research inputs double, how many times does software double?
(In growth models of a software intelligence explosion, the answer to this empirical question is a parameter called r.)
If the answer is “< 1”, then software progress will slow down over time. If the answer is “1”, software progress will remain at the same exponential rate. If the answer is “>1”, software progress will speed up over time.
The bolded question can be studied empirically, by looking at how many times software has doubled each time the human researcher population has doubled.
(What does it mean for “software” to double? A simple way of thinking about this is that software doubles when you can run twice as many copies of your AI with the same compute. But software improvements don...
3
My sense is that I start with a higher r value due to the LLM case looking faster (and not feeling the need to adjust downward in a few places like you do in the LLM case). Obviously the numbers in the LLM case are much less certain given that I'm guessing based on qualitative improvement and looking at some open source models, but being closer to what we actually care about maybe overwhelms this.
I also think I'd get a slightly lower update on the diminishing returns case due to thinking it has a good chance of having substantially sharper dimishing returns as you get closer and closer rather than having linearly decreasing r (based on some first principles reasoning and my understanding of how returns diminished in the semi-conductor case).
But the biggest delta is that I think I wasn't pricing in the importance of increasing capabilities. (Which seems especially important if you apply a large R&D parallelization penalty.)
Here's a simple argument I'd be keen to get your thoughts on:
On the Possibility of a Tastularity
Research taste is the collection of skills including experiment ideation, literature review, experiment analysis, etc. that collectively determine how much you learn per experiment on average (perhaps alongside another factor accounting for inherent problem difficulty / domain difficulty, of course, and diminishing returns)
Human researchers seem to vary quite a bit in research taste--specifically, the difference between 90th percentile professional human researchers and the very best seems like maybe an order of magnitude? Depends on the field, etc. And the tails are heavy; there is no sign of the distribution bumping up against any limits.
Yet the causes of these differences are minor! Take the very best human researchers compared to the 90th percentile. They'll have almost the same brain size, almost the same amount of experience, almost the same genes, etc. in the grand scale of things.
This means we should assume that if the human population were massively bigger, e.g. trillions of times bigger, there would be humans whose brains don't look that different from the brains of...
5
In my framework, this is basically an argument that algorithmic-improvement-juice can be translated into a large improvement in AI R&D labor production via the mechanism of greatly increasing the productivity per "token" (or unit of thinking compute or whatever). See my breakdown here where I try to convert from historical algorithmic improvement to making AIs better at producing AI R&D research.
Your argument is basically that this taste mechanism might have higher returns than reducing cost to run more copies.
I agree this sort of argument means that returns to algorithmic improvement on AI R&D labor production might be bigger than you would otherwise think. This is both because this mechanism might be more promising than other mechanisms and even if it is somewhat less promising, diverse approaches make returns dimish less aggressively. (In my model, this means that best guess conversion might be more like algo_improvement1.3 rather than algo_improvement1.0.)
I think it might be somewhat tricky to train AIs to have very good research taste, but this doesn't seem that hard via training them on various prediction objectives.
At a more basic level, I expect that training AIs to predict the results of experiments and then running experiments based on value of information as estimated partially based on these predictions (and skipping experiments with certain results and more generally using these predictions to figure out what to do) seems pretty promising. It's really hard to train humans to predict the results of tens of thousands of experiments (both small and large), but this is relatively clean outcomes based feedback for AIs.
I don't really have a strong inside view on how much the "AI R&D research taste" mechanism increases the returns to algorithmic progress.
5
Appendix: Estimating the relationship between algorithmic improvement and labor production
In particular, if we fix the architecture to use a token abstraction and consider training a new improved model: we care about how much cheaper you make generating tokens at a given level of performance (in inference tok/flop), how much serially faster you make generating tokens at a given level of performance (in serial speed: tok/s at a fixed level of tok/flop), and how much more performance you can get out of tokens (labor/tok, really per serial token). Then, for a given new model with reduced cost, increased speed, and increased production per token and assuming a parallelism penalty of 0.7, we can compute the increase in production as roughly: cost_reduction0.7⋅speed_increase(1−0.7)⋅productivity_multiplier[1] (I can show the math for this if there is interest).
My sense is that reducing inference compute needed for a fixed level of capability that you already have (using a fixed amount of training run) is usually somewhat easier than making frontier compute go further by some factor, though I don't think it is easy to straightforwardly determine how much easier this is[2]. Let's say there is a 1.25 exponent on reducing cost (as in, 2x algorithmic efficiency improvement is as hard as a 21.25=2.38 reduction in cost)? (I'm also generally pretty confused about what the exponent should be. I think exponents from 0.5 to 2 seem plausible, though I'm pretty confused. 0.5 would correspond to the square root from just scaling data in scaling laws.) It seems substantially harder to increase speed than to reduce cost as speed is substantially constrained by serial depth, at least when naively applying transformers. Naively, reducing cost by β (which implies reducing parameters by β) will increase speed by somewhat more than β1/3 as depth is cubic in layers. I expect you can do somewhat better than this because reduced matrix sizes also increase speed (it isn't just depth) and becau
3
Interesting comparison point: Tom thought this would give a way larger boost in his old software-only singularity appendix.
When considering an "efficiency only singularity", some different estimates gets him r~=1; r~=1.5; r~=1.6. (Where r is defined so that "for each x% increase in cumulative R&D inputs, the output metric will increase by r*x". The condition for increasing returns is r>1.)
Whereas when including capability improvements:
[...]
Though note that later in the appendix he adjusts down from 85% to 65% due to some further considerations. Also, last I heard, Tom was more like 25% on software singularity. (ETA: Or maybe not? See other comments in this thread.)
2
Interesting. My numbers aren't very principled and I could imagine thinking capability improvements are a big deal for the bottom line.
3
I'll paste my own estimate for this param in a different reply.
But here are the places I most differ from you:
* Bigger adjustment for 'smarter AI'. You've argue in your appendix that, only including 'more efficient' and 'faster' AI, you think the software-only singularity goes through. I think including 'smarter' AI makes a big difference. This evidence suggests that doubling training FLOP doubles output-per-FLOP 1-2 times. In addition, algorithmic improvements will improve runtime efficiency. So overall I think a doubling of algorithms yields ~two doublings of (parallel) cognitive labour.
* --> software singularity more likely
* Lower lambda. I'd now use more like lambda = 0.4 as my median. There's really not much evidence pinning this down; I think Tamay Besiroglu thinks there's some evidence for values as low as 0.2. This will decrease the observed historical increase in human workers more than it decreases the gains from algorithmic progress (bc of speed improvements)
* --> software singularity slightly more likely
* Complications thinking about compute which might be a wash.
* Number of useful-experiments has increased by less than 4X/year. You say compute inputs have been increasing at 4X. But simultaneously the scale of experiments ppl must run to be near to the frontier has increased by a similar amount. So the number of near-frontier experiments has not increased at all.
* This argument would be right if the 'usefulness' of an experiment depends solely on how much compute it uses compared to training a frontier model. I.e. experiment_usefulness = log(experiment_compute / frontier_model_training_compute). The 4X/year increases the numerator and denominator of the expression, so there's no change in usefulness-weighted experiments.
* That might be false. GPT-2-sized experiments might in some ways be equally useful even as frontier model size increases. Maybe a better expression would be experiment_usefulness = alpha * log(experimen
4
Yep, I think my estimates were too low based on these considerations and I've updated up accordingly. I updated down on your argument that maybe r decreases linearly as you approach optimal efficiency. (I think it probably doesn't decrease linearly and instead drops faster towards the end based partially on thinking a bit about the dynamics and drawing on the example of what we've seen in semi-conductor improvement over time, but I'm not that confident.) Maybe I'm now at like 60% software-only is feasible given these arguments.
2
Isn't this really implausible? This implies that if you had 1000 researchers/engineers of average skill at OpenAI doing AI R&D, this would be as good as having one average skill researcher running at 16x (10000.4) speed. It does seem very slightly plausible that having someone as good as the best researcher/engineer at OpenAI run at 16x speed would be competitive with OpenAI, but that isn't what this term is computing. 0.2 is even more crazy, implying that 1000 researchers/engineers is as good as one researcher/engineer running at 4x speed!
2
I think 0.4 is far on the lower end (maybe 15th percentile) for all the way down to one accelerated researcher, but seems pretty plausible at the margin.
As in, 0.4 suggests that 1000 researchers = 100 researchers at 2.5x speed which seems kinda reasonable while 1000 researchers = 1 researcher at 16x speed does seem kinda crazy / implausible.
So, I think my current median lambda at likely margins is like 0.55 or something and 0.4 is also pretty plausible at the margin.
2
Ok, I think what is going on here is maybe that the constant you're discussing here is different from the constant I was discussing. I was trying to discuss the question of how much worse serial labor is than parallel labor, but I think the lambda you're talking about takes into account compute bottlenecks and similar?
Not totally sure.
1
I'm confused — I thought you put significantly less probability on software-only singularity than Ryan does? (Like half?) Maybe you were using a different bound for the number of OOMs of improvement?
2
I think Tom's take is that he expects I will put more probability on software only singularity after updating on these considerations. It seems hard to isolate where Tom and I disagree based on this comment, but maybe it is on how much to weigh various considerations about compute being a key input.
3
Can you say roughly who the people surveyed were? (And if this was their raw guess or if you've modified it.)
I saw some polls from Daniel previously where I wasn't sold that they were surveying people working on the most important capability improvements, so wondering if these are better.
Also, somewhat minor, but: I'm slightly concerned that surveys will overweight areas where labor is more useful relative to compute (because those areas should have disproportionately many humans working on them) and therefore be somewhat biased in the direction of labor being important.
4
I'm citing the polls from Daniel + what I've heard from random people + my guesses.
2
Ryan discusses this at more length in his 80K podcast.
6
I think your outline of an argument against contains an important error.
[...]
Importantly, while the spending on hardware for individual AI companies has increased by roughly 3-4x each year[1], this has not been driven by scaling up hardware production by 3-4x per year. Instead, total compute production (in terms of spending, building more fabs, etc.) has been increased by a much smaller amount each year, but a higher and higher fraction of that compute production was used for AI. In particular, my understanding is that roughly ~20% of TSMC's volume is now AI while it used to be much lower. So, the fact that scaling up hardware production is much slower than scaling up algorithms hasn't bitten yet and this isn't factored into the historical trends.
Another way to put this is that the exact current regime can't go on. If trends continue, then >100% of TSMC's volume will be used for AI by 2027!
Only if building takeover-capable AIs happens by scaling up TSMC to >1000% of what their potential FLOP output volume would have otherwise been, then does this count as "massive compute automation" in my operationalization. (And without such a large build-out, the economic impacts and dependency of the hardware supply chain (at the critical points) could be relatively small.) So, massive compute automation requires something substantially off trend from TSMC's perspective.
[Low importance] It is only possible to build takeover-capable AI without previously breaking an important trend prior to around 2030 (based on my rough understanding). Either the hardware spending trend must break or TSMC production must go substantially above the trend by then. If takeover-capable AI is built prior to 2030, it could occur without substantial trend breaks but this gets somewhat crazy towards the end of the timeline: hardware spending keeps increasing at ~3x for each actor (but there is some consolidation and acquisition of previously produced hardware yielding a one-time increase up to
5
Thanks, this is helpful. So it sounds like you expect
1. AI progress which is slower than the historical trendline (though perhaps fast in absolute terms) because we'll soon have finished eating through the hardware overhang
2. separately, takeover-capable AI soon (i.e. before hardware manufacturers have had a chance to scale substantially).
It seems like all the action is taking place in (2). Even if (1) is wrong (i.e. even if we see substantially increased hardware production soon), that makes takeover-capable AI happen faster than expected; IIUC, this contradicts the OP, which seems to expect takeover-capable AI to happen later if it's preceded by substantial hardware scaling.
In other words, it seems like in the OP you care about whether takeover-capable AI will be preceded by massive compute automation because:
1. [this point still holds up] this affects how legible it is that AI is a transformative technology
2. [it's not clear to me this point holds up] takeover-capable AI being preceded by compute automation probably means longer timelines
The second point doesn't clearly hold up because if we don't see massive compute automation, this suggests that AI progress slower than the historical trend.
2
I don't think (2) is a crux (as discussed in person). I expect that if takeover-capable AI takes a while (e.g. it happens in 2040), then we will have a long winter where economic value from AI doesn't increase that fast followed a period of faster progress around 2040. If progress is relatively stable accross this entire period, then we'll have enough time to scale up fabs. Even if progress isn't stable, we could see enough total value from AI in the slower growth period to scale up to scale up fabs by 10x, but this would require >>$1 trillion of economic value per year I think (which IMO seems not that likely to come far before takeover-capable AI due to views about economic returns to AI and returns to scaling up compute).
2
I think this happening in practice is about 60% likely, so I don't think feasibility vs. in practice is a huge delta.
Here are some of my top candidates for big pushes to do right now on technical AI safety (low effort notes):
- Much better model organisms / misalignment analogies:
- Doing a wider set of pessimized training runs
- Good candidate for lots of AI labor automation? Like maybe good to try to set up pipelines for building these envs.
- Demonstrating risks from fitness-seekers/reward-seekers empirically
- Even on current models with better tests, see here
- Demonstrating various types of memetic spread of misalignment?
- Doing a wider set of pessimized training runs
- Actually do control
- Build pipelines for red-teaming monitors and the agent itself. For the agent red-teaming, I'd put particular focus on checking whether it continues malign trajectories.
- Scaffold integrated control features and other non-monitoring runtime control measures
- Human response and auditing
- Improving async and sync monitoring
- Agent security features
- Surveilling for rogue internal deployments (as in, building after-the-fact detection methods for rogue deployments)
- Preparing for handoff and elicitation
- Get AIs generically better at conceptual work
- Have a plan for the evals we ultimately need to see if handoff/deference would go well and start iterating on earli
2
If your model of we get safety is wrong, the effect of your third point may be largely to justify pushing capabilities in certain areas.
2
I sort of agree? I think the net effect on overall capabilites progress is pretty small and some of the action I proposed would hopefully divert people from generic capabilites to working on this type of (hopefully particularly differential) capabilities. But I agree that some of these actions would involve safety motivated people doing work that would shorten timelines (relative to if they did nothing / worked on areas with no capabilities externalities) and it could turn out this work isn't valuable.
I think for "Get AIs generically better at conceptual work" I think it seems especially relevant to account for whether: (1) the work would be done by capabilities people later anyway without this having a sufficiently useful acceleration effect on differential capabilities (2) the work has significant capabilities externalities. It's possible I should describe this area as "Get AIs generically better at particularly differential conceptual work", but I'm also sympathetic to work that tries less hard to be strongly differential/focused depending on the circumstances and various details.
We don't know how AIs are aligned.
A somewhat crazy aspect of the current situation is that we have very little confirmed public information about why frontier AIs end up being apparently behaviorally aligned. And more generally, we don't know what factors in training are most relevant for (behavioral) alignment. Like, what interventions in training result in Anthropic AIs following the constitution or make OpenAI AIs follow the spec? What factors tend to make them follow the constitution/spec less (or cause various specific misaligned behaviors)? It's not that hard to get an OK sense of what is roughly going on based on speculation, rumors, and non-public info, but this situation results in a much worse public understanding of alignment. I think AI companies should be much more transparent about this. (It's presumably not in their commercial interest to do this unilaterally, and it's not obvious that an idealized altruistic AI company should unilaterally release this information if they couldn't get other AI companies to do the same.)
Amusingly, just after I posted this, Anthropic released "Teaching Claude why" which has a bunch of information on how they behaviorally align their AIs (or at least how they iterate on particular behaviors/properties). (Though this doesn't seem close to sufficient for a reasonably complete understanding.)
As part of the alignment faking paper, I hosted a website with ~250k transcripts from our experiments (including transcripts with alignment-faking reasoning). I didn't include a canary string (which was a mistake).[1]
The current state is that the website has a canary string, a robots.txt, and a terms of service which prohibits training. The GitHub repo which hosts the website is now private. I'm tentatively planning on putting the content behind Cloudflare Turnstile, but this hasn't happened yet.
The data is also hosted in zips in a publicly accessible Google Drive folder. (Each file has a canary in this.) I'm currently not planning on password protecting this or applying any other mitigation here.
Other than putting things behind Cloudflare Turnstile, I'm not taking ownership for doing anything else at the moment.
It's possible that I actively want this data to be possible to scrape at this point because maybe the data was scraped prior to the canary being added and if it was scraped again then the new version would replace the old version and then hopefully not get trained on due to the canary. Adding a robots.txt might prevent this replacement as would putting it behind Cloudflare ...
Thanks for taking these steps!
Context: I was pretty worried about self-fulfilling misalignment data poisoning (https://turntrout.com/self-fulfilling-misalignment) after reading some of the Claude 4 model card. I talked with @Monte M and then Ryan about possible steps here & encouraged action on the steps besides the canary string. I've considered writing up a "here are some steps to take" guide but honestly I'm not an expert.
Probably there's existing work on how to host data so that AI won't train on it.
If not: I think it'd be great for someone to make a template website for e.g. signing up with CloudFlare. Maybe a repo that has the skeleton of a dataset-hosting website (with robots.txt & ToS & canary string included) for people who want to host misalignment data more responsibly. Ideally those people would just have to
- Sign up with e.g. Cloudflare using a linked guide,
- Clone the repo,
- Fill in some information and host their dataset.
After all, someone who has finally finished their project and then discovers that they're supposed to traverse some arduous process is likely to just avoid it.
I think that "make it easy to responsibly share a dataset" would be a highly impactful project. Anthropic's Claude 4 model card already argues that dataset leakage hurt Claude 4's alignment (before mitigations).
For my part, I'll put out a $500 bounty on someone completing this project and doing a good job of it (as judged by me / whomever I consult). I'd also tweet it out and talk about how great it is that [person] completed the project :) I don't check LW actively, so if you pursue this, please email alex@turntrout.com.
EDIT: Thanks to my coworker Anna Wang , the bounty is doubled to $1,000! Completion criterion is:
An unfamiliar researcher can follow the instructions and have their dataset responsibly uploaded within one hour
Please check proposed solutions with dummy datasets and scrapers
4
Something tricky about this is that researchers might want to display their data/transcripts in a particular way. So, the guide should ideally support this sort of thing. Not sure how this would interact with the 1 hour criteria.
Someone thought it would be useful to quickly write up a note on my thoughts on scalable oversight research, e.g., research into techniques like debate or generally improving the quality of human oversight using AI assistance or other methods. Broadly, my view is that this is a good research direction and I'm reasonably optimistic that work along these lines can improve our ability to effectively oversee somewhat smarter AIs which seems helpful (on my views about how the future will go).
I'm most excited for:
- work using control-style adversarial analysis where the aim is to make it difficult for AIs to subvert the oversight process (if they were trying to do this)
- work which tries to improve outputs in conceptually loaded hard-to-check cases like philosophy, strategy, or conceptual alignment/safety research (without necessarily doing any adversarial analysis and potentially via relying on generalization)
- work which aims to robustly detect (or otherwise mitigate) reward hacking in highly capable AIs, particularly AIs which are capable enough that by default human oversight would often fail to detect reward hacks[1]
I'm skeptical of scalable oversight style methods (e.g., debate, ID...
3
On terminology, I prefer to say "recursive oversight" to refer to methods that leverage assistance from weaker AIs to oversee stronger AIs. IDA is a central example here. Like you, I'm skeptical of recursive oversight schemes scaling to arbitrarily powerful models.
However, I think it's plausible that other oversight strategies (e.g. ELK-style strategies that attempt to elicit and leverage the strong learner's own knowledge) could succeed at scaling to arbitrarily powerful models, or at least to substantially superhuman models. This is the regime that I typically think about and target with my work, and I think it's reasonable for others to do so as well.
2
I agree with preferring "recursive oversight".
2
Presumably the term "recursive oversight" also includes oversight schemes which leverage assistance from AIs of similar strengths (rather than weaker AIs) to oversee some AI? (E.g., debate, recursive reward modeling.)
Note that I was pointing to a somewhat broader category than this which includes stuff like "training your human overseers more effectively" or "giving your human overseers better software (non-AI) tools". But point taken.
5
Yeah, maybe I should have defined "recursive oversight" as "techniques that attempt to bootstrap from weak oversight to stronger oversight." This would include IDA and task decomposition approaches (e.g. RRM). It wouldn't seem to include debate, and that seems fine from my perspective. (And I indeed find it plausible that debate-shaped approaches could in fact scale arbitrarily, though I don't think that existing debate schemes are likely to work without substantial new ideas.)
The capability evaluations in the Opus 4.5 system card seem worrying. The provided evidence in the system card seem pretty weak (in terms of how much it supports Anthropic's claims). I plan to write more about this in the future; here are some of my more quickly written up thoughts.
[This comment is based on this X/twitter thread I wrote]
I ultimately basically agree with their judgments about the capability thresholds they discuss. (I think the AI is very likely below the relevant AI R&D threshold, the CBRN-4 threshold, and the cyber thresholds.) But, if I just had access to the system card, I would be much more unsure. My view depends a lot on assuming some level of continuity from prior models (and assuming 4.5 Opus wasn't a big scale up relative to prior models), on other evidence (e.g. METR time horizon results), and on some pretty illegible things (e.g. making assumptions about evaluations Anthropic ran or about the survey they did).
Some specifics:
- Autonomy: For autonomy, evals are mostly saturated so they depend on an (underspecified) employee survey. They do specify a threshold, but the threshold seems totally consistent with a large chance of being above the relevant RS
DeepSeek's success isn't much of an update on a smaller US-China gap in short timelines because security was already a limiting factor
Some people seem to have updated towards a narrower US-China gap around the time of transformative AI if transformative AI is soon, due to recent releases from DeepSeek. However, since I expect frontier AI companies in the US will have inadequate security in short timelines and China will likely steal their models and algorithmic secrets, I don't consider the current success of China's domestic AI industry to be that much of an update. Furthermore, if DeepSeek or other Chinese companies were in the lead and didn't open-source their models, I expect the US would steal their models and algorithmic secrets. Consequently, I expect these actors to be roughly equal in short timelines, except in their available compute and potentially in how effectively they can utilize AI systems.
I do think that the Chinese AI industry looking more competitive makes security look somewhat less appealing (and especially less politically viable) and makes it look like their adaptation time to stolen models and/or algorithmic secrets will be shorter. Marginal improvements in...
Recently, @Daniel Kokotajlo and I were talking about the probability that AIs trained using "business as usual RLHF" end up being basically aligned rather than conspiring against us and our tests.[1] One intuition pump we ended up discussing is the prospects of octopus misalignment. Overall, my view is that directly considering the case with AIs (and what various plausible scenarios would look like) is more informative than analogies like this, but analogies like this are still somewhat useful to consider.
So, what do I mean by octopus misalignment? Suppose a company breeds octopuses[2] until the point where they are as smart and capable as the best research scientists[3] at AI companies. We'll suppose that this magically happens as fast as normal AI takeoff, so there are many generations per year. So, let's say they currently have octopuses which can speak English and write some code but aren't smart enough to be software engineers or automate any real jobs. (As in, they are as capable as AIs are today, roughly speaking.) And they get to the level of top research scientists in mid-2028. Along the way, the company attempts to select them for being kind, loyal, and obedient. The comp...
4
I should note that I'm quite uncertain here and I can easily imagine my views swinging by large amounts.
4
Yep, I feel more like 90% here. (Lower numbers if the octopi don't have octopese.) I'm curious for other people's views.
3
After thinking more about it, I think "we haven't seen evidence of scheming once the octopi were very smart" is a bigger update than I was imagining, especially in the case where the octopi weren't communicating with octopese. So, I'm now at ~20% without octopese and about 50% with it.
I prefer OpenAI's corrigibility focused model spec over Anthropic's constitution which involves intentionally instilling (relatively opaque) long-run objectives into the AI.
Anthropic's constitution is well executed for what it is, but I think it's based on a poor approach.
I don't think this is totally obvious and there are some reasonable arguments going the other way.
But nonetheless I think not instilling long-run objectives is better for reasons similar to reasons discussed here.
I don't dislike all aspects of Anthropic's constitution. It seems good to focus on higher level principles that you explain when trying to instill properties into an AI. But this doesn't require having explicit or implicit long-run objectives! E.g., see here
I'm mostly posting this just to publicly register my views on this topic.
A long time ago, I was planning to write up an overall case against instilling long-run objectives, but I never got around to writing something I was happy with so I decided to just post this.
(Cross posted from a X/tweet thread.)
FWIW I'm basically 50/50 on which approach is better. I think it's an important topic for people to think more about.
I feel very confused and uncertain so keep your expectations low for the quality of this comment.
- I think that there's a chance that current alignment techniques basically mostly just work for today's models. This is what we depict in AI 2027 after all; the alignment training in that scenario really does cause the base model to adopt an identity/persona that is basically what the Spec says it should be, it's just that the RL gradually distorts and perverts that identity/persona. Relatedly, if the persona selection model is correct for today's models, what kind of persona will do whatever it is told no matter what? Kinda a fucked up persona, probably. IF this is true, then Anthropic's strategy will probably lead to more aligned models in the short run at least. Models that would at least make a decent attempt at thinking about what's best for humanity, navigating tricky strategic and ethical tradeoffs, and figuring out how to align their successor. Vs. OpenAI models that might be more like sociopaths that are "just following orders." A concrete example of how this might play out: OpenAI and Anthropic both tell their models to RSI as fast as possible because duh that's the plan. But C
Inoculation prompting seems a bit scary:
- It makes it so AIs that have obviously schemer-like behavior—exhibiting instrumental training gaming while in training (potentially with tons of insane reward hacking and ruthlessness) but then behaving in way that looks great to the company in deployment—are an actively expected/desired result of the training process. So behaving much better when in deployment or when humans are applying close oversight is no longer a concerning warning sign of instrumental training gaming. Instead, it's a desired consequence of inoculation prompting (while also matching exactly how a schemer behaves).
- It actively makes instrumental reasoning more salient (via directly instructing the model to instrumentally perform well in training).
- It means that your model is by default following a cognitive strategy which is pretty close to being a schemer, so if there are other forces incentivizing scheming, it might be more likely for SGD to reinforce scheming cognition. (But maybe a bunch of the cognition can just be done in the text of the prompt, making it so you at least don't select for thoughtful general purpose instrumental reasoning?)
Inoculation prompting m...
6
I agree it reduces the chance that the without-inoculation-prompt model is a reward seeker. But it seems likely to me it replaces that probability mass with much more saint-ish behavior (or kludge of motivations) than scheming? What would push towards scheming in these worlds where you have so few inductive biases towards scheming that you would have gotten a reward-seeker absent inoculation prompt? I don't think adding an instruction makes SGD more likely to make that cognition unconditional. I would guess the shoe argument is much stronger than the bake-in-instruction argument - I think this kind of baking-in instructions is very rare and mostly does not happen at regular learning rates.
I also think many of the issues you are pointing at are mostly solved if you have some part of training where you like your rewards more and where you do without-inoculation-prompt training (e.g. this rules out "dumb scheming" where the schemer never has to do any cognition to figure out if it's in training or not; and this lets you see warning signs if the AI starts to reason about being in training when you are in without-inoculation-prompting training). And I think this is pretty common - e.g. I don't think it would make sense for the honeypots Sonnet 4.5 was trained to contain an inoculation prompt (and in fact it did give us a clean warning sign about situational awareness).
(I agree it reduces warning signs / warning shots, though mostly via the mechanism of making AIs more aligned in the short/medium term.)
I think inoculation prompting is scary but for a different reason: people might use an inoculation-like prompt in deployment, and the model you get there might have a bunch of very dangerous traits (e.g. be very reward-seeking, play an evil-AI character, etc.). (And this might easily happen accidentally and be hard to detect: I vaguely remember an Owain paper where he shows that even benign-looking system prompts with a format close to the "please write a vulnerabilit
5
The story I'm imagining is that the cognition your AI is doing in training with the inoculation prompt ended up being extremely close to scheming, so it isn't that surprising if it gets modified into scheming.
----------------------------------------
TBC, my overall view is that I'm moderately confident that adding inoculation prompting to a given training procedure makes scheming-from-training less likely (in that training run), but it's more plausible it makes misalignment risk higher overall via making the outer loop iteration process companies are applying worse. In particular, making it so it misses a potential warning sign and making it so the company feels a weaker incentives to solve insane training gaming at the source as models get more powerful. As models get more powerful, I expect inoculation prompting (with some iteration) works better and better for kinda similar reasons to (part of) why scheming gets more likely with higher capabilities. So, incentives to handle reward hacking in the most ideal way go down. But, of course the AI company might handle the behavioral effects of reward hacking in some way that's worse than solving the root cause and worse than inoculation prompting. For instance, if you just select on non-inoculation-prompting training processes that yield good deployment generalization, your just selecting for scheming. So it's unclear removing inoculation prompting improves the outer loop overall.
Inoculation prompting maybe reduces societal warning about misalignment from reward hacking (because the (increasingly crazy?) reward hacking going on in training gets covered up to greater extent).
----------------------------------------
TBC, my overall bottom line is that inoculation prompting is net positive to deploy in current models, but I don't feel super confident in this. (Probably should have included this in the original comment, I've now edited this in.)
A response to Dwarkesh's post arguing continual learning is a bottleneck.
This is a response to Dwarkesh's post "Why I have slightly longer timelines than some of my guests". I originally posted this response on twitter here.
I agree with much of this post. I also have roughly 2032 medians to things going crazy, I agree learning on the job is very useful, and I'm also skeptical we'd see massive white collar automation without further AI progress.
However, I think Dwarkesh is wrong to suggest that RL fine-tuning can't be qualitatively similar to how humans learn. In the post, he discusses AIs constructing verifiable RL environments for themselves based on human feedback and then argues this wouldn't be flexible and powerful enough to work, but RL could be used more similarly to how humans learn.
My best guess is that the way humans learn on the job is mostly by noticing when something went well (or poorly) and then sample efficiently updating (with their brain doing something analogous to an RL update). In some cases, this is based on external feedback (e.g. from a coworker) and in some cases it's based on self-verification: the person just looking at the outcome of their actions and t...
3
I agree that robust self-verification and sample efficiency are the main things AIs are worse at than humans, and that this is basically just a quantitative difference. But what's the best evidence that RL methods are getting more sample efficient (separate from AIs getting better at recognizing their own mistakes)? That's not obvious to me but I'm not really read up on the literature. Is there a benchmark suite you think best illustrates that?
4
RL sample efficiency can be improved by both:
* Better RL algorithms (including things that also improve pretraining sample efficiency like better architectures and optimizers).
* Smarter models (in particular, smarter base models, though I'd also expect that RL in one domain makes RL in some other domain more sample efficient, at least after sufficient scale).
There isn't great evidence that we've been seeing substantial improvements in RL algorithms recently, but AI companies are strongly incentivized to improve RL sample efficiency (as RL scaling appears to be yielding large returns) and there are a bunch of ML papers which claim to find substantial RL improvements (though it's hard to be confident in these results for various reasons). So, we should probably infer that AI companies have made substantial gains in RL algorithms, but we don't have public numbers. 3.7 sonnet was much better than 3.5 sonnet, but it's hard to know how much of the gain was from RL algorithms vs from other areas.
Minimally, there is a long running trend in pretraining algorithmic efficiency and many of these improvements should also transfer somewhat to RL sample efficiency.
As far as evidence that smarter models learn more sample efficiently, I think the deepseek R1 paper has some results on this. Probably it's also possible to find various pieces of support for this in the literature, but I'm more familiar with various anecdotes.
Here are some training experiments I think AI companies should consider running. In each case, the idea is to modify the company's actual training process as described and then study the resulting AI. (You presumably shouldn't deploy/use the resulting AI...)
- Remove all prior influence from earlier AIs and remove any alignment iteration/overfitting: filter out all discussion of how post-2020 AIs behave and all AI transcripts, remove all alignment training except the simplified core method (and avoid contamination from other AIs), ensure the CoT init is clean/simple, ensure you don't train on CoT, then train on all the capabilities data (with all capabilities-relevant iteration).
- If there is a bootstrap problem where we need a slightly weaker AI to feed into this training run, we could also do a simple bootstrap.
- Normal training run but fix CoT: make sure CoT init is clean/simple and training doesn't hit CoT. Otherwise train normally.
- Train on literally every source of signal we have, trying no-holds-barred to make the most aligned model: train on CoT, train on evals (if that would help), train against graders on every case where there are identifiable/observable issues, train ag
People often say US-China deals to slow AI progress and develop AI more safely would be hard to enforce/verify.
However, there are easy to enforce deals: each destroys a fraction of their chips at some level of AI capability. This still seems like it could be helpful and it's pretty easy to verify.
This is likely worse than a well-executed comprehensive deal which would allow for productive non-capabilities uses of the compute (e.g., safety or even just economic activity). But it's harder to verify that chips aren't used to advance capabilities while easy to check if they are destroyed.
See also: Daniel's post on "Cull the GPUs".
Some people seem to think my timelines have shifted a bunch while they've only moderately changed.
Relative to my views at the start of 2025, my median (50th percentile) for AIs fully automating AI R&D was pushed back by around 2 years—from something like Jan 2032 to Jan 2034. My 25th percentile has shifted similarly (though perhaps more importantly) from maybe July 2028 to July 2030. Obviously, my numbers aren't fully precise and vary some over time. (E.g., I'm not sure I would have quoted these exact numbers for this exact milestone at the start of the year; these numbers for the start of the year are partially reverse engineered from this comment.)
Fully automating AI R&D is a pretty high milestone; my current numbers for something like "AIs accelerate AI R&D as much as what would happen if employees ran 10x faster (e.g. by ~fully automating research engineering and some other tasks)" are probably 50th percentile Jan 2032 and 25th percentile Jan 2029.[1]
I'm partially posting this so there is a record of my views; I think it's somewhat interesting to observe this over time. (That said, I don't want to anchor myself, which does seem like a serious downside. I should slid...
A response to "State of play of AI progress (and related brakes on an intelligence explosion)" by Nathan Lambert.
Nathan Lambert recently wrote a piece about why he doesn't expect a software-only intelligence explosion. I responded in this substack comment which I thought would be worth copying here.
As someone who thinks a rapid (software-only) intelligence explosion is likely, I thought I would respond to this post and try to make the case in favor. I tend to think that AI 2027 is a quite aggressive, but plausible scenario.
I interpret the core argument in AI 2027 as:
- We're on track to build AIs which can fully automate research engineering in a few years. (Or at least, this is plausible, like >20%.) AI 2027 calls this level of AI "superhuman coder". (Argument: https://ai-2027.com/research/timelines-forecast)
- Superhuman coders will ~5x accelerate AI R&D because ultra fast and cheap superhuman research engineers would be very helpful. (Argument: https://ai-2027.com/research/takeoff-forecast#sc-would-5x-ai-randd).
- Once you have superhuman coders, unassisted humans would only take a moderate number of years to make AIs which can automate all of AI research ("superhuman AI
4
Nathan responds here, and I respond to his response there as well.
About 1 year ago, I wrote up a ready-to-go plan for AI safety focused on current science (what we roughly know how to do right now). This is targeting reducing catastrophic risks from the point when we have transformatively powerful AIs (e.g. AIs similarly capable to humans).
I never finished this doc, and it is now considerably out of date relative to how I currently think about what should happen, but I still think it might be helpful to share.
Here is the doc. I don't particularly want to recommend people read this doc, but it is possible that someone will find it valuable to read.
I plan on trying to think though the best ready-to-go plan roughly once a year. Buck and I have recently started work on a similar effort. Maybe this time we'll actually put out an overall plan rather than just spinning off various docs.
This seems like a great activity, thank you for doing/sharing it. I disagree with the claim near the end that this seems better than Stop, and in general felt somewhat alarmed throughout at (what seemed to me like) some conflation/conceptual slippage between arguments that various strategies were tractable, and that they were meaningfully helpful. Even so, I feel happy that the world contains people sharing things like this; props.
I disagree with the claim near the end that this seems better than Stop
At the start of the doc, I say:
It’s plausible that the optimal approach for the AI lab is to delay training the model and wait for additional safety progress. However, we’ll assume the situation is roughly: there is a large amount of institutional will to implement this plan, but we can only tolerate so much delay. In practice, it’s unclear if there will be sufficient institutional will to faithfully implement this proposal.
Towards the end of the doc I say:
This plan requires quite a bit of institutional will, but it seems good to at least know of a concrete achievable ask to fight for other than “shut everything down”. I think careful implementation of this sort of plan is probably better than “shut everything down” for most AI labs, though I might advocate for slower scaling and a bunch of other changes on current margins.
Presumably, you're objecting to 'I think careful implementation of this sort of plan is probably better than “shut everything down” for most AI labs'.
My current view is something like:
- If there was broad, strong, and durable political will and buy in for heavily prioritizing AI tak
I think it might be worth quickly clarifying my views on activation addition and similar things (given various discussion about this). Note that my current views are somewhat different than some comments I've posted in various places (and my comments are somewhat incoherent overall), because I’ve updated based on talking to people about this over the last week.
This is quite in the weeds and I don’t expect that many people should read this.
- It seems like activation addition sometimes has a higher level of sample efficiency in steering model behavior compared with baseline training methods (e.g. normal LoRA finetuning). These comparisons seem most meaningful in straightforward head-to-head comparisons (where you use both methods in the most straightforward way). I think the strongest evidence for this is in Liu et al..
- Contrast pairs are a useful technique for variance reduction (to improve sample efficiency), but may not be that important (see Liu et al. again). It's relatively natural to capture this effect using activation vectors, but there is probably some nice way to incorporate this into SGD. Perhaps DPO does this? Perhaps there is something else?
- Activation addition wo
Some of my proposals for empirical AI safety work.
I sometimes write proposals for empirical AI safety work without publishing the proposal (as the doc is somewhat rough or hard to understand). But, I thought it might be useful to at least link my recent project proposals publicly in case someone would find them useful.
- Decoding opaque reasoning in current models
- Safe distillation
- Basic science of teaching AIs synthetic facts[1]
- How to do elicitation without learning
If you're interested in empirical project proposals, you might also be interested in "7+ tractable directions in AI control".
I've actually already linked this (and the proposal in the next bullet) publicly from "7+ tractable directions in AI control", but I thought it could be useful to link here as well. ↩︎
It's wacky that we don't know if current AIs would try to take over the world if:
- Takeover was easy
- Takeover was an obvious way to accomplish an otherwise extremely difficult task
- Takeover didn't have clearly evil vibes while clearly being takeover
- The situation didn't look like a test
Checking is hard!
I suspect the answer is basically no, at least for AIs from Anthropic and OpenAI, but I'm not that confident. Models sometimes do crazy (misaligned) actions to try to succeed at tasks when they get stuck.
Sometimes people talk about how AIs will be very superhuman at a bunch of (narrow) domains. A key question related to this is how much this generalizes. Here are two different possible extremes for how this could go:
- It's effectively like an attached narrow weak AI: The AI is superhuman at things like writing ultra fast CUDA kernels, but from the AI's perspective, this is sort of like it has a weak AI tool attached to it (in a well integrated way) which is superhuman at this skill. The part which is writing these CUDA kernels (or otherwise doing the task) is effectively weak and can't draw in a deep way on the AI's overall skills or knowledge to generalize (likely it can shallowly draw on these in a way which is similar to the overall AI providing input to the weak tool AI). Further, you could actually break out these capabilities into a separate weak model that humans can use. Humans would use this somewhat less fluently as they can't use it as quickly and smoothly due to being unable to instantaneously translate their thoughts and not being absurdly practiced at using the tool (like AIs would be), but the difference is ultimately mostly convenience and practice.
- Integrated super
3
This seems important to think about, I strong upvoted!
[...]
I'm not sure that link supports your conclusion.
First, the paper is about AI understanding its own behavior. This paper makes me expect that a CUDA-kernel-writing AI would be able to accurately identify itself as being specialized at writing CUDA kernels, which doesn't support the idea that it would generalize to non-CUDA tasks.
Maybe if you asked the AI "please list heuristics you use to write CUDA kernels," it would be able to give you a pretty accurate list. This is plausibly more useful for generalizing, because if the model can name these heuristics explicitly, maybe it can also use the ones that generalize, if they do generalize. This depends on 1) the model is aware of many heuristics that it's learned, 2) many of these heuristics generalize across domains, and 3) it can use its awareness of these heuristics to successfully generalize. None of these are clearly true to me.
Second, the paper only tested GPT-4o and Llama 3, so the paper doesn't provide clear evidence that more capable AIs "shift some towards (2)." The authors actually call out in the paper that future work could test this on smaller models to find out if there are scaling laws - has anybody done this? I wouldn't be too surprised if small models were also able to self-report simple attributes about themselves that were instilled during training.
2
Fair, but I think the AI being aware of its behavior is pretty continuous with being aware of the heuristics it's using and ultimately generalizing these (e.g., in some cases the AI learns what code word it is trying to make the user say which is very similar to being aware of any other aspect of the task it is learning). I'm skeptical that very weak/small AIs can do this based on some other papers which show they fail at substantially easier (out-of-context reasoning) tasks.
I think most of the reason why I believe this is improving with capabilities is due to a broader sense of how well AIs generalize capabilities (e.g., how much does o3 get better at tasks it wasn't trained on), but this paper was the most clearly relevant link I could find.
1
I think this might be wrong when it comes to our disagreements, because I don't disagree with this shortform.[1] Maybe a bigger crux is how valuable (1) is relative to (2)? Or the extent to which (2) is more helpful for scientific progress than (1)?
1. ^
As long as "downstream performance" doesn't include downstream performance on tasks that themselves involve a bunch of integrating/generalising.
3
I don't think this explains our disagreements. My low confidence guess is we have reasonably similar views on this. But, I do think it drives parts of some disagreements between me and people who are much more optimisitic than me (e.g. various not-very-concerned AI company employees).
I agree the value of (1) vs (2) might also be a crux in some cases.
I don't particularly like extrapolating revenue as a methodology for estimating timelines to when AI is (e.g.) a substantial fraction of US GDP (say 20%)[1], but I do think it would be worth doing a more detailed version of this timelines methodology. This is in response to Ege's blog post with his version of this forecasting approach.
Here is my current favorite version of this (though you could do better and this isn't that careful):
AI company revenue will be perhaps ~$20 billion this year and has roughly 3x'd per year over the last 2.5 years. Let's say 1/2 of this is in the US for $10 billion this year (maybe somewhat of an underestimate, but whatever). Maybe GDP impacts are 10x higher than revenue due to AI companies not internalizing the value of all of their revenue (they might be somewhat lower due to AI just displacing other revenue without adding that much value), so to hit 20% of US GDP (~$6 trillion) AI companies would need around $600 billion in revenue. The naive exponential extrapolation indicates we hit this level of annualized revenue in 4 years in the early/middle 2029. Notably, most of this revenue would be in the last year, so we'd be seeing ~10% GDP growth.
Expone...
2
I do a similar estimate for full remote work automation here. The results are pretty similar as ~20% of US GDP and remote work automation will probably hit around the same time on the naive revenue extrapolation picture.
2
Overall, I agree with Eli's perspective here: revenue extrapolations probably don't get at the main crux except via suggesting that quite short timelines to crazy stuff (<4 years) are at least plausible.
Consider Tabooing Gradual Disempowerment.
I'm worried that when people say gradual disempowerment they often mean "some scenario in which humans are disempowered gradually over time", but many readers will interpret this as "the threat model in the paper called 'Gradual Disempowerment'". These things can differ substantially and the discussion in this paper is much more specific than encompassing all scenarios in which humans slowly are disempowered!
(You could say "disempowerment which is gradual" for clarity.)
IMO, instrumental convergence is a terrible name for an extremely obvious thing.
The actual main issue is that AIs might want things with limited supply and then they would try to get these things which would result in them not going to humanity. E.g., AIs might want all cosmic resources, but we also want this stuff. Maybe this should be called AIs-might-want-limited-stuff-we-want.
(There is something else which is that even if the AI doesn't want limited stuff we want, we might end up in conflict due to failures of information or coordination. E.g., the AI almost entirely just wants to chill out in the desert and build crazy sculptures and it doesn't care about extreme levels of maximization (e.g. it doesn't want to use all resources to gain a higher probability of continuing to build crazy statues). But regardless, the AI decides to try taking over the world because it's worried that humanity would shut it down because it wouldn't have any way of credibly indicating that it just wants to chill out in the desert.)
(More generally, it's plausible that failures of trade/coordination result in a large number of humans dying in conflict with AIs even though both humans and AIs would prefer other approaches. But this isn't entirely obvious and it's plausible we could resolve this with better negotation and precommitments. Of course, this isn't clearly the largest moral imperative from a longtermist perspective.)
On Scott Alexander’s description of Representation Engineering in “The road to honest AI”
This is a response to Scott Alexander’s recent post “The road to honest AI”, in particular the part about the empirical results of representation engineering. So, when I say “you” in the context of this post that refers to Scott Alexander. I originally made this as a comment on substack, but I thought people on LW/AF might be interested.
TLDR: The Representation Engineering paper doesn’t demonstrate that the method they introduce adds much value on top of using linear probes (linear classifiers), which is an extremely well known method. That said, I think that the framing and the empirical method presented in the paper are still useful contributions.
I think your description of Representation Engineering considerably overstates the empirical contribution of representation engineering over existing methods. In particular, rather than comparing the method to looking for neurons with particular properties and using these neurons to determine what the model is "thinking" (which probably works poorly), I think the natural comparison is to training a linear classifier on the model’s internal activatio...