A bunch of this was frustrating to read because it seemed like Paul was yelling "we should model continuous changes!" and Eliezer was yelling "we should model discrete events!" and these were treated as counter-arguments to each other.
It seems obvious from having read about dynamical systems that continuous models still have discrete phase changes. E.g. consider boiling water. As you put in energy the temperature increases until it gets to the boiling point, at which point more energy put in doesn't increase the temperature further (for a while), it converts more of the water to steam; after all the water is converted to steam, more energy put in increases the temperature further.
So there are discrete transitions from (a) energy put in increases water temperature to (b) energy put in converts water to steam to (c) energy put in increases steam temperature.
In the case of AI improving AI vs. humans improving AI, a simple model to make would be one where AI quality is modeled as a variable, , with the following dynamical equation:
where is the speed at which humans improve AI and is a recursive self-improvement efficiency factor. The curve transitions from a line at early times (where ) to an exponential at later times (where ). It could be approximated as a piecewise function with a linear part followed by an exponential part, which is a more-discrete approximation than the original function, which has a continuous transition between linear and exponential.
This is nowhere near an adequate model of AI progress, but it's the sort of model that would be created in the course of a mathematically competent discourse on this subject on the way to creating an adequate model.
Dynamical systems contains many beautiful and useful concepts like basins of attraction which make sense of discrete and continuous phenomena simultaneously (i.e. there are a discrete number of basins of attraction which points fall into based on their continuous properties).
I've found Strogatz's book, Nonlinear Dynamics and Chaos, helpful for explaining the basics of dynamical systems.
I don’t really feel like anything you are saying undermines my position here, or defends the part of Eliezer’s picture I’m objecting to.
(ETA: but I agree with you that it's the right kind of model to be talking about and is good to bring up explicitly in discussion. I think my failure to do so is mostly a failure of communication.)
I usually think about models that show the same kind of phase transition you discuss, though usually significantly more sophisticated models and moving from exponential to hyperbolic growth (you only get an exponential in your model because of the specific and somewhat implausible functional form for technology in your equation).
With humans alone I expect efficiency to double roughly every year based on the empirical returns curves, though it depends a lot on the trajectory of investment over the coming years. I've spent a long time thinking and talking with people about these issues.
At the point when the work is largely done by AI, I expect progress to be maybe 2x faster, so doubling every 6 months. And them from there I expect a roughly hyperbolic trajectory over successive doublings.
If takeoff is fast I still expect it to most likely be through a similar situation, where e.g. total human investment in AI R&D never grows above 1% and so at the time when takeoff occurs the AI companies are still only 1% of the economy.
(I'm interested in which of my claims seem to dismiss or not adequately account for the possibility that continuous systems have phase changes.)
This section seemed like an instance of you and Eliezer talking past each other in a way that wasn't locating a mathematical model containing the features you both believed were important (e.g. things could go "whoosh" while still being continuous):
[Christiano][13:46]
Even if we just assume that your AI needs to go off in the corner and not interact with humans, there’s still a question of why the self-contained AI civilization is making ~0 progress and then all of a sudden very rapid progress
[Yudkowsky][13:46]
unfortunately a lot of what you are saying, from my perspective, has the flavor of, “but can’t you tell me about your predictions earlier on of the impact on global warming at the Homo erectus level”
you have stories about why this is like totally not a fair comparison
I do not share these stories
[Christiano][13:46]
I don’t understand either your objection nor the reductio
like, here’s how I think it works: AI systems improve gradually, including on metrics like “How long does it take them to do task X?” or “How high-quality is their output on task X?”
[Yudkowsky][13:47]
I feel like the thing we know is something like, there is a sufficiently high level where things go whooosh humans-from-hominids style
[Christiano][13:47]
We can measure the performance of AI on tasks like “Make further AI progress, without human input”
Any way I can slice the analogy, it looks like AI will get continuously better at that task
My claim is that the timescale of AI self-improvement, at the point it takes over from humans, is the same as the previous timescale of human-driven AI improvement. If it was a lot faster, you would have seen a takeover earlier instead.
This claim is true in your model. It also seems true to me about hominids, that is I think that cultural evolution took over roughly when its timescale was comparable to the timescale for biological improvements, though Eliezer disagrees
I thought Eliezer's comment "there is a sufficiently high level where things go whooosh humans-from-hominids style" was missing the point. I think it might have been good to offer some quantitative models at that point though I haven't had much luck with that.
I can totally grant there are possible models for why the AI moves quickly from "much slower than humans" to "much faster than humans," but I wanted to get some model from Eliezer to see what he had in mind.
(I find fast takeoff from various frictions more plausible, so that the question mostly becomes one about how close we are to various kinds of efficient frontiers, and where we respectively predict civilization to be adequate/inadequate or progress to be predictable/jumpy.)
+1 on using dynamical systems models to try to formalize the frameworks in this debate. I also give Eliezer points for trying to do something similar in Intelligence Explosion Microeconomics (and to people who have looked at this from the macro perspective).
I feel like the biggest subjective thing is that I don't feel like there is a "core of generality" that GPT-3 is missing
I just expect it to gracefully glide up to a human-level foom-ing intelligence
This is a place where I suspect we have a large difference of underlying models. What sort of surface-level capabilities do you, Paul, predict that we might get (or should not get) in the next 5 years from Stack More Layers? Particularly if you have an answer to anything that sounds like it's in the style of Gwern's questions, because I think those are the things that actually matter and which are hard to predict from trendlines and which ought to depend on somebody's model of "what kind of generality makes it into GPT-3's successors".
If you give me 1 or 10 examples of surface capabilities I'm happy to opine. If you want me to name industries or benchmarks, I'm happy to opine on rates of progress. I don't like the game where you say "Hey, say some stuff. I'm not going to predict anything and I probably won't engage quantitatively with it since I don't think much about benchmarks or economic impacts or anything else that we can even talk about precisely in hindsight for GPT-3."
I don't even know which of Gwern's questions you think are interesting/meaningful. "Good meta-learning"--I don't know what this means but if actually ask a real question I can guess. Qualitative descriptions---what is even a qualitative description of GPT-3? "Causality"---I think that's not very meaningful and will be used to describe quantitative improvements at some level made up by the speaker. The spikes in capabilities Gwern talks about seem to be basically measurement artifacts, but if you want to describe a particular measurements I can tell you whether they will have similar artifacts. (How much economic value I can talk about, but you don't seem interested.)
Mostly, I think the Future is not very predictable in some ways, and this extends to, for example, it being the possible that 2022 is the year where we start Final Descent and by 2024 it's over, because it so happened that although all the warning signs were Very Obvious In Retrospect they were not obvious in antecedent and so stuff just started happening one day. The places where I dare to extend out small tendrils of prediction are the rare exception to this rule; other times, people go about saying, "Oh, no, it definitely couldn't start in 2022" and then I say "Starting in 2022 would not surprise me" by way of making an antiprediction that contradicts them. It may sound bold and startling to them, but from my own perspective I'm just expressing my ignorance. That's one reason why I keep saying, if you think the world more orderly than that, why not opine on it yourself to get the Bayes points for it - why wait for me to ask you?
If you ask me to extend out a rare tendril of guessing, I might guess, for example, that it seems to me that GPT-3's current text prediction-hence-production capabilities are sufficiently good that it seems like somewhere inside GPT-3 must be represented a level of understanding which seems like it should also suffice to, for example, translate Chinese to English or vice-versa in a way that comes out sounding like a native speaker, and being recognized as basically faithful to the original meaning. We haven't figured out how to train this input-output behavior using loss functions, but gradient descent on stacked layers the size of GPT-3 seems to me like it ought to be able to find that functional behavior in the search space, if we knew how to apply the amounts of compute we've already applied using the right loss functions.
So there's a qualitative guess at a surface capability we might see soon - but when is "soon"? I don't know; history suggests that even what predictably happens later is extremely hard to time. There are subpredictions of the Yudkowskian imagery that you could extract from here, including such minor and perhaps-wrong but still suggestive implications like, "170B weights is probably enough for this first amazing translator, rather than it being a matter of somebody deciding to expend 1.7T (non-MoE) weights, once they figure out the underlying setup and how to apply the gradient descent" and "the architecture can potentially look like somebody Stacked More Layers and like it didn't need key architectural changes like Yudkowsky suspects may be needed to go beyond GPT-3 in other ways" and "once things are sufficiently well understood, it will look clear in retrospect that we could've gotten this translation ability in 2020 if we'd spent compute the right way".
It is, alas, nowhere written in this prophecy that we must see even more un-Paul-ish phenomena, like translation capabilities taking a sudden jump without intermediates. Nothing rules out a long wandering road to the destination of good translation in which people figure out lots of little things before they figure out a big thing, maybe to the point of nobody figuring out until 20 years later the simple trick that would've gotten it done in 2020, a la ReLUs vs sigmoids. Nor can I say that such a thing will happen in 2022 or 2025, because I don't know how long it takes to figure out how to do what you clearly ought to be able to do.
I invite you to express a different take on machine translation; if it is narrower, more quantitative, more falsifiable, and doesn't achieve this just by narrowing its focus to metrics whose connection to the further real-world consequences is itself unclear, and then it comes true, you don't need to have explicitly bet against me to have gained more virtue points.
I'm mostly not looking for virtue points, I'm looking for: (i) if your view is right then I get some kind of indication of that so that I can take it more seriously, (ii) if your view is wrong then you get some indication feedback to help snap you out of it.
I don't think it's surprising if a GPT-3 sized model can do relatively good translation. If talking about this prediction, and if you aren't happy just predicting numbers for overall value added from machine translation, I'd kind of like to get some concrete examples of mediocre translations or concrete problems with existing NMT that you are predicting can be improved.
It seems like Eliezer is mostly just more uncertain about the near future than you are, so it doesn't seem like you'll be able to find (ii) by looking at predictions for the near future.
It seems to me like Eliezer rejects a lot of important heuristics like "things change slowly" and "most innovations aren't big deals" and so on. One reason he may do that is because he literally doesn't know how to operate those heuristics, and so when he applies them retroactively they seem obviously stupid. But if we actually walked through predictions in advance, I think he'd see that actual gradualists are much better predictors than he imagines.
That seems a bit uncharitable to me. I doubt he rejects those heuristics wholesale. I'd guess that he thinks that e.g. recursive self improvement is one of those things where these heuristics don't apply, and that this is foreseeable because of e.g. the nature of recursion. I'd love to hear more about what sort of knowledge about "operating these heuristics" you think he's missing!
Anyway, it seems like he expects things to seem more-or-less gradual up until FOOM, so I think my original point still applies: I think his model would not be "shaken out" of his fast-takeoff view due to successful future predictions (until it's too late).
He says things like AlphaGo or GPT-3 being really surprising to gradualists, suggesting he thinks that gradualism only works in hindsight.
I agree that after shaking out the other disagreements, we could just end up with Eliezer saying "yeah but automating AI R&D is just fundamentally unlike all the other tasks to which we've applied AI" (or "AI improving AI will be fundamentally unlike automating humans improving AI") but I don't think that's the core of his position right now.
I agree we seem to have some kind of deeper disagreement here.
I think stack more layers + known training strategies (nothing clever) + simple strategies for using test-time compute (nothing clever, nothing that doesn't use the ML as a black box) can get continuous improvements in tasks like reasoning (e.g. theorem-proving), meta-learning (e.g. learning to learn new motor skills), automating R&D (including automating executing ML experiments, or proposing new ML experiments), or basically whatever.
I think these won't get to human level in the next 5 years. We'll have crappy versions of all of them. So it seems like we basically have to get quantitative. If you want to talk about something we aren't currently measuring, then that probably takes effort, and so it would probably be good if you picked some capability where you won't just say "the Future is hard to predict." (Though separately I expect to make somewhat better predictions than you in most of these domains.)
A plausible example is that I think it's pretty likely that in 5 years, with mere stack more layers + known techniques (nothing clever), you can have a system which is clearly (by your+my judgment) "on track" to improve itself and eventually foom, e.g. that can propose and evaluate improvements to itself, whose ability to evaluate proposals is good enough that it will actually move in the right direction and eventually get better at the process, etc., but that it will just take a long time for it to make progress. I'd guess that it looks a lot like a dumb kid in terms of the kind of stuff it proposes and its bad judgment (but radically more focused on the task and conscientious and wise than any kid would be). Maybe I think that's 10% unconditionally, but much higher given a serious effort. My impression is that you think this is unlikely without adding in some missing secret sauce to GPT, and that my picture is generally quite different from your criticallity-flavored model of takeoff.
Found two Eliezer-posts from 2016 (on Facebook) that I feel helped me better grok his perspective.
It is amazing that our neural networks work at all; terrifying that we can dump in so much GPU power that our training methods work at all; and the fact that AlphaGo can even exist is still blowing my mind. It's like watching a trillion spiders with the intelligence of earthworms, working for 100,000 years, using tissue paper to construct nuclear weapons.
And earlier, Jan. 27, 2016:
People occasionally ask me about signs that the remaining timeline might be short. It's very easy for nonprofessionals to take too much alarm too easily. Deep Blue beating Kasparov at chess was not such a sign. Robotic cars are not such a sign.
This is.
"Here we introduce a new approach to computer Go that uses ‘value networks’ to evaluate board positions and ‘policy networks’ to select moves... Without any lookahead search, the neural networks play Go at the level of state-of-the-art Monte Carlo tree search programs that simulate thousands of random games of self-play. We also introduce a new search algorithm that combines Monte Carlo simulation with value and policy networks. Using this search algorithm, our program AlphaGo achieved a 99.8% winning rate against other Go programs, and defeated the human European Go champion by 5 games to 0."
Repeat: IT DEFEATED THE EUROPEAN GO CHAMPION 5-0.
As the authors observe, this represents a break of at least one decade faster than trend in computer Go.
This matches something I've previously named in private conversation as a warning sign - sharply above-trend performance at Go from a neural algorithm. What this indicates is not that deep learning in particular is going to be the Game Over algorithm. Rather, the background variables are looking more like "Human neural intelligence is not that complicated and current algorithms are touching on keystone, foundational aspects of it." What's alarming is not this particular breakthrough, but what it implies about the general background settings of the computational universe.
To try spelling out the details more explicitly, Go is a game that is very computationally difficult for traditional chess-style techniques. Human masters learn to play Go very intuitively, because the human cortical algorithm turns out to generalize well. If deep learning can do something similar, plus (a previous real sign) have a single network architecture learn to play loads of different old computer games, that may indicate we're starting to get into the range of "neural algorithms that generalize well, the way that the human cortical algorithm generalizes well".
This result also supports that "Everything always stays on a smooth exponential trend, you don't get discontinuous competence boosts from new algorithmic insights" is false even for the non-recursive case, but that was already obvious from my perspective. Evidence that's more easily interpreted by a wider set of eyes is always helpful, I guess.
Next sign up might be, e.g., a similar discontinuous jump in machine programming ability - not to human level, but to doing things previously considered impossibly difficult for AI algorithms.
I hope that everyone in 2005 who tried to eyeball the AI alignment problem, and concluded with their own eyeballs that we had until 2050 to start really worrying about it, enjoyed their use of whatever resources they decided not to devote to the problem at that time.
Some thinking-out-loud on how I'd go about looking for testable/bettable prediction differences here...
I think my models overlap mostly with Eliezer's in the relevant places, so I'll use my own models as a proxy for his, and think about how to find testable/bettable predictions with Paul (or Ajeya, or someone else in their cluster).
One historical example immediately springs to mind where something-I'd-consider-a-Paul-esque-model utterly failed predictively: the breakdown of the Philips curve. The original Philips curve was based on just fitting a curve to inflation-vs-unemployment data; Friedman and Phelps both independently came up with theoretical models for that relationship in the late sixties ('67-'68), and Friedman correctly forecasted that the curve would break down in the next recession (i.e. the "stagflation" of '73-'75). This all led up to the Lucas Critique, which I'd consider the canonical case-against-what-I'd-call-Paul-esque-worldviews within economics. The main idea which seems transportable to other contexts is that surface relations (like the Philips curve) break down under distribution shifts in the underlying factors.
So, how would I look for something analogous to that situation in today's AI? We need something with an established trend, but where a distribution shift happens in some underlying factor. One possible place to look: I've heard that OpenAI plans to make the next generation of GPT not actually much bigger than the previous generation; they're trying to achieve improvement through strategies other than Stack More Layers. Assuming that's true, it seems like a naive Paul-esque model would predict that the next GPT is relatively unimpressive compared to e.g. the GPT2 -> GPT 3 delta? Whereas my models (or I'd guess Eliezer's models) would predict that it's relatively more impressive, compared to the expectations of Paul-esque models (derived by e.g. extrapolating previous performance as a function of model size and then plugging in actual size of the next GPT)? I wouldn't expect either view to make crisp high-certainty predictions here, but enough to get decent Bayesian evidence.
Other than distribution shifts, the other major place I'd look for different predictions is in the extent to which aggregates tell us useful things. The post got into that in a little detail, but I think there's probably still room there. For instance, I recently sat down and played with some toy examples of GDP growth induced by tech shifts, and I was surprised by how smooth GDP was even in scenarios with tech shifts which seemed very impactful to me. I expect that Paul would be even more surprised by this if he were to do the same exercise. In particular, this quote seems relevant:
the point is that housing and healthcare are not central examples of things that scale up at the beginning of explosive growth, regardless of whether it's hard or soft
It is surprisingly difficult to come up with a scenario where GDP growth looks smooth AND housing+healthcare don't grow much AND GDP growth accelerates to a rate much faster than now. If everything except housing and healthcare are getting cheaper, then housing and healthcare will likely play a much larger role in GDP (and together they're 30-35% already), eventually dominating GDP. This isn't a logical necessity; in principle we could consume so much more of everything else that the housing+healthcare share shrinks, but I think that would probably diverge from past trends (though I have not checked). What I actually expect is that as people get richer, they spend a larger fraction on things which have a high capacity to absorb marginal income, of which housing and healthcare are central examples.
If housing and healthcare aren't getting cheaper, and we're not spending a smaller fraction of income on them (by buying way way more of the things which are getting cheaper), then that puts a pretty stiff cap on how much GDP can grow.
Zooming out a meta-level, I think GDP is a particularly good example of a big aggregate metric which approximately-always looks smooth in hindsight, even when the underlying factors of interest undergo large jumps. I think Paul would probably update toward that view if he spent some time playing around with examples (similar to this post).
Similarly, I've heard that during training of GPT-3, while aggregate performance improves smoothly, performance on any particular task (like e.g. addition) is usually pretty binary - i.e. performance on any particular task tends to jump quickly from near-zero to near-maximum-level. Assuming this is true, presumably Paul already knows about it, and would argue that what matters-for-impact is ability at lots of different tasks rather than one (or a few) particular tasks/kinds-of-tasks? If so, that opens up a different line of debate, about the extent to which individual humans' success today hinges on lots of different skills vs a few, and in which areas.
The "continuous view" as I understand it doesn't predict that all straight lines always stay straight. My version of it (which may or may not be Paul's version) predicts that in domains where people are putting in lots of effort to optimize a metric, that metric will grow relatively continuously. In other words, the more effort put in to optimize the metric, the more you can rely on straight lines for that metric staying straight (assuming that the trends in effort are also staying straight).
In its application to AI, this is combined with a prediction that people will in fact be putting in lots of effort into making AI systems intelligent / powerful / able to automate AI R&D / etc, before AI has reached a point where it can execute a pivotal act. This second prediction comes for totally different reasons, like "look at what AI researchers are already trying to do" combined with "it doesn't seem like AI is anywhere near the point of executing a pivotal act yet".
(I think on Paul's view the second prediction is also bolstered by observing that most industries / things that had big economic impacts also seemed to have crappier predecessors. This feels intuitive to me but is not something I've checked and so isn't my personal main reason for believing the second prediction.)
One historical example immediately springs to mind where something-I'd-consider-a-Paul-esque-model utterly failed predictively: the breakdown of the Philips curve.
I'm not very familiar with this (I've only seen your discussion and the discussion in IEM) but it does not seem like the sort of thing where the argument I laid out above would have had a strong opinion. Was the y-axis of the straight line graph a metric that people were trying to optimize? If so, did the change in policy not represent a change in the amount of effort put into optimizing the metric? (I haven't looked at the details here, maybe the answer is yes to both, in which case I would be interested in looking at the details.)
Zooming out a meta-level, I think GDP is a particularly good example of a big aggregate metric which approximately-always looks smooth in hindsight, even when the underlying factors of interest undergo large jumps.
This seems plausible but it also seems like you can apply the above argument to a bunch of other topics besides GDP, like the ones listed in this comment, so it still seems like you should be able to exhibit a failure of the argument on those topics.
One of the problems here is that, as well as disagreeing about underlying world models and about the likelihoods of some pre-AGI events, Paul and Eliezer often just make predictions about different things by default. But they do (and must, logically) predict some of the same world events differently.
My very rough model of how their beliefs flow forward is:
Paul
Low initial confidence on truth/coherence of 'core of generality'
→
Human Evolution tells us very little about the 'cognitive landscape of all minds' (if that's even a coherent idea) - it's simply a loosely analogous individual historical example. Natural selection wasn't intelligently aiming for powerful world-affecting capabilities, and so stumbled on them relatively suddenly with humans. Therefore, we learn very little about whether there will/won't be a spectrum of powerful intermediately general AIs from the historical case of evolution - all we know is that it didn't happen during evolution, and we've got good reasons to think it's a lot more likely to happen for AI. For other reasons (precedents already exist - MuZero is insect-brained but better at chess or go than a chimp, plus that's the default with technology we're heavily investing in), we should expect there will be powerful, intermediately general AIs by default (and our best guess of the timescale should be anchored to the speed of human-driven progress, since that's where it will start) - No core of generality
Then, from there:
No core of generality and extrapolation of quantitative metrics for things we care about and lack of common huge secrets in relevant tech progress reference class → Qualitative prediction of more common continuous progress on the 'intelligence' of narrow AI and prediction of continuous takeoff
Eliezer
High initial confidence on truth/coherence of 'core of generality'
→
Even though there are some disanalogies between Evolution and AI progress, the exact details of how closely analogous the two situations are don't matter that much. Rather, we learn a generalizable fact about the overall cognitive landscape from human evolution - that there is a way to reach the core of generality quickly. This doesn't make it certain that AGI development will go the same way, but it's fairly strong evidence. The disanalogies between evolution and ML are indeed a slight update in Paul's direction and suggest that AI could in principle take a smoother route to general intelligence, but we've never historically seen this smoother route (and it has to be not just technically 'smooth' but sufficiently smooth to give us a full 4-year economic doubling) or these intermediate powerful agents, so this correction is weak compared to the broader knowledge we gain from evolution. In other words, all we know is that there is a fast route to the core of generality but that it's imaginable that there's a slow route we've not yet seen - Core of generality
Then, from there:
Core of generality and very common presence of huge secrets in relevant tech progress reference class → Qualitative prediction of less common continuous progress on the 'intelligence' of narrow AI and prediction of discontinuous takeoff
Eliezer doesn’t have especially divergent views about benchmarks like perplexity because he thinks they're not informative, but differs from Paul on qualitative predictions of how smoothly various practical capabilities/signs of 'intelligence' will emerge - he's getting his qualitative predictions about this ultimately from interrogating his 'cognitive landscape' abstraction, while Paul is getting his from trend extrapolation on measures of practical capabilities and then translating those to qualitative predictions. These are very different origins, but they do eventually give different predictions about the likelihood of the same real-world events.
Since they only reach the point of discussing the same things at a very vague, qualitative level of detail, in order to get to a bet you have to back-track from both of their qualitative predictions of how likely the sudden emergence of various types of narrow intelligent behaviour are, find some clear metric for the narrow intelligent behaviour that we can apply fairly, and then there should be a difference in beliefs about the world before AI takeoff.
Updates on this after reflection and discussion (thanks to Rohin):
Human Evolution tells us very little about the 'cognitive landscape of all minds' (if that's even a coherent idea) - it's simply a loosely analogous individual historical example
Saying Paul's view is that the cognitive landscape of minds might be simply incoherent isn't quite right - at the very least you can talk about the distribution over programs implied by the random initialization of a neural network.
I could have just said 'Paul doesn't see this strong generality attractor in the cognitive landscape' but it seems to me that it's not just a disagreement about the abstraction, but that he trusts claims made on the basis of these sorts of abstractions less than Eliezer.
Also, on Paul's view, it's not that evolution is irrelevant as a counterexample. Rather, the specific fact of 'evolution gave us general intelligence suddenly by evolutionary timescales' is an unimportant surface fact, and the real truth about evolution is consistent with the continuous view.
No core of generality and extrapolation of quantitative metrics for things we care about and lack of common huge secrets in relevant tech progress reference class
These two initial claims are connected in a way I didn't make explicit - No core of generality and lack of common secrets in the reference class together imply that there are lots of paths to improving on practical metrics (not just those that give us generality), that we are putting in lots of effort into improving such metrics and that we tend to take the best ones first, so the metric improves continuously, and trend extrapolation will be especially correct.
Core of generality and very common presence of huge secrets in relevant tech progress reference class
The first clause already implies the second clause (since "how to get the core of generality" is itself a huge secret), but Eliezer seems to use non-intelligence related examples of sudden tech progress as evidence that huge secrets are common in tech progress in general, independent of the specific reason to think generality is one such secret.
Nate's Summary
... Eliezer was saying something like "the fact that humans go around doing something vaguely like weighting outcomes by possibility and also by attractiveness, which they then roughly multiply, is quite sufficient evidence for my purposes, as one who does not pay tribute to the gods of modesty", while Richard protested something more like "but aren't you trying to use your concept to carry a whole lot more weight than that amount of evidence supports?"..
And, ofc, at this point, my Eliezer-model is again saying "This is why we should be discussing things concretely! It is quite telling that all the plans we can concretely visualize for saving our skins, are scary-adjacent; and all the non-scary plans, can't save our skins!"
Nate's summary brings up two points I more or less ignored in my summary because I wasn't sure what I thought - one is, just what role do the considerations about expected incompetent response/regulatory barriers/mistakes in choosing alignment strategies play? Are they necessary for a high likelihood of doom, or just peripheral assumptions? Clearly, you have to posit some level of "civilization fails to do the x-risk-minimizing thing" if you want to argue doom, but how extreme are the scenarios Eliezer is imagining where success is likely?
The other is the role that the modesty worldview plays in Eliezer's objections.
I feel confused/suspect we might have all lost track of what Modesty epistemology is supposed to consist of - I thought it was something like "overuse of the outside view, especially in a social cognition context".
Which of the following is:
a) probably the product of a Modesty world-view?
b) no good reason to think comes from a Modesty world-view but still bad epistemology?
c) good epistemology?
- Not believing theories which don’t make new testable predictions just because they retrodict lots of things in a way that the theories proponents claim is more natural, but that you don’t understand, because that seems generally suspicious
- Not believing theories which don’t make new testable predictions just because they retrodict lots of things in the world naturally (in a way you sort of get intuitively), because you don’t trust your own assessments of naturalness that much in the absence of discriminating evidence
- Not believing theories which don’t make new testable predictions just because they retrodict lots of things in the world naturally (in a way you sort of get intuitively), because most powerful theories which cause conceptual revolutions also make new testable predictions, so it’s a bad sign if the newly proposed theory doesn’t.
- As a general matter, accepting that there are lots of cases of theories which are knowably true independent of any new testable predictions they make because of features of the theory. Things like the implication of general relativity from the equivalence principle, or the second law of thermodynamics from Noether’s theorem, or many-worlds from QM are real, but you’ll only believe you’ve found a case like this if you’re walked through to the conclusion, so you're sure that the underlying concepts are clear and applicable, or there’s already a scientific consensus behind it.
Not believing theories which don’t make new testable predictions just because they retrodict lots of things in a way that the theories proponents claim is more natural, but that you don’t understand, because that seems generally suspicious
My Eliezer-model doesn't categorically object to this. See, e.g., Fake Causality:
[Phlogiston] feels like an explanation. It’s represented using the same cognitive data format. But the human mind does not automatically detect when a cause has an unconstraining arrow to its effect. Worse, thanks to hindsight bias, it may feel like the cause constrains the effect, when it was merely fitted to the effect.
[...] Thanks to hindsight bias, it’s also not enough to check how well your theory “predicts” facts you already know. You’ve got to predict for tomorrow, not yesterday.
And A Technical Explanation of Technical Explanation:
Nineteenth century evolutionism made no quantitative predictions. It was not readily subject to falsification. It was largely an explanation of what had already been seen. It lacked an underlying mechanism, as no one then knew about DNA. It even contradicted the nineteenth century laws of physics. Yet natural selection was such an amazingly good post facto explanation that people flocked to it, and they turned out to be right. Science, as a human endeavor, requires advance prediction. Probability theory, as math, does not distinguish between post facto and advance prediction, because probability theory assumes that probability distributions are fixed properties of a hypothesis.
The rule about advance prediction is a rule of the social process of science—a moral custom and not a theorem. The moral custom exists to prevent human beings from making human mistakes that are hard to even describe in the language of probability theory, like tinkering after the fact with what you claim your hypothesis predicts. People concluded that nineteenth century evolutionism was an excellent explanation, even if it was post facto. That reasoning was correct as probability theory, which is why it worked despite all scientific sins. Probability theory is math. The social process of science is a set of legal conventions to keep people from cheating on the math.
Yet it is also true that, compared to a modern-day evolutionary theorist, evolutionary theorists of the late nineteenth and early twentieth century often went sadly astray. Darwin, who was bright enough to invent the theory, got an amazing amount right. But Darwin’s successors, who were only bright enough to accept the theory, misunderstood evolution frequently and seriously. The usual process of science was then required to correct their mistakes.
My Eliezer-model does object to things like 'since I (from my position as someone who doesn't understand the model) find the retrodictions and obvious-seeming predictions suspicious, you should share my worry and have relatively low confidence in the model's applicability'. Or 'since the case for this model's applicability isn't iron-clad, you should sprinkle in a lot more expressions of verbal doubt'. My Eliezer-model views these as isolated demands for rigor, or as isolated demands for social meekness.
Part of his general anti-modesty and pro-Thielian-secrets view is that it's very possible for other people to know things that justifiably make them much more confident than you are. So if you can't pass the other person's ITT / you don't understand how they're arriving at their conclusion (and you have no principled reason to think they can't have a good model here), then you should be a lot more wary of inferring from their confidence that they're biased.
Not believing theories which don’t make new testable predictions just because they retrodict lots of things in the world naturally (in a way you sort of get intuitively), because you don’t trust your own assessments of naturalness that much in the absence of discriminating evidence
My Eliezer-model thinks it's possible to be so bad at scientific reasoning that you need to be hit over the head with lots of advance predictive successes in order to justifiably trust a model. But my Eliezer-model thinks people like Richard are way better than that, and are (for modesty-ish reasons) overly distrusting their ability to do inside-view reasoning, and (as a consequence) aren't building up their inside-view-reasoning skills nearly as much as they could. (At least in domains like AGI, where you stand to look a lot sillier to others if you go around expressing confident inside-view models that others don't share.)
Not believing theories which don’t make new testable predictions just because they retrodict lots of things in the world naturally (in a way you sort of get intuitively), because most powerful theories which cause conceptual revolutions also make new testable predictions, so it’s a bad sign if the newly proposed theory doesn’t.
My Eliezer-model thinks this is correct as stated, but thinks this is a claim that applies to things like Newtonian gravity and not to things like probability theory. (He's also suspicious that modest-epistemology pressures have something to do with this being non-obvious — e.g., because modesty discourages you from trusting your own internal understanding of things like probability theory, and instead encourages you to look at external public signs of probability theory's impressiveness, of a sort that could be egalitarianly accepted even by people who don't understand probability theory.)
My version of it (which may or may not be Paul's version) predicts that in domains where people are putting in lots of effort to optimize a metric, that metric will grow relatively continuously. In other words, the more effort put in to optimize the metric, the more you can rely on straight lines for that metric staying straight (assuming that the trends in effort are also staying straight).
This is super helpful, thanks. Good explanation.
With this formulation of the "continuous view", I can immediately think of places where I'd bet against it. The first which springs to mind is aging: I'd bet that we'll see a discontinuous jump in achievable lifespan of mice. The gears here are nicely analogous to AGI too: I expect that there's a "common core" (or shared cause) underlying all the major diseases of aging, and fixing that core issue will fix all of them at once, in much the same way that figuring out the "core" of intelligence will lead to a big discontinuous jump in AI capabilities. I can also point to current empirical evidence for the existence of a common core in aging, which might suggest analogous types of evidence to look at in the intelligence context.
Thinking about other analogous places... presumably we saw a discontinuous jump in flight range when Sputnik entered orbit. That one seems extremely closely analogous to AGI. There it's less about the "common core" thing, and more about crossing some critical threshold. Nuclear weapons and superconductors both stand out a-priori as places where we'd expect a critical-threshold-related discontinuity, though I don't think people were optimizing hard enough in superconductor-esque directions for the continuous view to make a strong prediction there (at least for the original discovery of superconductors).
I agree that when you know about a critical threshold, as with nukes or orbits, you can and should predict a discontinuity there. (Sufficient specific knowledge is always going to allow you to outperform a general heuristic.) I think that (a) such thresholds are rare in general and (b) in AI in particular there is no such threshold. (According to me (b) seems like the biggest difference between Eliezer and Paul.)
Some thoughts on aging:
- It does in fact seem surprising, given the complexity of biology relative to physics, if there is a single core cause and core solution that leads to a discontinuity.
- I would a priori guess that there won't be a core solution. (A core cause seems more plausible, and I'll roll with it for now.) Instead, we see a sequence of solutions that intervene on the core problem in different ways, each of which leads to some improvement on lifespan, and discovering these at different times leads to a smoother graph.
- That being said, are people putting in a lot of effort into solving aging in mice? Everyone seems to constantly be saying that we're putting in almost no effort whatsoever. If that's true then a jumpy graph would be much less surprising.
- As a more specific scenario, it seems possible that the graph of mouse lifespan over time looks basically flat, because we were making no progress due to putting in ~no effort. I could totally believe in this world that someone puts in some effort and we get a discontinuity, or even that the near-zero effort we're putting in finds some intervention this year (but not in previous years) which then looks like a discontinuity.
If we had a good operationalization, and people are in fact putting in a lot of effort now, I could imagine putting my $100 to your $300 on this (not going beyond 1:3 odds simply because you know way more about aging than I do).
I'm not particularly enthusiastic about betting at 75%, that seems like it's already in the right ballpark for where the probability should be. So I guess we've successfully Aumann agreed on that particular prediction.
presumably we saw a discontinuous jump in flight range when Sputnik entered orbit.
While I think orbit is the right sort of discontinuity for this, I think you need to specify 'flight range' in a way that clearly favors orbits for this to be correct, mostly because about a month before was the manhole cover launched/vaporized with a nuke.
[But in terms of something like "altitude achieved", I think Sputnik is probably part of a continuous graph, and probably not the most extreme member of the graph?]
My understanding is that Sputnik was a big discontinuous jump in "distance which a payload (i.e. nuclear bomb) can be delivered" (or at least it was a conclusive proof-of-concept of a discontinuous jump in that metric). That metric was presumably under heavy optimization pressure at the time, and was the main reason for strategic interest in Sputnik, so it lines up very well with the preconditions for the continuous view.
So it looks like the R-7 (which launched Sputnik) was the first ICBM, and the range is way longer than the V-2s of ~15 years earlier, but I'm not easily finding a graph of range over those intervening years. (And the R-7 range is only about double the range of a WW2-era bomber, which further smooths the overall graph.)
[And, implicitly, the reason we care about ICBMs is because the US and the USSR were on different continents; if the distance between their major centers was comparable to England and France's distance instead, then the same strategic considerations would have been hit much sooner.]
I don't necessarily expect GPT-4 to do better on perplexity than would be predicted by a linear model fit to neuron count plus algorithmic progress over time; my guess for why they're not scaling it bigger would be that Stack More Layers just basically stopped scaling in real output quality at the GPT-3 level. They can afford to scale up an OOM to 1.75 trillion weights, easily, given their funding, so if they're not doing that, an obvious guess is that it's because they're not getting a big win from that. As for their ability to then make algorithmic progress, depends on how good their researchers are, I expect; most algorithmic tricks you try in ML won't work, but maybe they've got enough people trying things to find some? But it's hard to outpace a field that way without supergeniuses, and the modern world has forgotten how to rear those.
While GPT-4 wouldn't be a lot bigger than GPT-3, Sam Altman did indicate that it'd use a lot more compute. That's consistent with Stack More Layers still working; they might just have found an even better use for compute.
(The increased compute-usage also makes me think that a Paul-esque view would allow for GPT-4 to be a lot more impressive than GPT-3, beyond just modest algorithmic improvements.)
If they've found some way to put a lot more compute into GPT-4 without making the model bigger, that's a very different - and unnerving - development.
and some of my sense here is that if Paul offered a portfolio bet of this kind, I might not take it myself, but EAs who were better at noticing their own surprise might say, "Wait, that's how unpredictable Paul thinks the world is?"
If Eliezer endorses this on reflection, that would seem to suggest that Paul actually has good models about how often trend breaks happen, and that the problem-by-Eliezer's-lights is relatively more about, either:
- that Paul's long-term predictions do not adequately take into account his good sense of short-term trend breaks.
- that Paul's long-term predictions are actually fine and good, but that his communication about it is somehow misleading to EAs.
That would be a very different kind of disagreement than I thought this was about. (Though actually kind-of consistent with the way that Eliezer previously didn't quite diss Paul's track-record, but instead dissed "the sort of person who is taken in by this essay [is the same sort of person who gets taken in by Hanson's arguments in 2008 and gets caught flatfooted by AlphaGo and GPT-3 and AlphaFold 2]"?)
Also, none of this erases the value of putting forward the predictions mentioned in the original quote, since that would then be a good method of communicating Paul's (supposedly miscommunicated) views.
superforecasters were claiming that AlphaGo had a 20% chance of beating Lee Se-dol and I didn't disagree with that at the time
Good Judgment Open had the probability at 65% on March 8th 2016, with a generally stable forecast since early February (Wikipedia says that the first match was on March 9th).
Metaculus had the probability at 64% with similar stability over time. Of course, there might be another source that Eliezer is referring to, but for now I think it's right to flag this statement as false.
A note I want to add, if this fact-check ends up being valid:
It appears that a significant fraction of Eliezer's argument relies on AlphaGo being surprising. But then his evidence for it being surprising seems to rest substantially on something that was misremembered. That seems important if true.
I would point to, for example, this quote, "I mean the superforecasters did already suck once in my observation, which was AlphaGo, but I did not bet against them there, I bet with them and then updated afterwards." It seems like the lesson here, if indeed superforecasters got AlphaGo right and Eliezer got it wrong, is that we should update a little bit towards superforecasting, and against Eliezer.
Adding my recollection of that period: some people made the relevant updates when DeepMind's system beat the European Champion Fan Hui (in October 2015). My hazy recollection is that beating Fan Hui started some people going "Oh huh, I think this is going to happen" and then when AlphaGo beat Lee Sedol (in March 2016) everyone said "Now it is happening".
It seems from this Metaculus question that people indeed were surprised by the announcement of the match between Fan Hui and AlphaGo (which was disclosed in January, despite the match happening months earlier, according to Wikipedia).
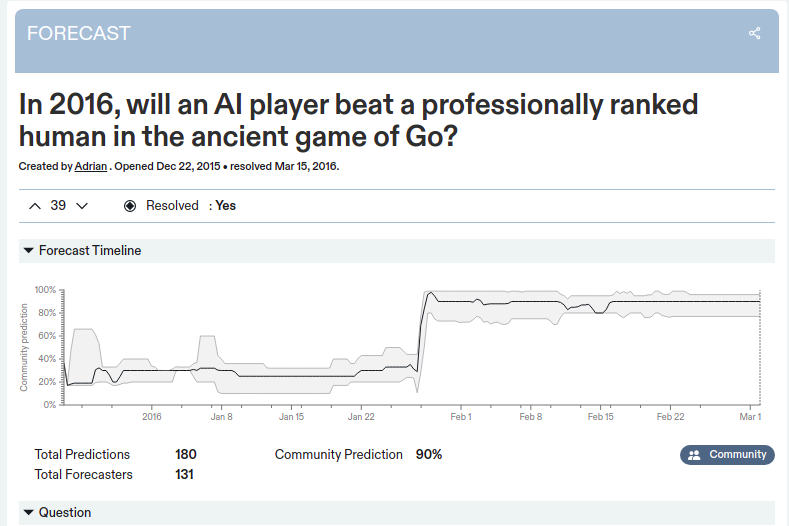
It seems hard to interpret this as AlphaGo being inherently surprising though, because the relevant fact is that the question was referring only to 2016. It seems somewhat reasonable to think that even if a breakthrough is on the horizon, it won't happen imminently with high probability.
Perhaps a better source of evidence of AlphaGo's surprisingness comes from Nick Bostrom's 2014 book Superintelligence in which he says, "Go-playing amateur programs have been improving at a rate of about 1 level dan/year in recent years. If this rate of improvement continues, they might beat the human world champion in about a decade." (Chapter 1).
This vindicates AlphaGo being an impressive discontinuity from pre-2015 progress. Though one can reasonably dispute whether superforecasters thought that the milestone was still far away after being told that Google and Facebook made big investments into it (as was the case in late 2015).
Wow thanks for pulling that up. I've gotta say, having records of people's predictions is pretty sweet. Similarly, solid find on the Bostrom quote.
Do you think that might be the 20% number that Eliezer is remembering? Eliezer, interested in whether you have a recollection of this or not. [Added: It seems from a comment upthread that EY was talking about superforecasters in Feb 2016, which is after Fan Hui.]
My memory of the past is not great in general, but considering that I bet sums of my own money and advised others to do so, I am surprised that my memory here would be that bad, if it was.
Neither GJO nor Metaculus are restricted to only past superforecasters, as I understand it; and my recollection is that superforecasters in particular, not all participants at GJO or Metaculus, were saying in the range of 20%. Here's an example of one such, which I have a potentially false memory of having maybe read at the time: https://www.gjopen.com/comments/118530
Thanks for clarifying. That makes sense that you may have been referring to a specific subset of forecasters. I do think that some forecasters tend to be much more reliable than others (and maybe there was/is a way to restrict to "superforecasters" in the UI).
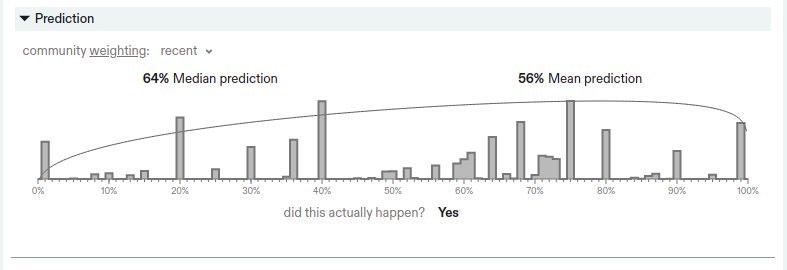
I will add the following piece of evidence, which I don't think counts much for or against your memory, but which still seems relevant. Metaculus shows a histogram of predictions. On the relevant question, a relatively high fraction of people put a 20% chance, but it also looks like over 80% of forecasters put higher credences.
Transcript error fixed -- the line that previously read
[Yudkowsky][17:40] I expect it to go away before the end of days but with there having been a big architectural innovation, not Stack More Layers |
[Christiano][17:40] I expect it to go away before the end of days but with there having been a big architectural innovation, not Stack More Layers |
[Yudkowsky][17:40] if you name 5 possible architectural innovations I can call them small or large |
should be
[Yudkowsky][17:40] I expect it to go away before the end of days but with there having been a big architectural innovation, not Stack More Layers |
[Christiano][17:40] yeah whereas I expect layer stacking + maybe changing loss (since logprob is too noisy) is sufficient |
[Yudkowsky][17:40] if you name 5 possible architectural innovations I can call them small or large |
Christiano predicts progress will be (approximately) a smooth curve, whereas Yudkowsky predicts there will be discontinuous-ish "jumps", but there's another thing that can happen that both of them seem to dismiss: progress hitting a major obstacle and plateauing for a while (i.e. the progress curve looking locally like a sigmoid). I guess that the reason they dismiss it is related to this quote by Soares:
I observe that, 15 years ago, everyone was saying AGI is far off because of what it couldn't do -- basic image recognition, go, starcraft, winograd schemas, programmer assistance. But basically all that has fallen. The gap between us and AGI is made mostly of intangibles.
However, I think this is not entirely accurate. Some games are still unsolved without "cheating", where by cheating I mean using human demonstrations or handcrafted rewards, and that includes Montezuma's Revenge, StarCraft II and Dota 2 (and Dota 2 with unlimited hero selection is even more unsolved). Moreover, we haven't seen RL show superhuman performance on any task in which the environment is substantially more complex than the agent in important ways (this rules out all video games, unless if winning the game requires a good theory of mind of your opponents[1], which is arguably never the case for zero-sum two-player games). Language models made impressive progress, but I don't think they are superhuman along any interesting dimension. Classifiers still struggle with adversarial examples (although, this is not necessarily an important limitation, maybe humans have "adversarial examples" too).
So, it is certainly possible that it's a "clear runway" from here to superintelligence. But I don't think it's obvious.
I know there are strong poker AIs, but I suspect they win via something other than theory of mind. Maybe someone who knows the topic can comment. ↩︎
My Eliezer-model is a lot less surprised by lulls than my Paul-model (because we're missing key insights for AGI, progress on insights is jumpy and hard to predict, the future is generally very unpredictable, etc.). I don't know exactly how large of a lull or winter would start to surprise Eliezer (or how much that surprise would change if the lull is occurring two years from now, vs. ten years from now, for example).
In Yudkowsky and Christiano Discuss "Takeoff Speeds", Eliezer says:
I have a rough intuitive feeling that it [AI progress] was going faster in 2015-2017 than 2018-2020.
So in that sense Eliezer thinks we're already in a slowdown to some degree (as of 2020), though I gather you're talking about a much larger and more long-lasting slowdown.
I generally expect smoother progress, but predictions about lulls are probably dominated by Eliezer's shorter timelines. Also lulls are generally easier than spurts, e.g. I think that if you just slow investment growth you get a lull and that's not too unlikely (whereas part of why it's hard to get a spurt is that investment rises to levels where you can't rapidly grow it further).
Makes some sense, but Yudkowsky's prediction that TAI will arrive before AI has large economic impact does forbid a lot of plateau scenarios. Given a plateau that's sufficiently high and sufficiently long, AI will land in the market, I think. Even if regulatory hurdles are the bottleneck for a lot of things atm, eventually in some country AI will become important and the others will have to follow or fall behind.
(ETA: this wasn't actually in this log but in a future part of the discussion.)
I found the elephants part of this discussion surprising. It looks to me like human brains are better than elephant brains at most things, and it's interesting to me that Eliezer thought otherwise. This is one of the main places where I couldn't predict what he would say.
I also think human brains are better than elephant brains at most things - what did I say that sounded otherwise?
Oops, this was in reference to the later part of the discussion where you disagreed with "a human in a big animal body, with brain adapted to operate that body instead of our own, would beat a big animal [without using tools]".
This post is a transcript of a discussion between Paul Christiano, Ajeya Cotra, and Eliezer Yudkowsky on AGI forecasting, following up on Paul and Eliezer's "Takeoff Speeds" discussion.
Color key:
8. September 20 conversation
8.1. Chess and Evergrande
[Christiano][15:28]
I still feel like you are overestimating how big a jump alphago is, or something. Do you have a mental prediction of how the graph of (chess engine quality) vs (time) looks, and whether neural net value functions are a noticeable jump in that graph?
Like, people investing in "Better Software" doesn't predict that you won't be able to make progress at playing go. The reason you can make a lot of progress at go is that there was extremely little investment in playing better go.
So then your work is being done by the claim "People won't be working on the problem of acquiring a decisive strategic advantage," not that people won't be looking in quite the right place and that someone just had a cleverer idea
[Yudkowsky][16:35]
I think I'd expect something like... chess engine slope jumps a bit for Deep Blue, then levels off with increasing excitement, then jumps for the Alpha series? Albeit it's worth noting that Deepmind's efforts there were going towards generality rather than raw power; chess was solved to the point of being uninteresting, so they tried to solve chess with simpler code that did more things. I don't think I do have strong opinions about what the chess trend should look like, vs. the Go trend; I have no memories of people saying the chess trend was breaking upwards or that there was a surprise there.
Incidentally, the highly well-traded financial markets are currently experiencing sharp dips surrounding the Chinese firm of Evergrande, which I was reading about several weeks before this.
I don't see the basic difference in the kind of reasoning that says "Surely foresightful firms must produce investments well in advance into earlier weaker applications of AGI that will double the economy", and the reasoning that says "Surely world economic markets and particular Chinese stocks should experience smooth declines as news about Evergrande becomes better-known and foresightful financial firms start to remove that stock from their portfolio or short-sell it", except that in the latter case there are many more actors with lower barriers to entry than presently exist in the auto industry or semiconductor industry never mind AI.
or if not smooth because of bandwagoning and rational fast actors, then at least the markets should (arguendo) be reacting earlier than they're reacting now, given that I heard about Evergrande earlier; and they should have options-priced Covid earlier; and they should have reacted to the mortgage market earlier. If even markets there can exhibit seemingly late wild swings, how is the economic impact of AI - which isn't even an asset market! - forced to be earlier and smoother than that, as a result of wise investing?
There's just such a vast gap between hopeful reasoning about how various agents and actors should all do the things the speaker finds very reasonable, thereby yielding smooth behavior of the Earth, versus reality.
9. September 21 conversation
9.1. AlphaZero, innovation vs. industry, the Wright Flyer, and the Manhattan Project
[Christiano][10:18]
(For benefit of readers, the market is down 1.5% from friday close -> tuesday open, after having drifted down 2.5% over the preceding two weeks. Draw whatever lesson you want from that.)
Also for the benefit of readers, here is the SSDF list of computer chess performance by year. I think the last datapoint is with the first version of neural net evaluations, though I think to see the real impact we want to add one more datapoint after the neural nets are refined (which is why I say I also don't know what the impact is)
No one keeps similarly detailed records for Go, and there is much less development effort, but the rate of progress was about 1 stone per year from 1980 until 2015 (see https://intelligence.org/files/AlgorithmicProgress.pdf, written way before AGZ). In 2012 go bots reached about 4-5 amateur dan. By DeepMind's reckoning here (https://www.nature.com/articles/nature16961, figure 4) Fan AlphaGo about 4-5 stones stronger-4 years later, with 1 stone explained by greater runtime compute. They could then get further progress to be superhuman with even more compute, radically more than were used for previous projects and with pretty predictable scaling. That level is within 1-2 stones of the best humans (professional dan are greatly compressed relative to amateur dan), so getting to "beats best human" is really just not a big discontinuity and the fact that DeepMind marketing can find an expert who makes a really bad forecast shouldn't be having such a huge impact on your view.
This understates the size of the jump from AlphaGo, because that was basically just the first version of the system that was superhuman and it was still progressing very rapidly as it moved from prototype to slightly-better-prototype, which is why you saw such a close game. (Though note that the AlphaGo prototype involved much more engineering effort than any previous attempt to play go, so it's not surprising that a "prototype" was the thing to win.)
So to look at actual progress after the dust settles and really measure how crazy this was, it seems much better to look at AlphaZero which continued to improve further, see (https://sci-hub.se/https://www.nature.com/articles/nature24270, figure 6b). Their best system got another ~8 stones of progress over AlphaGo. Now we are like 7-10 stones ahead of trend, of which I think about 3 stones are explained by compute. Maybe call it 6 years ahead of schedule?
So I do think this is pretty impressive, they were slightly ahead of schedule for beating the best humans but they did it with a huge margin of error. I think the margin is likely overstated a bit by their elo evaluation methodology, but I'd still grant like 5 years ahead of the nearest competition.
I'd be interested in input from anyone who knows more about the actual state of play (+ is allowed to talk about it) and could correct errors.
Mostly that whole thread is just clearing up my understanding of the empirical situation, probably we still have deep disagreements about what that says about the world, just as e.g. we read very different lessons from market movements.
Probably we should only be talking about either ML or about historical technologies with meaningful economic impacts. In my view your picture is just radically unlike how almost any technologies have been developed over the last few hundred years. So probably step 1 before having bets is to reconcile our views about historical technologies, and then maybe as a result of that we could actually have a bet about future technology. Or we could try to shore up the GDP bet.
Like, it feels to me like I'm saying: AI will be like early computers, or modern semiconductors, or airplanes, or rockets, or cars, or trains, or factories, or solar panels, or genome sequencing, or basically anything else. And you are saying: AI will be like nuclear weapons.
I think from your perspective it's more like: AI will be like all the historical technologies, and that means there will be a hard takeoff. The only way you get a soft takeoff forecast is by choosing a really weird thing to extrapolate from historical technologies.
So we're both just forecasting that AI will look kind of like other stuff in the near future, and then both taking what we see as the natural endpoint of that process.
To me it feels like the nuclear weapons case is the outer limit of what looks plausible, where someone is able to spend $100B for a chance at a decisive strategic advantage.
[Yudkowsky][11:11]
Go-wise, I'm a little concerned about that "stone" metric - what would the chess graph look like if it was measuring pawn handicaps? Are the professional dans compressed in Elo, not just "stone handicaps", relative to the amateur dans? And I'm also hella surprised by the claim, which I haven't yet looked at, that Alpha Zero got 8 stones of progress over AlphaGo - I would not have been shocked if you told me that God's Algorithm couldn't beat Lee Se-dol with a 9-stone handicap.
Like, the obvious metric is Elo, so if you go back and refigure in "stone handicaps", an obvious concern is that somebody was able to look into the past and fiddle their hindsight until they found a hindsightful metric that made things look predictable again. My sense of Go said that 5-dan amateur to 9-dan pro was a HELL of a leap for 4 years, and I also have some doubt about the original 5-dan-amateur claims and whether those required relatively narrow terms of testing (eg timed matches or something).
One basic point seems to be whether AGI is more like an innovation or like a performance metric over an entire large industry.
Another point seems to be whether the behavior of the world is usually like that, in some sense, or if it's just that people who like smooth graphs can go find some industries that have smooth graphs for particular performance metrics that happen to be smooth.
Among the smoothest metrics I know that seems like a convergent rather than handpicked thing to cite, is world GDP, which is the sum of more little things than almost anything else, and whose underlying process is full of multiple stages of converging-product-line bottlenecks that make it hard to jump the entire GDP significantly even when you jump one component of a production cycle... which, from my standpoint, is a major reason to expect AI to not hit world GDP all that hard until AGI passes the critical threshold of bypassing it entirely. Having 95% of the tech to invent a self-replicating organism (eg artificial bacterium) does not get you 95%, 50%, or even 10% of the impact.
(it's not so much the 2% reaction of world markets to Evergrande that I was singling out earlier, 2% is noise-ish, but the wider swings in the vicinity of Evergrande particularly)
[Christiano][12:41]
Yeah, I'm just using "stone" to mean "elo difference that is equal to 1 stone at amateur dan / low kyu," you can see DeepMind's conversion (which I also don't totally believe) in figure 4 here (https://sci-hub.se/https://www.nature.com/articles/nature16961). Stones are closer to constant elo than constant handicap, it's just a convention to name them that way.
[Yudkowsky][12:42]
k then
[Christiano][12:47]
But my description above still kind of understates the gap I think. They call 230 elo 1 stone, and I think prior rate of progress is more like 200 elo/year. They put AlphaZero about 3200 elo above the 2012 system, so that's like 16 years ahead = 11 years ahead of schedule. At least 2 years are from test-time hardware, and self-play systematically overestimates elo differences at the upper end of that. But 5 years ahead is still too low and that sounds more like 7-9 years ahead. ETA: and my actual best guess all things considered is probably 10 years ahead, which I agree is just a lot bigger than 5. And I also understated how much of the gap was getting up to Lee Sedol.
The go graph I posted wasn't made with hindsight, that was from 2014
I mean, I'm fine with you saying that people who like smooth graphs are cherry-picking evidence, but do you want to give any example other than nuclear weapons of technologies with the kind of discontinuous impact you are describing?
I do agree that the difference in our views is like "innovation" vs "industry." And a big part of my position is that innovation-like things just don't usually have big impacts for kind of obvious reasons, they start small and then become more industry-like as they scale up. And current deep learning seems like an absolutely stereotypical industry that is scaling up rapidly in an increasingly predictable way.
As far as I can tell the examples we know of things changing continuously aren't handpicked, we've been looking at all the examples we can find, and no one is proposing or even able to find almost anything that looks like you are imagining AI will look.
Like, we've seen deep learning innovations in the form of prototypes (most of all AlexNet), and they were cool and represented giant fast changes in people's views. And more recently we are seeing bigger much-less-surprising changes that are still helping a lot in raising the tens of billions of dollars that people are raising. And the innovations we are seeing are increasingly things that trade off against modest improvements in model size, there are fewer and fewer big surprises, just like you'd predict. It's clearer and clearer to more and more people what the roadmap is---the roadmap is not yet quite as clear as in semiconductors, but as far as I can tell that's just because the field is still smaller.
[Yudkowsky][13:23]
I sure wasn't imagining there was a roadmap to AGI! Do you perchance have one which says that AGI is 30 years out?
From my perspective, you could as easily point to the Wright Flyer as an atomic bomb. Perhaps this reflects again the "innovation vs industry" difference, where I think in terms of building a thing that goes foom thereby bypassing our small cute world GDP, and you think in terms of industries that affect world GDP in an invariant way throughout their lifetimes.
Would you perhaps care to write off the atomic bomb too? It arguably didn't change the outcome of World War II or do much that conventional weapons in great quantity couldn't; Japan was bluffed into believing the US could drop a nuclear bomb every week, rather than the US actually having that many nuclear bombs or them actually being used to deliver a historically outsized impact on Japan. From the industry-centric perspective, there is surely some graph you can draw which makes nuclear weapons also look like business as usual, especially if you go by destruction per unit of whole-industry non-marginal expense, rather than destruction per bomb.
[Christiano][13:27]
seems like you have to make the wright flyer much better before it's important, and that it becomes more like an industry as that happens, and that this is intimately related to why so few people were working on it
I think the atomic bomb is further on the spectrum than almost anything, but it still doesn't feel nearly as far as what you are expecting out of AI
the manhattan project took years and tens of billions; if you wait an additional few years and spend an additional few tens of billions then it would be a significant improvement in destruction or deterrence per $ (but not totally insane)
I do think it's extremely non-coincidental that the atomic bomb was developed in a country that was practically outspending the whole rest of the world in "killing people technology"
and took a large fraction of that country's killing-people resources
eh, that's a bit unfair, the us was only like 35% of global spending on munitions
and the manhattan project itself was only a couple percent of total munitions spending
[Yudkowsky][13:32]
a lot of why I expect AGI to be a disaster is that I am straight-up expecting AGI to be different. if it was just like coal or just like nuclear weapons or just like viral biology then I would not be way more worried about AGI than I am worried about those other things.
[Christiano][13:33]
that definitely sounds right
but it doesn't seem like you have any short-term predictions about AI being different
9.2. AI alignment vs. biosafety, and measuring progress
[Yudkowsky][13:33]
are you more worried about AI than about bioengineering?
[Christiano][13:33]
I'm more worried about AI because (i) alignment is a thing, unrelated to takeoff speed, (ii) AI is a (ETA: likely to be) huge deal and bioengineering is probably a relatively small deal
(in the sense of e.g. how much $ people spend, or how much $ it makes, or whatever other metric of size you want to use)
[Yudkowsky][13:35]
what's the disanalogy to (i) biosafety is a thing, unrelated to the speed of bioengineering? why expect AI to be a huge deal and bioengineering to be a small deal? is it just that investing in AI is scaling faster than investment in bioengineering?
[Christiano][13:35]
no, alignment is a really easy x-risk story, bioengineering x-risk seems extraordinarily hard
It's really easy to mess with the future by creating new competitors with different goals, if you want to mess with the future by totally wiping out life you have to really try at it and there's a million ways it can fail. The bioengineering seems like it basically requires deliberate and reasonably competent malice whereas alignment seems like it can only be averted with deliberate effort, etc.
I'm mostly asking about historical technologies to try to clarify expectations, I'm pretty happy if the outcome is: you think AGI is predictably different from previous technologies in ways we haven't seen yet
though I really wish that would translate into some before-end-of-days prediction about a way that AGI will eventually look different
[Yudkowsky][13:38]
in my ontology a whole lot of threat would trace back to "AI hits harder, faster, gets too strong to be adjusted"; tricks with proteins just don't have the raw power of intelligence
[Christiano][13:39]
in my view it's nearly totally orthogonal to takeoff speed, though fast takeoffs are a big reason that preparation in advance is more useful
(but not related to the basic reason that alignment is unprecedentedly scary)
It feels to me like you are saying that the AI-improving-AI will move very quickly from "way slower than humans" to "FOOM in <1 year," but it just looks like that is very surprising to me.
However I do agree that if AI-improving-AI was like AlphaZero, then it would happen extremely fast.
It seems to me like it's pretty rare to have these big jumps, and it gets much much rarer as technologies become more important and are more industry-like rather than innovation like (and people care about them a lot rather than random individuals working on them, etc.). And I can't tell whether you are saying something more like "nah big jumps happen all the time in places that are structurally analogous to the key takeoff jump, even if the effects are blunted by slow adoption and regulatory bottlenecks and so on" or if you are saying "AGI is atypical in how jumpy it will be"
[Yudkowsky][13:44]
I don't know about slower; GPT-3 may be able to type faster than a human
[Christiano][13:45]
Yeah, I guess we've discussed how you don't like the abstraction of "speed of making progress"
[Yudkowsky][13:45]
but, basically less useful in fundamental ways than a human civilization, because they are less complete, less self-contained
[Christiano][13:46]
Even if we just assume that your AI needs to go off in the corner and not interact with humans, there's still a question of why the self-contained AI civilization is making ~0 progress and then all of a sudden very rapid progress
[Yudkowsky][13:46]
unfortunately a lot of what you are saying, from my perspective, has the flavor of, "but can't you tell me about your predictions earlier on of the impact on global warming at the Homo erectus level"
you have stories about why this is like totally not a fair comparison
I do not share these stories
[Christiano][13:46]
I don't understand either your objection nor the reductio
like, here's how I think it works: AI systems improve gradually, including on metrics like "How long does it take them to do task X?" or "How high-quality is their output on task X?"
[Yudkowsky][13:47]
I feel like the thing we know is something like, there is a sufficiently high level where things go whooosh humans-from-hominids style
[Christiano][13:47]
We can measure the performance of AI on tasks like "Make further AI progress, without human input"
Any way I can slice the analogy, it looks like AI will get continuously better at that task
[Yudkowsky][13:48]
how would you measure progress from GPT-2 to GPT-3, and would you feel those metrics really captured the sort of qualitative change that lots of people said they felt?
[Christiano][13:48]
And it seems like we have a bunch of sources of data we can use about how fast AI will get better
Could we talk about some application of GPT-2 or GPT-3?
also that's a lot of progress, spending 100x more is a lot more money
[Yudkowsky][13:49]
my world, GPT-3 has very few applications because it is not quite right and not quite complete
[Christiano][13:49]
also it's still really dumb
[Yudkowsky][13:49]
like a self-driving car that does great at 99% of the road situations
economically almost worthless
[Christiano][13:49]
I think the "being dumb" is way more important than "covers every case"
[Yudkowsky][13:50]
(albeit that if new cities could still be built, we could totally take those 99%-complete AI cars and build fences and fence-gates around them, in a city where they were the only cars on the road, in which case they would work, and get big economic gains from these new cities with driverless cars, which ties back into my point about how current world GDP is unwilling to accept tech inputs)
like, it is in fact very plausible to me that there is a neighboring branch of reality with open borders and no housing-supply-constriction laws and no medical-supply-constriction laws, and their world GDP does manage to double before AGI hits them really hard, albeit maybe not in 4 years. this world is not Earth. they are constructing new cities to take advantage of 99%-complete driverless cars right now, or rather, they started constructing them 5 years ago and finished 4 years and 6 months ago.
9.3. Requirements for FOOM
[Christiano][13:53]
I really feel like the important part is the jumpiness you are imagining on the AI side / why AGI is different from other things
[Cotra][13:53]
It's actually not obvious to me that Eliezer is imagining that much more jumpiness on the AI technology side than you are, Paul
E.g. he's said in the past that while the gap from "subhuman to superhuman AI" could be 2h if it's in the middle of FOOM, it could also be a couple years if it's more like scaling alphago
[Yudkowsky][13:54]
Indeed! We observed this jumpiness with hominids. A lot of stuff happened at once with hominids, but a critical terminal part of the jump was the way that hominids started scaling their own food supply, instead of being ultimately limited by the food supply of the savanna.
[Cotra][13:54]
A couple years is basically what Paul believes
[Christiano][13:55]
(discord is not a great place for threaded conversations :()
[Cotra][13:55]
What are the probabilities you're each placing on the 2h-2y spectrum? I feel like Paul is like "no way on 2h, likely on 2y" and Eliezer is like "who knows" on the whole spectrum, and a lot of the disagreement is the impact of the previous systems?
[Christiano][13:55]
yeah, I'm basically at "no way," because it seems obvious that the AI that can foom in 2h is preceded by the AI that can foom in 2y
[Yudkowsky][13:56]
well, we surely agree there!
[Christiano][13:56]
OK, and it seems to me like it is preceded by years
[Yudkowsky][13:56]
we disagree on whether the AI that can foom in 2y clearly comes more than 2y before the AI that fooms in 2h
[Christiano][13:56]
yeah
perhaps we can all agree it's preceded by at least 2h
so I have some view like: for any given AI we can measure "how long does it take to foom?" and it seems to me like this is just a nice graph
and it's not exactly clear how quickly that number is going down, but a natural guess to me is something like "halving each year" based on the current rate of progress in hardware and software
and you see localized fast progress most often in places where there hasn't yet been much attention
and my best guess for your view is that actually that's not a nice graph at all, there is some critical threshold or range where AI quickly moves from "not fooming for a really long time" to "fooming really fast," and that seems like the part I'm objecting to
[Cotra][13:59]
Paul, is your take that there's a non-infinity number for time to FOOM that'd be associated with current AI systems (unassisted by humans)?
And it's going down over time?
I feel like I would have said something more like "there's a $ amount it takes to build a system that will FOOM in X amount of time, and that's going down"
where it's like quadrillions of dollars today
[Christiano][14:00]
I think it would be a big engineering project to make such an AI, which no one is doing because it would be uselessly slow even if successful
[Yudkowsky][14:02]
I... don't think GPT-3 fooms given 2^30 longer time to think about than the systems that would otherwise exist 30 years from now, on timelines I'd consider relatively long, and hence generous to this viewpoint? I also don't think you can take a quadrillion dollars and scale GPT-3 to foom today?
[Cotra][14:03]
I would agree with your take on GPT-3 fooming, and I didn't mean a quadrillion dollars just to scale GPT-3, would probably be a difft architecture
[Christiano][14:03]
I also agree that GPT-3 doesn't foom, it just keeps outputting <EOT>[next web page]<EOT>...
But I think the axes of "smart enough to foom fast" and "wants to foom" are pretty different. I also agree there is some minimal threshold below which it doesn't even make sense to talk about "wants to foom," which I think is probably just not that hard to reach.
(Also there are always diminishing returns as you continue increasing compute, which become very relevant if you try to GPT-3 for a billion billion years as in your hypothetical even apart from "wants to foom".)
[Cotra][14:06]
I think maybe you and EY then disagree on where the threshold from "infinity" to "a finite number" for "time for this AI system to FOOM" begins? where eliezer thinks it'll drop from infinity to a pretty small finite number and you think it'll drop to a pretty large finite number, and keep going down from there
[Christiano][14:07]
I also think we will likely jump down to a foom-ing system only after stuff is pretty crazy, but I think that's probably less important
I think what you said is probably the main important disagreement
[Cotra][14:08]
as in before that point it'll be faster to have human-driven progress than FOOM-driven progress bc the FOOM would be too slow?
and there's some crossover point around when the FOOM time is just a bit faster than the human-driven progress time
[Christiano][14:09]
yeah, I think most likely (AI+humans) is faster than (AI alone) because of complementarity. But I think Eliezer and I would still disagree even if I thought there was 0 complementarity and it's just (humans improving AI) and separately (AI improving AI)
on that pure substitutes model I expect "AI foom" to start when the rate of AI-driven AI progress overtakes the previous rate of human-driven AI progress
like, I expect the time for successive "doublings" of AI output to be like 1 year, 1 year, 1 year, 1 year, [AI takes over] 6 months, 3 months, ...
and the most extreme fast takeoff scenario that seems plausible is that kind of perfect substitutes + no physical economic impact from the prior AI systems
and then by that point fast enough physical impact is really hard so it happens essentially after the software-only singularity
I consider that view kind of unlikely but at least coherent
9.4. AI-driven accelerating economic growth
[Yudkowsky][14:12]
I'm expecting that the economy doesn't accept much inputs from chimps, and then the economy doesn't accept much input from village idiots, and then the economy doesn't accept much input from weird immigrants. I can imagine that there may or may not be a very weird 2-year or 3-month period with strange half-genius systems running around, but they will still not be allowed to build houses. In the terminal phase things get more predictable and the AGI starts its own economy instead.
[Christiano][14:12]
I guess you can go even faster, by having a big and accelerating ramp-up in human investment right around the end, so that the "1 year" is faster (e.g. if recursive self-improvement was like playing go, and you could move from "a few individuals" to "google spending $10B" over a few years)
[Yudkowsky][14:13]
My
modelprophecy doesn't rule that out as a thing that could happen, but sure doesn't emphasize it as a key step that needs to happen.[Christiano][14:13]
I think it's very likely that AI will mostly be applied to further hardware+software progress
I don't really understand why you keep talking about houses and healthcare
[Cotra][14:13]
Eliezer, what about stuff like Google already using ML systems to automate its TPU load-sharing decisions, and people starting ot use Codex to automate routine programming, and so on? Seems like there's a lot of stuff like that starting to already happen and markets are pricing in huge further increases
[Christiano][14:14]
it seems like the non-AI up-for-grabs zone are things like manufacturing, not things like healthcare
[Cotra][14:14]
(I mean on your timelines obviously not much time for acceleration anyway, but that's distinct from the regulation not allowing weak AIs to do stuff story)
[Yudkowsky][14:14]
Because I think that a key thing of what makes your prophecy less likely is the way that it happens inside the real world, where, economic gains or not, the System is unwilling/unable to take the things that are 99% self-driving cars and start to derive big economic benefits from those.
[Cotra][14:15]
but it seems like huge economic gains could happen entirely in industries mostly not regulated and not customer-facing, like hardware/software R&D, manufacturing. shipping logistics, etc
[Yudkowsky][14:15]
Ajeya, I'd consider Codex of far greater could-be-economically-important-ness than automated TPU load-sharing decisions
[Cotra][14:15]
i would agree with that, it's smarter and more general
and i think that kind of thing could be applied on the hardware chip design side too
[Yudkowsky][14:16]
no, because the TPU load-sharing stuff has an obvious saturation point as a world economic input, while superCodex could be a world economic input in many more places
[Cotra][14:16]
the TPU load sharing thing was not a claim that this application could scale up to crazy impacts, but that it was allowed to happen, and future stuff that improves that kind of thing (back-end hardware/software/logistics) would probably also be allowed
[Yudkowsky][14:16]
my sense is that dectupling the number of programmers would not lift world GDP much, but it seems a lot more possible for me to be wrong about that
[Christiano][14:17]
the point is that housing and healthcare are not central examples of things that scale up at the beginning of explosive growth, regardless of whether it's hard or soft
they are slower and harder, and also in efficient markets-land they become way less important during the transition
so they aren't happening that much on anyone's story
and also it doesn't make that much difference whether they happen, because they have pretty limited effects on other stuff
like, right now we have an industry of ~hundreds of billions that is producing computing hardware, building datacenters, mining raw inputs, building factories to build computing hardware, solar panels, shipping around all of those parts, etc. etc.
I'm kind of interested in the question of whether all that stuff explodes, although it doesn't feel as core as the question of "what are the dynamics of the software-only singularity and how much $ are people spending initiating it?"
but I'm not really interested in the question of whether human welfare is spiking during the transition or only after
[Yudkowsky][14:20]
All of world GDP has never felt particularly relevant to me on that score, since twice as much hardware maybe corresponds to being 3 months earlier, or something like that.
[Christiano][14:21]
that sounds like the stuff of predictions?
[Yudkowsky][14:21]
But if complete chip manufacturing cycles have accepted much more effective AI input, with no non-AI bottlenecks, then that... sure is a much more material element of a foom cycle than I usually envision.
[Christiano][14:21]
like, do you think it's often the case that 3 months of software progress = doubling compute spending? or do you think AGI is different from "normal" AI on this perspective?
I don't think that's that far off anyway
I would guess like ~1 year
[Yudkowsky][14:22]
Like, world GDP that goes up by only 10%, but that's because producing compute capacity was 2.5% of world GDP and that quadrupled, starts to feel much more to me like it's part of a foom story.
I expect software-beats-hardware to hit harder and harder as you get closer to AGI, yeah.
the prediction is firmer near the terminal phase, but I think this is also a case where I expect that to be visible earlier
[Christiano][14:24]
I think that by the time that the AI-improving-AI takes over, it's likely that hardware+software manufacturing+R&D represents like 10-20% of GDP, and that the "alien accountants" visiting earth would value those companies at like 80%+ of GDP
9.5. Brain size and evolutionary history
[Cotra][14:24]
On software beating hardware, how much of your view is dependent on your belief that the chimp -> human transition was probably not mainly about brain size because if it were about brain size it would have happened faster? My understanding is that you think the main change is a small software innovation which increased returns to having a bigger brain. If you changed your mind and thought that the chimp -> human transition was probably mostly about raw brain size, what (if anything) about your AI takeoff views would change?
[Yudkowsky][14:25]
I think that's a pretty different world in a lot of ways!
but yes it hits AI takeoff views too
[Christiano][14:25]
regarding software vs hardware, here is an example of asking this question for imagenet classification ("how much compute to train a model to do the task?"), with a bit over 1 year doubling times (https://openai.com/blog/ai-and-efficiency/). I guess my view is that we can make a similar graph for "compute required to make your AI FOOM" and that it will be falling significantly slower than 2x/year. And my prediction for other tasks is that the analogous graphs will also tend to be falling slower than 2x/year.
[Yudkowsky][14:26]
to the extent that I modeled hominid evolution as having been "dutifully schlep more of the same stuff, get predictably more of the same returns" that would correspond to a world in which intelligence was less scary, different, dangerous-by-default
[Cotra][14:27]
thanks, that's helpful. I looked around in IEM and other places for a calculation of how quickly we should have evolved to humans if it were mainly about brain size, but I only found qualitative statements. If there's a calculation somewhere I would appreciate a pointer to it, because currently it seems to me that a story like "selection pressure toward general intelligence was weak-to-moderate because it wasn't actually that important for fitness, and this degree of selection pressure is consistent with brain size being the main deal and just taking a few million years to happen" is very plausible
[Yudkowsky][14:29]
well, for one thing, the prefrontal cortex expanded twice as fast as the rest
and iirc there's evidence of a lot of recent genetic adaptation... though I'm not as sure you could pinpoint it as being about brain-stuff or that the brain-stuff was about cognition rather than rapidly shifting motivations or something.
elephant brains are 3-4 times larger by weight than human brains (just looked up)
if it's that easy to get returns on scaling, seems like it shouldn't have taken that long for evolution to go there
[Cotra][14:31]
but they have fewer synapses (would compute to less FLOP/s by the standard conversion)
how long do you think it should have taken?
[Yudkowsky][14:31]
early dinosaurs should've hopped onto the predictable returns train
[Cotra][14:31]
is there a calculation?
you said in IEM that evolution increases organ sizes quickly but there wasn't a citation to easily follow up on there
[Yudkowsky][14:33]
I mean, you could produce a graph of smooth fitness returns to intelligence, smooth cognitive returns on brain size/activity, linear metabolic costs for brain activity, fit that to humans and hominids, then show that obviously if hominids went down that pathway, large dinosaurs should've gone down it first because they had larger bodies and the relative metabolic costs of increased intelligence would've been lower at every point along the way
I do not have a citation for that ready, if I'd known at the time you'd want one I'd have asked Luke M for it while he still worked at MIRI 😐
[Cotra][14:35]
cool thanks, will think about the dinosaur thing (my first reaction is that this should depend on the actual fitness benefits to general intelligence which might have been modest)
[Yudkowsky][14:35]
I suspect we're getting off Paul's crux, though
[Cotra][14:35]
yeah we can go back to that convo (though i think paul would also disagree about this thing, and believes that the chimp to human thing was mostly about size)
sorry for hijacking
[Yudkowsky][14:36]
well, if at some point I can produce a major shift in EA viewpoints by coming up with evidence for a bunch of non-brain-size brain selection going on over those timescales, like brain-related genes where we can figure out how old the mutation is, I'd then put a lot more priority on digging up a paper like that
I'd consider it sufficiently odd to imagine hominids->humans as being primarily about brain size, given the evidence we have, that I do not believe this is Paul's position until Paul tells me so
[Christiano][14:49]
I would guess it's primarily about brain size / neuron count / cortical neuron count
and that the change in rate does mostly go through changing niche, where both primates and birds have this cycle of rapidly accelerating brain size increases that aren't really observed in other animals
it seems like brain size is increasing extremely quickly on both of those lines
[Yudkowsky][14:50]
why aren't elephants GI?
[Christiano][14:51]
mostly they have big brains to operate big bodies, and also my position obviously does not imply (big brain) ==(necessarily implies)==> general intelligence
[Yudkowsky][14:52]
I don't understand, in general, how your general position manages to strongly imply a bunch of stuff about AGI and not strongly imply similar stuff about a bunch of other stuff that sure sounds similar to me
[Christiano][14:52]
don't elephants have very few synapses relative to humans?
how does the scale hypothesis possibly take a strong stand on synapses vs neurons? I agree that it takes a modest predictive hit from "why aren't the big animals much smarter?"
[Yudkowsky][14:53]
if adding more synapses just scales, elephants should be able to pay hominid brain costs for a much smaller added fraction of metabolism and also not pay the huge death-in-childbirth head-size tax
because their brains and heads are already 4x as huge as they need to be for GI
and now they just need some synapses, which are a much tinier fraction of their total metabolic costs
[Christiano][14:54]
I mean, you can also make smaller and cheaper synapses as evidenced by birds
I'm not sure I understand what you are saying
it's clear that you can't say "X is possible metabolically, so evolution would do it"
or else you are confused about why primate brains are so bad
[Yudkowsky][14:54]
great, then smaller and cheaper synapses should've scaled many eons earlier and taken over the world
[Christiano][14:55]
this isn't about general intelligence, this is a reductio of your position...
[Yudkowsky][14:55]
and here I had thought it was a reductio of your position...
[Christiano][14:55]
indeed
like, we all grant that it's metabolically possible to have small smart brains
and evolution doesn't do it
and I'm saying that it's also possible to have small smart brains
and that scaling brains up matters a lot
[Yudkowsky][14:56]
no, you grant that it's metabolically possible to have cheap brains full of synapses, which are therefore, on your position, smart
[Christiano][14:56]
birds are just smart
we know they are smart
this isn't some kind of weird conjecture
like, we can debate whether they are a "general" intelligence, but it makes no difference to this discussion
the point is that they do more with less metabolic cost
[Yudkowsky][14:57]
on my position, the brain needs to invent the equivalents of ReLUs and Transformers and really rather a lot of other stuff because it can't afford nearly that many GPUs, and then the marginal returns on adding expensive huge brains and synapses have increased enough that hominids start to slide down the resulting fitness slope, which isn't even paying off in guns and rockets yet, they're just getting that much intelligence out of it once the brain software has been selected to scale that well
[Christiano][14:57]
but all of the primates and birds have brain sizes scaling much faster than the other animals
like, the relevant "things started to scale" threshold is way before chimps vs humans
isn't it?
[Cotra][14:58]
to clarify, my understanding is that paul's position is "Intelligence is mainly about synapse/neuron count, and evolution doesn't care that much about intelligence; it cared more for birds and primates, and both lines are getting smarter+bigger-brained." And eliezer's position is that "evolution should care a ton about intelligence in most niches, so if it were mostly about brain size then it should have gone up to human brain sizes with the dinosaurs"
[Christiano][14:58]
or like, what is the evidence you think is explained by the threshold being between chimps and humans
[Yudkowsky][14:58]
if hominids have less efficient brains than birds, on this theory, it's because (post facto handwave) birds are tiny, so whatever cognitive fitness gradients they face, will tend to get paid more in software and biological efficiency and biologically efficient software, and less paid in Stack More Neurons (even compared to hominids)
elephants just don't have the base software to benefit much from scaling synapses even though they'd be relatively cheaper for elephants
[Christiano][14:59]
@ajeya I think that intelligence is about a lot of things, but that size (or maybe "more of the same" changes that had been happening recently amongst primates) is the big difference between chimps and humans
[Cotra][14:59]
got it yeah i was focusing on chimp-human gap when i said "intelligence" there but good to be careful
[Yudkowsky][14:59]
I have not actually succeeded in understanding Why On Earth Anybody Would Think That If Not For This Really Weird Prior I Don't Get Either
re: the "more of the same" theory of humans
[Cotra][15:00]
do you endorse my characterization of your position above? "evolution should care a ton about intelligence in most niches, so if it were mostly about brain size then it should have gone up to human brain sizes with the dinosaurs"
in which case the disagreement is about how much evolution should care about intelligence in the dinosaur niche, vs other things it could put its skill points into?
[Christiano][15:01]
Eliezer, it seems like chimps are insanely smart compared to other animals, basically as smart as they get
so it's natural to think that the main things that make humans unique are also present in chimps
or at least, there was something going on in chimps that is exceptional
and should be causally upstream of the uniqueness of humans too
otherwise you have too many coincidences on your hands
[Yudkowsky][15:02]
ajeya: no, I'd characterize that as "the human environmental niche per se does not seem super-special enough to be unique on a geological timescale, the cognitive part of the niche derives from increased cognitive abilities in the first place and so can't be used to explain where they got started, dinosaurs are larger than humans and would pay lower relative metabolic costs for added brain size and it is not the case that every species as large as humans was in an environment where they would not have benefited as much from a fixed increment of intelligence, hominids are probably distinguished from dinosaurs in having better neural algorithms that arose over intervening evolutionary time and therefore better returns in intelligence on synapses that are more costly to humans than to elephants or large dinosaurs"
[Christiano][15:03]
I don't understand how you can think that hominids are the special step relative to something earlier
or like, I can see how it's consistent, but I don't see what evidence or argument supports it
it seems like the short evolutionary time, and the fact that you also have to explain the exceptional qualities of other primates, cut extremely strongly against it
[Yudkowsky][15:04]
paul: indeed, the fact that dinosaurs didn't see their brain sizes and intelligences ballooning, says there must be a lot of stuff hominids had that dinosaurs didn't, explaining why hominids got much higher returns on intelligence per synapse. natural selection is enough of a smooth process that 95% of this stuff should've been in the last common ancestor of humans and chimps.
[Christiano][15:05]
it seems like brain size basically just increases faster in the smarter animals? though I mostly just know about birds and primates
[Yudkowsky][15:05]
that is what you'd predict from smartness being about algorithms!
[Christiano][15:05]
and it accelerates further and further within both lines
it's what you'd expect if smartness is about algorithms and chimps and birds have good algorithms
[Yudkowsky][15:06]
if smartness was about brain size, smartness and brain size would increase faster in the larger animals or the ones whose successful members ate more food per day
well, sure, I do model that birds have better algorithms than dinosaurs
[Cotra][15:07]
it seems like you've given arguments for "there was algorithmic innovation between dinosaurs and humans" but not yet arguments for "there was major algorithmic innovation between chimps and humans"?
[Christiano][15:08]
(much less that the algorithmic changes were not just more-of-the-same)
[Yudkowsky][15:08]
oh, that's not mandated by the model the same way. (between LCA of chimps and humans)
[Christiano][15:08]
isn't that exactly what we are discussing?
[Yudkowsky][15:09]
...I hadn't thought so, no.
[Cotra][15:09]
original q was:
so i thought we were talking about if there's a cool innovation from chimp->human?
[Yudkowsky][15:10]
I can see how this would have been the more obvious intended interpretation on your viewpoint, and apologize
[Christiano][15:10]
Is what I was responding to in part
I am open to saying that I'm conflating size and "algorithmic improvements that are closely correlated with size in practice and are similar to the prior algorithmic improvements amongst primates"
[Yudkowsky][15:11]
from my perspective, the question is "how did that hominid->human transition happen, as opposed to there being an elephant->smartelephant or dinosaur->smartdinosaur transition"?
I expect there were substantial numbers of brain algorithm stuffs going on during this time, however
because I don't think that synapses scale that well with the baseline hominid boost
[Christiano][15:11]
FWIW, it seems quite likely to me that there would be an elephant->smartelephant transition within tens of millions or maybe 100M years, and a dinosaur->smartdinosaur transition in hundreds of millions of years
and those are just cut off by the fastest lines getting there first
[Yudkowsky][15:12]
which I think does circle back to that point? actually I think my memory glitched and forgot the original point while being about this subpoint and I probably did interpret the original point as intended.
[Christiano][15:12]
namely primates beating out birds by a hair
[Yudkowsky][15:12]
that sounds like a viewpoint which would also think it much more likely that GPT-3 would foom in a billion years
where maybe you think that's unlikely, but I still get the impression your "unlikely" is, like, 5 orders of magnitude likelier than mine before applying overconfidence adjustments against extreme probabilities on both sides
yeah, I think I need to back up
[Cotra][15:15]
Is your position something like "at some point after dinosaurs, there was an algorithmic innovation that increased returns to brain size, which meant that the birds and the humans see their brains increasing quickly while the dinosaurs didn't"?
[Christiano][15:15]
it also seems to me like the chimp->human difference is in basically the same ballpark of the effect of brain size within humans, given modest adaptations for culture
which seems like a relevant sanity-check that made me take the "mostly hardware" view more seriously
[Yudkowsky][15:15]
there's a part of my model which very strongly says that hominids scaled better than elephants and that's why "hominids->humans but not elephants->superelephants"
[Christiano][15:15]
previously I had assumed that analysis would show that chimps were obviously way dumber than an extrapolation of humans
[Yudkowsky][15:16]
there's another part of my model which says "and it still didn't scale that well without algorithms, so we should expect a lot of alleles affecting brain circuitry which rose to fixation over the period when hominid brains were expanding"
this part is strong and I think echoes back to AGI stuff, but it is not as strong as the much more overdetermined position that hominids started with more scalable algorithms than dinosaurs.
[Christiano][15:17]
I do agree with the point that there are structural changes in brains as you scale them up, and this is potentially a reason why brain size changes more slowly than e.g. bone size. (Also there are small structural changes in ML algorithms as you scale them up, not sure how much you want to push the analogy but they feel fairly similar.)
[Yudkowsky][15:17]
this part also seems pretty blatantly false to me
is there, like, a smooth graph that you looked at there?
[Christiano][15:18]
I think the extrapolated difference would be about 4 standard deviations, so we are comparing a chimp to an IQ 40 human
[Yudkowsky][15:18]
I'm really not sure how much of a fair comparison that is
IQ 40 humans in our society may be mostly sufficiently-damaged humans, not scaled-down humans
[Christiano][15:19]
doesn't seem easy, but the point is that the extrapolated difference is huge, it corresponds to completely debilitating developmental problems
[Yudkowsky][15:19]
if you do enough damage to a human you end up with, for example, a coma victim who's not competitive with other primates at all
[Christiano][15:19]
yes, that's more than 4 SD down
I agree with this general point
I'd guess I just have a lot more respect for chimps than you do
[Yudkowsky][15:20]
I feel like I have a bunch of respect for chimps but more respect for humans
like, that stuff humans do
that is really difficult stuff!
it is not just scaled-up chimpstuff!
[Christiano][15:21]
Carl convinced me chimps wouldn't go to space, but I still really think it's about domesticity and cultural issues rather than intelligence
[Yudkowsky][15:21]
the chimpstuff is very respectable but there is a whole big layer cake of additional respect on top
[Christiano][15:21]
not a prediction to be resolved until after the singularity
I mean, the space prediction isn't very confident 🙂
and it involved a very large planet of apes
9.6. Architectural innovation in AI and in evolutionary history
[Yudkowsky][15:22]
I feel like if GPT-based systems saturate and require any architectural innovation rather than Stack More Layers to get much further, this is a pre-Singularity point of observation which favors humans probably being more qualitatively different from chimp-LCA
(LCA=last common ancestor)
[Christiano][15:22]
any seems like a kind of silly bar?
[Yudkowsky][15:23]
because single architectural innovations are allowed to have large effects!
[Christiano][15:23]
like there were already small changes to normalization from GPT-2 to GPT-3, so isn't it settled?
[Yudkowsky][15:23]
natural selection can't afford to deploy that many of them!
[Christiano][15:23]
and the model really eventually won't work if you increase layers but don't fix the normalization, there are severe problems that only get revealed at high scale
[Yudkowsky][15:23]
that I wouldn't call architectural innovation
transformers were
this is a place where I would not discuss specific ideas because I do not actually want this event to occur
[Christiano][15:24]
sure
have you seen a graph of LSTM scaling vs transformer scaling?
I think LSTM with ongoing normalization-style fixes lags like 3x behind transformers on language modeling
[Yudkowsky][15:25]
no, does it show convergence at high-enough scales?
[Christiano][15:25]
figure 7 here: https://arxiv.org/pdf/2001.08361.pdf
[Yudkowsky][15:26]
yeah... I unfortunately would rather not give other people a sense for which innovations are obviously more of the same and which innovations obviously count as qualitative
[Christiano][15:26]
I think smart money is that careful initialization and normalization on the RNN will let it keep up for longer
anyway, I'm very open to differences like LSTM vs transformer between humans and 3x-smaller-brained-ancestors, as long as you are open to like 10 similar differences further back in the evolutionary history
[Yudkowsky][15:28]
what if there's 27 differences like that and 243 differences further back in history?
[Christiano][15:28]
sure
[Yudkowsky][15:28]
is that a distinctly Yudkowskian view vs a Paul view...
apparently not
I am again feeling confused about cruxes
[Christiano][15:29]
I mean, 27 differences like transformer vs LSTM isn't actually plausible, so I guess we could talk about it
[Cotra][15:30]
Here's a potential crux articulation that ties it back to the animals stuff: paul thinks that we first discover major algorithmic innovations that improve intelligence at a low level of intelligence, analogous to evolution discovering major architectural innovations with tiny birds and primates, and then there will be a long period of scaling up plus coming up with routine algorithmic tweaks to get to the high level, analogous to evolution schlepping on the same shit for a long time to get to humans. analogously, he thinks when big innovations come onto the scene the actual product is crappy af (e.g. wright brother's plane), and it needs a ton of work to scale up to usable and then to great.
you both seem to think both evolution and tech history consiliently point in your direction
[Christiano][15:33]
that sounds vaguely right, I guess the important part of "routine" is "vaguely predictable," like you mostly work your way down the low-hanging fruit (including new fruit that becomes more important as you scale), and it becomes more and more predictable the more people are working on it and the longer you've been at it
and deep learning is already reasonably predictable (i.e. the impact of successive individual architectural changes is smaller, and law of large numbers is doing its thing) and is getting more so, and I just expect that to continue
[Cotra][15:34]
yeah, like it's a view that points to using data that relates effort to algorithmic progress and using that to predict future progress (in combination with predictions of future effort)
[Christiano][15:35]
yeah
and for my part, it feels like this is how most technologies look and also how current ML progress looks
[Cotra][15:36]
and also how evolution looks, right?
[Christiano][15:37]
you aren't seeing big jumps in translation or in self-driving cars or in image recognition, you are just seeing a long slog, and you see big jumps in areas where few people work (usually up to levels that are not in fact that important, which is very correlated with few people working there)
I don't know much about evolution, but it at least looks very consistent with what I know and the facts eliezer cites
(not merely consistent, but "explains the data just about as well as the other hypotheses on offer")
9.7. Styles of thinking in forecasting
[Yudkowsky][15:38]
I do observe that this would seem, on the surface of things, to describe the entire course of natural selection up until about 20K years ago, if you were looking at surface impacts
[Christiano][15:39]
by 20k years ago I think it's basically obvious that you are tens of thousands of years from the singularity
like, I think natural selection is going crazy with the brains by millions of years ago, and by hundreds of thousands of years ago humans are going crazy with the culture, and by tens of thousands of years ago the culture thing has accelerated and is almost at the finish line
[Yudkowsky][15:41]
really? I don't know if I would have been able to call that in advance if I'd never seen the future or any other planets. I mean, maybe, but I sure would have been extrapolating way out onto a further limb than I'm going here.
[Christiano][15:41]
Yeah, I agree singularity is way more out on a limb---or like, where the singularity stops is more uncertain since that's all that's really at issue from my perspective
but the point is that everything is clearly crazy in historical terms, in the same way that 2000 is crazy, even if you don't know where it's going
and the timescale for the crazy changes is tens of thousands of years
[Yudkowsky][15:42]
I frankly model that, had I made any such prediction 20K years ago of hominids being able to pull of moon landings or global warming - never mind the Singularity - I would have faced huge pushback from many EAs, such as, for example, Robin Hanson, and you.
[Christiano][15:42]
like I think this can't go on would have applied just as well: https://www.lesswrong.com/posts/5FZxhdi6hZp8QwK7k/this-can-t-go-on
I don't think that's the case at all
and I think you still somehow don't understand my position?
[Yudkowsky][15:43]
https://www.lesswrong.com/posts/XQirei3crsLxsCQoi/surprised-by-brains is my old entry here
[Christiano][15:43]
like, what is the move I'm making here, that you think I would have made in the past?
and would have led astray?
[Yudkowsky][15:44]
I sure do feel in a deeper sense that I am trying very hard to account for perspective shifts in how unpredictable the future actually looks at the time, and the Other is looking back at the past and organizing it neatly and expecting the future to be that neat
[Christiano][15:45]
I don't even feel like I'm expecting the future to be neat
are you just saying you have a really broad distribution over takeoff speed, and that "less than a month" gets a lot of probability because lots of numbers are less than a month?
[Yudkowsky][15:47]
not exactly?
[Christiano][15:47]
in what way is your view the one that is preferred by things being messy or unpredictable?
like, we're both agreeing X will eventually happen, and I'm making some concrete prediction about how some other X' will happen first, and that's the kind of specific prediction that's likely to be wrong?
[Yudkowsky][15:48]
more like, we sure can tell a story today about how normal and predictable AlphaGo was, but we can always tell stories like that about the past. I do not particularly recall the AI field standing up one year before AlphaGo and saying "It's time, we're coming for the 8-dan pros this year and we're gonna be world champions a year after that." (Which took significantly longer in chess, too, matching my other thesis about how these slides are getting steeper as we get closer to the end.)
[Christiano][15:49]
it's more like, you are offering AGZ as an example of why things are crazy, and I'm doubtful / think it's pretty lame
maybe I don't understand how it's functioning as bayesian evidence
for what over what
[Yudkowsky][15:50]
I feel like the whole smoothness-reasonable-investment view, if evaluated on Earth 5My ago without benefit of foresight, would have dismissed the notion of brains overtaking evolution; evaluated 1My ago, it would have dismissed the notion of brains overtaking evolution; evaluated 20Ky ago, it would have barely started to acknowledge that brains were doing anything interesting at all, but pointed out how the hominids could still only eat as much food as their niche offered them and how the cute little handaxes did not begin to compare to livers and wasp stings.
there is a style of thinking that says, "wow, yeah, people in the past sure were surprised by stuff, oh, wait, I'm also in the past, aren't I, I am one of those people"
and a view where you look back from the present and think about how reasonable the past all seems now, and the future will no doubt be equally reasonable
[Christiano][15:52]
(the AGZ example may fall flat, because the arguments we are making about it now we were also making in the past)
[Yudkowsky][15:52]
I am not sure this is resolvable, but it is among my primary guesses for a deep difference in believed styles of thought
[Christiano][15:52]
I think that's a useful perspective, but still don't see how it favors your bottom line
[Yudkowsky][15:53]
where I look at the style of thinking you're using, and say, not, "well, that's invalidated by a technical error on line 3 even on Paul's own terms" but "isn't this obviously a whole style of thought that never works and ends up unrelated to reality"
I think the first AlphaGo was the larger shock, AlphaGo Zero was a noticeable but more mild shock on account of how it showed the end of game programming and not just the end of Go
[Christiano][15:54]
sorry, I lumped them together
[Yudkowsky][15:54]
it didn't feel like the same level of surprise; it was precedented by then
the actual accomplishment may have been larger in an important sense, but a lot of the - epistemic landscape of lessons learned? - is about the things that surprise you at the time
[Christiano][15:55]
also AlphaGo was also quite easy to see coming after this paper (as was discussed extensively at the time): https://www.cs.toronto.edu/~cmaddis/pubs/deepgo.pdf
[Yudkowsky][15:55]
Paul, are you on the record as arguing with me that AlphaGo will win at Go because it's predictably on-trend?
back then?
[Cotra][15:55]
Hm, it sounds like Paul is saying "I do a trend extrapolation over long time horizons and if things seem to be getting faster and faster I expect they'll continue to accelerate; this extrapolation if done 100k years ago would have seen that things were getting faster and faster and projected singularity within 100s of K years"
Do you think Paul is in fact doing something other than the trend extrap he says he's doing, or that he would have looked at a different less informative trend than the one he says he would have looked at, or something else?
[Christiano][15:56]
my methodology for answering that question is looking at LW comments mentioning go by me, can see if it finds any
[Yudkowsky][15:56]
Different less informative trend, is most of my suspicion there?
though, actually, I should revise that, I feel like relatively little of the WHA was AlphaGo v2 whose name I forget beating Lee Se-dol, and most was in the revelation that v1 beat the high-dan pro whose name I forget.
Paul having himself predicted anything at all like this would be the actually impressive feat
that would cause me to believe that the AI world is more regular and predictable than I experienced it as, if you are paying more attention to ICLR papers than I do
9.8. Moravec's prediction
[Cotra][15:58]
And jtbc, the trend extrap paul is currently doing is something like:
and this is the wrong trend, because he shouldn't be looking at hardware/software progress across the whole big industry and should be more open to an upset innovation coming from an area with a small number of people working on it?
and he would have similarly used the wrong trends while trying to do trend extrap in the past?
[Yudkowsky][15:59]
because I feel like this general style of thought doesn't work when you use it on Earth generally, and then fails extremely hard if you try to use it on Earth before humans to figure out where the hominids are going because that phenomenon is Different from Previous Stuff
like, to be clear, I have seen this used well on solar
I feel like I saw some people calling the big solar shift based on graphs, before that happened
I have seen this used great by Moravec on computer chips to predict where computer chips would be in 2012
and also witnessed Moravec completely failing as soon as he tried to derive literally anything but the graph itself namely his corresponding prediction for human-equivalent AI in 2012 (I think, maybe it was 2010) or something
[Christiano][16:02]
(I think in his 1988 book Moravec estimated human-level AI in ~2030, not sure if you are referring to some earlier prediction?)
[Yudkowsky][16:02]
(I have seen Ray Kurzweil project out Moore's Law to the $1,000,000 human brain in, what was it, 2025, followed by the $1000 human brain in 2035 and the $1 human brain in 2045, and when I asked Ray whether machine superintelligence might shift the graph at all, he replied that machine superintelligence was precisely how the graph would be able to continue on trend. This indeed is sillier than EAs.)
[Cotra][16:03]
moravec's prediction appears to actually be around 2025, looking at his hokey graph? https://jetpress.org/volume1/moravec.htm
[Yudkowsky][16:03]
but even there, it does feel to me like there is a commonality between Kurzweil's sheer graph-worship and difficulty in appreciating the graphs as surface phenomena that are less stable than deep phenomena, and something that Hanson was doing wrong in the foom debate
[Cotra][16:03]
which is...like, your timelines?
[Yudkowsky][16:04]
that's 1998
Mind Children in 1988 I am pretty sure had an earlier prediction
[Christiano][16:04]
I should think you'd be happy to bet against me on basically any prediction, shouldn't you?
[Yudkowsky][16:05]
any prediction that sounds narrow and isn't like "this graph will be on trend in 3 more years"
...maybe I'm wrong, an online source says Mind Children in 1988 predicted AGI in "40 years" but I sure do seem to recall an extrapolated graph that reached "human-level hardware" in 2012 based on an extensive discussion about computing power to duplicate the work of the retina
[Christiano][16:08]
don't think it matters too much other than for Moravec's honor, doesn't really make a big difference for the empirical success of the methodology
I think it's on page 68 if you have the physical book
[Yudkowsky][16:09]
p60 via Google Books says 10 teraops for a human-equivalent mind
[Christiano][16:09]
I have a general read of history where trend extrapolation works extraordinarily well relative to other kinds of forecasting, to the extent that the best first-pass heuristic for whether a prediction is likely to be accurate is whether it's a trend extrapolation and how far in the future it is
[Yudkowsky][16:09]
which, incidentally, strikes me as entirely plausible if you had algorithms as sophisticated as the human brain
my sense is that Moravec nailed the smooth graph of computing power going on being smooth, but then all of his predictions about the actual future were completely invalid on account of a curve interacting with his curve that he didn't know things about and so simply omitted as a step in his calculations, namely, AGI algorithms
[Christiano][16:12]
though again, from your perspective 2030 is still a reasonable bottom-line forecast that makes him one of the most accurate people at that time?
[Yudkowsky][16:12]
you could be right about all the local behaviors that your history is already shouting out at you as having smooth curve (where by "local" I do mean to exclude stuff like world GDP extrapolated into the indefinite future) and the curves that history isn't shouting at you will tear you down
[Christiano][16:12]
(I don't know if he even forecast that)
[Yudkowsky][16:12]
I don't remember that part from the 1988 book
my memory of the 1988 book is "10 teraops, based on what it takes to rival the retina" and he drew a graph of Moore's Law
[Christiano][16:13]
yeah, I think that's what he did
(and got 2030)
[Yudkowsky][16:14]
"If this rate of improvement were to continue into the next century, the 10 teraops required for a humanlike computer would be available in a $10 million supercomputer before 2010 and in a $1,000 personal computer by 2030."
[Christiano][16:14]
or like, he says "human equivalent in 40 years" and predicts that in 50 years we will have robots with superhuman reasoning ability, not clear he's ruling out human-equivalent AGI before 40 years but I think the tone is clear
[Yudkowsky][16:15]
so 2030 for AGI on a personal computer and 2010 for AGI on a supercomputer, and I expect that on my first reading I simply discarded the former prediction as foolish extrapolation past the model collapse he had just predicted in 2010.
(p68 in "Powering Up")
[Christiano][16:15]
yeah, that makes sense
I do think the PC number seems irrelevant
[Cotra][16:16]
I think both in that book and in the 98 article he wants you to pay attention to the "very cheap human-size computers" threshold, not the "supercomputer" threshold, i think intentionally as a way to handwave in "we need people to be able to play around with these things"
(which people criticized him at the time for not more explicitly modeling iirc)
[Yudkowsky][16:17]
but! I mean! there are so many little places where the media has a little cognitive hiccup about that and decides in 1998 that it's fine to describe that retrospectively as "you predicted in 1988 that we'd have true AI in 40 years" and then the future looks less surprising than people at the time using Trend Logic were actually surprised by it!
all these little ambiguities and places where, oh, you decide retroactively that it would have made sense to look at this Trend Line and use it that way, but if you look at what people said at the time, they didn't actually say that!
[Christiano][16:19]
I mean, in fairness reading the book it just doesn't seem like he is predicting human-level AI in 2010 rather than 2040, but I do agree that it seems like the basic methodology (why care about the small computer thing?) doesn't really make that much sense a priori and only leads to something sane if it cancels out with a weird view
9.9. Prediction disagreements and bets
[Christiano][16:19]
anyway, I'm pretty unpersuaded by the kind of track record appeal you are making here
[Yudkowsky][16:20]
if the future goes the way I predict and yet anybody somehow survives, perhaps somebody will draw a hyperbolic trendline on some particular chart where the trendline is retroactively fitted to events including those that occurred in only the last 3 years, and say with a great sage nod, ah, yes, that was all according to trend, nor did anything depart from trend
trend lines permit anything
[Christiano][16:20]
like from my perspective the fundamental question is whether I would do better or worse by following the kind of reasoning you'd advocate, and it just looks to me like I'd do worse, and I'd love to make any predictions about anything to help make that more clear and hindsight-proof in advance
[Yudkowsky][16:20]
you just look into the past and find a line you can draw that ended up where reality went
[Christiano][16:21]
it feels to me like you really just waffle on almost any prediction about the before-end-of-days
[Yudkowsky][16:21]
I don't think I know a lot about the before-end-of-days
[Christiano][16:21]
like if you make a prediction I'm happy to trade into it, or you can pick a topic and I can make a prediction and you can trade into mine
[Cotra][16:21]
but you know enough to have strong timing predictions, e.g. your bet with caplan
[Yudkowsky][16:21]
it's daring enough that I claim to know anything about the Future at all!
[Cotra][16:21]
surely with that difference of timelines there should be some pre-2030 difference as well
[Christiano][16:21]
but you are the one making the track record argument against my way of reasoning about things!
how does that not correspond to believing that your predictions are better!
what does that mean?
[Yudkowsky][16:22]
yes and if you say something narrow enough or something that my model does at least vaguely push against, we should bet
[Christiano][16:22]
my point is that I'm willing to make a prediction about any old thing, you can name your topic
I think the way I'm reasoning about the future is just better in general
and I'm going to beat you on whatever thing you want to bet on
[Yudkowsky][16:22]
but if you say, "well, Moore's Law on trend, next 3 years", then I'm like, "well, yeah, sure, since I don't feel like I know anything special about that, that would be my prediction too"
[Christiano][16:22]
sure
you can pick the topic
pick a quantity
or a yes/no question
or whatever
[Yudkowsky][16:23]
you may know better than I would where your Way of Thought makes strong, narrow, or unusual predictions
[Christiano][16:23]
I'm going to trend extrapolation everywhere
spoiler
[Yudkowsky][16:23]
okay but any superforecaster could do that and I could do the same by asking a superforecaster
[Cotra][16:24]
but there must be places where you'd strongly disagree w the superforecaster
since you disagree with them eventually, e.g. >2/3 doom by 2030
[Bensinger][18:40] (Nov. 25 follow-up comment)
">2/3 doom by 2030" isn't an actual Eliezer-prediction, and is based on a misunderstanding of something Eliezer said. See Eliezer's comment on LessWrong.
[Yudkowsky][16:24]
in the terminal phase, sure
[Cotra][16:24]
right, but there are no disagreements before jan 1 2030?
no places where you'd strongly defy the superforecasters/trend extrap?
[Yudkowsky][16:24]
superforecasters were claiming that AlphaGo had a 20% chance of beating Lee Se-dol and I didn't disagree with that at the time, though as the final days approached I became nervous and suggested to a friend that they buy out of a bet about that
[Cotra][16:25]
what about like whether we get some kind of AI ability (e.g. coding better than X) before end days
[Yudkowsky][16:25]
though that was more because of having started to feel incompetent and like I couldn't trust the superforecasters to know more, than because I had switched to a confident statement that AlphaGo would win
[Cotra][16:25]
seems like EY's deep intelligence / insight-oriented view should say something about what's not possible before we get the "click" and the FOOM
[Christiano][16:25]
I mean, I'm OK with either (i) evaluating arguments rather than dismissive and IMO totally unjustified track record, (ii) making bets about stuff
I don't see how we can both be dismissing things for track record reasons and also not disagreeing about things
if our methodologies agree about all questions before end of days (which seems crazy to me) then surely there is no track record distinction between them...
[Cotra][16:26]
do you think coding models will be able to 2x programmer productivity before end days? 4x?
what about hardware/software R&D wages? will they get up to $20m/yr for good ppl?
will someone train a 10T param model before end days?
[Christiano][16:27]
things I'm happy to bet about: economic value of LMs or coding models at 2, 5, 10 years, benchmark performance of either, robotics, wages in various industries, sizes of various industries, compute/$, someone else's views about "how ML is going" in 5 years
maybe the "any GDP acceleration before end of days?" works, but I didn't like how you don't win until the end of days
[Yudkowsky][16:28]
okay, so here's an example place of a weak general Yudkowskian prediction, that is weaker than terminal-phase stuff of the End Days: (1) I predict that cycles of 'just started to be able to do Narrow Thing -> blew past upper end of human ability at Narrow Thing' will continue to get shorter, the same way that, I think, this happened faster with Go than with chess.
[Christiano][16:28]
great, I'm totally into it
what's a domain?
coding?
[Yudkowsky][16:28]
Does Paul disagree? Can Paul point to anything equally specific out of Paul's viewpoint?
[Christiano][16:28]
benchmarks for LMs?
robotics?
[Yudkowsky][16:28]
well, for these purposes, we do need some Elo-like ability to measure at all where things are relative to humans
[Cotra][16:29]
problem-solving benchmarks for code?
MATH benchmark?
[Christiano][16:29]
well, for coding and LM'ing we have lots of benchmarks we can use
[Yudkowsky][16:29]
this unfortunately does feel a bit different to me from Chess benchmarks where the AI is playing the whole game; Codex is playing part of the game
[Christiano][16:29]
in general the way I'd measure is by talking about how fast you go from "weak human" to "strong human" (e.g. going from top-10,000 in chess to top-10 or whatever, going from jobs doable by $50k/year engineer to $500k/year engineer...)
[Yudkowsky][16:30]
golly, that sounds like a viewpoint very favorable to mine
[Christiano][16:30]
what do you mean?
that way of measuring would be favorable to your viewpoint?
[Yudkowsky][16:31]
if we measure how far it takes AI to go past different levels of paying professionals, I expect that the Chess duration is longer than the Go duration and that by the time Codex is replacing
amost paid $50k/year programmers the time to replacingamost programmers paid as much as a top Go player will be pretty darned short[Christiano][16:31]
top Go players don't get paid, do they?
[Yudkowsky][16:31]
they tutor students and win titles
[Christiano][16:31]
but I mean, they are like low-paid engineers
[Yudkowsky][16:31]
yeah that's part of the issue here
[Christiano][16:31]
I'm using wages as a way to talk about the distribution of human abilities, not the fundamental number
[Yudkowsky][16:32]
I would expect something similar to hold over going from low-paying welder to high-paying welder
[Christiano][16:32]
like, how long to move from "OK human" to "pretty good human" to "best human"
[Cotra][16:32]
says salary of $350k/yr for lee: https://www.fameranker.com/lee-sedol-net-worth
[Yudkowsky][16:32]
but I also mostly expect that AIs will not be allowed to weld things on Earth
[Cotra][16:32]
why don't we just do an in vitro benchmark instead of wages?
[Christiano][16:32]
what, machines already do virtually all welding?
[Cotra][16:32]
just pick a benchmark?
[Yudkowsky][16:33]
yoouuuu do not want to believe sites like that (fameranker)
[Christiano][16:33]
yeah, I'm happy with any benchmark, and then we can measure various human levels at that benchmark
[Cotra][16:33]
what about MATH? https://arxiv.org/abs/2103.03874
[Christiano][16:34]
also I don't know what "shorter and shorter" means, the time in go and chess was decades to move from "strong amateur" to "best human," I do think these things will most likely be shorter than decades
seems like we can just predict concrete #s though
like I can say how long I think it will take to get from "median high schooler" to "IMO medalist" and you can bet against me?
and if we just agree about all of those predictions then again I'm back to being very skeptical of a claimed track record difference between our models
(I do think that it's going to take years rather than decades on all of these things)
[Yudkowsky][16:36]
possibly! I worry this ends up in a case where Katja or Luke or somebody goes back and collects data about "amateur to pro performance times" and Eliezer says "Ah yes, these are shortening over time, just as I predicted" and Paul is like "oh, well, I predict they continue to shorten on this trend drawn from the data" and Eliezer is like "I guess that could happen for the next 5 years, sure, sounds like something a superforecaster would predict as default"
[Cotra][16:37]
i'm pretty sure paul's methodology here will just be to look at the MATH perf trend based on model size and combine with expectations of when ppl will make big enough models, not some meta trend thing like that?
[Yudkowsky][16:37]
so I feel like... a bunch of what I feel is the real disagreement in our models, is a bunch of messy stuff Suddenly Popping Up one day and then Eliezer is like "gosh, I sure didn't predict that" and Paul is like "somebody could have totally predicted that" and Eliezer is like "people would say exactly the same thing after the world ended in 3 minutes"
if we've already got 2 years of trend on a dataset, I'm not necessarily going to predict the trend breaking
[Cotra][16:38]
hm, you're presenting your view as more uncertain and open to anything here than paul's view, but in fact it's picking out a narrower distribution. you're more confident in powerful AGI soon
[Christiano][16:38]
seems hard to play the "who is more confident?" game
[Cotra][16:38]
so there should be some places where you make a strong positive prediction paul disagrees with
[Yudkowsky][16:39]
I might want to buy options on a portfolio of trends like that, if Paul is willing to sell me insurance against all of the trends breaking upward at a lower price than I think is reasonable
I mean, from my perspective Paul is the one who seems to think the world is well-organized and predictable in certain ways
[Christiano][16:39]
yeah, and you are saying that I'm overconfident about that
[Yudkowsky][16:39]
I keep wanting Paul to go on and make narrower predictions than I do in that case
[Christiano][16:39]
so you should be happy to bet with me about anything
and I'm letting you pick anything at all you want to bet about
[Cotra][16:40]
i mean we could do a portfolio of trends like MATH and you could bet on at least a few of them having strong surprises in the sooner direction
but that means we could just bet about MATH and it'd just be higher variance
[Yudkowsky][16:40]
ok but you're not going to sell me cheap options on sharp declines in the S&P 500 even though in a very reasonable world there would not be any sharp declines like that
[Christiano][16:41]
if we're betting $ rather than bayes points, then yes I'm going to weigh worlds based on the value of $ in those worlds
[Cotra][16:41]
wouldn't paul just sell you options at the price the options actually trade for? i don't get it
[Christiano][16:41]
but my sense is that I'm just generally across the board going to be more right than you are, and I'm frustrated that you just keep saying that "people like me" are wrong about stuff
[Yudkowsky][16:41]
Paul's like "we'll see smooth behavior in the end days" and I feel like I should be able to say "then Paul, sell me cheap options against smooth behavior now" but Paul is just gonna wanna sell at market price
[Christiano][16:41]
and so I want to hold you to that by betting about anything
ideally just tons of stuff
random things about what AI will be like, and other technologies, and regulatory changes
[Cotra][16:42]
paul's view doesn't seem to imply that he should value those options less than the market
he's more EMH-y than you not less
[Yudkowsky][16:42]
but then the future should behave like that market
[Christiano][16:42]
what do you mean?
[Yudkowsky][16:42]
it should have options on wild behavior that are not cheap!
[Christiano][16:42]
you mean because people want $ more in worlds where the market drops a lot?
I don't understand the analogy
[Yudkowsky][16:43]
no, because jumpy stuff happens more than it would in a world of ideal agents
[Cotra][16:43]
I think EY is saying the non-cheap option prices are because P(sharp declines) is pretty high
[Christiano][16:43]
ok, we know how often markets jump, if that's the point of your argument can we just talk about that directly?
[Yudkowsky][16:43]
or sharp rises, for that matter
[Christiano][16:43]
(much lower than option prices obviously)
I'm probably happy to sell you options for sharp rises
I'll give you better than market odds in that direction
that's how this works
[Yudkowsky][16:44]
now I am again confused, for I thought you were the one who expected world GDP to double in 4 years at some point
and indeed, drew such graphs with the rise suggestively happening earlier than the sharp spike
[Christiano][16:44]
yeah, and I have exposure to that by buying stocks, options prices are just a terrible way of tracking these things
[Yudkowsky][16:44]
suggesting that such a viewpoint is generally favor to near timelines for that
[Christiano][16:44]
I mean, I have bet a lot of money on AI companies doing well
well, not compared to the EA crowd, but compared to my meager net worth 🙂
and indeed, it has been true so far
and I'm continuing to make the bet
it seems like on your view it should be surprising that AI companies just keep going up
aren't you predicting them not to get to tens of trillions of valuation before the end of days?
[Yudkowsky][16:45]
I believe that Nate, of a generally Yudkowskian view, did the same (bought AI companies). and I focused my thoughts elsewhere, because somebody needs to, but did happen to buy my first S&P 500 on its day of exact minimum in 2020
[Christiano][16:46]
point is, that's how you get exposure to the crazy growth stuff with continuous ramp-ups
and I'm happy to make the bet on the market
or on other claims
I don't know if my general vibe makes sense here, and why it seems reasonable to me that I'm just happy to bet on anything
as a way of trying to defend my overall attack
and that if my overall epistemic approach is vulnerable to some track record objection, then it seems like it ought to be possible to win here
9.10. Prediction disagreements and bets: Standard superforecaster techniques
[Cotra][16:47]
I'm still kind of surprised that Eliezer isn't willing to bet that there will be a faster-than-Paul expects trend break on MATH or whatever other benchmark. Is it just the variance of MATH being one benchmark? Would you make the bet if it were 6?
[Yudkowsky][16:47]
a large problem here is that both of us tend to default strongly to superforecaster standard techniques
[Christiano][16:47]
it's true, though it's less true for longer things
[Cotra][16:47]
but you think the superforecasters would suck at predicting end days because of the surface trends thing!
[Yudkowsky][16:47]
before I bet against Paul on MATH I would want to know that Paul wasn't arriving at the same default I'd use, which might be drawn from trend lines there, or from a trend line in trend lines
I mean the superforecasters did already suck once in my observation, which was AlphaGo, but I did not bet against them there, I bet with them and then updated afterwards
[Christiano][16:48]
I'd mostly try to eyeball how fast performance was improving with size; I'd think about difficulty effects (where e.g. hard problems will be flat for a while and then go up later, so you want to measure performance on a spectrum of difficulties)
[Cotra][16:48]
what if you bet against a methodology instead of against paul's view? the methodology being the one i described above, of looking at the perf based on model size and then projecting model size increases by cost?
[Christiano][16:48]
seems safer to bet against my view
[Cotra][16:48]
yeah
[Christiano][16:48]
mostly I'd just be eyeballing size, thinking about how much people will in fact scale up (which would be great to factor out if possible), assuming performance trends hold up
are there any other examples of surface trends vs predictable deep changes, or is AGI the only one?
(that you have thought a lot about)
[Cotra][16:49]
yeah seems even better to bet on the underlying "will the model size to perf trends hold up or break upward"
[Yudkowsky][16:49]
so from my perspective, there's this whole thing where unpredictably something breaks above trend because the first way it got done was a way where somebody could do it faster than you expected
[Christiano][16:49]
(makes sense for it to be the domain where you've thought a lot)
you mean, it's unpredictable what will break above trend?
[Cotra][16:49]
IEM has a financial example
[Yudkowsky][16:49]
I mean that I could not have said "Go will break above trend" in 2015
[Christiano][16:49]
yeah
ok, here's another example
[Yudkowsky][16:50]
it feels like if I want to make a bet with imaginary Paul in 2015 then I have to bet on a portfolio
and I also feel like as soon as we make it that concrete, Paul does not want to offer me things that I want to bet on
because Paul is also like, sure, something might break upward
I remark that I have for a long time been saying that I wish Paul had more concrete images and examples attached to a lot of his stuff
[Cotra][16:51]
surely the view is about the probability of each thing breaking upward. or the expected number from a basket
[Christiano][16:51]
I mean, if you give me any way of quantifying how much stuff breaks upwards we have a bet
[Cotra][16:51]
not literally that one single thing breaks upward
[Christiano][16:51]
I don't understand how concreteness is an accusation here, I've offered 10 quantities I'd be happy to bet about, and also allowed you to name literally any other quantity you want
and I agree that we mostly agree about things
[Yudkowsky][16:52]
and some of my sense here is that if Paul offered a portfolio bet of this kind, I might not take it myself, but EAs who were better at noticing their own surprise might say, "Wait, that's how unpredictable Paul thinks the world is?"
so from my perspective, it is hard to know specific anti-superforecaster predictions that happen long before terminal phase, and I am not sure we are really going to get very far there.
[Christiano][16:53]
but you agree that the eventual prediction is anti-superforecaster?
[Yudkowsky][16:53]
both of us probably have quite high inhibitions against selling conventionally priced options that are way not what a superforecaster would price them as
[Cotra][16:53]
why does it become so much easier to know these things and go anti-superforecaster at terminal phase?
[Christiano][16:53]
I assume you think that the superforecasters will continue to predict that big impactful AI applications are made by large firms spending a lot of money, even through the end of days
I do think it's very often easy to beat superforecasters in-domain
like I expect to personally beat them at most ML prediction
and so am also happy to do bets where you defer to superforecasters on arbitrary questions and I bet against you
[Yudkowsky][16:54]
well, they're anti-prediction-market in the sense that, at the very end, bets can no longer settle. I've been surprised of late by how much AGI ruin seems to be sneaking into common knowledge; perhaps in the terminal phase the superforecasters will be like, "yep, we're dead". I can't even say that in this case, Paul will disagree with them, because I expect the state on alignment to be so absolutely awful that even Paul is like "You were not supposed to do it that way" in a very sad voice.
[Christiano][16:55]
I'm just thinking about takeoff speeds here
I do think it's fairly likely I'm going to be like "oh no this is bad" (maybe 50%?), but not that I'm going to expect fast takeoff
and similarly for the superforecasters
9.11. Prediction disagreements and bets: Late-stage predictions, and betting against superforecasters
[Yudkowsky][16:55]
so, one specific prediction you made, sadly close to terminal phase but not much of a surprise there, is that the world economy must double in 4 years before the End Times are permitted to begin
[Christiano][16:56]
well, before it doubles in 1 year...
I think most people would call the 4 year doubling the end times
[Yudkowsky][16:56]
this seems like you should also be able to point to some least impressive thing that is not permitted to occur before WGDP has doubled in 4 years
[Christiano][16:56]
and it means that the normal planning horizon includes the singularity
[Yudkowsky][16:56]
it may not be much but we would be moving back the date of first concrete disagreement
[Christiano][16:57]
I can list things I don't think would happen first, since that's a ton
[Yudkowsky][16:57]
and EAs might have a little bit of time in which to say "Paul was falsified, uh oh"
[Christiano][16:57]
the only things that aren't permitted are the ones that would have caused the world economy to double in 4 years
[Yudkowsky][16:58]
and by the same token, there are things Eliezer thinks you are probably not going to be able to do before you slide over the edge. a portfolio of these will have some losing options because of adverse selection against my errors of what is hard, but if I lose more than half the portfolio, this may said to be a bad sign for Eliezer.
[Christiano][16:58]
(though those can happen at the beginning of the 4 year doubling)
[Yudkowsky][16:58]
this is unfortunately late for falsifying our theories but it would be progress on a kind of bet against each other
[Christiano][16:59]
but I feel like the things I'll say are like fully automated construction of fully automated factories at 1-year turnarounds, and you're going to be like "well duh"
[Yudkowsky][16:59]
...unfortunately yes
[Christiano][16:59]
the reason I like betting about numbers is that we'll probably just disagree on any given number
[Yudkowsky][16:59]
I don't think I know numbers.
[Christiano][16:59]
it does seem like a drawback that this can just turn up object-level differences in knowledge-of-numbers more than deep methodological advantages
[Yudkowsky][17:00]
the last important number I had a vague suspicion I might know was that Ethereum ought to have a significantly larger market cap in pre-Singularity equilibrium.
and I'm not as sure of that one since El Salvador supposedly managed to use Bitcoin L2 Lightning.
(though I did not fail to act on the former belief)
[Christiano][17:01]
do you see why I find it weird that you think there is this deep end-times truth about AGI, that is very different from a surface-level abstraction and that will take people like Paul by surprise, without thinking there are other facts like that about the world?
I do see how this annoying situation can come about
and I also understand the symmetry of the situation
[Yudkowsky][17:02]
we unfortunately both have the belief that the present world looks a lot like our being right, and therefore that the other person ought to be willing to bet against default superforecasterish projections
[Cotra][17:02]
paul says that he would bet against superforecasters too though
[Christiano][17:02]
I would in ML
[Yudkowsky][17:02]
like, where specifically?
[Christiano][17:02]
or on any other topic where I can talk with EAs who know about the domain in question
I don't know if they have standing forecasts on things, but e.g.: (i) benchmark performance, (ii) industry size in the future, (iii) how large an LM people will train, (iv) economic impact of any given ML system like codex, (v) when robotics tasks will be plausible
[Yudkowsky][17:03]
I have decided that, as much as it might gain me prestige, I don't think it's actually the right thing for me to go spend a bunch of character points on the skills to defeat superforecasters in specific domains, and then go around doing that to prove my epistemic virtue.
[Christiano][17:03]
that seems fair
[Yudkowsky][17:03]
you don't need to bet with me to prove your epistemic virtue in this way, though
okay, but, if I'm allowed to go around asking Carl Shulman who to ask in order to get the economic impact of Codex, maybe I can also defeat superforecasters.
[Christiano][17:04]
I think the deeper disagreement is that (i) I feel like my end-of-days prediction is also basically just a default superforecaster prediction (and if you think yours is too then we can bet about what some superforecasters will say on it), (ii) I think you are leveling a much stronger "people like paul get taken by surprise by reality" claim whereas I'm just saying that I don't like your arguments
[Yudkowsky][17:04]
it seems to me like the contest should be more like our intuitions in advance of doing that
[Christiano][17:04]
yeah, I think that's fine, and also cheaper since research takes so much time
I feel like those asymmetries are pretty strong though
9.12. Self-duplicating factories, AI spending, and Turing test variants
[Yudkowsky][17:05]
so, here's an idea that is less epistemically virtuous than our making Nicely Resolvable Bets
what if we, like, talked a bunch about our off-the-cuff senses of where various AI things are going in the next 3 years
and then 3 years later, somebody actually reviewed that
[Christiano][17:06]
I do think just saying a bunch of stuff about what we expect will happen so that we can look back on it would have a significant amount of the value
[Yudkowsky][17:06]
and any time the other person put a thumbs-up on the other's prediction, that prediction coming true was not taken to distinguish them
[Cotra][17:06]
i'd suggest doing this in a format other than discord for posterity
[Yudkowsky][17:06]
even if the originator was like HOW IS THAT ALSO A PREDICTION OF YOUR THEORY
well, Discord has worked better than some formats
[Cotra][17:07]
something like a spreadsheet seems easier for people to look back on and score and stuff
discord transcripts are pretty annoying to read
[Yudkowsky][17:08]
something like a spreadsheet seems liable to be high-cost and not actually happen
[Christiano][17:08]
I think a conversation is probably easier and about as good for our purposes though?
[Cotra][17:08]
ok fair
[Yudkowsky][17:08]
I think money can be inserted into humans in order to turn Discord into spreadsheets
[Christiano][17:08]
and it's possible we will both think we are right in retrospect
and that will also be revealing
[Yudkowsky][17:09]
but, besides that, I do want to boop on the point that I feel like Paul should be able to predict intuitively, rather than with necessity, things that should not happen before the world economy doubled in 4 years
[Christiano][17:09]
it may also turn up some quantitative differences of view
there are lots of things I think won't happen before the world economy has doubled in 4 years
[Yudkowsky][17:09]
because on my model, as we approach the end times, AI was still pretty partial and also the world economy was lolnoping most of the inputs a sensible person would accept from it and prototypes weren't being commercialized and stuff was generally slow and messy
[Christiano][17:09]
prototypes of factories building factories in <2 years
[Yudkowsky][17:10]
"AI was still pretty partial" leads it to not do interesting stuff that Paul can rule out
[Christiano][17:10]
like I guess I think tesla will try, and I doubt it will be just tesla
[Yudkowsky][17:10]
but the other parts of that permit AI to do interesting stuff that Paul can rule out
[Christiano][17:10]
automated researchers who can do ML experiments from 2020 without human input
[Yudkowsky][17:10]
okay, see, that whole "factories building factories" thing just seems so very much after the End Times to me
[Christiano][17:10]
yeah, we should probably only talk about cognitive work
since you think physical work will be very slow
[Yudkowsky][17:11]
okay but not just that, it's a falsifiable prediction
it is something that lets Eliezer be wrong in advance of the End Times
[Christiano][17:11]
what's a falsifiable prediction?
[Yudkowsky][17:11]
if we're in a world where Tesla is excitingly gearing up to build a fully self-duplicating factory including its mining inputs and chips and solar panels and so on, we're clearly in the Paulverse and not in the Eliezerverse!
[Christiano][17:12]
yeah
I do think we'll see that before the end times
just not before 4 year doublings
[Yudkowsky][17:12]
this unfortunately only allows you to be right, and not for me to be right, but I think there are also things you legit only see in the Eliezerverse!
[Christiano][17:12]
I mean, I don't think they will be doing mining for a long time because it's cheap
[Yudkowsky][17:12]
they are unfortunately late in the game but they exist at all!
and being able to state them is progress on this project!
[Christiano][17:13]
but fully-automated factories first, and then significant automation of the factory-building process
I do expect to see
I'm generally pretty bullish on industrial robotics relative to you I think, even before the crazy stuff?
but you might not have a firm view
like I expect to have tons of robots doing all kinds of stuff, maybe cutting human work in manufacturing 2x, with very modest increases in GDP resulting from that in particular
[Yudkowsky][17:13]
so, like, it doesn't surprise me very much if Tesla manages to fully automate a factory that takes in some relatively processed inputs including refined metals and computer chips, and outputs a car? and by the same token I expect that has very little impact on GDP.
[Christiano][17:14]
refined metals are almost none of the cost of the factory
and also tesla isn't going to be that vertically integrated
the fabs will separately continue to be more and more automated
I expect to have robot cars driving everywhere, and robot trucks
another 2x fall in humans required for warehouses
elimination of most brokers involved in negotiating shipping
[Yudkowsky][17:15]
if despite the fabs being more and more automated, somehow things are managing not to cost less and less, and that sector of the economy is not really growing very much, is that more like the Eliezerverse than the Paulverse?
[Christiano][17:15]
most work in finance and loan origination
[Yudkowsky][17:15]
though this is something of a peripheral prediction to AGI core issues
[Christiano][17:16]
yeah, I think if you cut the humans to do X by 2, but then the cost falls much less than the number you'd naively expect (from saving on the human labor and paying for the extra capital), then that's surprising to me
I mean if it falls half as much as you'd expect on paper I'm like "that's a bit surprising" rather than having my mind blown, if it doesn't fall I'm more surprised
but that was mostly physical economy stuff
oh wait, I was making positive predictions now, physical stuff is good for that I think?
since you don't expect it to happen?
[Yudkowsky][17:17]
...this is not your fault but I wish you'd asked me to produce my "percentage of fall vs. paper calculation" estimate before you produced yours
my mind is very whiffy about these things and I am not actually unable to deanchor on your estimate 😦
[Christiano][17:17]
makes sense, I wonder if I should just spoiler
one benefit of discord
[Yudkowsky][17:18]
yeah that works too!
[Christiano][17:18]
a problem for prediction is that I share some background view about insane inefficiency/inadequacy/decadence/silliness
so these predictions are all tampered by that
but still seem like there are big residual disagreements
[Yudkowsky][17:19]
sighgreat
[Christiano][17:19]
since you have way more of that than I do
[Yudkowsky][17:19]
not your fault but
[Christiano][17:19]
I think that the AGI stuff is going to be a gigantic megaproject despite that
[Yudkowsky][17:19]
I am not shocked by the AGI stuff being a gigantic megaproject
it's not above the bar of survival but, given other social optimism, it permits death with more dignity than by other routes
[Christiano][17:20]
what if spending is this big:
Google invests $100B training a model, total spending across all of industry is way bigger
[Yudkowsky][17:20]
ooooh
I do start to be surprised if, come the end of the world, AGI is having more invested in it than a TSMC fab
though, not... super surprised?
also I am at least a little surprised before then
actually I should probably have been spoiling those statements myself but my expectation is that Paul's secret spoiler is about
$10 trillion dollars or something equally totally shocking to an Eliezer
[Christiano][17:22]
my view on that level of spending is
it's an only slightly high-end estimate for spending by someone on a single model, but that in practice there will be ways of dividing more across different firms, and that the ontology of single-model will likely be slightly messed up (e.g. by OpenAI Five-style surgery). Also if it's that much then it likely involves big institutional changes and isn't at google.
I read your spoiler
my estimate for total spending for the whole project of making TAI, including hardware and software manufacturing and R&d, the big datacenters, etc.
is in the ballpark of $10T, though it's possible that it will be undercounted several times due to wage stickiness for high-end labor
[Yudkowsky][17:24]
I think that as
spending on particular AGI megaprojects starts to go past $50 billion, it's not especially ruled out per se by things that I think I know for sure, but I feel like a third-party observer should justly start to weakly think, 'okay, this is looking at least a little like the Paulverse rather than the Eliezerverse', and as we get to $10 trillion, that is not absolutely ruled out by the Eliezerverse but it was a whoole lot more strongly predicted by the Paulverse, maybe something like 20x unless I'm overestimating how strongly Paul predicts that
[Christiano][17:24]
Proposed modification to the "speculate about the future to generate kind-of-predictions" methodology: we make shit up, then later revise based on points others made, and maybe also get Carl to sanity-check and deciding which of his objections we agree with. Then we can separate out the "how good are intuitions" claim (with fast feedback) from the all-things-considered how good was the "prediction"
[Yudkowsky][17:25]
okay that hopefully allows me to read Paul's spoilers... no I'm being silly. @ajeya please read all the spoilers and say if it's time for me to read his
[Cotra][17:25]
you can read his latest
[Christiano][17:25]
I'd guess it's fine to read all of them?
[Cotra][17:26]
yeah sorry that's what i meant
[Yudkowsky][17:26]
what should I say more about before reading earlier ones?
ah k
[Christiano][17:26]
My $10T estimate was after reading yours (didn't offer an estimate on that quantity beforehand), though that's the kind of ballpark I often think about, maybe we should just spoiler only numbers so that context is clear 🙂
I think fast takeoff gets significantly more likely as you push that number down
[Yudkowsky][17:27]
so, may I now ask what starts to look to you like "oh damn I am in the Eliezerverse"?
[Christiano][17:28]
big mismatches between that AI looks technically able to do and what AI is able to do, though that's going to need a lot of work to operationalize
I think low growth of AI overall feels like significant evidence for Eliezerverse (even if you wouldn't make that prediction), since I'm forecasting it rising to absurd levels quite fast whereas your model is consistent with it staying small
some intuition about AI looking very smart but not able to do much useful until it has the whole picture, I guess this can be combined with the first point to be something like---AI looks really smart but it's just not adding much value
all of those seem really hard
[Cotra][17:30]
strong upward trend breaks on benchmarks seems like it should be a point toward eliezer verse, even if eliezer doesn't want to bet on a specific one?
especially breaks on model size -> perf trends rather than calendar time trends
[Christiano][17:30]
I think that any big break on model size -> perf trends are significant evidence
[Cotra][17:31]
meta-learning working with small models?
e.g. model learning-to-learn video games and then learning a novel one in a couple subjective hours
[Christiano][17:31]
I think algorithmic/architectural changes that improve loss as much as 10x'ing model, for tasks that looking like they at least should have lots of economic value
(even if they don't end up having lots of value because of deployment bottlenecks)
is the meta-learning thing an Eliezer prediction?
(before the end-of-days)
[Cotra][17:32]
no but it'd be an anti-bio-anchor positive trend break and eliezer thinks those should happen more than we do
[Christiano][17:32]
fair enough
a lot of these things are about # of times that it happens rather than whether it happens at all
[Cotra][17:32]
yeah
but meta-learning is special as the most plausible long horizon task
[Christiano][17:33]
e.g. maybe in any given important task I expect a single "innovation" that's worth 10x model size? but that it still represents a minority of total time?
hm, AI that can pass a competently administered turing test without being economically valuable?
that's one of the things I think is ruled out before 4 year doubling, though Eliezer probably also doesn't expect it
[Cotra][17:34]
what would this test do to be competently administered? like casual chatbots seem like they have reasonable probability of fooling someone for a few mins now
[Christiano][17:34]
I think giant google-automating-google projects without big external economic impacts
[Cotra][17:34]
would it test knowledge, or just coherence of some kind?
[Christiano][17:35]
it's like a smart-ish human (say +2 stdev at this task) trying to separate out AI from smart-ish human, iterating a few times to learn about what works
I mean, the basic ante is that the humans are trying to win a turing test, without that I wouldn't even call it a turing test
dunno if any of those are compelling @Eliezer
something that passes a like "are you smart?" test administered by a human for 1h, where they aren't trying to specifically tell if you are AI
just to see if you are as smart as a human
I mean, I guess the biggest giveaway of all would be if there is human-level (on average) AI as judged by us, but there's no foom yet
[Yudkowsky][17:37]
I think we both don't expect that one before the End of Days?
[Christiano][17:37]
or like, no crazy economic impact
I think we both expect that to happen before foom?
but the "on average" is maybe way too rough a thing to define
[Yudkowsky][17:37]
oh, wait, I missed that it wasn't the full Turing Test
[Christiano][17:37]
well, I suggested both
the lamer one is more plausible
[Yudkowsky][17:38]
full Turing Test happeneth not before the End Times, on Eliezer's view, and not before the first 4-year doubling time, on Paul's view, and the first 4-year doubling happeneth not before the End Times, on Eliezer's view, so this one doesn't seem very useful
9.13. GPT-n and small architectural innovations vs. large ones
[Christiano][17:39]
I feel like the biggest subjective thing is that I don't feel like there is a "core of generality" that GPT-3 is missing
I just expect it to gracefully glide up to a human-level foom-ing intelligence
[Yudkowsky][17:39]
the "are you smart?" test seems perhaps passable by GPT-6 or its kin, which I predict to contain at least one major architectural difference over GPT-3 that I could, pre-facto if anyone asked, rate as larger than a different normalization method
but by fooling the humans more than by being smart
[Christiano][17:39]
like I expect GPT-5 would foom if you ask it but take a long time
[Yudkowsky][17:39]
that sure is an underlying difference
[Christiano][17:39]
not sure how to articulate what Eliezer expects to see here though
or like what the difference is
[Cotra][17:39]
something that GPT-5 or 4 shouldn't be able to do, according to eliezer?
where Paul is like "sure it could do that"?
[Christiano][17:40]
I feel like GPT-3 clearly has some kind of "doesn't really get what's going on" energy
and I expect that to go away
well before the end of days
so that it seems like a kind-of-dumb person
[Yudkowsky][17:40]
I expect it to go away before the end of days
but with there having been a big architectural innovation, not Stack More Layers
[Christiano][17:40]
yeah
whereas I expect layer stacking + maybe changing loss (since logprob is too noisy) is sufficient
[Yudkowsky][17:40]
if you name 5 possible architectural innovations I can call them small or large
[Christiano][17:41]
1. replacing transformer attention with DB nearest-neighbor lookup over an even longer context
[Yudkowsky][17:42]
okay 1's a bit borderline
[Christiano][17:42]
2. adding layers that solve optimization problems internally (i.e. the weights and layer N activations define an optimization problem, the layer N+1 solves it) or maybe simulates an ODE
[Yudkowsky][17:42]
if it's 3x longer context, no biggie, if it's 100x longer context, more of a game-changer
2 - big change
[Christiano][17:42]
I'm imagining >100x if you do that
3. universal transformer XL, where you reuse activations from one context in the next context (RNN style) and share weights across layers
[Yudkowsky][17:43]
I do not predict 1 works because it doesn't seem like an architectural change that moves away from what I imagined to be the limits, but it's a big change if it 100xs the window
3 - if it is only that single change and no others, I call it not a large change relative to transformer XL. Transformer XL itself however was an example of a large change - it didn't have a large effect but it was what I'd call a large change.
[Christiano][17:45]
4. Internal stochastic actions trained with reinforce
I mean, is mixture of experts or switch another big change?
are we just having big changes non-stop?
[Yudkowsky][17:45]
4 - I don't know if I'm imagining right but it sounds large
[Christiano][17:45]
it sounds from these definitions like the current rate of big changes is > 1/year
[Yudkowsky][17:46]
5 - mixture of experts: as with 1, I'm tempted to call it a small change, but that's because of my model of it as doing the same thing, not because it isn't in a certain sense a quite large move away from Stack More Layers
I mean, it is not very hard to find a big change to try?
finding a big change that works is much harder
[Christiano][17:46]
several of these are improvements
[Yudkowsky][17:47]
one gets a minor improvement from a big change rather more often than a big improvement from a big change
that's why dinosaurs didn't foom
[Christiano][17:47]
like transformer -> MoE -> switch transformer is about as big an improvement as LSTM vs transformer
so if we all agree that big changes are happening multiple times per year, then I guess that's not the difference in prediction
is it about the size of gains from individual changes or something?
or maybe: if you take the scaling laws for transformers, are the models with impact X "on trend," with changes just keeping up or maybe buying you 1-2 oom of compute, or are they radically better / scaling much better?
that actually feels most fundamental
[Yudkowsky][17:49]
I had not heard that transformer -> switch transformer was as large an improvement as lstm -> transformers after a year or two, though maybe you're referring to a claimed 3x improvement and comparing that to the claim that if you optimize LSTMs as hard as transformers they come within 3x (I have not examined these claims in detail, they sound a bit against my prior, and I am a bit skeptical of both of them)
so remember that from my perspective, I am fighting an adverse selection process and the Law of Earlier Success
[Christiano][17:50]
I think it's actually somewhat smaller
[Yudkowsky][17:51]
if you treat GPT-3 as a fixed thingy and imagine scaling it in the most straightforward possible way, then I have a model of what's going on in there and I don't think that most direct possible way of scaling gets you past GPT-3 lacking a deep core
somebody can come up and go, "well, what about this change that nobody tried yet?" and I can be like, "ehhh, that particular change does not get at what I suspect the issues are"
[Christiano][17:52]
I feel like the framing is: paul says that something is possible with "stack more layers" and eliezer isn't. We both agree that you can't literally stack more layers and have to sometimes make tweaks, and also that you will scale faster if you make big changes. But it seems like for Paul that means (i) changes to stay on the old trend line, (ii) changes that trade off against modest amounts of compute
so maybe we can talk about that?
[Yudkowsky][17:52]
when it comes to predicting what happens in 2 years, I'm not just up against people trying a broad range of changes that I can't foresee in detail, I'm also up against a Goodhart's Curse on the answer being a weird trick that worked better than I would've expected in advance
[Christiano][17:52]
but then it seems like we may just not know, e.g. if we were talking lstm vs transformer, no one is going to run experiments with the well-tuned lstm because it's still just worse than a transformer (though they've run enough experiments to know how important tuning is, and the brittleness is much of why no one likes it)
[Yudkowsky][17:53]
I would not have predicted Transformers to be a huge deal if somebody described them to me in advance of having ever tried it out. I think that's because predicting the future is hard not because I'm especially stupid.
[Christiano][17:53]
I don't feel like anyone could predict that being a big deal
but I do think you could predict "there will be some changes that improve stability / make models slightly better"
(I mean, I don't feel like any of the actual humans on earth could have, some hypothetical person could)
[Yudkowsky][17:57]
whereas what I'm trying to predict is more like "GPT-5 in order to start-to-awaken needs a change via which it, in some sense, can do a different thing, that is more different than the jump from GPT-1 to GPT-3; and examples of things with new components in them abound in Deepmind, like Alpha Zero having not the same architecture as the original AlphaGo; but at the same time I'm also trying to account for being up against this very adversarial setup where a weird trick that works much better than I expect may be the thing that makes GPT-5 able to do a different thing"
this may seem Paul-unfairish because any random innovations that come along, including big changes that cause small improvements, would tend to be swept up into GPT-5 even if they made no more deep difference than the whole thing with MoE
so it's hard to bet on
but I also don't feel like it - totally lacks Eliezer-vs-Paul-ness if you let yourself sort of relax about that and just looked at it?
also I'm kind of running out of energy, sorry
[Christiano][18:03]
I think we should be able to get something here eventually
seems good to break though
that was a lot of arguing for one day