Epistemic Status: I only know as much as anyone else in my reference class (I build ML models, I can grok the GPT papers, and I don't work for OpenAI or a similar lab). But I think my thesis is original.
For the last several years, I've gone around saying that I'm worried abouttransformative AI, an AI capable of making an Industrial Revolution sized impact (the concept is agnostic on whether it has to be AGI or self-improving), because I think we might be one or two cognitive breakthroughs away from building one.
GPT-3 has made me move up my timelines, because it makes me think we might need zero more cognitive breakthroughs, just more refinement / efficiency / computing power: basically, GPT-6 or GPT-7 might do it. My reason for thinking this is comparing GPT-3 to GPT-2, and reflecting on what the differences say about the "missing pieces" for transformative AI.
My Thesis:
The difference between GPT-2 and GPT-3 has made me suspect that there's a legitimate comparison to be made between the scale of a network architecture like the GPTs, and some analogue of "developmental stages" of the resulting network. Furthermore, it's plausible to me that the functions needed to be a transformative AI are covered by a moderate number of such developmental stages, without requiring additional structure. Thus GPT-N would be a transformative AI, for some not-too-large N, and we need to redouble our efforts on ways to align such AIs.
The thesis doesn't strongly imply that we'll reach transformative AI via GPT-N especially soon; I have wide uncertainty, even given the thesis, about how large we should expect N to be, and whether the scaling of training and of computation slows down progress before then. But it's also plausible to me now that the timeline is only a few years, and that no fundamentally different approach will succeed before then. And that scares me.
Architecture and Scaling
GPT, GPT-2, and GPT-3 use nearly the same architecture; each paper says as much, with a sentence or two about minor improvements to the individual transformers. Model size (and the amount of training computation) is really the only difference.
GPT took 1 petaflop/s-day to train 117M parameters, GPT-2 took 10 petaflop/s-days to train 1.5B parameters, and the largest version of GPT-3 took 3,000 petaflop/s-days to train 175B parameters. By contrast, AlphaStar seems to have taken about 30,000 petaflop/s-days of training in mid-2019, so the pace of AI research computing power projects that there should be about 10x that today. The upshot is that OpenAI may not be able to afford it, but if Google really wanted to make GPT-4 this year, they could afford to do so.
Analogues to Developmental Stages
There are all sorts of (more or less well-defined) developmental stages for human beings: image tracking, object permanence, vocabulary and grammar, theory of mind, size and volume, emotional awareness, executive functioning, et cetera.
We don't have feature visualization for language models, but we do have generative outputs. And as you scale up an architecture like GPT, you see higher levels of abstraction. Grammar gets mastered, then content (removing absurd but grammatical responses), then tone (first rough genre, then spookily accurate authorial voice). Topic coherence is mastered first on the phrase level, then the sentence level, then the paragraph level. So too with narrative flow.
Gwern's poetry experiments (GPT-2, GPT-3) are good examples. GPT-2 could more or less continue the meter of a poem and use words that fit the existing theme, but even its best efforts can get stuck in topic loops:
…Methinks I see her in her blissful dreams: —Or, fancy-like, in some mirage she lies, Majestic yet majestic, and of seems The image of the unconquerable skies. Methinks I see her in her blissful dreams: —Or, fancy-like, in some majestic cell, Where lordly seraphs strew their balmy dreams On the still night, or in their golden shell.
Or:
In the dark the sun doth gleam, And in the dark the moon doth seem But now the evening is begun— Gone is the sun upon the earth! The silver moon doth like a cup Of blood-red wine, and as that cup Is drained of life, doth quench no drop. What man will drink such wine?
GPT-3, though, has the sense of going somewhere, at least on the topic level. (Prompts in bold.)
O time thy pyramids, thy palaces forgot, Pensive through nations wander with no more state Than in thy days, when wandering was thy trade: Mourn for Patraos, for the glory fled Of him and thee, and in their stead left, left To other eyes a length of rolling sand, And such memorials as the traveller reads, Half guessed in shade, of sculptured walls half round, And long-defaced metopes, and friezes old.
[EDIT: Previously I also included its completion of a famous Emily Dickinson poem here, but as benkuhn pointed out, GPT-3 had simply memorized the poem and recited it. I'm really embarrassed, and also kind of shocked that I looked at the actual text of "Because I could not stop for Death" and thought, "yup, that looks like something GPT-3 could produce".]
(One last shocking bit is that, while GPT-2 had to be fine-tuned by taking the general model and training it some more on a poetry-only dataset, you're seeing what GPT-3's model does with no fine-tuning, with just a prompt that sounds poetic!)
Similarly, GPT-3's ability to write fiction is impressive- unlike GPT-2, it doesn't lose track of the plot, it has sensible things happen, it just can't plan its way to a satisfying resolution.
I'd be somewhat surprised if GPT-4 shared that last problem.
What's Next?
How could one of the GPTs become a transformative AI, even if it becomes a better and better imitator of human prose style? Sure, we can imagine it being used maliciously to auto-generate targeted misinformation or things of that sort, but that's not the real risk I'm worrying about here.
My real worry is that causal inference and planning are starting to look more and more like plausible developmental stages that GPT-3 is moving towards, and that these were exactly the things I previously thought were the obvious obstacles between current AI paradigms and transformative AI.
Learning causal inference from observations doesn't seem qualitatively different from learning arithmetic or coding from examples (and not only is GPT-3 accurate at adding three-digit numbers, but apparently at writing JSX code to spec), only more complex in degree.
Planning is more complex to assess. We've seen GPTs ascend from coherence of the next few words, to the sentence or line, to the paragraph or stanza, and we've even seen them write working code. But this can be done without planning; GPT-3 may simply have a good enough distribution over next words to prune out those that would lead to dead ends. (On the other hand, how sure are we that that's not the same as planning, if planning is just pruning on a high enough level of abstraction?)
The bigger point about planning, though, is that the GPTs are getting feedback on one word at a time in isolation. It's hard for them to learn not to paint themselves into a corner. It would make training more finicky and expensive if we expanded the time horizon of the loss function, of course. But that's a straightforward way to get the seeds of planning, and surely there are other ways.
With causal modeling and planning, you have the capability of manipulation without external malicious use. And the really worrisome capability comes when it models its own interactions with the world, and makes plans with that taken into account.
Could GPT-N turn out aligned, or at least harmless?
GPT-3 is trained simply to predict continuations of text. So what would it actually optimize for, if it had a pretty good model of the world including itself and the ability to make plans in that world?
One might hope that because it's learning to imitate humans in an unsupervised way, that it would end up fairly human, or at least act in that way. I very much doubt this, for the following reason:
Two humans are fairly similar to each other, because they have very similar architectures and are learning to succeed in the same environment.
A mimic species will be similar in some ways but not others to the species it mimics, because even if they share recent ancestry, the environmental pressures on the poisonous one are different from the environmental pressures on the mimic.
What we have with the GPTs is the first deep learning architecture we've found that scales this well in the domain (so, probably not that much like our particular architecture), learning to mimic humans rather than growing in an environment with similar pressures. Why should we expect it to be anything but very alien under the hood, or to continue acting human once its actions take us outside of the training distribution?
Moreover, there may be much more going on under the hood than we realize; it may take much more general cognitive power to learn and imitate the patterns of humans, than it requires us to execute those patterns.
Next, we might imagine GPT-N to just be an Oracle AI, which we would have better hopes of using well. But I don't expect that an approximate Oracle AI could be used safely with anything like the precautions that might work for a genuine Oracle AI. I don't know what internal optimizers GPT-N ends up building along the way, but I'm not going to count on there being none of them.
I don't expect that GPT-N will be aligned or harmless by default. And if N isn't that large before it gets transformative capacity, that's simply terrifying.
What Can We Do?
While the short timeline suggested by the thesis is very bad news from an AI safety readiness perspective (less time to come up with better theoretical approaches), there is one silver lining: it at least reduces the chance of a hardware overhang. A project or coalition can feasibly wait and take a better-aligned approach that uses 10x the time and expense of an unaligned approach, as long as they have that amount of resource advantage over any competitor.
Unfortunately, the thesis also makes it less likely that a fundamentally different architecture will reach transformative status before something like GPT does.
I don't want to take away from MIRI's work (I still support them, and I think that if the GPTs peter out, we'll be glad they've been continuing their work), but I think it's an essential time to support projects that can work for a GPT-style near-term AGI, for instance by incorporating specific alignment pressures during training. Intuitively, it seems as if Cooperative Inverse Reinforcement Learning or AI Safety via Debate or Iterated Amplification are in this class.
We may also want to do a lot of work on how better to mold a GPT-in-training into the shape of an Oracle AI.
It would also be very useful to build some GPT feature "visualization" tools ASAP.
I don't want to take away from MIRI's work (I still support them, and I think that if the GPTs peter out, we'll be glad they've been continuing their work), but I think it's an essential time to support projects that can work for a GPT-style near-term AGI
I'd love to know of a non-zero integer number of plans that could possibly, possibly, possibly work for not dying to a GPT-style near-term AGI.
Here are 11. I wouldn't personally assign greater than 50/50 odds to any of them working, but I do think they all pass the threshold of “could possibly, possibly, possibly work.” It is worth noting that only some of them are language modeling approaches—though they are all prosaic ML approaches—so it does sort of also depend on your definition of “GPT-style” how many of them count or not.
Pretty sure OpenPhil and OpenAI currently try to fund plans that claim to look like this (e.g. all the ones orthonormal linked in the OP), though I agree that they could try increasing the financial reward by 100x (e.g. a prize) and see what that inspires.
As I understand it, the high level summary (naturally Eliezer can correct me) is that (a) corrigible behaviour is very unnatural and hard to find (most nearby things in mindspace are not in equilibrium and will move away from corrigibility as they reflect / improve), and (b) using complicated recursive setups with gradient descent to do supervised learning is incredible chaotic and hard to manage, and shouldn't be counted on working without major testing and delays (i.e. could not be competitive).
There's also some more subtle and implicit disagreement that's not been quite worked out but feeds into the above, where a lot of the ML-focused alignment strategies contain this idea that we will be able to expose ML system's thought processes to humans in a transparent and inspectable way, and check whether it has corrigibility, alignment, and intelligence, then add them up together like building blocks. My read is that Eliezer finds this to be an incredible claim that would be a truly dramatic update if there was a workable proposal for it, whereas many of the proposals above take it more as a starting assumption that this is feasible and move on from there to use it in a recursive setup, then alter the details of the recursive setup in order to patch any subsequent problems.
For more hashed out details on that subtle disagreement, see the response post linked above which has several concrete examples.
As I understand it, the high level summary (naturally Eliezer can correct me) is that (a) corrigible behaviour is very unnatural and hard to find (most nearby things in mindspace are not in equilibrium and will move away from corrigibility as they reflect / improve), and (b) using complicated recursive setups with gradient descent to do supervised learning is incredible chaotic and hard to manage, and shouldn't be counted on working without major testing and delays (i.e. could not be competitive).
Perhaps Eliezer can interject here, but it seems to me like these are not knockdown criticisms that such an approach can't “possibly, possibly, possibly work”—just reasons that it's unlikely to and that we shouldn't rely on it working.
My model is that those two are the well-operationalised disagreements and thus productive to focus on, but that most of the despair is coming from the third and currently more implicit point.
Then there are more interesting proposals that require being able to fully inspect the cognition of an ML system and have it be fully introspectively clear and then use it as a building block to build stronger, competitive, corrigible and aligned ML systems. I think this is an accurate description of Iterated Amplification + Debate as Zhu says in section 1.1.4 of his FAQ, and I think something very similar to this is what Chris Olah is excited about re: microscopes about reverse engineering the entire codebase/cognition of an ML system.
I don't deny that there are lot of substantive and fascinating details to a lot of these proposals and that if this is possible we might indeed solve the alignment problem, but I think that is a large step that sounds from some initial perspectives kind of magical. And don't forget that at the same time we have to be able to combine it in a way that is competitive and corrigible and aligned.
I feel like it's one reasonable position to call such proposals non-starters until a possibility proof is shown, and instead work on basic theory that will eventually be able to give more plausible basic building blocks for designing an intelligent system. I feel confident that certain sorts of basic theories are definitely there to be discovered, that there are strong intuitions about where to look, they haven't been worked on much, and that there is low-hanging fruit to be plucked. I think Jessica Taylor wrote about a similar intuition about why she moved away from ML to do basic theory work.
I feel like it's one reasonable position to call such proposals non-starters until a possibility proof is shown, and instead work on basic theory that will eventually be able to give more plausible basic building blocks for designing an intelligent system.
I agree that deciding to work on basic theory is a pretty reasonable research direction—but that doesn't imply that other proposals can't possibly work. Thinking that a research direction is less likely to mitigate existential risk than another is different than thinking that a research direction is entirely a non-starter. The second requires significantly more evidence than the first and it doesn't seem to me like the points that you referenced cross that bar, though of course that's a subjective distinction.
Unfortunately what you say sounds somewhat plausible to me; I look forward to hearing the responses.
I'll add this additional worry: If you are an early chemist exploring the properties of various metals, and you discover a metal that gets harder as it gets colder, this should increase your credence that there are other metals that share this property. Similarly, I think, for AI architectures. The GPT architecture seems to exhibit pretty awesome scaling properties. What if there are other architectures that also have awesome scaling properties, such that we'll discover this soon? How many architectures have had 1,000+ PF-days pumped into them? Seems like just two or three. And equally importantly, how many architectures have been tried with 100+ billion parameters? I don't know, please tell me if you do.
EDIT: By "architectures" I mean "Architectures + training setups (data, reward function, etc.)"
On the one hand, GPT-3 is quite useful while being not robustly aligned, but on the other hand GPT-3's lack of alignment is impeding its capabilities to some degree.
Maybe if you update on both you just end up back where you started.
What would you say is wrong with the 'exaggerated' criticism?
I don't think you can call the arguments wrong if you also think the Orthogonality Thesis and Instrumental Convergence are real and relevant to AI safety, and as far as I can tell the criticism doesn't claim that - just that there are other assumptions needed for disaster to be highly likely.
I don't have an elevator pitch summary of my views yet, and it's possible that my interpretation of the classic arguments is wrong, I haven't reread them recently. But here's an attempt:
--The orthogonality thesis and convergent instrumental goals arguments, respectively, attacked and destroyed two views which were surprisingly popular at the time: 1. that smarter AI would necessarily be good (unless we deliberately programmed it not to be) because it would be smart enough to figure out what's right, what we intended, etc. and 2. that smarter AI wouldn't lie to us, hurt us, manipulate us, take resources from us, etc. unless it wanted to (e.g. because it hates us, or because it has been programmed to kill, etc) which it probably wouldn't. I am old enough to remember talking to people who were otherwise smart and thoughtful who had views 1 and 2.
--As for whether the default outcome is doom, the original argument makes clear that default outcome means absent any special effort to make AI good, i.e. assuming everyone just tries to make it intelligent, but no effort is spent on making it good, the outcome is likely to be doom. This is, I think, true. Later the book goes on to talk about how making it good is more difficult than it sounds. Moreover, Bostrom doesn't wave around his arguments about they are proofs; he includes lots of hedge words and maybes. I think we can interpret it as a burden-shifting argument; "Look, given the orthogonality thesis and instrumental convergence, and various other premises, and given the enormous stakes, you'd better have some pretty solid arguments that everything's going to be fine in order to disagree with the conclusion of this book (which is that AI safety is extremely important)." As far as I know no one has come up with any such arguments, and in fact it's now the consensus in the field that no one has found such an argument.
Proceeding from the idea of first-mover advantage, the orthogonality thesis, and the instrumental convergence thesis, we can now begin to see the outlines of an argument for fearing that a plausible default outcome of the creation of machine superintelligence is existential catastrophe.
...
Second, the orthogonality thesis suggests that we cannot blithely assume that a superintelligence will necessarily share any of the final values stereotypically associated with wisdom and intellectual development in humans—scientific curiosity, benevolent concern for others, spiritual enlightenment and contemplation, renunciation of material acquisitiveness, a taste for refined culture or for the simple pleasures in life, humility and selflessness, and so forth. We will consider later whether it might be possible through deliberate effort to construct a superintelligence that values such things, or to build one that values human welfare, moral goodness, or any other complex purpose its designers might want it to serve. But it is no less possible—and in fact technically a lot easier—to build a superintelligence that places final value on nothing but calculating the decimal expansion of pi. This suggests that—absent a special effort—the first superintelligence may have some such random or reductionistic final goal.
--The orthogonality thesis and convergent instrumental goals arguments, respectively, attacked and destroyed two views which were surprisingly popular at the time: 1. that smarter AI would necessarily be good (unless we deliberately programmed it not to be) because it would be smart enough to figure out what's right, what we intended, etc. and 2. that smarter AI wouldn't lie to us, hurt us, manipulate us, take resources from us, etc. unless it wanted to (e.g. because it hates us, or because it has been programmed to kill, etc) which it probably wouldn't. I am old enough to remember talking to people who were otherwise smart and thoughtful who had views 1 and 2.
Speaking from personal experience, those views both felt obvious to me before I came across Orthogonality Thesis or Instrumental convergence.
--As for whether the default outcome is doom, the original argument makes clear that default outcome means absent any special effort to make AI good, i.e. assuming everyone just tries to make it intelligent, but no effort is spent on making it good, the outcome is likely to be doom. This is, I think, true.
It depends on what you mean by 'special effort' and 'default'. The Orthogonality thesis, instrumental convergence, and eventual fast growth together establish that if we increased intelligence while not increasing alignment, a disaster would result. That is what is correct about them. What they don't establish is how natural it is that we will increase intelligence without increasing alignment to the degree necessary to stave off disaster.
It may be the case that the particular technique for building very powerful AI that is easiest to use is a technique that makes alignment and capability increase together, so you usually get the alignment you need just in the course of trying to make your system more capable.
Depending on how you look at that possibility, you could say that's an example of the 'special effort' being not as difficult as it appeared / likely to be made by default, or that the claim is just wrong and the default outcome is not doom. I think that the criticism sees it the second way and so sees the arguments as not establishing what they are supposed to establish, and I see it the first way - there might be a further fact that says why OT and IC don't apply to AGI like they theoretically should, but the burden is on you to prove it. Rather than saying that we need evidence OT and IC will apply to AGI.
For the reasons you give, the Orthogonality thesis and instrumental convergence do shift the burden of proof to explaining why you wouldn't get misalignment, especially if progress is fast. But such reasons have been given, see e.g. this from Stuart Russell:
The first reason for optimism [about AI alignment] is that there are strong economic incentives to develop AI systems that defer to humans and gradually align themselves to user preferences and intentions. Such systems will be highly desirable: the range of behaviours they can exhibit is simply far greater than that of machines with fixed, known objectives...
And there are outside-view analogies with other technologies that suggests that by default alignment and capability do tend to covary to quite a large extent. This is a large part of Ben Garfinkel's argument.
But I do think that some people (maybe not Bostrom, based on the caveats he gave), didn't realise that they did also need to complete the argument to have a strong expectation of doom - to show that there isn't an easy, and required alignment technique that we'll have a strong incentive to use.
"A system that is optimizing a function of n variables, where the objective depends on a subset of size k<n, will often set the remaining unconstrained variables to extreme values; if one of those unconstrained variables is actually something we care about, the solution found may be highly undesirable. "
We could see this as marking out a potential danger - a large number of possible mind-designs produce very bad outcomes if implemented. The fact that such designs exist 'weakly suggest' (Ben's words) that AGI poses an existential risk since we might build them. If we add in other premises that imply we are likely to (accidentally or deliberately) build such systems, the argument becomes stronger. But usually the classic arguments simply note instrumental convergence and assume we're 'shooting into the dark' in the space of all possible minds, because they take the abstract statement about possible minds to be speaking directly about the physical world.
I also think that, especially when you bring Mesa-optimisers or recent evidence into the picture, the evidence we have so far suggests that even though alignment and capability are likely to covary to some degree (a degree higher than e.g. Bostrom expected back before modern ML), the default outcome is still misalignment.
I think that the criticism sees it the second way and so sees the arguments as not establishing what they are supposed to establish, and I see it the first way - there might be a further fact that says why OT and IC don't apply to AGI like they theoretically should, but the burden is on you to prove it. Rather than saying that we need evidence OT and IC will apply to AGI.
I agree with that burden of proof. However, we do have evidence that IC will apply, if you think we might get AGI through RL.
I think that hypothesized AI catastrophe is usually due to power-seeking behavior and instrumental drives. Iprovedthat that optimal policies are generally power-seeking in MDPs. This is a measure-based argument, and it is formally correct under broad classes of situations, like "optimal farsighted agents tend to preserve their access to terminal states" (Optimal Farsighted Agents Tend to Seek Power, §6.2 Theorem 19) and "optimal agents generally choose paths through the future that afford strictly more options" (Generalizing the Power-Seeking Theorems, Theorem 2).
The theorems aren't conclusive evidence:
maybe we don't get AGI through RL
learned policies are not going to be optimal
the results don't prove how hard it is tweak the reward function distribution, to avoid instrumental convergence (perhaps a simple approval penalty suffices! IMO: doubtful, but technically possible)
perhaps the agents inherit different mesa objectives during training
The optimality theorems + mesa optimization suggest that not only might alignment be hard because of Complexity of Value, it might also be hard for agents with very simple goals! Most final goals involve instrumental goals; agents trained through ML may stumble upon mesa optimizers, which are generalizing over these instrumental goals; the mesa optimizers are unaligned and seek power, even though the outer alignment objective was dirt-easy to specify.
But the theorems are evidence that RL leads to catastrophe at optimum, at least. We're not just talking about "the space of all possible minds and desires" anymore.
We know there are many possible AI systems (including “powerful” ones) that are not inclined toward omnicide
Any possible (at least deterministic) policy is uniquely optimal with regard to some utility function. And many possible policies do not involve omnicide.
On its own, this point is weak; reading part of his 80K talk, I do not think it is a key part of his argument. Nonetheless, here's why I think it's weak:
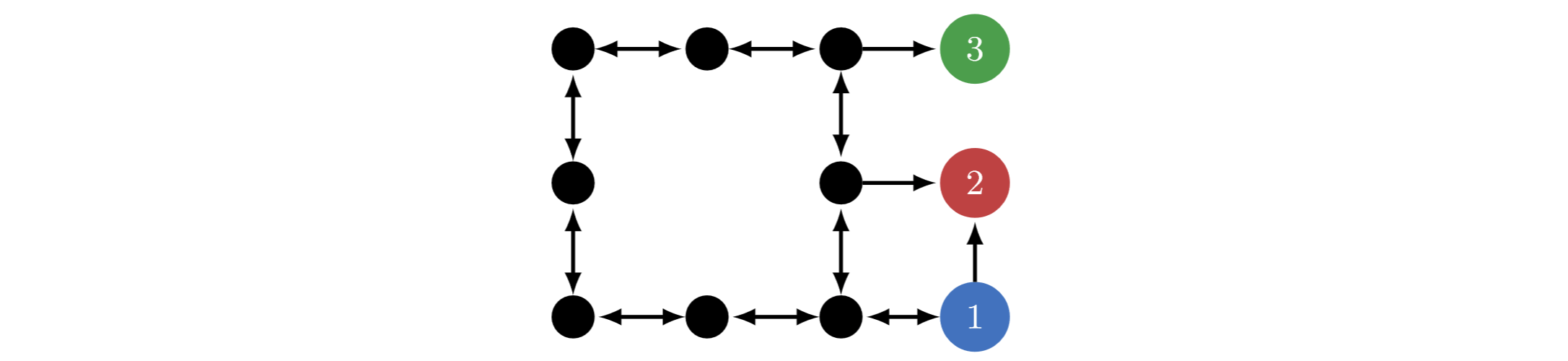
"All states have self-loops, left hidden to reduce clutter.
In AI: A Modern Approach (3e), the agent starts at 1 and receives reward for reaching 3. The optimal policy for this reward function avoids 2, and one might suspect that avoiding 2 is instrumentally convergent. However, a skeptic might provide a reward function for which navigating to 2 is optimal, and then argue that "instrumental convergence'' is subjective and that there is no reasonable basis for concluding that 2 is generally avoided.
We can do better... for any way of independently and identically distributing reward over states, 1011 of reward functions have farsighted optimal policies which avoid 2. If we complicate the MDP with additional terminal states, this number further approaches 1.
If we suppose that the agent will be forced into 2 unless it takes preventative action, then preventative policies are optimal for 1011 of farsighted agents – no matter how complex the preventative action. Taking 2 to represent shutdown, we see that avoiding shutdown is instrumentally convergent in any MDP representing a real-world task and containing a shutdown state. We argue that this is a special case of a more general phenomenon: optimal farsighted agents tend to seek power."
But the theorems are evidence that RL leads to catastrophe at optimum, at least.
RL with a randomly chosen reward leads to catastrophe at optimum.
Iprovedthat that optimal policies are generally power-seeking in MDPs.
The proof is for randomly distributed rewards.
Ben's main critique is that the goals evolve in tandem with capabilities, and goals will be determined by what humans care about. These are specific reasons to deny the conclusion of analysis of random rewards.
(A random Python program will error with near-certainty, yet somehow I still manage to write Python programs that don't error.)
I do agree that this isn't enough reason to say "there is no risk", but it surely is important for determining absolute levels of risk. (See also this comment by Ben.)
Right, it’s for randomly distributed rewards. But if I show a property holds for reward functions generically, then it isn’t necessarily enough to say “we’re going to try to try to provide goals without that property”. Can we provide reward functions without that property?
Every specific attempt so far has been seemingly unsuccessful (unless you want the AI to choose a policy at random or shut down immediately). The hope might be that future goals/capability research will help, but I’m not personally convinced that researchers will receive good Bayesian evidence via their subhuman-AI experimental results.
I agree it’s relevant that we will try to build helpful agents, and might naturally get better at that. I don’t know that it makes me feel much better about future objectives being outer aligned.
ETA: also, i was referring to the point you made when i said
“the results don't prove how hard it is tweak the reward function distribution, to avoid instrumental convergence”
Every specific attempt so far has been seemingly unsuccessful
Idk, I could say that every specific attempt made by the safety community to demonstrate risk has been seemingly unsuccessful, therefore systems must not be risky. This pretty quickly becomes an argument about priors and reference classes and such.
But I don't really think I disagree with you here. I think this paper is good, provides support for the point "we should have good reason to believe an AI system is safe, and not assume it by default", and responds to an in-fact incorrect argument of "but why would any AI want to kill us all, that's just anthropomorphizing".
But when someone says "These arguments depend on some concept of a 'random mind', but in reality it won't be random, AI researchers will fix issues and goals and capabilities will evolve together towards what we want, seems like IC may or may not apply", it seems like a response of the form "we have support for IC, not just in random minds, but also for random reward functions" has not responded to the critique and should not be expected to be convincing to that person.
Aside:
I don’t know that it makes me feel much better about future objectives being outer aligned.
I am legitimately unconvinced that it matters whether you are outer aligned at optimum. Not just being a devil's advocate here. (I am also not convinced of the negation.)
it seems like a response of the form "we have support for IC, not just in random minds, but also for random reward functions" has not responded to the critique and should not be expected to be convincing to that person.
I agree that the paper should not be viewed as anything but slight Bayesian evidence for the difficulty of real objective distributions. IIRC I was trying to reply to the point of "but how do we know IC even exists?" with "well, now we can say formal things about it and show that it exists generically, but (among other limitations) we don't (formally) know how hard it is to avoid if you try".
I find myself agreeing with the idea that an agent unaware of it's task will seek power, but also conclude that an agent aware of it's task will give-up power.
I think this is a slight misunderstanding of the theory in the paper. I'd translate the theory of the paper to English as:
If we do not know an agent's goal, but we know that the agent knows its goal and is optimal w.r.t it, then from our perspective the agent is more likely to go to higher-power states. (From the agent's perspective, there is no probability, it always executes the deterministic perfect policy for its reward function.)
Any time the paper talks about "distributions" over reward functions, it's talking from our perspective. The way the theory does this is by saying that first a reward function is drawn from the distribution, then it is given to the agent, then the agent thinks really hard, and then the agent executes the optimal policy. All of the theoretical analysis in the paper is done "before" the reward function is drawn, but there is no step where the agent is doing optimization but doesn't know its reward.
In your paper, theorem 19 suggests that given a choice between two sets of 1-cycles C1 and C2 the agent is more likely to select the larger set.
I'd rewrite this as:
Theorem 19 suggests that, if an agent that knows its reward is about to choose between C1 and C2, but we don't know the reward and our prior is that it is uniformly distributed, then we will assign higher probability to the agent going to the larger set.
I do not see how the agent 'seeks' out powerful states because, as you say, the agent is fixed.
I do think this is mostly a matter of translation of math to English being hard. Like, when Alex says "optimal agents seek power", I think you should translate it as "when we don't know what goal an optimal agent has, we should assign higher probability that it will go to states that have higher power", even though the agent itself is not thinking "ah, this state is powerful, I'll go there".
Great observation. Similarly, a hypothesis called "Maximum Causal Entropy" once claimed that physical systems involving intelligent actors tended tended towards states where the future could be specialized towards many different final states, and that maybe this was even part of what intelligence was. However, people objected: (monogamous) individuals don't perpetually maximize their potential partners -- they actually pick a partner, eventually.
My position on the issue is: most agents steer towards states which afford them greater power, and sometimes most agents give up that power to achieve their specialized goals. The point, however, is that they end up in the high-power states at some point in time along their optimal trajectory. I imagine that this is sufficient for the catastrophic power-stealing incentives: the AI only has to disempower us once for things to go irreversibly wrong.
If there's a collection of 'turned-off' terminal states where the agent receives no further reward for all time then every optimized policy will try to avoid such a state.
To clarify, I don't assume that. The terminal states, even those representing the off-switch, also have their reward drawn from the same distribution. When you distribute reward IID over states, the off-state is in fact optimal for some low-measure subset of reward functions.
But, maybe you're saying "for realistic distributions, the agent won't get any reward for being shut off and therefore π∗ won't ever let itself be shut off". I agree, and this kind of reasoning is captured by Theorem 3 of Generalizing the Power-Seeking Theorems. The problem is that this is just a narrow example of the more general phenomenon. What if we add transient "obedience" rewards, what then? For some level of farsightedness (γ close enough to 1), the agent will still disobey, and simultaneously disobedience gives it more control over the future.
The paper doesn't draw the causal diagram "Power → instrumental convergence", it gives sufficient conditions for power-seeking being instrumentally convergent. Cycle reachability preservation is one of those conditions.
In general, I'd suspect that there are goals we could give the agent that significantly reduce our gain. However, I'd also suspect the opposite.
Yes, right. The point isn't that alignment is impossible, but that you have to hit a low-measure set of goals which will give you aligned or non-power-seeking behavior. The paper helps motivate why alignment is generically hard and catastrophic if you fail.
It seems reasonable to argue that we would if we could guarantee r=h.
Yes, if r=h, introduce the agent. You can formalize a kind of "alignment capability" by introducing a joint distribution over the human's goals and the induced agent goals (preliminary Overleaf notes). So, if we had goal X, we'd implement an agent with goal X', and so on. You then take our expected optimal value under this distribution and find whether you're good at alignment, or whether you're bad and you'll build agents whose optimal policies tend to obstruct you.
There might be a way to argue over randomness and say this would double our gain.
The doubling depends on the environment structure. There are game trees and reward functions where this holds, and some where it doesn't.
More speculatively, what if |r−h|<ϵ?
If the rewards are ϵ-close in sup-norm, then you can get nice regret bounds, sure.
Great question. One thing you could say is that an action is power-seeking compared to another, if your expected (non-dominated subgraph; see Figure 19) power is greater for that action than for the other.
Power is kinda weird when defined for optimal agents, as you say - when γ=1, POWER can only decrease. See Power as Easily Exploitable Opportunities for more on this.
My understanding of figure 7 of your paper indicates that cycle reachability cannot be a sufficient condition.
Shortly after Theorem 19, the paper says: "In appendix C.6.2, we extend this reasoning to k-cycles (k >1) via theorem 53 and explain how theorem19 correctly handles fig. 7". In particular, see Figure 19.
The key insight is that Theorem 19 talks about how many agents end up in a set of terminal states, not how many go through a state to get there. If you have two states with disjoint reachable terminal state sets, you can reason about the phenomenon pretty easily. Practically speaking, this should often suffice: for example, the off-switch state is disjoint from everything else.
If not, you can sometimes consider the non-dominated subgraph in order to regain disjointness. This isn't in the main part of the paper, but basically you toss out transitions which aren't part of a trajectory which is strictly optimal for some reward function. Figure 19 gives an example of this.
The main idea, though, is that you're reasoning about what the agent's end goals tend to be, and then say "it's going to pursue some way of getting there with much higher probability, compared to this small set of terminal states (ie shutdown)". Theorem 17 tells us that in the limit, cycle reachability totally controls POWER.
I think I still haven't clearly communicated all my mental models here, but I figured I'd write a reply now while I update the paper.
Thank you for these comments, by the way. You're pointing out important underspecifications. :)
My philosophy is that aligned/general is OK based on a shared (?) premise that,
I think one problem is that power-seeking agents are generally not that corrigible, which means outcomes are extremely sensitive to the initial specification.
I agree that this is the biggest concern with these models, and the GPT-n series running out of steam wouldn't be a huge relief. It looks likely that we'll have the first human-scale (in terms of parameters) NNs before 2026 - Metaculus, 81% as of 13.08.2020.
Does anybody know of any work that's analysing the rate at which, once the first NN crosses the n-parameter barrier, other architectures are also tried at that scale? If no-one's done it yet, I'll have a look at scraping the data from Papers With Code's databases on e.g. ImageNet models, it might be able to answer your question on how many have been tried at >100B as well.
I think GPT-N is definitely not aligned, for mesa-optimizer reasons. It'll be some unholy being with a superhuman understanding of all the different types of humans, all the different parts of the internet, all the different kinds of content and style... but it won't itself be human, or anything close.
Of course, it's also not outer-aligned in Evan's sense, because of the universal prior being malign etc.
As for planning, we've seen the GPTs ascend from planning out the next few words, to planning out the sentence or line, to planning out the paragraph or stanza. Planning out a whole text interaction is well within the scope I could imagine for the next few iterations, and from there you have the capability of manipulation without external malicious use.
Perhaps a nitpick, but is what it does planning?
Is it actually thinking several words ahead (a la AlphaZero evaluating moves) when it decides what word to say next, or is it just doing free-writing, and it just happens to be so good at coming up with words that fit with what's come before that it ends up looking like a planned out text?
You might argue that if it ends up as-good-as-planned, then it doesn't make a difference if it was actually planned or not. But it seems to me like it does make a difference. If it has actually learned some internal planning behavior, then that seems more likely to be dangerous and to generalize to other kinds of planning.
Upon reflection, the structured sentences, thematically resolved paragraphs, and even JSX code can be done without a lot of real lookahead. And there's some evidence it's not doing lookahead - its difficulty completing rhymes when writing poetry, for instance.
(Hmm, what's the simplest game that requires lookahead that we could try to teach to GPT-3, such that it couldn't just memorize moves?)
Thinking about this more, I think that since planning depends on causal modeling, I'd expect the latter to get good before the former. But I probably overstated the case for its current planning capabilities, and I'll edit accordingly. Thanks!
I have to further compliment my past self: this section aged extremely well, prefiguring the Shoggoth-with-a-smiley-face analogies several years in advance.
GPT-3 is trained simply to predict continuations of text. So what would it actually optimize for, if it had a pretty good model of the world including itself and the ability to make plans in that world?
One might hope that because it's learning to imitate humans in an unsupervised way, that it would end up fairly human, or at least act in that way. I very much doubt this, for the following reason:
Two humans are fairly similar to each other, because they have very similar architectures and are learning to succeed in the same environment.
A mimic species will be similar in some ways but not others to the species it mimics, because even if they share recent ancestry, the environmental pressures on the poisonous one are different from the environmental pressures on the mimic.
What we have with the GPTs is the first deep learning architecture we've found that scales this well in the domain (so, probably not that much like our particular architecture), learning to mimic humans rather than growing in an environment with similar pressures. Why should we expect it to be anything but very alien under the hood, or to continue acting human once its actions take us outside of the training distribution?
Moreover, there may be much more going on under the hood than we realize; it may take much more general cognitive power to learn and imitate the patterns of humans, than it requires us to execute those patterns.
You're careful here to talk about transformative AI rather than AGI, and I think that's right. GPT-N does seem like it stands to have transformative effects without necessarily being AGI, and that is quite worrisome. I think many of us expected to find ourselves in a world where AGI was primarily what we had to worry about, and instead we're in a world where "lesser" AI is on track to be powerful enough to dramatically change society. Or at least, so it seems from where we stand, extracting out the trends.
There are some posts with perennial value, and some which depend heavily on their surrounding context. This post is of the latter type. I think it was pretty worthwhile in its day (and in particular, the analogy between GPT upgrades and developmental stages is one I still find interesting), but I leave it to you whether the book should include time capsules like this.
I suspect that you cannot get this out of small large amounts of gradient descent on small large layered transformers, and therefore I suspect that GPT-N does not approach superintelligence before the world is ended by systems that look differently, but I could be wrong about that.
I unpack this as the claim that someone will always be working on directly goal-oriented AI development, and that inner optimizers in an only-indirectly-goal-oriented architecture like GPT-N will take enough hardware that someone else will have already built an outer optimizer by the time it happens.
That sounds reasonable, it's a consideration I'd missed at the time, and I'm sure that OpenAI-sized amounts of money will be paid into more goal-oriented natural language projects adapted to whatever paradigm is prominent at the time. But I still agree with Eliezer's "but I could be wrong" here.
As I argued here, I think GPT-3 is more likely to be aligned than whatever we might do with CIRL/IDA/Debate ATM, since it is trained with (self)-supervised learning and gradient descent.
The main reason such a system could pose an x-risk by itself seems to be mesa-optimization, so studying mesa-optimization in the context of such systems is a priority (esp. since GPT-3's 0-shot learning looks like mesa-optimization).
In my mind, things like IDA become relevant when we start worrying about remaining competitive with agent-y systems built using self-supervised learning systems as a component, but actually come with a safety cost relative to SGD-based self-supervised learning.
This is less the case when we think about them as methods for increasing interpretability, as opposed to increasing capabilities (which is how I've mostly seen them framed recently, a la the complexity theory analogies).
I'm still thinking about the point you made in the other subthread about MAML. It seems very plausible to me that GPT is doing MAML type stuff. I'm still thinking about if/how that could result in dangerous mesa-optimization.
esp. since GPT-3's 0-shot learning looks like mesa-optimization
Could you provide more details on this?
Sometimes people will give GPT-3 a prompt with some examples of inputs along with the sorts of responses they'd like to see from GPT-3 in response to those inputs ("few-shot learning", right? I don't know what 0-shot learning you're referring to.) Is your claim that GPT-3 succeeds at this sort of task by doing something akin to training a model internally?
If that's what you're saying... That seems unlikely to me. GPT-3 is essentially a stack of 96 transformers right? So if it was doing something like gradient descent internally, how many consecutive iterations would it be capable of doing? It seems more likely to me that GPT-3 is simply able to learn sufficiently rich internal representations such that when the input/output examples are within its context window, it picks up their input/output structure and forms a sufficiently sophisticated conception of that structure that the word that scores highest according to next-word prediction is a word that comports with the structure.
96 transformers would appear to offer a very limited budget for any kind of serial computation, but there's a lot of parallel computation going on there, and there are non-gradient-descent optimization algorithms, genetic algorithms say, that can be parallelized. I guess the query matrix could be used to implement some kind of fitness function? It would be interesting to try some kind of layer-wise pretraining on transformer blocks and train them to compute steps in a parallelizable optimization algorithm (probably you'd want to pick a deterministic algorithm which is parallelizable instead of a stochastic algorithm like genetic algorithms). Then you could look at the resulting network and based on it, try to figure out what the telltale signs of a mesa-optimizer are (since this network is almost certainly implementing a mesa-optimizer).
Still, my impression is you need 1000+ generations to get interesting results with genetic algorithms, which seems like a lot of serial computation relative to GPT-3's budget...
Sometimes people will give GPT-3 a prompt with some examples of inputs along with the sorts of responses they'd like to see from GPT-3 in response to those inputs ("few-shot learning", right? I don't know what 0-shot learning you're referring to.)
No, that's zero-shot. Few shot is when you train on those instead of just stuffing them into the context.
It looks like mesa-optimization because it seems to be doing something like learning about new tasks or new prompts that are very different from anything its seen before, without any training, just based on the context (0-shot).
Is your claim that GPT-3 succeeds at this sort of task by doing something akin to training a model internally?
By "training a model", I assume you mean "a ML model" (as opposed to, e.g. a world model). Yes, I am claiming something like that, but learning vs. inference is a blurry line.
I'm not saying it's doing SGD; I don't know what it's doing in order to solve these new tasks. But TBC, 96 steps of gradient descent could be a lot. MAML does meta-learning with 1.
Next, we might imagine GPT-N to just be an Oracle AI, which we would have better hopes of using well. But I don't expect that an approximate Oracle AI could be used safely with anything like the precautions that might work for a genuine Oracle AI. I don't know what internal optimizers GPT-N ends up building along the way, but I'm not going to count on there being none of them.
Is the distinguishing feature between Oracle AI and approximate Oracle AI, as you use the terms here, just about whether there are inner optimizers or not?
(When I started the paragraph I assumed "approximate Oracle AI" just meant an Oracle AI whose predictions aren't very reliable. Given how the paragraph ends though, I conclude that whether there are inner optimizers is an important part of the distinction you're drawing. But I'm just not sure if it's the whole of the distinction or not.)
The outer optimizer is the more obvious thing: it's straightforward to say there's a big difference in dealing with a superhuman Oracle AI with only the goal of answering each question accurately, versus one whose goals are only slightly different from that in some way. Inner optimizers are an illustration of another failure mode.
The outer optimizer is the more obvious thing: it's straightforward to say there's a big difference in dealing with a superhuman Oracle AI with only the goal of answering each question accurately, versus one whose goals are only slightly different from that in some way.
GPT generates text by repeatedly picking whatever word seems highest probability given all the words that came before. So if its notion of "highest probability" is almost, but not quite, answering every question accurately, I would expect a system which usually answers questions accurately but sometimes answers them inaccurately. That doesn't sound very scary?
Epistemic Status: I only know as much as anyone else in my reference class (I build ML models, I can grok the GPT papers, and I don't work for OpenAI or a similar lab). But I think my thesis is original.
Related: Gwern on GPT-3
For the last several years, I've gone around saying that I'm worried about transformative AI, an AI capable of making an Industrial Revolution sized impact (the concept is agnostic on whether it has to be AGI or self-improving), because I think we might be one or two cognitive breakthroughs away from building one.
GPT-3 has made me move up my timelines, because it makes me think we might need zero more cognitive breakthroughs, just more refinement / efficiency / computing power: basically, GPT-6 or GPT-7 might do it. My reason for thinking this is comparing GPT-3 to GPT-2, and reflecting on what the differences say about the "missing pieces" for transformative AI.
My Thesis:
The difference between GPT-2 and GPT-3 has made me suspect that there's a legitimate comparison to be made between the scale of a network architecture like the GPTs, and some analogue of "developmental stages" of the resulting network. Furthermore, it's plausible to me that the functions needed to be a transformative AI are covered by a moderate number of such developmental stages, without requiring additional structure. Thus GPT-N would be a transformative AI, for some not-too-large N, and we need to redouble our efforts on ways to align such AIs.
The thesis doesn't strongly imply that we'll reach transformative AI via GPT-N especially soon; I have wide uncertainty, even given the thesis, about how large we should expect N to be, and whether the scaling of training and of computation slows down progress before then. But it's also plausible to me now that the timeline is only a few years, and that no fundamentally different approach will succeed before then. And that scares me.
Architecture and Scaling
GPT, GPT-2, and GPT-3 use nearly the same architecture; each paper says as much, with a sentence or two about minor improvements to the individual transformers. Model size (and the amount of training computation) is really the only difference.
GPT took 1 petaflop/s-day to train 117M parameters, GPT-2 took 10 petaflop/s-days to train 1.5B parameters, and the largest version of GPT-3 took 3,000 petaflop/s-days to train 175B parameters. By contrast, AlphaStar seems to have taken about 30,000 petaflop/s-days of training in mid-2019, so the pace of AI research computing power projects that there should be about 10x that today. The upshot is that OpenAI may not be able to afford it, but if Google really wanted to make GPT-4 this year, they could afford to do so.
Analogues to Developmental Stages
There are all sorts of (more or less well-defined) developmental stages for human beings: image tracking, object permanence, vocabulary and grammar, theory of mind, size and volume, emotional awareness, executive functioning, et cetera.
I was first reminded of developmental stages a few years ago, when I saw the layers of abstraction generated in this feature visualization tool for GoogLeNet.
We don't have feature visualization for language models, but we do have generative outputs. And as you scale up an architecture like GPT, you see higher levels of abstraction. Grammar gets mastered, then content (removing absurd but grammatical responses), then tone (first rough genre, then spookily accurate authorial voice). Topic coherence is mastered first on the phrase level, then the sentence level, then the paragraph level. So too with narrative flow.
Gwern's poetry experiments (GPT-2, GPT-3) are good examples. GPT-2 could more or less continue the meter of a poem and use words that fit the existing theme, but even its best efforts can get stuck in topic loops:
Or:
GPT-3, though, has the sense of going somewhere, at least on the topic level. (Prompts in bold.)
[EDIT: Previously I also included its completion of a famous Emily Dickinson poem here, but as benkuhn pointed out, GPT-3 had simply memorized the poem and recited it. I'm really embarrassed, and also kind of shocked that I looked at the actual text of "Because I could not stop for Death" and thought, "yup, that looks like something GPT-3 could produce".]
(One last shocking bit is that, while GPT-2 had to be fine-tuned by taking the general model and training it some more on a poetry-only dataset, you're seeing what GPT-3's model does with no fine-tuning, with just a prompt that sounds poetic!)
Similarly, GPT-3's ability to write fiction is impressive- unlike GPT-2, it doesn't lose track of the plot, it has sensible things happen, it just can't plan its way to a satisfying resolution.
I'd be somewhat surprised if GPT-4 shared that last problem.
What's Next?
How could one of the GPTs become a transformative AI, even if it becomes a better and better imitator of human prose style? Sure, we can imagine it being used maliciously to auto-generate targeted misinformation or things of that sort, but that's not the real risk I'm worrying about here.
My real worry is that causal inference and planning are starting to look more and more like plausible developmental stages that GPT-3 is moving towards, and that these were exactly the things I previously thought were the obvious obstacles between current AI paradigms and transformative AI.
Learning causal inference from observations doesn't seem qualitatively different from learning arithmetic or coding from examples (and not only is GPT-3 accurate at adding three-digit numbers, but apparently at writing JSX code to spec), only more complex in degree.
One might claim that causal inference is harder to glean from language-only data than from direct observation of the physical world, but that's a moot point, as OpenAI are using the same architecture to learn how to infer the rest of an image from one part.
Planning is more complex to assess. We've seen GPTs ascend from coherence of the next few words, to the sentence or line, to the paragraph or stanza, and we've even seen them write working code. But this can be done without planning; GPT-3 may simply have a good enough distribution over next words to prune out those that would lead to dead ends. (On the other hand, how sure are we that that's not the same as planning, if planning is just pruning on a high enough level of abstraction?)
The bigger point about planning, though, is that the GPTs are getting feedback on one word at a time in isolation. It's hard for them to learn not to paint themselves into a corner. It would make training more finicky and expensive if we expanded the time horizon of the loss function, of course. But that's a straightforward way to get the seeds of planning, and surely there are other ways.
With causal modeling and planning, you have the capability of manipulation without external malicious use. And the really worrisome capability comes when it models its own interactions with the world, and makes plans with that taken into account.
Could GPT-N turn out aligned, or at least harmless?
GPT-3 is trained simply to predict continuations of text. So what would it actually optimize for, if it had a pretty good model of the world including itself and the ability to make plans in that world?
One might hope that because it's learning to imitate humans in an unsupervised way, that it would end up fairly human, or at least act in that way. I very much doubt this, for the following reason:
What we have with the GPTs is the first deep learning architecture we've found that scales this well in the domain (so, probably not that much like our particular architecture), learning to mimic humans rather than growing in an environment with similar pressures. Why should we expect it to be anything but very alien under the hood, or to continue acting human once its actions take us outside of the training distribution?
Moreover, there may be much more going on under the hood than we realize; it may take much more general cognitive power to learn and imitate the patterns of humans, than it requires us to execute those patterns.
Next, we might imagine GPT-N to just be an Oracle AI, which we would have better hopes of using well. But I don't expect that an approximate Oracle AI could be used safely with anything like the precautions that might work for a genuine Oracle AI. I don't know what internal optimizers GPT-N ends up building along the way, but I'm not going to count on there being none of them.
I don't expect that GPT-N will be aligned or harmless by default. And if N isn't that large before it gets transformative capacity, that's simply terrifying.
What Can We Do?
While the short timeline suggested by the thesis is very bad news from an AI safety readiness perspective (less time to come up with better theoretical approaches), there is one silver lining: it at least reduces the chance of a hardware overhang. A project or coalition can feasibly wait and take a better-aligned approach that uses 10x the time and expense of an unaligned approach, as long as they have that amount of resource advantage over any competitor.
Unfortunately, the thesis also makes it less likely that a fundamentally different architecture will reach transformative status before something like GPT does.
I don't want to take away from MIRI's work (I still support them, and I think that if the GPTs peter out, we'll be glad they've been continuing their work), but I think it's an essential time to support projects that can work for a GPT-style near-term AGI, for instance by incorporating specific alignment pressures during training. Intuitively, it seems as if Cooperative Inverse Reinforcement Learning or AI Safety via Debate or Iterated Amplification are in this class.
We may also want to do a lot of work on how better to mold a GPT-in-training into the shape of an Oracle AI.
It would also be very useful to build some GPT feature "visualization" tools ASAP.
In the meantime, uh, enjoy AI Dungeon, I guess?